0.Overview
本次 project 我们要实现数据库系统(DBMS)的执行层。
计算机里没有魔法;当我们写下一个 sql,送进 DBMS 以发起一次查询/修改时,这条 sql 会先被送给 parser 解析,从而产生一个 sql 的抽象语法树(AST)。
接着解析结果会交给 binder,binder 会遍历上一步产生的 AST,找出 sql 语句中所有有意义的标识符,如表名、列名以及别名分析等,然后产生一个新的 AST。这个 AST 与 parser 产生的不同,binder 产生的 AST 会明确携带表达式的类型信息,而且包含了一些语法糖的解糖。
最后 binder 的 AST 被转交给 planer,将语法树转写为一个与实际物理结构有关的计划树(生成执行上下文、填入 table_oid_t 等),并且在交付给 execution engine 之前,调用 optimizer 优化计划树。
如果需要提前查看不同阶段的编译产物,我们可以用
EXPLAIN命令告知 DBMS 我们希望查看哪些部分。
一般 optimizer 有两种优化策略,基于规则的优化(RBO)以及基于代价模型的优化(CBO)。
CBO 要求 DBMS 在运行时动态维护一个代价模型,代价模型一般会包括 IO 代价、内存使用代价、甚至包括优化代价本身。
而 RBO 则简单地实现多条优化规则,并且按照某个固定顺序调用它们,从而完成计划树的优化。
优化规则是存在依赖关系的;而且在某些情况下,后执行的规则可能还会要求重复执行已经执行过的规则(甚至包括自身),这被称为 fixed-point optimization,因此 RBO 的优化规则调用顺序相当重要。
在执行器设计上,BusTub 采用的是带向量优化的火山模型,这类模型要求每个算子都必须有 Init() 和返回一个 bool 的 Next() 方法,执行引擎会调用根结点的 Next() 自上而下、递归地从最底层的算子中提取一批数据;如果某次调用的 Next() 返回 false,表示对应算子的数据已经全部提取完毕,没有更多数据。
为了实现各种执行算子,Project#3 要求我们深入阅读并使用 BusTub 的代码,但不包括 Project#4 的部分。我们已经在之前大概讲解过了 BusTub 管理 tuple 以及 table 的方法,所以这里不再重复阐述。
1.Task#1 - Access Method Executors
Task#1 相当简单,算是整个 project 的 introduction;在本次任务里,我们要实现以下几个算子:
SeqScanInsertUpdateDeleteIndexScan
以及一条优化规则 OptimizeSeqScanAsIndexScan。
Insert、Update、Delete 都可以对应到具体的 sql 语句,也就是和它们同名的 insert、update 和 delete;而 SeqScan 则负责顺序扫描整张表,它是整个执行层的基础数据产出算子。
1.1 Insert、Update 与 Delete
这三个算子的实现非常简单。
Insert 需要在插入过程中同时维护索引(若有)的完整性,并且必须在单次 Next() 调用中插入所有数据,然后向上传递本次插入了几行。
BusTub 承诺不会插入重复的行,所以我们不需要考虑处理重复元素插入到索引中的问题(Project#2 假定 B+ 树不处理重复索引)。
Update 和 Delete 一个性质,为了支持事务机制,DBMS 不可能在删除一个 tuple 时立即把对应数据从物理上抹除,所以我们必须通过 TableHeap 记录的 TupleMeta 标记某个 tuple 是否被删除。
而且正因为这种延迟删除性质,Update 必须被实现为先删除后插入。
1.2 SeqScan 与 IndexScan
每个算子都继承自 AbstractExecutor,而这个顶级基类存储了执行上下文 exec_ctx_,上下文里有当前执行环境所需的数据库目录 catalog_,我们可以配合计划树结点信息从中找到要扫描的表的 table_oid_,然后去找索引或者表的迭代器。
因为我们总是延迟删除 tuple,在做全表/全索引扫描时,我们不能把 TupleMeta 被标记删除了的 tuple 传递给上层算子。
而且特别有意思的是,SeqScan 有一个谓词表达式;这是因为严格意义上的火山模型在执行形如 SELECT * FROM a WHERE a.x > 3; 的查询时,会生成 Filter -> SeqScan 的结构,这种结构会在 Filter 处产生大量无意义且被立即丢弃的 tuple,拖慢执行速度。
因此我们可以把 Filter 的过滤逻辑下推到 SeqScan 执行时,这样就可以只返回满足谓词需求的 tuple;这种优化技术被称作谓词下推。
要注意,BusTub 的表达式计算模型允许出现 Null(
Value::IsNull()),因此一个 boolean 谓词有着三元结果:NULL、true和false,但 C++ 的bool是二元的,所以我们要把NULL视作与false等价
由于 BPlusTree 的键大小是一个模板参数,也就是一个编译期常量,而 IndexScan 的执行在运行期,这导致我们必须手动枚举索引结构的键大小,然后才能将索引信息 Index 转换为正确的 B+ 树类型。
不得不吐槽的是,BusTub 存储了很多重复的索引信息,例如 IndexInfo::key_size_ 是索引键的长度(按字节),IndexInfo::key_schema_ 按照每列的字节大小求和也是索引键的长度,直接访问 IndexMetadata::key_schema_ 也可以按列统计索引长度,这就显得非常冗余;而且一份数据放得到处都是很让人担心。
简单起见,只访问 IndexInfo::key_size_ 就好,毕竟可以少几次指针跳转。
1.3 OptimizeSeqScanAsIndexScan
IndexScan 与 SeqScan 相似,不过 IndexScan 是在索引上做全表扫描,这里多了一个间接层。
在 Project#2 中,我们完成了一个基础的索引结构 B+ 树,索引结构的键是一个可变长度的 GenericKey,所以我们可以在一张表的部分列上构造一个索引;列数大于 1 的索引叫复合索引。
而且我们实现的索引结构是一个有序关联容器,这使得顺序遍历 B+ 树的叶子结点时,返回的 tuple 天然按照某个顺序排列;于是类似于 ORDER BY 的操作可以直接优化为一个简单的 IndexScan。
但我们只能优化带有谓词的 SeqScan(还记得谓词下推吗?),而且谓词必须引用了某个被索引的列,因为只有这种谓词才能决定我们要在哪个索引上进行全表扫描。
BusTub 的优化策略比较反直觉,采用的是自底向上优化,也就是说一个优化规则总是先作用在子结点上,然后才应用到当前结点中;具体含义可以看已经提供好的优化规则。
为了将 SeqScan 优化为 IndexScan,我们必须遍历 SeqScan 的谓词(用 dynamic_cast 检查表达式类型),实际上就是遍历整个表达式树(也属于一种抽象语法树 AST),找出所有类型属于 ColumnValueExpression 的表达式项,然后检查列引用是否属于当前表的一个索引。
如果有多个满足条件的索引,我们要选取其中最长的那个,而且被选中的索引必须满足前缀匹配(也就是不能跳列)。
而且有趣的是,如果索引发生在一个 > 或 >= 比较上,由于我们实现的 BPlusTree 是默认升序的,我们可以把扫描起始点定在常量表达式的 max lower bound 处,这样一来我们可以跳过很多一定会被过滤掉的 tuple。
这还是因为 B+ 树用升序存储了所有 tuple,如果我们通过谓词逻辑分析找到了一个"最紧"的 lower bound,显然在索引结构中,小于这个下界的 tuple 一定不满足谓词表达式,因此我们完全没必要访问它们。
总而言之,我们可以得到一个比较抽象的伪代码演示:
python
# 我们借用一点 python 的语法结构描述伪代码
def OptimizeSeqScanAsIndexScan(plan):
children = [] # 自底向上优化
for child in plan.GetChildren():
children.append(OptimizeSeqScanAsIndexScan(child))
optimized_plan = plan.CloneWithChildren(children)
if optimized_plan is not SeqScanPlanNode:
return optimized_plan
seq_scan_plan = optimized_plan as SeqScanPlanNode
if seq_scan_plan.filter_predicate_ is None:
return optimized_plan
if seq_scan_plan.filter_predicate_ is ComparisonExpression:
# ComparisonExpression 有且仅有两个 children
# 检查这两个 children 是否一个是 ColumnValueExpression 而另一个是 ConstantValueExpression
# 然后分析是否引用了索引,并且是否是索引的一个前缀,并构造一个 IndexScanPlanNode 后返回
return IndexScanPlanNode()
if seq_scan_plan.filter_predicate_ is LogicExpression:
# 递归遍历表达式树,找到所有索引信息,按照索引信息分组并升序排列 ColIdx,以便后续做前缀匹配
# 如果有足够精力的话,可以在这里引入谓词逻辑分析,根据合取/析取的特性提取常量表达式
# 然后尽可能地将全索引扫描转化为一个 PointLookup 或者部分索引扫描
return IndexScanPlanNode()
# 如果谓词不属于以上两个表达式,没法优化
return optimized_plan因为树的遍历(几乎)必须采用 DFS 以及递归逻辑,非常建议在 optimizer/optimizer_internal.h 里写一个负责构造遍历表达式树的模板函数:
cpp
// 遍历表达式树
template <typename ExprType, typename F>
auto WalkAST(ExprType &&root, F &&visitor) -> decltype(auto) {
return visitor(visitor, std::forward<ExprType>(root));
}
// primary 决定了调用 visitor 还是 alternative,如果有两个遍历路径要走,可以传递一个 bool 参数选择
template <typename ExprType, typename F1, typename F2>
auto WalkAST(bool primary, ExprType &&root, F1 &&visitor, F2 &&alternative) -> decltype(auto) {
if (primary) {
return visitor(visitor, std::forward<F2>(alternative), std::forward<ExprType>(root));
}
return WalkAST(std::forward<ExprType>(root), std::forward<F2>(alternative));
}假设我们需要遍历 SeqScan 的谓词,我们可以这样做:
cpp
auto optimized_plan = /* 自底向上优化子结点,得到一个新的、优化后的计划树结点 */
if (optimized_plan->GetType() != PlanType::SeqScan) {
return optimized_plan;
}
auto &seq_scan_plan = static_cast<SeqScanPlanNode &>(*optimized_plan);
// 可以看出 WalkAST 相当于一个递归启动器,也就是所谓的不动点组合子
WalkAST(seq_scan_plan.filter_predicate_.get(), [&](auto &self, const AbstractExpression *expr) -> void {
if (const auto column = dynamic_cast<const ColumnValueExpression *>(expr); column != nullptr) {
/// do something...
