💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
本文给大家带来的教程是将YOLO26的主干网络替换为RMT 来提取特征 。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改 ,并将修改后的完整代码 放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
专栏地址:YOLO26改进-论文涨点------点击跳转看所有内容,关注不迷路!****
目录
[2. RMT代码实现](#2. RMT代码实现)
[2.1 将RMT添加到YOLO26中](#2.1 将RMT添加到YOLO26中)
[2.2 更改init.py文件](#2.2 更改init.py文件)
[2.3 添加yaml文件](#2.3 添加yaml文件)
[2.4 在task.py中进行注册](#2.4 在task.py中进行注册)
[2.5 执行程序](#2.5 执行程序)
[3. 完整代码分享](#3. 完整代码分享)
[4. GFLOPs](#4. GFLOPs)
[5. 进阶](#5. 进阶)
1.论文

论文地址: RMT:Retentive Networks Meet Vision Transformers
官方代码: 官方代码仓库点击即可跳转
2. RMT代码实现
2.1 将RMT添加到YOLO26中
**关键步骤一:**在ultralytics\ultralytics\nn\modules下面新建文件夹models,在文件夹下新建RMT.py,粘贴下面代码
python
import torch
import torch.nn as nn
from torch.nn.common_types import _size_2_t
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
import math
import torch
import torch.nn.functional as F
import torch.nn as nn
from timm.models.layers import DropPath, trunc_normal_
from timm.models.vision_transformer import VisionTransformer
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
from typing import Tuple, Union
from functools import partial
__all__ = ['RMT_T', 'RMT_S', 'RMT_B', 'RMT_L']
class DWConv2d(nn.Module):
def __init__(self, dim, kernel_size, stride, padding):
super().__init__()
self.conv = nn.Conv2d(dim, dim, kernel_size, stride, padding, groups=dim)
def forward(self, x: torch.Tensor):
'''
x: (b h w c)
'''
x = x.permute(0, 3, 1, 2) #(b c h w)
x = self.conv(x) #(b c h w)
x = x.permute(0, 2, 3, 1) #(b h w c)
return x
class RelPos2d(nn.Module):
def __init__(self, embed_dim, num_heads, initial_value, heads_range):
'''
recurrent_chunk_size: (clh clw)
num_chunks: (nch ncw)
clh * clw == cl
nch * ncw == nc
default: clh==clw, clh != clw is not implemented
'''
super().__init__()
angle = 1.0 / (10000 ** torch.linspace(0, 1, embed_dim // num_heads // 2))
angle = angle.unsqueeze(-1).repeat(1, 2).flatten()
self.initial_value = initial_value
self.heads_range = heads_range
self.num_heads = num_heads
decay = torch.log(1 - 2 ** (-initial_value - heads_range * torch.arange(num_heads, dtype=torch.float) / num_heads))
self.register_buffer('angle', angle)
self.register_buffer('decay', decay)
def generate_2d_decay(self, H: int, W: int):
'''
generate 2d decay mask, the result is (HW)*(HW)
'''
index_h = torch.arange(H).to(self.decay)
index_w = torch.arange(W).to(self.decay)
grid = torch.meshgrid([index_h, index_w])
grid = torch.stack(grid, dim=-1).reshape(H*W, 2) #(H*W 2)
mask = grid[:, None, :] - grid[None, :, :] #(H*W H*W 2)
mask = (mask.abs()).sum(dim=-1)
mask = mask * self.decay[:, None, None] #(n H*W H*W)
return mask
def generate_1d_decay(self, l: int):
'''
generate 1d decay mask, the result is l*l
'''
index = torch.arange(l).to(self.decay)
mask = index[:, None] - index[None, :] #(l l)
mask = mask.abs() #(l l)
mask = mask * self.decay[:, None, None] #(n l l)
return mask
def forward(self, slen: Tuple[int], activate_recurrent=False, chunkwise_recurrent=False):
'''
slen: (h, w)
h * w == l
recurrent is not implemented
'''
