分治算法核心定义
分治:分而治之,把一个规模较大的复杂原问题,拆分成若干个规模较小、结构和原问题相同的子问题;递归解决所有子问题后,再将子问题的结果合并,得到原问题的解。
三大核心步骤:分 → 治 → 合
分治经典应用
- 快速排序
分:选基准,将数组划分为左右两个区间
治:递归排序左、右子区间
合:天然有序,无需额外合并
- 归并排序
分:从中间拆分成左右两个子数组
治:递归排序左右子数组
合:双指针合并两个有序数组
-
快速选择(TopK问题):第K大/最小k个数,基于快排分治思想,只递归单侧区间
-
二分查找
分:折半划分区间
治:递归查找左/右区间
合:直接返回结果
- 其他:大数乘法、汉诺塔、最近点对问题
题目1:颜色分类(LeetCode 75)
- 题目描述
给定一个包含红色、白色和蓝色、共 n个元素的数组 nums ,**原地**对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。
必须在不使用库内置的 sort 函数的情况下解决这个问题。
示例 1:输入: nums = 2,0,2,1,1,0 输出:0,0,1,1,2,2
示例 2:输入: nums = 2,0,1 输出:0,1,2
提示: n == nums.length,1 <= n <= 300,nums[i] 为 0、1 或 2
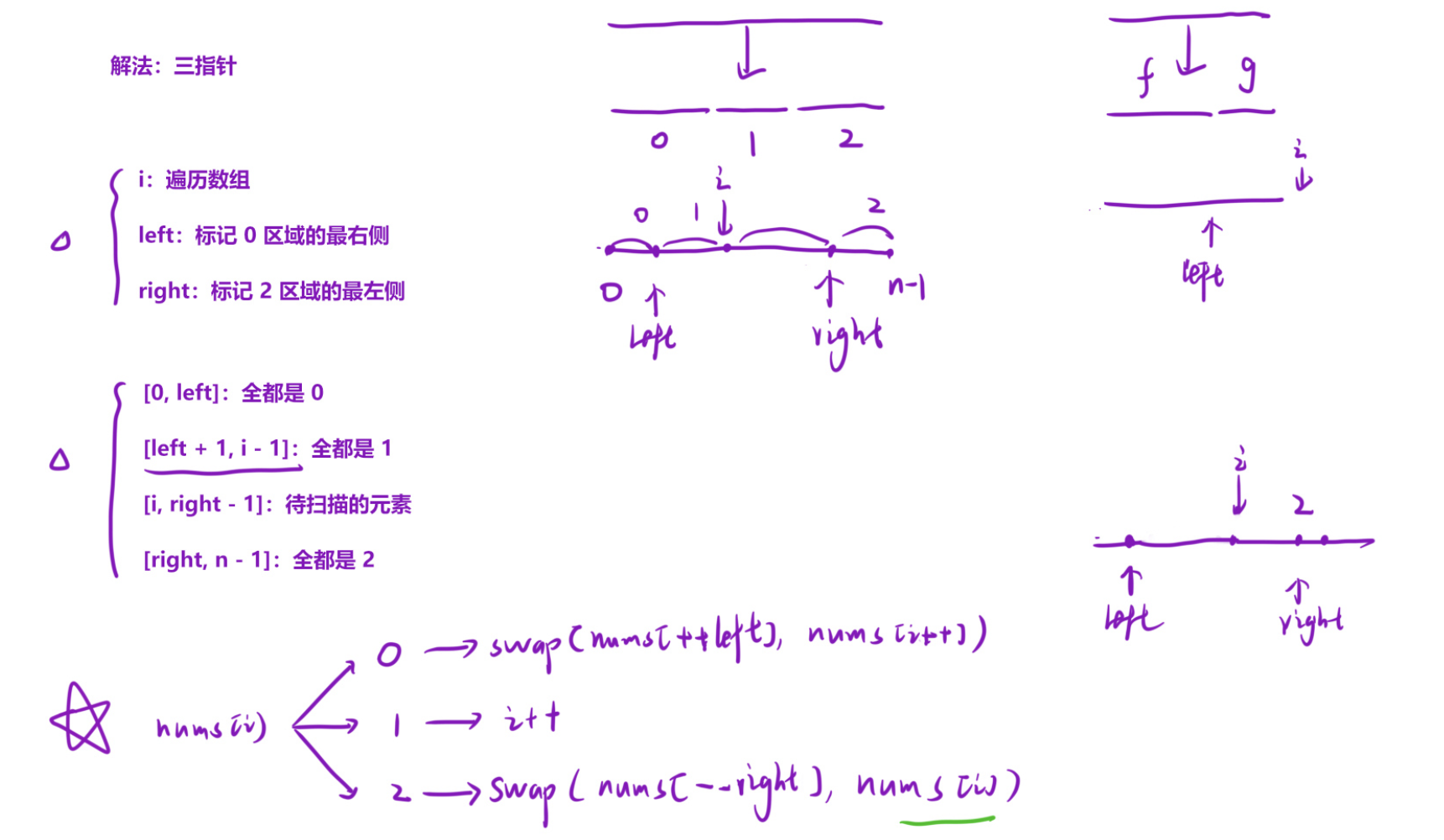
- 核心思想:三指针分块
定义三个指针,把数组划分成4个逻辑区域:
0, left:全是0(红色),left 是0序列的右边界
left+1, cur-1:全是1(白色),这是已经处理好的中间区域
cur, right-1:待处理区域
right, n-1:全是2(蓝色),right 是2序列的左边界
- 指针初始化与循环条件
cpp
cur = 0; // 扫描指针,负责遍历待处理区域
left = -1; // 初始时0序列为空,所以边界在-1
right = n; // 初始时2序列为空,所以边界在n(数组末尾+1)
while (cur < right) { ... }为什么循环条件是 cur < right?right 是2序列的左边界,当 cur 碰到 right 时,说明所有待处理元素都已经划分完成,不需要再处理了。
- 三种情况的处理逻辑
|------------------|------------------------------------------|-----------------------------------------------------------------------------------------------------|
| 情况 | 处理方式 | 为什么要这样做? |
| numscur == 0 | 交换 nums++left 和 numscur++ | left+1 是1序列的第一个位置,交换后0, left扩展一个0,cur 直接+1是因为交换过来的要么是1(cur原来的位置),要么是0(cur和left+1是同一个位置),都已经处理好了 |
| numscur == 1 | 直接 cur++ | 1已经在正确的区域里,不需要交换,直接扫描下一个 |
| numscur == 2 | 交换 nums--right 和 numscur,cur 不移动 | 交换过来的元素是right-1位置的,这个元素还没被扫描过,所以cur不能+1,要留在原地继续判断 |
- 代码逐行解析(颜色分类)
cpp
class Solution {
public:
void sortColors(vector<int>& nums) {
int n = nums.size();
int left = -1, right = n, i = 0;
while(i < right)
{
if(nums[i] == 0) swap(nums[++left], nums[i++]);
else if(nums[i] == 1) i++;
else swap(nums[--right], nums[i]);
}
}
};int left = -1, right = n, i = 0;:初始化三个指针,i就是上面的cur
numsi == 0:交换left+1和i,然后left和i同时+1,完成0区域的扩展
numsi == 1:直接i++,跳过已经正确的元素
numsi == 2:先right--,再交换right和i,i不变,因为交换来的元素需要重新判断
- 复杂度分析
时间复杂度:O(n),仅一次遍历,cur 从 0 走到 right,每个元素最多被访问/交换 1 次
空间复杂度:O(1),仅用 3 个指针变量,无额外数组/栈,原地修改
题目2:排序数组(LeetCode 912)快速排序
- 题目描述
给你一个整数数组 nums,请你将该数组升序排列。
你必须在 不使用任何内置函数 的情况下解决问题,时间复杂度为 O(nlog(n)),并且空间复杂度尽可能小。
示例 1:输入: nums = 5,2,3,1 输出: 1,2,3,5 **解释:**数组排序后,某些数字的位置没有改变(例如,2 和 3),而其他数字的位置发生了改变(例如,1 和 5)。
示例 2:输入: nums = 5,1,1,2,0,0 输出: 0,0,1,1,2,5 **解释:**请注意,nums 的值不一定唯一。
提示: 1 <= nums.length <= 5 * 104,-5 * 104 <= nums[i] <= 5 * 104
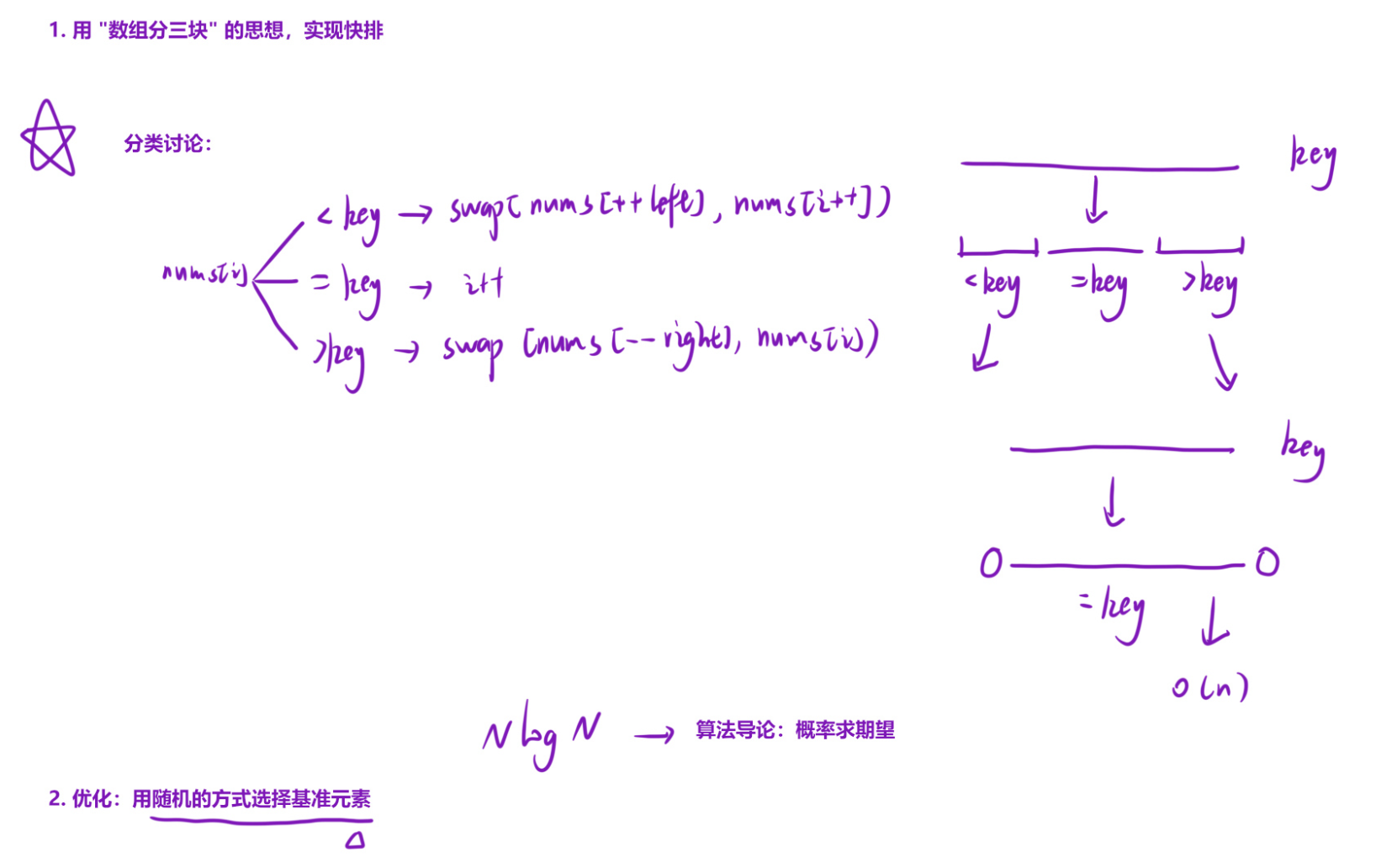
- 解法(数组分三块思想 + 随机选择基准元素的快速排序)
普通快排最坏时间复杂度是O(n^2)(比如数组完全有序时),而分三块+随机选基准的快排,平均时间复杂度稳定在O(nlog n),且在有大量重复元素时效率极高。
算法思路:快排最核心的一步就是 Partition(分割数据):将数据按照一个标准,分成左右两部分。
使用颜色分类问题的思想,将数组划分为左中右三部分:
左边:比基准元素小的数据 中间:与基准元素相同的数据 右边:比基准元素大的数据
然后再去递归的排序左边部分和右边部分(可以省去大量的中间部分)。在处理数据量有很多重复的情况下,效率会大大提升。
算法流程
1) 随机选择基准算法流程:如果每次选最左/最右元素当基准,当数组有序时,快排会退化成O(n^2);解决:用rand()生成随机下标,选数组中随机元素当基准,避免最坏情况
a. 在主函数里种下一颗随机数种子;
b. 在随机选择基准函数里生成一个随机数;
c. 将随机数转换成随机下标:随机数 % 区间大小 + 区间左边界。
cpp
int getRandom(vector<int>& nums, int left, int right)
{
return nums[rand() % (right - left + 1) + left];
}rand() % (right-left+1)生成0, 区间长度-1的随机数,加上left就变成left, right的随机下标
2) 快速排序算法主要流程
a. 定义递归出口(区间长度<=1时返回);
b. 利用随机选择基准函数生成一个基准元素;
c. 利用颜色分类思想将数组划分成三个区域;
d. 递归处理左边区域和右边区域(中间等于基准的区域不用处理)。
cpp
class Solution {
public:
vector<int> sortArray(vector<int>& nums) {
// 种下随机数种子,避免每次基准相同导致最坏情况
srand(time(NULL));
