引言
在 AI 大模型时代,算子性能优化是提升整体训练和推理效率的关键。
TileLang 是一门面向高性能算子开发的领域特定语言(DSL),采用简洁直观的编程范式,让开发者能够以接近数学表达的方式描述计算逻辑。相比传统的手写算子开发,TileLang 大幅降低了开发门槛,使开发者能够更高效地完成高性能算子的开发与调优。
TileLang-Ascend 是 TileLang 针对 Ascend NPU 的高性能算子开发框架,在保持易用性的同时提供了强大的性能优化能力。通过内置的优化原语(如 T.pipelined、T.tile 等)和自动化优化策略,开发者可以轻松实现核间流水、核内并行、内存常驻等高级优化技术,无需手动编写复杂的同步和调度代码。这种"高层抽象 + 底层优化"的设计理念,使得在 TileLang-Ascend 上进行性能优化既高效又便捷。
本文将系统介绍 TileLang-Ascend 框架下的算子性能优化方法论,并以 Flash Attention (FA) 和 Sparse Flash Attention (SFA) 算子为例,展示优化思路的实际应用与显著效果。
一、性能优化方法
1.1 先把单核做到足够快,再谈多核协同
在 TileLang-Ascend 里,算子性能优化天然分两层:C/V 核内优化 (单核是不是够快)和 C/V 核间优化(多核能不能高效并行)。
为什么一般选择先做核内、再做核间?原因很实际:如果单核本身就有大量气泡和等待,核间流水线再怎么设计都会被拖住------慢流水拖快流水,优化空间还没打开就先被锁死了。反过来,单核打满之后,核间流水的效果才能完整释放。
| 优化层次 | 核心问题 | 典型手段 |
|---|---|---|
| C/V核内(Intra-Core) | 单核的计算和搬运能不能充分重叠 | Cube 核 L1 常驻、多 Buffer、Vector 核 num_stages 调优、scalar 向量化 |
| C/V核间(Inter-Core) | Cube 和 Vector 之间流水能不能接紧 | num_stages 调优、任务均衡、同步优化 |
1.2 优化不是一个动作,而是一个闭环
性能优化不是"选几个手段叠上去",而是"测→找→改→验"的迭代闭环:
性能基准测试 → 识别瓶颈 → 针对性优化 → 验证收益
↑
└────────── 迭代 ←──────────┘具体四步:
- 建立基线:通过 profiling 获取初始性能数据,明确当前版本的耗时分布。
- 定位瓶颈:判断瓶颈主要来自核内计算、数据搬运,还是核间同步与调度。
- 实施优化:围绕主要瓶颈选择最合适的手段,避免一次性叠加过多优化,影响问题定位。
- 验证收益:对比优化前后的性能变化,确认收益是否稳定,同时检查是否引入新的瓶颈。
迭代几轮之后,性能会收敛到一个比较稳的状态。
1.3 三条原则,贯穿始终
在具体执行过程中,建议始终围绕以下三个原则展开:
| 原则 | 说明 |
|---|---|
| 掩盖短流水 | 将耗时短的流水尽量用耗时长的流水掩盖 |
| 减少气泡 | 优化任务排布,减少核间等待时间 |
| 收敛到单一 Bound | 理想情况下优化至单一类型流水 bound |
2. 核内优化
2.1 多Buffer:搬运和计算,别再串着跑
Cube或Vector都可以开启多buffer,以vector为例,计算队列、MTE2搬运队列、MTE3搬运队列互相独立,天然可以并行。多 Buffer 就是利用这个特性,把数据分成多份,让 CopyIn、Compute、CopyOut 三个阶段交错执行,以double buffer为例:
串行模式:
------------------------------时间轴------------------------------>
[MTE2][VEC][MTE3][MTE2][VEC][MTE3]
Double Buffer:
------------------------------时间轴------------------------------>
buffer0: [MTE2][VEC][MTE3]
