
🦆 个人主页:深邃-

目录
实现顺序结构二叉树
一般堆使用顺序结构的数组来存储数据,堆是一种特殊的二叉树,具有二叉树的特性的同时,还具备其他的特性。
堆的概念与结构
如果有一个关键码的集合 K = { k 0 , k 1 , k 2 , ... , k n − 1 } K=\{k_0, k_1, k_2, \dots, k_{n-1}\} K={k0,k1,k2,...,kn−1},把它的所有元素按完全二叉树的顺序存储方式存储 ,在一个一维数组中,并满足: K i ≤ K 2 i + 1 K_i\leq K_{2i+1} Ki≤K2i+1且 K i ≤ K 2 i + 2 K_i\leq K_{2i+2} Ki≤K2i+2 ( K i ≥ K 2 i + 1 (K_i\geq K_{2i+1} (Ki≥K2i+1 且 K i ≥ K 2 i + 2 ) K_i\geq K_{2i+2}) Ki≥K2i+2)则称为小堆(或大堆) 。将根结点最大的堆叫做最大堆或大根堆,根结点最小的堆叫做最小堆或小根堆。
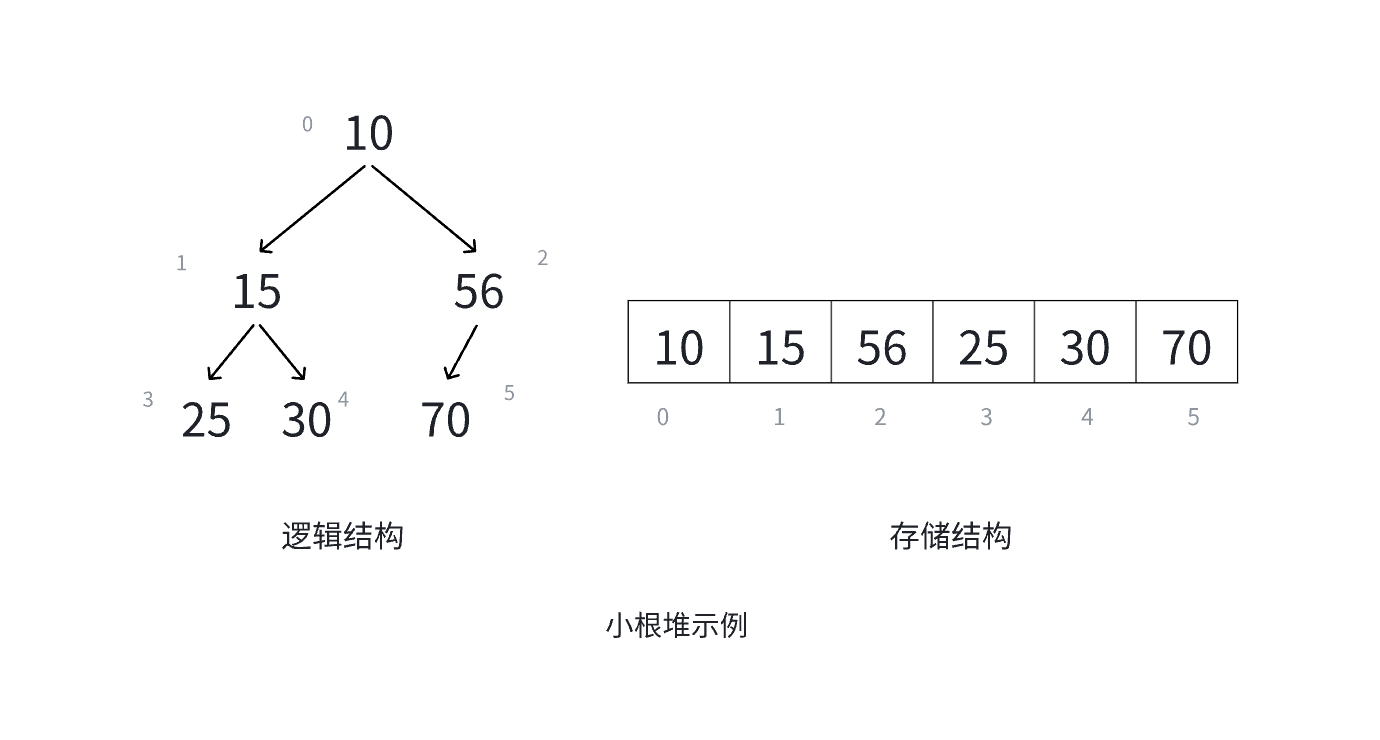
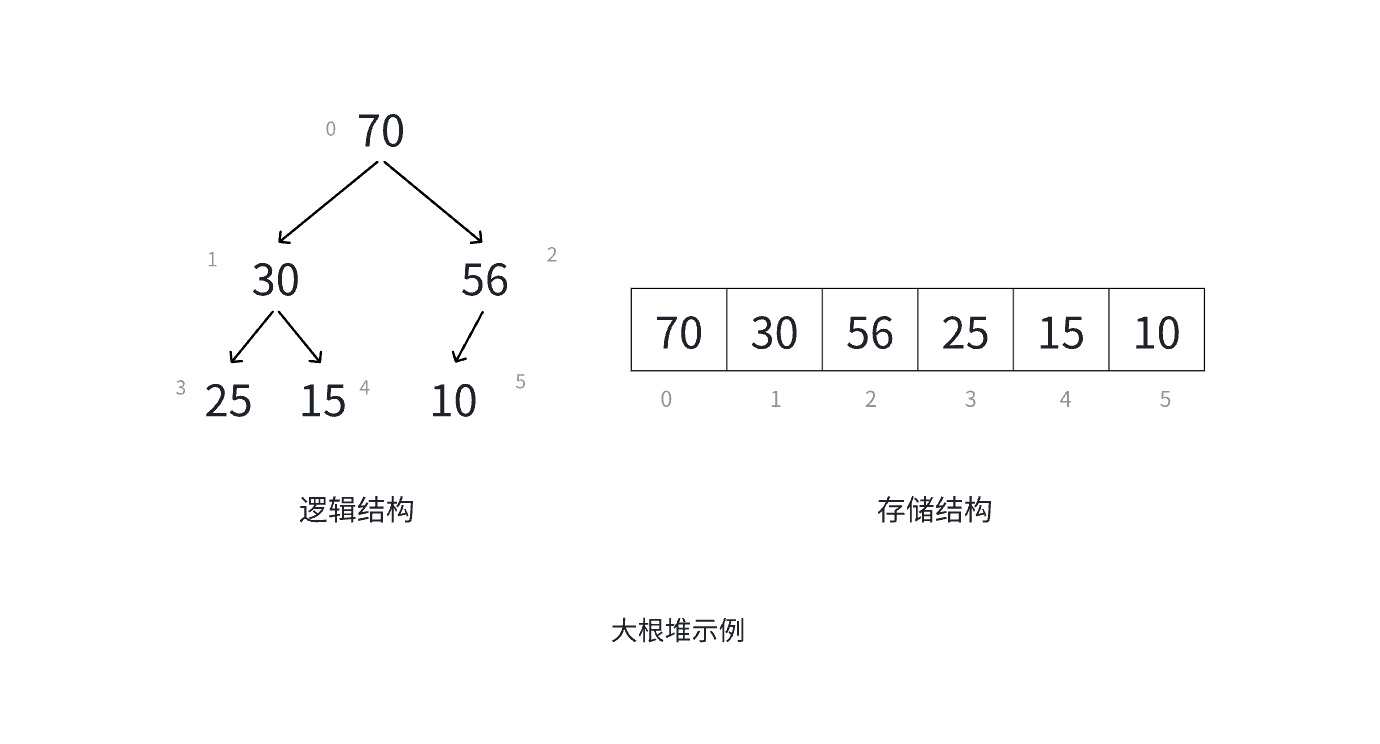
堆与二叉树的性质
堆具有以下性质:
- 堆中某个结点的值总是不大于或不小于其父结点的值;
- 堆总是一棵完全二叉树。
二叉树性质
对于具有 n n n个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有结点从 0 0 0 开始编号,则对于序号为 i i i 的结点有:
- 若 i > 0 i>0 i>0, i i i 位置结点的双亲序号: i − 1 2 \dfrac{i-1}{2} 2i−1(向下取整); i = 0 i=0 i=0, i i i 为根结点编号,无双亲结点。
- 若 2 i + 1 < n 2i+1<n 2i+1<n,左孩子序号: 2 i + 1 2i+1 2i+1; 2 i + 1 ≥ n 2i+1\geq n 2i+1≥n 则无左孩子。
- 若 2 i + 2 < n 2i+2<n 2i+2<n,右孩子序号: 2 i + 2 2i+2 2i+2; 2 i + 2 ≥ n 2i+2\geq n 2i+2≥n 则无右孩子。
堆的实现
堆底层结构为数组,因此定义堆的结构为:
- 头文件
c
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
//定义堆结构
typedef int HPDataType;
typedef struct Heap {
HPDataType* arr;
int size; //有效数据个数
int capaicty;//空间大小