// 调用快速排序函数,区间[0, nums.size()-1]
qsort(nums, 0, nums.size() - 1);
return nums;
}
// 快速排序主函数
void qsort(vector<int>& nums, int l, int r)
{
// 递归出口:区间只有一个元素或为空,无需排序
if(l >= r) return;
// 1. 随机选择一个基准元素
int key = getRandom(nums, l, r);
// 2. 利用颜色分类思想将数组分三块
// [l, left] < key, [left+1, right-1] == key, [right, r] > key
int i = l, left = l - 1, right = r + 1;
while(i < right)
{
if(nums[i] < key)
// 小于key,放到左边区域
swap(nums[++left], nums[i++]);
else if(nums[i] == key)
// 等于key,直接跳过
i++;
else
// 大于key,放到右边区域
swap(nums[--right], nums[i]);
}
// 3. 递归处理左右两块,中间等于key的区域无需排序
qsort(nums, l, left);
qsort(nums, right, r);
}
// 随机获取区间[l, r]内的一个基准元素
int getRandom(vector<int>& nums, int left, int right)
{
// 生成[left, right]区间内的随机下标
int r = rand();
return nums[r % (right - left + 1) + left];
}
};- 复杂度分析
时间复杂度:平均:O(nlog n),随机基准+分三块,避免了重复元素的低效递归;最坏:O(n^2)(随机基准几乎不会触发)
空间复杂度:O(log n),递归栈深度平均为\log n,最坏为O(n)
题目3:数组中的第K个最大元素(LeetCode 215)
- 题目描述
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1: 输入: [3,2,1,5,6,4], k = 2 输出: 5
示例 2: 输入: [3,2,3,1,2,4,5,5,6], k = 4 输出: 4
提示: 1 <= k <= nums.length <= 105,-104 <= nums[i] <= 104
- 核心思想
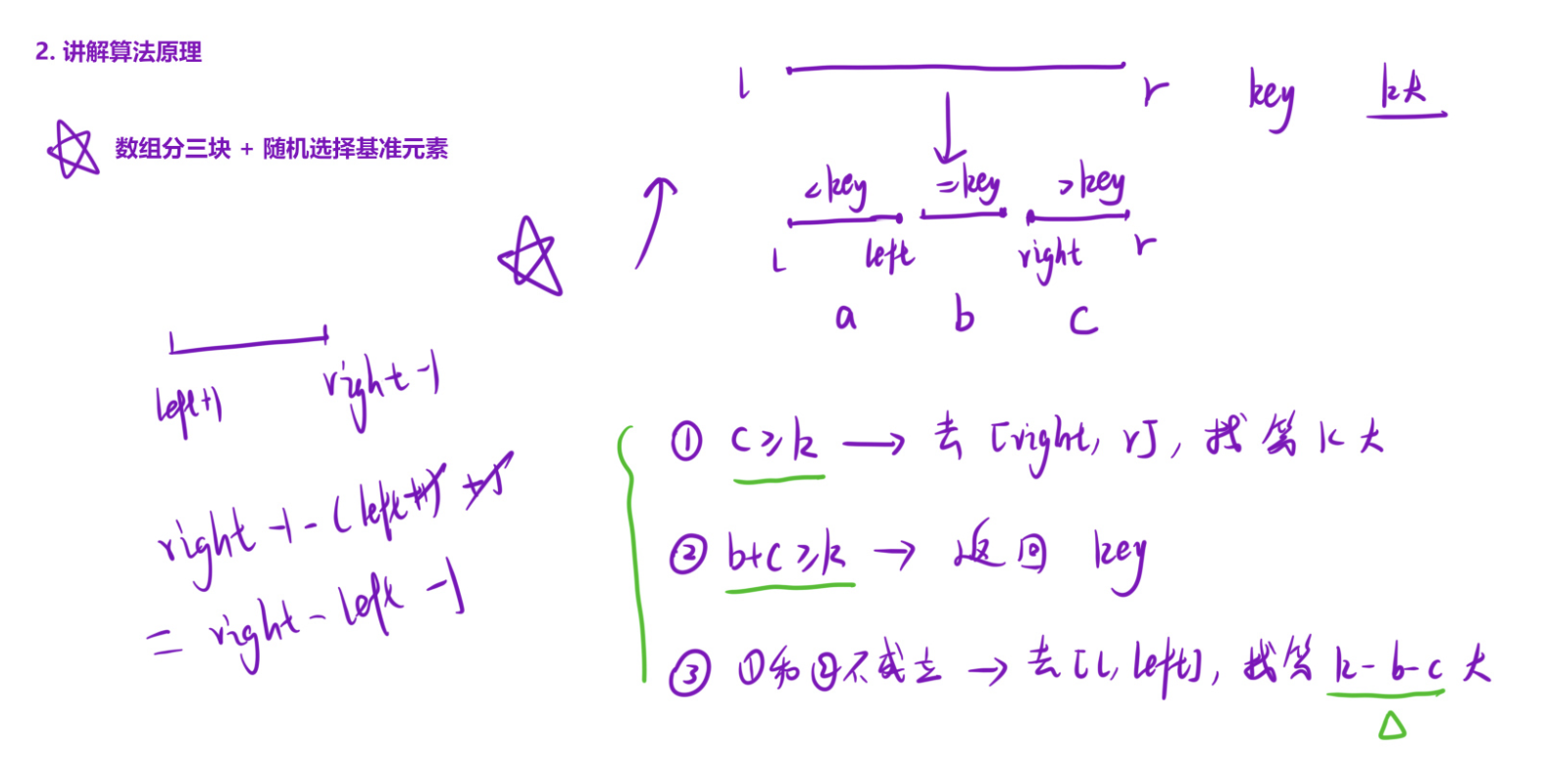
和快排分块的逻辑完全一样,但不需要把整个数组排好序,只需要根据分块后的三个区间的元素个数,判断我们要找的第K大元素在哪个区间里,然后只递归那个区间即可。
分块后三个区间的元素个数:
大于等于基准的元素:right, r,个数为 c = r - right + 1
等于基准的元素:left+1, right-1,个数为 b = right - left - 1
小于基准的元素:l, left,个数为 a = left - l + 1
分情况讨论(关键逻辑)
题目要找的是第K个最大元素,也就是从大到小数的第K个,所以我们优先看右边的大元素区间:
1) 如果 c >= k:第K大元素在right, r区间里,递归这个区间
2) 如果 c + b >= k:第K大元素就是基准key(因为中间的都是等于key的元素,第K个一定在这里面)
3) 否则:第K大元素在左边的l, left区间里,此时要找的是第k - c - b大的元素(减去右边和中间的元素个数)
cpp
class Solution {
public:
int findKthLargest(vector<int>& nums, int k) {
// 种下随机数种子
srand(time(NULL));
// 调用快速选择函数,区间[0, nums.size()-1],找第k大
return qsort(nums, 0, nums.size() - 1, k);
}
int qsort(vector<int>& nums, int l, int r, int k)
{
// 递归出口:区间只剩一个元素,就是答案
if(l == r) return nums[l];
// 1. 随机选择基准元素
int key = getRandom(nums, l, r);
// 2. 根据基准元素将数组分三块(同荷兰国旗逻辑)
int left = l - 1, right = r + 1, i = l;
while(i < right)
{
if(nums[i] < key) swap(nums[++left], nums[i++]);
else if(nums[i] == key) i++;
else swap(nums[--right], nums[i]);
}
// 3. 分情况讨论第K大元素所在的区间
int c = r - right + 1; // 右边大于等于key的元素个数
int b = right - left - 1; // 中间等于key的元素个数
if(c >= k)
// 第K大在右边区间,递归右边
return qsort(nums, right, r, k);
else if(b + c >= k)
// 第K大在中间区间,直接返回key
return key;
else
// 第K大在左边区间,更新k后递归左边
return qsort(nums, l, left, k - b - c);
}
// 随机获取区间[l, r]内的一个基准元素
int getRandom(vector<int>& nums, int left, int right)
{
return nums[rand() % (right - left + 1) + left];
}
};- 复杂度分析
时间复杂度:平均:O(n),每次只递归一侧,总操作数为 n + n/2 + n/4 + ... = O(n),最坏:O(n^2)(随机基准几乎不会触发)
空间复杂度:O(\log n),递归栈深度平均为\log n,最坏为O(n)
题目4:最小的k个数(剑指Offer 40)/库存管理(LeetCode LCR 159)
- 题目描述
仓库管理员以数组 stock 形式记录商品库存表,其中 stock[i] 表示对应商品库存余量。请返回库存余量最少的 cnt 个商品余量,返回 顺序不限。
示例 1: 输入: stock = 2,5,7,4, cnt = 1 输出:2
示例 2: 输入: stock = 0,2,3,6, cnt = 2 输出:0,2 或 2,0
提示: 0 <= cnt <= stock.length <= 10000,0 <= stock[i] <= 10000
- 解法一:直接排序法(最简单、笔试暴力通用)
思路:数组整体升序排序,取前k个即可
cpp
#include <vector>
#include <algorithm>
using namespace std;
class Solution {
public:
vector<int> getLeastNumbers(vector<int>& nums, int k) {
// 对整个数组进行升序排序
sort(nums.begin(), nums.end());
// 截取前k个最小的元素返回
return vector<int>(nums.begin(), nums.begin() + k);
}
