现在大家聊大模型,总容易把两个词弄混:Transformer 和 LLM。
有人觉得,Transformer 不就是大模型嘛。
也有人觉得,Transformer 就是早期的一个架构,LLM 才是后来真正厉害的新东西。
其实这两种理解都不对。
更实在的说法是:Transformer 是大模型的底层骨架,LLM 就是这套骨架,在后续的训练和扩展中,一步步慢慢长成的样子。
说白了就是,Transformer 解决的是"模型该怎么搭",LLM 解决的是"模型为啥能这么强"。它们不是两个不相关的概念,而是同一条技术发展路上的前后两个阶段。
这篇文章就只讲一件事:Transformer 为啥能成为起点,它后来又经历了哪些关键变化,最后才变成了今天我们看到的大语言模型。
一、先把关系讲清楚
Transformer,本质上就是一种模型的结构。
它主要规定了三件事:文本怎么放进模型里,词和词之间怎么产生关联,信息在模型内部怎么流动。
LLM,本质上是一种能力的体现。
它不是某一种特定结构的名字,而是一类经过大规模训练后,能完成通用理解、生成内容、对话、写文章、编代码、做推理这些任务的模型系统。
所以这两者不是并列的关系。

更形象一点说:
- Transformer 是骨架
- LLM 是长成型的完整系统
你可以把 Transformer 理解成"大脑的构造方式",把 LLM 理解成"这个大脑经过长期训练后,所拥有的所有能力的总和"。
这也是为啥,有一个 Transformer 模型,不代表就有了一个大语言模型。中间还差着好多步骤呢。
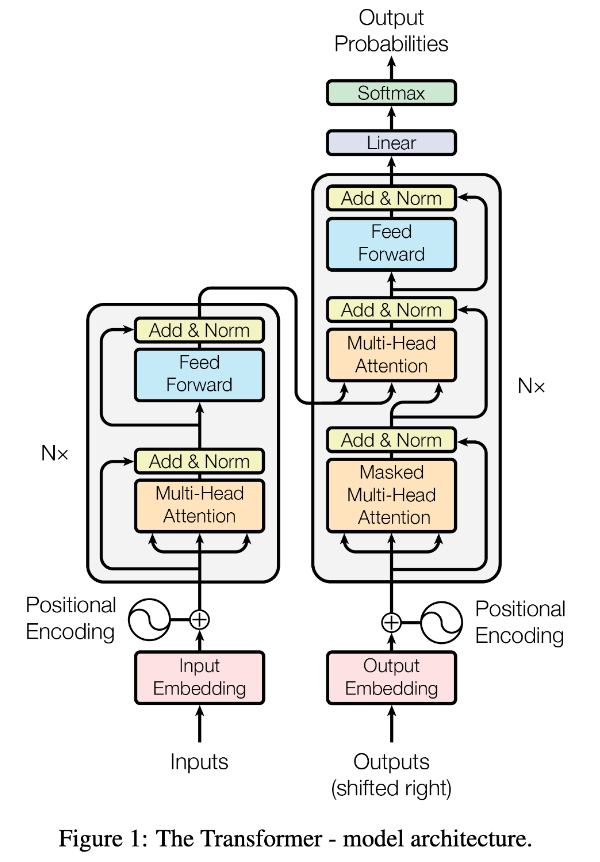
二、为什么大模型是从 Transformer 开始起飞的
在 Transformer 出现之前,文本模型主要靠 RNN、LSTM 这类循环网络。
它们的工作方式跟我们人读句子差不多:先处理前一个词,再处理后一个词,信息顺着句子的顺序一步步往后传。
这种方法能用是能用,但有两个明显的毛病。
第一个是慢。
因为它必须按顺序处理,没法真正把一整段文本放在一起计算。模型一旦做大,数据一旦变多,训练起来就会特别慢,效率一下子就跟不上了。
第二个是看不远。
一句话前面出现的信息,传到后面的时候,影响力会越来越弱。文本一长,模型就抓不住那些远距离的词之间的关系了。
可语言理解这事儿,偏偏特别依赖这种远距离的关系。比如前面埋下的条件,后面才出现结论;前面提到的人物,后面才用代词指代。以前的方法不是完全做不到,就是做得不够自然,也不适合继续把模型做大。
所以不是以前没人想做大模型,而是以前的主流结构,根本不适合一路放大。真正的转折点,就是 Transformer 的出现。
Transformer 最核心的变化,用一句大白话就能说懂:
它不再让模型按顺序慢慢记,而是让每个词都能直接去看一整段文本里,和自己有关系的其他词。
