一、什么是"一段式端到端"?
在自动驾驶领域,**"一段式端到端"(Single-Stage End-to-End)** 是一种摒弃传统模块化流水线的技术范式。
-
基本概念 :它使用一个统一的深度学习模型(通常是一个巨大的神经网络),直接将传感器的原始输入(如摄像头图像、激光雷达点云)映射到车辆的控制指令(如转向角、油门、刹车)或未来的行驶轨迹。
-
核心特点:
-
去模块化:不再人为地硬性划分"感知"、"预测"、"规划"、"控制"等独立模块,而是让模型自己学习从输入到输出的整个映射过程。
-
全局优化:模型通过端到端的训练(如模仿学习或强化学习)进行全局优化,旨在找到从感知到控制的最优策略。
-
数据驱动:依赖海量驾驶数据,让模型学会像人类老司机一样基于直觉做出决策,而不仅仅是遵循规则。
-
二、三条技术路线
如下三条路线代表了在"一段式端到端"框架下,不同的技术侧重点和设计哲学:
2.1. 路线一:Planning-Oriented 统一范式
-
代表 :UniAD
-
首次系统证明"端到端"可形成完整设计范式,突破了仅在输出端接规划头的局限。
-
将感知、预测、规划统一进一个框架;中间任务不再追求单点最优,所有优化目标直指"最终规划效果最优"。
-
-
基本概念:
这条路线的核心理念是**"以规划为目标"** 。虽然它是一个端到端的模型,但它并没有完全抛弃自动驾驶的传统任务(感知、预测),而是将它们整合进一个统一的框架中,并且所有任务都围绕着"如何让规划做得更好"这一终极目标来组织(中间任务不再追求单点最优,所有优化目标直指"最终规划效果最优")。
-
基本理论:
-
统一框架:模型内部同时包含感知(如目标检测、跟踪、建图)、预测(如轨迹预测)和规划模块。
-
协同工作:通过Transformer等结构,让感知和预测模块的输出直接为规划模块提供信息。例如,规划模块可以通过注意力机制直接"询问"感知模块关于某个障碍物的信息,而不是等待感知模块输出最终结果后再传递给规划模块。
-
目的:解决传统流水线中模块间信息丢失和误差累积的问题,通过全局优化提升规划的安全性和可靠性。
-
2.2. 路线二:多模态规划的范式
-
代表 :VADv2、Hydra-MDP、SparseDrive、DiffusionDrive 系列
-
基本概念:
这条路线聚焦于**"规划路径的多样性"** 。传统的端到端模型往往输出一条确定的轨迹,但现实驾驶充满了不确定性(比如前方有行人,可能需要左转或右转,或者减速等待)。多模态规划旨在让模型能够同时生成多条合理的、不同的候选轨迹,并评估它们的优劣。
-
基本理论:
-
多模态(Multi-Modality) :模型能够捕捉驾驶行为固有的多种可能性。例如,面对同一个路口,模型可以同时输出"左转"、"直行"、"右转"甚至"原地等待"等多个合理的轨迹选项。
-
候选集与不确定性:通过构建大规模的轨迹词汇表(Vocabulary,如VADv2)、基于扩散模型(Diffusion,如DiffusionDrive)或基于规则评分器(如Hydra-MDP)来生成和评估这些候选轨迹。
-
目的:应对复杂的交通场景,避免因只输出单一轨迹而导致的"模式坍塌"或决策死板,提高车辆在不确定环境下的鲁棒性。
-
2.3 扩散模型生成轨迹的过程
扩散模型(如 DiffusionDrive)生成轨迹的过程,本质上是一个**"去噪"**的过程。它不像传统方法那样直接"猜"一条轨迹,而是先随机生成一堆噪声,然后一步步"修正"这些噪声,直到变成合理的轨迹。下面我们拆解一下它是如何生成多条轨迹、如何学习、以及如何保证有效性的。
2.3.1 如何生成多条轨迹?(逆向去噪过程)
扩散模型生成轨迹分为两个阶段:加噪(训练) 和去噪(推理) 。生成多条轨迹的关键在于推理时注入不同的随机噪声。
1. 加噪(训练阶段:把轨迹"弄乱")
-
过程:取一条真实的人类驾驶轨迹 x0,逐步加入高斯噪声。经过很多步(如 100 步)后,这条轨迹就完全变成了一个纯粹的随机噪声 xT。