};复杂度:时间:O(nlog n) 空间:O(log n) 排序自带栈开销 适用:笔试偷懒、数据量不大时首选
- 解法二:大根堆(优先队列,适合海量数据)
思路:维护一个大小为k的大根堆;堆内始终保存当前遍历到的最小k个数;新元素比堆顶小,就弹出堆顶,加入新元素
cpp
#include <vector>
#include <queue>
#include <algorithm>
using namespace std;
class Solution {
public:
vector<int> getLeastNumbers(vector<int>& nums, int k) {
// 大根堆:默认priority_queue就是大根堆
priority_queue<int> maxHeap;
for(int x : nums)
{
// 堆元素不足k个,直接入堆
if(maxHeap.size() < k)
{
maxHeap.push(x);
}
else
{
// 当前元素比堆顶更小,替换堆顶
if(x < maxHeap.top())
{
maxHeap.pop();
maxHeap.push(x);
}
}
}
// 把堆中k个最小元素存入结果数组
vector<int> res;
while(!maxHeap.empty())
{
res.push_back(maxHeap.top());
maxHeap.pop();
}
return res;
}
};复杂度:时间:O(nlog k),空间:O(k),优势:适合超大海量数据,不用一次性读入全部数组,面试常考
- 解法三:快速选择
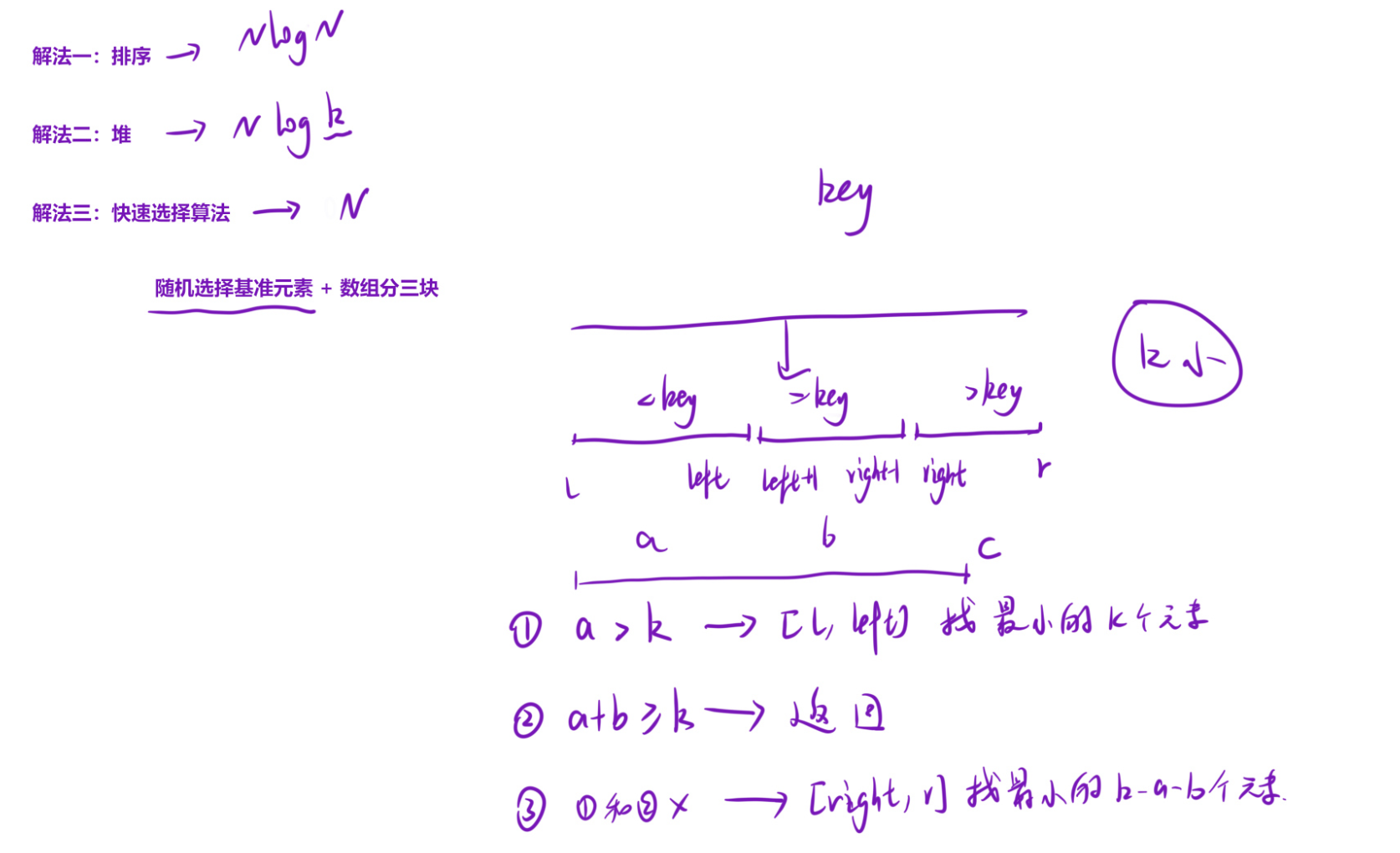
和第K大元素的逻辑完全对称,只是目标变成了找最小的k个元素,只需要调整分情况判断的逻辑即可。
同样用分三块的方法,根据三个区间的元素个数,判断最小的k个元素分布在哪些区间,只递归需要的区间即可。
分情况讨论(关键逻辑)
题目要找的是最小的k个元素,也就是从小到大的前k个,优先看左边的小元素区间:
1) 如果左边小于基准的元素个数a > k:最小的k个元素都在l, left里,递归这个区间
2) 如果 a + b >= k:最小的k个元素分布在左边和中间区间,此时数组前k个元素就是答案,直接返回即可
3) 否则:左边和中间的元素加起来不够k个,还需要从右边right, r里找k - a - b个元素,递归右边区间
cpp
class Solution {
public:
vector<int> getLeastNumbers(vector<int>& nums, int k) {
// 边界处理:k=0直接返回空数组
if(k == 0) return {};
// 种下随机数种子
srand(time(NULL));
// 调用快速选择函数,区间[0, nums.size()-1],找最小的k个
qsort(nums, 0, nums.size() - 1, k);
// 返回数组前k个元素
return {nums.begin(), nums.begin() + k};
}
void qsort(vector<int>& nums, int l, int r, int k)
{
// 递归出口:区间长度<=1,无需继续划分
if(l >= r) return;
// 1. 随机选择一个基准元素
int key = getRandom(nums, l, r);
// 2. 利用颜色分类思想将数组分三块
int left = l - 1, right = r + 1, i = l;
while(i < right)
{
if(nums[i] < key) swap(nums[++left], nums[i++]);
else if(nums[i] == key) i++;
else swap(nums[--right], nums[i]);
}
// 3. 分情况讨论最小的k个元素所在的区间
int a = left - l + 1; // 左边小于key的元素个数
int b = right - left - 1; // 中间等于key的元素个数
if(a > k)
// 最小的k个都在左边区间,递归左边
qsort(nums, l, left, k);
else if(a + b >= k)
// 左边+中间已经包含了前k小,直接返回
return;
else
// 还需要从右边区间找k - a - b个元素,递归右边
qsort(nums, right, r, k - a - b);
}
// 随机获取区间[l, r]内的一个基准元素
int getRandom(vector<int>& nums, int l, int r)
{
return nums[rand() % (r - l + 1) + l];
}
};复杂度分析
时间复杂度:平均:O(n),每次只递归一侧,总操作数为 O(n),最坏:O(n^2)(随机基准几乎不会触发)
空间复杂度:O(\log n),递归栈深度平均为\log n,最坏为O(n)
4道题易错点整理
1) 指针初始化:left = l-1、right = r+1,不要初始化为 l 和 r,否则边界处理错误
2) 扫描指针移动:处理大于基准的元素时,i 不要移动,因为交换来的元素还未被处理
3) 递归出口:快排的出口是 l >= r,快速选择找单个元素的出口是 l == r
4) 随机基准:必须使用 rand() % (r-l+1) + l,否则下标越界或无法覆盖整个区间
5) 区间判断:第K大优先看右边区间,前K小优先看左边区间,不要搞反
题目5:排序数组(LeetCode 912)归并排序
- 题目描述
给你一个整数数组 nums,请你将该数组升序排列。
• 示例 1
输入:nums = 5,2,3,1 输出:1,2,3,5
• 示例 2
输入:nums = 5,1,1,2,0,0 输出:0,0,1,1,2,5
- 归并排序核心思想(分治法)
归并排序是分治法(Divide and Conquer)思想的经典应用,核心分为两步:
1) 分(Divide):将数组不断二分,递归分解,直到每个子数组的长度为 1(长度为 1 的数组天然有序)。
2) 治(Conquer):将两个已排序的子数组合并为一个更长的有序数组,不断向上合并,最终得到完整的有序数组。
- C++ 完整代码 + 逐行注释
cpp
class Solution
{
// 全局(类内)临时数组,用于合并阶段暂存数据
// 避免每次递归都创建新数组,减少空间开销
vector<int> tmp;
public:
// 主函数:排序数组入口
vector<int> sortArray(vector<int>& nums)
{
// 1. 初始化临时数组 tmp,大小和原数组 nums 一致
// 后续合并操作都在 tmp 上暂存,再写回 nums
tmp.resize(nums.size());
// 2. 调用归并排序的递归函数,对 nums 的 [0, nums.size()-1] 区间排序
mergeSort(nums, 0, nums.size() - 1);
// 3. 返回排序后的数组
return nums;
}
// 递归归并排序函数:对 nums 的 [left, right] 区间进行排序
void mergeSort(vector<int>& nums, int left, int right)
{
// 递归终止条件:当区间左边界 >= 右边界,说明区间长度 <= 1,已经有序,直接返回
if (left >= right) return;