return; // 提前返回
}
// 递归遍历子表达式
for (const auto &subexpr : expr->GetChildren()) {
self(self, subexpr.get());
}
});此外,如果索引是一个部分索引,也就是只有满足某些条件的列值,对应的 tuple 才会被计入索引中,那么将 SeqScan 优化为 IndexScan 可以降低一部分扫描开销,因为我们要扫描的行数少了。此时的优化操作要求我们分析谓词逻辑以维持逻辑等价性。
但 BusTub 的索引是普通索引,它记录了表中所有 tuple,因此一个不带有 lower bound 截断的 IndexScan 与 SeqScan 是等价的。
而且前面说过,BusTub 采用的是 RBO 优化策略,这导致一个问题:即使 IndexScan 能够降低扫描开销,这也必须要求被扫描索引是聚簇索引;但很明显,我们实现的 BPlusTree 的叶子结点存储的都是指向实际存储位置的 RID,也就是非聚簇索引。
在非聚簇索引下,盲目将 SeqScan 优化为 IndexScan 会导致严重的读放大问题:为了读取一行 tuple,我们一共发起了至少两次 IO(找 B+ 树叶子结点、通过叶子节点记录的 RID 找实际的 tuple);所以优化策略的实现完全是一个 trade-off 问题。
2.Task#2 - Aggregation and Join Executors
2.1 Aggregation
sql 的聚合函数一般是通过哈希表完成的;也就是说 GROUP BY colA, colB 会被实现为 unordered_map<pair<colA, colB>, AggregateFunction>。
这很符合直觉,本来 GROUP BY 就是按照某个列做分组,然后把整张表的数据作用在多个聚集函数上,得到一个看上去像拍扁整张表的结果。
BusTub 预定义了一个设计上非常别扭的哈希表 SimpleAggregationHashTable,实际上就是对 std::unordered_map 的一个封装,用不用都随便。
顺便一提,BusTub 的哈希策略产生的哈希质量相当烂,因为它提供的
HashUtil::CombineHashes()是一个非常简单的线性混淆算法,很难在有限步内将低位和高位的信息混淆在一起,而且更不用提产生原始哈希值的HashUtil::HashValue()基本上就是拿原始值做线性混淆,本身质量也不怎么样;有能力的话自己写一个更好。
只要实现了这个别扭的哈希表基本上就完成了 Aggregation 的功能,整个算子实现起来还算简单;唯一要注意的是,在实现 AggregateKey 时,两个 NULL 的比较应该被视作相等(可以用 CompareExactlyEquals() 方法),而不是一般序关系认为的 unordered。
而且比较关键的是,Aggregation 是一个 pipeline breaker 算子,也就是说这个算子必须消耗了下层算子的所有数据之后才能向上提供数据。
很显然,这是因为 aggregation 必须读取了所有数据才能做数据聚合。
一般来说,具有 pipeline breaker 性质的算子都会在 Init() 方法中完成下层数据读取,不过写在 Next() 里做一次 call once 初始化也是可以的。
还有一点比较坑,形如 SELECT COUNT(*) FROM table; 的 sql,即使 table 是一个空表,它也必须返回一个数字 0。这是因为 COUNT(*) 本质上只是统计这张表一共有几行,一个空表自然要返回 0 行.
但如果加上一个 GROUP BY,也就是写成:SELECT COUNT(*) FROM table GROUP BY colA;,那么又可以什么都不返回了;因为分组结果是空的,所以自然不存在对空分组结果的统计结果,所以与 COUNT(*) 不同,此时什么都不需要输出。
2.2 Nested Loop Join
从 NLJ 开始,接下来我们实现的全都是重量级算子。
NLJ 要求同时遍历左右两张表,并且按照连接属性将两张表的 tuple 拼在一起;BusTub 只要求我们实现 LEFT JOIN 和 INNER JOIN。
因为是遍历两张表,在代数结构上 NLJ 与一个嵌套双重循环是等价的:
python
def Next(tuple_batch):
mismatched = []
for left_tuple in left_table:
matched = False
for right_tuple in right_table:
if plan_.Predicate().EvaluateJoin(left_tuple, right_tuple):
tuple_batch.append(Concat(left_tuple, right_tuple))
matched = True
if not matched:
mismatched.append(left_tuple)
if plan_.GetJoinType() == JoinType::LEFT:
for unmatched in mismatched:
tuple_batch.append(ConcatWithNull(unmatched)) # 补 NULL但 BusTub 的算子采用了向量化优化,实际情况会比这要复杂:我们要一次提取一批左表,然后在遍历右表的同时,将右表的所有 tuple 与手中这批左表的每一项进行比较;并且在右表扫描结束后,如果是 LEFT JOIN,还需要用 NULL 补齐没有匹配的左表行并输出,否则要重新获取一批左表,重复上述过程直到左表扫描结束。
不过无论如何我们都要多次遍历右表,而且必须牢记的是:左表的某一行完全有可能与右表的多行相匹配。
正所谓 Everything is a state machine,一个 NLJ 算子可以用如下几个状态描述:
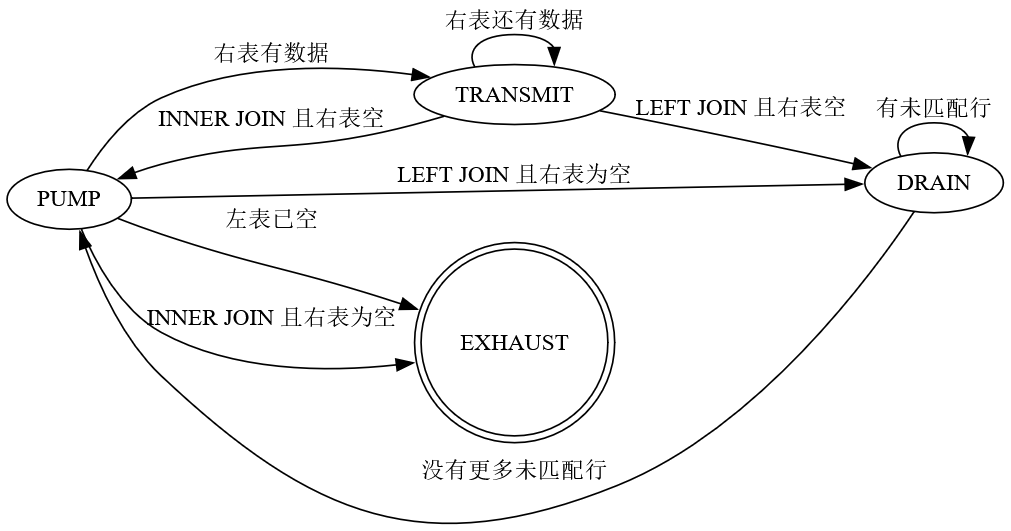
用状态机实现的好处是,因为每次调用 Next() 时我们提交的 tuple 数量是有限的,一个状态机可以维持多个 Next() 之间的状态变换,实现 tuple 的"断点续传"。
最后有一个很莫名其妙的地方:sqllogictest 里会检查 NLJ 的右算子调用 Init() 的次数是否大于等于左算子调用 Next() 的次数,这意味着实验期待的是强制性的嵌套循环,不允许一次读取大量左表以减少右表的扫描次数。
本意是限制大家把整张表加载到内存上做匹配,但这个限制有点拙劣。
2.3 Nested Index Join
如果 NLJ 的右表有索引,而连接条件又恰好包含了对应的索引,我们就可以用 NIJ 替代 NLJ,只全表扫描左表,然后用左表 tuple 的列,去右表索引中查找对应的右表 tuple 进行匹配。
与 NLJ 相比,NIJ 可以极大减少无关 tuple 的访问。
NIJ 的实现与 NLJ 类似,同样可以采用状态机描述,而且状态与跳转流程几乎相同,所以不再重复阐述。
不同点在于 NIJ 不再区分左表或右表,而是用 inner table 和 outer table 代称;而且右表索引有可能返回一批匹配的 RID。
一般来说,outer table 是需要被全量保留的表,也就是 LEFT JOIN 的左表;而 inner table 则相反。
在 NIJ 中我们需要直接访问索引结构产生的迭代器,这里的实现和 IndexScan 是相似的,因此同样需要注意不要提交被标记为删除的 tuple。
3.Task#3 - HashJoin Executor and Optimization
3.0 IntermediateResultPage
我们先来实现临时结果页。
根据 instruction,Hash Join 和之后的 External Merge Sort 都需要用到它;其中当且仅当使用 Grace Hash Join 策略的时候我们才会在 Hash Join 里使用到 IntermediateResultPage。
