第12章Streaming(下):视频应用(1)------项目八:基于WebRTC+YOLO的实时目标检测
- [第12章 Streaming(下):视频应用](#第12章 Streaming(下):视频应用)
-
- [12.1 YOLOv10:优化后处理和模型架构](#12.1 YOLOv10:优化后处理和模型架构)
-
- [12.1.1 模型技术特点、性能与子模型比较](#12.1.1 模型技术特点、性能与子模型比较)
- [12.1.2 安装、运行Demo与操作模型](#12.1.2 安装、运行Demo与操作模型)
- [12.2 项目八:基于WebRTC+YOLO的实时目标检测](#12.2 项目八:基于WebRTC+YOLO的实时目标检测)
-
- [12.2.1 加载模型、检测并绘制目标对象](#12.2.1 加载模型、检测并绘制目标对象)
- [12.2.2 WebRTC组件及Gradio界面](#12.2.2 WebRTC组件及Gradio界面)
第12章 Streaming(下):视频应用
本章讲述流式传输的视频应用,主要包括三个示例:基于WebRTC+YOLO的实时目标检测、使用RT-DETR模型构建视频流目标检测系统、使用FastRTC+Gemini创建实时沉浸式音频+视频的艺术评论家,使用三个不同的模型,由浅入深实现视频目标检测、视频流传输、音频+视频结合应用。此外,本章用到的其他技术讲解包括:YOLO系列视频检测模型,实时端到端检测模型RT-DETR,多模态模型Gemini简介及入门实战,以及为结合音视频的Gemini Live API实时连接。由于视频开发本身难度斐然,故本章对各类技术和大模型做了详细的介绍,并对复杂代码加入了大量详细解读。通过Streaming章节的学习,读者可以掌握音频+视频的自动检测、定制回复和实时传输等高端功能的开发,让读者步入复杂的多模态应用开发的门槛。
12.1 YOLOv10:优化后处理和模型架构
近年来,YOLO系列因其在计算成本与检测性能之间的有效平衡,已成为实时目标检测领域的主导技术。本节首先介绍YOLOv10模型的技术特点,然后介绍性能优势及子模型区别,最后进行实战,包括安装与运行Demo,下载模型并验证、训练和预测。
12.1.1 模型技术特点、性能与子模型比较
近年来,YOLO系列因其在计算成本与检测性能之间的有效平衡,已成为实时目标检测领域的主导技术。研究者们针对YOLO的架构设计、优化目标、数据增强策略等方面进行了深入探索,取得了显著进展。然而,依赖非极大值抑制(NMS)的后处理方式阻碍了YOLO的端到端部署,并对推理延迟产生负面影响。此外,YOLO各组件设计缺乏全面深入的考量,导致明显的计算冗余并限制了模型能力,使得其效率欠佳而存在较大性能提升空间。在2024年3月提出的YOLOv10中,旨在从后处理和模型架构两方面共同推进YOLO系列的性能-效率边界,其主要改进有两个方面:
- YOLOv10首先提出用于避免NMS训练的一致性双重分配策略,在保持高性能同时显著降低推理延迟。
- 其次,引入面向YOLO效率-精度的全方位驱动模型的设计策略,从效率与精度两个维度系统优化YOLO的各个组件,大幅降低计算开销并提升模型性能。
这些技术共同构建了新一代实时端到端目标检测YOLO系列------YOLOv10,请参阅《YOLOv10: Real-Time End-to-End Object Detection》🖇️链接12-1。
实验表明,YOLOv10在不同规模下均实现了近乎最优的性能与效率表现,例如:
- 在COCO数据集的相似指标AP(Accurate Performance,精准度)下,YOLOv10-S比RT-DETR-R18快1.8倍,且参数量减小2.8倍。
- 与YOLOv9-C相比,YOLOv10-B在同等性能下延迟降低46%,参数量减少25%。
图12-1展示了YOLOv10与其他模型在延迟-精度(左图)和参数量-精度(右图)权衡方面进行比较的结果:
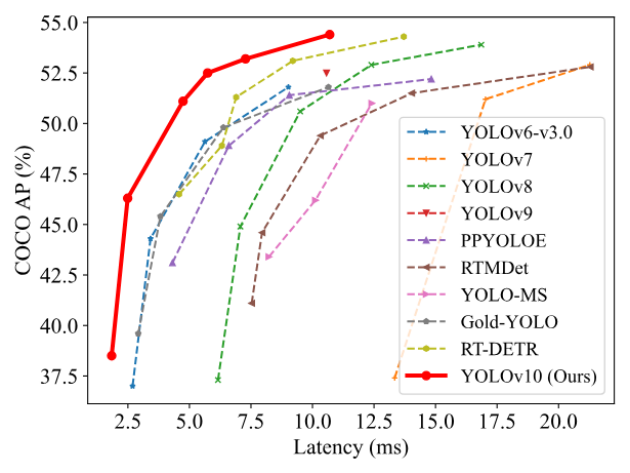
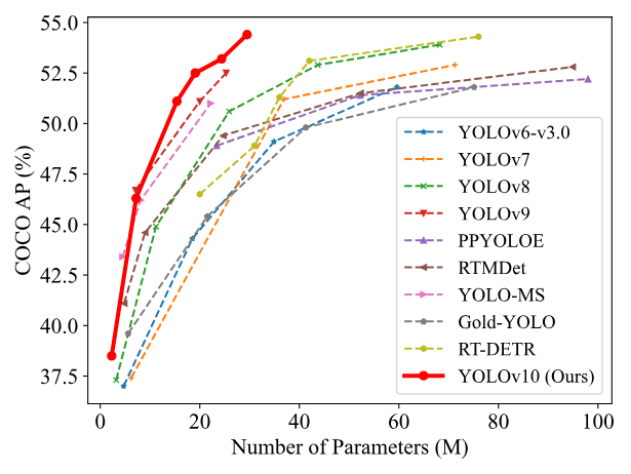
图12-1
