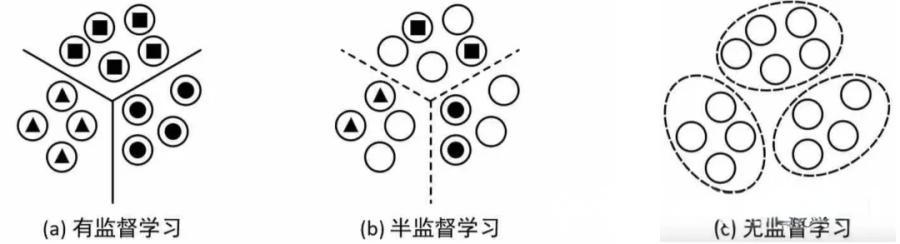
机器学习算法可以按照学习方式分为有监督学习、无监督学习和半监督学习三大类。
资料获取
为了加深大家对机器学习的掌握,我准备了一整套机器学习资料还有800G人工智能资料,不仅有入门教程和讲义,还有几十个机器学习练手项目,更有零基础入门学习路线,不论你处于什么阶段,这份资料都能帮助你更好地入门到进阶。
需要的兄弟可以按照这个图的方式免费获取
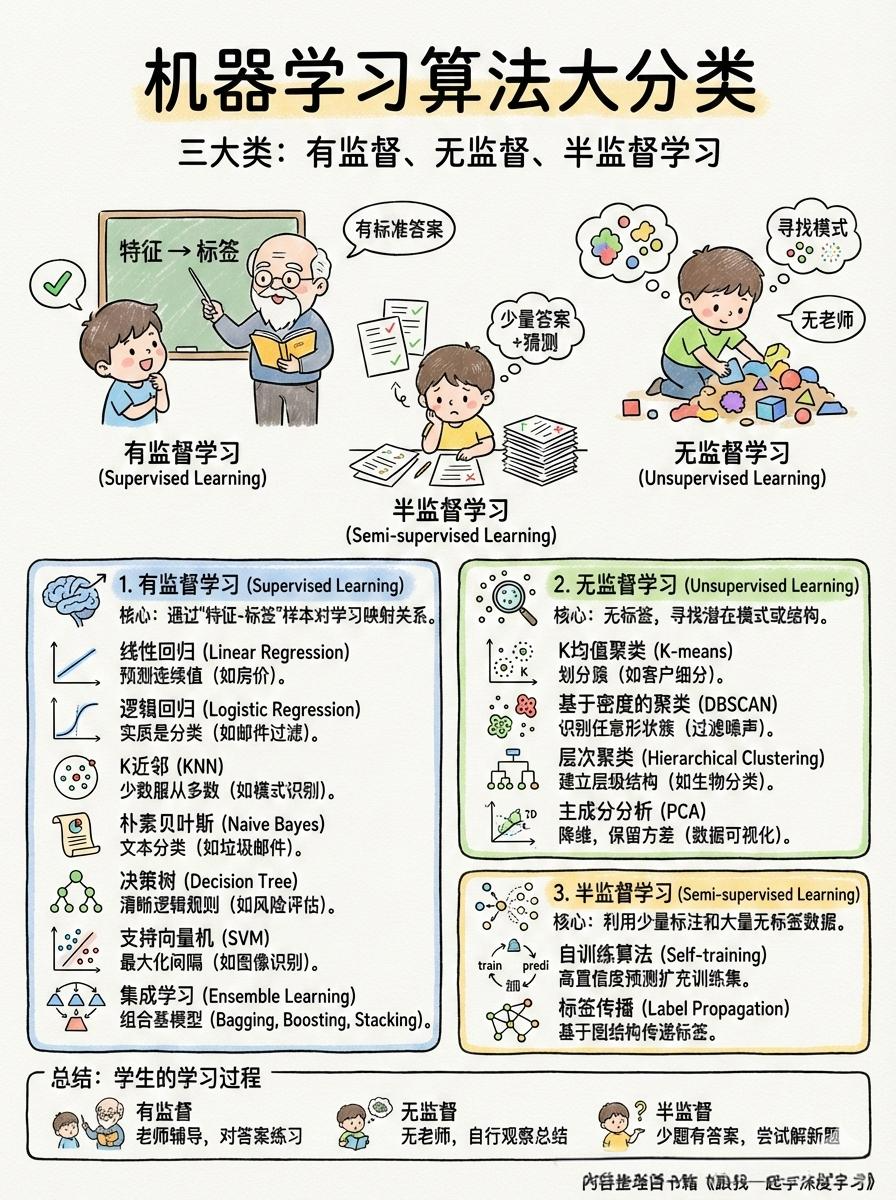
以下是常见算法的核心思想、适用场景及分类总结:
1. 有监督学习 (Supervised Learning)
有监督学习是指模型在训练过程中通过"特征-标签"样本对进行学习,建立从输入到输出的映射关系。
-
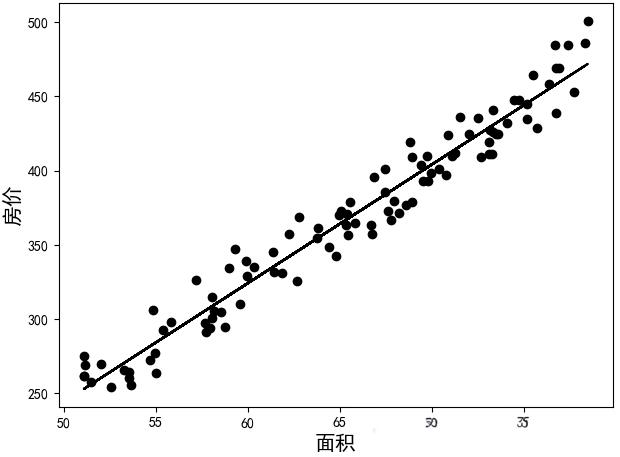
线性回归 (Linear Regression)
-
核心思想:通过寻找最佳的权重参数 和偏置 ,最小化预测值与真实值之间的均方误差。