}HP;
void HPInit(HP* php);
void HPDesTroy(HP* php);
void HPPrint(HP* php);
void Swap(int* x, int* y);
//向下调整算法
void AdjustDown(HPDataType* arr, int parent, int n);
//向上调整算法
void AdjustUp(HPDataType* arr, int child);
void HPPush(HP* php, HPDataType x);
void HPPop(HP* php);
HPDataType HPTop(HP* php);
bool HPEmpty(HP* php);定义堆结构
因为底层选型是数组,跟之前的顺序表一样,因此不再赘述
c
//定义堆结构
typedef int HPDataType;
typedef struct Heap {
HPDataType* arr;
int size; //有效数据个数
int capaicty;//空间大小
}HP;堆的初始化,销毁,打印
不再赘述
c
#include"Heap.h"
void HPInit(HP* php)
{
assert(php);
php->arr = NULL;
php->size = php->capaicty = 0;
}
void HPDesTroy(HP* php)
{
assert(php);
if (php->arr)
free(php->arr);
php->arr = NULL;
php->size = php->capaicty = 0;
}
void HPPrint(HP* php)
{
for (int i = 0; i < php->size; i++)
{
printf("%d ", php->arr[i]);
}
printf("\n");
}
void Swap(int* x, int* y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}向上调整算法
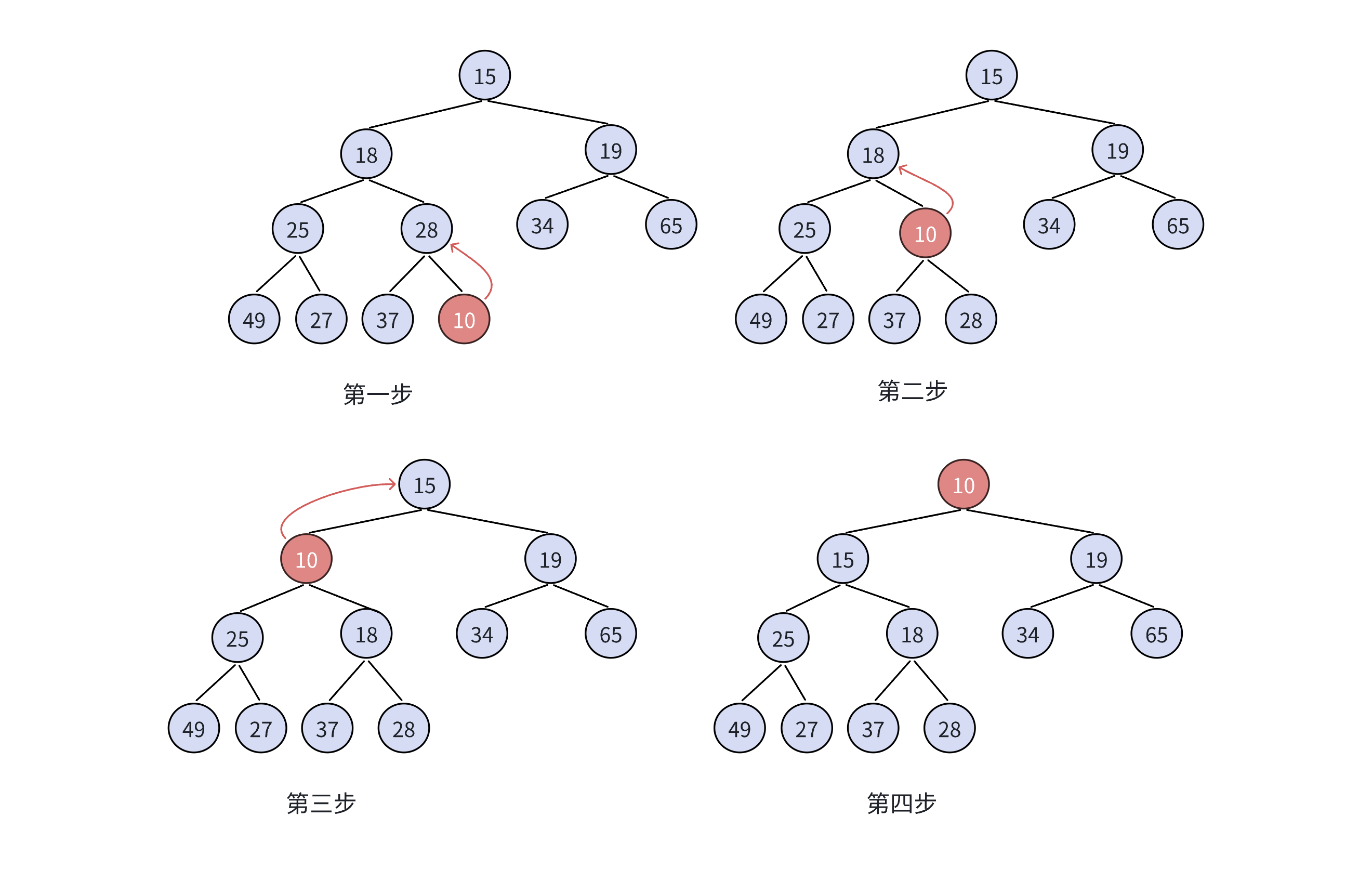
堆的插入
将新数据插入到数组的尾上,再进行向上调整算法,直到满足堆。
向上调整算法有一个前提:在新数据之上的左右子树必须是一个堆,才能调整。
向上调整算法
- 先将元素插入到堆的末尾,即最后一个孩子之后
- 插入之后如果堆的性质遭到破坏,将新插入结点顺着其双双亲往上调整到合适位置即可
c
//向上调整算法logn
void AdjustUp(HPDataType* arr, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