以COCO数据集为例,YOLOv10系列子模型的测试图片大小、参数量、浮点操作数(FLOP)、精度值及延迟等的比较如表12-1所示:
表12-1
| 模型 | 图片大小 | 参数量 | 浮点操作数 | 精度值 | 延迟 |
|---|---|---|---|---|---|
| YOLOv10-N | 640 | 2.3M | 6.7G | 38.5% | 1.84ms |
| YOLOv10-S | 640 | 7.2M | 21.6G | 46.3% | 2.49ms |
| YOLOv10-M | 640 | 15.4M | 59.1G | 51.1% | 4.74ms |
| YOLOv10-B | 640 | 19.1M | 92.0G | 52.5% | 5.74ms |
| YOLOv10-L | 640 | 24.4M | 120.3G | 53.2% | 7.28ms |
| YOLOv10-X | 640 | 29.5M | 160.4G | 54.4% | 10.70ms |
12.1.2 安装、运行Demo与操作模型
下面进行实操。首先下载Git代码库,然后运行示例,建议使用Coda环境:
bash
conda create -n yolov10 python=3.9
conda activate yolov10
pip install -r requirements.txt
pip install -e .
# start demo
python app.py使用模型的演示代码中,同样使用了Gradio库构建页面,感兴趣的读者可阅读源码,这里只讲解app.py的核心逻辑------推理函数,如代码12-1所示:
代码12-1
py
from ultralytics import YOLOv10
import tempfile
import cv2
def yolov10_inference(image, video, model_id, image_size, conf_threshold):
model = YOLOv10.from_pretrained(f'jameslahm/{model_id}')
if image:
results = model.predict(source=image, imgsz=image_size, conf=conf_threshold)
annotated_image = results[0].plot()
return annotated_image[:, :, ::-1], None
else:
video_path = tempfile.mktemp(suffix=".webm")
with open(video_path, "wb") as f:
with open(video, "rb") as g:
f.write(g.read())
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
output_video_path = tempfile.mktemp(suffix=".webm")
out = cv2.VideoWriter(output_video_path, cv2.VideoWriter_fourcc(*'vp80'), fps, (frame_width, frame_height))
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
results = model.predict(source=frame, imgsz=image_size, conf=conf_threshold)
annotated_frame = results[0].plot()
out.write(annotated_frame)
cap.release()
out.release()
return None, output_video_path函数yolov10_inference用于对图像或视频执行YOLOv10目标检测,并返回标注后的结果。下面逐行解析其功能和逻辑:
- 首先上传图像或视频文件、模型ID、图片大小和阈值,然后使用HuggingFace的from_pretrained方法加载预训练的指定模型ID的YOLOv10模型。
