【LangGraph】新篇章:LangGraph 持久化(Persistence)*重点*
- 前言
-
- [一、为什么选择 PostgreSQL](#一、为什么选择 PostgreSQL)
- 二、完整代码:支持持久化的搜索助手
- 三、核心知识点拆解
- 四、常见问题与注意事项
- 五、总结
上一章-> 【LangGraph 持久化】让 AI Agent 拥有"记忆"
前言
上一章我们留了一个尾巴:InMemorySaver 方便但重启即丢,生产环境推荐用 PostgresSaver
这一章我们就围绕 PostgreSQL + 线程级持久化 展开,用一个完整的"搜索助手"案例,演示:
-
如何配置 PostgresSaver
-
如何实现多轮对话的自动记忆
-
如何查看和回溯历史状态
-
如何利用重放(Replay)机制调试 Agent
代码基于之前发布的------>【LangGraph】实战:支持搜索的智能代理系统(Agent + Tool)
一、为什么选择 PostgreSQL
- LangGraph 状态存储方式对比
我们可以看个表格:
| 存储方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| InMemorySaver | 零配置、速度极快、无需依赖 | 重启程序丢失所有数据 | 本地调试、Demo 演示、单元测试 |
| SqliteSaver | 单文件、轻量、无需服务 | 并发能力差、不支持分布式、生产慎用 | 单机小工具、个人本地项目 |
| PostgresSaver | 官方原生支持、稳定可靠、分布式兼容、持久化不丢失 | 需要部署数据库服务 | 生产环境首选、正式项目、多人协作 |
| MySQL | 无官方适配 | 需要手动实现存储层、兼容性差、容易出问题 | 不推荐使用 |
总结一下:
-
LangGraph 官方只完整适配 PostgreSQL ,包含状态表结构、序列化、中断恢复、查询优化
MySQL 无官方支持,强行使用成本极高
-
正式开发/生产环境 → 直接用 PostgreSQL + Docker 一键部署
Docker 启动 PostgreSQL 的命令,复制到终端运行(仅供参考):
bash
# . 运⾏ PostgreSQL 容器
# --name postgres-sql: 给容器命名
# -e POSTGRES_PASSWORD=123: 设置PostgreSQL的postgres⽤⼾密码
# -p 5432:5432: 将容器的5432端⼝映射到宿主机的5432端⼝
# -d: 后台运⾏
docker run
--name postgres-sql
-e POSTGRES_PASSWORD=123
-p 5432:5432
-d postgres二、完整代码:支持持久化的搜索助手
以下代码是【LangGraph】实战:支持搜索的智能代理系统(Agent + Tool)的直接升级版,
只增加了 PostgresSaver 和状态查看逻辑
python
import operator
from typing import TypedDict, Annotated
from langchain.chat_models import init_chat_model
from langchain_core.messages import AnyMessage, SystemMessage, ToolMessage, HumanMessage
from langchain_tavily import TavilySearch
from langgraph.checkpoint.postgres import PostgresSaver
from langgraph.constants import START, END
from langgraph.graph import StateGraph
# ========== 1. 初始化模型和工具 ==========
search = TavilySearch(max_results=4)
tools = [search]
model = init_chat_model("gpt-4o-mini", temperature=0)
model_with_tool = model.bind_tools(tools)
# ========== 2. 定义状态 ==========
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], operator.add]
llm_calls: int
# ========== 3. 定义节点 ==========
def llm_call(state: MessagesState):
"""LLM 决定是否调用工具"""
result = model_with_tool.invoke(
[SystemMessage(content="你是一位乐于助人的助手,支持搜索工具")] + state["messages"]