if activate_recurrent:
retention_rel_pos = self.decay.exp()
elif chunkwise_recurrent:
mask_h = self.generate_1d_decay(slen[0])
mask_w = self.generate_1d_decay(slen[1])
retention_rel_pos = (mask_h, mask_w)
else:
mask = self.generate_2d_decay(slen[0], slen[1]) #(n l l)
retention_rel_pos = mask
return retention_rel_pos
class MaSAd(nn.Module):
def __init__(self, embed_dim, num_heads, value_factor=1):
super().__init__()
self.factor = value_factor
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = self.embed_dim * self.factor // num_heads
self.key_dim = self.embed_dim // num_heads
self.scaling = self.key_dim ** -0.5
self.q_proj = nn.Linear(embed_dim, embed_dim, bias=True)
self.k_proj = nn.Linear(embed_dim, embed_dim, bias=True)
self.v_proj = nn.Linear(embed_dim, embed_dim * self.factor, bias=True)
self.lepe = DWConv2d(embed_dim, 5, 1, 2)
self.out_proj = nn.Linear(embed_dim*self.factor, embed_dim, bias=True)
self.reset_parameters()
def reset_parameters(self):
nn.init.xavier_normal_(self.q_proj.weight, gain=2 ** -2.5)
nn.init.xavier_normal_(self.k_proj.weight, gain=2 ** -2.5)
nn.init.xavier_normal_(self.v_proj.weight, gain=2 ** -2.5)
nn.init.xavier_normal_(self.out_proj.weight)
nn.init.constant_(self.out_proj.bias, 0.0)
def forward(self, x: torch.Tensor, rel_pos, chunkwise_recurrent=False, incremental_state=None):
'''
x: (b h w c)
mask_h: (n h h)
mask_w: (n w w)
'''
bsz, h, w, _ = x.size()
mask_h, mask_w = rel_pos
q = self.q_proj(x)
k = self.k_proj(x)
v = self.v_proj(x)
lepe = self.lepe(v)
k *= self.scaling
qr = q.view(bsz, h, w, self.num_heads, self.key_dim).permute(0, 3, 1, 2, 4) #(b n h w d1)
kr = k.view(bsz, h, w, self.num_heads, self.key_dim).permute(0, 3, 1, 2, 4) #(b n h w d1)
'''
qr: (b n h w d1)
kr: (b n h w d1)
v: (b h w n*d2)
'''
qr_w = qr.transpose(1, 2) #(b h n w d1)
kr_w = kr.transpose(1, 2) #(b h n w d1)
v = v.reshape(bsz, h, w, self.num_heads, -1).permute(0, 1, 3, 2, 4) #(b h n w d2)
qk_mat_w = qr_w @ kr_w.transpose(-1, -2) #(b h n w w)
qk_mat_w = qk_mat_w + mask_w #(b h n w w)
qk_mat_w = torch.softmax(qk_mat_w, -1) #(b h n w w)
v = torch.matmul(qk_mat_w, v) #(b h n w d2)
qr_h = qr.permute(0, 3, 1, 2, 4) #(b w n h d1)
kr_h = kr.permute(0, 3, 1, 2, 4) #(b w n h d1)
v = v.permute(0, 3, 2, 1, 4) #(b w n h d2)
qk_mat_h = qr_h @ kr_h.transpose(-1, -2) #(b w n h h)
qk_mat_h = qk_mat_h + mask_h #(b w n h h)
qk_mat_h = torch.softmax(qk_mat_h, -1) #(b w n h h)
output = torch.matmul(qk_mat_h, v) #(b w n h d2)
output = output.permute(0, 3, 1, 2, 4).flatten(-2, -1) #(b h w n*d2)
output = output + lepe
output = self.out_proj(output)
return output
class MaSA(nn.Module):
def __init__(self, embed_dim, num_heads, value_factor=1):
super().__init__()
self.factor = value_factor
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = self.embed_dim * self.factor // num_heads
self.key_dim = self.embed_dim // num_heads
self.scaling = self.key_dim ** -0.5
self.q_proj = nn.Linear(embed_dim, embed_dim, bias=True)
self.k_proj = nn.Linear(embed_dim, embed_dim, bias=True)
self.v_proj = nn.Linear(embed_dim, embed_dim * self.factor, bias=True)