- 如果是图片,处理步骤如下:model.predict()对输入图像执行推理;results0.plot()将检测到的目标框、标签等绘制在图像上,返回BGR格式的numpy数组;annotated_image:, :, ::-1将BGR转换为RGB,因为Gradio等前端通常使用RGB。
- 如果是视频,处理步骤如下所述:①tempfile.mktemp生成一个临时文件路径,后缀为.webm,然后将传入的视频写入临时文件,以便OpenCV可以读取。②使用OpenCV打开视频文件,获取帧率、宽度、高度。创建输出视频文件,使用VP8编码,帧率和尺寸与输入视频保持一致。③使用While循环逐帧读取视频,对每一帧执行YOLOv10推理,绘制检测结果,将标注后的帧写入输出视频文件。最后释放资源,返回符合函数设计的格式。
其它代码请参照源码,运行界面如图12-2所示:
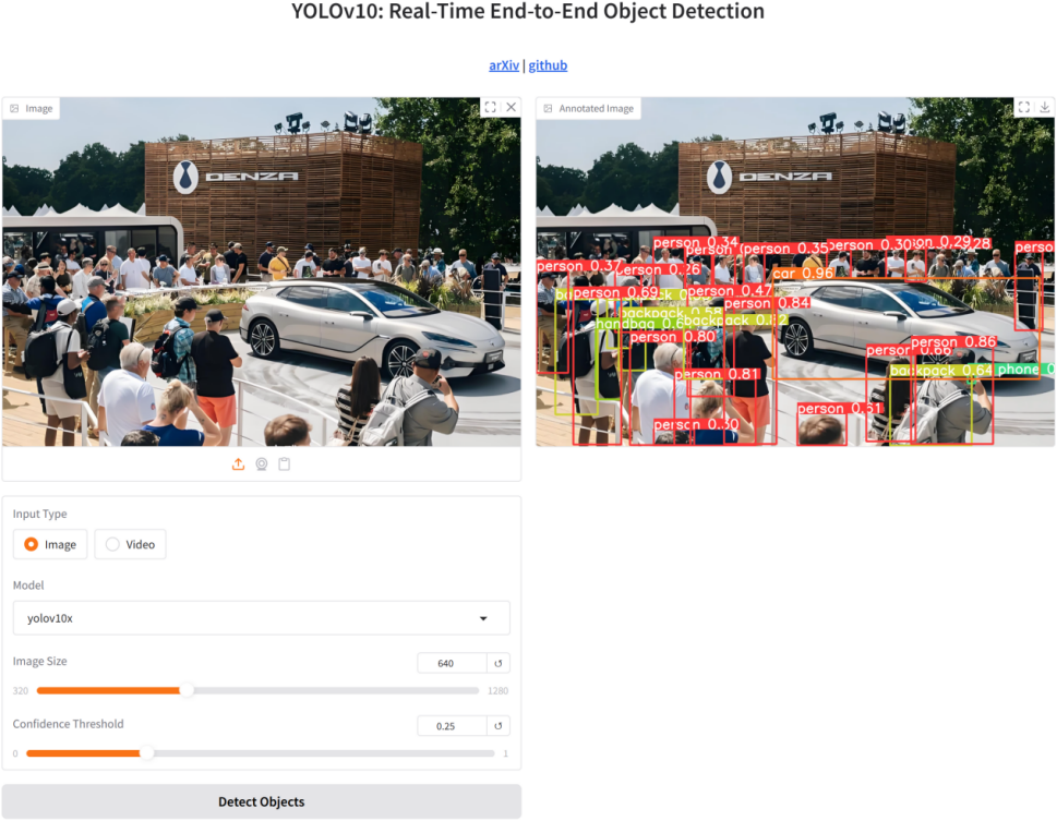
图12-2
加载模型并验证、训练、预测和推送hub。安装完成后,还可使用模型验证、训练、预测和推送hub,如代码12-2所示:
代码12-2
py
from ultralytics import YOLOv10
model = YOLOv10.from_pretrained('jameslahm/yolov10{n/s/m/b/l/x}')
# or download from github
# wget https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10{n/s/m/b/l/x}.pt
# model = YOLOv10('yolov10{n/s/m/b/l/x}.pt')
# Validation, Training and Prediction
model.val(data='coco.yaml', batch=256)
model.train(data='coco.yaml', epochs=500, batch=256, imgsz=640)
source = 'http://images.cocodataset.org/val2017/000000039769.jpg'
model.predict(source=source, save=True)
# after training, one can push to the hub
model.push_to_hub("your-hf-username/yolov10-finetuned")YOLO系列的最新进展是YOLOE(念作"耶"):实时全场景视觉系统,一种高效、统一且开放的目标检测与分割模型,它能够像人眼一样实时感知任何物体。该模型支持多种提示机制(包括文本提示、视觉输入提示以及无提示范式),且完全开源,与封闭集YOLO模型相比,它在推理和迁移过程中实现了零额外开销。YOLO全系列模型的详细介绍请参考:Ultralytics YOLO文档🖇️链接12-2。
12.2 项目八:基于WebRTC+YOLO的实时目标检测
本节将使用OpenCV读取图像,使用YOLO系列模型进行推理识别,并使用fastrtc 库的自定义WebRTC组件来传输数据,达到近乎零延迟。首先安装项目中的依赖项文件requirements.txt:pip install -r requirements.txt。使用YOLOv10系列模型推理时,将利用ONNX运行时环境来加速推理。默认GPU可用,当然需要提前安装NVIDIA的CUDA Toolkit和cuDNN库。如果没有GPU,请将requirements.txt中的onnxruntime-gpu更改为onnxruntime。没有GPU的情况下,模型运行较慢,可能导致演示出现延迟。
另外,将应用部署在外部云服务器时,还可以采用Twilio的TURN服务器以便数据穿透NAT防火墙进行传输。本项目可在线上或Spaces中查看:freddyaboulton/webrtc-yolov10n(🖇️链接12-3)。
12.2.1 加载模型、检测并绘制目标对象