这就是自注意力。
以前模型理解一句话,就像拿着手电筒往前走,只能一段一段地看。
Transformer 就不一样了,它更像把整间屋子的灯都打开,每个位置都能直接看到其他位置。
这个变化,带来了三件决定性的事:
第一,模型更容易理解全局的关系。
一个词和远处的词之间的联系,不用绕很长的路,那些远距离的依赖关系,更容易被抓住。
第二,模型更适合一起训练。
一整段文本可以放在一起计算,不用一个词一个词地往后推。对于后来那些动辄几十亿、几百亿参数的大模型来说,这几乎是最基本的前提。
第三,模型更容易扩展。
Transformer 的层级结构很规整,很适合继续加深、加宽,增加更多参数。
所以,Transformer 的意义不只是"更强",而是它第一次让整个行业看到:语言模型,终于有了一副可以被大规模放大的骨架。
这一步,就是 LLM 的起点。
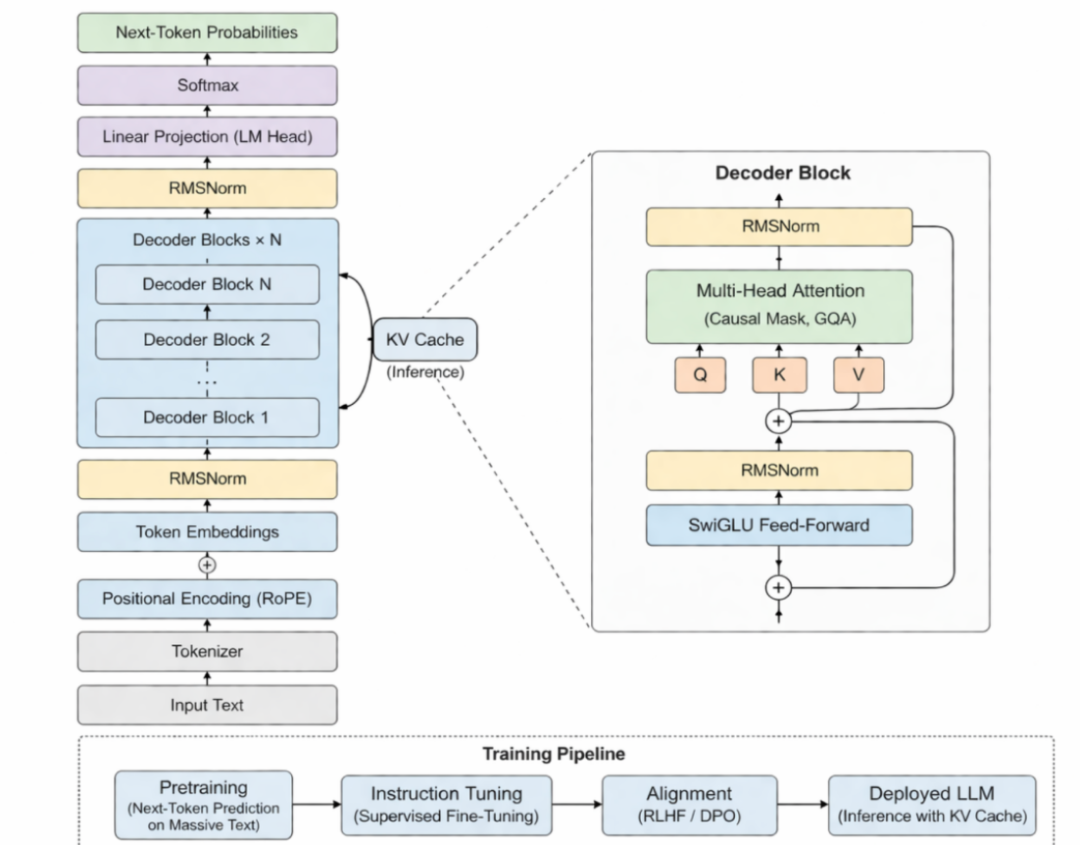
三、模型先要学会语言本身
光有结构还不够。
Transformer 解决了"怎么搭模型"的问题,但还没解决"模型怎么变聪明"的问题。
真正的下一步,是大家不再只让模型做某一个特定任务,而是先让它去学习语言本身。
以前很多 NLP 模型,都像是为某个任务量身做的。做翻译训练一个,做分类训练一个,做问答再训练一个。每次训练都跟临时备考似的,针对性强,但不通用。
后来研究者发现,这种方式太零散了。与其每次都为一道题单独训练,不如先让模型在海量的文本里,把语言的规律学明白。
从这时候开始,模型就不再只是某个任务的工具,而是慢慢变成了一个通用的语言底座。它学的也不再只是任务标签,而是更底层的东西:语法、语义、上下文怎么组织、知识怎么表达。
也正是在这个阶段,模型的发展路线开始分成了两条:
有的更注重"理解",有的更注重"生成"。
前者更接近编码器路线,擅长把一句话读懂,压缩成一个表征,适合做理解、分类、检索这类任务。
后者更接近解码器路线,不只是看懂一句话,还要根据前面的内容,一直往下生成新的内容。
今天我们看到的主流大语言模型,基本上都走了以解码器为主的生成路线。
原因也很简单:大家对大模型最核心的期待,不只是"能看懂一句话",而是能根据上下文,一直生成内容。不管是聊天、写文章、编代码,还是一步步分析问题,本质上都更偏向生成类的任务。
而让这条路线真正走通的关键,是训练目标的统一:
预测下一个 token。
别看这事说起来简单,其实威力特别大。因为模型要想把下一个 token 预测准,就必须尽可能理解前面所有的内容:上下文是什么,语义有没有接上,常识和知识能不能支撑,甚至推理的逻辑顺不顺。
所以,表面上它是在做"预测下一个词",本质上却是在被迫吸收整个人类文本世界里的大量规律。
到这里,Transformer 就不只是一个架构了,它开始通过生成式预训练,慢慢长出了通用语言能力的雏形。