-
目的 :让模型学会"认识"噪声。模型的任务是,给定第 t步的噪声轨迹 xt,预测出这一步的噪声 ϵ是多少。
2. 去噪(推理阶段:从噪声中"还原")
这是生成多条轨迹的核心环节:
-
Step 1:随机采样 :我们不是从一条轨迹开始,而是从多个不同的随机噪声样本 xT(1),xT(2),...开始。每个噪声样本都对应一条潜在的轨迹。
-
Step 2:迭代去噪:对于每个噪声样本,模型根据当前状态(以及地图、周围车辆等条件)预测噪声,然后"减去"一部分噪声,得到稍微清晰一点的 xt−1。
-
Step 3:重复直至生成:重复 Step 2 几十次,直到噪声被完全去除,得到最终的光滑轨迹 x0(1),x0(2),...。
-
结果 :由于初始噪声不同,最终会生成多条不同的轨迹(例如,一条是直行,一条是避让,一条是减速)。
2.3.2 如何学习生成?(训练机制)
扩散模型的学习目标是预测噪声,而不是直接预测轨迹坐标。
训练目标(Loss 函数)
-
核心公式 :
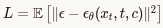
-
解读:
-
ϵ:真实加入的噪声(标签)。
-
:模型预测的噪声。
-
c:条件信息(如地图、周围车辆状态、导航指令)。
-
-
通俗理解:给模型看一张"被噪声模糊了的轨迹图"和"周围环境",让它猜"模糊的程度是多少"。猜对了,Loss 就小。
为什么这样设计?
直接回归轨迹坐标(x, y)容易导致模型输出"平均解"(即保守的、不激进的轨迹)。而预测噪声迫使模型去学习数据分布本身的细节,从而能生成更丰富、更多样化的轨迹。
2.3.3 如何保证生成轨迹的有效性?(安全与物理约束)
生成轨迹容易,但生成安全、合理的轨迹是难点。DiffusionDrive 等模型通过以下机制保证有效性:
1. 条件注入(Conditioning)
-
原理 :在去噪的每一步,模型都会接收环境条件 c。
-
内容:BEV 地图、周围车辆的预测轨迹、交通规则、导航指令。
-
作用:模型在去噪时,会不断"瞄一眼"环境,确保生成的轨迹不偏离地图、不撞车。例如,如果地图显示前方是墙,模型在去噪时会修正轨迹,避免穿墙。
2. 基于分类器引导(Classifier Guidance)
-
原理:在去噪过程中,引入一个额外的"打分器"(Classifier)。
-
作用:这个打分器不参与生成轨迹,但它会评估当前生成的轨迹是否安全(如是否碰撞、是否舒适)。然后,利用这个打分器的梯度去"引导"去噪过程,让轨迹向"高分"(安全、舒适)的方向修正。
-
通俗理解:相当于有一个"安全教练"在旁边看着,每当模型生成一个危险的轨迹点,教练就说"不对,往这边改"。
3. 后处理筛选(Rescoring & Selection)
-
原理 :先生成 N 条候选轨迹(多模态),然后通过一个价值函数(Value Function) 或碰撞检测模块 给每条轨迹打分。
-
作用 :从生成的 10 条、20 条轨迹中,选出综合得分最高 且无碰撞的一条作为最终输出。
-
优势:即使生成过程中有瑕疵,也可以通过后筛选来兜底。
2.3.4 总结:Diffusion 的优势与挑战
| 维度 | 说明 |
|---|---|
| 优势 | 天生多模态 :通过随机种子自然生成多条候选;表达能力强 :能拟合复杂、非线性的驾驶行为;避免平均解:不像回归模型那样输出平庸的轨迹。 |
| 挑战 | 推理慢 :需要多步迭代,实时性差;训练不稳定 :需要精细调参;安全性依赖后验:生成轨迹的安全性严重依赖条件注入和后续筛选。 |
形象比喻
扩散模型生成轨迹就像"雕塑":
-
传统回归模型:直接捏一个泥人(轨迹),容易捏成四不像(平均解)。
-
扩散模型:先找一块混沌的大理石(噪声),根据蓝图(环境条件)和教练的指导(分类器引导),一刀刀凿去多余部分(去噪),最终露出雕像(轨迹)。如果凿坏了,就换一块石头(重采样)或者换个凿法(引导)。
