一、核心基础
1. 大模型请求超时控制
1.1 核心定义
大模型超时控制,是部署在客户端、应用服务层、网关层、模型推理服务层的多层级资源管控机制。指系统为单次大模型推理请求、会话连接、流式数据分片传输设定最大允许运行时长,当任务执行时长超出预设阈值时,系统主动触发强制中断逻辑,销毁当前请求链路、释放占用的网络连接、CPU线程、内存显存、推理队列等软硬件资源,杜绝请求无限阻塞、资源长期占用的问题。

1.2 模型推理的独有特性
1.2.1 算力负载差异显著
- 普通互联网业务接口多为数据库查询、逻辑计算、数据转发等轻量任务,响应耗时普遍维持在毫秒至百毫秒级别;
- 而大模型推理属于典型的GPU密集型、计算密集型任务,包含Tokenizer分词、上下文编码、注意力机制计算、逐Token解码等复杂运算,单次基础问答请求耗时可达数秒,长文本生成、万字文档总结、多轮超长对话场景下,推理耗时会突破数十秒甚至分钟级。
1.2.2 任务耗时高度不可控
- 大模型推理时长受输入Token数量、输出生成长度、模型参数量、GPU硬件性能、集群算力负载、后台任务调度策略、并发请求挤压等多重变量影响;
- 同一类请求在不同时段、不同负载环境下,耗时波动差距可达数倍,固定化的管控策略完全无法适配。
1.2.3 业务形态多元化
- 大模型分为同步一次性返回的非流式输出、逐字逐段实时推送的流式输出两大主流形态,两种形态的运行逻辑、数据传输方式、异常触发场景完全不同;
- 需要针对性设计超时规则,不能统一套用标准逻辑。
1.2.4 集群服务波动常态化
- 商业化大模型服务、私有化部署推理集群,会存在算力动态扩容、节点上下线、负载均衡调度、硬件降频节能等运维操作,会周期性出现瞬时服务延迟升高、响应卡顿的情况,无超时防护会直接引发连锁故障。
1.3 超时控制的核心作用
1.3.1 实现资源隔离与快速回收
- 无效阻塞的大模型请求会持续占用线程池、网络端口、GPU显存等核心资源,大量堆积后会耗尽服务资源池。
- 超时机制可以精准识别僵死、卡顿、卡死的请求,及时释放资源,保障正常业务请求的资源配额,避免单点故障扩散至全服务。
1.3.2 优化终端用户交互体验
- 用户无法感知后台推理运算的复杂程度,无限等待会直接造成使用体验下滑。
- 合理的超时控制可以在请求超时后,及时返回标准化提示、降级方案或主动触发重试,避免页面长时间加载卡死、无响应空白等问题。
1.3.3 构建服务故障隔离屏障
- 单条慢请求、卡死请求不会占用全局调度资源,防止个别异常请求拖垮整体服务吞吐量、接口响应速度,保障服务整体运行水位稳定,实现故障单点隔离。
1.3.4 约束长耗时任务占比
- 通过超时阈值限制超长耗时任务的运行上限,避免批量长文本生成、大规模知识库问答等重型任务无限制占用算力,平衡整体集群负载,保障多业务线、多用户场景下的服务吞吐能力。
1.3.5 降低运维与故障排查成本
- 超时触发会自动生成日志、链路追踪记录、异常告警,快速定位慢请求、卡死请求的发生节点,帮助研发人员快速识别推理性能瓶颈、节点故障、网络链路问题。
2. 大模型异常重试机制
2.1 核心定义
大模型异常重试,是服务容错体系中的核心自愈能力。特指当大模型请求因临时性、瞬时性、可恢复性故障出现执行失败、连接中断、响应异常、数据缺失时,系统按照预设的次数限制、时间间隔、请求规则,自动重新发起推理调用的机制。重试机制的核心设计理念为只修复临时故障,不掩盖业务错误,严格区分故障类型,拒绝无差别暴力重试。
2.2 重试异常精细化划分
2.2.1 可重试异常
- 可重试异常的核心判断条件是瞬时故障,具备自愈条件:
2.2.1.1 网络链路类异常
- 跨机房网络抖动、局域网端口波动、DNS 解析临时失败、TCP 连接断开、SSL 握手超时、代理服务临时中断等网络层问题。
2.2.1.2 服务端临时过载异常
- 大模型推理集群CPU/GPU负载爆满、接口限流触发、队列排队拥堵、节点负载过高导致响应延迟、服务临时熔断降级、502网关错误、503服务不可用、504网关超时等服务端状态码异常。
2.2.1.3 大模型推理专属异常
- 流式输出中途分片传输中断、推理节点动态切换导致任务暂停、后台算力调度引发瞬时卡顿、显存临时释放冲突造成推理暂停。
2.2.1.4 第三方依赖异常
- 向量数据库、缓存中间件、鉴权服务等周边组件瞬时故障,间接导致大模型请求执行失败。
2.2.2 不可重试异常
- 不可重试异常的核心判断条件是永久故障,重试无意义
2.2.2.1 业务参数类错误
- 请求参数格式错误、Prompt内容违规、输入文本超出模型最大上下文长度、指定模型名称不存在、参数缺失或类型不匹配等400系列错误。
2.2.2.2 权限与鉴权类错误
- API密钥失效、访问权限不足、IP白名单限制、账号额度耗尽、付费服务欠费停机、令牌过期等401、403权限异常。
2.2.2.3 业务逻辑类限制
- 内容安全审核拦截、敏感内容屏蔽、接口调用频次硬限制、单用户并发配额超限等业务规则限制。
2.2.2.4 底层致命故障