-
适用场景 :对连续值进行预测,如房价预测、气象数值预测。
-
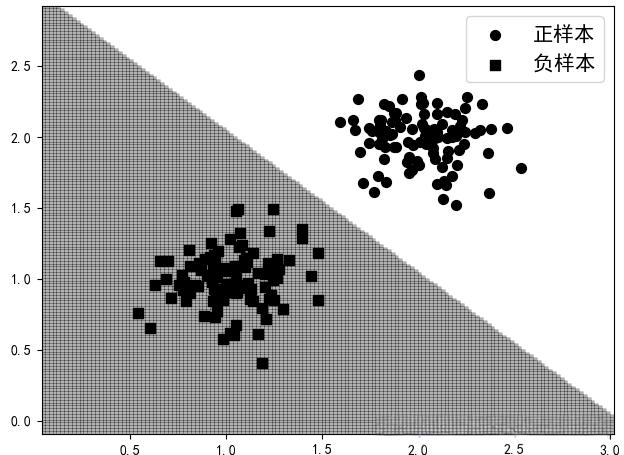
逻辑回归 (Logistic Regression)
-
核心思想:虽然名为回归,实质是分类模型。它将线性组合的结果通过 Sigmoid 函数映射到 区间,表示样本属于某一类别的概率。
-
适用场景 :二分类或多分类任务,如邮件过滤、点击率预测。
-
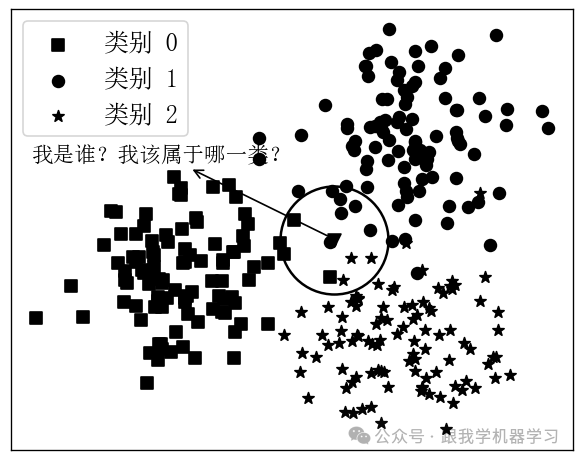
K近邻 (K-Nearest Neighbor, KNN)
-
核心思想:基于"少数服从多数"原则,根据新样本周围最近的 个训练样本的类别进行投票决策。
-
适用场景 :模式识别、简单分类任务,如手写体识别、垃圾邮件初步分类。
-
-
朴素贝叶斯 (Naive Bayes)
-
核心思想:基于贝叶斯公式并假设特征之间相互独立(朴素假设),通过极大化后验概率来确定类别。
-