2.4. 路线三:VLA / 世界模型路线
-
代表 :DriveVLA-W0、Alpamayo-1、DriveWorld-VLA
-
基本概念:
这条路线引入了**"语言"** 和**"想象"**的能力。它将自动驾驶视为一个类似于人类"看(Vision)-想(Language)-做(Action)"的过程,或者通过构建一个"世界模型"在脑海中模拟未来。
-
基本理论:
-
Vision-Language-Action (VLA):将视觉感知与大型语言模型(LLM)的语义推理能力结合。模型不仅能识别物体,还能理解场景的语义(如"前方是施工路段"、"有警察在指挥"),并根据这些语义信息生成动作。这使得决策过程更具可解释性。
-
世界模型(World Model):模型内部学习了一个关于物理世界动态的模型。它能够根据当前的观测和动作,预测未来的场景变化(例如,"如果我向左变道,后车会怎么反应?")。
-
语义+想象+动作一体:结合VLA的语义理解和世界模型的预测能力,模型能够进行反事实推理(Counterfactual Reasoning),即在"脑中"模拟不同动作带来的后果,从而选择最优的动作。这种路线更接近人类的高级认知和推理过程。
-
三、UniAD 开山之作
UniAD(Unified Autonomous Driving)是上海AI Lab等团队提出的端到端自动驾驶统一范式代表作。
3.1. UniAD各模块作用+设计核心思想(通俗解释)
1. 模块拆解与作用
(流程:Backbone→Perception→Prediction→Planning)
我们把UniAD想象成一个"自动驾驶大脑",从"看路"到"决策开车"分成4个核心环节:
-
**① Backbone(骨干网络):负责"看"和"提取基础信息"**
-
输入:多视角摄像头图像(纯视觉,也可以扩展激光雷达)。
-
输出:BEV特征(Bird's Eye View Feature,鸟瞰图特征)。
-
通俗理解:把不同角度的摄像头画面,转换成"上帝视角"的地图特征(比如道路、车道线、障碍物在俯视图中的位置),相当于给大脑提供"环境的数字画像"。
-
-
**② Perception(感知):负责"识别+跟踪+建图"**
-
包含三个子模块:TrackFormer(跟踪)、MapFormer(建图)、以及隐含的目标检测。
-
TrackFormer:用"注意力机制"跟踪路上其他车辆、行人等,回答"谁在动?往哪动?"。
-
MapFormer:用"注意力机制"理解道路结构(车道、路口、停止线等),回答"路怎么走?哪里能拐弯?"。
-
通俗理解:感知模块是大脑的"眼睛+记忆",既认出周围的物体(车、人),又记住道路的规矩(车道、路口),还跟踪它们的运动趋势。
-
-
**③ Prediction(预测):负责"猜未来"**
-
核心模块:MotionFormer(运动预测)。
-
作用:不仅预测"其他物体未来会走到哪",还预测"自车未来可能的轨迹",甚至考虑"预测终点(比如导航要去的路口)"和"其他物体"的交互。
-
通俗理解:大脑开始"脑补未来"------别车会不会突然变道?行人会不会横穿?我如果这么开,未来几秒会到哪?
-
-
**④ Planning(规划):负责"决定怎么开"**
-
核心模块:Planner + Occ(占用预测)。
-
Planner:根据前面感知、预测的信息,结合"自车当前状态""导航指令(比如要去左边路口)",输出一条明确的行驶轨迹(比如转向角、油门刹车的控制序列)。
-
Occ(占用预测):在后处理阶段,检查这条轨迹是否安全(比如会不会撞到障碍物、会不会压到不可行驶区域),给轨迹"做体检",确保物理上的安全性。
-
通俗理解:大脑最终做决策------"现在该打方向盘多少度?踩多少油?",还要先拿"占用预测"检查一遍,确认轨迹不会撞墙、不会掉沟里。
-
2. 设计核心思想(为什么说它是"开山之作"?)