不难发现,无论是 Grace Hash 还是 External Merge Sort,它们都会在产生一个结果页之后不再修改这个页的内容。
对于 Grace Hash 来说,可以将每个结果页视作是一个哈希桶,显然一个哈希桶生成完毕后就只需要遍历其中存储的 tuple 检查匹配,不存在需要修改或者删掉其中 tuple 的情况。
对于 External Merge Sort 来说,每个结果页可以被视作是一个归并段,根据 k 路归并排序原理,我们同样只需要同时顺序读取 k 个归并段的内容,不需要也不应该修改或删除其中的 tuple。
所以我们要实现的是一个不可变数据结构,而不可变这一性质相当美妙,因为它可以让我们的存储结构变得非常紧凑。
通过阅读 Tuple 类型的实现不难发现,一个 tuple 就是由一个 RID 和一段二进制数据构成的,而 RID 本身满足 trivially copyable 和 standard layout,所以 RID 类型可以整个二进制序列化;因此我们可以按布局结构存储整个 Tuple。
但千万不要直接
std::memcpy整个Tuple对象,因为里面的std::vector不满足 trivially copyable,我们必须单独提取Tuple的RID和二进制数据(通过GetRid()和GetData())。
我们可以参考 src/include/storage/page/table_page.h 里 TablePage 的实现,得到以下布局结构:
cpp
class IntermediateResultPage {
// +----------------------------+----------------+--------------------+---------------------+
// | Number of tuples (2 bytes) | Tuple Location | ... Free Space ... | Payload (RID, Data) |
// +----------------------------+----------------+--------------------+---------------------+
// ^~~~~~~~~~~~~~~~~~~ Header ~~~~~~~~~~~~~~~~~~~^
std::byte page_start_[0]; // 便于索引页内容
uint16_t num_tuples_;
uint16_t offsets_[0]; // offsets_ 的大小恰是 num_tuples_ 的大小
// 根据传入的 tuple 大小估计一个 page 里能存放几个这样的 tuple
// 在某些时候会需要用到这个函数估计某些参数
static constexpr auto Capacity(size_t tuple_length) noexcept -> uint16_t {
// 设结果为 x,则有不等关系:
// x * (sizeof(RID) + tuple_length + sizeof(uint16_t)) + sizeof(uint16_t) <= BUSTUB_PAGE_SIZE
// 若取相等构造方程,则可得能够容纳的 tuple 的数量,且结果向下取整
return (BUSTUB_PAGE_SIZE - sizeof(uint16_t)) / (sizeof(RID) + tuple_length + sizeof(uint16_t));
}
// IntermediateResultPage 必须分配在 bpm 产生的一个 8 KB 大小数组上
// 所以必须有一个与构造函数无关的初始化函数
void Init() noexcept { num_tuples_ = 0; }
};题外话:为了满足 implicit-lifetime 约束(见前文),我们不应该显式定义
IntermediateResultPage的构造函数。
虽然 External Merge Sort 和 Hash Join 在比较时只会用到 tuple 的一部分列 value,但重复存储 value 会导致一个 page 能容纳的 tuple 数量迅速降低,毕竟一个 page 也就 8 KB 大小;所以我们不存储额外无关数据。
为了方便访问 page 上的 tuple,我们可以定义一个这样的类型:
cpp
struct FragileTuple {
RID rid_;
uint16_t size_;
const char *data_;
operator Tuple() const { return {rid_, data_, size_}; } // NOLINT
};这样 IntermediateResultPage 的访问接口就可以返回这个能够隐式转换为 Tuple 的代理类型,而不需要每次访问都实际构造一个 Tuple(有动态内存分配开销)。
3.1 Hash Join
如果我们有一个 NLJ,虽然连接条件全是等值谓词,但是这些谓词全都不发生在索引上,我们就不能用 NIJ 优化连接。
不过因为全都是等值谓词,我们可以将连接条件中的列按照它们的哈希值进行分类,分类后所有可能满足谓词条件的 tuple 必然会存放在同一组中,因此我们可以用这些局部分组之间的 Nested Loop 替换整张表上的 Nested Loop。
在 Hash Join 中,我们把存放在哈希表中的表叫做 build table,另一张去哈希表中匹配的表叫 probe table。
Hash Join 有两种实现:Simple(或者叫 Basic)Hash Join 和 Grace Hash Join。前者只是单纯把 build table 整个加载到内存上的哈希表中,这在表不大于内存容量时很有效。但如果 build table 是一个巨量的表,不能一次装进内存的时候,就需要使用 Grace Hash Join 算法。
3.1.1 Grace Hash Join
Grace Hash Join 的做法是:构造一个哈希函数 H 1 H_1 H1,根据左表和右表的大小划分多个哈希桶,两张表的哈希桶数量一定相等(不相等会导致有错误失匹的 tuple),而且要确保单个哈希桶的 tuple 容量不超过内存限制;接着分别遍历左表和右表,用 H 1 H_1 H1 计算拿到的每个 tuple 的哈希值并丢到对应桶中。
这些划分的哈希桶会被存放在磁盘上,而且如果扫描过程中发现一个桶的 tuple 数量过多,超出了原来规定的 tuple 数量限制,此时意味着发生了数据倾斜。
这种情况可能是表中某一列有海量相同数据(例如一个身份信息表里面大约一半人性别是"男",另一半是"女"),也可能只是运气不好发生了大规模哈希冲突,对于严格的 Grace Hash Join 来说,为了解决这种严重的数据倾斜问题,必须对这个桶内的数据进行一次递归哈希。
所谓递归哈希就是将溢出的哈希桶本身当作目录,并基于目录大小划定多个哈希桶,将倾斜的数据按照额外构造的另一个不同的哈希函数派发到这些桶中。
非常容易想到的是,递归哈希过程同样可能导致溢出的哈希桶内的某个哈希桶又一次溢出了,这就是一次极为严重的数据倾斜;不过我们同样可以再次递归哈希处理。
当然,如果运气背到多次哈希依然会溢出,那么就不应该继续递归哈希(所以要有一个最大递归哈希次数限制),但这种时候就有很多不同的解决方案:例如可以更换算子实现,或者就把这些 tuple 全部存到桶中然后分批做 Nested Loop 匹配。
当两张表都扫描完了之后,我们就能两两遍历两张表的哈希桶(因此哈希桶数量必须相等),这两个桶内的元素都是哈希值相等的元素,也即所有列值可能相等的 tuple 全部都在这个哈希桶内;并且最重要的是,这个桶一定可以被全量加载到内存上。现在我们取第二个不同的哈希函数 H 2 H_2 H2,将左表哈希桶全量加载到 H 2 H_2 H2 构成的哈希表中,然后用这张哈希表去匹配右表的哈希桶内元素。