//建大堆:>
//建小堆: <
if (arr[child] < arr[parent])
{
Swap(&arr[child], &arr[parent]);
child = parent;
parent = (child - 1) / 2;
}
else {
break;
}
}
}时间复杂的:logn
堆的插入
堆的插入
c
void HPPush(HP* php, HPDataType x)
{
assert(php);
//空间不够要增容
if (php->size == php->capaicty)
{
//增容
int newCapacity = php->capaicty == 0 ? 4 : 2 * php->capaicty;
HPDataType* tmp = (HPDataType*)realloc(php->arr, newCapacity * sizeof(HPDataType));
if (tmp == NULL)
{
perror("realloc fail!");
exit(1);
}
php->arr = tmp;
php->capaicty = newCapacity;
}
//空间足够
php->arr[php->size] = x;
//向上调整
AdjustUp(php->arr, php->size);
++php->size;
}向下调整算法
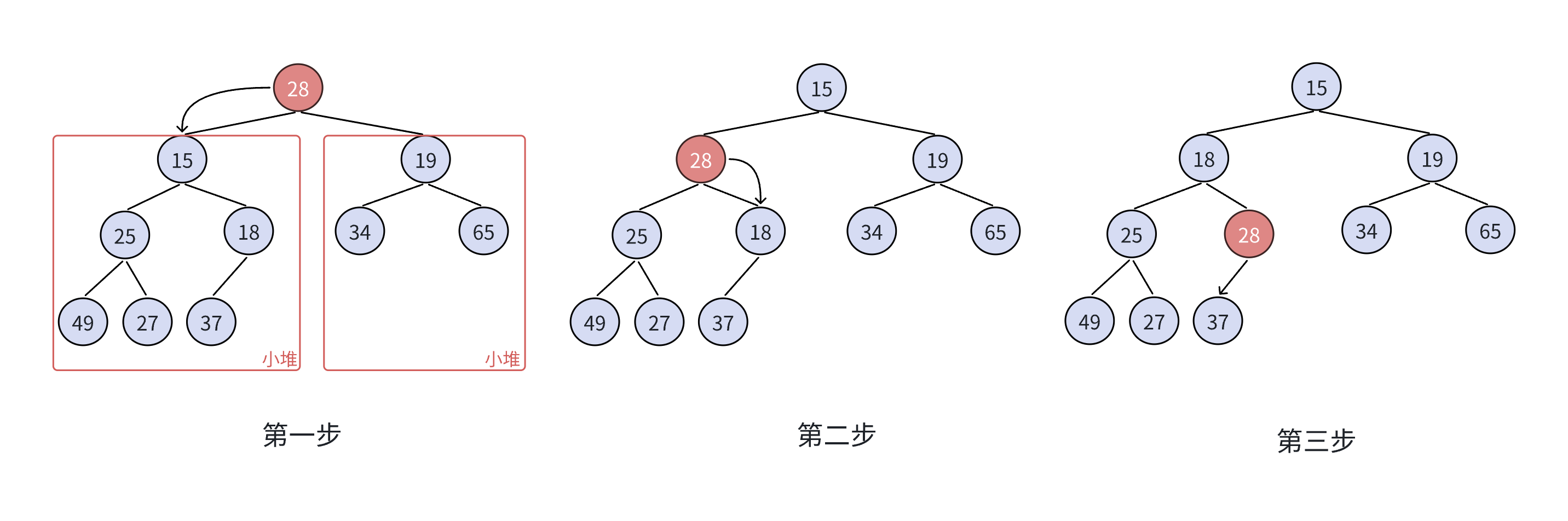
堆的删除(出堆)
删除堆是删除堆顶的数据,将堆顶的数据根最后一个数据一换,然后删除数组最后一个数据,再进行向下调整算法。
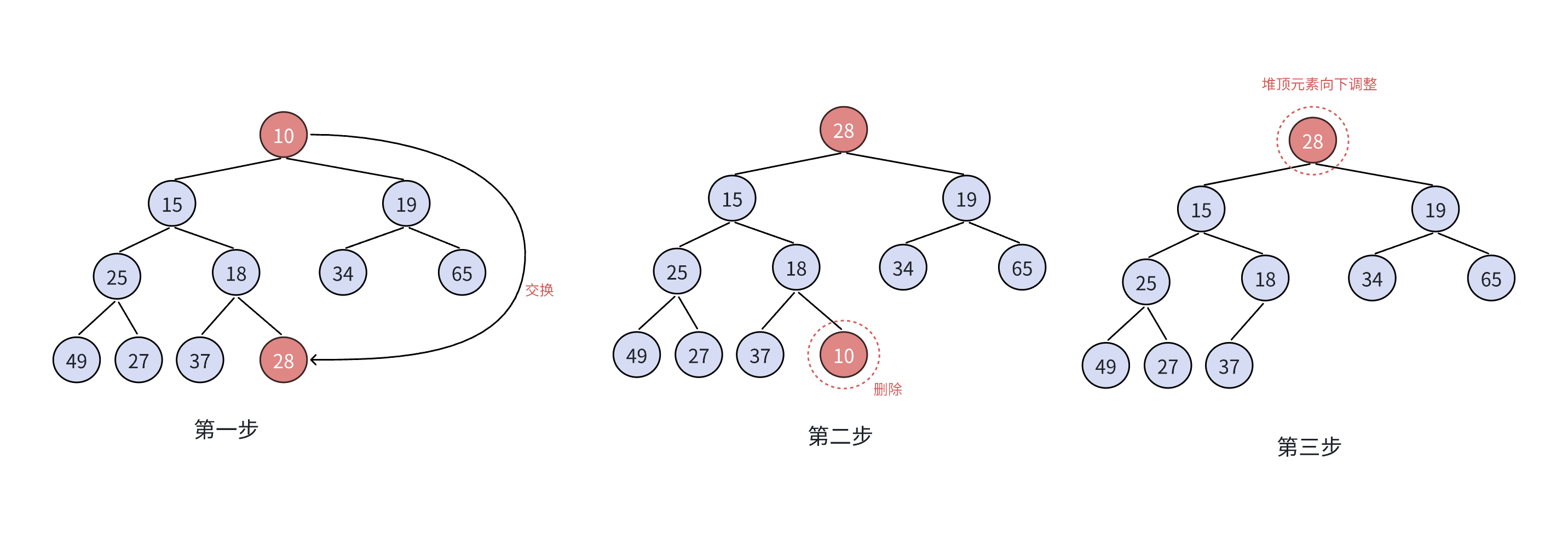
向下调整算法有一个前提:要调整的堆顶之下的左右子树必须是一个堆,才能调整。
向下调整算法
- 将堆顶元素与堆中最后一个元素进行交换
- 删除堆中最后一个元素
- 将堆顶元素向下调整到满足堆特性为止
c
//向下调整算法 logn
void AdjustDown(HPDataType* arr, int parent, int n)
{
int child = parent * 2 + 1;
while (child < n)
{
//建大堆:<
//建小堆: >
if (child + 1 < n && arr[child] > arr[child + 1])
{
child++;
}
//孩子和父亲比较
//建大堆:>
//建小堆:<
if (arr[child] < arr[parent])
{
Swap(&arr[child], &arr[parent]);
parent = child;
child = parent * 2 + 1;
}
else {