self.lepe = DWConv2d(embed_dim, 5, 1, 2)
self.out_proj = nn.Linear(embed_dim*self.factor, embed_dim, bias=True)
self.reset_parameters()
def reset_parameters(self):
nn.init.xavier_normal_(self.q_proj.weight, gain=2 ** -2.5)
nn.init.xavier_normal_(self.k_proj.weight, gain=2 ** -2.5)
nn.init.xavier_normal_(self.v_proj.weight, gain=2 ** -2.5)
nn.init.xavier_normal_(self.out_proj.weight)
nn.init.constant_(self.out_proj.bias, 0.0)
def forward(self, x: torch.Tensor, rel_pos, chunkwise_recurrent=False, incremental_state=None):
'''
x: (b h w c)
rel_pos: mask: (n l l)
'''
bsz, h, w, _ = x.size()
mask = rel_pos
assert h*w == mask.size(1)
q = self.q_proj(x)
k = self.k_proj(x)
v = self.v_proj(x)
lepe = self.lepe(v)
k *= self.scaling
qr = q.view(bsz, h, w, self.num_heads, -1).permute(0, 3, 1, 2, 4) #(b n h w d1)
kr = k.view(bsz, h, w, self.num_heads, -1).permute(0, 3, 1, 2, 4) #(b n h w d1)
qr = qr.flatten(2, 3) #(b n l d1)
kr = kr.flatten(2, 3) #(b n l d1)
vr = v.reshape(bsz, h, w, self.num_heads, -1).permute(0, 3, 1, 2, 4) #(b n h w d2)
vr = vr.flatten(2, 3) #(b n l d2)
qk_mat = qr @ kr.transpose(-1, -2) #(b n l l)
qk_mat = qk_mat + mask #(b n l l)
qk_mat = torch.softmax(qk_mat, -1) #(b n l l)
output = torch.matmul(qk_mat, vr) #(b n l d2)
output = output.transpose(1, 2).reshape(bsz, h, w, -1) #(b h w n*d2)
output = output + lepe
output = self.out_proj(output)
return output
class FeedForwardNetwork(nn.Module):
def __init__(
self,
embed_dim,
ffn_dim,
activation_fn=F.gelu,
dropout=0.0,
activation_dropout=0.0,
layernorm_eps=1e-6,
subln=False,
subconv=False
):
super().__init__()
self.embed_dim = embed_dim
self.activation_fn = activation_fn
self.activation_dropout_module = torch.nn.Dropout(activation_dropout)
self.dropout_module = torch.nn.Dropout(dropout)
self.fc1 = nn.Linear(self.embed_dim, ffn_dim)
self.fc2 = nn.Linear(ffn_dim, self.embed_dim)
self.ffn_layernorm = nn.LayerNorm(ffn_dim, eps=layernorm_eps) if subln else None
self.dwconv = DWConv2d(ffn_dim, 3, 1, 1) if subconv else None
def reset_parameters(self):
self.fc1.reset_parameters()
self.fc2.reset_parameters()
if self.ffn_layernorm is not None:
self.ffn_layernorm.reset_parameters()
def forward(self, x: torch.Tensor):
'''
x: (b h w c)
'''
x = self.fc1(x)
x = self.activation_fn(x)
x = self.activation_dropout_module(x)
if self.dwconv is not None:
residual = x
x = self.dwconv(x)
x = x + residual
if self.ffn_layernorm is not None:
x = self.ffn_layernorm(x)
x = self.fc2(x)
x = self.dropout_module(x)
return x
class RetBlock(nn.Module):
def __init__(self, retention: str, embed_dim: int, num_heads: int, ffn_dim: int, drop_path=0., layerscale=False, layer_init_values=1e-5):
super().__init__()
self.layerscale = layerscale
self.embed_dim = embed_dim
self.retention_layer_norm = nn.LayerNorm(self.embed_dim, eps=1e-6)
assert retention in ['chunk', 'whole']
if retention == 'chunk':
self.retention = MaSAd(embed_dim, num_heads)
else:
self.retention = MaSA(embed_dim, num_heads)
self.drop_path = DropPath(drop_path)
self.final_layer_norm = nn.LayerNorm(self.embed_dim, eps=1e-6)