// ---------------------- 第一步:分(Divide) ----------------------
// 计算区间中间点 mid,将 [left, right] 拆分为 [left, mid] 和 [mid+1, right] 两个子区间
// 用 (left + right) >> 1 等价于 (left + right) / 2,位运算效率更高
int mid = (left + right) >> 1;
// 两个子区间分别递归排序
// 对左半区间 [left, mid] 递归排序
mergeSort(nums, left, mid);
// 对右半区间 [mid+1, right] 递归排序
mergeSort(nums, mid + 1, right);
// ---------------------- 第二步:治(Conquer)合并 ----------------------
// 初始化两个指针,分别指向左半区间和右半区间的起始位置
// cur1:左半区间的当前指针,初始为 left
// cur2:右半区间的当前指针,初始为 mid + 1
// i:临时数组 tmp 的当前写入位置,初始为 0(相对当前子区间的偏移)
int cur1 = left, cur2 = mid + 1, i = 0;
// 1. 同时遍历左右两个有序子区间,取较小值写入 tmp
while(cur1 <= mid && cur2 <= right)
{
// 三目运算符:nums[cur1] <= nums[cur2] 时,取 nums[cur1],cur1 后移;否则取 nums[cur2],cur2 后移
tmp[i++] = nums[cur1] <= nums[cur2] ? nums[cur1++] : nums[cur2++];
}
// 2. 处理未遍历完的剩余元素(左右两个子区间必有一个还有剩余元素)
// 若左半区间还有剩余,直接依次写入 tmp
while(cur1 <= mid) tmp[i++] = nums[cur1++];
// 若右半区间还有剩余,直接依次写入 tmp
while(cur2 <= right) tmp[i++] = nums[cur2++];
// 3. 将 tmp 中合并好的有序数据,还原回原数组 nums 的 [left, right] 区间
// 注意:tmp 是相对当前子区间的偏移,所以 nums 的起始位置是 left,对应 tmp 的起始位置是 0
for(int i = left; i <= right; i++)
{
nums[i] = tmp[i - left];
}
}
};- 核心知识点拆解
1) 递归过程拆解(以 nums = 5,2,3,1 为例)
① 分的过程(递归分解)
cpp
初始数组:[5,2,3,1] → mid=(0+3)/2=1,拆分为 [5,2] 和 [3,1]
├─ 处理 [5,2]:mid=(0+1)/2=0,拆分为 [5] 和 [2]
│ ├─ [5] 长度为 1,终止递归
│ └─ [2] 长度为 1,终止递归
│ → 合并 [5] 和 [2] → [2,5]
└─ 处理 [3,1]:mid=(2+3)/2=2,拆分为 [3] 和 [1]
├─ [3] 长度为 1,终止递归
└─ [1] 长度为 1,终止递归
→ 合并 [3] 和 [1] → [1,3]
→ 合并 [2,5] 和 [1,3] → [1,2,3,5]② 合并过程(关键步骤)
合并两个有序数组 2,5 和 1,3 的过程:
-
cur1=0(值2),cur2=2(值1):1更小 → tmp0=1,cur2=3
-
cur1=0(值2),cur2=3(值3):2更小 → tmp1=2,cur1=1
-
cur1=1(值5),cur2=3(值3):3更小 → tmp2=3,cur2=4(超出右边界)
-
左半区间剩余 cur1=1(值5) → tmp3=5
-
把 tmp 还原回原数组:1,2,3,5
2) 关键细节说明
① 临时数组 tmp 的作用
合并阶段需要同时读取两个有序子数组的元素,不能直接在原数组上覆盖,所以需要一个临时数组暂存合并结果,再写回原数组。
把 tmp 定义为类内成员变量,而不是每次递归都创建,避免了大量的内存分配和释放,提升效率。
② mid 的计算方式
mid = (left + right) >> 1 等价于 mid = left + (right - left) / 2,可以避免 left + right 过大导致的整数溢出问题(虽然本题 int 范围内一般不会溢出,但这是规范写法)。
③ 合并阶段的指针边界
cur1 <= mid:左半区间的范围是 left, mid,所以指针 cur1 不能超过 mid。
cur2 <= right:右半区间的范围是 mid+1, right,所以指针 cur2 不能超过 right。
④ 还原阶段的偏移量 i - left
tmp 是按当前子区间的长度写入的,比如子区间 2,3,在 tmp 里的位置是 0,1,对应原数组的位置是 2,3,所以需要用 i - left 来定位 tmp 中的元素。
3) 复杂度分析
|-------|---------------------|------------------------------------------------------------|
| 指标 | 归并排序 | 说明 |
| 时间复杂度 | 平均/最好/最坏:O(n log n) | 每次二分拆分是 log n 层,每层合并的总操作数是 n,所以总时间是 n log n |
| 空间复杂度 | O(n) | 需要一个和原数组等长的临时数组 tmp,递归栈深度是 O(log n),整体空间复杂度由 tmp 主导,为 O(n) |
| 稳定性 | 稳定 | 合并时,当两个元素相等,优先取左半区间的元素,不会交换相等元素的相对位置,所以是稳定排序 |
4) 常见易错点
-
递归终止条件错误:把 left >= right 写成 left == right,虽然也能跑,但处理 left > right(空区间)时会出错,left >= right 更通用。
-
临时数组越界:tmp 的大小没有初始化为 nums.size(),或者合并时指针越界,导致数组下标错误。
-
还原阶段下标错误:忘记 tmp 是相对偏移,直接用 numsi = tmpi,导致数据写错位。
-
合并顺序错误:没有先合并左右子区间,就直接操作,导致合并的不是有序数组。
-
和其他排序算法的对比
|------------|------------------------|----------|------|--------------|
| 算法 | 时间复杂度 | 空间复杂度 | 稳定性 | 适用场景 |
| 冒泡/选择/插入排序 | O(n²) | O(1) | 部分稳定 | 小规模数据 |
| 快速排序 | 平均 O(n log n),最坏 O(n²) | O(log n) | 不稳定 | 大规模数据,内存有限 |
| 归并排序 | O(n log n) | O(n) | 稳定 | 大规模数据,要求稳定排序 |
题目6:交易逆序对的总数(LeetCode LCR 170)
- 题目描述
在股票交易中,如果前一天的股价高于后一天的股价,则可以认为存在一个「交易逆序对」。请设计一个程序,输入一段时间内的股票交易记录 record,返回其中存在的「交易逆序对」总数。
示例 1:输入: record = 9, 7, 5, 4, 6 **输出:**8