break;
}
}
}时间复杂的:logn
parent:父结点,从哪里开始向下调整
n:调整范围的结点个数
堆的删除
c
void HPPop(HP* php)
{
assert(!HPEmpty(php));
Swap(&php->arr[0], &php->arr[php->size - 1]);
--php->size;
//堆顶数据需要向下调整
AdjustDown(php->arr, 0, php->size);
}堆的判空
c
bool HPEmpty(HP* php)
{
assert(php);
return php->size == 0;
}取堆顶
c
HPDataType HPTop(HP* php)
{
assert(!HPEmpty(php));
return php->arr[0];
}堆排序
随便给定一个乱序数组,用堆排序的思想解决
向上调整算法建堆
向上调整算法思想
c
//向上调整算法建堆O(n*logn)
for (int i = 0; i < n; i++)
{
AdjustUp(arr, i);
}计算向上调整算法建堆时间复杂度
向上调整建堆 错位相减完整推导
原式①:
T ( h ) = 2 1 ⋅ 1 + 2 2 ⋅ 2 + 2 3 ⋅ 3 + ⋯ + 2 h − 2 ⋅ ( h − 2 ) + 2 h − 1 ⋅ ( h − 1 ) (①) T(h)=2^1 \cdot 1+2^2 \cdot 2+2^3 \cdot 3+\dots+2^{h-2} \cdot (h-2)+2^{h-1} \cdot (h-1) \tag{①} T(h)=21⋅1+22⋅2+23⋅3+⋯+2h−2⋅(h−2)+2h−1⋅(h−1)(①)
同乘 2 得式②:
2 T ( h ) = 2 2 ⋅ 1 + 2 3 ⋅ 2 + 2 4 ⋅ 3 + ⋯ + 2 h − 1 ⋅ ( h − 2 ) + 2 h ⋅ ( h − 1 ) (②) 2T(h)=2^2 \cdot 1+2^3 \cdot 2+2^4 \cdot 3+\dots+2^{h-1} \cdot (h-2)+2^h \cdot (h-1) \tag{②} 2T(h)=22⋅1+23⋅2+24⋅3+⋯+2h−1⋅(h−2)+2h⋅(h−1)(②)
② − - − ① 错位相减:
2 T ( h ) − T ( h ) = − 2 1 ⋅ 1 − 2 2 − 2 3 − ⋯ − 2 h − 1 + 2 h ( h − 1 ) T ( h ) = 2 h ( h − 1 ) − ( 2 1 + 2 2 + 2 3 + ⋯ + 2 h − 1 ) \begin{aligned} 2T(h)-T(h) &= -2^1\cdot1 - 2^2 - 2^3 - \dots - 2^{h-1} + 2^h(h-1) \\ T(h) &= 2^h(h-1) - \big(2^1+2^2+2^3+\dots+2^{h-1}\big) \end{aligned} 2T(h)−T(h)T(h)=−21⋅1−22−23−⋯−2h−1+2h(h−1)=2h(h−1)−(21+22+23+⋯+2h−1)
