但凡好一点的程序员,写代码的时候都在想一件事:怎么把代码组织好,让它有结构。
代码一旦有了结构,就不容易被破坏。别人要新增功能的时候,是在这个结构上修改的,不是随便找个地方塞几行代码。好的代码结构,是对未来修改的一种约束。它不阻止修改,而是引导修改沿着正确的方向走。
如果你觉得某块业务的固定流程很明显,就大胆地把代码组织好。
AccessToken的获取就是这种场景。做过第三方系统对接的都知道,不管是钉钉、飞书还是企业微信,获取AccessToken的流程几乎一样:用应用凭证请求接口,拿到有时效的AccessToken,缓存起来,快过期了刷新。不同的只是每个平台的API地址、请求参数和返回格式。
流程骨架一样,细节不同。把骨架抽到基类里,子类只管自己平台那点差异。再配合工厂做分发,调用方连具体是哪个平台都不需要知道。下面看看怎么落地。
先看整体架构
展开细节之前,先看一下整体结构,有个全局认知后再看具体实现。
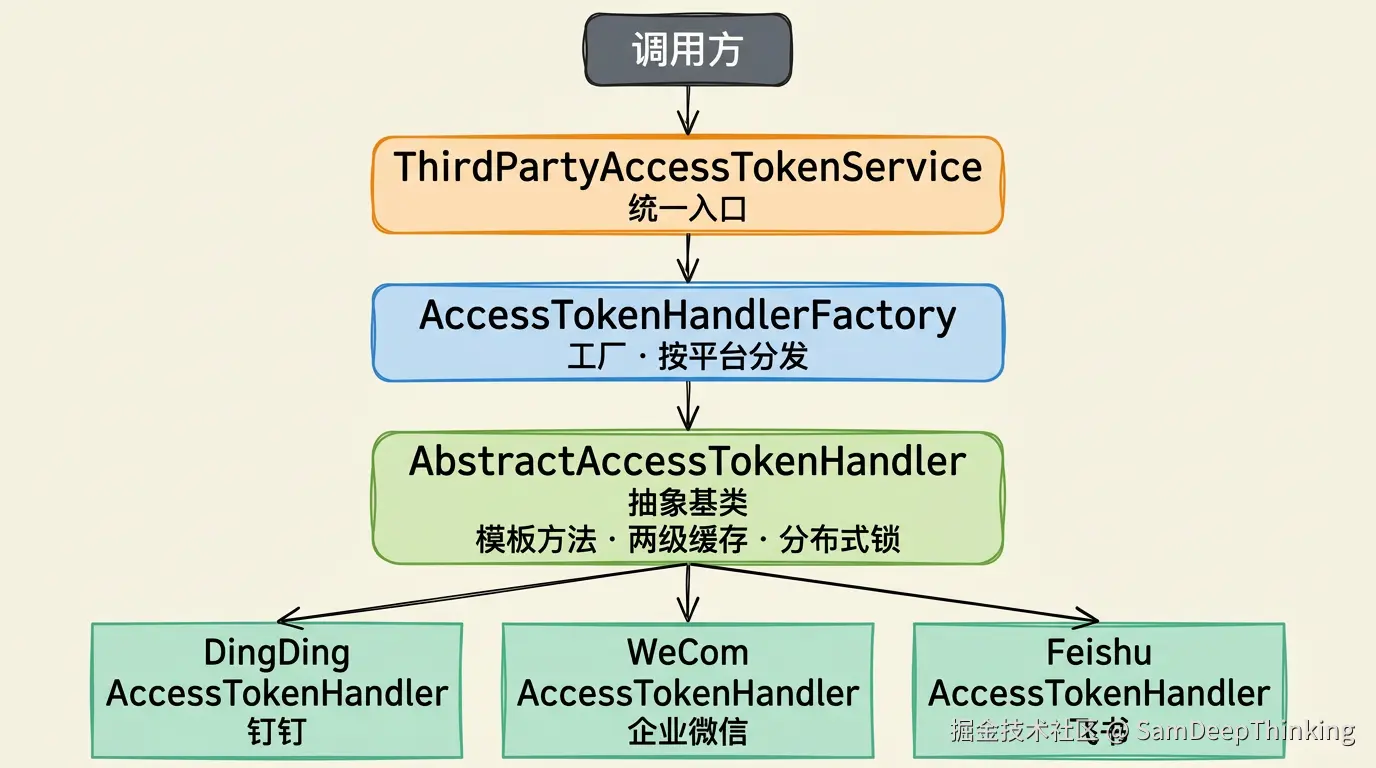
整个设计分四层:
ThirdPartyAccessTokenService是对外的统一入口。调用方只需要传一个平台枚举,就能拿到对应平台的AccessToken。它不包含任何获取AccessToken的具体逻辑,只负责把请求转交给下一层。
AccessTokenHandlerFactory是工厂。它在应用启动的时候,通过Spring自动注入收集所有的Handler实现类,按平台标识注册到一个Map里。拿到平台枚举后,从Map里取出对应的Handler,交给它去处理。
AbstractAccessTokenHandler是抽象基类,也是整个设计的核心。它定义了获取AccessToken的完整流程:查本地缓存、查Redis、加分布式锁、调第三方API、存缓存。这些步骤对所有平台都一样,全部在基类里实现。
DingDingAccessTokenHandler 、WeComAccessTokenHandler 、FeishuAccessTokenHandler是三个具体的子类。每个子类只需要实现两件事:怎么调自己平台的API,怎么把自己平台的返回值转成统一格式。
调用方不需要知道底层有几个平台、每个平台的API长什么样。新增平台的时候,调用方的代码一行都不用改。
不封装,会怎样
接过多个第三方系统的项目,如果不做统一封装,通常会发展成这样。
每个平台的AccessToken获取逻辑散落在各自的业务模块里。钉钉的在钉钉服务里,企业微信的在企业微信服务里,飞书的在飞书服务里。看起来各管各的挺整齐,问题是这几段代码的重复率能到70%以上。获取、缓存、过期判断、刷新,这些逻辑几乎一模一样,只是API地址和参数不同。
缓存策略也容易乱。有的同事用Redis缓存,有的用本地变量存,有的干脆不缓存每次都去请求第三方接口。在测试环境可能没什么感觉,到了生产环境请求量上来之后,频繁请求第三方接口很容易触发限流。
更麻烦的是并发场景。多个实例同时发现AccessToken过期,同时去请求第三方API刷新,拿回来的AccessToken互相覆盖。这种问题偶发且难复现,排查起来很耗时间。
每新接一个平台,就把上面的代码复制一遍改改参数。接了五六个平台之后,想统一调整缓存策略或者加个监控埋点,得改五六个地方。漏改一个就是线上问题。
模板方法:流程骨架放基类
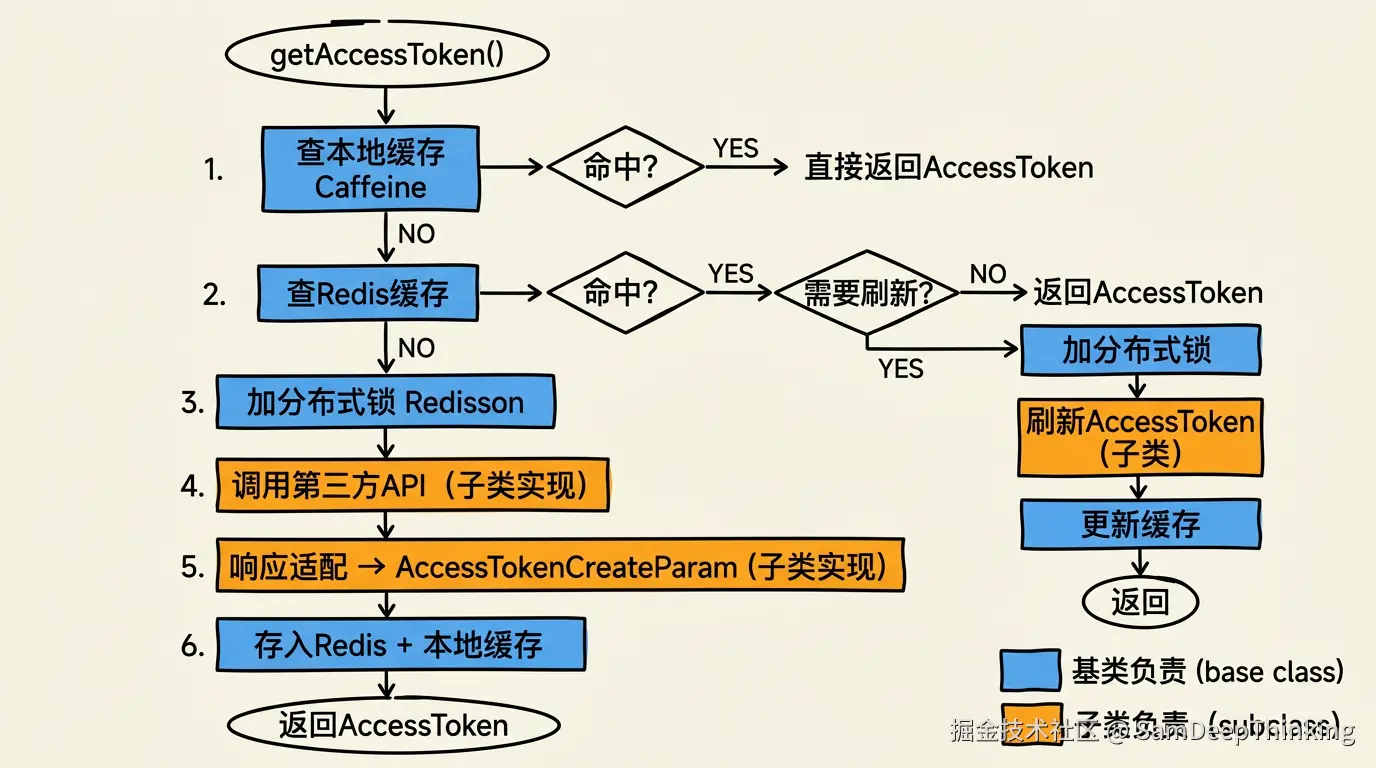
不管是哪个平台,获取AccessToken的流程骨架是固定的:
- 先查本地缓存(Caffeine),有就直接返回
- 本地没有,查Redis
- Redis有,判断是否快过期需要刷新
- Redis也没有,加分布式锁,调第三方API拿一个新的
- 拿到之后存Redis,返回结果
这就是模板方法模式最典型的应用场景。把不变的流程骨架放在基类AbstractAccessTokenHandler里,把变化的部分(调哪个API、怎么解析返回值)留给子类实现。
AbstractAccessTokenHandler的核心代码:
Java
package com.example.accesstoken.handler;
@Slf4j
public abstract class AbstractAccessTokenHandler {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Resource
private RedissonClient redissonClient;