- 推理服务彻底宕机、集群整体下线、硬件硬件损坏、核心存储故障等不可逆的服务中断问题。
2.3 异常重试的核心价值
2.3.1 显著提升请求整体成功率
- 大模型服务瞬时波动属于常态化现象,单纯依靠人工刷新、手动重试成本极高。
- 自动化重试可以自动抹平网络抖动、服务过载、节点调度等临时问题,大幅降低业务失败率。
2.3.2 减少业务数据与任务损耗
- 对话会话、内容创作、文档解析、智能摘要等业务场景中,单次请求失败会导致任务中断、内容丢失。
- 重试机制可以自动恢复任务执行,避免重复编辑、重复提问等额外操作。
2.3.3 适配大模型服务运行特性
- 公有云大模型厂商、私有化推理集群普遍存在算力弹性调度机制,高峰期负载波动明显;
- 智能重试策略可以完美适配这类不稳定的运行环境,弱化底层架构波动带来的业务影响。
2.3.4 降低人工运维介入频率
- 依靠技术机制实现故障自愈,减少夜间、低峰期人工值守排查故障的频次,提升服务自动化运维水平。
2.4 超时控制与异常重试的协同关系
2.4.1 无超时约束的重试机制存在致命缺陷
- 如果没有超时时间限制,异常请求会长期阻塞线程,叠加无限次重试逻辑后,会持续新建请求连接、占用算力资源,短时间内就会引发线程耗尽、连接打爆、集群负载飙升,直接诱发服务雪崩,属于生产环境绝对禁止的设计方案。
2.4.2 无重试能力的超时机制存在体验短板
- 单纯的超时控制只能做到被动止损,请求一旦超时直接判定失败,无法修复网络抖动、服务瞬时过载等临时问题。大量可自愈的轻微故障会直接转化为用户侧业务失败,大幅降低服务可用性与使用体验。
2.4.3 二者深度结合才是应用标准架构
- 超时控制作为前置熔断止损手段,负责及时终止无效请求、回收资源;
- 异常重试作为后置自愈修复手段,针对超时、网络、服务过载等可恢复故障自动补救。
分级超时定义单请求最大存活周期,重试策略限制重试次数与间隔,双重约束互相制衡,既不会放任故障扩散,也不会过度限制业务容错能力,共同构建稳定可靠的大模型调用链路。
2.5 示例:超时 + 次数限制重试
python
import requests
import time
# 全局基础配置
# 单次请求最大超时时间,适配常规短文本大模型请求
BASE_SINGLE_TIMEOUT = 10
# 最大重试次数,避免无限重试
MAX_RETRY_TIMES = 3
# 基础重试间隔,无退避策略,适用于入门演示
BASIC_RETRY_SLEEP = 1
def base_llm_chat_request(prompt: str):
"""
基础版大模型请求函数
能力:固定超时控制 + 简单次数重试 + 异常分类捕获
"""
# 模拟本地大模型推理服务接口
request_url = "http://192.168.3.61:8000/v1/chat/completions"
request_payload = {
"messages": [{"role": "user", "content": prompt}],
"temperature": 0.7
}
# 循环执行重试逻辑
for retry_count in range(MAX_RETRY_TIMES):
try:
# 核心:强制设置请求超时时间
response = requests.post(
url=request_url,
json=request_payload,
timeout=BASE_SINGLE_TIMEOUT
)
# 主动抛出HTTP状态码异常
response.raise_for_status()
# 请求正常返回,格式化结果
return {
"code": 200,
"message": "请求执行成功",
"data": response.json(),
"retry_used": retry_count
}
# 捕获请求超时专属异常
except requests.exceptions.Timeout:
print(f"【异常提醒】第{retry_count + 1}次请求触发全局超时,即将进入重试流程")
# 捕获网络连接异常
except requests.exceptions.ConnectionError:
print(f"【异常提醒】第{retry_count + 1}次请求网络连接失败,存在链路抖动")
# 捕获HTTP业务异常
except requests.exceptions.HTTPError as error:
# 区分5xx可重试异常与4xx不可重试异常
if response.status_code >= 500:
print(f"【异常提醒】第{retry_count + 1}次遇到服务端异常,状态码:{response.status_code}")
else:
return {
"code": response.status_code,
"message": f"业务参数或权限错误,不可重试:{str(error)}"
}
# 最后一次重试失败,直接终止流程
if retry_count == MAX_RETRY_TIMES - 1:
return {
"code": 504,
"message": "全部重试次数耗尽,大模型请求最终执行失败"
}
# 固定间隔休眠后重试
time.sleep(BASIC_RETRY_SLEEP)
# 本地测试运行
if __name__ == "__main__":
res = base_llm_chat_request("简述大模型超时控制的核心作用")
print("最终请求结果:", res)输出结果:
【异常提醒】第1次请求触发全局超时,即将进入重试流程
【异常提醒】第2次请求触发全局超时,即将进入重试流程
【异常提醒】第3次请求触发全局超时,即将进入重试流程
最终请求结果: {'code': 504, 'message': '全部重试次数耗尽,大模型请求最终执行失败'}
二、长请求分级超时设计
1. 普通固定超时的缺陷
- 一刀切超时:10的字提问短请求和1万字总结长请求用相同超时时间;
- 短请求超时过长:浪费资源,阻塞服务;
- 长请求超时过短:任务未完成被强制终止,用户体验极差;
- 流式输出与非流式输出无区分:中断用户正在接收的内容。
2. 分级超时核心定义
2.1 核心定义
大模型分级超时,是基于请求特征、业务属性、运行形态、链路层级多维度指标,对不同类型的大模型推理请求配置差异化、动态化超时阈值的精细化管控方案。
摒弃统一固定数值的管控模式,根据请求实际运算复杂度、业务重要程度、数据传输形式,动态计算并分配合理的最大执行时长,实现"一请求一策略、一场景一阈值"的精准化资源管控。
2.2 核心设计理念
-
- 适配性优先:贴合大模型推理耗时的客观规律,长短任务区分对待;
-
- 资源平衡:在用户体验与服务资源利用率之间寻找最优平衡点;
-
- 分层防护:全链路多节点配置分级超时,层层拦截异常请求;
-
- 动态可调:支持根据集群负载、业务峰值自动微调超时参数。
2.3 大模型分级超时核心维度
2.3.1 按输出运行模式分级
- 1. 非流式完整输出模式
- 运行特征:模型完成全部 Token 解码运算后,一次性将完整文本结果返回客户端,中间无数据推送,推理过程完全在服务端闭环完成。
- 超时配置标准:
- 短问答场景:3s~5s;
- 常规文案生成:10s~15s;
- 适用业务:智能分类、数据抽取、短句翻译、简单指令执行。
- 核心管控重点:全局总请求超时,杜绝整体推理卡死。
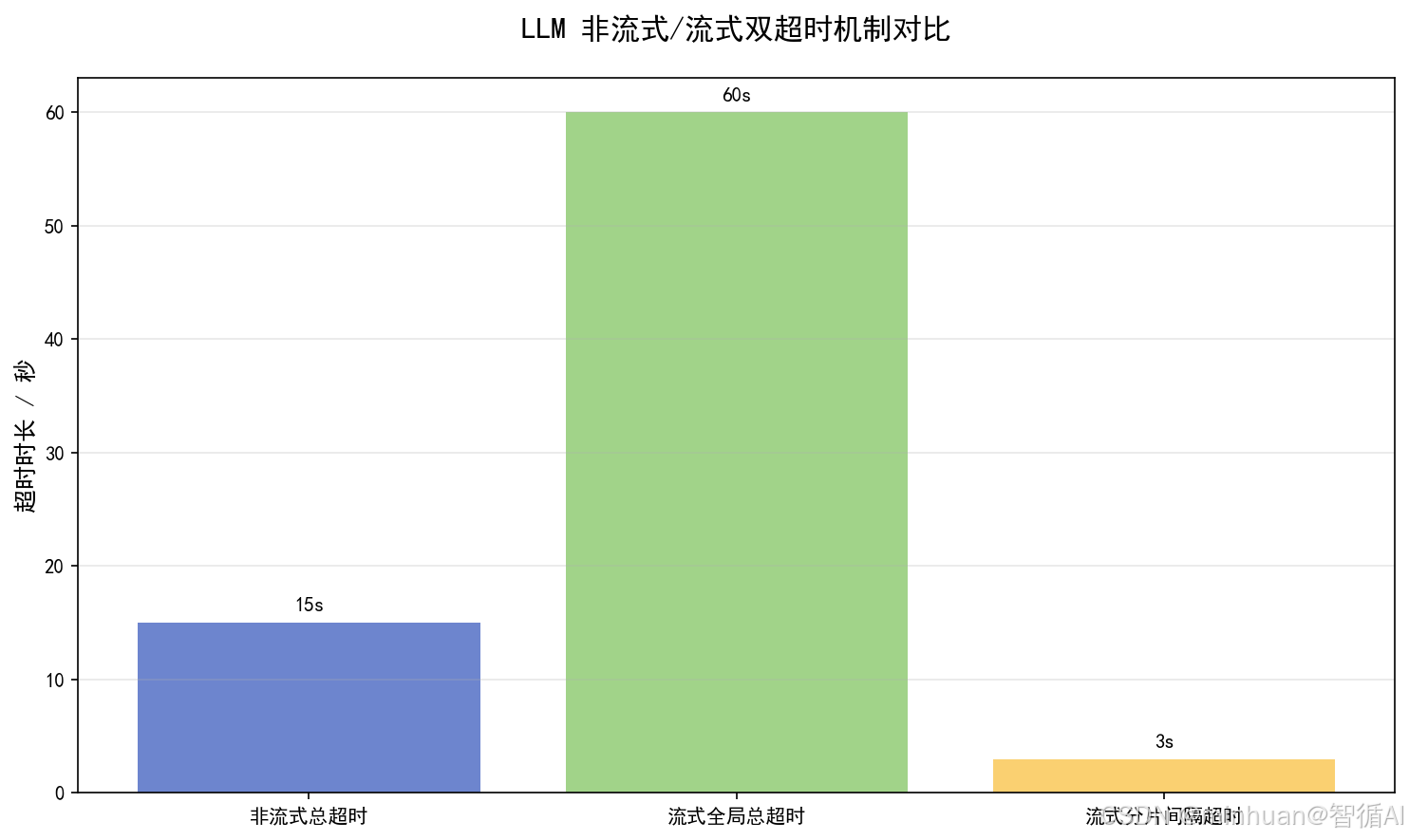
- 2. 流式分片输出模式
- 运行特征:模型每生成一段文字、若干 Token,就实时通过长连接推送至前端,页面逐字渲染,是当前对话类、创作类产品的主流形态。
- 双超时配置标准:
- 全局总超时:30s~120s,限制整个任务的最大运行时长;
- 分片间隔超时:2s~5s,限制两次数据推送的最大间隔时间;
- 核心管控重点:依靠分片超时识别「假连接、僵死推理」问题,避免连接存活但无内容输出的无效等待。
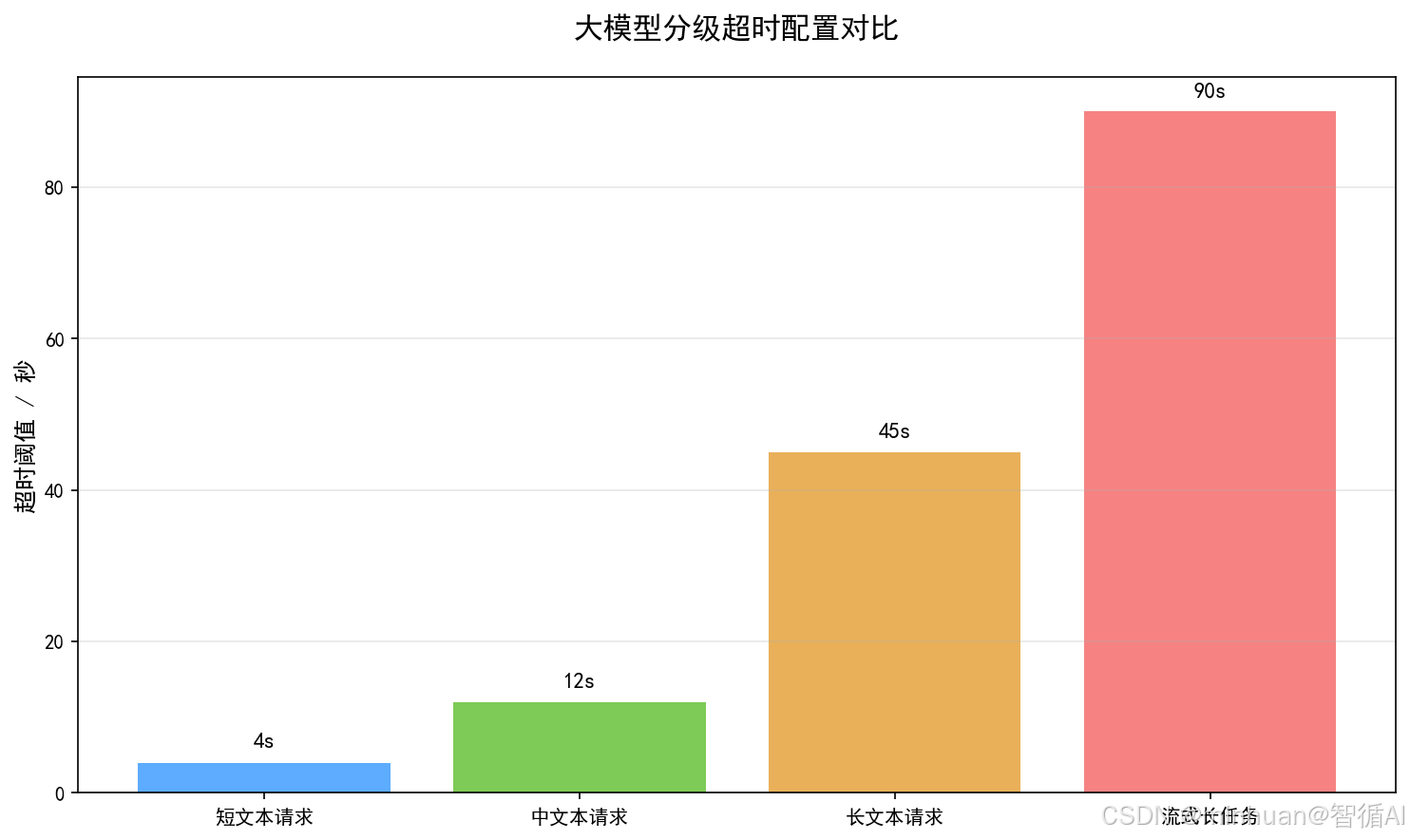
2.3.2 按输入输出文本Token规模分级
大模型推理耗时与输入上下文长度、输出生成长度呈正相关,Token数量越大,注意力计算、解码运算压力越高,所需耗时越长。
- 1. 轻量短文本请求
- 输入 Token<500,输出 Token<100,适用于简单问答、指令操作,基础超时配置 3~5 秒;
- 2. 中等文本请求
- 输入 Token 500~2000,输出 Token 100~500,适用于短文创作、常规总结,基础超时配置 10~15 秒;
- 3. 重型长文本请求
- 输入 Token>2000,输出 Token>500,适用于长文档摘要、万字创作、多轮长对话,基础超时配置 30~60 秒;
- 4. 超大型批量任务
- 批量文档处理、知识库全局问答,可单独配置 120 秒以上专属超时,并限制并发数量。
2.3.3 按业务优先级与用户权限分级
- 1. 高优先级业务
- 付费用户、企业定制服务、核心办公系统、付费 API 调用,在基础超时数值上上浮 20%~30%,提升故障容忍度,保障核心业务稳定性;
- 2. 标准普通优先级
- 个人免费用户、通用基础功能,严格使用默认标准超时参数,维持资源均衡分配;
- 3. 低优先级任务
- 内部测试任务、批量异步处理、离线数据生成、临时调试接口,超时数值下浮 30%~40%,严格限制资源占用,错峰运行。
2.3.4 按请求链路层级分级
完整大模型调用链路包含多层服务节点,各层级超时逐级递减,形成层层防护:
-
- 网关层超时:链路第一道防线,配置最短超时,优先拦截恶意请求、超长阻塞连接;
-
- 业务应用层超时:核心业务管控节点,使用精细化分级动态超时,承载主要容错逻辑;
-
- 模型推理服务层超时:底层算力防护,防止单条推理任务无限制占用GPU资源。
2.4 流式分片间隔超时原理
流式输出是大模型区别于传统接口的核心场景,也是超时管控的重难点。在实际生产环境中,经常出现一种特殊异常:
- 客户端与服务端的网络长连接保持正常,TCP链路未断开,但是大模型推理进程卡死、解码中断、显存溢出挂起,导致长时间没有任何文字分片输出。
- 此时单纯依靠全局总超时无法快速发现问题,用户会持续等待数十秒才会触发失败,体验极差。
分片间隔超时的核心原理:
- 系统实时记录上一次分片数据推送的时间戳,持续检测当前时间与历史时间的差值;
- 当两次有效数据传输的间隔超过预设阈值,直接判定推理进程僵死、任务异常,主动关闭长连接、终止推理任务,快速释放 GPU 资源。
该机制可以将流式异常的发现时长压缩至 3~5 秒以内,是大模型流式服务稳定性的关键优化点。
2.5 分级超时完整执行流程

- 1. 请求接入解析阶段
客户端请求到达业务服务后,系统自动解析核心特征参数:判断是否为流式输出、统计输入文本字符/Token 数量、识别请求所属业务线、标记用户优先级标签、记录链路请求节点信息。
- 2. 动态超时参数计算阶段
依托预设的分级规则,结合多维度特征,自动计算当前请求专属的总超时数值;若为流式请求,同步生成分片间隔超时阈值,整合为完整超时配置结构体。
- 3. 请求发起与计时启动阶段
携带动态计算后的超时参数发起大模型推理请求,分别开启全局总计时器、流式分片独立计时器,双计时器并行监控任务运行状态。
- 4. 双维度异常检测阶段
非流式请求仅监控全局总耗时,超出阈值立即中断;流式请求同时监控总耗时与分片间隔耗时,任意一项触发阈值即刻判定异常。
- 5. 异常中断与资源释放阶段
触发超时规则后,主动向推理服务发送连接终止指令,销毁本地请求会话、关闭网络连接、清空临时缓存数据,同步记录超时类型、请求参数、耗时日志。
- 6. 故障判定与流程流转阶段
根据超时类型、服务端状态码,判断是否属于可重试异常,符合条件则进入后续退避重试、断点续传流程;不可重试异常直接返回标准化错误信息与降级方案。
2.6 示例:分级超时实践
python
import requests
import time
def get_dynamic_timeout_config(text_length: int, is_stream: bool, user_priority: str = "normal"):
"""
动态计算分级超时配置
返回:总超时、流式分片超时
"""
# 1. 根据文本长度初始化基础超时
if text_length < 500:
base_total = 5
elif text_length < 2000:
base_total = 15
else:
base_total = 60
chunk_timeout = None
# 2. 按流式/非流式调整参数
if is_stream:
chunk_timeout = 1.0
base_total = min(base_total * 1.5, 120)
# 3. 按业务优先级浮动调整
if user_priority == "high":
final_total = base_total * 1.2
elif user_priority == "low":
final_total = base_total * 0.7
else:
final_total = base_total
return {
"total_timeout": round(final_total, 1),
"chunk_timeout": chunk_timeout
}
def graded_timeout_llm_request(prompt: str, is_stream: bool = False, priority: str = "normal"):
# 文本长度统计,模拟Token量级判断
prompt_len = len(prompt)
timeout_cfg = get_dynamic_timeout_config(prompt_len, is_stream, priority)
total_t = timeout_cfg["total_timeout"]
chunk_t = timeout_cfg["chunk_timeout"]
print(f"【分级超时配置】总超时:{total_t}s,分片超时:{chunk_t}s")
url = "http://192.168.3.6:8000/v1/chat/completions"
payload = {
"prompt": prompt,
"stream": is_stream
}
try:
resp = requests.post(
url=url,
json=payload,
timeout=total_t,
stream=is_stream
)
resp.raise_for_status()
# 流式分片超时逻辑
if is_stream and chunk_t:
last_time = time.time()
for chunk in resp.iter_lines(decode_unicode=True):
# 检测分片间隔超时
if time.time() - last_time > chunk_t:
raise TimeoutError(f"流式分片超时:连续{chunk_t}s无数据返回")
last_time = time.time()
if chunk:
print("流式片段:", chunk)
return {
"code": 200,
"msg": "请求正常完成",
"timeout_config": timeout_cfg
}
except requests.exceptions.Timeout:
return {"code": 504, "msg": f"全局总超时触发,限制时长:{total_t}s"}
except TimeoutError as e:
return {"code": 504, "msg": f"流式分片异常:{str(e)}"}
if __name__ == "__main__":
# 模拟长文本+流式+高优用户场景
result = graded_timeout_llm_request(
prompt="请详细撰写一份人工智能行业年度发展分析报告,包含技术趋势、落地场景、行业挑战",
is_stream=True,
priority="high"
)
print("最终结果:", result)输出结果:
流式片段: data: {"id": "chatcmpl-local", "object": "chat.completion.chunk", "model": "ZhipuAI/chatglm2-6b", "choices": [{"delta": {"content": "人工智能(AI)是当前科技领域中最受关注的领域之一,它的发展对未来的经济和社会产生了深远的影响。本报告将详细分析人工智能行业在过去一年中的技术趋势、落地场景以及行业挑战。\n\n一、技术趋势\n\n(1)深度学习\n\n深度学习是目前人工智能领域中最为热门的技术之一,也是实现人工智能的重要手段之一。深度学习是一种基于神经网络的机器学习技术,通过构建多层神经网络,可以实现对数据的
(省略部分内容。。。。。)
\n\n(2)模型的可解释性\n\n模型的可解释性是目前人工智能技术面临的一个关键挑战。由于人工智能模型往往具有很强的复杂性,因此很难解释模型的决策过程和结果,这也是人工智能技术发展面临的一个挑战。"}, "index": 0, "finish_reason": null}]}
流式片段: data: {"id": "chatcmpl-local", "object": "chat.completion.chunk", "choices": {"delta": {}, "index": 0, "finish_reason": "stop"}}
流式片段: data: DONE
最终结果: {'code': 200, 'msg': '请求正常完成', 'timeout_config': {'total_timeout': 9.0, 'chunk_timeout': 1.0}}
三、幂等重试与退避重试机制
1. 幂等重试
1.1 核心定义
幂等性:同一请求执行一次和执行多次,结果完全一致,不会产生重复数据、重复扣费、重复生成等副作用,是大模型重试的安全底线。
1.2 保证幂等的必要性
- 重试机制会重复发送相同请求;
- 非幂等会导致:重复生成内容、重复计费、对话上下文错乱、数据库脏数据;
- 大模型对话、生成、编辑类场景,幂等是生产可用的前提。
1.3 大模型幂等实现方案
-
- 请求唯一ID
- 每个请求生成全局唯一ID,如UUID;
- 服务端根据ID去重,相同ID只执行一次;
-
- 无状态请求设计
- 避免依赖服务端临时状态;
- 对话上下文完整携带在请求中;
-
- 只读或无副作用请求优先重试
- 生成类、问答类天然幂等,优先重试;
- 写入、扣费类必须加唯一ID校验;
-
- 服务端幂等缓存
- 缓存成功结果,相同请求直接返回缓存,不重复推理。
2. 退避重试
2.1 核心定义
退避重试:重试间隔不固定,每次重试等待时间逐步延长,给大模型服务留出恢复时间。简单概括为优雅重试,避免雪崩。
2.2 主流退避算法
-
- 指数退避
- 间隔:1s → 2s → 4s → 8s → 16s
- 优势:快速重试前几次,后续逐步让步,适配瞬时波动
-
- 指数退避 + 抖动
- 间隔:1s±0.2 → 2s±0.5 → 4s±1
- 优势:解决"惊群效应",避免所有请求同时重试
-
- 固定间隔退避
- 间隔:1s→1s→1s
- 适用:低并发、简单场景
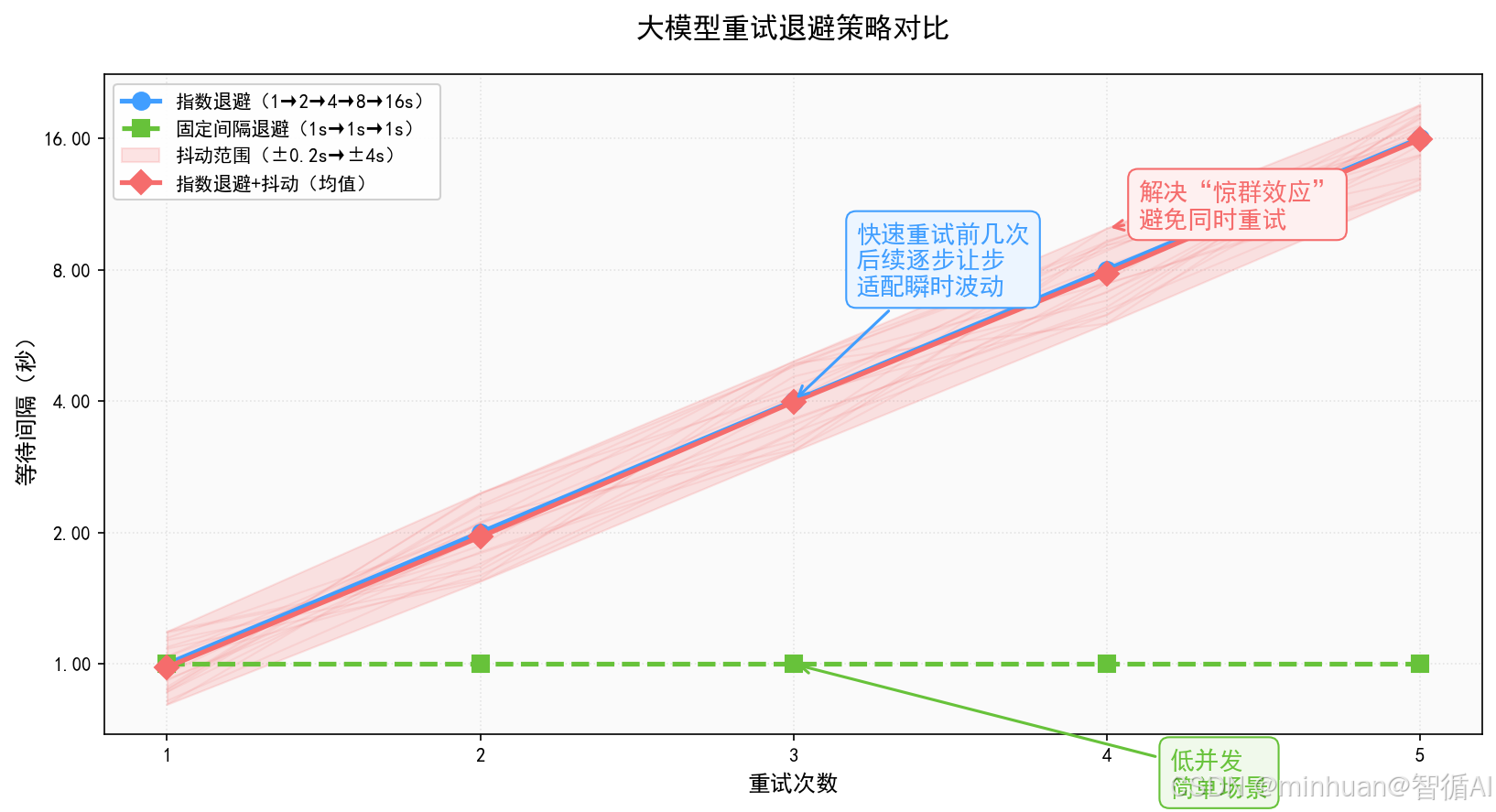
2.3 退避重试核心规则
- 重试次数有限制,3~5次为宜;
- 总重试时间不超过分级超时上限;
- 仅对可重试异常执行退避;
- 高并发下必须加抖动。
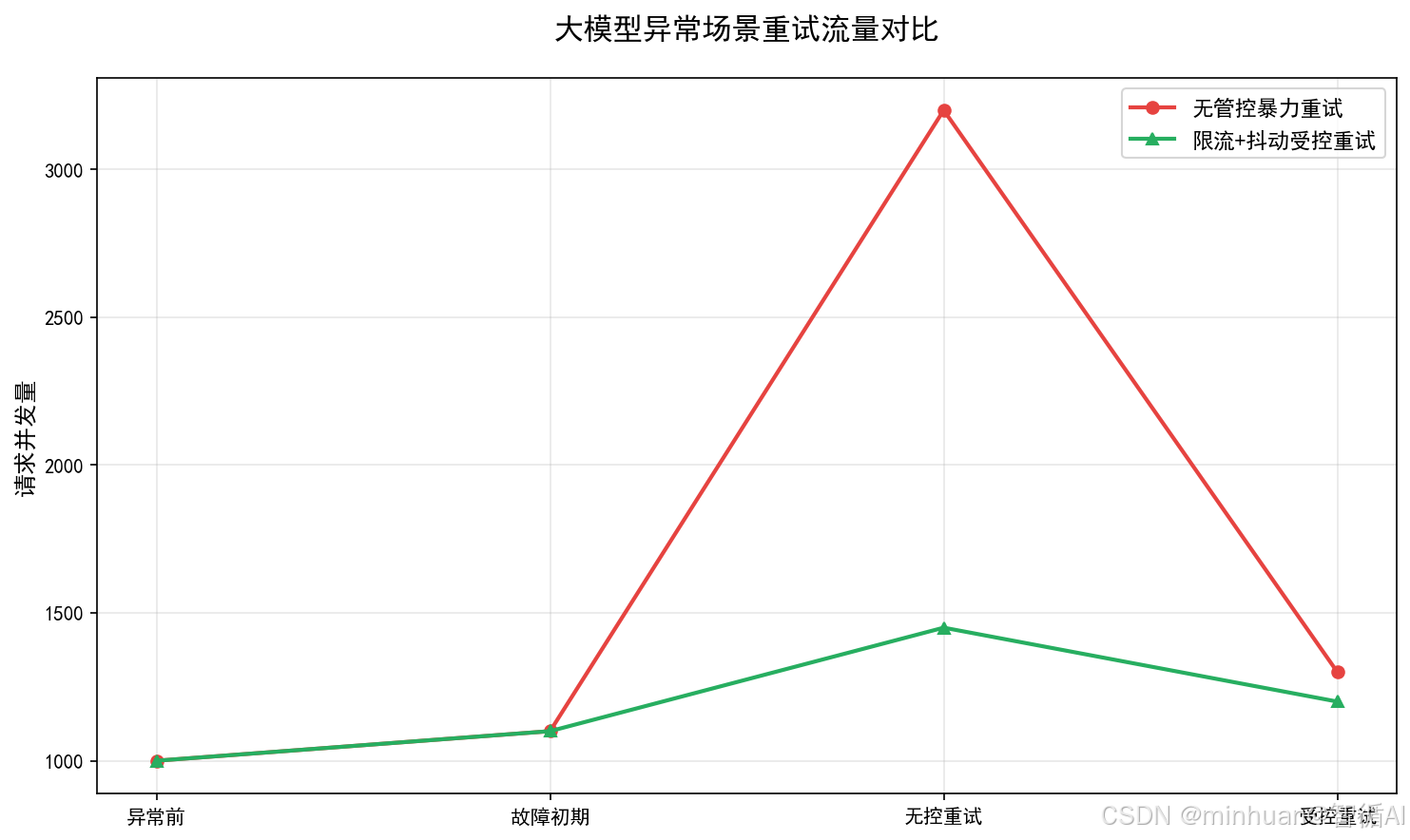
3. 避免雪崩式重试
3.1 雪崩原因
大量请求同时失败 → 同时重试 → 服务负载瞬间翻倍 → 服务彻底崩溃。