3.1.2 Hybrid Hash Join
回到实验,BusTub 并不限制我们用哪种哈希策略,纯粹的内存上哈希表也行,Grace Hash 也可以,虽然 instruction 确实推荐实现 Grace Hash。
但是 Grace Hash 的递归哈希分区要求我们维护不同哈希桶的状态,这太复杂了,我采用的是更简单的 Hybrid Hash Join 策略。
和 Grace Hash 相比,Hybrid Hash 会按顺序执行以下策略:
- 如果左表可以被全量加载到内存上,则采用关于左表的 Basic Hash Join
- 如果右表可以被全量加载,则采用关于右表的 Basic Hash Join
- 否则执行不带递归哈希分区的 Grace Hash 策略
所谓不带递归哈希分区的 Grace Hash,是指不再检测是否出现数据倾斜,反而一股脑地把数据全部丢到对应哈希桶里,最后根据这个哈希桶的大小,决定哈希桶内的匹配采用 Basic Hash Join 还是 Nested Loop Join。
为了支持一股脑丢数据,我们要维护一个基于 IntermediateResultPage 的数组,也就是自动将溢出数据转移到下一个结果页上。
这可以通过添加一个新的类型实现:
cpp
class IntermediateResults {
BufferPoolManager *bpm_{nullptr};
std::vector<page_id_t> pages_{};
bool require_page_{true};
public:
class Iterator {
BufferPoolManager *bpm_{nullptr};
std::vector<page_id_t>::const_iterator cursor_;
std::vector<page_id_t>::const_iterator terminus_;
ReadPageGuard reader_;
size_t offset_{0};
/// ...
};
/// Insert() 和 Begin() 等函数
};通过定义该类型,我们可以将多个 page 的数据插入抽象为一个流式数据传输(通过 Iterator 实现),这能极大减轻我们的心智负担。
此时我们的每个哈希桶就是一个 IntermediateResults 对象,扫描结束后,每轮 Nested Loop 时都用迭代器从里面提取一批数据即可。
不过非常可悲的是,BusTub 并不提供获取一张表的 tuple 数量的接口,这使得我们根本无从提前获知一张表是否足够大。
所以我们要手动维护一个内存限额,并通过左表和右表的 tuple 大小计算内存内最多可以容纳多少条 tuple 解决这个问题。
如果某个哈希桶实在过大,我们就需要 fallback 到最基础的 NLJ 实现,所以 Hybrid Hash Join 里面还得内嵌一个简化版的 NLJ 逻辑。
实际上实现时最简单的 Hybrid Hash 策略也远比我在这里所说的要复杂得多的多,整个 project 的绝大多数时间都花费在了这上面,我实现的 Hybrid Hash Join 的状态图如下,可以从中粗略看出复杂度:
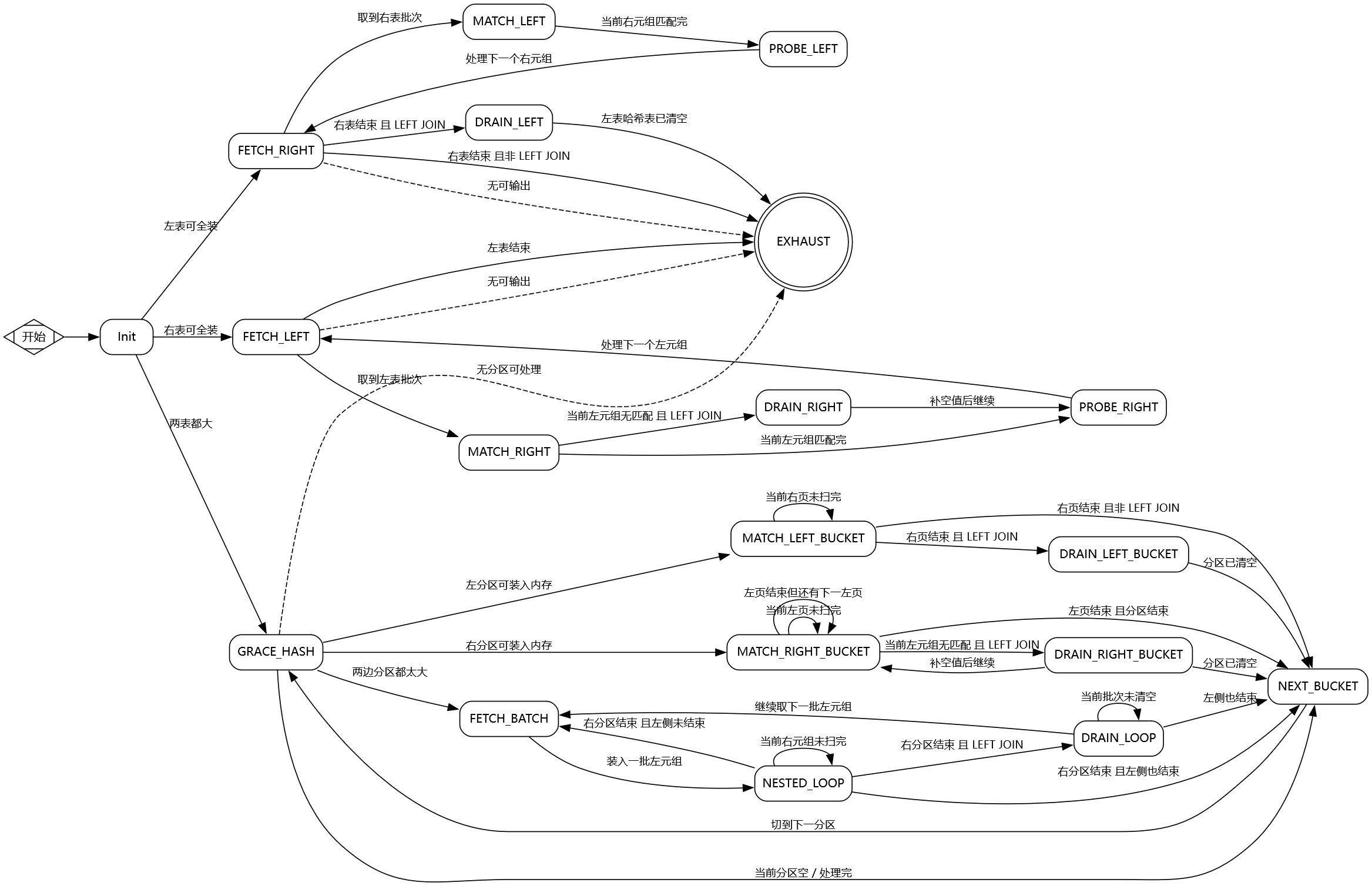
实际的渲染代码长这样:
dot
digraph HybridHashJoin {
rankdir=LR;
bgcolor="white";
node [shape=box, style="rounded", fontname="Microsoft YaHei", fontsize=12];
edge [fontname="Microsoft YaHei", fontsize=11];
start [shape=Mdiamond, label="开始"];
exhaust [shape=doublecircle, label="EXHAUST"];
init [label="Init"];
fetch_right [label="FETCH_RIGHT"];
probe_left [label="PROBE_LEFT"];
match_left [label="MATCH_LEFT"];
drain_left [label="DRAIN_LEFT"];
fetch_left [label="FETCH_LEFT"];
probe_right [label="PROBE_RIGHT"];
match_right [label="MATCH_RIGHT"];
drain_right [label="DRAIN_RIGHT"];
grace_hash [label="GRACE_HASH"];
next_bucket [label="NEXT_BUCKET"];
match_left_bucket [label="MATCH_LEFT_BUCKET"];
drain_left_bucket [label="DRAIN_LEFT_BUCKET"];
match_right_bucket [label="MATCH_RIGHT_BUCKET"];
drain_right_bucket [label="DRAIN_RIGHT_BUCKET"];
fetch_batch [label="FETCH_BATCH"];
nested_loop [label="NESTED_LOOP"];
drain_loop [label="DRAIN_LOOP"];
start -> init;
init -> fetch_right [label="左表可全装"];
init -> fetch_left [label="右表可全装"];
init -> grace_hash [label="两表都大"];
fetch_right -> match_left [label="取到右表批次"];
fetch_right -> drain_left [label="右表结束 且 LEFT JOIN"];
fetch_right -> exhaust [label="右表结束 且非 LEFT JOIN"];
match_left -> probe_left [label="当前右元组匹配完"];
probe_left -> fetch_right [label="处理下一个右元组"];
drain_left -> exhaust [label="左表哈希表已清空"];
fetch_left -> match_right [label="取到左表批次"];
fetch_left -> exhaust [label="左表结束"];
match_right -> drain_right [label="当前左元组无匹配 且 LEFT JOIN"];
match_right -> probe_right [label="当前左元组匹配完"];
probe_right -> fetch_left [label="处理下一个左元组"];
drain_right -> probe_right [label="补空值后继续"];
grace_hash -> next_bucket [label="当前分区空 / 处理完"];
grace_hash -> match_left_bucket [label="左分区可装入内存"];
grace_hash -> match_right_bucket [label="右分区可装入内存"];
grace_hash -> fetch_batch [label="两边分区都太大"];
next_bucket -> grace_hash [label="切到下一分区"];
match_left_bucket -> match_left_bucket [label="当前右页未扫完"];
match_left_bucket -> drain_left_bucket [label="右页结束 且 LEFT JOIN"];