)
return {
"messages": [result],
"llm_calls": state.get("llm_calls", 0) + 1
}
tools_by_name = {tool.name: tool for tool in tools}
def tool_node(state: MessagesState):
"""执行工具调用"""
result = []
last_message = state["messages"][-1]
for tool_call in last_message.tool_calls:
tool = tools_by_name[tool_call["name"]]
obs = tool.invoke(tool_call["args"])
result.append(ToolMessage(content=obs, tool_call_id=tool_call["id"]))
return {"messages": result}
def should_continue(state: MessagesState):
"""条件边:判断是否还要调用工具"""
last_message = state["messages"][-1]
if last_message.tool_calls:
return "tool_node"
return END
# ========== 4. 构建图 ==========
builder = StateGraph(MessagesState)
builder.add_node("llm_call", llm_call)
builder.add_node("tool_node", tool_node)
builder.add_edge(START, "llm_call")
builder.add_conditional_edges("llm_call", should_continue, ["tool_node", END])
builder.add_edge("tool_node", "llm_call")
# ========== 5. 编译图(绑定 PostgreSQL) ==========
DB_URI = "postgresql://postgres:***@localhost:5432/postgres"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
# 第一次运行需要建表
checkpointer.setup()
agent = builder.compile(checkpointer=checkpointer)
# ========== 6. 演示多轮记忆 ==========
config = {"configurable": {"thread_id": "user_123"}}
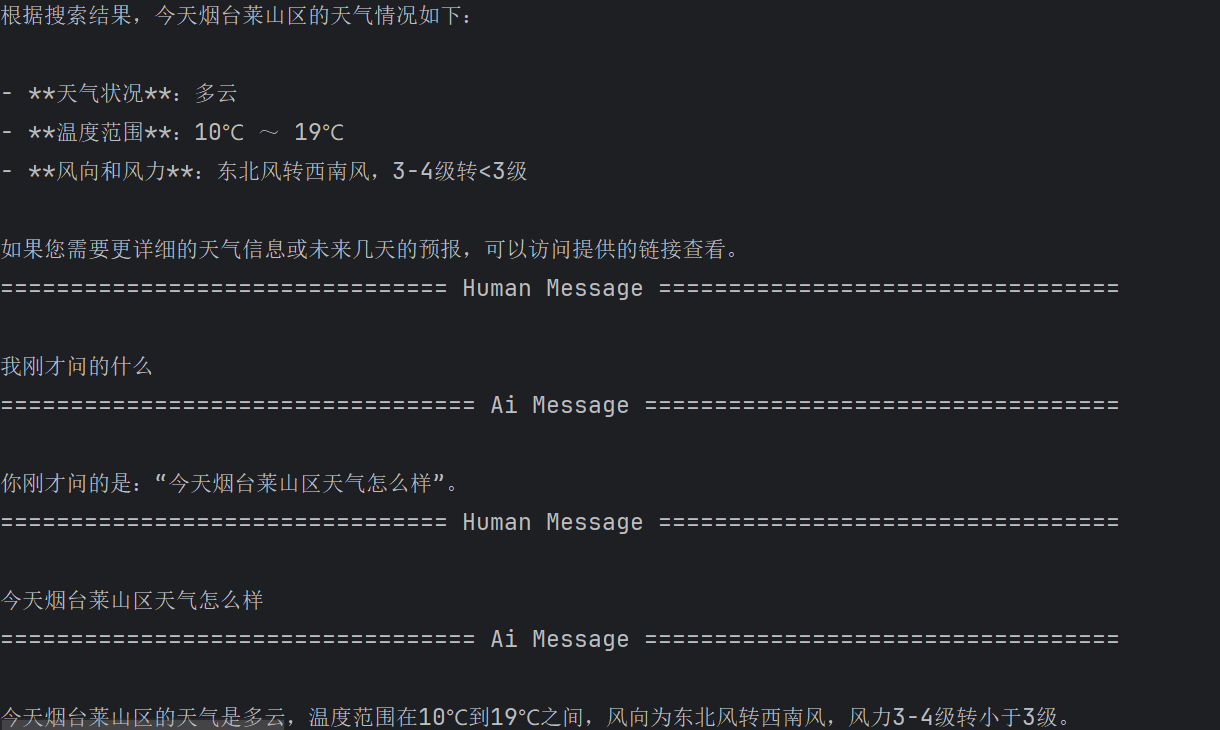
print("=== 第一轮对话 ===")
result1 = agent.invoke(
{"messages": [HumanMessage(content="今天烟台天气怎么样")]},
config=config
)
result1 ["messages"][-1].pretty_print()
print("\n=== 第二轮对话(测试记忆) ===")
result2 = agent.invoke(
{"messages": [HumanMessage(content="我刚才问的什么")]},
config=config
)
for i in result2 ["messages"]:
i.pretty_print()
# ========== 7. 查看状态历史 ==========
for snapshot in agent.get_state_history(config):
print(f"checkpoint_id: {snapshot.config['configurable']['checkpoint_id']}")
print(f"下一节点: {snapshot.next}")
print("---")运行结果:
三、核心知识点拆解
- thread_id 就是会话的身份证
相同的 thread_id 共享同一个状态历史
不同的 thread_id 完全隔离,互不干扰
python
# 用户A的会话
config_a = {"configurable": {"thread_id": "a_001"}}
# 用户B的会话
config_b = {"configurable": {"thread_id": "b_001"}}我们可以直接在postgres上观察到:
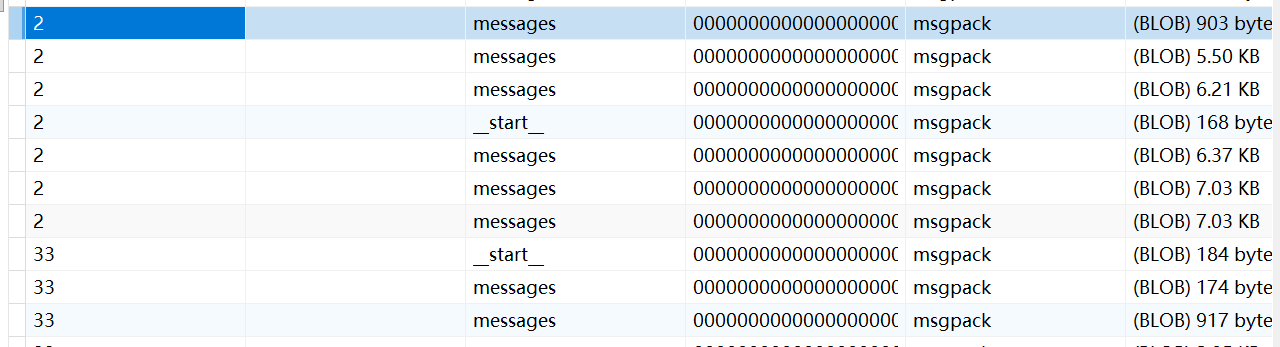
get_state_history()让你看到 Agent 的每一步