等比数列求和:
2 1 + 2 2 + ⋯ + 2 h − 1 = 2 h − 2 2^1+2^2+\dots+2^{h-1} = 2^h - 2 21+22+⋯+2h−1=2h−2
代入化简:
T ( h ) = 2 h ( h − 1 ) − ( 2 h − 2 ) = h ⋅ 2 h − 2 h − 2 h + 2 = h ⋅ 2 h − 2 h + 1 + 2 \begin{aligned} T(h) &= 2^h(h-1) - (2^h - 2) \\ &= h\cdot 2^h - 2^h - 2^h + 2 \\ &= h\cdot 2^h - 2^{h+1} + 2 \end{aligned} T(h)=2h(h−1)−(2h−2)=h⋅2h−2h−2h+2=h⋅2h−2h+1+2
T ( h ) = 2 h ( h − 2 ) + 2 T(h) = 2^h(h-2) + 2 T(h)=2h(h−2)+2
根据二叉树的性质:
n = 2 h − 1 , h = log 2 ( n + 1 ) n = 2^h - 1,\quad h = \log_2(n+1) n=2h−1,h=log2(n+1)
把h换形成n,注意这里变换对应法则,不换自变量(T(h)不将h换成n)
F ( n ) = ( n + 1 ) ( log 2 ( n + 1 ) − 2 ) + 2 F(n) = (n+1)\big(\log_2(n+1) - 2\big) + 2 F(n)=(n+1)(log2(n+1)−2)+2
F ( n ) = O ( n log 2 n ) F(n) = O(n\log_2 n) F(n)=O(nlog2n)
向下调整算法建堆
向下调整算法思想
c
//向下调整算法------建堆O(n)
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(arr, i, n);
}计算向下调整算法建堆时间复杂度
第1层, 2 0 2^0 20 个结点,需要向下移动 h − 1 h-1 h−1 层
第2层, 2 1 2^1 21 个结点,需要向下移动 h − 2 h-2 h−2 层
第3层, 2 2 2^2 22 个结点,需要向下移动 h − 3 h-3 h−3 层
第4层, 2 3 2^3 23 个结点,需要向下移动 h − 4 h-4 h−4 层
