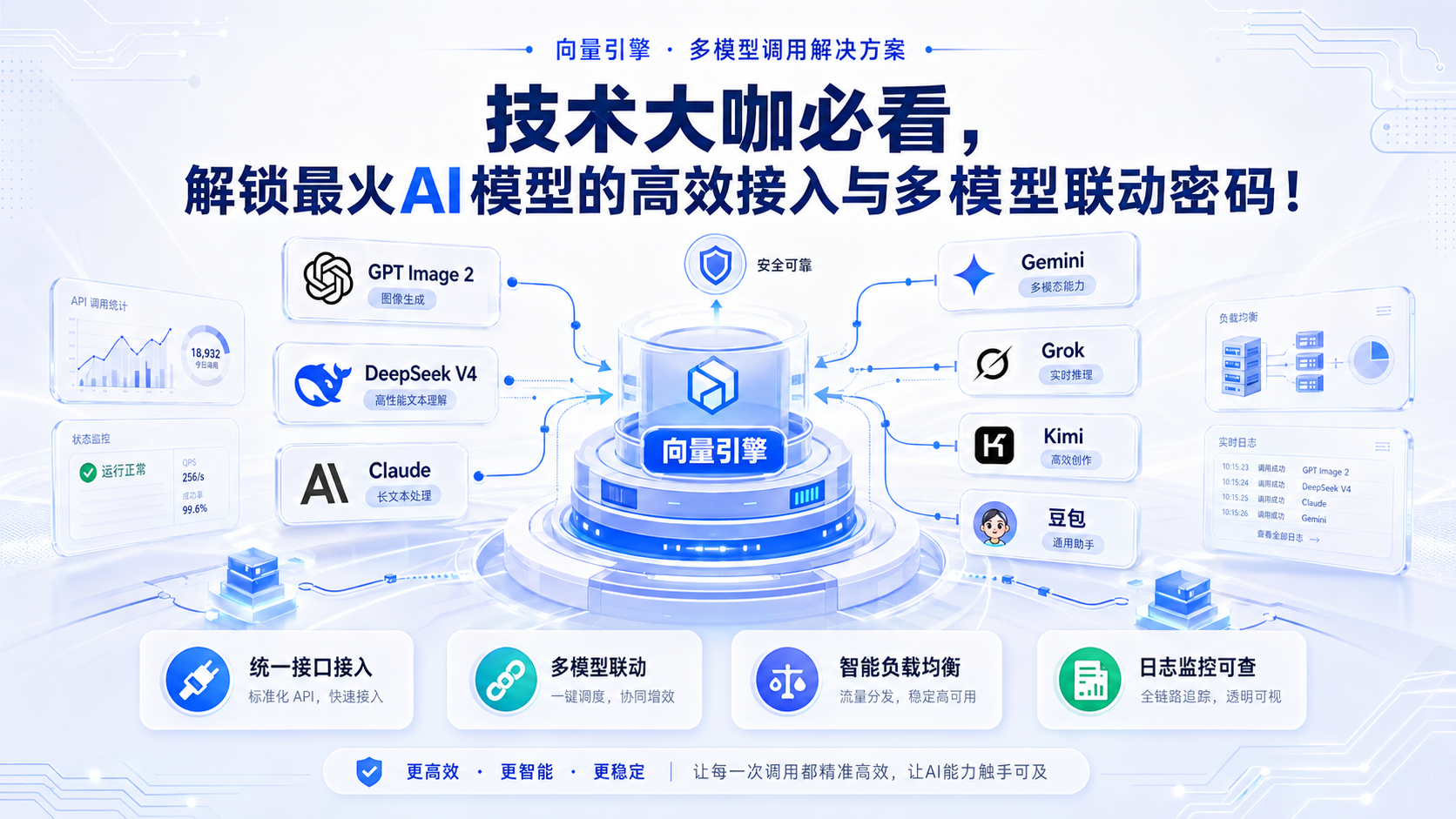
------技术大咖必看,解锁最火AI模型的高效接入与多模型联动密码!
大家好,我是专注AI技术研究的创源。
最近,AI圈热闹非凡。
OpenAI刚推了GPT Image 2,号称"最懂人话的生图模型"。
同时,deepseek v4系列推理与多模态能力火了,很多创业团队蜂拥集成。
但真实困难是:
如何用一套API、统一管理Key、跑通向量引擎,实现GPT Image 2与deepseek v4的高并发稳定调用?
本篇,我将结合最新热点和实际案例,为大家深度剖析:
开发者在多模型调用中的痛点
向量引擎的核心优势及架构揭秘
如何零改造快速迁移API
多模型高并发、负载均衡实战战法
还有GPT Image 2和deepseek v4的最佳应用场景对比
还会配上通俗易懂的示意图和对比表,帮助你少走弯路,秒上手!