buffer1: [MTE2][VEC][MTE3]原理很简单:buffer0和buffer1使用不同的地址空间,当 buffer0 做 Compute 的时候,buffer1 就可以进行 CopyIn 搬入下一块数据,搬运时间被"藏"在计算后面,Vector 单元的等待时间直接降下来。也可以根据循环次数已经数据总量选择更多的buffer数,但随着buffer数增加,占用的空间也会增加。
2.2 Cube 核:L1 常驻省空间,流水争取优化到单一Bound
Cube 核做矩阵乘的时候,L1 容量有限,Q/K/V矩阵不一定全放得下。这时候可以选择:让复用率最高的那份长驻 L1,只分批搬运其他矩阵,减少 GM↔L1 之间的搬运次数。
以 FA 算子为例,常见策略:
| 策略 | 适用条件 | 做法 |
|---|---|---|
| 大复用 | L1 充裕 | Q 在 L1 中持续多个基本块,每次只换 KV |
| 小复用 | L1 紧张 | Q 只保留一个基本块,省空间 |
具体选哪份常驻,要看算子的访问模式,也可以反过来让 KV 常驻,效果类似。
常驻做完之后,下一步就是收敛到单一 Bound。 理想状态下,Cube 核上应该只剩一条流水是瓶颈(耗时最长的那条),其余流水全部被它盖住:
优化前(各流水串行):
时间轴 →
MTE: [==] [==]
M: [===] [===]
FIX: [==============]
优化后(FIX 作为 Bound,MTE 和 M 被它掩盖):
时间轴 →
|------ 一个FIX周期 ------|
MTE: [==] ← 被 FIX 盖住
M: [===] ← 被 FIX 盖住
FIX: [=============] ← 瓶颈流水当 MTE(搬运)和 M(矩阵乘)都能被 FIX 阶段盖住的时候,系统就只剩一个瓶颈,针对瓶颈流水(当前为FIX)优化才能有进一步的性能提升,这个判断非常关键,它决定了优化往哪个方向推才是有效的。
2.3 Vector 核:向量化 + 指令合并
Vector 核经常遇到的瓶颈是 scalar 操作过多,Scalar 负责标量运算和流程控制,它会阻塞整个异步并行流水,所以优化方向很明确:把 scalar 循环改成 tile 操作,让一批数据一次处理完。
python
# 优化前:对 m_i 逐元素 scalar 操作
for h_i in range(block_M // 2):
T.tile.sub(acc_s_ub[h_i, :], acc_s_ub[h_i, :], m_i[h_i])
# 优化后:一次 broadcast + 一次 tile 操作
T.tile.broadcast(m_i_2d, m_i, tmp_ub)
T.tile.sub(acc_s_ub, acc_s_ub, m_i_2d)scalar 减完之后,还可以进一步合并可融合的指令,减少指令下发次数:
python
# 优化前:两条指令
T.tile.mul(acc_s_ub, acc_s_ub, sm_scale)
T.tile.sub(acc_s_ub, acc_s_ub, m_i_2d)
# 优化后:一条 axpy 搞定
T.tile.axpy(acc_s_ub, m_i_2d, sm_scale)指令下发次数直接影响 Vector 单元的调度开销。尤其在高频循环里,少一条指令、每轮就少一个调度节拍,累积下来对性能提升的帮助也很大。
3. 核间优化:提升 Cube 与 Vector 的流水线衔接效率
核内做到位之后,下一个瓶颈通常会移到 Cube 和 Vector 之间的衔接上。CV 融合算子的核间优化,建议按以下顺序推进:先把慢的核内部流水做好 → 选合适的流水深度 → 降低核间同步开销。
3.1 num_stages 调优:控制流水线深度以减少气泡
T.Pipelined是 TileLang-Ascend 的流水线循环原语,用来把普通循环组织成可重叠执行的producer/consumer流水。在 C/V 核间流水场景下,Cube 核通常作为producer,将中间结果写入workspace;Vector 核作为consumer,从workspace读取结果并继续处理。
num_stages表示producer和consumer之间可使用的最大buffer数,决定这条流水线可同时保留多少个中间结果版本。合适的num_stages能提高前后任务的重叠度,减少Cube与Vector之间的等待时间。