... \dots ...
第 h − 1 h-1 h−1层, 2 h − 2 2^{h-2} 2h−2 个结点,需要向下移动 1 1 1 层
需要移动结点总的移动步数为:每层结点个数 × \times × 向下调整次数
T ( h ) = 2 0 ( h − 1 ) + 2 1 ( h − 2 ) + 2 2 ( h − 3 ) + 2 3 ( h − 4 ) + ⋯ + 2 h − 3 ⋅ 2 + 2 h − 2 ⋅ 1 T(h)=2^0 (h-1)+2^1 (h-2)+2^2 (h-3)+2^3 (h-4)+\dots+2^{h-3} \cdot 2+2^{h-2} \cdot 1 T(h)=20(h−1)+21(h−2)+22(h−3)+23(h−4)+⋯+2h−3⋅2+2h−2⋅1
同乘 2:
2 T ( h ) = 2 1 ( h − 1 ) + 2 2 ( h − 2 ) + 2 3 ( h − 3 ) + 2 4 ( h − 4 ) + ⋯ + 2 h − 2 ⋅ 2 + 2 h − 1 ⋅ 1 2T(h)=2^1(h-1)+2^2(h-2)+2^3(h-3)+2^4(h-4)+\dots+2^{h-2}\cdot 2+2^{h-1}\cdot 1 2T(h)=21(h−1)+22(h−2)+23(h−3)+24(h−4)+⋯+2h−2⋅2+2h−1⋅1
错位相减:
T ( h ) = 1 − h + 2 1 + 2 2 + 2 3 + 2 4 + ⋯ + 2 h − 2 + 2 h − 1 T(h)=1-h+2^1+2^2+2^3+2^4+\dots+2^{h-2}+2^{h-1} T(h)=1−h+21+22+23+24+⋯+2h−2+2h−1
整理:
T ( h ) = 2 0 + 2 1 + 2 2 + 2 3 + 2 4 + ⋯ + 2 h − 2 + 2 h − 1 − h T(h)=2^0+2^1+2^2+2^3+2^4+\dots+2^{h-2}+2^{h-1}-h T(h)=20+21+22+23+24+⋯+2h−2+2h−1−h
等比数列求和化简:
T ( h ) = 2 h − 1 − h T(h)=2^h-1-h T(h)=2h−1−h
根据二叉树的性质:
n = 2 h − 1 , h = log 2 ( n + 1 ) n=2^h-1,\quad h=\log_2(n+1) n=2h−1,h=log2(n+1)
代入得:
F ( n ) = n − log 2 ( n + 1 ) ≈ n F(n)=n-\log_2(n+1) \approx n F(n)=n−log2(n+1)≈n
向下调整算法建堆时间复杂度为:
O ( n ) O(n) O(n)
堆排序的实现