match_left_bucket -> next_bucket [label="右页结束 且非 LEFT JOIN"];
drain_left_bucket -> next_bucket [label="分区已清空"];
match_right_bucket -> match_right_bucket [label="当前左页未扫完"];
match_right_bucket -> drain_right_bucket [label="当前左元组无匹配 且 LEFT JOIN"];
match_right_bucket -> next_bucket [label="左页结束 且分区结束"];
match_right_bucket -> match_right_bucket [label="左页结束但还有下一左页"];
drain_right_bucket -> next_bucket [label="分区已清空"];
drain_right_bucket -> match_right_bucket [label="补空值后继续"];
fetch_batch -> nested_loop [label="装入一批左元组"];
nested_loop -> nested_loop [label="当前右元组未扫完"];
nested_loop -> drain_loop [label="右分区结束 且 LEFT JOIN"];
nested_loop -> next_bucket [label="右分区结束 且左侧也结束"];
nested_loop -> fetch_batch [label="右分区结束 且左侧未结束"];
drain_loop -> drain_loop [label="当前批次未清空"];
drain_loop -> next_bucket [label="左侧也结束"];
drain_loop -> fetch_batch [label="继续取下一批左元组"];
fetch_right -> exhaust [style=dashed, label="无可输出"];
fetch_left -> exhaust [style=dashed, label="无可输出"];
grace_hash -> exhaust [style=dashed, label="无分区可处理"];
{ rank=same; fetch_right; fetch_left; grace_hash; }
}其中每个状态所需要的 context 是不同的,所以我用了一个 std::variant 维护多个状态上下文,它长这样:
cpp
struct Entry {
Tuple tuple_;
// Entry 可以同时表示二次 hash 后的左表或右表,这个 matched_ 仅供左表使用
bool matched_; // NOLINT
// 不禁用 linter 的话 clang-tidy 会在这里左脑打右脑
Entry() : matched_{false} {}
explicit Entry(Tuple &&tuple) : tuple_{std::move(tuple)}, matched_{false} {}
};
// 因为不同行的同一列是允许有相同值的,所以同一个 key 可能对应多个 tuple
using HashTable = std::unordered_multimap<std::vector<Value>, Entry, ValuesHash<>, EqualTo>;
// 用于 simple hash join
struct MemProber {
HashTable hash_table_;
std::vector<Tuple> tuples_;
std::vector<Value> key_;
HashTable::iterator iter_, terminus_;
bool matched_; // 同上
explicit MemProber(HashTable &&hash_table) : hash_table_{std::move(hash_table)} {}
MemProber(HashTable &&hash_table, std::vector<Tuple> &&tuples)
: hash_table_{std::move(hash_table)}, tuples_{std::move(tuples)} {}
void Reset(const Tuple &tuple, const std::vector<AbstractExpressionRef> &key_exprs, const Schema &schema) {
key_ = TakeKeys(tuple, key_exprs, schema);
std::tie(iter_, terminus_) = hash_table_.equal_range(key_);
}
};
// 用于 grace hash join
struct GraceProber {
struct Target {
Tuple tuple_;
std::vector<Value> key_;
// 同上
bool matched_; // NOLINT
Target() : matched_{false} {}
};
HashTable hash_table_;
IntermediateResults::Iterator disk_iter_;
HashTable::iterator hash_iter_, terminus_;
Target detector_;
GraceProber(HashTable &&table, IntermediateResults::Iterator &&iter)
: hash_table_{std::move(table)}, disk_iter_{std::move(iter)} {}
void Reset(Tuple &&tuple, const std::vector<AbstractExpressionRef> &key_exprs, const Schema &schema) {
detector_.tuple_ = std::move(tuple);
detector_.key_ = TakeKeys(detector_.tuple_, key_exprs, schema);
detector_.matched_ = false;
std::tie(hash_iter_, terminus_) = hash_table_.equal_range(detector_.key_);
}
};
// 用于对两个超大 hash 分区做 nested loop
struct Matcher {
IntermediateResults::Iterator left_iter_, right_iter_;
Tuple right_tuple_;
std::vector<Value> right_key_;
std::vector<Tuple> left_tuples_;
std::vector<std::vector<Value>> left_keys_;
std::vector<bool> matched_;
size_t tuple_cursor_;
explicit Matcher(IntermediateResults::Iterator &&left_iter) : left_iter_{std::move(left_iter)} {}
};
std::variant<std::monostate, MemProber, GraceProber, Matcher> context_;
size_t cursor_;至于到底要采用哪种哈希策略就看个人本事了。
3.2 OptimizeNLJAsHashJoin