self.ffn = FeedForwardNetwork(embed_dim, ffn_dim)
self.pos = DWConv2d(embed_dim, 3, 1, 1)
if layerscale:
self.gamma_1 = nn.Parameter(layer_init_values * torch.ones(1, 1, 1, embed_dim),requires_grad=True)
self.gamma_2 = nn.Parameter(layer_init_values * torch.ones(1, 1, 1, embed_dim),requires_grad=True)
def forward(
self,
x: torch.Tensor,
incremental_state=None,
chunkwise_recurrent=False,
retention_rel_pos=None
):
x = x + self.pos(x)
if self.layerscale:
x = x + self.drop_path(self.gamma_1 * self.retention(self.retention_layer_norm(x), retention_rel_pos, chunkwise_recurrent, incremental_state))
x = x + self.drop_path(self.gamma_2 * self.ffn(self.final_layer_norm(x)))
else:
x = x + self.drop_path(self.retention(self.retention_layer_norm(x), retention_rel_pos, chunkwise_recurrent, incremental_state))
x = x + self.drop_path(self.ffn(self.final_layer_norm(x)))
return x
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, out_dim, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.reduction = nn.Conv2d(dim, out_dim, 3, 2, 1)
self.norm = nn.BatchNorm2d(out_dim)
def forward(self, x):
'''
x: B H W C
'''
x = x.permute(0, 3, 1, 2).contiguous() #(b c h w)
x = self.reduction(x) #(b oc oh ow)
x = self.norm(x)
x = x.permute(0, 2, 3, 1) #(b oh ow oc)
return x
class BasicLayer(nn.Module):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
fused_window_process (bool, optional): If True, use one kernel to fused window shift & window partition for acceleration, similar for the reversed part. Default: False
"""
def __init__(self, embed_dim, out_dim, depth, num_heads,
init_value: float, heads_range: float,
ffn_dim=96., drop_path=0., norm_layer=nn.LayerNorm, chunkwise_recurrent=False,
downsample: PatchMerging=None, use_checkpoint=False,
layerscale=False, layer_init_values=1e-5):
super().__init__()
self.embed_dim = embed_dim
self.depth = depth
self.use_checkpoint = use_checkpoint
self.chunkwise_recurrent = chunkwise_recurrent
if chunkwise_recurrent:
flag = 'chunk'
else:
flag = 'whole'
self.Relpos = RelPos2d(embed_dim, num_heads, init_value, heads_range)
# build blocks
self.blocks = nn.ModuleList([
RetBlock(flag, embed_dim, num_heads, ffn_dim,
drop_path[i] if isinstance(drop_path, list) else drop_path, layerscale, layer_init_values)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(dim=embed_dim, out_dim=out_dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x):
b, h, w, d = x.size()
rel_pos = self.Relpos((h, w), chunkwise_recurrent=self.chunkwise_recurrent)
for blk in self.blocks:
if self.use_checkpoint:
tmp_blk = partial(blk, incremental_state=None, chunkwise_recurrent=self.chunkwise_recurrent, retention_rel_pos=rel_pos)
x = checkpoint.checkpoint(tmp_blk, x)
else:
x = blk(x, incremental_state=None, chunkwise_recurrent=self.chunkwise_recurrent, retention_rel_pos=rel_pos)
if self.downsample is not None:
x = self.downsample(x)
return x
class LayerNorm2d(nn.Module):
def __init__(self, dim):
super().__init__()
self.norm = nn.LayerNorm(dim, eps=1e-6)
def forward(self, x: torch.Tensor):
'''
x: (b c h w)
'''