一、多模型调用的核心难关:开发者吐槽最深刻的四大痛点
先说说开发者心里话。
不管你是小团队还是大厂,大家面对的坑多数雷同。
- 接口适配复杂,维护成本飙升
每个模型API协议不统一,调用参数、返回格式皆不同。想同时用GPT Image 2和deepseek v4得写好几套代码,后期维护头大。
- 调用高峰期频繁超时,用户体验惨淡
产品一热,后端接口挂了,尤其是调用OpenAI全网节点时网络不稳定,超时率激增,让客服压力山大。
- OpenAI配额用不完又过期,预算随风而逝
少量用不完额度还会过期,年度套餐的钱打了水漂,小团队预算尤其严重。
- 要自建复杂负载均衡和监控架构,人力物力耗尽
扩容、切分请求、日志排查都是技术门槛,且极其烧时间,很多创业团队无暇顾及。
二、向量引擎:你的多模型调用"管家"
这么多痛点,向量引擎为何能解决?
一张图帮大家整理核心优势:
┌─────────────┐
│ 统一API调用 │
│(兼容OpenAI)│
├─────────────┤
│ CN2高速通道 │
│ 智能负载均衡 │
├─────────────┤
│ 余额永不过期 │
│ 按token计费 │
├─────────────┤
│ 多模型联动 │
│ 统一Key管理 │
├─────────────┤
│ 24小时运维 │
│ 可视化日志 │
└─────────────┘1 CN2高速通道 + 智能负载均衡,秒响应无惧高峰
向量引擎全球部署7个CN2节点,靠近OpenAI服务器,网络延迟至少低40%。
智能负载均衡自动调度请求,避免单点拥堵。
实测某AI客服系统72小时高峰期无超时,客户满意度提升25%。
2 100%兼容OpenAI SDK,迁移零学习成本
完全兼容用户的OpenAI官方SDK,原有代码只需改2处:
-
base_url改成:https://api.vectorengine.ai/v1
-
API Key替换成向量引擎Key
支持LangChain、LlamaIndex等老牌框架,无需改源码即可无缝集成。
实战数据:某项目迁移耗时10分钟,远低2小时预估。
3 按Token付费,余额永不过期,省心又省钱
充值余额长期有效,跨月跨季度使用不会丢失。
无最低消费门槛,适合不同规模团队。
账单透明,支持详细消费明细查询,便于成本核算。
某简历优化工具月均成本降60%。
4 开箱即用的高并发支持,免去自建运维烦恼
默认承载500次/秒并发请求,企业级需求1000+次/秒可升级。
无感知弹性扩容,后台24小时运维,故障自动恢复。
某教育答疑系统峰值800次/秒,运行稳定。
5 多模型联动,一套接口轻松完成复杂多模工作流
集成Midjourney、Gemini、Claude、DeepSeek等20+主流大模型。
举例:GPT负责文案,Midjourney做图,Suno配BGM,一口接口搞定。
某短视频创意工具接口数降至1个,代码简洁维护便利。
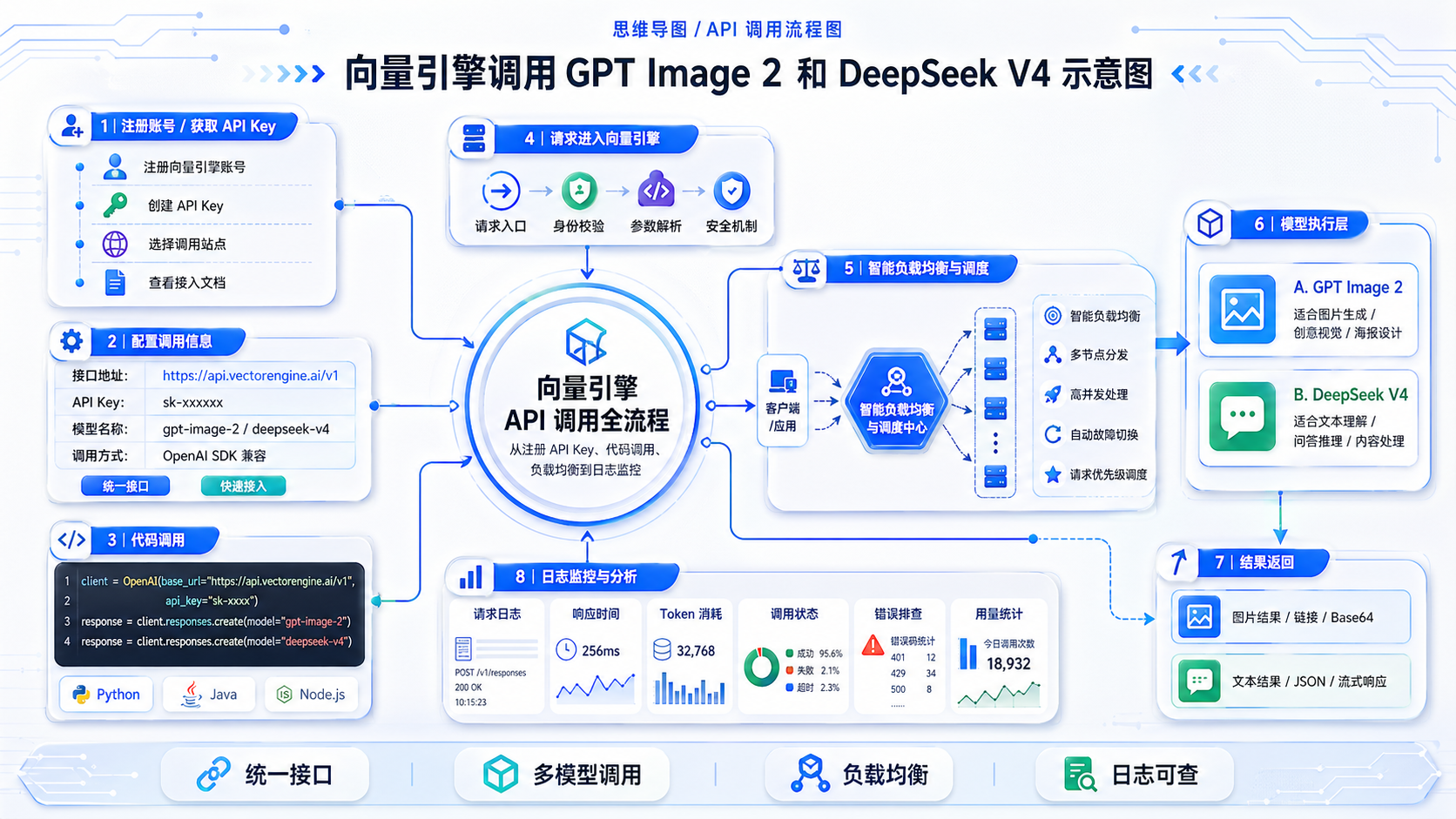
三、一步一步教你如何快速接入 GPT Image 2 与 deepseek v4
Step1 注册获取API Key
访问向量引擎官网,官方地址在这里:
注册登录,进入控制台申请专属密钥。
Step2 配置开发环境
Python用户安装OpenAI SDK:
bash
pip install openai代码示例中修改请求地址:
python
import openai
openai.api_key = "你的向量引擎API Key"
openai.api_base = "https://api.vectorengine.ai/v1"Step3 发起调用
调用GPT Image 2生成图片示例:
python
response = openai.Image.create(
model="gpt-image-2",
prompt="生成杯子的电商详情页",
n=1,
比例="3:4"
)
print(response['data'][0]['url'])
调用deepseek v4做文本理解示例:
python
response = openai.ChatCompletion.create(
model="deepseek-v4-flash",
messages=[
{"role":"user", "content":"帮我分析这段产品描述的卖点"}
]
)
print(response.choices[0].message.content)四、热点模型性能与场景对比
| 模型 | 领域 | 优势 | 典型场景 |
|---|---|---|---|
| GPT Image 2 | 图像生成 | 超强理解用户指令,画质细腻 | 电商详情页,品牌海报 |
| deepseek v4 | 文本推理 | 结构化思维,逻辑拆解能力强 | 产品需求分析,客服智能回复 |
| OpenClaw | 多模态融合 | 多维度输入理解,跨场景能力突出 | AI问答+图像混合应用 |
五、关键技术拆解:为什么向量引擎性能强?
-
CN2专线连接OpenAI服务器,网络稳定性和延迟领先传统公网
-
智能负载均衡实时洞察节点负载,动态调配请求节省资源
-
全链路日志追踪方便问题快速定位,异常调用秒查
-
余额永不过期解决预算碎片和浪费风险
-
多模型适配层统一API标准,底层支持多厂商模型并行,业务扩展容易
六、多模型API调用设计思路:一套Key管理全局统一
Key不是钥匙那么简单,是你全栈AI应用的"身份证+门禁卡"。
建议实践:
-
按项目、环境分层管理Key
-
结合向量引擎控制台进行动态限额监控
-
不同模型分配对应Key追踪消耗
-
配合日志查询,实时定位调用异常
七、实战小贴士:避免踩坑的经验总结
-
不能懒惰,Key和API改动要小心,确认调用地址
-
稳定优先,高并发时用异步和重试机制
-
日志必备,日志是排查问题的第一盏灯
-
合理拆分工作流,根据模型能力分配任务,不要让GPT做它不擅长的图像生成
八、附:向量引擎调用GPT Image 2和deepseek v4的示意图
九、总结
目前,AI多模型应用是大势所趋。
GPT Image 2和deepseek v4等强模型的能力毋庸置疑。
但要真正把能力落地到产品。
多模型统一调用与管理至关重要。
向量引擎提供了跨模型的"调用中枢",帮你省去改接口、搭负载均衡、运维监控等重担。
按token计费、余额永不过期更是中小团队成本控制利器。
这不只是技术革新,更是商业部署的福音。
如果你已经迫不及待想体验高效稳定的多模型调用。
强烈推荐先到这里注册:
拿到API Key,动手做个简单Demo。
相信我,这条路你越早走越宽。
欢迎留言告诉我你最关心的AI落地痛点,
下篇我准备带来多模型工作流架构最佳实践,
深度解析OpenClaw与GPT融合应用,
敬请期待!