数据结构概念
数据结构,就是一种程序设计优化的方法论,研究数据的**逻辑结构**和**物理结构**以及它们之间相互关系,并对这种结构定义相应的**运算**,目的是加快程序的执行速度、减少内存占用的空间。
数据结构的研究对象
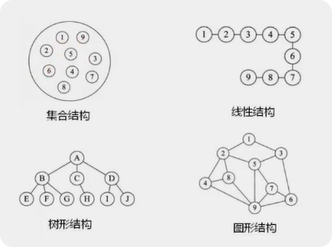
研究对象1:数据之间的逻辑关系
集合结构
线性结构:一对一关系
树形结构:一对多关系
图形结构:多对多关系
研究对象2:数据的存储结构(或物理结构)
-
顺序结构
-
链式结构
-
索引结构
-
散列(哈希)结构
开发中,我们更习惯上如下的方式理解存储结构:
>线性表(一对一关系):一维数组、单向链表、双向链表、栈、队列
>树(一对多关系):各种树。比如:二叉树、B+树
>图(多对多关系)
>哈希表:比如:HashMap、HashSet
研究对象3:相关的算法操作
-
分配资源,建立结构,释放资源
-
插入和删除
-
获取和遍历
-
修改和排序
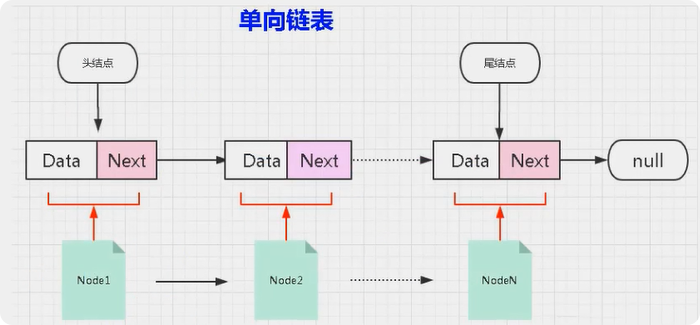
常见存储结构之:链表
链表中的基本单位是:节点(Node)
单向链表
java
class Node{
Object data;
Node next;
public Node(Object data){
this.data = data;
}
}创建对象:
java
Node node1 = new Node("AA");
Node node2 = new Node("BB");
node1.next = node2;双向链表
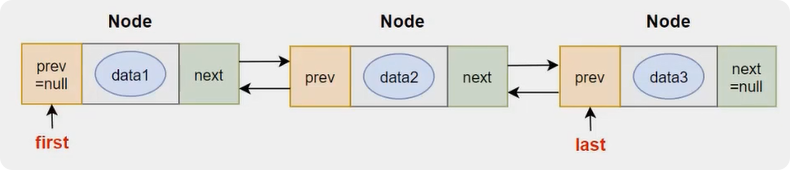
java
class Node{
Node prev;
Object data;
Node next;
public Node(Object data){
this.data = data;
}
public Node(Node prev, Object data, Node next){
this.prev = prev;
this.data = data;
this.next = next;
}
}创建对象:
java
Node node1 = new Node(null, "AA", null);
Node node2 = new Node(node1, "BB", null);
Node node3 = new Node(node2, "CC", null);
node1.next = node2;
node2.next = node3;常见存储结构之:二叉树
方式一:
java
class TreeNode{
TreeNode left;
Object data;
TreeNode right;
public TreeNode(Object data){
this.data = data;
}
public TreeNode(TreeNode left,Object data,TreeNode right){
this.left = left;
this.data = data;
this.right = right;
}
}创建对象:
java
TreeNode node1 = new TreeNode(null,"AA",null);
TreeNode leftNode = new TreeNode(null,"BB",null);
TreeNode rightNode = new TreeNode(null,"CC",null);
node1.left = leftNode;
node1.right = rightNode;方式二:
java
class TreeNode{
TreeNode parent;
TreeNode left;
Object data;
TreeNode right;
public TreeNode(Object data){
this.data = data;
}
public TreeNode(TreeNode left,Object data,TreeNode right){
this.left = left;
this.data = data;
this.right = right;
}
public TreeNode(TreeNode parent,TreeNode left,Object data,TreeNode right){
this.parent = parent;
this.left = left;
this.data = data;
this.right = right;
}
}创建对象:
java
TreeNode node1 = new TreeNode(null,null,"AA",null);
TreeNode leftNode = new TreeNode(node1,null,"BB",null);
TreeNode rightNode = new TreeNode(node1,null,"CC",null);
node1.left = leftNode;
node1.right = rightNode;遍历方式
- **前序遍历**: 中左右(根左右)