private LoadingCache<AccessTokenAppCredential, AccessTokenResult> localCache;
private final Long localExpireTime;
private final Long redisExpireTime;
private final TimeUnit timeUnit;
private static final String CACHE_KEY_PREFIX = "access_token";
private static final String LOCK_KEY_PREFIX = "access_token_lock";
public AbstractAccessTokenHandler(Long localExpireTime, Long redisExpireTime, TimeUnit timeUnit) {
this.localExpireTime = localExpireTime;
this.redisExpireTime = redisExpireTime;
this.timeUnit = timeUnit;
}
@PostConstruct
public void init() {
// Caffeine本地缓存,过期后自动触发loadAccessToken加载
localCache = Caffeine.newBuilder()
.initialCapacity(2)
.maximumSize(2)
.expireAfterWrite(localExpireTime, timeUnit)
.build(this::loadAccessToken);
}
private AccessTokenResult loadAccessToken(AccessTokenAppCredential credential) {
String cacheKey = buildCacheKey(credential);
String lockKey = buildLockKey(credential);
// 查Redis
String cached = stringRedisTemplate.opsForValue().get(cacheKey);
if (StringUtils.isNotBlank(cached)) {
AccessTokenResult result = JSON.parseObject(cached, AccessTokenResult.class);
// 如果快过期了,走刷新逻辑
if (needRefreshAccessToken(result)) {
return doRefreshAndCache(result, cacheKey, lockKey);
}
return result;
}
// Redis也没有,加锁后调第三方API创建
return doCreateAndCache(cacheKey, lockKey, credential);
}
private AccessTokenResult doCreateAndCache(String cacheKey, String lockKey,
AccessTokenAppCredential credential) {
RLock lock = redissonClient.getLock(lockKey);
try {
lock.lock();
// 调用子类实现的方法,获取AccessToken
AccessTokenResult result = doCreateAccessToken(credential);
// 存入Redis
stringRedisTemplate.opsForValue()
.set(cacheKey, JSON.toJSONString(result), redisExpireTime, timeUnit);
return result;
} finally {
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
// 子类必须实现:调第三方API获取AccessToken,并把响应转换成统一结构
protected abstract AccessTokenResult doCreateAccessToken(AccessTokenAppCredential credential);