和上一个需要实现的优化规则相比,NLJAsHashJoin 的需求以及实现简单到过分了。
根据 Hash Join 的原理,只有等值条件才能采用哈希分区,并在分区内做 Nested Loop 匹配;那么显而易见的是,我们只需要遍历并找出 NLJ 算子谓词引用的所有列,以及这个列所属的表和谓词条件,如果 NLJ 的连接条件只涉及了等值条件,且等值判断两侧引用的列分别来自两张表,那么就可以把 NLJ 优化为 Hash Join。
比较有意思的是,初始的 planer 只会产生一种形如
Filter -> NLJ的结构,此时 NLJ 中不包含对应的谓词逻辑,而 Filter 会在稍后执行优化规则OptimizeMergeFilterNLJ的时候被下推给 NLJ 算子。因此 NLJ 的谓词逻辑首先依赖于前面的谓词下推规则,而我们目前要实现的这一规则显然就需要依赖自谓词下推优化,因此
OptimizeNLJAsHashJoin的执行显然必须晚于OptimizeMergeFilterNLJ。
注意我们必须限制等值条件来自合取表达式,也就是由 AND 连接的多个谓词,并且不能包含 OR(析取)。
这是因为合取表达了约束范围的收缩,而析取表示约束条件的扩大:AND 连接的多个谓词必须全部都成立,而 OR 连接的多个谓词只需要其中一个成立即可;偏偏 Hash Join 又只比较两个 tuple 对应列的哈希值是否相等,这天然就是一个合取逻辑。
如果我们不小心把析取表达式的列一并划分给了 Hash Join,就会导致本该表达 OR 的逻辑意外变成了 AND,这就违背了优化规则的 as-if 原则。
因为我们又要遍历表达式树,所以之前写的
WalkAST()函数又可以派上用场了。
4.Task#4 - External Merge Sort + Limit Executor + Window Functions
Limit 的实现太简单了,我们只介绍一下 ExternalMergeSort 与 WindowFunction。
4.1 External Merge Sort
外部归并排序实际上就是 k 路归并排序,但是与内存上的归并排序不同,外部排序分为两个步骤:
- 顺序扫描全表,生成多个初始归并段
- 在多个初始归并段的基础上完成 k 路归并排序
虽然 ExternalMergeSortExecutor 写的是多路归并排序,但 BusTub 只实例化了 k = 2 的情况,也就是最简单的双路归并排序。
很明显,排序算子是一个典型的 pipeline breaker。
BusTub 为我们提供了一个存储归并段的结构 MergeSortRun,但由于我实现了一个 IntermediateResults,所以这里完全用不上 MergeSortRun,而且两个类型的功能是等价的,我直接把它删掉了。
很恶心的一点在于,sqllogictest 会检查磁盘写次数和 delete 次数,如果实现的算法性能过好的话会无法通过检查,这个时候就需要耍点花招手动刷一些 IO 次数,至于怎么刷还请仔细阅读源码:)
最基础的双路归并排序非常简单,接下来介绍如何实现一个无法通过上述检测的外部 k 路归并排序。
4.1.1 生成初始归并段
传统外部排序的做法是:加载一批 tuple 到内存上,调用 std::sort 或者其他排序算法,然后把这批 tuple 作为一个初始归并段写回磁盘上。
假设每次加载 tuple 的数量为 M,这种方式只能生成大小为 M 的多个初始归并段;而根据归并排序原理,如果初始归并段越少、归并段内元素数量越多,那么整个外部排序过程中需要发起 IO 的次数就越少。
因为我们可以在读取 k 个归并段的时候同时处理更多数据,从而实现更大范围的有序性。
对于一个随机的有序序列来说,例如整数序列,如果我们希望这个序列的长度尽可能长,那么序列内元素之间的"差值"就必须尽可能小。
因此假设升序的情况下,要生成尽可能长的初始归并段,实际上等价于在扫描过程中找到一个最长上升子序列(LIS);不过与传统 LIS 问题不同,我们不关心序列长度,我们只关心怎么构造这个子序列。
我不难想到,如果我们在扫描数据的时候,总是找出其中最小的元素并把它加入到当前归并段中,那么我们在构造归并段时就出现了一个读写窗口,这个窗口总是逐出当前数据集中最小的元素,并且逐出后又可以容纳新的元素。而且如果新进来的元素比上一次逐出的元素更小(违反了升序性),我们就要缓存元素并缩减窗口大小。
假设我们能够一次读取 N 个 tuple 到内存上,我们可以在扫描数据的时候维护一个大小为 N 的最小堆,每次读取一个 tuple 先判断它和上一次弹出元素的大小关系(显然初始建堆后要立即弹出一个元素),如果小于则缓存起来,并缩减堆大小;否则插入到堆中,然后弹出堆顶元素(最小元素),把弹出的元素插入到初始归并段中,并记录这个最小元素。
如果不缩减堆大小,我们会被迫在构造初始归并段的时候就完成了整个表的内存内排序,显然此时就不再是外部排序了。
当堆的逻辑大小变为 0,代表本轮归并段已经构造完毕;此时我们重新用先前被缓存的元素构造一个新的最小堆(显然大小依然为 N),然后重复上述过程直到扫描完全表。
这种做法被称为置换选择排序,它能够让初始归并段的大小从 M 变为平均 2M,而且一定大于等于 M。
而且虽然要维护一个堆,但我们不需要使用 std::priority_queue,因为堆是一个完全二叉树,而所有二叉树都可以按层序遍历结构存储在一个数组上;因此标准库提供了三个算法:std::make_heap、std::push_heap 和 std::pop_heap,利用它们我们可以直接在一个 std::vector 上构建堆。
由于 BusTub 不提供表大小信息,而且我们不可能让一个算子直接吃掉所有内存,所以我们必须手动维护一个最大内存配额,并且利用内存配额和表的 tuple 大小计算我们可以加载多少个 tuple。
4.1.2 构造最佳归并树
当我们构造了所有初始归并段之后,就需要开始归并排序。k 路归并排序的意思是同时读取 k 个归并段,在内存中处理这 k 个归并段元素的排序,然后输出一个归并段。
显然,如果我们归并的时候总是优先处理较大的归并段,当 k 个归并段被合并为一个更大的归并段之后,我们必然会在下次归并时再次选中刚产生的归并段,显然刚刚才被写到 disk 上的 tuple 又要被我们读到内存上,这有很多重复的 IO。
所以我们总是要合并最小的 k 个归并段,即使我们会重复选中一个刚刚被合并的归并段,因为归并段小,我们反复搬运的数据量就会少。
假设初始归并段是叶子结点,不难发现任何归并排序的过程都可以构造自底向上合并的归并树。现在我们把归并段的大小视作权重,考虑归并段到根结点的路径,我们可以得到一个带权路径的归并树。
在带权路径的归并树中,每个结点的权重值相当于每次归并操作读写的数据量,很明显我们希望根结点的权重最小,这样我们整个归并过程中发生的 IO 次数会最少;而带权路径的树中,哈夫曼树的根结点权重最少。
所以我们要让我们的归并路径形成一个哈夫曼树。
根据哈夫曼树的构造原理,我们要构造一个关于初始归并段的最小堆,每次弹出 k 个归并段进行合并,然后再把结果归并段插回堆中,重复以上步骤直到堆大小为 1。
由于我们总是提取 k 个归并段,然后返回 1 个归并段,这相当于我们总是拿走 k-1 个归并段;为了维持归并树的哈夫曼树结构,我们总是期望初始归并段数量 - 1(因为最后会输出一个归并段)能够被 k-1 整除,即:(runs.size() - 1) % (K - 1) == 0。
当不能整除的时候,我们需要向初始归并段所在的最小堆中插入多个空的归并段,使得归并段数量满足上述关系,这些归并段被称作虚段。而要插入的虚段数量可以这样计算:(K - 1) - (runs.size() - 1) % (K - 1)。
插入后,初始我们必然会弹出这 k 个虚段,因此虚段会在第一轮归并之后消失,不影响后续归并过程。
4.1.3 败者树
现在我们开始读取 k 个归并段,并且同时比较来自 k 个归并段的不同元素大小元素,按照比较结果输出最小的元素(假定升序)。