即先访问根结点,再前序遍历左子树,最后再前序遍历右子树。前序遍历运算访问二叉树各结点是以根、左、右的顺序进行访问的。
- **中序遍历**: 左中右(左根右)
即先中前序遍历左子树,然后再访问根结点,最后再中序遍历右子树。中序遍历运算访问二叉树各结点是以左、根、右的顺序进行访问的。
- **后序遍历**: 左右中(左右根)
即先后序遍历左子树,然后后序遍历右子树,最后访问根结点。后序遍历运算访问二叉树各结点是以左、右、根的顺序进行访问的。
常见存储结构之, 栈(stack、先进后出、first in Last out、FILO、LIFO)
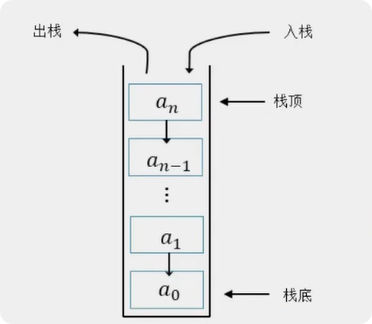
> 属于抽象数据类型(ADT)
> 可以使用数组或链表来构建
java
class Stack{
Object[] values;
int size; //记录存储的元素的个数
public Stack(int length){
values = new Object[length];
}
//入栈
public void push(Object ele){
if(size >= values.length){
throw new RuntimeException("栈空间已满,入栈失败");
}
values[size] = ele;
size++;
}
//出栈
public Object pop(){
if(size <= 0){
throw new RuntimeException("栈空间已空,出栈失败");
}
Object obj = values[size - 1];
values[size - 1] = null;
size--;
return obj;
}
}常见存储结构之:队列(queue、先进先出、first in first out、FIFO)
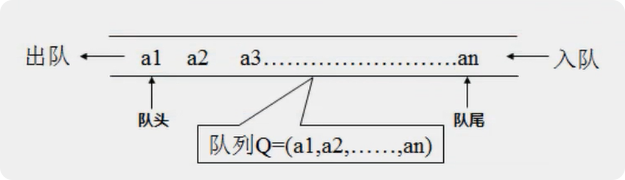
> 属于抽象数据类型(ADT)
> 可以使用数组或链表来构建
java
//数组实现队列
class Queue{
Object[] values;
int size; //记录存储的元素的个数
public Queue(int length){
values = new Object[length];
}
public void add(Object ele){ //添加
if(size >= values.length){
throw new RuntimeException("队列已满,添加失败");
}
values[size] = ele;
size++;
}
public Object get() { //获取
if(size <= 0){
throw new RuntimeException("队列已空,获取失败");
}
Object obj = values[0];
//数据前移
for(int i = 0; i < size - 1; i++) {
values[i] = values[i + 1];
}
//最后一个元素置空
values[size - 1] = null;
size--;
return obj;
}
}List实现类源码分析
ArrayList
ArrayList的特点:
-
实现了List接口,存储有序的,可以重复的数据
-
底层使用Object\[\]数组存储
-
线程不安全的
ArrayList源码解析:
jdk7版本:(以jdk1.7.0_07为例)
首次创建时,会初始化一个长度为10的数组--类似饿汉式
java
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
//如下代码的执行:底层会初始化数组,数组的长度为10。Object[] elementData = new Object[10];
ArrayList<String> list = new ArrayList<>();
list.add("AA"); //elementData[0] = "AA";
list.add("BB"); //elementData[1] = "BB";
}
}当要添加第11个元素的时候,底层的elementData数组已满,则需要扩容。默认扩容为原来长度的1.5倍(oldCapacity + oldCapacity >> 1)。并将原有数组中的元素复制到新的数组中。
jdk8版本:(以jdk1.8.0_271为例)
创建时是赋值一个长度为0的数组--类似懒汉式
每一次添加都会进行判断(在长度为0,时直接赋值10),不够的时候都是增加1.5倍(oldCapacity + oldCapacity >> 1)
java
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
//如下代码的执行:底层会初始化数组,即。Object[] elementData = new Object[]{};
ArrayList<String> list = new ArrayList<>();
//首次添加元素时,会初始化数组elementData = new Object[10];elementData[0] = "AA";