// 子类必须实现:返回平台标识
protected abstract String getPlatform();
// 可选覆写:判断是否需要提前刷新
protected boolean needRefreshAccessToken(AccessTokenResult result) {
return false;
}
public AccessTokenResult getAccessToken() {
return localCache.get(new AccessTokenAppCredential(null, null));
}
public AccessTokenResult getAccessToken(AccessTokenAppCredential credential) {
return localCache.get(credential);
}
}这段代码里有几个设计决策值得注意。
Caffeine的build(this::loadAccessToken)把缓存的加载逻辑和缓存本身绑定在了一起。调用方只需要调localCache.get(credential),如果本地缓存没有命中,Caffeine会自动执行loadAccessToken方法去加载。这意味着调用方完全不需要关心缓存命中还是没命中,Caffeine帮你处理了这个分支。
doCreateAccessToken是子类必须实现的抽象方法。基类的流程走到需要调第三方API的时候,就调这个方法。子类在这个方法里做两件事:发HTTP请求拿到原始响应,把原始响应转换成统一的AccessTokenResult。基类拿到的永远是同一个类型,后续的缓存、过期判断全部统一处理。
needRefreshAccessToken是一个可选覆写的方法,默认返回false。如果某个平台需要在AccessToken即将过期前提前刷新,子类可以覆写这个方法,加上自己的判断逻辑。大部分平台不需要这个能力,所以基类给了一个默认实现,子类不覆写也能正常工作。
子类有多简洁
看一个具体的子类实现。钉钉的AccessTokenHandler:
Java
package com.example.accesstoken.handler;
@Component
public class DingDingAccessTokenHandler extends AbstractAccessTokenHandler {
@Resource
private RestTemplate restTemplate;
// 本地缓存3600秒,Redis缓存7000秒
public DingDingAccessTokenHandler() {
super(3600L, 7000L, TimeUnit.SECONDS);
}
@Override
protected AccessTokenResult doCreateAccessToken(AccessTokenAppCredential credential) {
// 构造请求
String url = "https://oapi.dingtalk.com/gettoken?appkey="
+ credential.getAppId() + "&appsecret=" + credential.getAppSecret();
JSONObject response = restTemplate.getForObject(url, JSONObject.class);
// 把钉钉的响应格式转成统一结构
AccessTokenCreateParam createParam = convertResponse(response);
return AccessTokenResult.create(createParam);
}
@Override
protected String getPlatform() {
return AccessTokenPlatformEnum.DING_DING.getCode();
}
private AccessTokenCreateParam convertResponse(JSONObject response) {
// 钉钉返回的字段名是access_token和expires_in
return AccessTokenCreateParam.builder()
.accessToken(response.getString("access_token"))