**解释:**交易中的逆序对为 (9, 7), (9, 5), (9, 4), (9, 6), (7, 5), (7, 4), (7, 6), (5, 4)。
提示: 0 <= record.length <= 50000
- 核心解法:归并排序(分治思想)
1) 为什么用归并排序?
逆序对可以按来源分为三类:
-
两个元素都来自数组的左半部分
-
两个元素都来自数组的右半部分
-
一个来自左半部分,一个来自右半部分,且左边元素 > 右边元素
根据分类加法原理,总逆序对数量 = 左半部分逆序对 + 右半部分逆序对 + 跨左右的逆序对。
而归并排序的流程(先分后合)完美匹配这个思路:
递归排序左半数组,统计左半部分的逆序对
递归排序右半数组,统计右半部分的逆序对
合并两个有序数组时,统计跨左右的逆序对
2) 核心关键:合并有序数组时统计逆序对
合并两个有序数组(升序)时,统计跨左右逆序对有两种等价方法,核心都是利用数组的有序性,避免暴力枚举(O(n²)),实现O(n)时间复杂度统计。
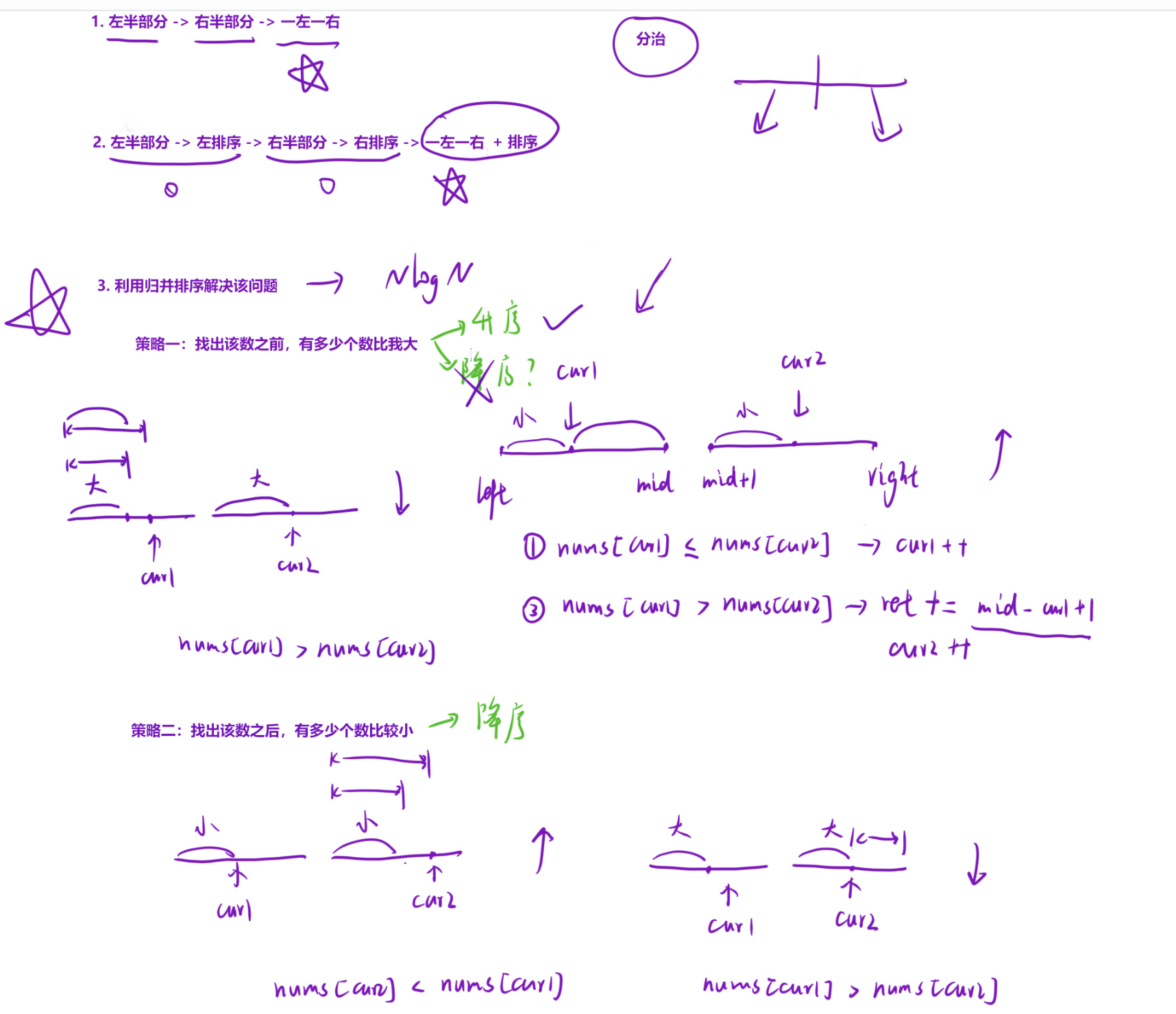
方法一:统计「右边元素」贡献的逆序对
核心逻辑
合并时,用两个指针cur1遍历左数组、cur2遍历右数组:
当numscur1 > numscur2时,说明左数组中从cur1到末尾的所有元素,都比numscur2大,因此贡献的逆序对数量为 mid - cur1 + 1(mid是左数组的末尾索引)。
当numscur1 <= numscur2时,无法形成逆序对,直接将numscur1加入辅助数组。
示例演示(left=5,7,9,right=4,5,8)
|----------------------|------|------|------|-------------------------|---------------|
| 循环 | cur1 | cur2 | 比较结果 | 逆序对更新 | 操作 |
| 1 | 0 | 0 | 5>4 | ret += 3(mid=2,2-0+1=3) | cur2++,辅助数组加4 |
| 2 | 0 | 1 | 5==5 | 无更新 | cur1++,辅助数组加5 |
| 3 | 1 | 1 | 7>5 | ret += 2(2-1+1=2) | cur2++,辅助数组加5 |
| 4 | 1 | 2 | 7<8 | 无更新 | cur1++,辅助数组加7 |
| 5 | 2 | 2 | 9>8 | ret +=1(2-2+1=1) | cur2++,辅助数组加8 |
| 最终ret=3+2+1=6,与预期一致。 | | | | |
方法二:统计「左边元素」贡献的逆序对
核心逻辑
合并时,同样用cur1遍历左数组、cur2遍历右数组:
当numscur1 <= numscur2时,说明右数组中从开头到cur2前的所有元素,都比numscur1小,因此贡献的逆序对数量为 cur2 - (mid+1)(mid+1是右数组的起始索引)。
当numscur1 > numscur2时,无法直接统计,先将numscur2加入辅助数组,直到后续左数组元素出现<=的情况。
循环结束后,若左数组还有剩余元素,剩余的每个左元素都比所有已遍历的右元素大,因此需额外统计:ret += (mid - cur1 + 1) * (cur2 - (mid+1))。
示例演示(left=5,7,9,right=4,5,8)
|-------------------------------------------------------------------------|------|------|------|---------------------------|---------------|
| 循环 | cur1 | cur2 | 比较结果 | 逆序对更新 | 操作 |
| 1 | 0 | 0 | 5>4 | 无更新 | cur2++,辅助数组加4 |
| 2 | 0 | 1 | 5==5 | ret +=1(cur2 - 1 = 1-1=1) | cur1++,辅助数组加5 |
| 3 | 1 | 1 | 7>5 | 无更新 | cur2++,辅助数组加5 |
| 4 | 1 | 2 | 7<8 | ret +=2(cur2 -1 =2-1=2) | cur1++,辅助数组加7 |
| 5 | 2 | 2 | 9>8 | 无更新 | cur2++,辅助数组加8 |
| 循环结束后,左数组剩余1个元素(cur1=2),额外统计:ret +=1 * (3-1)=2,最终ret=1+2+3=6,与方法一结果一致。 | | | | |
- 升序版本C++代码(方法一)
cpp
class Solution
{
int tmp[50010];
public:
int reversePairs(vector<int>& nums)
{
return mergeSort(nums, 0, nums.size() - 1);
}
int mergeSort(vector<int>& nums, int left, int right)
{
if(left >= right) return 0;
int ret = 0;
// 1. 找中间点,将数组分成两部分
int mid = (left + right) >> 1;
// [left, mid] [mid + 1, right]
// 2. 左边的逆序对 + 排序 + 右边的逆序对 + 排序
ret += mergeSort(nums, left, mid);
ret += mergeSort(nums, mid + 1, right);
// 3. 统计跨左右的逆序对 + 合并有序数组
int cur1 = left, cur2 = mid + 1, i = 0;
while(cur1 <= mid && cur2 <= right) // 升序合并
{
if(nums[cur1] <= nums[cur2])
{
tmp[i++] = nums[cur1++];
}
else
{
// 左数组cur1到末尾的所有元素,都比nums[cur2]大,贡献逆序对
ret += mid - cur1 + 1;
tmp[i++] = nums[cur2++];
}
}
// 4. 处理剩余元素(合并有序数组)
while(cur1 <= mid) tmp[i++] = nums[cur1++];
while(cur2 <= right) tmp[i++] = nums[cur2++];
// 将辅助数组的内容拷贝回原数组
for(int j = left; j <= right; j++)
nums[j] = tmp[j - left];
return ret;
}
};- 降序版本C++代码(拓展)
除了升序合并,也可以用降序合并统计逆序对,逻辑与升序版本对称:
cpp
class Solution
{
int tmp[50010];
public:
int reversePairs(vector<int>& nums)
{
return mergeSort(nums, 0, nums.size() - 1);
}
int mergeSort(vector<int>& nums, int left, int right)
{
if(left >= right) return 0;
int ret = 0;
// 1. 找中间点,将数组分成两部分
int mid = (left + right) >> 1;
// [left, mid] [mid + 1, right]
// 2. 左边的逆序对 + 排序 + 右边的逆序对 + 排序
ret += mergeSort(nums, left, mid);