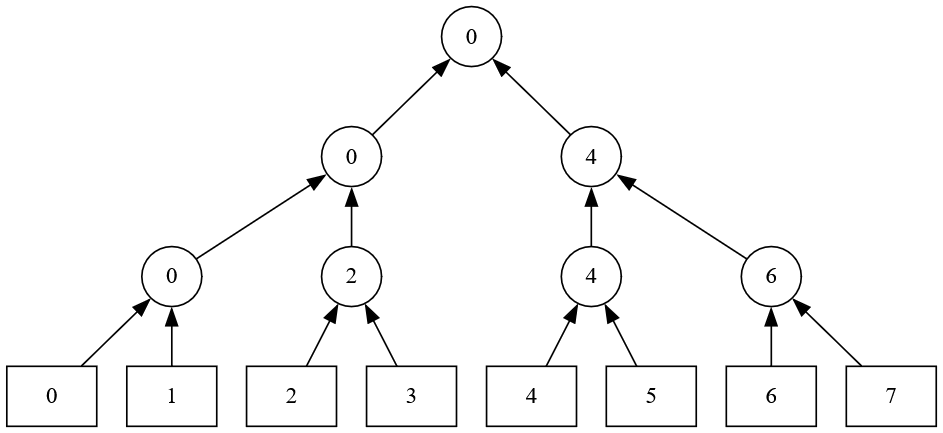
为了同时比较 k 个元素,我们很容易想到两两比较决出一个胜者,然后让胜者继续和其他胜者进行比较,最后决出一个最小元素。
按照现实中的锦标赛打法,我们会构造出一个胜者树,即叶子结点是本轮参与的所有元素,每个父结点都是两个叶子节点比较后的优胜者,以此类推根结点就是所有叶子结点的唯一胜者。
假设我们有 8 个归并段,那么一个胜者树会长这样:
但很明显胜者树中我们会在父结点反复存储胜者,这有很多冗余信息,根据信息论原理来看显然不是最优的数据结构。
所以实际上我们只在父结点存储败者,也就是记录本次比较是哪个子结点输了,这样一来当我们决出一个唯一胜者之后,从胜者所在的归并段再提取一个元素出来参与比较的时候,只需要与父结点存储的败者进行一次比较,获胜上升,失败则与父结点存储的败者进行身份置换,让原来的败者向上比较角逐。
而对应的败者树则是:
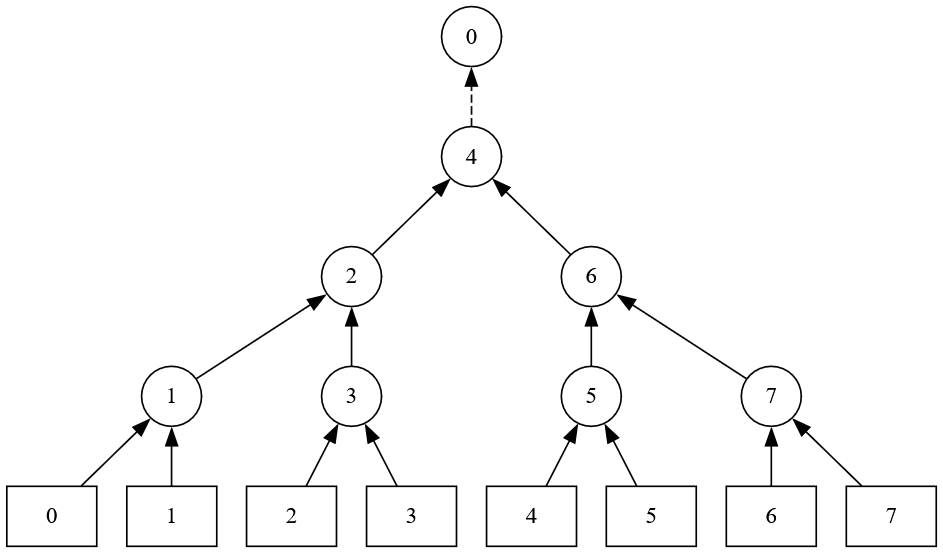
这里有一个隐含的前提:我们不会实际拿出当前归并段的 tuple 存放到败者树中;相反,败者树里只存放了当前败者来自哪一个归并段,也就是我们只记录下标。
这是因为下标是一个 scalar type,而归并段的 tuple 不是,如果实际存储归并段元素我们会产生很多次移动开销,这是完全没必要的。
我们反过来看,如果构造的是胜者树会怎么样,这样就能理解败者树的好处:
胜者树由于每个父结点只存储本轮胜者,我们不知道败者到底是左右子结点的谁,所以每次有一个元素要向上角逐的时候,它要同时比较这个结点的左右两个子结点,因此会额外多一次比较操作。
和胜者树不同,败者树的根结点同样也是一个败者,真正的胜者是一个游离在败者树之外的独立结点,不过一般实现中我们会把它当作是败者树根结点的"根结点"。
很凑巧的是,败者树是一个满二叉树,除去 k 个作为叶子结点的归并段,只需要一个大小为 k 的数组恰能存放下整个败者树(其中第 0 元素放唯一胜者),然后再额外维护一个大小为 k 的数组存放归并段(即 IntermediateResults 对象)即可。
不过此处我们必须手动维护整棵二叉树,在这样一个败者树中,第 i 个归并段的父结点是 (i + K) / 2;第 k 个结点的父结点则是 k / 2。
最后我们就实现了一个无法通过 sqllogictest 磁盘读写次数检测的外部排序算子。
4.2 Window Function
窗口函数可以看作是一个比较高级的 GROUP BY 功能,不同之处在于窗口函数不会把整张表拍扁,而且可以自由地把一张表划分为多个分组,在每个分组内进行单独的排序和聚合操作。
同样,窗口函数也是一个 pipeline breaker,我们必须一次消耗完下层算子的所有数据;虽然下层算子可能会很大,但为了实现简单,我们总是假定下层算子产生的数据可以被全量加载到内存上。
实现起来不是特别难,因为实验已经做出了两个重要的限定:不可能存在不一致的 ORDER BY 子句,不需要实现 Window Frame。
前者的意思是我们只需要对全表做一次全量排序即可得到满足所有 partition 排序需求的结果,后者的意思是我们只需要:
- 如果包含
ORDER BY语句,那么一个 partition 的聚合函数执行范围是整个分区 - 如果不包含
ORDER BY,聚合函数执行范围是分区首行到当前扫描行
因为只需要做一次全量排序,后续计算窗口函数的时候我们需要引用某个 tuple 时就必须通过下标访问,否则会破坏有序性。
每个 window function 算子的输出形式都写在计划树结点中,就是结点里的 columns_ 成员;实现窗口函数时,我们可以遵循以下步骤:
- 全量加载所有 tuple 到一个
std::vector中,并按窗口函数的ORDER BY执行全量排序 - 按顺序扫描窗口函数,为其中的每一个
PARTITION BY构造一个哈希分区,每个分区存储的元素是存储了 tuple 的std::vector的下标 - 维护一个结果列表
std::vector<std::vector<Value>>,顺序遍历plan_->columns_,如果当前列不是一个 placeholder(其实就是一个存储了uint32_t(-1)的ColumnValueExpression),那么遍历所有 tuple 并求值,把结果加入到结果列表的对应元素处;否则需要在这个列上执行窗口函数
就三个步骤,不过需要注意的是其实 PARTITION BY 是有可能重复的,而且有些分区可能不存在分区键,如果重复的话就会重复计算多个哈希分区,这是一个很大的开销,所以构造哈希分区的时候要根据存储的 partition_by_ 进行去重处理。
窗口函数部分的实现其实和前面的 Aggregation 是类似的,这部分参照之前的实现就行。
5.Optional Leaderboard Task
最后 project 留了三个额外的可选优化任务,前两个是有大量冗余计算的 sql 查询,最后一个则只和算子的实现方法有关。
5.1 Hash Join 的谓词下推
回顾之前编写 OptimizeNLJAsHashJoin 的过程,不难发现我们只分析了是否仅包含等值谓词,这是不够的,我们必须顺便将一些与连接条件无关的谓词下推。
所谓与连接条件无关的谓词,实际上就是只引用了单侧表的谓词表达式,而且这类表达式必须出现在合取条件下。
而且我们必须过滤那些需要保留在 Hash Join 的连接谓词,这类连接谓词实际上是一个同时引用了两张表的等值条件表达式,我们要将它们全部取出来不做下推。
我们不处理包含析取逻辑的谓词,这类谓词应当被视作无法优化的有毒表达式。
在实现优化规则时,我们依然需要递归遍历整个谓词表达式树,在遍历过程中检测是否存在析取逻辑,并且收集所有列引用信息和对应的谓词,在遍历结束之后就可以利用收集得到的信息进行优化执行。
如果我们能够提取到有效的能下推的谓词,那么谓词应该被打包到一个新的 FilterPlanNode 结点中,并且下推给下一层结点作为下层计划树的根结点。
因为此时优化产生了一个新的 FilterPlanNode 结点,我们有可能促成了新的优化机会出现:所有与 Filter 有关的优化规则都可以再次作用在新产生的子树上。
前文说过,OptimizeNLJAsHashJoin 必须晚于 OptimizeMergeFilterNLJ 规则的执行,而且优化规则的执行是自底向上的。现在我们向下插入了一个新的 FilterPlanNode,因为我们必然已经执行过了 OptimizeMergeFilterNLJ 规则,子结点必然也执行过了 OptimizeNLJAsHashJoin,为了吃下这次新增的优化机会,我们必须对产生的新子树重复调用 OptimizeMergeFilterNLJ 以及 OptimizeNLJAsHashJoin,这是一次典型的不动点迭代优化。
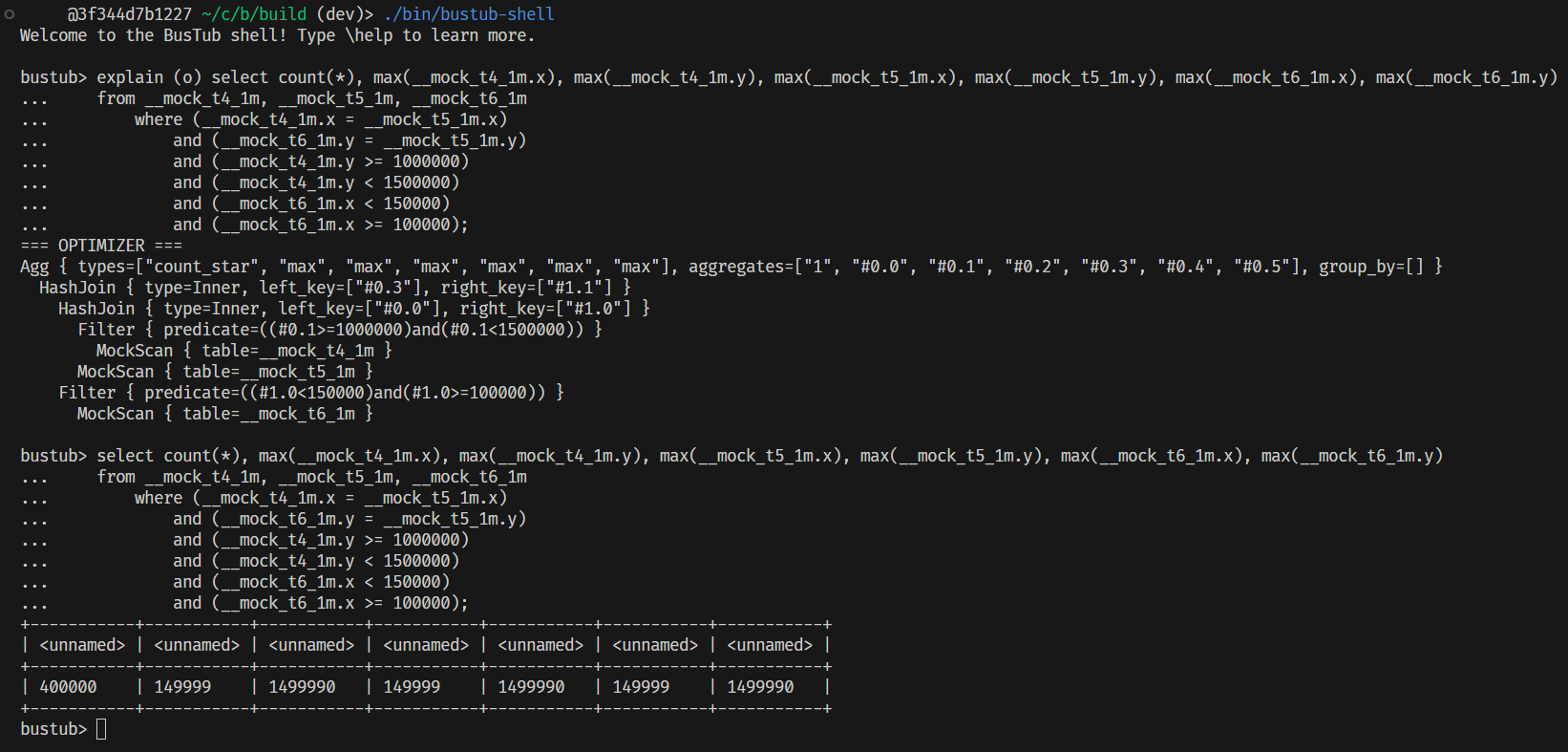
应用优化规则后,检查 p3.leaderboard-q1.slt 提供的表达式,可以看到如下优化以及执行结果:
5.2 Column Pruning
在计划树中,如果存在这样的结构:ProjectionPlanNode -> AbstractPlanNode,并且 Projection 实际引用的列数量要少于下层算子的输出列数量,我们可以说下层计划树产出了多个无关的列,存在着一次列裁切机会。
不难发现,任何有效的列裁切都来自一个部分投影的
Projection算子。而且
OptimizeColumnPruning必须枚举AbstractPlanNode的类型,否则没法修改下层计划树结点。
所以在优化规则 OptimizeColumnPruning 中,我们可以遍历 Projection 的全部表达式,找出类型是 ColumnValueExpression 的结点,无重复地收集投影算子引用的所有列下标。