对于CV融合算子,当参与流水的任务块数较多,且C核与V核执行时间不均衡时,适当增大num_stages可以减少气泡:
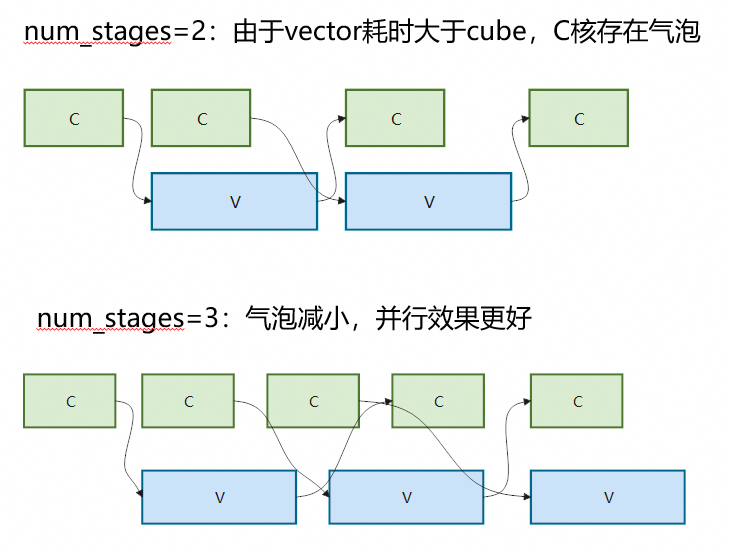
3.2 核间同步优化
核间同步过于频繁会增加Scalar控制开销,容易出现scalar bound;但同步次数过少又可能降低C/V核间并行度,带来性能损失。应在保证正确性的前提下,权衡同步开销与并行收益,选择较优的同步次数:
python
# 优化前:每次任务都同步
for i in range(n):
process()
sync()
# 优化后:多次任务后同步
for i in range(n):
process()
if i % 2 == 1:
sync()如果确认核间同步的耗时较大,可以增大cross_interval参数查看性能收益,起始频率一般可以从"每 2 次任务同步一次"开始试,然后根据 profiling 调整,原则和前面的迭代闭环一样:改一个变量,测一轮数据,确认方向对了再继续。
四、实操案例一:Flash Attention 算子优化
Flash Attention 是 Transformer 模型中的核心算子,其性能直接影响模型训练和推理效率。
4.1 性能测试
输入参数定义:
| 参数 | 取值 | 说明 |
|---|---|---|
| B | 1 | Batch大小 |
| Q_N | 12 | Query序列长度 |
| KV_N | 1 | KV序列数 |
| D | 128 | 隐藏层维度 |
| S | 32K/64K/128K | 序列长度 |
| block_size | 128 | 块大小 |
最佳性能结果:
| S | Ascend C | TileLang | 性能百分比(Ascend C/TileLang) |
|---|---|---|---|
| 32K | 37555u | 46643u | 80.52% |
| 64K | 149578u | 185188u | 80.77% |
| 128K | 600018u | 741211u | 80.95% |
4.2 优化策略及收益分析
针对 FA 算子,我们采用了以下优化组合:
- L1 内存常驻:Q 矩阵在 L1 中持续多个基本块,减少 GM 访问
- 指令向量化 :将 scalar 操作转换为 tile 操作,减少scalar指令 --- 原生Ascend C算子36%
- 多Buffer:核内流水并行,掩盖数据搬运延迟
- 核内冗余同步消除 :--- 原生Ascend C算子50%
- T.pipelined 原语 :开启核间 CV 流水,最大化 Cube 和 Vector 核并行度,调整num_stages为8 --- 原生Ascend C算子60%
- 优化核间同步下发次数 :每两次任务进行一次核间同步 --- 原生Ascend C算子72%
- 减少指令数 :使用axpy代替mul和sub,减少指令下发数 --- 原生Ascend C算子80%
4.3 优化效果
通过系统性优化,FA 算子在保持 TileLang 的高开发效率前提下,达到了 Ascend C 原生算子80%的性能,混合编程模式下性能达到原生算子60%。
| 优化项 | L1 内存常驻 | 指令向量化 | 多Buffer | 核内冗余同步消除 | CV pipelined | 优化核间同步下发次数 | 减少指令数 | 性能(A3) |
|---|---|---|---|---|---|---|---|---|
| flash_attn_bhsd_expert_h16_d128.py | √ | √ | √ | √ | √ | √ | √ | 80% |
| flash_attn_bhsd_auto_pipeline_h16_d128.py | √ | √ | √ | × | √ | × | √ | 60% |
算子实现:https://github.com/tile-ai/tilelang-ascend/tree/ascendc_pto/examples/flash_attention/fa_opt
五、实操案例二:Sparse Flash Attention 算子优化
Sparse Flash Attention (SFA) 是 DeepSeek v3.2 版本中引入的核心注意力机制。本节展示从基线版本到极致优化版本的完整优化路径。