x = x.permute(0, 2, 3, 1).contiguous() #(b h w c)
x = self.norm(x) #(b h w c)
x = x.permute(0, 3, 1, 2).contiguous()
return x
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Sequential(
nn.Conv2d(in_chans, embed_dim//2, 3, 2, 1),
nn.BatchNorm2d(embed_dim//2),
nn.GELU(),
nn.Conv2d(embed_dim//2, embed_dim//2, 3, 1, 1),
nn.BatchNorm2d(embed_dim//2),
nn.GELU(),
nn.Conv2d(embed_dim//2, embed_dim, 3, 2, 1),
nn.BatchNorm2d(embed_dim),
nn.GELU(),
nn.Conv2d(embed_dim, embed_dim, 3, 1, 1),
nn.BatchNorm2d(embed_dim)
)
def forward(self, x):
B, C, H, W = x.shape
x = self.proj(x).permute(0, 2, 3, 1) #(b h w c)
return x
class VisRetNet(nn.Module):
def __init__(self, in_chans=3, num_classes=1000,
embed_dims=[96, 192, 384, 768], depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
init_values=[1, 1, 1, 1], heads_ranges=[3, 3, 3, 3], mlp_ratios=[3, 3, 3, 3], drop_path_rate=0.1, norm_layer=nn.LayerNorm,
patch_norm=True, use_checkpoints=[False, False, False, False], chunkwise_recurrents=[True, True, False, False],
layerscales=[False, False, False, False], layer_init_values=1e-6):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dims[0]
self.patch_norm = patch_norm
self.num_features = embed_dims[-1]
self.mlp_ratios = mlp_ratios
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(in_chans=in_chans, embed_dim=embed_dims[0],
norm_layer=norm_layer if self.patch_norm else None)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(
embed_dim=embed_dims[i_layer],
out_dim=embed_dims[i_layer+1] if (i_layer < self.num_layers - 1) else None,
depth=depths[i_layer],
num_heads=num_heads[i_layer],
init_value=init_values[i_layer],
heads_range=heads_ranges[i_layer],
ffn_dim=int(mlp_ratios[i_layer]*embed_dims[i_layer]),
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
chunkwise_recurrent=chunkwise_recurrents[i_layer],
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoints[i_layer],
layerscale=layerscales[i_layer],
layer_init_values=layer_init_values
)
self.layers.append(layer)
self.width_list = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
try:
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
except:
pass
@torch.jit.ignore
def no_weight_decay(self):
return {'absolute_pos_embed'}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'relative_position_bias_table'}
def forward(self, x):
input_size = x.size(2)
scale = [4, 8, 16, 32]
features = [None, None, None, None]
x = self.patch_embed(x)
if input_size // x.size(2) in scale:
features[scale.index(input_size // x.size(2))] = x.permute(0, 3, 1, 2)
for layer in self.layers:
x = layer(x)
if input_size // x.size(2) in scale:
features[scale.index(input_size // x.size(2))] = x.permute(0, 3, 1, 2)
return features
def RMT_T():
model = VisRetNet(
embed_dims=[64, 128, 256, 512],
depths=[2, 2, 8, 2],
num_heads=[4, 4, 8, 16],
init_values=[2, 2, 2, 2],
heads_ranges=[4, 4, 6, 6],
mlp_ratios=[3, 3, 3, 3],
drop_path_rate=0.1,
chunkwise_recurrents=[True, True, False, False],
layerscales=[False, False, False, False]
)
model.default_cfg = _cfg()
return model
def RMT_S():
model = VisRetNet(
