
摘要
大家好,我是深耕 Spring AI 架构的后端开发。在这个系列的前两篇文章里,我给大家分享了万级 QPS 分布式架构搭建、全链路可观察性体系落地的实战经验。但架构和监控搭完,真正的线上运维难题才刚刚开始:本地能跑的 AI 服务,到线上就因为环境不一致报错;高峰期要扩容,手动装 JDK、配环境搞了半个多小时,错过了流量峰值;发布新版本要一台台重启虚拟机,回滚慢、风险高,还经常出现 "一半成功一半失败" 的尴尬局面。
痛定思痛,我们带着团队把 Spring AI 服务做了完整的云原生容器化改造,用 Docker 做镜像打包,K8s 做编排管理,GitLab CI/CD 做自动部署,还深度整合了 Spring Cloud Kubernetes,实现了配置热更新、原生服务发现。改造完成后,我们的服务发布时间从 1 小时缩短到 5 分钟,扩容从手动半小时变成秒级自动伸缩,环境一致性问题彻底解决,资源利用率从 30% 提升到了 70%。
这篇文章我会把整个改造过程、核心优化方案、踩过的坑全部分享给大家,从 Docker 镜像优化、K8s 全资源配置、弹性伸缩策略,到完整的 CI/CD 流水线落地,全程配套可直接复制的代码和插图,看完就能直接落地到你的 Spring AI 项目里。
1. 引言:为什么 Spring AI 服务必须做云原生容器化改造?
先给大家看看我们改造前的运维噩梦,相信做 AI 服务的兄弟们都有共鸣:
- 环境一致性问题:本地开发用 JDK17,线上虚拟机是 JDK11,本地跑的好好的 RAG 功能,线上直接报错;本地模型依赖的 CUDA 版本,线上和本地不一致,服务直接起不来;
- 扩容效率极低:业务搞活动,流量峰值是平时的 10 倍,手动开虚拟机、装 JDK、配环境、拉代码、启动服务,一套流程下来半个多小时,流量峰值都过去了;
- 发布风险极高:每次发布要一台台登录虚拟机重启服务,不仅慢,还经常出现 "一半实例更新成功,一半更新失败" 的情况,回滚要一台台操作,线上故障恢复时间长达几十分钟;
- 资源利用率极低:为了应对高峰期,每台虚拟机都按峰值配置了 8C16G,平时低峰期 CPU 利用率只有 10% 不到,大量资源被浪费;
- 配置管理混乱:模型 API Key、向量数据库地址、Prompt 模板这些配置,要么写死在代码里,要么散落在每台虚拟机的配置文件里,改个配置要重启所有服务,还经常出现漏改、错改的情况。
这些问题,靠传统的虚拟机部署根本解决不了,而云原生容器化就是最佳解决方案。Docker 把应用和依赖一起打包成镜像,彻底解决了环境一致性问题;K8s 实现了应用的自动化编排、秒级扩容、滚动发布、一键回滚;Spring Cloud Kubernetes 让 Spring 应用能无缝对接 K8s 的原生能力,不用再依赖 Eureka、Nacos 这些中间件,架构更轻量。
对于 Spring AI 服务来说,云原生改造的价值更是被放大了:AI 服务有明显的流量波峰波谷,弹性伸缩能极大降低资源成本;AI 服务依赖的模型、环境复杂,镜像打包能彻底解决依赖问题;AI 服务的配置变更频繁,ConfigMap 能实现热更新,不用重启服务。
2. 核心架构概览:Spring AI 云原生部署全景架构
先给大家看一下我们最终落地的 Spring AI 云原生部署全景架构图,这套架构稳定运行了半年,支撑了多次大流量活动,零线上故障:
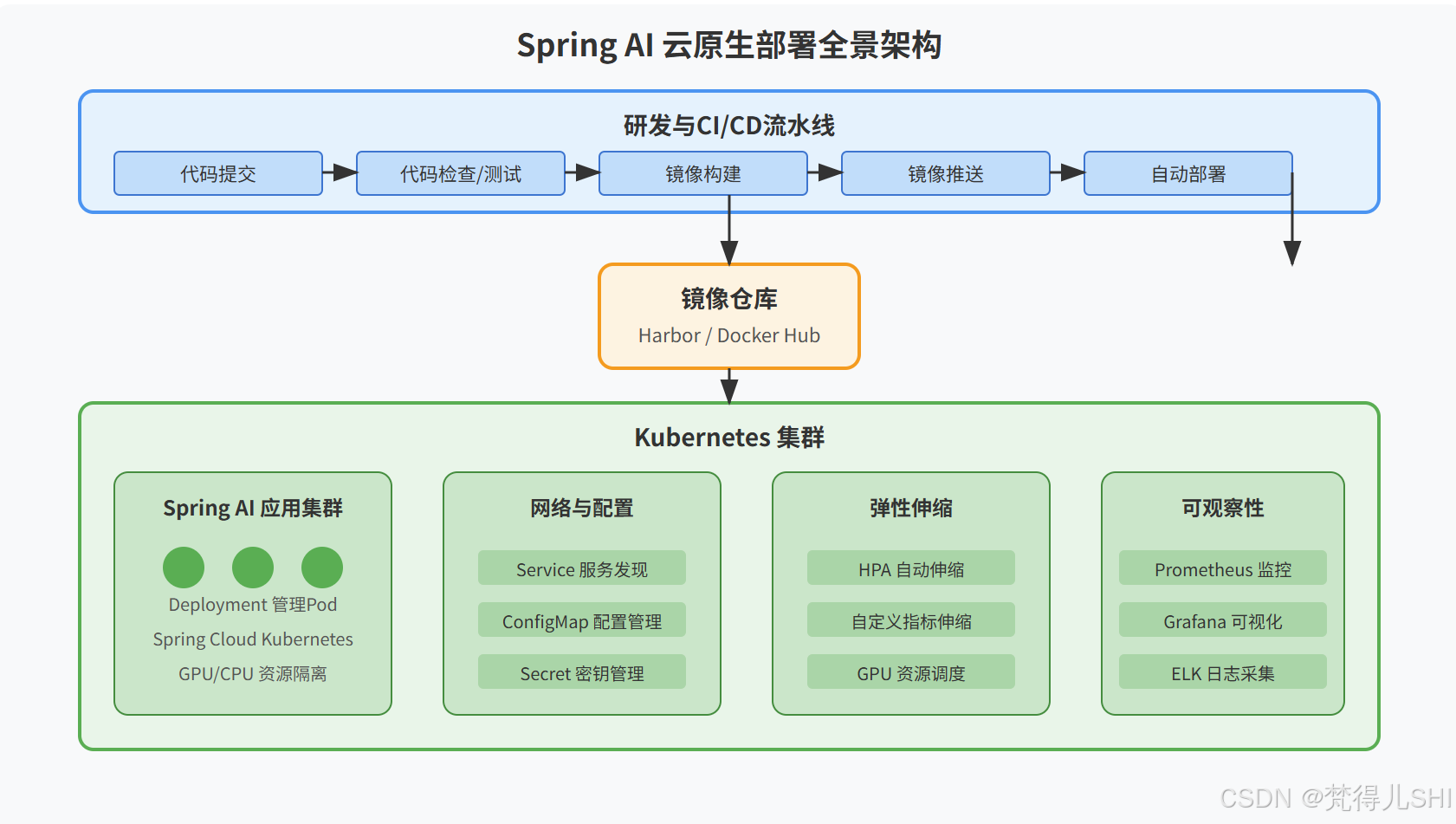
整个架构从上到下分为四大核心层,完全贴合云原生最佳实践:
- 研发与 CI/CD 层:从代码提交到自动部署的全流程自动化,实现 AI 应用的持续集成与持续交付;
- 镜像仓库层:存储 Spring AI 应用的 Docker 镜像,做版本管理、安全扫描,是环境一致性的核心保障;
- K8s 集群层:整个架构的核心,负责应用的编排、调度、服务发现、配置管理、弹性伸缩,是 AI 服务稳定运行的底座;
- 可观察性层:和前两篇文章的监控体系联动,实现容器、Pod、应用全维度的监控、日志、链路追踪。
接下来的章节,我会给大家拆解每一层的落地细节,从代码到配置,从优化到踩坑,全部分享给大家。
3. Docker 镜像优化:多阶段构建 + 分层缓存,极致压缩镜像体积
3.1 AI 服务镜像的核心痛点:为什么你的镜像又大又慢?
很多人第一次打包 Spring AI 的 Docker 镜像,都会遇到同样的问题:镜像体积太大,动辄 1G 以上,不仅拉取慢,占用大量磁盘空间,还会导致扩容、发布的时间变长。
Spring AI 服务的镜像之所以容易变大,核心原因有三个:
- 直接用 fat jar 打包:把 JDK、所有依赖、编译代码、源码都打包到了一个镜像里,大量无用的构建环境依赖被带到了运行环境;
- 基础镜像选型错误:用了完整的 openjdk 镜像,甚至是 ubuntu 镜像,自带了大量无用的系统工具和依赖;