四、真正让能力爆发的是规模化
如果说 Transformer 解决了结构的问题,预训练解决了学习方式的问题,那么接下来最关键的一步,就是规模化。
这也是为啥大家后来开始叫它"大"语言模型。
这个"大"当然包括模型参数的规模,但不只是参数多。真正重要的是好几件事一起升级:
- 模型参数变大
- 训练数据变多
- 训练过程变长
- 工程能力变强
模型在这种规模化的过程中,开始表现出更明显的通用能力:续写更自然,处理长上下文更稳定,能从提示里读懂任务,也更容易把在一个任务上学到的能力,用到另一个任务上。
这也是很多人第一次真正感觉到,"大模型"和"小模型"不是一类东西。差别不是回答得长一点、流畅一点,而是模型内部装下的语言规律,已经完全不是一个量级的了。
所以,从 Transformer 到 LLM,真正的变化不是"多了一个小技巧",而是:
同样的核心结构,被数据、算力和训练规模,推到了以前根本达不到的高度。
在模型继续做大的过程中,行业里也出现了一些更高效的扩容方法,比如 MoE。
你可以这么理解:模型的总容量继续变大,但每次不用把所有参数都调动起来,只需要用其中一部分就行。它确实很重要,但在这条主线里,你只要知道:这是大模型继续扩张时,一种提升效率的优化方法就够了。
五、大模型最后为什么会变成"助手"
走到这一步,模型已经很强了:
会写、会续、会回答问题,看起来跟今天的聊天机器人差不多。
但其实还差最后一步,也是特别关键的一步:
因为一个只做过大规模预训练的模型,虽然很会生成文本,却不一定擅长按人的要求做事。
它更像一个强大的续写机器:你给它一个开头,它能一直往下写;但你让它严格总结、翻译、按固定格式输出,或者识别危险请求,它的表现就不一定稳定了。
所以,后面还需要继续做两件事:
第一件事,是让模型学会遵循指令。
也就是说,模型原来学的是"语言该怎么继续",后来还得再学"人类到底想让我怎么回答"。
第二件事,是做对齐训练。
这一步不是为了让模型多学多少知识,而是为了让它的行为方式,更符合人类的想法。
模型需要慢慢学会:
- 什么样的回答更符合用户的需求
- 什么样的表达更清楚
- 什么情况下该先问清楚用户的意思
- 什么问题应该拒绝回答
- 怎样回答才更有帮助、更稳定
如果说预训练解决的是"模型会不会说话",
那么后面的指令微调和对齐训练,解决的就是"模型会不会按人的方式说话"。
这也是为啥今天成熟的大模型产品,给人的感觉不只是"更聪明",而是"更像助手"。差别不只是知识量的多少,而是它的交互方式,已经被重新塑造过了。
所以,今天的大语言模型之所以像"助手",不只是靠 Transformer,也不只是靠大规模预训练,对齐训练是最后那道特别关键的工序。
六、总结
现在再回到最开始的问题:
Transformer 和 LLM 到底是什么关系?