3.2 防护方案
-
- 重试限流
- 单个客户端每秒最大重试次数限制;
- 全局重试流量占比不超过总流量的10%;
-
- 熔断机制
- 失败率达到阈值,如50%,暂停重试,直接返回降级结果;
- 半开探测:少量请求试探恢复后,再放开重试;
-
- 请求合并与排队
- 相同请求合并执行,减少重试压力;
-
- 抖动退避
- 打散重试时间,避免流量峰值叠加。
4. 示例:幂等 + 退避 + 抖动重试
python
import requests
import time
import uuid
import random
from typing import Optional
# ===================== 生产级全局配置 =====================
MAX_RETRY_COUNT = 4 # 最大重试次数
BASE_BACKOFF_SEC = 1 # 基础退避秒数
MAX_BACKOFF_SEC = 16 # 最大退避上限,防止等待过久
TIMEOUT_LIMIT = 20 # 单次请求全局超时
# 可重试异常状态码白名单
RETRY_STATUS_WHITE_LIST = {502, 503, 504, 500}
class IdempotentLLMRequest:
def __init__(self):
# 生成全局唯一幂等请求ID
self.request_id: str = str(uuid.uuid4())
def _calc_backoff_time(self, retry_times: int) -> float:
"""
计算退避等待时间:指数退避 + 随机抖动 + 最大值限制
"""
# 指数退避
exp_time = BASE_BACKOFF_SEC * (2 ** retry_times)
# 限制上限
exp_time = min(exp_time, MAX_BACKOFF_SEC)
# 增加随机抖动 0.5 ~ 1.0倍
jitter_ratio = random.uniform(0.5, 1.0)
final_sleep = exp_time * jitter_ratio
return round(final_sleep, 2)
def request_with_retry(self, prompt: str) -> dict:
url = "http://192.168.3.26:8000/v1/chat/completions"
payload = {
"prompt": prompt,
"request_id": self.request_id, # 幂等核心字段
"temperature": 0.7
}
resp: Optional[requests.Response] = None
for retry_idx in range(MAX_RETRY_COUNT):
try:
resp = requests.post(
url=url,
json=payload,
timeout=TIMEOUT_LIMIT
)
resp.raise_for_status()
return {
"code": 200,
"success": True,
"request_id": self.request_id,
"retry_used": retry_idx,
"data": resp.json()
}
except requests.exceptions.Timeout:
print(f"[{self.request_id}] 第{retry_idx+1}次请求超时")
except requests.exceptions.ConnectionError:
print(f"[{self.request_id}] 第{retry_idx+1}次网络连接异常")
except requests.exceptions.HTTPError:
# 非白名单状态码,直接终止重试
if resp and resp.status_code not in RETRY_STATUS_WHITE_LIST:
return {
"code": resp.status_code,
"success": False,
"msg": "不可重试业务异常"
}
print(f"[{self.request_id}] 服务端临时异常,状态码:{resp.status_code}")
# 最后一次重试,不再等待
if retry_idx >= MAX_RETRY_COUNT - 1:
return {
"code": 504,
"success": False,
"request_id": self.request_id,
"msg": "重试次数耗尽,请求失败"
}
# 计算退避时间并休眠
sleep_time = self._calc_backoff_time(retry_idx)
print(f"[{self.request_id}] 等待{sleep_time}s后进行下一次重试\n")