- AI 服务额外依赖多:如果部署本地大模型,还会带 CUDA、Python 环境、模型文件,镜像体积会进一步膨胀。
镜像太大带来的直接问题就是:发布慢、扩容慢、拉取镜像容易超时,尤其是高峰期扩容的时候,镜像还没拉完,流量峰值已经过去了。所以,镜像优化是云原生改造的第一步,也是最关键的一步。
3.2 多阶段构建:分离构建与运行环境,从源头减体积
Docker 多阶段构建的核心思想,就是把构建环境和运行环境彻底分离:用一个完整的 JDK 镜像做构建,编译代码、打包 jar 包;然后用一个精简的 JRE 镜像做运行环境,只把构建好的 jar 包和运行需要的依赖复制过来,构建环境里的所有东西都不会被带到最终的镜像里。
先给大家看一下优化前的错误 Dockerfile,相信很多人都是这么写的:
bash
# 错误示例:单阶段构建,镜像体积大,有安全风险
FROM openjdk:17-jdk
WORKDIR /app
COPY . .
# 直接在镜像里构建,把maven、源码、编译缓存都带到了最终镜像里
RUN ./mvnw clean package -DskipTests
EXPOSE 8080
# 用完整的JDK运行,自带了大量无用的开发工具
CMD ["java", "-jar", "target/spring-ai-service.jar"]这个 Dockerfile 打出来的镜像,体积直接到了 1.2G,里面包含了 maven、源码、编译缓存、完整的 JDK,大量无用的内容。
再给大家看优化后的多阶段构建 Dockerfile,也是我们生产环境在用的版本:
bash
# 第一阶段:构建阶段,用完整的JDK + Maven,只负责编译打包
FROM eclipse-temurin:17-jdk-alpine AS builder
WORKDIR /build
# 先复制pom.xml,下载依赖,利用Docker缓存,不用每次构建都重新下载依赖
COPY pom.xml .
COPY mvnw .
COPY .mvn .mvn
RUN ./mvnw dependency:go-offline -DskipTests
# 再复制源码,编译打包
COPY src ./src
RUN ./mvnw clean package -DskipTests
# 第二阶段:运行阶段,用精简的JRE镜像,只复制构建好的jar包
FROM eclipse-temurin:17-jre-alpine
WORKDIR /app
# 设置时区,避免日志时间不对
RUN apk add --no-cache tzdata
ENV TZ=Asia/Shanghai
# 从构建阶段复制打包好的jar包,只复制这一个文件
COPY --from=builder /build/target/*.jar app.jar
EXPOSE 8080
# 启动参数优化,适配容器环境
CMD ["java", "-XX:+UseContainerSupport", "-XX:MaxRAMPercentage=75.0", "-jar", "app.jar"]这个多阶段构建的 Dockerfile,打出来的镜像体积直接降到了 400M,比优化前缩小了 2/3。
3.3 极致优化:JRE 裁剪 + 分层构建 + 基础镜像选型
如果想把镜像体积压缩到极致,还可以做这三个优化,我们就是靠这几步,把镜像从 400M 进一步压缩到了 180M。
1. 用 jlink 裁剪 JRE,只保留需要的模块
JDK9 之后提供了 jlink 工具,可以把 JRE 裁剪成只包含项目需要的模块,不用带完整的 JRE。Spring AI 项目只需要 java.base、java.logging、java.sql 等核心模块,裁剪后的 JRE 体积只有几十 M。
给大家看一下裁剪 JRE 的多阶段构建 Dockerfile:
bash
# 第一阶段:构建JRE + 编译打包
FROM eclipse-temurin:17-jdk-alpine AS builder
WORKDIR /build
# 第一步:用jlink裁剪JRE,只保留需要的模块
RUN jlink \
--module-path $JAVA_HOME/jmods \
--add-modules java.base,java.logging,java.sql,java.naming,java.desktop,java.management,java.security.jgss,java.instrument \
--output /minimal-jre \
--strip-debug \
--no-man-pages \
--no-header-files \
--compress=2
# 第二步:编译打包Spring AI项目
COPY pom.xml .