适用场景 :文本分类,尤其是垃圾邮件识别、情感分析。
-
-
决策树 (Decision Tree)
-
核心思想:通过信息增益或基尼不纯度等标准,将决策过程看作一系列 if-then 规则的集合,旨在降低信息的不确定性。
-
适用场景 :风险评估、贷款审批、医疗诊断等具有清晰逻辑规则的场景。
-
-
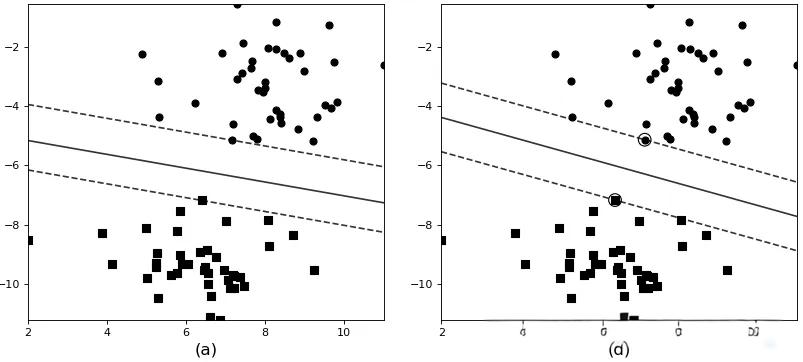
支持向量机 (Support Vector Machine, SVM)
-
核心思想:寻找一个能够最大化两类样本之间间隔的超平面,通过核技巧解决线性不可分问题。
-
适用场景 :高维特征的小样本分类,如图像识别、生物信息学。
-
-
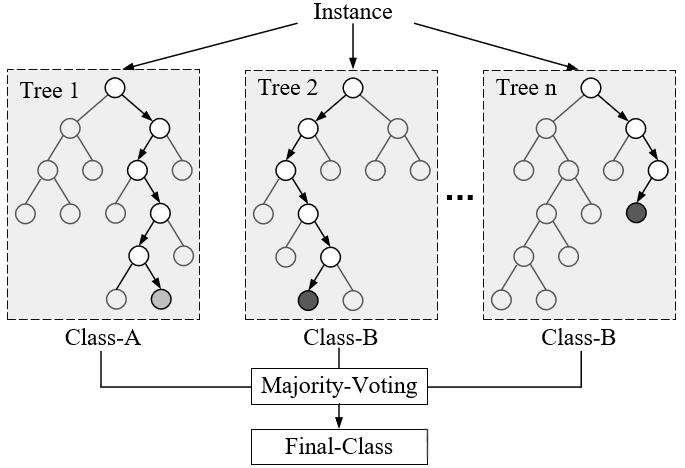
集成学习 (Ensemble Learning)
-
核心思想 :通过组合多个基模型来提高整体泛化能力。包括并行训练的 Bagging (如随机森林)、串行纠错的 Boosting (如AdaBoost、GBDT)和层叠组合的 Stacking。