.expiresIn(response.getLong("expires_in"))
.build();
}
}整个子类就做了三件事:在构造函数里配置缓存时间,在doCreateAccessToken里调钉钉API并转换响应,在getPlatform里返回平台标识。其他所有事情,缓存查找、分布式锁、Redis存储,全部由基类处理,子类一行都不用写。
钉钉AccessToken的有效期是7200秒(2小时)。这里本地缓存设的是3600秒,Redis设的是7000秒。为什么不直接设7200秒?因为要留出余量,避免使用一个马上就要过期的AccessToken发起请求,请求还没返回AccessToken就失效了。这个提前量没有标准答案,根据业务对时效性的要求来定。
响应适配:不同的返回值,统一的结构
整个方案能落地的一个关键环节是响应适配。每个第三方平台获取AccessToken的API,返回的JSON结构、字段名都不一样。
钉钉的返回结构:
JSON
{
"errcode": 0,
"errmsg": "ok",
"access_token": "xxx",
"expires_in": 7200
}企业微信的返回结构:
JSON
{
"errcode": 0,
"errmsg": "ok",
"access_token": "xxx",
"expires_in": 7200
}飞书的返回结构:
JSON
{
"code": 0,
"msg": "success",
"tenant_access_token": "xxx",
"expire": 7200
}看起来钉钉和企业微信的结构很像,但和飞书一比差异就出来了。飞书的AccessToken字段叫tenant_access_token而不是access_token,过期时间字段叫expire而不是expires_in,错误码字段叫code而不是errcode。请求方式也不同,钉钉和企业微信用GET请求带查询参数,飞书用POST请求带JSON body。
如果基类直接处理这些原始响应,就得写一堆if-else判断当前是哪个平台、字段名是什么。这就又耦合了。
解决方案是让每个子类自己负责把平台特有的响应格式,转换成统一的AccessTokenCreateParam。基类拿到的永远是同一个结构,不管底层是钉钉、企业微信还是飞书。
看一下飞书子类的转换逻辑和钉钉的对比:
Java
// 钉钉的转换:字段名是access_token和expires_in
private AccessTokenCreateParam convertResponse(JSONObject response) {
return AccessTokenCreateParam.builder()
.accessToken(response.getString("access_token"))
.expiresIn(response.getLong("expires_in"))
.build();
}
// 飞书的转换:字段名是tenant_access_token和expire
private AccessTokenCreateParam convertResponse(JSONObject response) {
return AccessTokenCreateParam.builder()
.accessToken(response.getString("tenant_access_token"))
.expiresIn(response.getLong("expire"))
.build();
}两段代码结构一模一样,只是取值的字段名不同。经过这一层转换,到了基类那里看到的都是AccessTokenCreateParam,里面永远是accessToken和expiresIn这两个字段,和具体平台无关。
适配这一层看着简单,但它的价值在于把外部差异挡在了子类里,基类完全不需要知道外面的世界有多混乱。 这是模板方法模式能落地的关键:基类定义数据结构的契约,子类负责把外部的混乱适配成基类能处理的统一格式。
实际项目中还会遇到更复杂的情况。有些第三方平台返回的过期时间不是剩余秒数,而是毫秒级的绝对时间戳,需要用当前时间做减法再除以1000才能换算成剩余秒数。这类差异全部在子类的转换方法里处理,基类完全无感。
AccessTokenCreateParam的结构:
Java
package com.example.accesstoken.factory;
@Data
@Builder