COPY mvnw .
COPY .mvn .mvn
RUN ./mvnw dependency:go-offline -DskipTests
COPY src ./src
RUN ./mvnw clean package -DskipTests
# 第二阶段:运行阶段,用alpine基础镜像 + 裁剪后的JRE
FROM alpine:3.19
WORKDIR /app
# 安装必要的依赖
RUN apk add --no-cache tzdata libc6-compat
ENV TZ=Asia/Shanghai
# 从构建阶段复制裁剪后的JRE
COPY --from=builder /minimal-jre /opt/minimal-jre
ENV JAVA_HOME=/opt/minimal-jre
ENV PATH=$JAVA_HOME/bin:$PATH
# 复制构建好的jar包
COPY --from=builder /build/target/*.jar app.jar
EXPOSE 8080
CMD ["java", "-XX:+UseContainerSupport", "-XX:MaxRAMPercentage=75.0", "-jar", "app.jar"]用 jlink 裁剪后,镜像体积直接从 400M 降到了 200M 以内。
2. 分层构建,利用 Docker 缓存加速构建
Spring Boot 的 jar 包里,依赖包占了 90% 以上的体积,而我们的代码变更频率远高于依赖变更频率。所以我们可以把 jar 包分层,把依赖包和代码分开,依赖包单独放一层,代码放另一层,这样只要依赖不变,构建的时候就会复用缓存,不用每次都重新复制依赖包,构建速度能提升 80% 以上。
Spring Boot 2.3 + 已经内置了分层打包的能力,只需要在 pom.xml 里开启:
XML
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<!-- 开启分层打包 -->
<layers>
<enabled>true</enabled>
</layers>
</configuration>
</plugin>
</plugins>
</build>然后在 Dockerfile 里分层复制:
bash
# 从构建好的jar包里提取分层内容
COPY --from=builder /build/target/*.jar app.jar
RUN java -Djarmode=layertools -jar app.jar extract
# 先复制依赖层,这层很少变,会被缓存
COPY --from=builder /build/dependencies/ ./
COPY --from=builder /build/spring-boot-loader/ ./
COPY --from=builder /build/snapshot-dependencies/ ./
# 最后复制应用层,代码变更只会影响这一层
COPY --from=builder /build/application/ ./3. 基础镜像选型避坑
给大家总结一下 Spring AI 服务的基础镜像选型建议,按优先级排序:
- 生产环境首选 :
eclipse-temurin:17-jre-alpine,体积小、安全、稳定,适配 Spring Boot 3.x; - 极致体积首选 :
alpine+ jlink 裁剪后的 JRE,体积最小,适合对镜像大小有极致要求的场景; - 绝对不要用 :
ubuntu、centos这类完整的系统镜像,体积大,有安全风险;也不要用过时的openjdk镜像,已经停止维护了。
3.4 GPU 镜像专项优化:本地模型部署踩坑指南
如果你的 Spring AI 服务需要部署本地大模型,需要用到 GPU,镜像优化会更复杂,这里给大家分享两个核心踩坑经验:
- 基础镜像必须用官方 CUDA 镜像 :NVIDIA 官方提供的
nvidia/cuda镜像,已经适配好了显卡驱动、CUDA、cuDNN,不要自己在 ubuntu 里装 CUDA,很容易出现驱动版本不兼容的问题; - 多阶段构建分离模型文件:大模型的文件动辄几个 G,不要把模型文件直接打包到镜像里,否则镜像体积会爆炸。应该用 K8s 的 PV/PVC 挂载模型文件,或者用对象存储在服务启动时拉取,镜像里只放代码和运行环境。
给大家看一下 GPU 镜像的极简 Dockerfile 示例:
bash
# 构建阶段
FROM nvidia/cuda:12.1.1-cudnn8-devel-ubuntu22.04 AS builder
WORKDIR /build
# 安装JDK、Maven,编译打包Spring AI项目
RUN apt-get update && apt-get install -y openjdk-17-jdk maven
COPY pom.xml .