UniAD的核心逻辑是 "把所有自动驾驶任务(感知、预测、规划)打包进一个网络,端到端一起优化",而不是传统方法"感知→预测→规划"各做各的(模块间容易信息丢失、误差累加)。具体设计的"巧思"体现在:
-
① 统一框架,全局优化
传统自动驾驶是"流水线":感知模块输出给预测,预测输出给规划,每个模块独立训练,容易"前一个模块错了,后面全错"。UniAD把这些模块塞进同一个神经网络,用一个目标(比如"安全规划出可行轨迹")一起训练,让感知、预测都为了"规划更好"服务。
-
**② MotionFormer的"三层交互注意力"**
为了让模型更懂环境,MotionFormer设计了三种注意力机制:
-
目标↔目标:比如"前车和我"的位置关系、运动关系;
-
目标↔地图:比如"我"和"车道线""路口"的关系;
-
预测终点↔目标:比如"我要去的路口"和"其他车"会不会冲突。
通俗说:模型不是孤立看每个物体,而是像人开车一样,同时考虑"周围车、路、目的地"三者互动,让预测更精准。
-
-
**③ Planner-Query的"首创范式"**
做规划时,Planner的"输入指令(Query)"不是随便编的,而是把自车的轨迹预测、自车当前状态(速度、位置)、导航指令(往哪走) 都"编码"进去。相当于给规划模块一个"明确的问题":"我现在速度60km/h,在左车道,要去前方路口左转,周围车的情况是这样...该咋开?" 这种把多维度信息打包成Query的方式,后续很多方法都在借鉴。
-
**③ Occ的后处理安全优化(非端到端损失,但实用)**
规划出轨迹后,用**Occ(占用预测)** 检查轨迹是否安全(比如轨迹经过的区域有没有障碍物、是不是可行驶区域)。注意:这个优化是"后处理"(损失没参与整体网络训练),但能大幅提升安全性。相当于"大脑先想个方案,再找专家(Occ)检查一遍,确认没危险才执行"。
3.2.总结:UniAD为什么是"开山之作"?
它第一次把感知、预测、规划全放进一个网络端到端优化 ,解决了传统模块化的信息割裂问题;同时通过MotionFormer的多层交互、Planner-Query的信息整合、Occ的安全后处理,为后续端到端自动驾驶方法提供了设计模板和技术启发(后续VADv2、Hydra-MDP等方法都在这些点上改进)。
简单说:UniAD是"端到端自动驾驶"的第一个完整'样板间',让行业看到"把感知-预测-规划打包成一个大脑,一起训练"是可行且有效的,因此被很多人视为端到端自动驾驶的"开山之作"。
3.3. UniAD:优点与局限
1. UniAD的优点
-
**避免误差累积(整体优化)**
传统自动驾驶是"感知→预测→规划→控制"的流水线,前一模块的输出是后一模块的输入,误差会层层传递。UniAD将感知、预测、规划全部纳入一个网络,信息全链路共享、全局优化,从源头上避免了"前一个模块算错,后一个模块跟着错"的问题。
-
**决全栈协同(统一处理多任务)**
用一个网络同时处理"感知(识别物体、建图)、预测(物体/自车未来轨迹)、规划(输出行驶路线)",打破了模块间的壁垒。比如,规划模块可以直接通过注意力机制"询问"感知模块"某辆车的精确位置",而不用等感知模块输出最终结果再传递,让信息传递更高效、协同更紧密。