embed_dims=[64, 128, 256, 512],
depths=[3, 4, 18, 4],
num_heads=[4, 4, 8, 16],
init_values=[2, 2, 2, 2],
heads_ranges=[4, 4, 6, 6],
mlp_ratios=[4, 4, 3, 3],
drop_path_rate=0.15,
chunkwise_recurrents=[True, True, True, False],
layerscales=[False, False, False, False]
)
model.default_cfg = _cfg()
return model
def RMT_B():
model = VisRetNet(
embed_dims=[80, 160, 320, 512],
depths=[4, 8, 25, 8],
num_heads=[5, 5, 10, 16],
init_values=[2, 2, 2, 2],
heads_ranges=[5, 5, 6, 6],
mlp_ratios=[4, 4, 3, 3],
drop_path_rate=0.4,
chunkwise_recurrents=[True, True, True, False],
layerscales=[False, False, True, True],
layer_init_values=1e-6
)
model.default_cfg = _cfg()
return model
def RMT_L():
model = VisRetNet(
embed_dims=[112, 224, 448, 640],
depths=[4, 8, 25, 8],
num_heads=[7, 7, 14, 20],
init_values=[2, 2, 2, 2],
heads_ranges=[6, 6, 6, 6],
mlp_ratios=[4, 4, 3, 3],
drop_path_rate=0.5,
chunkwise_recurrents=[True, True, True, False],
layerscales=[False, False, True, True],
layer_init_values=1e-6
)
model.default_cfg = _cfg()
return model2.2 更改init.py文件
**关键步骤二:**在文件ultralytics\ultralytics\nn\modules\models文件夹下新建__init__.py文件,先导入函数
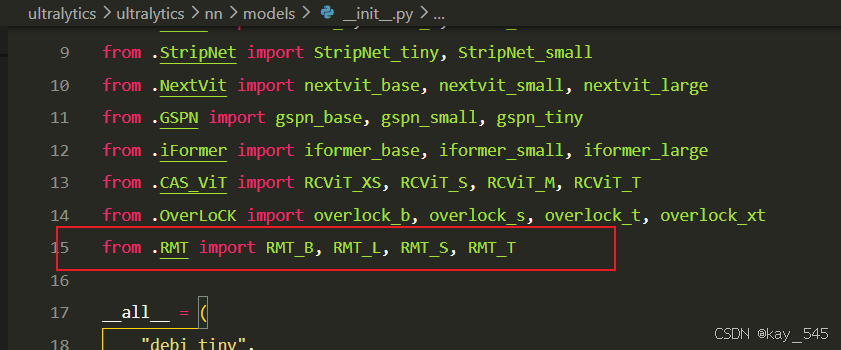
然后在下面的__all__中声明函数
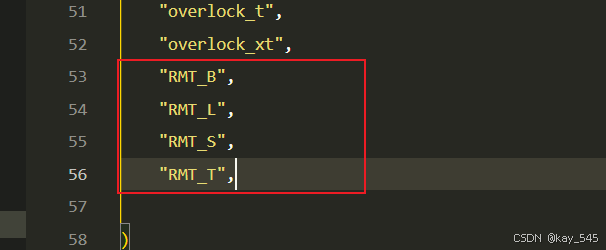
2.3 添加yaml文件
**关键步骤三:**在/ultralytics/ultralytics/cfg/models/26下面新建文件yolo26_RMT.yaml文件,粘贴下面的内容
- 目标检测
python
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Ultralytics YOLO26 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolo26
# Task docs: https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
end2end: True # whether to use end-to-end mode
reg_max: 1 # DFL bins
scales: # model compound scaling constants, i.e. 'model=yolo26n.yaml' will call yolo26.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 260 layers, 2,572,280 parameters, 2,572,280 gradients, 6.1 GFLOPs
s: [0.50, 0.50, 1024] # summary: 260 layers, 10,009,784 parameters, 10,009,784 gradients, 22.8 GFLOPs
m: [0.50, 1.00, 512] # summary: 280 layers, 21,896,248 parameters, 21,896,248 gradients, 75.4 GFLOPs
l: [1.00, 1.00, 512] # summary: 392 layers, 26,299,704 parameters, 26,299,704 gradients, 93.8 GFLOPs
x: [1.00, 1.50, 512] # summary: 392 layers, 58,993,368 parameters, 58,993,368 gradients, 209.5 GFLOPs
# YOLO26n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, RMT_T, []]
- [-1, 1, SPPF, [1024, 5]] # 5
- [-1, 2, C2PSA, [1024]] # 6
# YOLO26n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 3], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 9
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 2], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 12 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 15 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 6], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 18 (P5/32-large)
- [[12, 15, 18], 1, Detect, [nc]] # Detect(P3, P4, P5)- 语义分割
python
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Ultralytics YOLO26 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolo26
# Task docs: https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
end2end: True # whether to use end-to-end mode