加载模型。从Hub下载YOLO模型,并在自定义推理类中使用。本例选择使用yolov10-n变体,因为它具有最低的延迟特性。也可以选择最新的yoloe,但由于ONNX没有针对其优化,所以需要修改YOLO类中的推理代码。加载模型代码12-3所示:
代码12-3
py
# app.py
from huggingface_hub import hf_hub_download
from inference import YOLO
# yolov10
model_path = hf_hub_download(repo_id="onnx-community/yolov10n", filename="onnx/model.onnx")
model = YOLO(model_path)在选择不同模型时,根据存储库ID和文件名下载得到模型文件路径,然后根据路径初始化YOLO模型。加载完模型后,使用模型检测图像及并绘制画框。
检测目标对象的代码解读。检测函数通常由Stream对象触发,如代码12-4所示:
代码12-4
py
# app.py
def detection(image, conf_threshold=0.3):
image = cv2.resize(image, (model.input_width, model.input_height))
new_image = model.detect_objects(image, conf_threshold)
return cv2.resize(new_image, (500, 500))在函数detection中调用YOLO类的检测函数detect_objects。它接受来自网络摄像头的numpy数组形式的图像和一个期望的置信度阈值,像YOLO这样的目标检测模型会识别多个目标,并为每个目标分配一个置信度分数。置信度越低,出现误检的可能性越高,因此允许用户根据自身需要调整置信度阈值。该函数返回一个numpy数组,对应于输入图像,并在所有检测到的目标上绘制了边界框。
YOLO类及其检测函数detect_objects的实现细节代码12-5所示:
代码12-5
py
# inference.py
import time
import cv2
import numpy as np
import onnxruntime # ONNX模型推理引擎
from utils import draw_detections
class YOLOv10:
def __init__(self, path):
self.initialize_model(path)
def initialize_model(self, path):
self.session = onnxruntime.InferenceSession(
path, providers=onnxruntime.get_available_providers())
def __call__(self, image):
return self.detect_objects(image)
def detect_objects(self, image, conf_threshold=0.3):
input_tensor = self.prepare_input(image)
# Perform inference on the image
new_image = self.inference(image, input_tensor, conf_threshold)
return new_image
def prepare_input(self, image):
self.img_height, self.img_width = image.shape[:2]
input_img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Resize input image
input_img = cv2.resize(input_img, (self.input_width, self.input_height))
# Scale input pixel values to 0 to 1
input_img = input_img / 255.0
input_img = input_img.transpose(2, 0, 1)