-
**工程上简洁高效(接口&优化自然)**
通过"Query(查询)"机制实现模块间交互(如Track Query、Map Query、Motion Query),接口设计更简洁,不用维护复杂的模块间数据流转管道。同时,端到端的训练让模型能"自然"地学习从"感知环境"到"规划路径"的全局最优策略,部署时也更简单(一个网络代替多个模块的串联)。
2. UniAD的局限(结合截图及设计特性)
-
工程落地难度大
模型是"一张大网",参数规模大、结构复杂,调参和部署的复杂度高。比如,训练时需要大量算力和数据,部署到车载芯片上时,要考虑算力限制、延迟等问题,工程化难度比传统模块化方案更高。
-
**偏向"平均值解"(应对复杂场景能力有限)**
对"环境不确定性"的建模相对弱,规划结果常趋向**"单模解"** (即给出一个"平均意义上最优"的方案),而非"多模解"(考虑多种可能性后再决策)。比如,在复杂路口(如行人和车同时出现干扰),它可能无法像人类司机一样"先想多个方案再选最优",更像是"直接给一个答案的司机",对复杂场景的"想象力"(多可能性探索)不足。
简言之,UniAD的核心优势是**"一条龙式整体优化"** ,解决了传统流水线的误差累积和模块割裂问题;但局限也很明显------工程落地难 ,且应对复杂场景的"多模态决策能力"不足,更偏向"单模的平均解"。
四、多模态候选集规划
自动驾驶轨迹具有多模态不确定性(同一场景下存在多条安全/合理轨迹),规划需直面该问题,而非输出"平均解"。核心任务是先显式构造多模态轨迹候选集,再通过决策选择最优轨迹。
多模态候选集规划分为 "候选集范式(按菜单点菜)" 和 "动态生成范式(看食材做菜)",本质是"候选轨迹如何表达、如何选择"的不同解法。
4.1. 候选集范式(按菜单点菜)
-
核心逻辑 :类似"餐厅预设菜单→按菜单做菜→客人挑选",通过静态离散的轨迹候选集 (如词表、anchor),让模型在预定义的候选中打分选优。
-
代表方法:
-
VADv2:将轨迹离散为"静态词表",模型对词表中候选轨迹打分,选最优。
-
Hydra-MDP:基于离散词表,用"大模型+多teacher蒸馏"输出scoring/ranking头,选综合评分最高的轨迹。
-
SparseDrive:稀疏场景建模+anchor回归多模态轨迹,结合碰撞感知/rescore筛选最优。
-
-
核心矛盾:如何在有限算力下,高效表达复杂路口的多条安全路径并选最优(即"候选怎么表达、怎么挑、怎么算")。
4.2. 动态生成范式(看食材做菜)
-
核心逻辑 :类似"私厨根据当天食材→做多道菜→客人挑选",通过动态生成轨迹 (如扩散模型),根据场景实时生成多模态轨迹,再打分筛选。
-
代表方法 :DiffusionDrive/GoalFlow
-
利用扩散模型,从带噪声的连续空间出发,迭代去噪生成多模态轨迹;
-
结合感知(地图、智能体信息)作为条件,确保轨迹符合场景约束;
-
打分筛选最优轨迹,覆盖更多解空间。
-
-
目标:在有限计算内精细覆盖解空间,兼顾多样性与安全性。
4.3 优势与局限