time.sleep(sleep_time)
if __name__ == "__main__":
client = IdempotentLLMRequest()
result = client.request_with_retry("分析大模型退避重试的工程价值")
print("最终请求结果:", result)输出结果:
d40d1d77-1a2a-4a75-8046-d479a7839569 第1次请求超时
d40d1d77-1a2a-4a75-8046-d479a7839569 等待0.57s后进行下一次重试
d40d1d77-1a2a-4a75-8046-d479a7839569 第2次请求超时
d40d1d77-1a2a-4a75-8046-d479a7839569 等待1.67s后进行下一次重试
d40d1d77-1a2a-4a75-8046-d479a7839569 第3次请求超时
d40d1d77-1a2a-4a75-8046-d479a7839569 等待3.53s后进行下一次重试
d40d1d77-1a2a-4a75-8046-d479a7839569 第4次请求超时
最终请求结果: {'code': 504, 'success': False, 'request_id': 'd40d1d77-1a2a-4a75-8046-d479a7839569', 'msg': '重试次数耗尽,请求失败'}
四、流式输出异常重试设计
1. 流式输出异常的特殊性
-
- 请求已开始,数据已返回部分:普通重试会从头生成,用户体验极差;
-
- 分片超时、网络抖动:中断概率远高于非流式;
-
- 上下文依赖:中断后需要衔接已生成内容,不能重复;
-
- 前端实时展示:中断会导致页面卡顿、内容缺失。
2. 流式输出重试设计原则
-
- 断点续传:从中断位置继续生成,不重复输出已返回内容;
-
- 双超时机制:总超时 + 分片超时同时生效;
-
- 用户无感知:前端不展示异常,自动恢复;
-
- 幂等 + 断点:保证重试不重复、不错乱。
3. 流式输出重试完整执行流程
-
- 客户端发起流式请求,记录初始上下文 + 已生成内容 + 请求ID;
-
- 服务端逐帧返回数据,客户端实时缓存;
-
- 触发异常,如分片超时、网络中断;
-
- 校验是否可重试:是则进入断点重试;
-
- 重试请求携带:请求 ID + 已生成内容 + 中断位置;
-
- 服务端从断点继续生成,返回后续数据;
-
- 客户端拼接数据,推送给前端,完成无感知恢复;
-
- 重试失败:返回已生成内容 + 提示,不丢失数据。
4. 流式输出重试技术细节
- 断点标识
- 记录已生成token数、字符数;
- 服务端根据标识截断上下文,从断点推理;
- 上下文去重
- 重试时自动剔除重复内容,避免重复输出;
- 重试次数限制
- 流式重试最多2次,避免无限等待;
- 降级策略
- 重试失败:返回已生成内容,提示用户继续生成。
5. 示例:流式输出断点重试
python
import requests
import time
import uuid
class StreamLLMBreakpointRetry:
def __init__(self):
# 重试配置
self.max_stream_retry = 2
self.chunk_interval_timeout = 3.0
self.task_total_timeout = 90
# 幂等标识
self.request_id = str(uuid.uuid4())
# 断点缓存:保存已生成内容
self.finished_content = ""
def _stream_request_core(self, prompt: str, continue_text: str = None) -> dict:
"""
核心流式请求方法
:param prompt: 原始提问
:param continue_text: 断点接续内容
"""
url = "http://192.168.3.61:8000/v1/chat/completions"
payload = {
"prompt": prompt,
"stream": True,
"request_id": self.request_id,
"continue_content": continue_text
}
try:
response = requests.post(
url=url,
json=payload,
stream=True,
timeout=self.task_total_timeout
)
response.raise_for_status()
last_chunk_time = time.time()
for chunk in response.iter_lines(decode_unicode=True):
# 分片间隔超时检测
current_time = time.time()