ret += mergeSort(nums, mid + 1, right);
// 3. 统计跨左右的逆序对 + 降序合并有序数组
int cur1 = left, cur2 = mid + 1, i = 0;
while(cur1 <= mid && cur2 <= right) // 降序版本
{
if(nums[cur1] <= nums[cur2])
{
tmp[i++] = nums[cur2++];
}
else
{
// 右数组cur2到末尾的所有元素,都比nums[cur1]小,贡献逆序对
ret += right - cur2 + 1;
tmp[i++] = nums[cur1++];
}
}
// 4. 处理剩余元素(合并有序数组)
while(cur1 <= mid) tmp[i++] = nums[cur1++];
while(cur2 <= right) tmp[i++] = nums[cur2++];
// 将辅助数组的内容拷贝回原数组
for(int j = left; j <= right; j++)
nums[j] = tmp[j - left];
return ret;
}
};- 关键知识点总结
- 分治思想的应用
分:将数组递归拆分为左右两部分,分别统计内部逆序对并排序
合:合并两个有序数组时,利用有序性统计跨左右的逆序对
时间复杂度:O(n log n)(归并排序的时间复杂度,合并阶段统计逆序对仅增加O(n))
空间复杂度:O(n)(辅助数组tmp的空间开销)
- 两种统计方法的核心区别
|-----|------------|--------------------------------|-----------------|
| 方法 | 统计对象 | 统计时机 | 额外处理 |
| 方法一 | 右边元素贡献的逆序对 | numscur1 > numscur2时 | 无额外处理 |
| 方法二 | 左边元素贡献的逆序对 | numscur1 <= numscur2时 | 循环结束后需处理左数组剩余元素 |
- 边界条件注意事项
递归终止条件:left >= right,此时子数组只有1个元素,无逆序对
辅助数组拷贝:必须将tmp中合并后的有序数组拷贝回原数组,否则后续递归的合并阶段会出错
数组索引:mid = (left + right) >> 1,右数组起始索引为mid + 1,避免与左数组重叠
- 优化细节
用>>1代替/2,提高整数除法的效率
辅助数组tmp预定义为全局/类成员变量,避免每次递归都重新申请空间
降序版本与升序版本逻辑对称,可根据个人习惯选择实现方式
题目7:计算右侧小于当前元素的个数(LeetCode 315)
- 题目描述
给你一个整数数组 nums ,按要求返回一个新数组 counts 。数组 counts 有该性质: countsi 的值是 numsi 右侧小于 numsi 的元素的数量。
• 示例 1:
输入:nums = 5,2,6,1 输出:2,1,1,0
解释:5 的右侧有 2 个更小的元素 (2 和 1), 2 的右侧仅有 1 个更小的元素 (1), 6 的右侧有 1 个更小的元素 (1), 1 的右侧有 0 个更小的元素
• 示例 2:输入: nums = -1 输出:0
• 示例 3:输入: nums = -1,-1 输出:0,0
提示: 1 <= nums.length <= 105,-104 <= nums[i] <= 104
- 解法(归并排序)
算法思路
这道题的解法与求数组中的逆序对的解法类似,但本题不是求总个数,而是要返回一个数组,记录每一个元素的右边有多少个元素比自己小。
由于归并排序过程中元素的下标会跟着变化,因此需要一个辅助数组,将数组元素和对应的下标绑定在一起归并,在归并元素时,顺便将下标也转移到对应的位置上。利用归并排序中统计逆序对的方法,快速统计某一个元素后面有多少个比它小的元素。
算法流程
1) 创建两个全局的数组:
vector<int> index:记录下标,与原数组中对应位置的元素绑定
vector<int> ret:记录结果,每个位置统计出来的逆序对个数
2) countSmaller() 主函数:
a. 计算 nums 数组的大小为 n;
b. 初始化两个全局数组:
-
为两个数组开辟大小为 n 的空间
-
index 初始化为数组下标(indexi = i)
-
ret 初始化为 0
c. 调用 mergeSort() 函数,并且返回 ret 结果数组。
3) void mergeSort(vector<int>& nums, int left, int right) 函数:
函数设计:通过修改全局的数组 ret,统计出每一个位置对应的逆序对的数量,并且排序;无需返回值,因为直接对全局变量修改,当函数结束的时候,全局变量已经被修改成最后的结果。
4) mergeSort() 函数流程:
a. 定义递归出口:left >= right 时,直接返回;
b. 划分区间:根据中点 mid,将区间划分为 left, mid 和 mid + 1, right;
c. 统计左右两个区间逆序对的数量:
i. 统计左边区间 left, mid 中每个元素对应的逆序对的数量到 ret 数组中,并排序;
ii. 统计右边区间 mid + 1, right 中每个元素对应的逆序对的数量到 ret 数组中,并排序。
d. 合并左右两个有序区间,并且统计出逆序对的数量:
i. 创建两个大小为 right - left + 1 的辅助数组:- numsTmp:排序用的辅助数组;- indexTmp:处理下标用的辅助数组。
ii. 初始化遍历数组的指针:cur1 = left(遍历左半部分数组)、cur2 = mid + 1(遍历右半部分数组)、dest = 0(遍历辅助数组);
iii. 循环合并区间:
-
当 numscur1 <= numscur2 时:说明此时 mid + 1, cur2) 之间的元素都是小于 nums\[cur1 的,需要累加到 ret 数组的 indexcur1 位置上(因为 index 存储的是元素对应位置在原数组中的下标)。归并排序时,不仅要将数据放在对应的位置上,也要将数据对应的坐标也放在对应的位置上,使数据与原始的下标绑定在一起移动。
-
当 numscur1 > numscur2 时:无需统计,直接归并,注意 index 也要跟着归并。
iv. 处理归并排序中剩余的元素:
-
当左边有剩余的时候,还需要统计逆序对的数量;
-
当右边还有剩余的时候,无需统计,直接归并。
v. 将辅助数组的内容替换到原数组中去。
- C++ 算法代码
cpp
class Solution
{
// 全局成员变量,贯穿整个递归过程
vector<int> ret; // 最终答案数组:ret[原下标] = 右侧比它小的元素个数
vector<int> index; // 下标映射数组:index[i] 保存当前nums[i]在**原数组**的真实下标
int tmpNums[500010]; // 归并排序临时数组,暂存排序后的数值
int tmpIndex[500010]; // 下标临时数组,和tmpNums同步移动,保证数值和原下标绑定
public:
// 主入口函数
vector<int> countSmaller(vector<int>& nums)
{
int n = nums.size();
ret.resize(n); // 答案数组开辟空间,默认初始值全0
index.resize(n); // 下标映射数组开辟空间
// 初始化下标映射:一开始每个元素的当前位置就是原始下标
for(int i = 0; i < n; i++)