reg_max: 1 # DFL bins
scales: # model compound scaling constants, i.e. 'model=yolo26n.yaml' will call yolo26.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 260 layers, 2,572,280 parameters, 2,572,280 gradients, 6.1 GFLOPs
s: [0.50, 0.50, 1024] # summary: 260 layers, 10,009,784 parameters, 10,009,784 gradients, 22.8 GFLOPs
m: [0.50, 1.00, 512] # summary: 280 layers, 21,896,248 parameters, 21,896,248 gradients, 75.4 GFLOPs
l: [1.00, 1.00, 512] # summary: 392 layers, 26,299,704 parameters, 26,299,704 gradients, 93.8 GFLOPs
x: [1.00, 1.50, 512] # summary: 392 layers, 58,993,368 parameters, 58,993,368 gradients, 209.5 GFLOPs
# YOLO26n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, RMT_T, []]
- [-1, 1, SPPF, [1024, 5]] # 5
- [-1, 2, C2PSA, [1024]] # 6
# YOLO26n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 3], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 9
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 2], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 12 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 15 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 6], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 18 (P5/32-large)
- [[12, 15, 18], 1, Segment, [nc, 32, 256]]- 旋转目标检测
python
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Ultralytics YOLO26 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolo26
# Task docs: https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
end2end: True # whether to use end-to-end mode
reg_max: 1 # DFL bins
scales: # model compound scaling constants, i.e. 'model=yolo26n.yaml' will call yolo26.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 260 layers, 2,572,280 parameters, 2,572,280 gradients, 6.1 GFLOPs
s: [0.50, 0.50, 1024] # summary: 260 layers, 10,009,784 parameters, 10,009,784 gradients, 22.8 GFLOPs
m: [0.50, 1.00, 512] # summary: 280 layers, 21,896,248 parameters, 21,896,248 gradients, 75.4 GFLOPs
l: [1.00, 1.00, 512] # summary: 392 layers, 26,299,704 parameters, 26,299,704 gradients, 93.8 GFLOPs
x: [1.00, 1.50, 512] # summary: 392 layers, 58,993,368 parameters, 58,993,368 gradients, 209.5 GFLOPs
# YOLO26n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, RMT_T, []]
- [-1, 1, SPPF, [1024, 5]] # 5
- [-1, 2, C2PSA, [1024]] # 6
# YOLO26n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 3], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 9
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 2], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 12 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 15 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 6], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 18 (P5/32-large)
- [[12, 15, 18], 1, OBB, [nc, 1]]温馨提示:本文只是对yolo26基础上添加模块,如果要对yolo26 n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple
python
end2end: True # whether to use end-to-end mode
reg_max: 1 # DFL bins
scales: # model compound scaling constants, i.e. 'model=yolo26n.yaml' will call yolo26.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 260 layers, 2,572,280 parameters, 2,572,280 gradients, 6.1 GFLOPs