public class AccessTokenCreateParam {
// AccessToken字符串
private String accessToken;
// 过期时间,单位秒
private Long expiresIn;
// 部分平台支持通过refreshToken刷新AccessToken
private String refreshToken;
// 提前过期时间,默认180秒
private Integer advanceExpiresIn;
}这个类就是基类和子类之间的契约。子类往里填值,基类从里面取值,双方通过这个结构解耦。
工厂模式:按平台分发
有了基类和子类,还需要一个工厂来做分发。调用方传一个平台标识进来,工厂返回对应的Handler。
AccessTokenHandlerFactory的实现:
Java
package com.example.accesstoken.handler;
@Component
public class AccessTokenHandlerFactory {
@Autowired
private List<AbstractAccessTokenHandler> handlerList;
private final Map<String, AbstractAccessTokenHandler> handlerMap = new ConcurrentHashMap<>();
@PostConstruct
public void init() {
if (handlerList == null || handlerList.isEmpty()) {
return;
}
// 自动注册所有Handler到Map
for (AbstractAccessTokenHandler handler : handlerList) {
String platform = handler.getPlatform();
if (platform == null || platform.isEmpty()) {
continue;
}
handlerMap.put(platform, handler);
}
}
public AbstractAccessTokenHandler getHandler(String platform) {
AbstractAccessTokenHandler handler = handlerMap.get(platform);
if (handler == null) {
throw new IllegalArgumentException("未找到平台对应的AccessTokenHandler: " + platform);
}
return handler;
}
}这个工厂的注册机制利用了Spring的一个特性:当你注入List<AbstractAccessTokenHandler>的时候,Spring会自动把容器里所有AbstractAccessTokenHandler的子类实例收集起来放到这个List里。在@PostConstruct阶段遍历这个List,按平台标识注册到ConcurrentHashMap,就完成了工厂的初始化。
用Spring自动注入加Map注册的方式做工厂,比写if-else或switch-case好在哪?新增平台时只需要新建一个Handler类加上@Component注解,工厂代码零修改。 这就是开闭原则在实际项目中最常见的落地形式。不是抽象的原则,而是具体的代码组织方式。新来一个同事要接入飞书,他只需要写一个FeishuAccessTokenHandler,工厂、基类、其他平台的代码都不需要动。
统一入口ThirdPartyAccessTokenService则更简单,它只是把工厂和Handler串起来:
Java
package com.example.accesstoken.service;
@Service
@RequiredArgsConstructor
public class ThirdPartyAccessTokenService {
private final AccessTokenHandlerFactory handlerFactory;
public AccessTokenResult getAccessToken(AccessTokenAppCredential credential,
AccessTokenPlatformEnum platform) {