index[i] = i;
// 对整个数组 [0, n-1] 进行归并分治统计
mergeSort(nums, 0, n - 1);
return ret; // 返回统计好的结果数组
}
/**
* 归并排序分治函数
* @param nums 待排序数组
* @param left 当前处理区间左边界
* @param right 当前处理区间右边界
*/
void mergeSort(vector<int>& nums, int left, int right)
{
// 递归出口:区间只有一个元素或无元素,直接返回
if(left >= right) return;
// 1. 根据中间元素,划分区间
int mid = (left + right) >> 1; // 等价于 mid = (left + right) / 2,位运算更快
// 划分左右子区间:[left, mid] 和 [mid + 1, right]
// 2. 先递归处理左右两子区间(分治思想)
mergeSort(nums, left, mid);
mergeSort(nums, mid + 1, right);
// 3. 合并两个有序区间,同时统计右侧更小元素数量
int cur1 = left, cur2 = mid + 1, i = 0; // cur1左区间指针,cur2右区间指针,i临时数组指针
while(cur1 <= mid && cur2 <= right) // 降序归并
{
// 左区间元素 <= 右区间元素:右区间元素更大,先放入临时数组
if(nums[cur1] <= nums[cur2])
{
tmpNums[i] = nums[cur2]; // 存入大的数值
tmpIndex[i++] = index[cur2++]; // 同步存入对应原下标,指针后移
}
else
{
// 【核心关键逻辑】
// 左区间元素 > 右区间元素
// 说明当前cur1指向的数,右侧所有 cur2~right 的数都比它小
// 数量就是:right - cur2 + 1
// index[cur1]拿到该元素的原始下标,累加到答案数组对应位置
ret[index[cur1]] += right - cur2 + 1;
tmpNums[i] = nums[cur1]; // 存入左区间更大的数值
tmpIndex[i++] = index[cur1++]; // 同步下标,指针后移
}
}
// 4. 处理剩下的排序过程
// 左区间还有剩余元素,直接移入临时数组(都是较大值)
while(cur1 <= mid)
{
tmpNums[i] = nums[cur1];
tmpIndex[i++] = index[cur1++];
}
// 右区间还有剩余元素,直接移入临时数组
while(cur2 <= right)
{
tmpNums[i] = nums[cur2];
tmpIndex[i++] = index[cur2++];
}
// 把临时有序数组 覆盖回原nums和index数组
for(int j = left; j <= right; j++)
{
nums[j] = tmpNums[j - left]; // j-left 映射临时数组的下标
index[j] = tmpIndex[j - left]; // 下标数组同步覆盖,保持绑定关系
}
}
};核心公式:ret原下标 += 右侧剩余元素个数
为什么要绑index数组?因为排序会打乱元素位置
indexcur1 → 找回这个数在最开始数组的真实位置
降序归并优势:只要左边数 > 右边数,右边后面所有数都更小,直接批量统计
时间复杂度稳定 O(nlogn) 空间复杂度O(n)
题目8:翻转对(LeetCode 493)
- 题目描述
给定一个数组 nums ,如果 i < j 且 numsi > 2 * numsj 我们就将 (i, j) 称作一个重要翻转对。你需要返回给定数组中的重要翻转对的数量。
示例 1: 输入 : 1,3,2,3,1 输出: 2
示例 2: 输入 : 2,4,3,5,1 输出: 3
注意: 给定数组的长度不会超过50000。输入数组中的所有数字都在32位整数的表示范围内。
- 解法(归并排序)
题目解析
翻转对和逆序对的定义大同小异,逆序对是前面的数要大于后面的数。而翻转对是前面的一个数要大于后面某个数的两倍。因此,依旧可以用归并排序的思想来解决这个问题。
算法思路
大思路与求逆序对的思路一样,就是利用归并排序的思想,将求整个数组的翻转对的数量,转换成三部分:左半区间翻转对的数量,右半区间翻转对的数量,一左一右选择时翻转对的数量。重点就是在合并区间过程中,如何计算出翻转对的数量。
与上一个问题不同的是,上一道题可以一边合并一遍计算,但是这道题要求的是左边元素大于右边元素的两倍,如果我们直接合并的话,是无法快速计算出翻转对的数量的。
例如 left = 4, 5, 6 right = 3, 4, 5 时,如果是归并排序的话,我们需要计算 left 数组中有多少个能与 3 组成翻转对。但是我们要遍历到最后一个元素 6 才能确定,时间复杂度较高。
因此我们需要在归并排序之前完成翻转对的统计。下面依旧以一个示例模仿两个有序序列如何快速求出翻转对的过程:
假定已经有两个已经有序的序列 left = 4, 5, 6 right = 1, 2, 3。用两个指针 cur1 cur2 遍历两个数组。
对于任意给定的 leftcur1 而言,我们不断地向右移动 cur2,直到 leftcur1 <= 2 * rightcur2。此时对于 right 数组而言,cur2 之前的元素全部都可以与 leftcur1 构成翻转对。
随后,我们再将 cur1 向右移动一个单位,此时 cur2 指针并不需要回退(因为 left 数组是升序的),依旧往右移动直到 leftcur1 <= 2 * rightcur2。不断重复这样的过程,就能够求出所有左右端点分别位于两个子数组的翻转对数目。
由于两个指针最后都是不回退的扫描到数组的结尾,因此两个有序序列求出翻转对的时间复杂度是 O(N)。
综上所述,我们可以利用归并排序的过程,将求一个数组的翻转对转换成求:左数组的翻转对数量 + 右数组中翻转对的数量 + 左右数组合并时翻转对的数量。
- 降序版本 C++ 算法代码
cpp
class Solution
{
int tmp[50010]; // 归并排序临时辅助数组,存放合并后的有序数据
public:
// 主函数:入口,返回整个数组的翻转对总数量
int reversePairs(vector<int>& nums)
{
// 对整个数组 [0, n-1] 进行分治归并统计
return mergeSort(nums, 0, nums.size() - 1);
}
/**
* 分治归并函数
* @return 返回当前区间 [left, right] 内的翻转对总数
* 翻转对定义:i < j 且 nums[i] > 2 * nums[j]
*/
int mergeSort(vector<int>& nums, int left, int right)
{
// 递归终止条件:区间只有一个元素,不存在翻转对,返回0
if(left >= right) return 0;
int ret = 0; // 记录当前区间内翻转对的总数
// 1. 根据中间点划分左右两个子区间
int mid = (left + right) >> 1; // 等价于 (left+right)/2,位运算更快
// 左区间 [left, mid] 右区间 [mid + 1, right]