input_tensor = input_img[np.newaxis, :, :, :].astype(np.float32)
return input_tensor
def inference(self, image, input_tensor, conf_threshold=0.3):
start = time.perf_counter()
outputs = self.session.run(self.output_names, {self.input_names[0]: input_tensor})
print(f"Inference time: {(time.perf_counter() - start)*1000:.2f} ms")
boxes, scores, class_ids, = self.process_output(outputs, conf_threshold)
return self.draw_detections(image, boxes, scores, class_ids)
def draw_detections(self, image, boxes, scores, class_ids, draw_scores=True, mask_alpha=0.4):
return draw_detections(image, boxes, scores, class_ids, mask_alpha)
def process_output(self, output, conf_threshold=0.3):
predictions = np.squeeze(output[0])
scores = predictions[:, 4]
predictions = predictions[scores > conf_threshold, :]
scores = scores[scores > conf_threshold]
if len(scores) == 0:
return [], [], []
class_ids = predictions[:, 5].astype(int)
boxes = self.extract_boxes(predictions)
return boxes, scores, class_ids代码创建核心类YOLO,实现完整的YOLOv10 ONNX 推理,解读如下:
- 模型初始化:构造函数接收模型文件路径,调用initialize_model初始化模型,它创建onnxruntime.InferenceSession(),providers自动选择可用的加速器(CPU/CUDA/TensorRT等)。call函数使类的实例可以像函数一样调用,例如:yolo = YOLOv10('model.onnx'); result = yolo(image)。
- 主检测流程:将摄像头输入的图像预处理为输入张量input_tensor,然后调用推理函数进行处理,最后返回带检测结果的新图像。
- 图像预处理:依次进行保存原图尺寸、转换颜色空间(BGR -> RGBYOLO模型通常用RGB训练)、调整尺寸到模型输入大小(如640x640)、归一化(0-255 -> 0-1)、调整维度顺序(HWC -> CHW,模型要求的格式)、添加batch维度(CHW -> 1,CHW),最后返回预处理图像。
- 推理过程:首先根据物体名称和输入张量开始ONNX Runtime 推理并计时;然后将检测结果输入process_output进行处理,得到物体的画框、分数及class_id;最后将原图像检测结果输入绘制函数draw_detections进行绘制。
- 处理输出:首先移除batch维度,得到num_predictions, 6,并提取置信度分数(第4列);然后筛选置信度大于阈值的检测结果,获取合格分数和类别ID(第5列);最后提取边界框坐标。
绘制目标对象的代码解读。在检测代码中,使用utils中的函数draw_detections,将检测到的画框、标签及分数绘制到原图像中,其实现细节如代码12-6所示:
代码12-6
py
utils.py
import numpy as np