COPY src ./src
RUN mvn clean package -DskipTests
# 运行阶段,用runtime镜像,体积比devel镜像小很多
FROM nvidia/cuda:12.1.1-cudnn8-runtime-ubuntu22.04
WORKDIR /app
RUN apt-get update && apt-get install -y openjdk-17-jre tzdata
ENV TZ=Asia/Shanghai
# 只复制构建好的jar包,模型文件用PVC挂载
COPY --from=builder /build/target/*.jar app.jar
EXPOSE 8080
CMD ["java", "-jar", "app.jar"]用 runtime 镜像代替 devel 镜像,镜像体积能缩小一半以上。
3.5 踩坑实录:1.2G 镜像优化到 180M 的全过程
我第一次打包 Spring AI 镜像的时候,用了单阶段构建,打出来的镜像 1.2G,每次拉取镜像要 5 分钟,高峰期扩容的时候,镜像还没拉完,流量峰值就过去了。
后来我们一步步优化:
- 改成多阶段构建,分离构建和运行环境,镜像体积降到 400M;
- 开启 Spring Boot 分层构建,利用 Docker 缓存,构建时间从 10 分钟降到 1 分钟;
- 用 jlink 裁剪 JRE,只保留需要的模块,镜像体积降到 200M 以内;
- 把基础镜像换成 alpine,清理无用的系统依赖,最终镜像体积稳定在 180M。
优化完成后,镜像拉取时间从 5 分钟降到了 30 秒以内,高峰期扩容的速度提升了 10 倍,再也没出现过镜像拉取超时的问题。
4. K8s 部署实战:Deployment+Service+ConfigMap 全配置落地
4.1 资源规划:AI 服务在 K8s 里的核心资源选型
在部署之前,我们先要做好资源规划,AI 服务和普通 Java 服务的资源需求有很大的区别,核心要关注这几点:
- CPU / 内存资源:Spring AI 服务是 IO 密集型服务,普通的 API 调用场景,单 Pod 配置 2C4G 足够;如果有本地向量化、轻量模型推理,需要配置 4C8G 以上;
- GPU 资源:如果部署本地大模型,需要给 Pod 配置 GPU 资源,K8s 支持 NVIDIA GPU 调度,需要提前安装 NVIDIA GPU Operator;
- 存储资源:模型文件、向量索引文件需要用 PV/PVC 做持久化存储,不要放在容器的本地存储里,容器重启后数据会丢失;
- 副本数规划:生产环境最少配置 2 个副本,避免单点故障,用 HPA 做弹性伸缩,应对流量波动。
4.2 完整部署 YAML:Deployment+Service+ConfigMap+Secret
我把我们生产环境在用的 Spring AI 服务 K8s 部署 YAML 整理好了,大家可以直接复制修改使用,包含了所有核心资源:
1. ConfigMap:管理应用配置,不用写死在镜像里
bash
apiVersion: v1
kind: ConfigMap
metadata:
name: spring-ai-service-config
namespace: ai-service
data:
application.yml: |
spring:
application:
name: spring-ai-service
# AI模型配置,从ConfigMap管理,不用重启服务就能修改
ai:
openai:
api-key: ${OPENAI_API_KEY}
base-url: https://api.openai.com
chat:
options:
model: gpt-3.5-turbo
temperature: 0.7
# 向量数据库配置
milvus:
client:
address: milvus-service.ai-service.svc.cluster.local:19530
# 服务端口
server:
port: 8080
# 监控端点配置
management:
endpoints:
web:
exposure:
include: prometheus,health,info2. Secret:管理敏感信息,比如 API Key、数据库密码
bash
apiVersion: v1
kind: Secret
metadata:
name: spring-ai-service-secret
namespace: ai-service
type: Opaque
# 敏感数据用base64编码,不要明文写在这里
data:
openai-api-key: eW91ci1vcGVuYWktYXBpLWtleQ==3. Deployment:管理 Spring AI 应用的 Pod,核心部署配置
bash
apiVersion: apps/v1
kind: Deployment
metadata:
name: spring-ai-service
namespace: ai-service
labels:
app: spring-ai-service
spec:
# 副本数,生产环境最少2个
replicas: 3
# 滚动发布策略
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
# 标签选择器
selector:
matchLabels:
app: spring-ai-service
# Pod模板
template:
metadata:
labels:
app: spring-ai-service
spec:
# 容器配置
containers:
- name: spring-ai-service
# 镜像地址,改成你自己的镜像仓库地址
image: harbor.your-domain.com/ai-service/spring-ai-service:latest
imagePullPolicy: Always
# 端口配置
ports:
- containerPort: 8080
name: http
# 环境变量,从Secret里读取敏感信息
env:
- name: OPENAI_API_KEY
valueFrom:
secretKeyRef:
name: spring-ai-service-secret
key: openai-api-key
# 配置文件挂载,从ConfigMap读取
volumeMounts:
- name: config
mountPath: /app/config
# 模型文件挂载,用PVC持久化
- name: model-data
mountPath: /app/model
# 资源限制,避免Pod占用过多资源
resources:
requests:
cpu: "2"
memory: "4Gi"
limits:
cpu: "4"
memory: "8Gi"
# 存活探针:检测Pod是否正常运行,异常则重启
livenessProbe:
httpGet:
path: /actuator/health/liveness
port: http
initialDelaySeconds: 30
periodSeconds: 10
failureThreshold: 3
# 就绪探针:检测Pod是否可以接收流量,没就绪不会加入Service负载
readinessProbe:
httpGet:
path: /actuator/health/readiness
port: http
initialDelaySeconds: 20
periodSeconds: 5
failureThreshold: 2
# 数据卷配置
volumes:
- name: config
configMap:
name: spring-ai-service-config
- name: model-data
persistentVolumeClaim:
claimName: model-data-pvc4. Service:服务发现,给 Pod 提供统一的访问入口
bash
apiVersion: v1
kind: Service
metadata:
name: spring-ai-service
namespace: ai-service
spec:
selector:
app: spring-ai-service
ports:
- port: 80
targetPort: http
name: http
type: ClusterIP把这四个 YAML 文件应用到 K8s 集群里,你的 Spring AI 服务就成功部署到 K8s 里了。
4.3 核心配置详解:健康检查 + 资源限制 + 生命周期管理
上面的 YAML 里,有几个核心配置是 AI 服务稳定运行的关键,很多人踩坑都是因为这几个配置没做好,这里给大家详细解释:
1. 健康检查:存活探针 + 就绪探针,避免发布故障
这是我踩过的最大的坑之一:一开始没配就绪探针,发布的时候,Pod 刚启动就被加入了 Service 负载,结果请求进来,Spring 上下文还没初始化完,直接返回 503,线上告警直接炸了。
- 存活探针(livenessProbe):检测 Pod 是否正常运行,如果检测失败,K8s 会重启 Pod。AI 服务启动慢,initialDelaySeconds 要设长一点,建议 30 秒以上;
- 就绪探针(readinessProbe):检测 Pod 是否可以接收流量,只有检测成功,才会把 Pod 加入 Service 的负载。这个是发布零故障的关键,一定要配置,initialDelaySeconds 建议 20 秒以上。
2. 资源限制:requests 和 limits,避免资源争抢
K8s 里的资源配置,requests 是 Pod 的最低资源需求,K8s 会把 Pod 调度到满足 requests 的节点上;limits 是 Pod 的最大资源限制,超过会被 OOM killed。
对于 Spring AI 服务,给大家几个配置建议:
- CPU:requests 设为 2 核,limits 设为 4 核,避免 CPU 争抢导致服务卡顿;
- 内存:requests 设为 4G,limits 设为 8G,一定要比 JVM 的最大堆内存大,不然会出现容器 OOM,但是 JVM 没有堆内存溢出的情况;
- 一定要配置 requests 和 limits,不要让 Pod 的资源无限制使用,否则一个 Pod 出问题,会把整个节点的资源耗尽。
3. 滚动发布策略:零停机发布
Deployment 的 strategy 配置,我们用的是 RollingUpdate 滚动发布,maxSurge=1,maxUnavailable=0,意思是:发布的时候,先启动 1 个新版本的 Pod,等新版本 Pod 就绪了,再销毁 1 个旧版本的 Pod,全程不会有不可用的 Pod,实现零停机发布。
这个配置对于 AI 服务来说非常重要,因为 AI 服务启动慢,如果用默认的配置,可能会出现大量 Pod 同时重启,导致服务不可用。
4.4 核心亮点:Spring Cloud Kubernetes 深度整合实践
这是整个云原生改造的核心亮点:Spring Cloud Kubernetes 可以让 Spring AI 应用无缝对接 K8s 的原生能力,不用再依赖 Eureka、Nacos、Spring Cloud Config 这些中间件,架构更轻量,更贴合云原生最佳实践。
1. 核心能力
Spring Cloud Kubernetes 提供了这些核心能力,完美适配 Spring AI 服务:
- 配置管理:直接用 K8s 的 ConfigMap 和 Secret 管理配置,修改 ConfigMap 后,应用能自动刷新配置,不用重启 Pod;
- 服务发现:直接用 K8s 的 Service 实现服务发现,不用再部署注册中心,服务之间直接通过 Service 名称调用;
- 负载均衡:集成 Ribbon,实现客户端负载均衡;
- 健康检查:对接 K8s 的健康检查机制,实现应用生命周期管理。
2. 整合步骤
第一步:引入依赖(Spring Cloud 2023.x 版本)
XML
<!-- Spring Cloud Kubernetes 核心依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-kubernetes-fabric8-all</artifactId>
</dependency>
<!-- 配置热刷新依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>第二步:配置 bootstrap.yml,开启 K8s 配置管理
bash
spring:
application:
name: spring-ai-service
cloud:
kubernetes:
# 开启ConfigMap配置
config:
enabled: true
name: spring-ai-service-config
namespace: ai-service
# 开启Secret配置
secrets:
enabled: true
name: spring-ai-service-secret
namespace: ai-service
# 开启配置热刷新
reload:
enabled: true
mode: event
strategy: refresh第三步:给需要热刷新的配置类加上 @RefreshScope 注解
java
@RestController
@RequestMapping("/ai/config")
@RefreshScope
public class AiConfigController {
@Value("${spring.ai.openai.chat.options.model}")
private String modelName;
@GetMapping("/model")
public String getModelName() {
return modelName;
}
}配置完成后,你修改 K8s 里的 ConfigMap,Spring AI 应用会自动刷新配置,不用重启 Pod,对于需要频繁调整模型参数、Prompt 模板的 AI 服务来说,这个能力太实用了。
3. 权限配置
这里有个坑:Spring Cloud Kubernetes 需要访问 K8s 的 API,所以要给 Pod 配置对应的 ServiceAccount 和 RBAC 权限,否则会报权限不足的错误。
给大家提供完整的 RBAC 配置:
bash
apiVersion: v1
kind: ServiceAccount
metadata:
name: spring-ai-service-sa
namespace: ai-service
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: ai-service
name: spring-ai-service-role
rules:
- apiGroups: [""]
resources: ["configmaps", "secrets", "services", "endpoints", "pods"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: spring-ai-service-rolebinding
namespace: ai-service