AbstractAccessTokenHandler handler = handlerFactory.getHandler(platform.getCode());
if (credential == null || credential.getAppId() == null) {
// 使用默认凭证
return handler.getAccessToken();
}
return handler.getAccessToken(credential);
}
}两级缓存
AccessToken不是每次请求都需要重新获取的,它有时效性(大部分平台是2小时),在有效期内可以反复使用。缓存策略的选择直接影响系统的性能和稳定性。
这里用的是两级缓存:Caffeine做本地缓存,Redis做分布式缓存。
为什么不只用Redis?如果每次获取AccessToken都走一趟Redis网络请求,在高频调用场景下网络开销不可忽略。Caffeine是本地内存缓存,命中的话直接从JVM堆内存返回,没有网络开销。大部分请求在本地缓存就命中了,只有本地缓存过期才会穿透到Redis。
为什么不只用Caffeine?因为多实例部署的时候,每个实例的本地缓存是隔离的。如果只用本地缓存,实例A创建了一个新的AccessToken,实例B不知道,它本地缓存过期后又去请求第三方API创建了另一个。Redis作为分布式缓存,让所有实例共享同一份AccessToken,一个实例创建了其他实例都能用。
缓存时间的设计有一个细节:本地缓存的过期时间要短于Redis,Redis的过期时间要短于AccessToken的真实有效期。 以钉钉为例,AccessToken真实有效期7200秒,Redis设7000秒,本地缓存设3600秒。本地缓存3600秒过期后,请求穿透到Redis,这时候Redis里的AccessToken还有3400秒有效期,直接返回。Redis缓存7000秒过期后,才需要重新调第三方API。200秒的余量是为了防止一个请求拿到AccessToken后还没来得及用它就过期了。
AccessTokenResult在创建的时候还会计算一个提前过期时间,默认提前180秒:
Java
public static AccessTokenResult create(AccessTokenCreateParam createParam) {
Date expiresTime = DateUtils.plusSeconds(new Date(), createParam.getExpiresIn());
// 默认提前3分钟标记为即将过期
Integer advanceSeconds = 180;
if (createParam.getAdvanceExpiresIn() != null) {
advanceSeconds = createParam.getAdvanceExpiresIn();
}
Date advanceExpiresTime = DateUtils.plusSeconds(
new Date(), createParam.getExpiresIn() - advanceSeconds);
return AccessTokenResult.builder()
.accessToken(createParam.getAccessToken())
.expiresIn(createParam.getExpiresIn())
.refreshToken(createParam.getRefreshToken())
.expiresTime(expiresTime)
.advanceExpiresTime(advanceExpiresTime)
.build();
}这个提前过期时间是给needRefreshAccessToken用的。如果某个平台支持刷新AccessToken(不是重新创建,而是用refreshToken换一个新的),子类可以覆写needRefreshAccessToken方法,判断当前时间是否已经超过了提前过期时间。超过了就触发刷新,避免等到真正过期了才去处理。
分布式锁
多实例环境下,如果Redis缓存刚好过期,多个实例会同时发现缓存不存在,同时去请求第三方API。这会导致短时间内重复请求,浪费资源,某些平台可能因此触发限流。
解决方式是在调用第三方API之前加一把分布式锁,用Redisson实现。只有拿到锁的实例才去请求第三方API,其他实例等锁释放后直接从缓存取。