| 维度 | 候选集范式(按菜单) | 动态生成范式(看食材) |
|---|---|---|
| 优势 | 工程落地相对易(静态候选易部署) | 原生支持多模态,适应复杂路况;决策可解释性强;平衡安全与实时 |
| 局限 | 候选集离散性导致"最优解可能被遗漏"(静态词表/anchor粒度粗) | 计算开销大(扩散模型算力消耗高,端侧部署难);极端场景覆盖有盲区 |
关键设计点
-
候选表达:静态(词表、anchor) vs 动态(扩散生成);
-
候选选择:打分/排名(如Hydra-MDP的scoring head) vs 扩散去噪+打分;
-
算力与覆盖:候选集需平衡"覆盖度"与"计算量",动态生成需在"多样性"与"实时性"间 trade-off。
与UniAD的区别
UniAD是**"规划导向的统一范式"** (整合感知、预测、规划到单一网络,输出单条规划轨迹);而**"多模态规划范式"**核心是"候选集+选择",强调轨迹的多模态表达与决策,二者技术侧重点不同(UniAD重"统一优化",路线二重"多模态候选与选择")。
总结:多模态候选集规划通过"候选表达→候选生成→候选选择"的逻辑,解决自动驾驶轨迹的多模态不确定性问题,分为"静态候选+打分"(候选集范式)和"动态生成+打分"(动态生成范式),前者工程易落地但覆盖有限,后者覆盖好但算力要求高,需在实际场景中权衡。
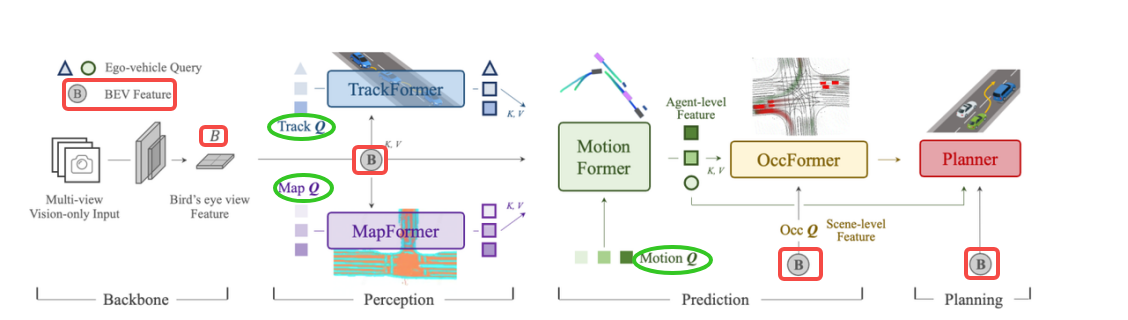
4.4 SparseDrive整体架构及核心思想总结
1. 整体架构模块拆解与作用原理
SparseDrive的架构围绕 "稀疏表示贯穿感知、预测、规划" 设计,核心模块包括:Image Encoder(图像编码器)、Symmetric Sparse Perception(对称稀疏感知)、Instance Memory Queue(实例记忆队列)、Parallel Motion Planner(并行运动规划器),以及贯穿各模块的稀疏表示(Anchor/Instance-Feature) 和时序融合机制。
这个方案相较于静态词表以及difussion方案是一个折中的方案。
1). Image Encoder(图像编码器)
-
作用 :从车载摄像头图像中提取多尺度特征,为后续感知、预测、规划提供基础视觉信息。
-
原理:采用类CNN(如Backbone+Neck)结构,对输入图像进行编码,输出包含语义、空间信息的特征图(Feature Map)。
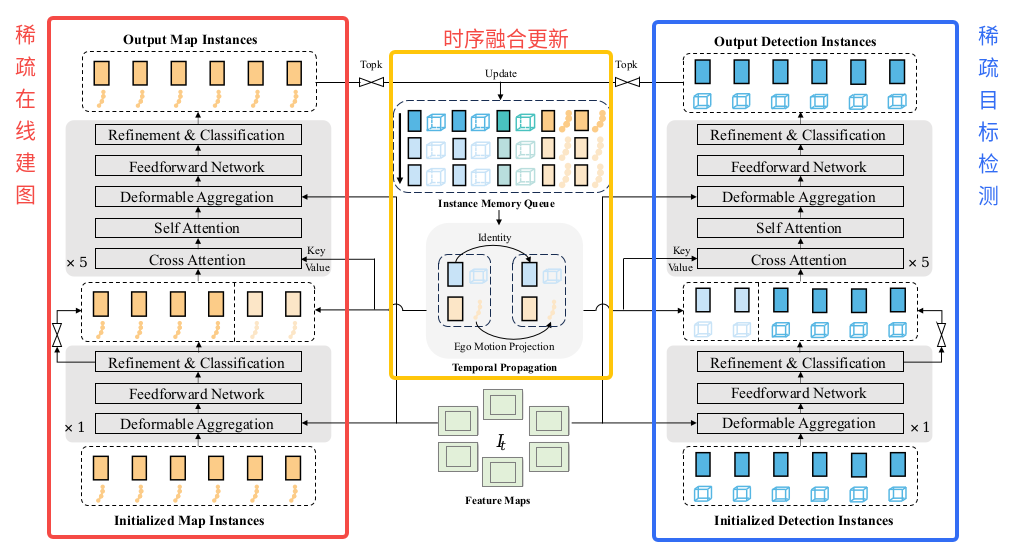
2). Symmetric Sparse Perception(对称稀疏感知)
-
作用 :实现检测(目标识别)、跟踪(时序关联)、在线制图(地图元素生成),输出"稀疏实例"(车、人、路标、车道线等的抽象表示)。
-
原理:
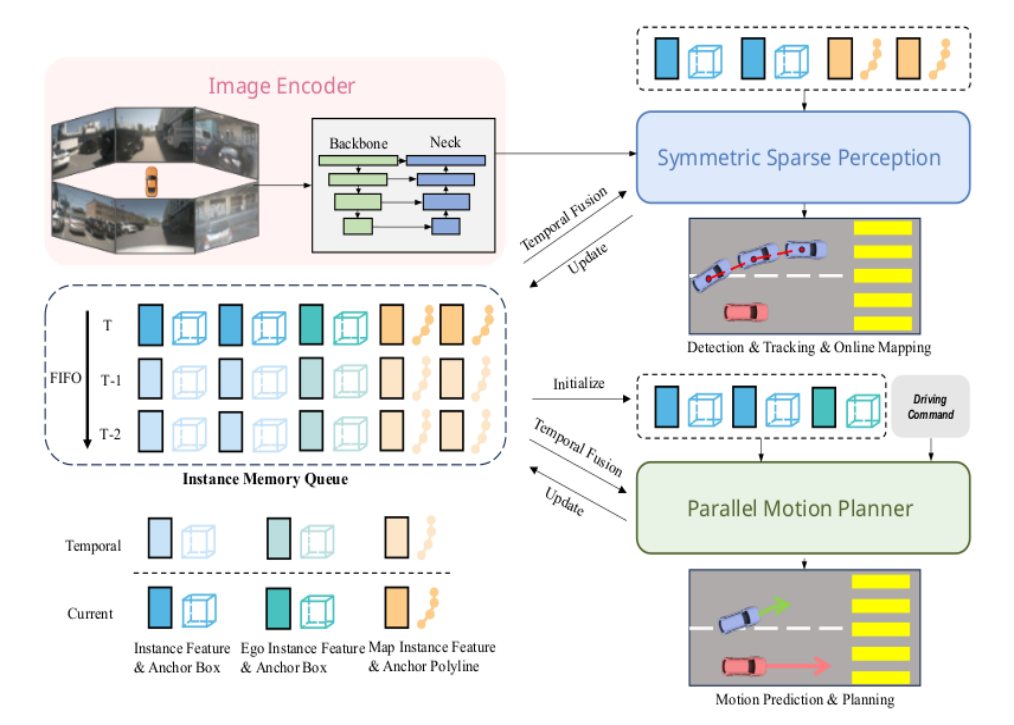
-
基于预设Anchor(训练集通过k-means聚类得到的"关键实例中心",如左图的聚类点),将特征图上的密集区域转换为"稀疏实例"(右图的彩色小方块)。
-
-
通过