数组建堆,首尾交换,交换后的堆尾数据从堆中删掉,将堆顶数据向下调整选出次大的数据
c
//堆排序------------使用的是堆结构的思想 n * logn
void HeapSort(int* arr, int n)
{
//向下调整算法------建堆O(n)
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(arr, i, n);
}
////向上调整算法建堆O(n*logn)
//for (int i = 0; i < n; i++)
//{
// AdjustUp(arr, i);
//}
//n*logn
int end = n - 1;
while (end > 0)
{
Swap(&arr[0], &arr[end]);
AdjustDown(arr, 0, end);//logn
end--;
}
}堆排序时间复杂度计算
通过分析发现,堆排序第二个循环中的向下调整,与建堆中的向上调整算法时间复杂度计算一致(也是求和) ,此处不再赘述。(建堆默认向下调整思想)
因此,堆排序总的时间复杂度为:
O ( n + n log n ) O(n + n\log n) O(n+nlogn)
化简可得堆排序最终时间复杂度:
O ( n log n ) O(n\log n) O(nlogn)
TOP-K问题
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能数据都不能一下子全部加载到内存中)。
最佳的方式就是用堆来解决,基本思路如下:
1)用数据集合中前K个元素来建堆
- 前k个最大的元素,则建小堆 (因为堆顶永远是最小的,通过排出堆顶小元素,存住堆顶下面的大元素,即可用有限的空间找出海量大数据的小元素)
- 前k个最小的元素,则建大堆
2)用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素
将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素
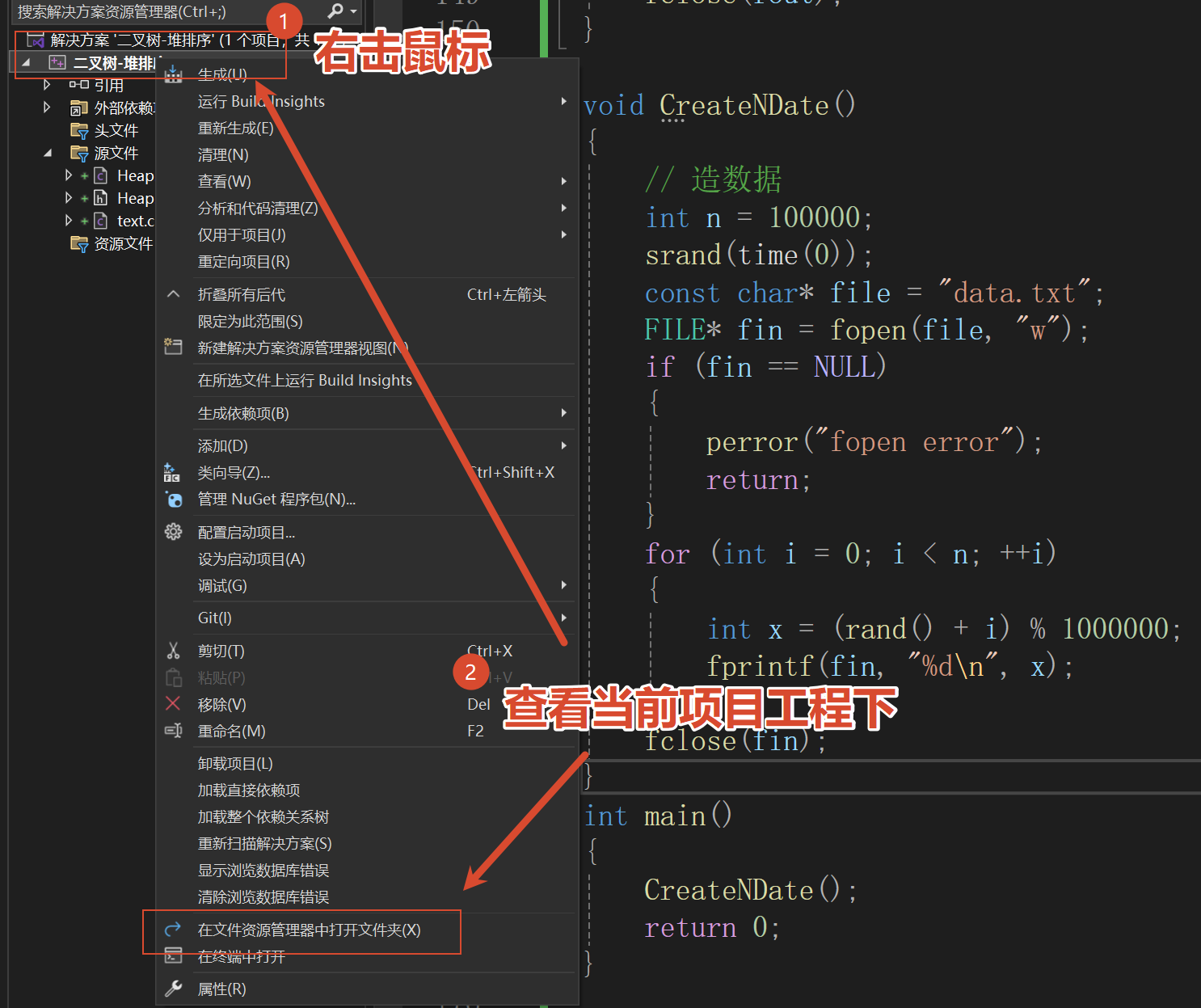
造十万个数据
c
void CreateNDate()
{
// 造数据
int n = 100000;
srand(time(0));
const char* file = "data.txt";
FILE* fin = fopen(file, "w");
if (fin == NULL)
{
perror("fopen error");
return;
}
for (int i = 0; i < n; ++i)
{
int x = (rand() + i) % 1000000;
fprintf(fin, "%d\n", x);