list.add("AA");
list.add("BB"); //elementData[1] = "BB";
}
}Vector
Vector的特点:
-
实现了List接口,存储有序的,可以重复的数据
-
底层使用Object\[\]数组存储
-
线程安全的
Vector源码解析:(以jdk1.8.0_271为例)
java
import java.util.Vector;
public class Main {
public static void main(String[] args) {
Vector v = new Vector(); // 底层初始化数组,长度为10。Object[] elementData = new Object[10];
v.add("AA"); // elementData[0] = "AA";
v.add("BB"); // elementData[1] = "BB";
}
}首次创建时,会初始化一个长度为10的数组当添加第11个元素时,需要扩容。默认扩容为原来的2倍。可以指定扩容多少。(capacityIncrement > 0 ? capacityIncrement : oldCapacity)
LinkedList
LinkedList的特点:
-
实现了List接口,存储有序的,可以重复的数据
-
底层使用双向链表存储(不存在扩容问题)
-
线程不安全的
LinkedList在jdk8中的源码解析:
java
import java.util.LinkedList;
public class Main {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();// 底层也没做啥
list.add("AA"); // 将 "AA" 封装到一个 Node 对象中,list 对象的属性 first、last 都指向此 Node 对象。
list.add("BB"); // 将 "BB" 封装到一个 Node 对象中,对象1和对象2构成一个双向链表,同时 last 指向此 Node 对象。
}
}LinkedList内部声明:
java
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
}启示与开发建议
-
Vector基本不使用。
-
ArrayList底层使用数组结构,
查找和添加(尾部添加)操作效率高,时间复杂度为O(1)
删除和插入操作效率低,时间复杂度为O(n)
LinkedList底层使用双向链表结构,
删除和插入操作效率高,时间复杂度为O(1)
查找和添加(尾部添加)操作效率高,时间复杂度为O(n)(有可能添加操作是O(1))
- 在选择了ArrayList的前提下,
new ArrayList():底层创建长度为10的数组。
new ArrayList(int capacity):底层创建指定capacity长度的数组。
如果开发中,大体确认数组的长度,则推荐使用ArrayList(int capacity)这个构造器,避免了底层的扩容、复制数组操作
Map实现类源码分析
HashMap
HashMap中元素的特点
-
HashMap中的所有的key彼此之间是不可重复的、无序的。所有的key就构成一个Set集合。--->key所在的类要重写hashCode方法。
-
HashMap中的所有的value彼此之间是可重复的、无序的。所有的value就构成一个Collection集合。--->value所在的类要重写equals方法。
-
HashMap中的一个key-value,就构成了一个entry。
-
HashMap中的所有的entry彼此之间是不可重复的、无序的。所有的entry就构成了一个Set集合。
HashMap源码解析
jdk7中创建对象和添加数据过程(以JDK1.7.0_07为例说明):
初始化时数组长度默认为16(可以自定义,但结果是2的幂次倍)
java
// 通过此循环,得到capacity的最终值,此最终值决定了Entry数组的长度。此时的capacity一定是2的整数倍
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;随着不断的添加元素,在满足如下的条件的情况下,会考虑扩容:
(size >= threshold) && (null != tablei)
当元素的个数达到临界值(-> 数组的长度 * 加载因子【默认0.75,可自定义】)时,就考虑扩容。
如默认的临界值 = ( 16 * 0.75 --> 12 )。
默认扩容为原来的2倍。
java
import java.util.HashMap;
public class Main {
public static void main(String[] args) {
//创建对象的过程中,底层会初始化数组Entry[] table = new Entry[16];
HashMap<String, Integer> map = new HashMap<>();
//...
map.put("AA", 78); // "AA"和78封装到一个Entry对象中,考虑将此对象添加到table数组中。
//...