subjects:
- kind: ServiceAccount
name: spring-ai-service-sa
namespace: ai-service
roleRef:
kind: Role
name: spring-ai-service-role
apiGroup: rbac.authorization.k8s.io然后在 Deployment 里指定这个 ServiceAccount:
bash
spec:
template:
spec:
serviceAccountName: spring-ai-service-sa5. 弹性伸缩:HPA + 自定义指标,从容应对 AI 流量洪峰
AI 服务的流量有非常明显的波峰波谷:白天业务高峰期 QPS 是平时的 10 倍,晚上低峰期只有不到 10% 的流量。如果按峰值配置固定的副本数,低峰期会浪费大量资源;如果按低峰期配置,高峰期又会扛不住。
而 K8s 的 HPA(Horizontal Pod Autoscaler)水平自动伸缩,完美解决了这个问题:它可以根据 CPU 利用率、QPS、GPU 利用率等指标,自动增加或减少 Pod 的副本数,高峰期自动扩容,低峰期自动缩容,既保证了服务稳定,又降低了资源成本。
5.1 基础 HPA:基于 CPU / 内存的弹性伸缩配置
最基础的 HPA 是基于 CPU 和内存利用率的伸缩,配置非常简单,适合刚入门的场景。
首先,要确保你的 K8s 集群里安装了 Metrics Server,它是 HPA 获取 CPU / 内存指标的基础,大部分 K8s 发行版都默认安装了。
然后,给大家看一下基础 HPA 的配置 YAML:
bash
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: spring-ai-service-hpa
namespace: ai-service
spec:
# 要伸缩的目标Deployment
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: spring-ai-service
# 副本数范围:最小2个,最大10个
minReplicas: 2
maxReplicas: 10
# 伸缩指标
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
# 目标CPU利用率:平均利用率超过60%就扩容
averageUtilization: 60
- type: Resource
resource:
name: memory
target:
type: Utilization
# 目标内存利用率:平均利用率超过70%就扩容
averageUtilization: 70
# 伸缩行为配置,避免频繁伸缩
behavior:
scaleUp:
# 扩容冷却时间:30秒
stabilizationWindowSeconds: 30
# 一次最多扩容5个Pod
maxPods: 5
scaleDown:
# 缩容冷却时间:5分钟,避免流量波动导致频繁缩容扩容
stabilizationWindowSeconds: 300
# 一次最多缩容2个Pod
maxPods: 2这个配置的意思是:
- Pod 的副本数最少 2 个,最多 10 个;
- 当所有 Pod 的平均 CPU 利用率超过 60%,或者平均内存利用率超过 70%,就自动扩容;
- 当利用率低于阈值,就自动缩容;
- 扩容冷却 30 秒,缩容冷却 5 分钟,避免频繁伸缩。
5.2 进阶实战:基于 Prometheus 自定义指标的 HPA(QPS/GPU 利用率)
对于 Spring AI 服务来说,只靠 CPU 和内存做伸缩是远远不够的。很多时候,CPU 利用率只有 30%,但是模型调用的 QPS 已经到了瓶颈,请求开始排队,响应变慢;如果是 GPU 推理场景,GPU 利用率才是核心的伸缩指标。
这时候,我们就需要用基于 Prometheus 自定义指标的 HPA,通过 Prometheus Adapter 把 Prometheus 里的指标暴露给 K8s,让 HPA 可以根据这些指标做伸缩。
1. 前置条件
- 你的 K8s 集群里已经安装了 Prometheus,并且已经采集了 Spring AI 服务的指标(比如 QPS、GPU 利用率);
- 安装了 Prometheus Adapter,把 Prometheus 指标转换成 K8s 的自定义指标。
2. 核心配置:基于 QPS 的 HPA
我们在前两篇文章里,用 Micrometer 采集了 Spring AI 服务的模型调用 QPS 指标ai_model_call_total,现在我们就用这个指标做 HPA。
首先,配置 Prometheus Adapter,把 QPS 指标转换成自定义指标:
bash
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-adapter-config
namespace: monitoring
data:
config.yaml: |
rules:
- seriesQuery: 'ai_model_call_total{namespace!="",pod!=""}'
resources:
overrides:
namespace: {resource: "namespace"}
pod: {resource: "pod"}
name:
matches: "^(.*)_total$"
as: "${1}_qps"
metricsQuery: 'sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)'然后,配置基于 QPS 的 HPA:
bash
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: spring-ai-service-qps-hpa
namespace: ai-service
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: spring-ai-service
minReplicas: 2
maxReplicas: 20
metrics:
# 自定义指标:单Pod每秒请求数超过100就扩容
- type: Pods
pods:
metric:
name: ai_model_call_qps
target:
type: AverageValue
averageValue: 100
# 保留CPU指标作为兜底
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
behavior:
scaleUp:
stabilizationWindowSeconds: 30
maxPods: 10
scaleDown:
stabilizationWindowSeconds: 300
maxPods: 3这个配置的意思是:当每个 Pod 的平均模型调用 QPS 超过 100,就自动扩容,最多扩容到 20 个副本,完美应对流量洪峰。
同样的,如果你是 GPU 推理场景,可以用 GPU 利用率指标做 HPA,核心逻辑是一样的。
5.3 AI 场景专项优化:伸缩冷却 + 副本保底 + 预热策略
针对 AI 服务的特点,我们给 HPA 做了三个专项优化,避免踩坑:
- 伸缩冷却时间优化:AI 服务的 Pod 启动慢,启动时间要 30 秒以上,所以扩容冷却时间设为 30 秒,保证新的 Pod 能正常启动;缩容冷却时间设为 5 分钟,避免流量波动导致的频繁缩容扩容,防止 "抖动";
- 副本保底策略:生产环境最小副本数最少设为 2 个,避免单点故障;如果是核心业务,建议设为 3 个以上,即使某个节点宕机,也不会影响服务;