最准确的回答其实很简单:Transformer 是起点,LLM 是结果。
Transformer 给了模型一副足够强、足够稳、足够适合扩展的骨架;
预训练让它学会了语言;
生成路线让它更适合持续输出内容;
规模化让它的能力真正爆发;
后续的指令微调和对齐训练,再把它塑造成一个真正能用的助手。
所以,大模型不是凭空出现的,也不是某一天突然多了一个神秘模块。它是一条很清晰的技术演化链:从 Transformer 出发,经过预训练、生成式建模、规模化扩展和对齐训练,最后变成了今天我们看到的大语言模型。
如果你现在再看"Transformer"和"LLM"这两个词,最好把它们理解成同一条进化路上的前后阶段,而不是两个互相替代的概念。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
人工智能时代最缺的是什么?就是能动手解决问题还会动脑创新的技术牛人!智泊AI为了让学员毕业后快速成为抢手的AI人才,直接把课程升级到了V6.0版本。
这个课程就像搭积木一样,既有机器学习、深度学习这些基本功教学,又教大家玩转大模型开发、处理图片语音等多种数据的新潮技能,把AI技术从基础到前沿全部都包圆了!
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
课程还教大家怎么和AI搭档一起工作,就像程序员带着智能助手写代码、优化方案,效率直接翻倍!
这么练出来的学员确实吃香,83%的应届生都进了大厂搞研发,平均工资比同行高出四成多。
智泊AI还特别注重培养"人无我有"的能力,比如需求分析、创新设计这些AI暂时替代不了的核心竞争力,让学员在AI时代站稳脚跟。
课程优势一:人才库优秀学员参与真实商业项目实训
课程优势二:与大厂深入合作,共建大模型课程

课程优势三:海外高校学历提升

课程优势四:热门岗位全覆盖,匹配企业岗位需求
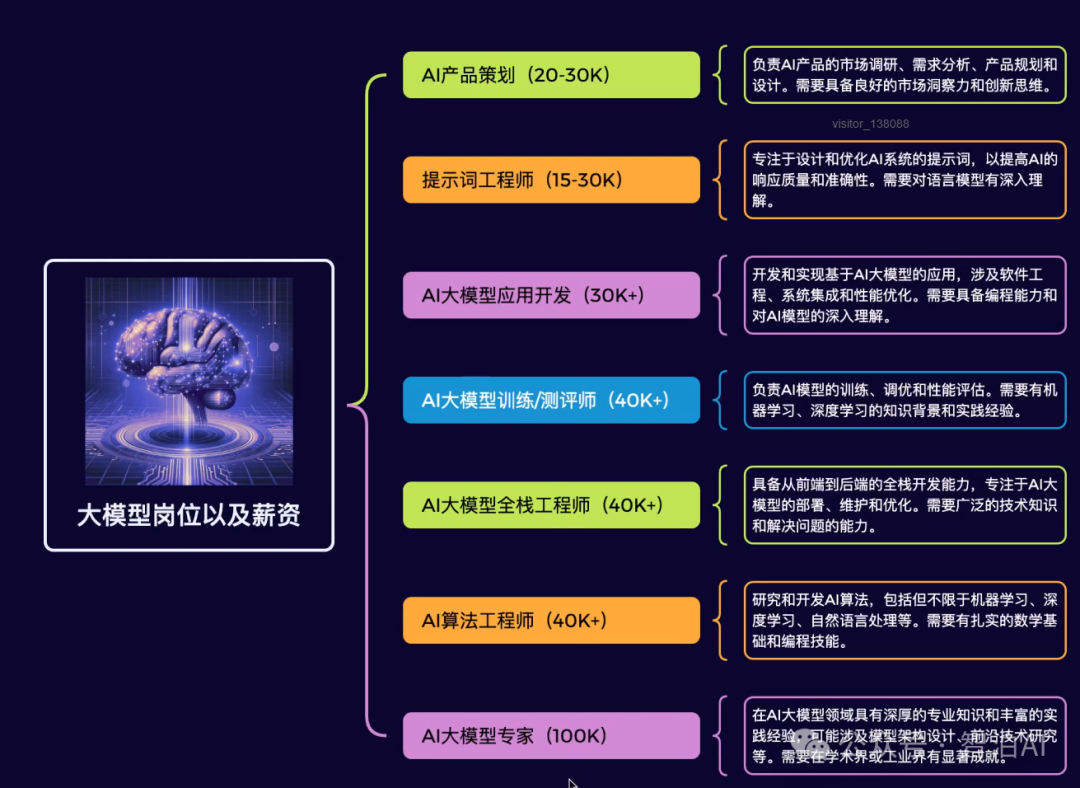
如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的"投资"换来的是终身受益!
·应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
·零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现"AI+行业"跨界。
·业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

智泊AI始终秉持着"让每个人平等享受到优质教育资源"的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
重磅消息
人工智能V6.0升级两大班型:AI大模型全栈班 、AI大模型算法班,为学生提供更多选择。

由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【最新最全版】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
来智泊AI,高起点就业
培养企业刚需人才
扫码咨询 抢免费试学
⬇⬇⬇

AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。