s: [0.50, 0.50, 1024] # summary: 260 layers, 10,009,784 parameters, 10,009,784 gradients, 22.8 GFLOPs
m: [0.50, 1.00, 512] # summary: 280 layers, 21,896,248 parameters, 21,896,248 gradients, 75.4 GFLOPs
l: [1.00, 1.00, 512] # summary: 392 layers, 26,299,704 parameters, 26,299,704 gradients, 93.8 GFLOPs
x: [1.00, 1.50, 512] # summary: 392 layers, 58,993,368 parameters, 58,993,368 gradients, 209.5 GFLOPs2.4 在task.py中进行注册
**关键步骤四:**在parse_model函数中进行注册,添加RMT
先在task.py导入函数

然后在task.py文件下找到parse_model这个函数,如下图,添加RMT
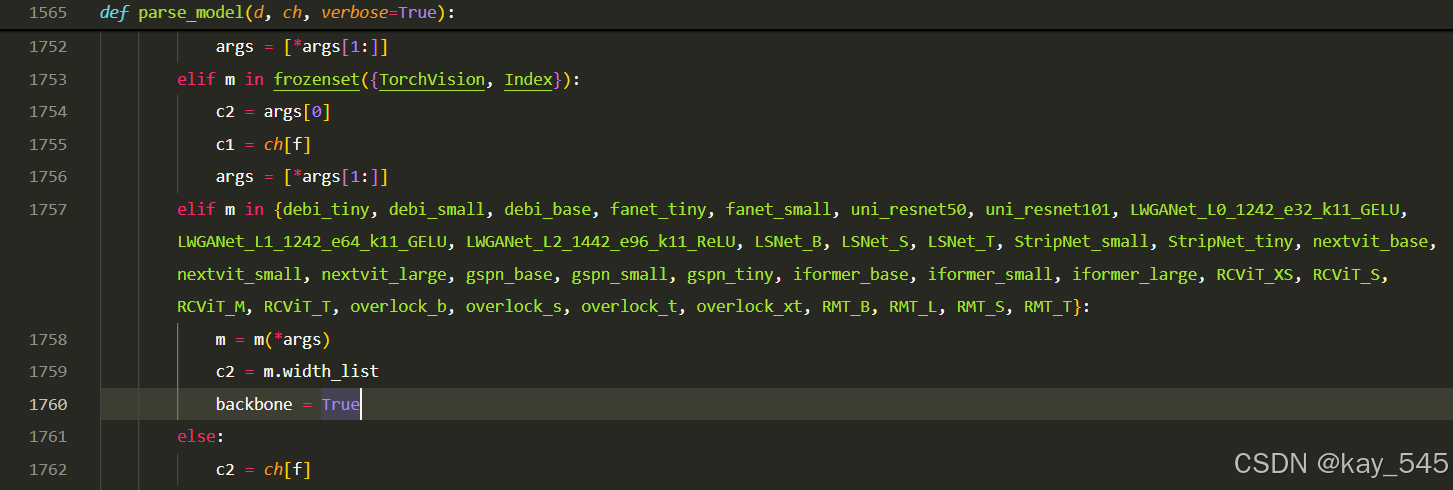
python
elif m in {RMT_B, RMT_L, RMT_S, RMT_T}:
m = m(*args)
c2 = m.width_list
backbone = True
else:
c2 = ch[f]2.5 执行程序
关键步骤五: 在ultralytics文件中新建train.py,将model的参数路径设置为yolo26_RMT .yaml的路径即可 【注意是在外边的Ultralytics下新建train.py】
python
from ultralytics import YOLO
import warnings
warnings.filterwarnings('ignore')
from pathlib import Path
if __name__ == '__main__':
# 加载模型
model = YOLO("ultralytics/cfg/26/yolo26.yaml") # 你要选择的模型yaml文件地址
# Use the model
results = model.train(data=r"你的数据集的yaml文件地址",
epochs=100, batch=16, imgsz=640, workers=4, name=Path(model.cfg).stem) # 训练模型🚀运行程序,如果出现下面的内容则说明添加成功🚀
python
from n params module arguments
0 -1 1 12678176 RMT_T []
1 -1 1 394240 ultralytics.nn.modules.block.SPPF [512, 256, 5]
2 -1 1 249728 ultralytics.nn.modules.block.C2PSA [256, 256, 1]
3 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
4 [-1, 3] 1 0 ultralytics.nn.modules.conv.Concat [1]
5 -1 1 127680 ultralytics.nn.modules.block.C3k2 [512, 128, 1, False]
6 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
7 [-1, 2] 1 0 ultralytics.nn.modules.conv.Concat [1]
8 -1 1 32096 ultralytics.nn.modules.block.C3k2 [256, 64, 1, False]
9 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
10 [-1, 9] 1 0 ultralytics.nn.modules.conv.Concat [1]
11 -1 1 86720 ultralytics.nn.modules.block.C3k2 [192, 128, 1, False]
12 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
13 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
14 -1 1 378880 ultralytics.nn.modules.block.C3k2 [384, 256, 1, True]
15 [12, 15, 18] 1 309656 ultralytics.nn.modules.head.Detect [80, 1, True, [64, 128, 256]]
YOLO26_RMT summary: 367 layers, 14,441,880 parameters, 14,441,880 gradients, 41.3 GFLOPs3. 完整代码分享
++主页侧边++
4. GFLOPs
关于GFLOPs的计算方式可以查看 :百面算法工程师 | 卷积基础知识------Convolution
未改进的YOLO26n GFLOPs
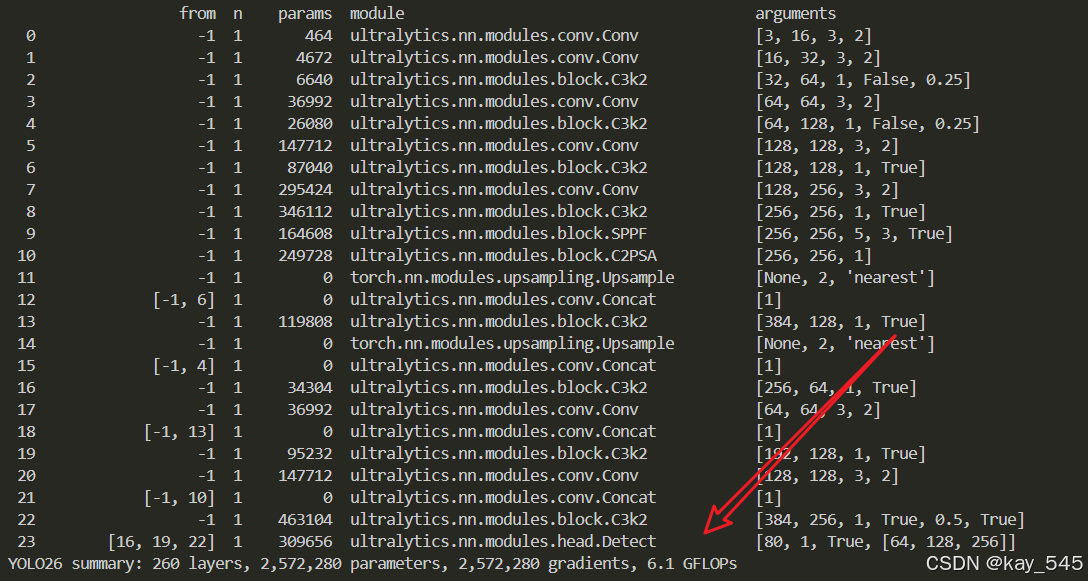
改进后的GFLOPs
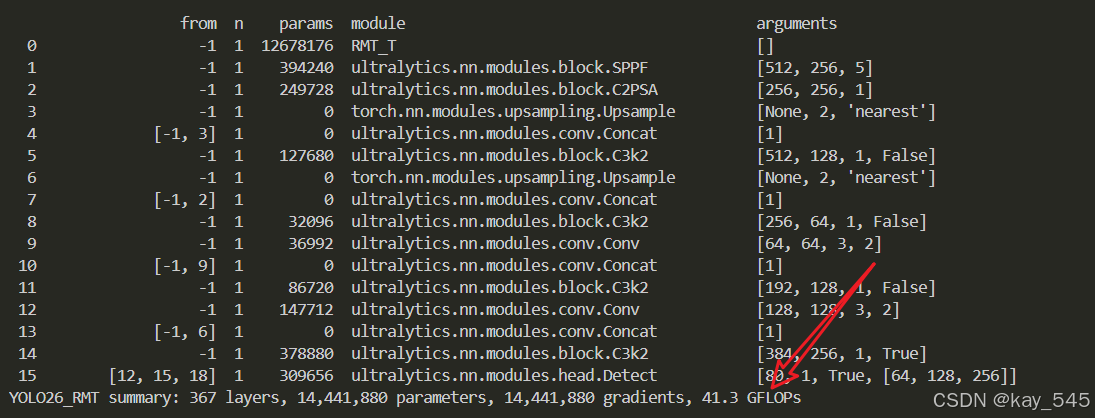
5. 进阶
可以与其他的注意力机制或者损失函数等结合,进一步提升检测效果
6.总结
通过以上的改进方法,我们成功提升了模型的表现。这只是一个开始,未来还有更多优化和技术深挖的空间。在这里,我想隆重向大家推荐我的专栏------<专栏地址: YOLO26改进-论文涨点------点击跳转看所有内容,关注不迷路!>。这个专栏专注于前沿的深度学习技术,特别是目标检测领域的最新进展,不仅包含对YOLO26的深入解析和改进策略,还会定期更新来自各大顶会(如CVPR、NeurIPS等)的论文复现和实战分享。
为什么订阅我的专栏? ------专栏地址:YOLO26改进-论文涨点------点击跳转看所有内容,关注不迷路!****
-
前沿技术解读:专栏不仅限于YOLO系列的改进,还会涵盖各类主流与新兴网络的最新研究成果,帮助你紧跟技术潮流。
-
详尽的实践分享 :所有内容实践性也极强。每次更新都会附带代码和具体的改进步骤,保证每位读者都能迅速上手。
-
问题互动与答疑 :订阅我的专栏后,你将可以随时向我提问,获取及时的答疑。
-
实时更新,紧跟行业动态:不定期发布来自全球顶会的最新研究方向和复现实验报告,让你时刻走在技术前沿。
专栏适合人群:
-
对目标检测、YOLO系列网络有深厚兴趣的同学
-
希望在用YOLO算法写论文的同学
-
对YOLO算法感兴趣的同学等