- 预热策略:AI 服务的第一次模型调用、向量检索会比较慢,我们可以在 Pod 启动后,做一次预热请求,让 Spring AI 初始化模型客户端、向量数据库连接,等预热完成后,再把 Pod 加入 Service 负载,避免用户请求出现慢响应。
预热可以用 K8s 的生命周期钩子实现,在 Deployment 的 Pod 模板里加上:
bash
spec:
containers:
- name: spring-ai-service
# 启动后钩子,执行预热请求
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "sleep 20 && curl -X GET http://localhost:8080/actuator/health/readiness"]5.4 踩坑实录:为什么我的 HPA 始终不生效?
很多人配置了 HPA,但是发现不生效,这里给大家总结了最常见的几个坑,90% 的问题都在这里:
- 没安装 Metrics Server/Prometheus Adapter:HPA 获取不到指标,自然不会伸缩,一定要先确认指标能正常获取;
- 资源 requests 没配置:HPA 的 CPU / 内存利用率是基于 requests 计算的,如果没配置 requests,利用率就无法计算,HPA 不会生效;
- 伸缩阈值设的太高:比如 CPU 利用率阈值设为 90%,平时 CPU 利用率只有 30%,永远不会触发扩容;
- 副本数达到了 maxReplicas 上限:已经扩容到了最大副本数,自然不会再扩容;
- 指标标签不对:自定义指标的标签和 HPA 的配置不匹配,HPA 获取不到指标;
- 冷却时间设的太长:比如扩容冷却时间设了 10 分钟,一次扩容后,要等 10 分钟才会再次扩容,高峰期跟不上流量增长。
6. 全流程实战:GitLab CI/CD 实现 AI 应用自动部署
手动打包镜像、推送镜像、修改 K8s 配置、执行部署,不仅效率低,还很容易出错。我们用 GitLab CI/CD 实现了 Spring AI 应用的全流程自动化部署:代码提交到 GitLab 后,自动执行代码检查、单元测试、镜像构建、镜像推送、K8s 部署,全程不用人工干预,发布时间从 1 小时降到了 5 分钟,还避免了人工操作的失误。
6.1 流水线整体设计:从代码提交到线上部署的全流程
我们的 CI/CD 流水线分为 5 个阶段,完全贴合 Spring AI 服务的发布流程:
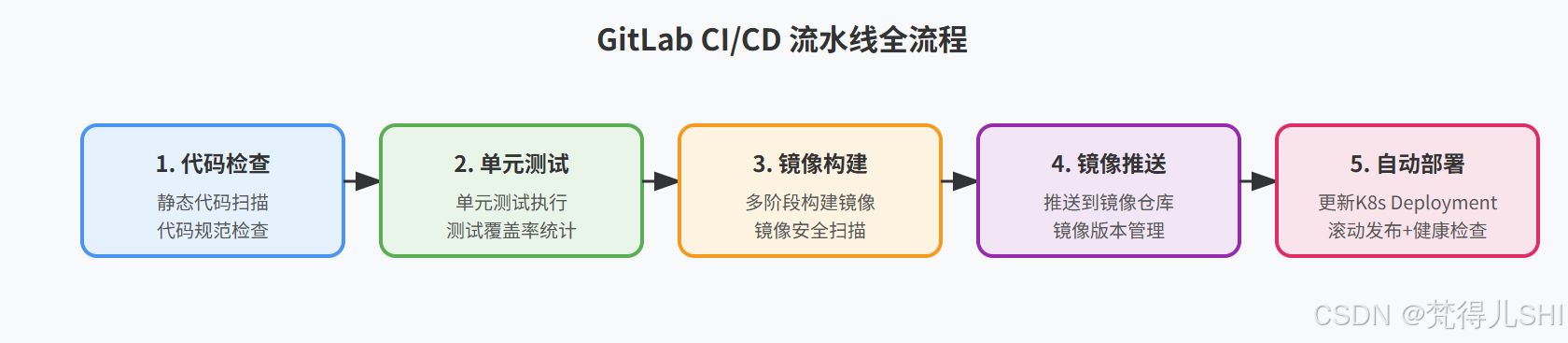
整个流水线的逻辑是:
- 代码提交到 GitLab 的指定分支,自动触发流水线;
- 先执行代码检查和单元测试,不通过则直接终止流水线,避免有问题的代码被发布;
- 测试通过后,执行多阶段构建,打包 Docker 镜像,做安全扫描;
- 镜像构建成功后,推送到 Harbor 镜像仓库,用 commit hash 做版本号,方便追溯;
- 最后自动更新 K8s 集群里的 Deployment 镜像,执行滚动发布,完成部署。
6.2 完整.gitlab-ci.yml 配置:分阶段详解
我把我们生产环境在用的.gitlab-ci.yml 整理好了,大家可以直接复制使用,适配 Spring AI 服务:
bash
# 全局变量
variables:
# 镜像仓库地址
REGISTRY_URL: harbor.your-domain.com
# 镜像仓库项目名
IMAGE_PROJECT: ai-service
# 镜像名称
IMAGE_NAME: spring-ai-service
# K8s命名空间
K8S_NAMESPACE: ai-service
# K8s Deployment名称
K8S_DEPLOYMENT: spring-ai-service
# 流水线阶段
stages:
- code-check
- test
- build
- push
- deploy
# 阶段1:代码检查
code-check:
stage: code-check
image: maven:3.9.6-eclipse-temurin-17
script:
- echo "开始代码静态检查"
- ./mvnw spotbugs:check checkstyle:check
only:
- main
- dev
tags:
- k8s-runner
# 阶段2:单元测试
unit-test:
stage: test
image: maven:3.9.6-eclipse-temurin-17
script:
- echo "开始执行单元测试"
- ./mvnw test -DskipTests=false
only:
- main
- dev
tags:
- k8s-runner
# 阶段3:镜像构建
build-image:
stage: build
image: docker:24.0.6-dind
services:
- docker:24.0.6-dind
script:
- echo "开始构建Docker镜像"
# 用Git commit hash作为镜像版本号,唯一标识
- export IMAGE_VERSION=$CI_COMMIT_SHORT_SHA
- export FULL_IMAGE_NAME=$REGISTRY_URL/$IMAGE_PROJECT/$IMAGE_NAME:$IMAGE_VERSION
# 登录镜像仓库
- docker login -u $REGISTRY_USER -p $REGISTRY_PASSWORD $REGISTRY_URL
# 构建镜像,用多阶段构建
- docker build -t $FULL_IMAGE_NAME .
# 镜像安全扫描
- docker scan $FULL_IMAGE_NAME --severity high
# 把镜像版本号写入临时文件,传递给后续阶段
- echo $FULL_IMAGE_NAME > image_version.txt
artifacts:
paths:
- image_version.txt
only:
- main
tags:
- k8s-runner
# 阶段4:镜像推送
push-image:
stage: push
image: docker:24.0.6-dind
services:
- docker:24.0.6-dind
script:
- echo "开始推送镜像到仓库"
- export FULL_IMAGE_NAME=$(cat image_version.txt)
- docker login -u $REGISTRY_USER -p $REGISTRY_PASSWORD $REGISTRY_URL
- docker push $FULL_IMAGE_NAME
# 给镜像打latest标签
- docker tag $FULL_IMAGE_NAME $REGISTRY_URL/$IMAGE_PROJECT/$IMAGE_NAME:latest
- docker push $REGISTRY_URL/$IMAGE_PROJECT/$IMAGE_NAME:latest
only:
- main
tags:
- k8s-runner
dependencies:
- build-image
# 阶段5:自动部署到K8s
deploy-to-k8s:
stage: deploy
image: bitnami/kubectl:1.29
script:
- echo "开始部署到K8s集群"
- export FULL_IMAGE_NAME=$(cat image_version.txt)