if current_time - last_chunk_time > self.chunk_interval_timeout:
raise TimeoutError("推理僵死,分片间隔超时")
last_chunk_time = current_time
if chunk and chunk.strip():
self.finished_content += chunk.strip()
print("实时输出片段:", chunk.strip())
return {
"success": True,
"content": self.finished_content,
"msg": "流式生成完成"
}
except Exception as e:
return {
"success": False,
"error": str(e),
"breakpoint_content": self.finished_content
}
def start_stream_task(self, prompt: str) -> dict:
"""流式任务入口:自动断点重试"""
retry_count = 0
current_continue = None
while retry_count < self.max_stream_retry:
print(f"\n===== 流式生成 第{retry_count + 1}次尝试 =====")
result = self._stream_request_core(prompt, current_continue)
if result["success"]:
return result
# 记录断点,准备接续重试
current_continue = result["breakpoint_content"]
print(f"流式任务中断,已生成内容长度:{len(current_continue)}")
print(f"异常原因:{result['error']}")
retry_count += 1
# 重试耗尽,兜底返回已有内容
return {
"success": False,
"content": self.finished_content,
"msg": "流式重试已用尽,返回已生成内容"
}
if __name__ == "__main__":
stream_client = StreamLLMBreakpointRetry()
final_res = stream_client.start_stream_task("写一篇500字的自然风景散文,文笔细腻优美")
print("\n===== 最终完整内容 =====")
print(final_res["content"])输出结果:
===== 流式生成 第1次尝试 =====
流式任务中断,已生成内容长度:0
异常原因:HTTPConnectionPool(host='192.168.3.61', port=8000): Max retries exceeded with url: /v1/chat/completions (Caused by ConnectTimeoutError(<HTTPConnection(host='192.168.3.61', port=8000) at 0x1a8929e3a50>, 'Connection to 192.168.3.61 timed out. (connect timeout=90)'))
===== 流式生成 第2次尝试 =====
流式任务中断,已生成内容长度:0
异常原因:HTTPConnectionPool(host='192.168.3.61', port=8000): Max retries exceeded with url: /v1/chat/completions (Caused by ConnectTimeoutError(<HTTPConnection(host='192.168.3.61', port=8000) at 0x1a89314b3d0>, 'Connection to 192.168.3.61 timed out. (connect timeout=90)'))
===== 最终完整内容 =====
五、总结
总的来说,大模型和普通接口完全不是一套设计逻辑。传统接口延迟低、链路简单,简单超时加基础重试就能满足需求,但大模型推理算力消耗大、耗时波动强、还有流式长连接场景,容错设计必须做的更精细、更全面。分级超时解决了长短请求一刀切的问题,幂等机制避免重试带来重复计费、内容错乱,带随机抖动的退避策略,能有效防止大规模重试压垮模型服务,而流式断点续传,更是解决了长文本生成中断、内容丢失的核心痛点。
越是深入越清楚,大模型开发不能只关注提示词优化、模型调用这类表层功能,稳定性设计才是项目能否落地商用的关键。很多线上故障,往往都是超时不合理、重试无约束导致的。实际开发经验总结,不要盲目套用策略,结合自身业务并发、模型类型、网络环境组合使用,慢慢养成高可用的工程思维,才能写出稳定、靠谱的大模型业务代码。