}
fclose(fin);
}
TOP-K代码
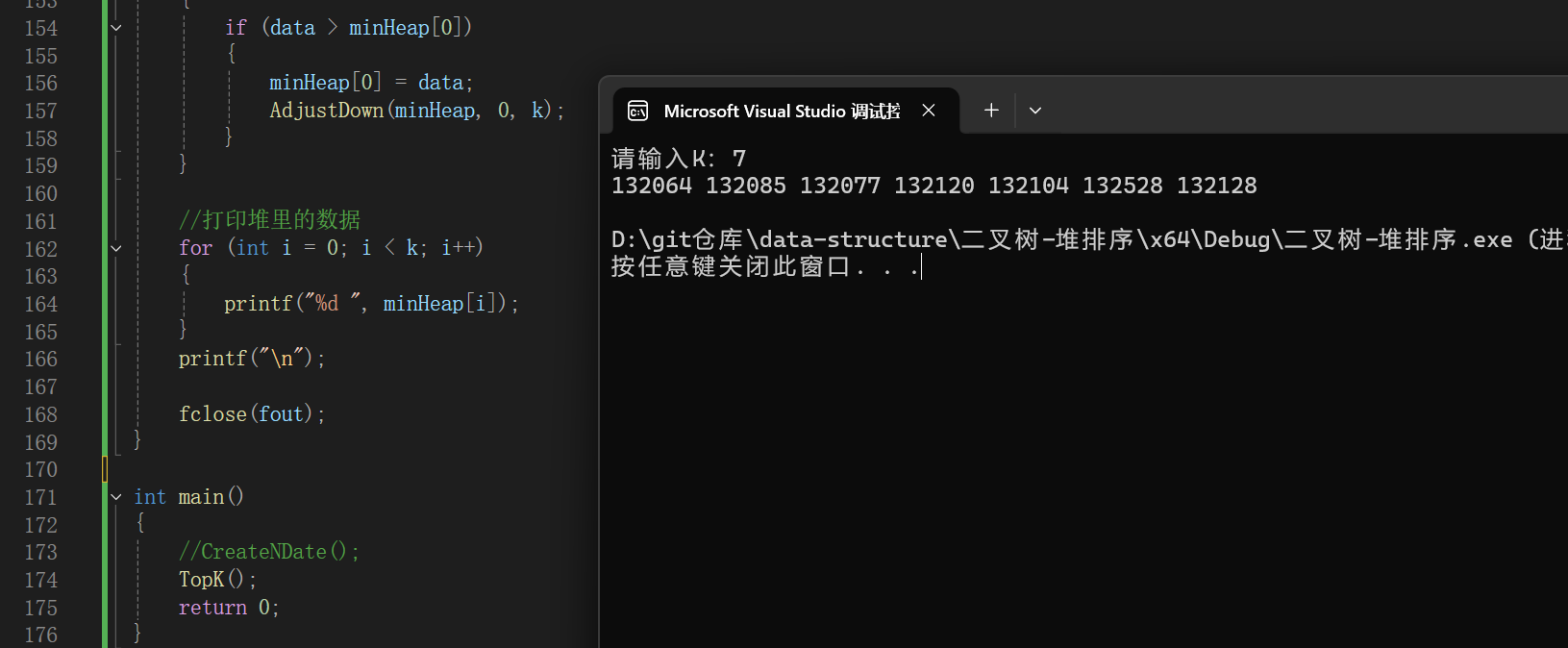
c
void TopK()
{
int k = 0;
printf("请输入K:");
scanf("%d", &k);
const char* file = "data.txt";
FILE* fout = fopen(file, "r");
if (fout == NULL)
{
perror("fopen fail!");
exit(1);
}
//申请空间大小为k的整型数组
int* minHeap = (int*)malloc(sizeof(int) * k);
if (minHeap == NULL)
{
perror("malloc fail!");
exit(2);
}
//读取文件中k个数据放到数组中
for (int i = 0; i < k; i++)
{
fscanf(fout, "%d", &minHeap[i]);
}
//数组调整建堆--向下调整建堆
//找最大的前K个数,建小堆
for (int i = (k - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(minHeap, i, k);
}
//遍历剩下的n-k个数,跟堆顶比较,谁大谁入堆
int data = 0;
while (fscanf(fout, "%d", &data) != EOF)
{
if (data > minHeap[0])
{
minHeap[0] = data;
AdjustDown(minHeap, 0, k);
}
}
//打印堆里的数据
for (int i = 0; i < k; i++)
{
printf("%d ", minHeap[i]);
}
printf("\n");
fclose(fout);
}
时间复杂度:(默认向下调整)
O ( n ) = k + ( n − k ) log 2 k O(n) = k + (n-k)\log_2 k O(n)=k+(n−k)log2k
空间足够的话
O ( n log k ) O(n\log k) O(nlogk) 看似永远优于全部建堆排序: O ( n log n ) O(n\log n) O(nlogn)
其实不然,仔细学习我前面的思路你会发现,堆排序浪费时间的地方其实是出堆,而全部建堆排序只需要出堆 K K K次,所以
n + k log n ≪ n log k \boldsymbol{n + k\log n \;\ll\; n\log k} n+klogn≪nlogk
时间 :全部建堆排序 ≪ \ll\; ≪ TOP-K
所以在空间无限,全局建堆未尝不可!!!