# 配置K8s集群访问凭证,存在GitLab的变量里
- echo "$K8S_KUBE_CONFIG" > ~/.kube/config
- chmod 600 ~/.kube/config
# 更新Deployment的镜像,执行滚动发布
- kubectl set image deployment/$K8S_DEPLOYMENT $IMAGE_NAME=$FULL_IMAGE_NAME -n $K8S_NAMESPACE
# 等待滚动发布完成
- kubectl rollout status deployment/$K8S_DEPLOYMENT -n $K8S_NAMESPACE --timeout=300s
- echo "部署完成,镜像版本:$FULL_IMAGE_NAME"
only:
- main
tags:
- k8s-runner
dependencies:
- build-image
- push-image
# 手动确认部署,避免误操作,生产环境建议开启
when: manual6.3 流水线优化:缓存加速 + 权限管控 + 密钥安全
上面的基础流水线可以直接跑,但是我们还做了几个优化,让构建速度更快,安全性更高:
1. Maven 缓存加速,构建时间从 10 分钟降到 1 分钟
每次构建都要重新下载 Maven 依赖,非常慢,我们用 GitLab Runner 的缓存功能,把 Maven 本地仓库缓存起来,不用每次都重新下载:
bash
# 全局缓存配置
cache:
paths:
- .m2/repository
key: ${CI_PROJECT_NAME}-maven-cache在 maven 命令里加上-Dmaven.repo.local=.m2/repository,指定本地仓库路径,就能复用缓存了。
2. 密钥安全管理,绝对不要把密钥写在配置文件里
镜像仓库的账号密码、K8s 的 kubeconfig 这些敏感信息,绝对不要写在.gitlab-ci.yml 里,要存在 GitLab 的项目变量里,也就是上面配置里的$REGISTRY_USER、$REGISTRY_PASSWORD、$K8S_KUBE_CONFIG,这些变量在 GitLab 项目的「设置」→「CI/CD」→「变量」里配置,不会被泄露。
3. 权限管控:不同分支对应不同环境
我们配置了多环境隔离:dev 分支提交自动部署到测试环境,main 分支合并后,需要手动确认才能部署到生产环境,避免误操作导致线上故障。
6.4 发布策略:滚动发布 + 一键回滚 + 多环境隔离
1. 滚动发布
我们用的是 K8s 的滚动发布策略,流水线里的kubectl rollout status命令会等待发布完成,如果发布失败,会自动回滚,不会影响线上服务。
2. 一键回滚
如果发布后出现问题,我们可以在 GitLab 里一键执行回滚流水线,或者直接用 kubectl 命令回滚:
bash
# 查看Deployment的发布历史
kubectl rollout history deployment/spring-ai-service -n ai-service
# 回滚到上一个版本
kubectl rollout undo deployment/spring-ai-service -n ai-service回滚是秒级完成的,比虚拟机部署的回滚速度快了几十倍。
3. 多环境隔离
我们用不同的 K8s 命名空间隔离开发、测试、生产环境:
- 开发环境:
ai-service-dev,dev 分支提交自动部署;- 测试环境:
ai-service-test,测试分支合并自动部署;- 生产环境:
ai-service,main 分支合并后手动确认部署。
不同环境的配置用不同的 ConfigMap 管理,完全隔离,不会出现测试环境的配置跑到生产环境的情况。
7. 踩坑总结:Spring AI 云原生改造的 8 个避坑指南
最后,给大家总结一下我们这半年云原生改造踩过的 8 个核心坑,大家可以直接避坑:
- 镜像体积太大,拉取超时:一定要用多阶段构建,分离构建和运行环境,用 jlink 裁剪 JRE,不要把模型文件打包到镜像里;
- 健康检查配置错误,发布时出现 503:一定要配置就绪探针,等 Spring 应用完全启动后,再把 Pod 加入 Service 负载,initialDelaySeconds 要设长一点;
- 容器 OOM,但是 JVM 没有堆溢出 :容器的内存 limits 一定要比 JVM 的最大堆内存大,JVM 的
-XX:MaxRAMPercentage参数要设为 75% 左右,不要让 JVM 把容器的内存占满; - Spring Cloud Kubernetes 权限不足:一定要给 Pod 配置 ServiceAccount 和 RBAC 权限,允许 Pod 访问 K8s 的 API,否则配置热更新、服务发现都用不了;
- HPA 不生效:先确认 Metrics Server/Prometheus Adapter 正常运行,Pod 配置了 resources.requests,指标能正常获取,阈值设置合理;
- CI/CD 流水线构建慢:一定要配置 Maven、Docker 的缓存,避免每次构建都重新下载依赖;
- 配置热更新不生效:给配置类加上 @RefreshScope 注解,开启 Spring Cloud Kubernetes 的 reload 配置,ConfigMap 的名称要和配置里的一致;
- GPU 调度失败:一定要提前安装 NVIDIA GPU Operator,用官方的 CUDA 基础镜像,Pod 的 GPU 资源配置要正确,不要用 limits 和 requests 不同的配置。
8. 总结与展望
总结
这篇文章里,我给大家完整分享了 Spring AI 服务从虚拟机部署到云原生容器化改造的全流程实战,从 Docker 镜像优化、K8s 全资源部署、弹性伸缩配置,到完整的 CI/CD 流水线落地,还有核心的 Spring Cloud Kubernetes 整合实践,所有的代码和配置都是我们生产环境验证过的,大家可以直接复制落地。
完成云原生改造后,我们的服务获得了这些核心收益:
- 环境一致性问题彻底解决:镜像里包含了所有运行依赖,彻底告别了 "本地能跑线上不行" 的问题;
- 发布效率提升 10 倍以上:从手动 1 小时发布,变成了自动化 5 分钟发布,滚动发布零停机,一键回滚;
- 扩容效率从半小时变成秒级:HPA 自动根据流量伸缩,高峰期自动扩容,低峰期自动缩容,从容应对流量洪峰;
- 资源利用率提升一倍以上:从原来的 30% 提升到了 70%,极大降低了服务器成本;
- 配置管理更规范:用 ConfigMap 和 Secret 管理配置,敏感信息加密存储,配置热更新不用重启服务。
展望
未来我们还会在云原生架构的基础上,做进一步的优化:
- 引入 Serverless K8s:用 Knative 实现基于请求的自动扩缩容,甚至可以缩容到 0,进一步降低资源成本;
- GPU 虚拟化与池化:用 GPU 虚拟化技术,实现多个 Pod 共享一张 GPU,提升 GPU 资源利用率,降低大模型部署成本;
- 模型预热与懒加载:实现模型的按需加载、预热,加快 Pod 启动速度,降低内存占用;
- GitOps 全流程管理:用 Argo CD 实现 GitOps,把 K8s 配置全部存在 Git 仓库里,实现配置的版本管理、审计、自动同步,进一步提升发布的安全性和规范性。
9. 参考文献
结语:以上就是 Spring AI 服务云原生容器化改造的全量实战分享,所有的代码和配置都可以直接复制到你的项目里使用。如果大家有任何问题,或者需要完整的配置文件,欢迎在评论区留言,我会一一回复。如果觉得这篇文章对你有帮助,别忘了点赞、收藏、转发三连,后续我还会分享更多 Spring AI 架构优化的实战干货,感谢大家的支持!