锁的粒度是按平台_appId维度的。也就是说,钉钉的AccessToken和企业微信的AccessToken用的是不同的锁,互不阻塞。同一个平台如果有多个应用(不同的appId),每个应用也有自己的锁。锁的key大概长这样:access_token_lock:DING_DING_your_app_id。
这个粒度的选择是有考量的。如果所有平台共用一把锁,钉钉的AccessToken过期刷新会阻塞企业微信的请求,没必要。按平台加appId做维度,锁的粒度足够细,不会产生不必要的互斥。
各平台AccessToken对比速查表
接入新平台之前,通常需要查一下这个平台的AccessToken接口长什么样。下面这张表汇总了三个常见平台的关键信息,接入的时候可以直接对照。
| 维度 | 钉钉 | 企业微信 | 飞书 |
|---|---|---|---|
| AccessToken有效期 | 7200秒 | 7200秒 | 7200秒 |
| 建议本地缓存时间 | 3600秒 | 6600秒 | 6600秒 |
| 建议Redis缓存时间 | 7000秒 | 6600秒 | 6600秒 |
| 请求方式 | GET | GET | POST |
| 认证参数 | appKey + appSecret | corpId + corpSecret | app_id + app_secret |
| AccessToken字段名 | access_token | access_token | tenant_access_token |
| 过期时间字段名 | expires_in(秒) | expires_in(秒) | expire(秒) |
| 错误码字段名 | errcode | errcode | code |
| 需要特殊适配 | 无 | 无 | 字段名与其他平台不同 |
三个平台的AccessToken有效期都是7200秒,但字段命名差异不小。钉钉和企业微信的返回结构比较接近,飞书的字段名完全不一样。这也是为什么响应适配这一层不能省掉的原因。
新增一个平台的步骤
现在如果要接入一个新的第三方平台,整个过程只有5步:
- 在AccessTokenPlatformEnum新增一个枚举值
- 新建一个类继承AbstractAccessTokenHandler
- 实现
doCreateAccessToken()方法:发HTTP请求,把响应转成AccessTokenCreateParam - 实现
getPlatform()方法:返回枚举值的code - 在类上加
@Component注解
工厂代码不用改,基类代码不用改,其他平台的代码不用改。Spring启动的时候自动把新的Handler注册到工厂里,调用方传新的平台枚举就能拿到AccessToken。如果哪天这个平台不用了,删掉这一个类就行。
小结
设计模式在实际项目里的价值,不在于你能说出它的名字,而在于你能在合适的时候想到用它。模板方法解决的问题很具体:多个流程的骨架一样,但细节不同。当你看到这种特征的时候,不需要犹豫,把骨架抽出来就对了。工厂模式也一样,当调用方不应该关心具体实现是哪个的时候,加一层工厂做分发。
有人可能会觉得,就三个平台,写三个类各管各的也能跑,干嘛要搞这么多抽象。如果永远只有三个平台,各管各的确实没什么大问题。但实际项目里,第三方平台的数量是会变的。半年前只有钉钉,现在加了企业微信和飞书,下个季度可能还要接入某个行业系统。你不封装的话,每加一个平台,缓存、锁、过期判断的逻辑都得再写一遍。三个平台的时候还能忍,到了七八个平台想统一改个缓存策略,改七八个地方,漏一个就是事故。
判断要不要做封装,不是看当前有几个实现,而是看新增一个实现需要改多少地方。 如果答案是只需要新建一个类,那说明结构已经到位了。如果答案是要改好几个文件、复制好几段逻辑,那就该考虑封装了。
AccessToken管理看起来是个小事,做好了能省掉大量排查问题的时间。AccessToken过期没刷新、并发重复请求、缓存不一致,踩过这些坑的人都知道,每一个都能让你排查半天。把这块做扎实,后面不管接多少个第三方系统,这些问题都不会再出现。
希望这篇内容可以帮到你。
最近在知乎出了秒杀专栏,感兴趣的可以订阅一下。至于知识星球的,可以搜:
- 老码头的技术浮生录
它是一个能实际帮你解决难题的星球。有问题的,找知心的Sam哥,支持无限次语音一对一解决你遇到的难题。另外后续我新写的所有对外的付费专栏,在星球内都是免费的,且可以拿到所有源代码。
我的知乎账号:
- SamDeepThinking