Refinement & Classification、Feedforward Network、Deformable Aggregation、Self Attention、Cross Attention等子模块,对每个实例进行精细化分类、特征聚合、时序关联(跟踪)。 -
-
最终输出
Output Detection Instances(检测实例,如车辆、行人)和Output Map Instances(地图实例,如车道线、路标),并初始化Initialized Detection Instances/Initialized Map Instances供后续模块使用。
-
3). Instance Memory Queue(实例记忆队列)
-
作用 :时序融合与记忆,维护历史实例信息,让模型具备"短期记忆",支持时序关联(跟踪)和动态规划。
-
原理:
-
存储不同时刻(T-2, T-1, Current)的实例特征(车、地图、自车等),通过
Ego Motion Projection(自车运动投影)和Temporal Propagation(时序传播)实现跨帧实例关联(如跟踪同一辆车的轨迹)。 -
对实例特征进行
Update(更新),确保历史信息与当前帧信息融合,为预测和规划提供连续的时序上下文。
-
4). Parallel Motion Planner(并行运动规划器)
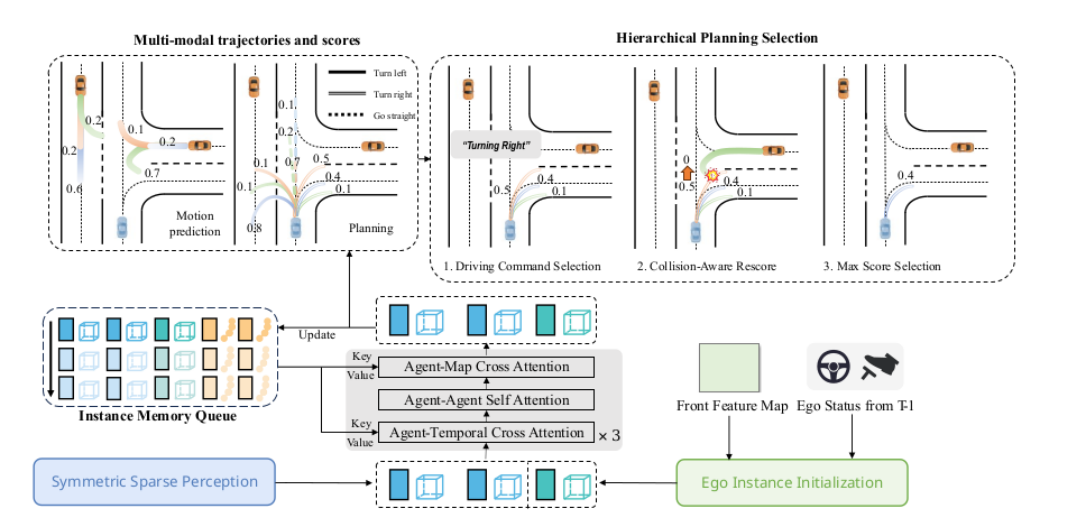
-
作用 :基于感知的实例信息和记忆队列的历史信息,生成多模态轨迹(安全、合理的行驶路径),并输出最终规划指令。
-
原理:
-
输入:感知模块的检测/地图实例、记忆队列的时序实例、自车状态(位置、速度等)。
-
通过
Detection & Tracking & Online Mapping、Driving Command(驾驶指令)、Motion Prediction & Planning等子模块,结合碰撞感知(Collision-aware) 和**重打分(Rescore)** 机制,筛选最优轨迹。 -
输出:最终的行驶轨迹(如转向、加速指令),支持多模态(考虑多种可能路径)。
-
2. 核心思想(三大设计理念)
SparseDrive的核心思想围绕 **"稀疏化、实例级统一、安全性内嵌"** 展开,解决传统端到端方法"密集计算冗余、模块割裂、安全后处理不自然"的问题。
1). 稀疏代替密集(高效计算)
-
逻辑 :现实世界由**离散对象(车、人、路标、车道线)** 组成,用"稀疏实例"表示既高效又贴合物理结构。
-
原理:
-
网络模块间仅传递Anchor/Instance-Feature(关键实例的特征),计算只围绕这些"关键实例"展开,去除大面积无用算力(如传统密集BEV特征的全局计算)。
-
预设Anchor通过k-means聚类得到(训练集中各类目标元素的top-k聚类中心),确保实例表示覆盖常见场景。
-
2). 感知/预测/规划真正统一在"实例层面"
-
逻辑 :用同一套稀疏表示 (Anchor/Instance-Feature)贯穿感知、预测、规划,让自车规划直接在"实例级信息"上做时空交互。