每一次从 llm_call 到 tool_node 再回到 llm_call,都会生成一个 checkpoint
通过遍历历史,你可以知道:
每个 checkpoint 的 ID
当时的状态(messages、llm_calls 等)
下一步要执行哪个节点(snapshot.next)
这个能力在调试 Agent 的决策逻辑时极其有用
- 重放(Replay):从某个 checkpoint 重新执行
你可以把一个历史 checkpoint 拿出来,让 Agent 从那里"重新开始跑"
python
# 获取所有历史
history = list(agent.get_state_history(config))
# 取第一个 checkpoint(最早的那个)
old_snapshot = history[-1]
# 从那个 checkpoint 重新执行
replay_result = agent.invoke(None, config=old_snapshot.config)应用场景:
调试验证:Agent 在某一步做错了决策,重放看看哪里出了问题
人工兜底:长任务执行到一半,人工修正状态后继续
- 更新状态
除了查看和重放历史状态,LangGraph 还允许你直接编辑图的状态
这在调试、修正错误输入、或者人工介入时非常有用
我们通过 update_state() 方法来实现
下面我们用一个搜索助手的例子,演示如何修改用户输入并重新执行:
python
from langchain_core.messages import HumanMessage
from langgraph.types import Overwrite
config = {"configurable": {"thread_id": "1"}}
# 第一次执行:用户问"西安天气"
result1 = agent.invoke(
{"messages": [HumanMessage(content="今天烟台的天气如何?")]},config)
# 查看历史,找到调用 LLM 之前的那个 checkpoint
selected_state = None
for state in agent.get_state_history(config):
print(f"checkpoint_id: {state.config['configurable']['checkpoint_id']}, "
f"消息数: {len(state.values['messages'])}, 下一节点: {state.next}")
if len(state.values["messages"]) == 1: # 还未调用 LLM 的状态
selected_state = state
# 更新用户输入:将"烟台"改为"北京"
new_config = agent.update_state(
selected_state.config,
{"messages": Overwrite([HumanMessage(content="今天北京的天气如何?")])}
)
# 从更新后的 checkpoint 重新执行
result2 = agent.invoke(None, config=new_config)
for message in result2['messages']:
message.pretty_print()四、常见问题与注意事项
-
Q1:第一次运行报错 relation "checkpoints" does not exist
A: 忘记调用 checkpointer.setup()
该方法会在 PostgreSQL 中创建必要的表(checkpoints、checkpoint_writes 等)
-
Q2:get_state_history() 返回空列表
A: 检查两点:
确保调用 invoke 时传入了 config(包含 thread_id)
如果使用 PostgresSaver,确认数据库连接正常
-
Q3:生产环境需要注意什么?
不要用 with 语句每次重连,应该使用连接池
定期清理过期的 checkpoint,避免表无限膨胀
可以为 thread_id 建立索引,提升查询性能
-
Q4:可以手动删除某个会话的状态吗?
可以,直接操作 PostgreSQL 表:
使用以下语句:
sql
DELETE FROM checkpoints WHERE thread_id = 'user_001';五、总结
这一章我们完成了从"无状态"到"有状态"的转变:
能力 实现方式
多轮记忆
python
thread_id + PostgresSaver状态追踪
python
get_state_history()断点恢复 重放(Replay)机制
线程级持久化是构建生产级 Agent 的地基
有了它,你的 AI 助手才能像真人一样记住上下文、扛得住崩溃、经得起调试
下一章我们将探讨跨会话持久化(Store)------让 Agent 在不同对话之间也能记住你的偏好和长期信息~