-
适用场景 :复杂分类和回归任务,追求高精度和强稳健性的工业级应用。
-
2. 无监督学习 (Unsupervised Learning)
无监督学习在训练中不需要真实标签,模型仅根据输入特征寻找数据中潜在的模式或结构。
-
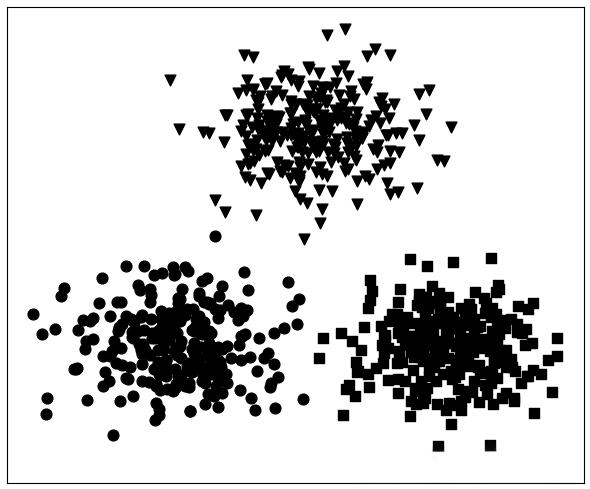
K均值聚类 (K-means/K-means++)
-
核心思想:通过迭代寻找 个簇中心,将样本划分到与其距离最近(相似度最高)的簇中。
-
适用场景 :客户细分、图像分割、数据探索性分析。
-
-
基于密度的聚类 (DBSCAN)
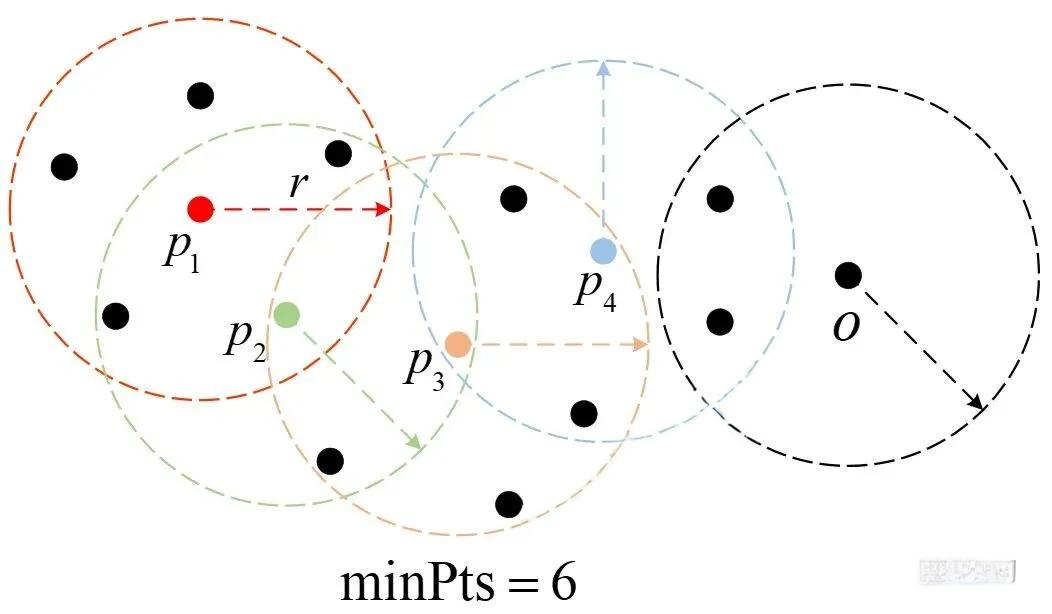
-
核心思想:根据样本分布的密度(紧凑程度)进行聚类,能够识别出任意形状的簇并过滤噪声点。
-
适用场景 :包含噪声、簇形状不规则的数据集。
-
-
层次聚类 (Hierarchical Clustering)