}
}添加/修改的过程:
将(key1, value1)添加到当前的map中:
首先,调用key1所在类的hashCode()方法,计算key1对应的哈希值1。此哈希值1经过某种算法(hash())之后,得到哈希值2。(在hash(key)通过key调用hashCode,然后进行再一次hash)
java
public V put(K key, V value) {
//HashMap允许添加key为null的值。将此(key, value)存放到table索引0的位置。
if (key == null)
return putForNullKey(value);
//将key传入hash(),内部使用了key的哈希值1,此方法执行结束后,返回哈希值2
int hash = hash(key);
//确定当前key,value在数组中的存放位置i
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;//如果put是修改操作,会返回原有的value值。
}
}
modCount++;
// 将key、value封装为一个Entry对象,并将此对象保存在索引i位置。【头插法】
// 将第二次hash值固定保存到Entry内的hash属性内
addEntry(hash, key, value, i);
return null;//如果put是添加操作,会返回null。
}
java
final int hash(Object k) {
int h = 0;
if (useAltHashing) {
if (k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h = hashSeed;
}
h ^= k.hashCode(); // 第一次哈希值参与运算
// 扰动处理(第二次哈希):让高位参与低位运算
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}哈希值2再经过某种算法(indexFor())之后,就确定了(key1, value1)在数组table中的索引位置i。(与【length-1】相与,同1为1)
java
static int indexFor(int h, int length) {
return h & (length-1);
}注:HashMap允许添加key为null的值。将此(key,value)存放到table索引0的位置。
1.1 如果此索引位置i的数组上没有元素,则(key1, value1)添加成功。 --->情况1
1.2 如果此索引位置i的数组上有元素(key2, value2),则需要继续比较key1和key2的哈希值2。--->哈希冲突
2.1 如果key1的哈希值2与key2的哈希值2不相同,则(key1, value1)添加成功,头插法。 --->情况2
2.2 如果key1的哈希值2与key2的哈希值2相同,则需要继续比较key1和key2的equals()。要调用key1所在类的equals(),将key2作为参数传递进去。
3.1 调用equals(),返回false:则(key1, value1)添加成功,头插法。 --->情况3
3.2 调用equals(),返回true:则认为key1和key2是相同的。默认情况下,value1替换原有的value2。
说明:情况1:将(key1,value1)存放到数组的索引i的位置
情况2,情况3:(key1,value1)元素与现有的(key2,value2)构成单向链表结构,(key1,value1)指向(key2,value2)
jdk8与jdk7的不同之处(以jdk1.8.0_271为例):
① 在 jdk8中,当我们创建了 HashMap 实例以后,底层并没有初始化 table 数组。当首次添加 (key, value) 时,进行判断如果发现 table 尚未初始化,则对数组进行初始化。
② 在 jdk8中,HashMap 底层定义了 Node 内部类,替换 jdk7中的 Entry 内部类。意味着,我们创建的数组是 Node\[\]
③ 在 jdk8中,如果当前的 (key, value) 经过一系列判断之后,可以添加到当前的数组角标 i 中。如果此时角标 i 位置上有元素。在 jdk7 中是将新的 (key, value) 指向已有的旧的元素(头插法),而在 jdk8 中是旧的元素指向新的 (key, value) 元素(尾插法)。"七上八下"
④ jdk7: 数组+单向链表
jk8: 数组+单向链表 + 红黑树
单向链表变为红黑树:如果数组索引i位置上的元素的个数达到8,并且数组的长度达到64时,我们就将此索引i位置上的多个元素改为使用红黑树的结构进行存储。(为什么修改呢?红黑树进行(put()/get()/remove())操作的时间复杂度为O(log n),比单向链表的时间复杂度O(n)的好。性能更高。
红黑树变为单向链表:当使用红黑树的索引i位置上的元素的个数低于6的时候,就会将红黑树结构退化为单向链表。
注:不管是树化还是退化都局限于该索引下的链表
属性/字段
java
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认的初始容量 16
static final int MAXIMUM_CAPACITY = 1 << 30; // 最大容量 1 << 30
static final float DEFAULT_LOAD_FACTOR = 0.75f; // 默认加载因子
static final int TREEIFY_THRESHOLD = 8; // 默认树化阈值8,当链表的长度达到这个值后,要考虑树化
static final int UNTREEIFY_THRESHOLD = 6; // 默认反树化阈值6,当树中结点的个数达到此阈值后,要考虑变为链表
// 当单个链表的结点个数达到8,并且table的长度达到64,才会树化。
// 当单个链表的结点个数达到8,但是table的长度未达到64,会先扩容
static final int MIN_TREEIFY_CAPACITY = 64; // 最小树化容量64
transient Node<K,V>[] table; // 数组
transient int size; // 记录有效映射关系的对数,也是Entry对象的个数
int threshold; // 阈值,当size达到阈值时,考虑扩容
final float loadFactor; // 加载因子,影响扩容的频率LinkedHashMap
LinkedHashMap 与 HashMap 的关系:
> LinkedHashMap 是 HashMap的子类。
> LinkedHashMap在HashMap使用的数组+单向链表+红黑树的基础上,又增加了一对双向链表,记录添加的(key, value)的先后顺序。便于我们遍历所有的key-value。
LinkedHashMap重写了HashMap的如下方法:
java
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}底层结构:
LinkedHashMap内部定义了一个Entry
java
static class Entry<K,V> extends HashMap<Node<K,V>, Integer> {
Entry<K,V> before, after; //增加的一对双向链表
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}注: HashSet底层使用的是HashMap;LinkedHashSet底层使用的是LinkedHashMap