-
原理:
-
感知模块输出的"检测/地图实例"直接作为预测(其他车辆轨迹)和规划(自车轨迹)的输入,无需模块间转换(如传统方法感知→预测→规划的"中间结果传递")。
-
规划时,自车实例与周围车辆、地图实例通过
Agent-Map Cross Attention、Agent-Agent Self Attention、Agent-Temporal Cross Attention等机制,实现实例间的时空交互(如考虑其他车的运动对自车轨迹的影响)。
-
3). 把"安全性"内嵌到端到端优化目标
-
逻辑 :不再事后用规则(如碰撞检测)过滤轨迹,而是把"碰撞感知"变成可微模块 ,纳入
end-to-end的训练目标,让模型"学会选安全轨迹=loss更小"。 -
原理:
-
损失函数设计包含
L_det(检测)、L_map(地图)、L_motion(运动预测)、L_plan(规划)、L_depth(深度辅助)等,其中:-
L_motion:对周围agents的多模态轨迹预测,采用winner-takes-all策略(只对最接近真实轨迹的模态回传损失),鼓励模型学习准确的运动预测。 -
L_plan:对自车多模态规划轨迹+状态回归的损失(包含位置、速度、加速度误差),同时结合碰撞感知的可微约束(如轨迹与环境实例的碰撞惩罚),让模型在训练中自动优化"安全轨迹"。
-
-
3. 训练方式(两阶段训练)
SparseDrive采用两阶段训练,逐步稳定模块并端到端优化:
-
Stage-1:只训练稀疏感知模块
-
目标:优先稳定检测、跟踪、在线制图模块,避免多模块联合训练的梯度冲突。
-
损失:包含
L_det(检测损失)、L_map(地图损失)、L_depth(深度辅助损失),仅优化感知模块。
-
-
Stage-2:端到端联合训练
-
目标:打开运动预测和规划模块的梯度,实现全局优化。
-
损失:总损失
L = L_det + L_map + L_motion + L_plan + L_depth,其中:-
L_motion:周围agents的多模态轨迹预测损失(winner-takes-all)。 -
L_plan:自车多模态规划轨迹+状态回归损失(含碰撞感知约束)。
-
-
4. 模块协作流程(简化版)
- 图像输入→Image Encoder :提取多尺度特征。
- 特征→Symmetric Sparse Perception :生成稀疏实例(检测、跟踪、制图),输出初始化实例。
- 初始化实例→Instance Memory Queue :时序融合历史实例,更新记忆。
- 记忆队列+感知实例→Parallel Motion Planner :生成多模态轨迹,筛选最优(结合碰撞感知、重打分)。
- 输出规划指令:控制自车行驶。
总结
SparseDrive通过稀疏实例表示 贯穿感知、预测、规划,用实例级统一交互 打破模块割裂,用可微安全约束 内嵌优化目标,结合两阶段训练 稳定收敛,最终实现"高效、安全、端到端"的自动驾驶规划。其核心创新在于用稀疏代替密集计算 、实例级模块统一 、安全性内嵌训练,解决了传统方法的算力冗余、模块割裂、安全后处理不自然等问题。