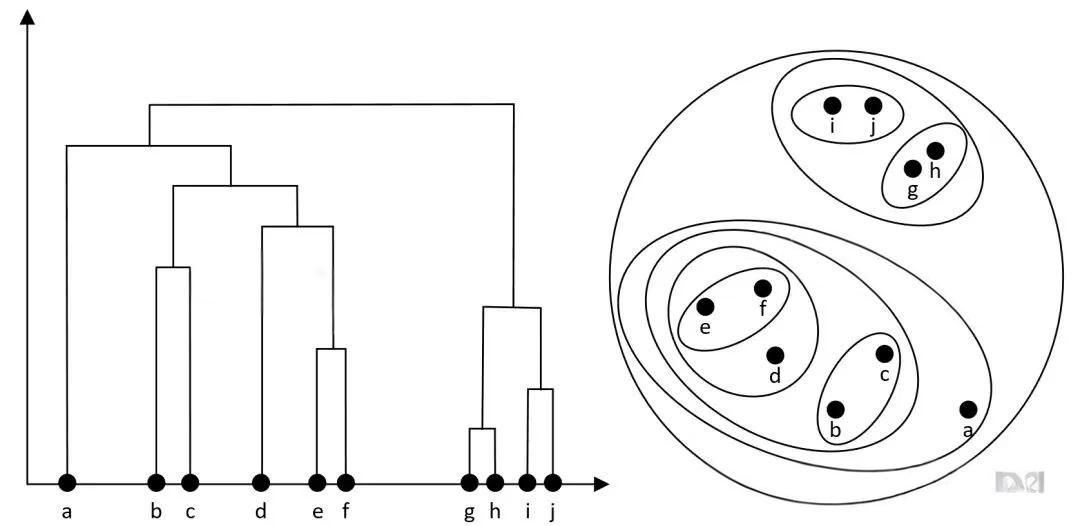
-
核心思想:自下而上(凝聚)或自上而下(分裂)地建立簇的层次结构,生成树状图展示样本间的包含关系。
-
适用场景 :需要展示数据层级结构的任务,如分类生物物种。
-
主成分分析 (PCA/Kernel PCA)
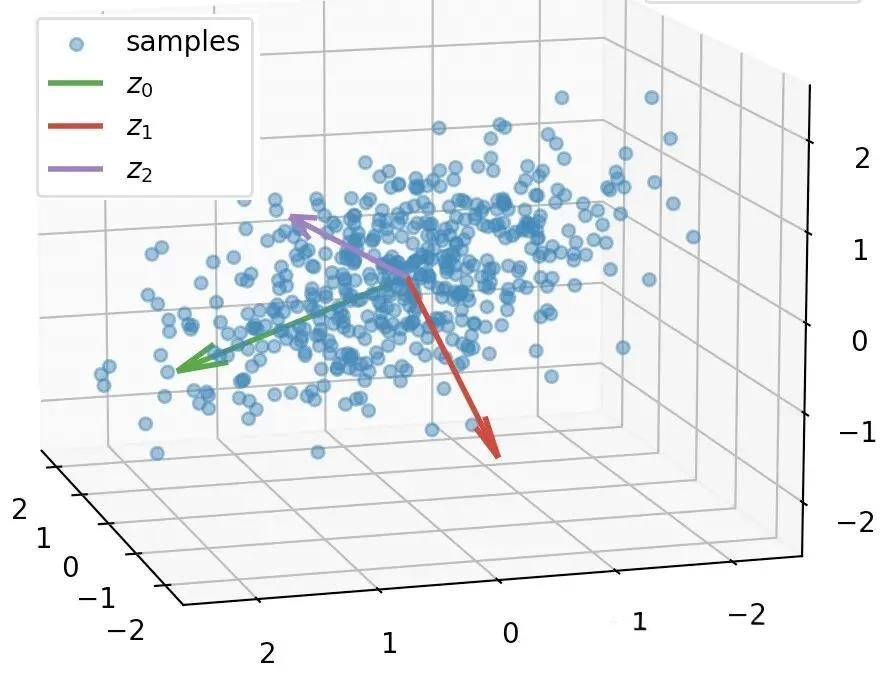
-
核心思想:将高维特征投影到低维的主成分空间,保留尽可能多的原始数据方差(结构信息)。
-
适用场景 :高维数据可视化、数据降维、去除冗余特征。
-
3. 半监督学习 (Semi-supervised Learning)
介于前两者之间,利用少量标注数据和大量无标签数据来完成模型训练。
-
自训练算法 (Self-training)
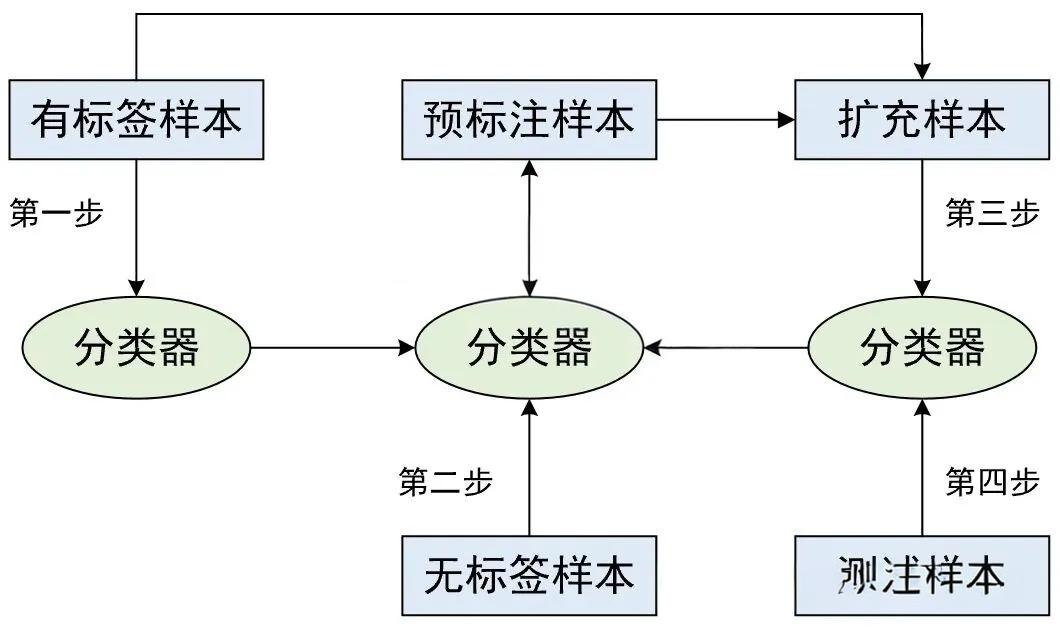
-
核心思想:先用少量标签数据训练一个弱分类器,对无标签数据预测后,选取高置信度的预测结果扩充训练集,循环往复。