rng = np.random.default_rng(3)
colors = rng.uniform(0, 255, size=(len(class_names), 3))
def draw_detections(image, boxes, scores, class_ids, mask_alpha=0.3):
det_img = image.copy()
img_height, img_width = image.shape[:2]
font_size = min([img_height, img_width]) * 0.0006
text_thickness = int(min([img_height, img_width]) * 0.001)
# Draw bounding boxes and labels of detections
for class_id, box, score in zip(class_ids, boxes, scores):
color = colors[class_id]
draw_box(det_img, box, color)
label = class_names[class_id]
caption = f"{label} {int(score * 100)}%"
draw_text(det_img, caption, box, color, font_size, text_thickness)
return det_img
def draw_box(image: np.ndarray, box: np.ndarray, thickness: int = 2,
color: tuple[int, int, int] = (0, 0, 255)) -> np.ndarray:
x1, y1, x2, y2 = box.astype(int)
return cv2.rectangle(image, (x1, y1), (x2, y2), color, thickness)
def draw_text(image: np.ndarray, text: str, box: np.ndarray,
font_size: float = 0.001, text_thickness: int = 2,
color: tuple[int, int, int] = (0, 0, 255), ) -> np.ndarray:
x1, y1, x2, y2 = box.astype(int)
(tw, th), _ = cv2.getTextSize(text=text, fontScale=font_size,
fontFace=cv2.FONT_HERSHEY_SIMPLEX, thickness=text_thickness)
th = int(th * 1.2)
cv2.rectangle(image, (x1, y1), (x1 + tw, y1 - th), color, -1)
return cv2.putText(image, text, (x1, y1), cv2.FONT_HERSHEY_SIMPLEX,
font_size, (255, 255, 255), text_thickness, cv2.LINE_AA)代码是可视化工具模块,用于在图像上绘制检测框和标签,解析如下:
- 生成随机颜色:首先default_rng创建随机数生成器,种子为3,保证每次运行颜色相同;然后由rng.uniform()生成类别数, 3 的随机颜色数组,每个颜色是RGB三通道值,范围0-255,class_names是预先定义的可检测物体列表。
- 主绘制函数:首先复制图像,避免修改原图,并获取图像尺寸;然后动态计算字体大小和线条粗细(根据图像尺寸自适应);最后遍历所有检测结果,依次获取该类别的颜色、绘制边界框、标注标题(格式:类别+置信度)、绘制文本标签。
- 绘制边界框:根据左上角坐标、右下角坐标、RGB颜色和线条粗细(默认2像素),使用cv2.rectangle绘制矩形框。