// 2. 分治:先递归求出左区间、右区间内部各自的翻转对数量
ret += mergeSort(nums, left, mid);
ret += mergeSort(nums, mid + 1, right);
// 3. 核心关键:统计【左区间元素、右区间元素】交叉产生的翻转对
int cur1 = left, cur2 = mid + 1, i = left;
// 遍历左区间每一个元素
while(cur1 <= mid)
{
// 双指针不回退思想
// 找到第一个满足 nums[cur1] > 2 * nums[cur2] 的位置
// nums[cur2] >= nums[cur1]/2.0 说明不构成翻转对,指针后移
while(cur2 <= right && nums[cur2] >= nums[cur1] / 2.0)
cur2++;
// cur2越界,后面都无法构成翻转对,直接退出循环
if(cur2 > right)
break;
// 从cur2到right的所有右侧元素,都能和当前nums[cur1]构成翻转对
// 累加当前能组成的翻转对个数
ret += right - cur2 + 1;
cur1++; // 考察下一个左区间元素
}
// 4. 降序合并左右两个已经各自有序的子区间
cur1 = left, cur2 = mid + 1;
// 降序归并:大的数先放进临时数组
while(cur1 <= mid && cur2 <= right)
tmp[i++] = nums[cur1] <= nums[cur2] ? nums[cur2++] : nums[cur1++];
// 处理左区间剩余元素
while(cur1 <= mid) tmp[i++] = nums[cur1++];
// 处理右区间剩余元素
while(cur2 <= right) tmp[i++] = nums[cur2++];
// 把临时有序数组覆盖回原数组,保证上层递归是有序区间
for(int j = left; j <= right; j++)
nums[j] = tmp[j];
// 返回当前区间总翻转对数量
return ret;
}
};翻转对条件 i<j & numsi > 2 * numsj
双指针不回退:左右子区间都是有序的,cur2 不需要每次重置回 mid+1,保证合并统计是 O(n)
统计顺序:先统计翻转对,再做归并排序,不能边合并边统计,两倍关系无法直接判断
时间复杂度:O(nlog n),空间复杂度:O(n)
- 升序版本 C++ 算法代码
cpp
class Solution
{
int tmp[50010]; // 归并辅助临时数组,用来存放合并后的有序数组
public:
// 主函数入口:返回整个数组的翻转对总个数
int reversePairs(vector<int>& nums)
{
// 对整个数组 [0, nums.size()-1] 分治求解
return mergeSort(nums, 0, nums.size() - 1);
}
/**
* 分治归并函数
* @param nums 原数组
* @param left 区间左边界
* @param right 区间右边界
* @return 当前区间内满足 nums[i] > 2 * nums[j] 的翻转对总数
*/
int mergeSort(vector<int>& nums, int left, int right)
{
// 递归终止条件:区间只有一个元素/空区间,无法构成翻转对,返回0
if(left >= right) return 0;
int ret = 0; // 记录当前区间的翻转对总数
// 1. 根据中间点划分左右子区间
int mid = (left + right) >> 1; // 等价 mid = (left + right) / 2,位运算效率更高
// 划分:左区间 [left, mid] 右区间 [mid + 1, right]
// 2. 分治思想:先递归统计左、右子区间内部的翻转对
ret += mergeSort(nums, left, mid);
ret += mergeSort(nums, mid + 1, right);
// 3. 核心逻辑:统计左区间、右区间交叉产生的翻转对(升序版本双指针)
int cur1 = left, cur2 = mid + 1, i = left;
// 遍历右侧每一个元素(升序写法:以右指针为主遍历)
while(cur2 <= right)
{
// 双指针不回退:
// 找到第一个满足 nums[cur1] > 2 * nums[cur2] 的左边界
// nums[cur2] >= nums[cur1]/2.0 不构成翻转对,左指针后移
while(cur1 <= mid && nums[cur2] >= nums[cur1] / 2.0)
cur1++;
// 左指针越界,左边没有元素可以构成翻转对,直接退出
if(cur1 > mid)
break;
// cur1 ~ mid 之间所有左元素,都满足 > 2*nums[cur2]
// 累加当前右侧元素能匹配的翻转对数量
ret += mid - cur1 + 1;
cur2++; // 考察下一个右侧元素
}
// 4. 升序合并左右两个各自有序的子区间
cur1 = left, cur2 = mid + 1;
// 升序归并:小的数优先放入临时数组
while(cur1 <= mid && cur2 <= right)
tmp[i++] = nums[cur1] <= nums[cur2] ? nums[cur1++] : nums[cur2++];
// 处理左区间剩余元素
while(cur1 <= mid) tmp[i++] = nums[cur1++];
// 处理右区间剩余元素
while(cur2 <= right) tmp[i++] = nums[cur2++];
// 将临时有序数组覆盖回原数组,保证上层递归区间有序
for(int j = left; j <= right; j++)
nums[j] = tmp[j];
// 返回当前区间统计到的所有翻转对数量
return ret;
}
};翻转对定义 i<j & numsi > 2 * numsj
双指针不回退原理:左右子区间都是升序有序,cur1 不会重置,每层合并只遍历一遍,保证合并阶段 O(n)
统计时机:先统计翻转对,再归并排序;不能边合并边统计,两倍关系无法直接判断
时间复杂度:O(nlog n),空间复杂度:O(n)
7、8题知识点总结
|---------------|---------------|-------------------------------------------------------|------------|
| 题目 | 核心思想 | 关键细节 | 时间复杂度 |
| 计算右侧小于当前元素的个数 | 归并排序 + 下标绑定 | 排序时同步移动原数组下标,在归并过程中统计 right - cur2 + 1 | O(nlog n) |
| 翻转对 | 归并排序 + 双指针不回退 | 合并前先统计满足 numsi > 2 * numsj 的对数,双指针不回退保证线性扫描 | O(nlog n) |
补充说明:两道题都利用了归并排序的分治思想,将大问题拆分成小问题,再合并解决,避免了暴力解法的 O(n^2) 复杂度。
核心差异在于统计时机:
计算右侧小于当前元素的个数:在合并过程中统计逆序对;
翻转对:在合并之前用双指针统计满足条件的对数,避免合并时无法快速判断两倍关系。