-
适用场景 :标签获取昂贵、仅有极少部分数据被标注的情况。
-
-
标签传播/扩散算法 (Label Propagation/Spreading)
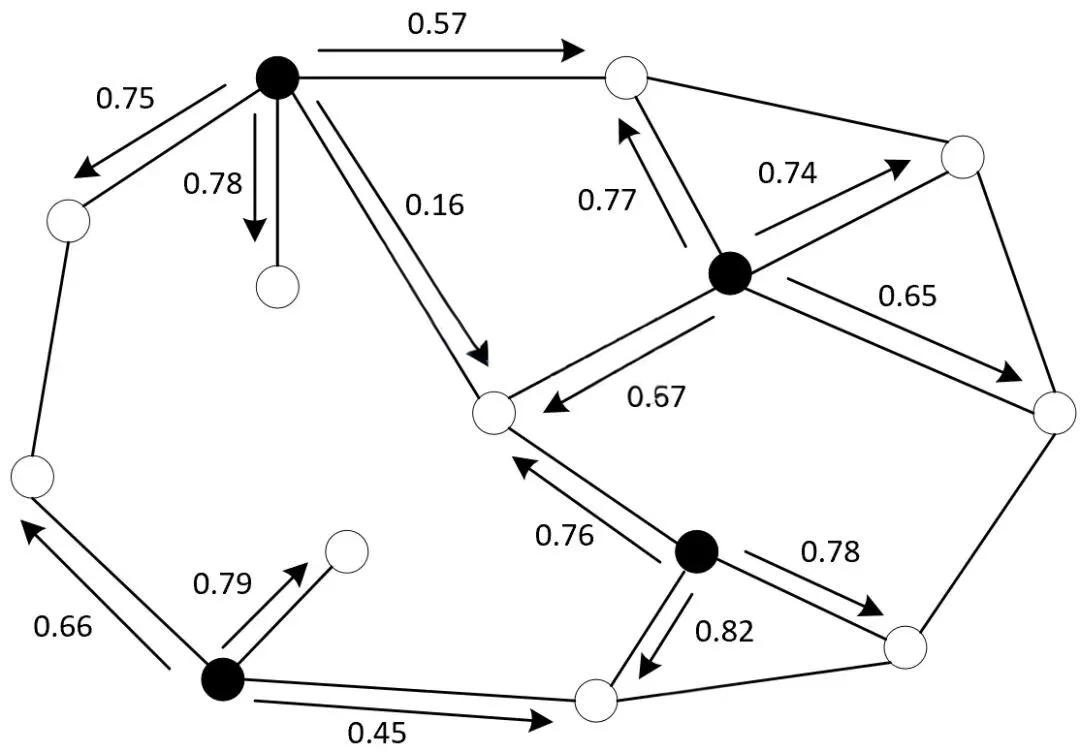
-
核心思想:构建样本间的有向图,利用相似样本点间距离越近越可能有相同标签的原理,将标签信息从有标注点传递到无标注点。
-
适用场景 :基于图结构的社交网络分析、半监督社区检测。
-
4. 总结
我们可以把机器学习算法比作一个学生学习知识的过程:
-
有监督学习 :像是在老师的辅导下,对着有标准答案的试卷不断练习,从而学会根据题目(特征)推导答案(标签)。
-
无监督学习:像是在没有老师和参考书的情况下,学生自己观察一堆物品,发现其中长得像的就分到一堆,或者找出物品的主要特征进行精简(聚类与降维)。
-
半监督学习 :像是一个学生只有几道题有答案,他先学会这几道题,然后尝试去写没有答案的题,并根据自己的判断把写对概率大的题目当作新的例题来学习。