- 绘制文本标签:首先获取文本的实际宽度和高度,并增加一点高度作为内边距;然后绘制背景框,左上角坐标向左向上拉伸,-1表示填充矩形(实心);最后使用cv2.putText绘制cv2.FONT_HERSHEY_SIMPLEX字体的白色文本,cv2.LINE_AA是抗锯齿,使文字更平滑。
12.2.2 WebRTC组件及Gradio界面
要构建独立的Gradio应用,可以使用WebRTC组件并实现stream事件。与Stream对象类似,你需要设置mode和modality参数,并传入一个处理器。在stream事件中,除了传入处理器,还需指定输入和输出组件。
本小节将结合fastrtc.WebRTC组件,由gr.Blocks实现界面,并展示运行效果。Gradio界面构建如代码12-7所示:
代码12-7
py
# app.py
import gradio as gr
from fastrtc import WebRTC
from twilio.rest import Client
import os
account_sid = os.environ.get("TWILIO_ACCOUNT_SID")
auth_token = os.environ.get("TWILIO_AUTH_TOKEN")
if account_sid and auth_token:
client = Client(account_sid, auth_token)
token = client.tokens.create()
rtc_configuration = {"iceServers": token.ice_servers,
"iceTransportPolicy": "relay"}
else:
rtc_configuration = None
with gr.Blocks(css=css) as demo:
with gr.Column(elem_classes=["my-column"]):
with gr.Group(elem_classes=["my-group"]):
image = WebRTC(label="Stream", rtc_configuration=rtc_configuration)
conf_threshold = gr.Slider(label="Confidence Threshold",
minimum=0.0, maximum=1.0, step=0.05, value=0.30)
image.stream(fn=detection, inputs=[image, conf_threshold],
outputs=[image], time_limit=10)
if __name__ == "__main__":
demo.launch(css=css)Gradio演示很简单,但可以实现以下几个特定功能:
(1)如果获得Twilio账户SID和认证令牌,则设置rtc_configuration,以便应用在有防火墙的环境中时,可以通过TURN与ICE穿透防火墙传输数据。
(2)使用WebRTC自定义组件,通过WebRTC确保将输入发送到服务器,并从服务器接受其输出。WebRTC组件将同时作为输入和输出组件。
(3)利用Stream对象的预处理函数设置检测功能;参数time_limit为每个用户的流设置处理时间。在类似Spaces的多用户环境中,处理程序将在规定时间段后停止处理当前用户的流,并转向下一个用户。
示例还会应用自定义CSS,使页面上的网络摄像头组件WebRTC和滑块Slider居中显示,限于篇幅,请参考线上源码。安装onnxruntime-gpu之前,需安装cuDNN和CUDA,不支持独立显卡的用户可安装onnxruntime。最终效果如图12-3所示:
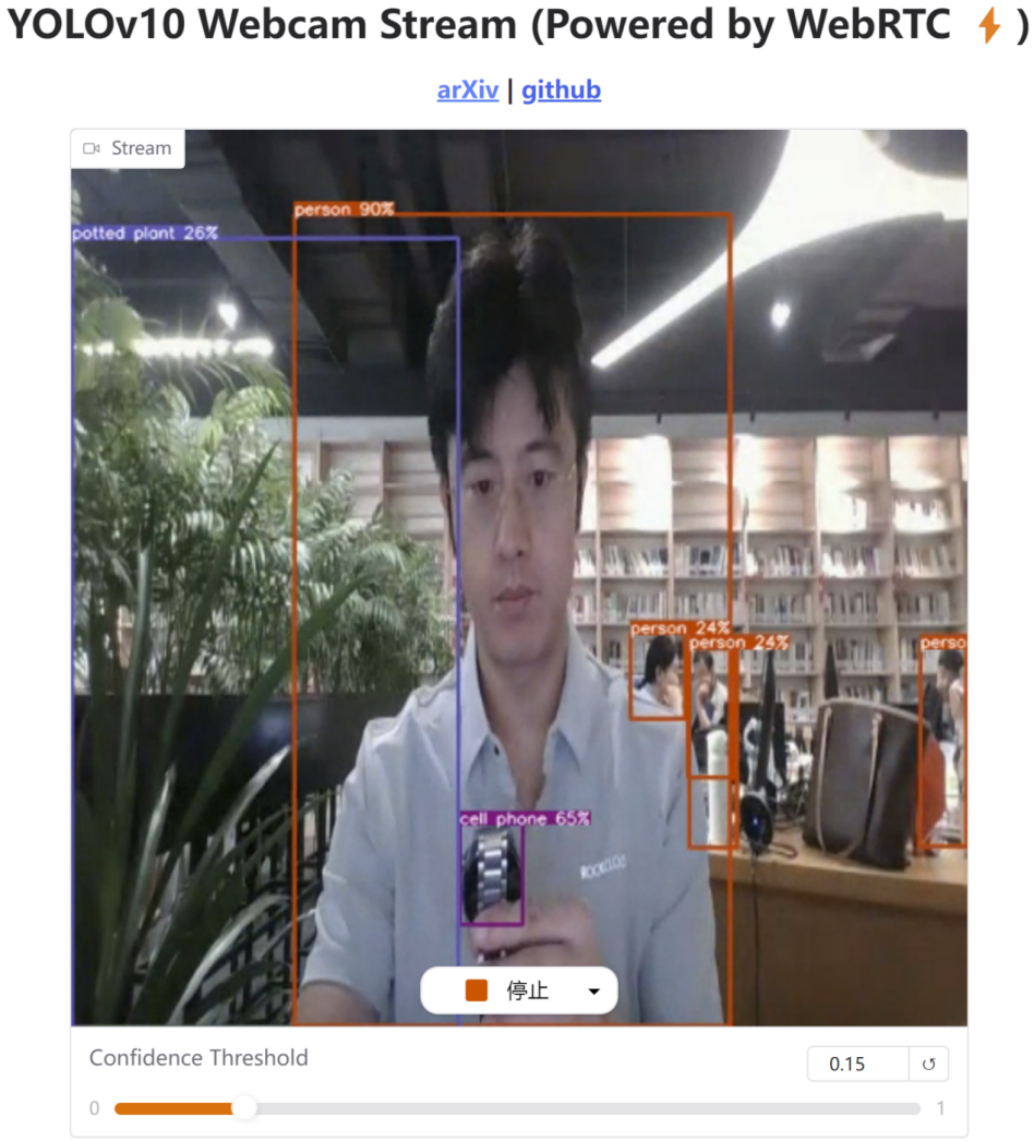
图12-3
版本更新用fastrtc.WebRTC代替gradio_webrtc,由于兼容性问题可能无法加载视频,可回退Gradio版本到5.49.1。此应用的Spaces受同时在线用户数影响,偶尔会触发并发错误,可使用FastRTC官网的目标检测:fastrtc/object-detection🖇️链接12-4,两者核心代码非常类似,只在前端代码有区别,读者可体验检测效果并查看代码细节,可以将它们作为开发实时图像应用的起点。