5.1 性能测试
输入参数定义:
- T=1, B=1, Q_N=128, KV_N=1
- D=512, D_rope=64
- sparse_size=2048, block_size=128
三组测试 shape(仅在 KV_S 上不同):
| 编号 | KV_S | 说明 |
|---|---|---|
| shape0 | 2560 | 短序列 |
| shape1 | 6400 | 中序列 |
| shape2 | 48000 | 长序列 |
5.2 优化策略及收益分析
以kv_s=2560的shape为例:
第一阶段:baseline → developer(性能提升 42%)
通过 Broadcast 优化,将多条指令合并,减少指令下发开销。同时,针对离散访存,将kv gather为连续内存后搬出,性能从 602us 提升至 347us。
第二阶段:developer → T.pipelined(性能提升 63%)
引入稀疏访存优化和 CV pipeline,利用 T.pipelined 原语开启核间流水,实现 Cube 和 Vector 核的高效并行。性能从 347us 提升至 127us。
第三阶段:T.pipelined → no_cv_pipeline(性能提升 14%)
通过增大 s2 切分大小(64→256),增加每轮 Gather kv 和 Copy out 的数据规模,有利于提升访存吞吐;同时,增大基本块大小,也能进一步提升cube侧计算效率。。性能从 127us 提升至 109us。
5.3 优化效果
从基线版本到最优版本,总体性能提升达 82% (602us → 109us),充分验证了系统化优化方法论的有效性。
在tileLang-ascend仓上,我们提供了四个逐步优化的版本:
| 文件 | Fixed Core | s2切分大小 | kv gather与连续搬出 | 异步拷贝/核内手动同步 | 搬入搬出 Ping-Pong | CV pipeline | Broadcast优化 | AXPY优化 | 性能数据(A3) |
|---|---|---|---|---|---|---|---|---|---|
| sparse_flash_attn_pa_baseline.py | √ | 64 | × | × | × | × | × | × | 602us |
| sparse_flash_attn_pa_developer.py | √ | 64 | √ | × | × | × | √ | × | 347us |
| sparse_flash_attn_pa.py | √ | 64 | √ | √ | √ | √ | √ | √ | 127us |
| sparse_flash_attn_pa_no_cv_pipeline.py | √ | 256 | √ | √ | √ | × | √ | √ | 109us |
六、性能调优 Checklist
在实际优化过程中,建议按以下清单逐项检查:
- 采集 msprof 性能数据
- 分析 C/V 核耗时比例
- 尝试不同
num_stages值 - 检查 L1/L0 内存利用率
- 确认 Double Buffer 已开启
- 优化 scalar 操作为向量化
- 减少不必要的核间同步
七、常见问题与解决方案
| 现象 | 可能原因 | 解决方案 |
|---|---|---|
| C 核大量气泡 | V 核耗时长,num_stages 太小 | 增大 num_stages |
| 内存溢出 | num_stages 过大或 buffer 过大 | 减小分块参数 |
| 指令下发慢 | scalar 操作过多 | 使用 T.tile 向量化 |
| GM 带宽未打满 | 数据搬运效率低 | 开启 L1 常驻、Double Buffer |
结语
算子性能优化是一项系统性工程,需要从核内和核间两个维度协同发力。本文通过 FA 和 SFA 两个实际案例,展示了从方法论到实践的完整优化路径。TileLang-Ascend在帮助开发者提高开发效率的同时,也提供了必备的性能调优能力。欢迎更多开发者加入高性能算子的建设。
TileLang 社区已开放完整示例、性能脚本与优化指南,欢迎体验与贡献。