当引用的列下标数量比下层算子的输出列数量要少的时候,代表下层算子计算了某些用不到的列,此时我们可以重写下层算子的表达式,删除所有不需要的列的表达式,然后重写下层算子的输出 Schema 以及 Projection 的表达式中的 ColumnValueExpression,使之正确匹配裁切后的结果。
但必须注意的是,对于 AggregationPlanNode 来说,它的 group_bys_ 聚合列不能被删除,否则会导致修改后的聚合函数功能与优化前不一致。
而且
AggregationPlanNode的输出格式是[group by, aggregations]。
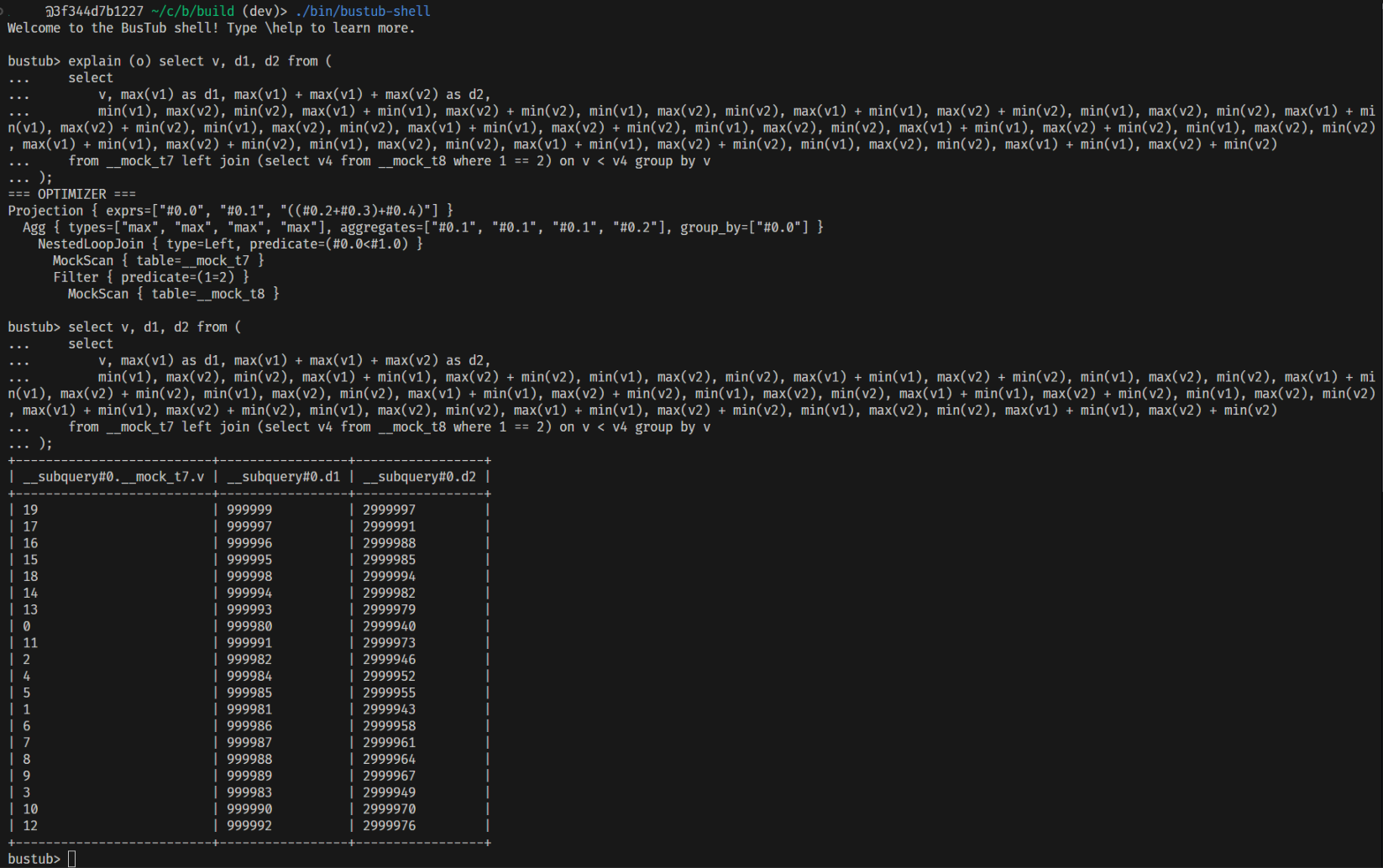
应用优化规则后,检查 p3.leaderboard-q2.slt 提供的表达式,可以看到如下优化以及执行结果:
5.3 常量折叠
不难发现,q2 提供的 sql 里包含了一个显然为 false 的常量等值比较 1=2,这个表达式不应该被交给执行引擎,而应该在优化阶段被提前计算出来并固化。
这种提前计算常量表达式的操作叫做常量折叠。
能够享受常量折叠的表达式结点有三个:ComparisonExpression、ArithmeticExpression 和 LogicExpression,恰好它们都是二元表达式。
常量折叠的实现其实很简单,我们递归遍历表达式树,检查当前结点是否是以上三个类型之一,如果是,那么递归地对左右两个子结点进行常量折叠。
如果左右两个子结点要么本来就是 ConstantValueExpression,要么能够被递归折叠成一个常量表达式(因此递归函数要向上返回一个 bool 值),此时我们就可以直接发起当前结点的求值,然后将当前结点替换成 ConstantValueExpression 类型。
由于调用常量表达式类型 ConstantValueExpression 的 Evaluate() 时不会使用任何传递进来的参数,所以一旦我们确信左右两个子结点都是常量时,我们可以向 Evaluate() 传递一个空指针和一个默认构造的 Schema 拿到求值结果。
值得一提的是,LogicExpression 的常量折叠过程比较特殊。因为合取与析取允许短路求值,也就是说假设我们有一个谓词:v1=3 AND 1=2,可以看出即使 v1=3 不是一个常量表达式,但由于 AND 逻辑的特性,我们可以通过短路求值强制判定整个 LogicExpression 的结果为 false。
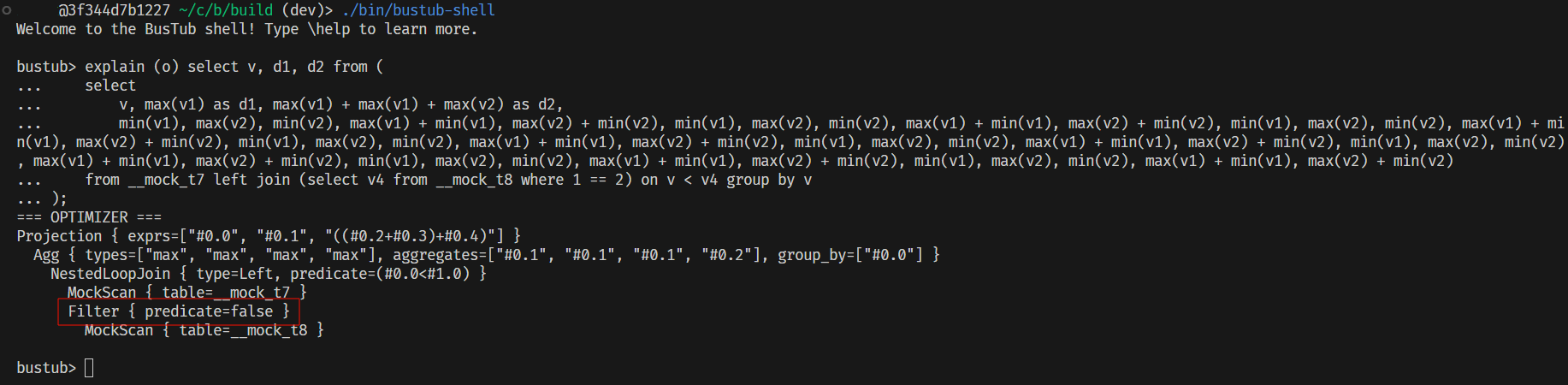
综上,应用优化规则后我们可以将 q2 的 sql 中的常量给折叠了:
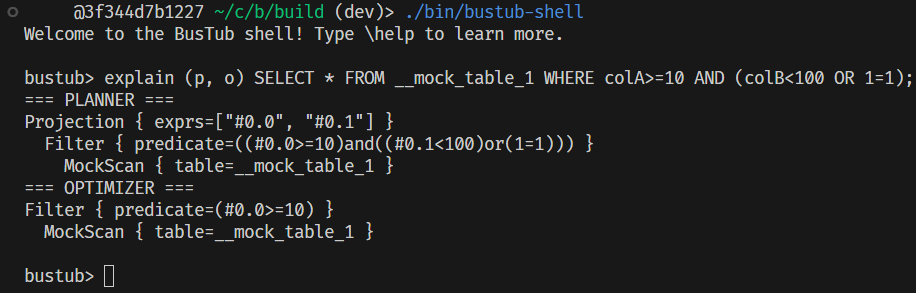
而且远不止于此,假设我们有这样一个 sql 查询:SELECT * FROM __mock_table_1 WHERE colA>=10 AND (colB<100 OR 1=1);,我们的优化规则能够正确地折叠出现的常量,并且利用短路求值消除不必要的表达式结点:
5.4 永假式消除
常量折叠可以产出永真或者永假的 FilterPlanNode,永真 Filter 会被优化规则 OptimizeEliminateTrueFilter 删除,而永假的 Filter 就没人管了;我们需要自己消除这里的死代码。
其实直接仿照 OptimizeEliminateTrueFilter 写一个相对的 OptimizeEliminateFalseFilter 就可以了,这并不复杂,唯一要注意的点是常量折叠必须发生在这两个规则之前。
一个永假的 Filter 什么都不会返回,所以这个 Filter 之下的所有计划结点都是不可达的,但是上层计划结点必须能正常看到 Filter 本应输出的列模式(即 OutputSchema()),所以我们要构造一个什么都不返回的计划结点顶替它。
不难发现一个持有的表达式数量为 0 的 ValuesPlanNode 非常适合充当这个角色,这样一个计划结点的确什么都不产出,而且不需要做其他额外的支持工作。
这样一来 q2 的 sql 又可以被优化为这样:
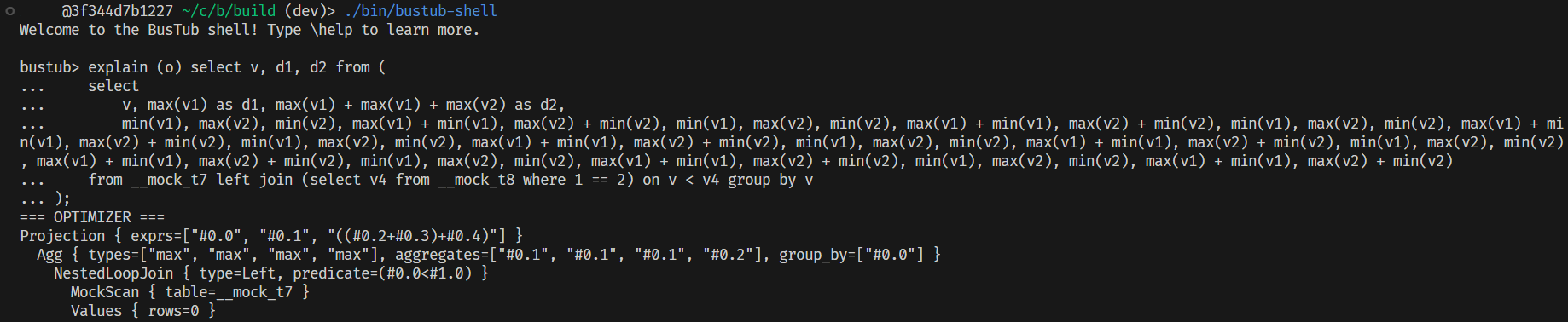
5.5 公共子表达式消除
最后我们可以注意到,被裁切后的 AggregationPlanNode 虽然减少了非常多的无关计算,但仍然重复计算了三次 max,这也是有一定开销的。
显然这三个重复出现的 max 就是一个公共子表达式。
一般来说公共子表达式消除(CSE)可以通过向上插入一个 Projection 结点实现,然后再配合投影消除规则合并多个相邻 Projection。但问题在于 BusTub 已经提供了一个 OptimizeMergeProjection 优化规则,而且这个规则只负责处理恒等变换,这就非常不爽了。
所以我也懒得再增加一个重复的投影消除,只做了点针对性优化:我仅分析形如 Projection -> Aggregation 的结构,如果 Aggregation 中有多个重复类型的聚合函数,并且这些重复的聚合函数里有相同的计算表达式,那么就存在公共子表达式;找到了公共子表达式所对应的列下标后,同时重写 Projection 的列引用、并且将公共子表达式从 Aggregation 里删除。
关键点在于如何判断两个以 AbstractExpressionRef 为根的表达式树是否相同。
这里和判断二叉树相等非常不同,我们必须面临一个非常棘手的问题:有些运算符是满足交换律的。
也就是说 a + b + (d - c) 和 (d - c) + b + a 是等价的,它们的表达式树分别长这样:
txt
// a + b + (d - c)
+
/ \
+ -
/ \ / \
a b d c
// (d - c) + b + a
+
/ \
- +
/ \ / \
d c b a出于简化考虑,我们暂时不考虑结合律导致的树结构变异。
显然由于满足交换律,计算结果相同的表达式树可以有完全不同的子树结构;所以我们必须得到一个表达式树的规范表示。
所谓的规范表示,指的是计算结果相同的表达式,即使它的结构因为结合律有着各种不同的组合方式,但它们一定共享同一个规范表示。
一种规范表示可以经由递归向上生成关于当前结点的字符串得到,而且为了维护规范表示的唯一性,我们必须按照字典序拼接左右子树生成的字符串。
除此之外,规范表示必须消除所有等价运算符表示,也就是说我们要把 >= 和 > 一律扭转为 <= 和 <,这样才不影响同一个表达式树的规范表达唯一性。
我们可以写一个类似这样的函数生成每个表达式树的规范化表示:
cpp
auto CanonicalizeAST(const AbstractExpression *root) -> std::string;有了规范表示之后,我们就可以识别所有重复表达式并且删除公共子表达式了,现在 q2 的优化以及执行结果如下:
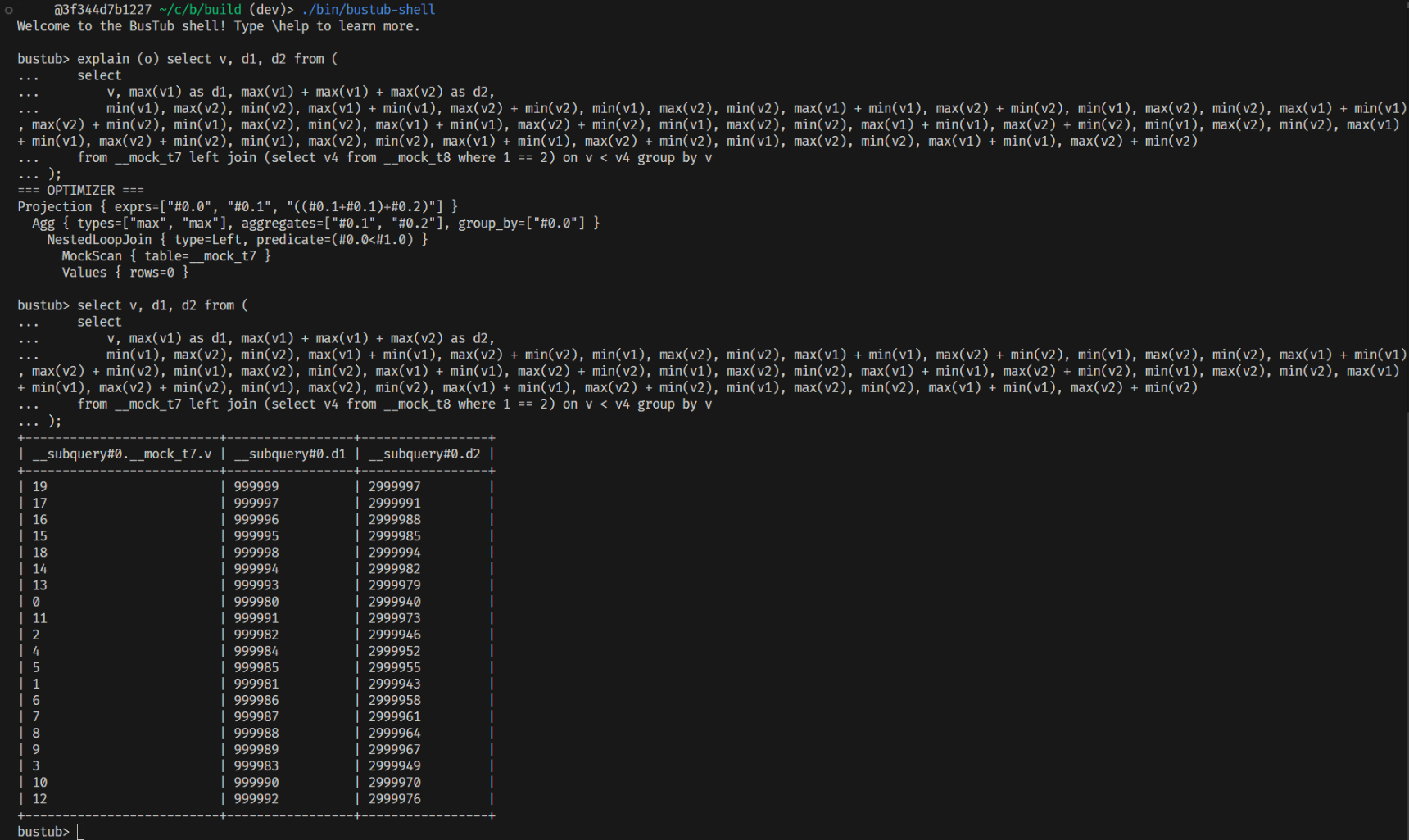
因为 q2 的优化结果已经是一个相对最优形式了,最后我们可以说已经完成了 q2 的针对性优化。
5.6 Bloom 过滤器
Bloom 过滤器就是一个布隆过滤器。
q3 是一个 Hash Join,sql 本身没有什么可圈可点的地方,主要的优化操作在于:实现一个布隆过滤器提前滤掉不可能匹配的 tuple。
因为 LEFT JOIN 必须保留左表,我们可以总是可以在左表上构造一个布隆过滤器,然后用这个布隆过滤器提前拦截不可能匹配的右表 tuple,在 grace hash 阶段不让右表 tuple 进入磁盘。
由于我们反复强调多次表大小不可能提前预知,所以我们必须实现一个可自扩展的布隆过滤器(Scalable Bloom Filter);而且前面也说过了 BusTub 本身提供的哈希函数质量相当差,为了避免大范围哈希冲突,还需要顺便实现一个新的哈希函数。
所有资料都可以在互联网公开检索到,所以就不赘述了。
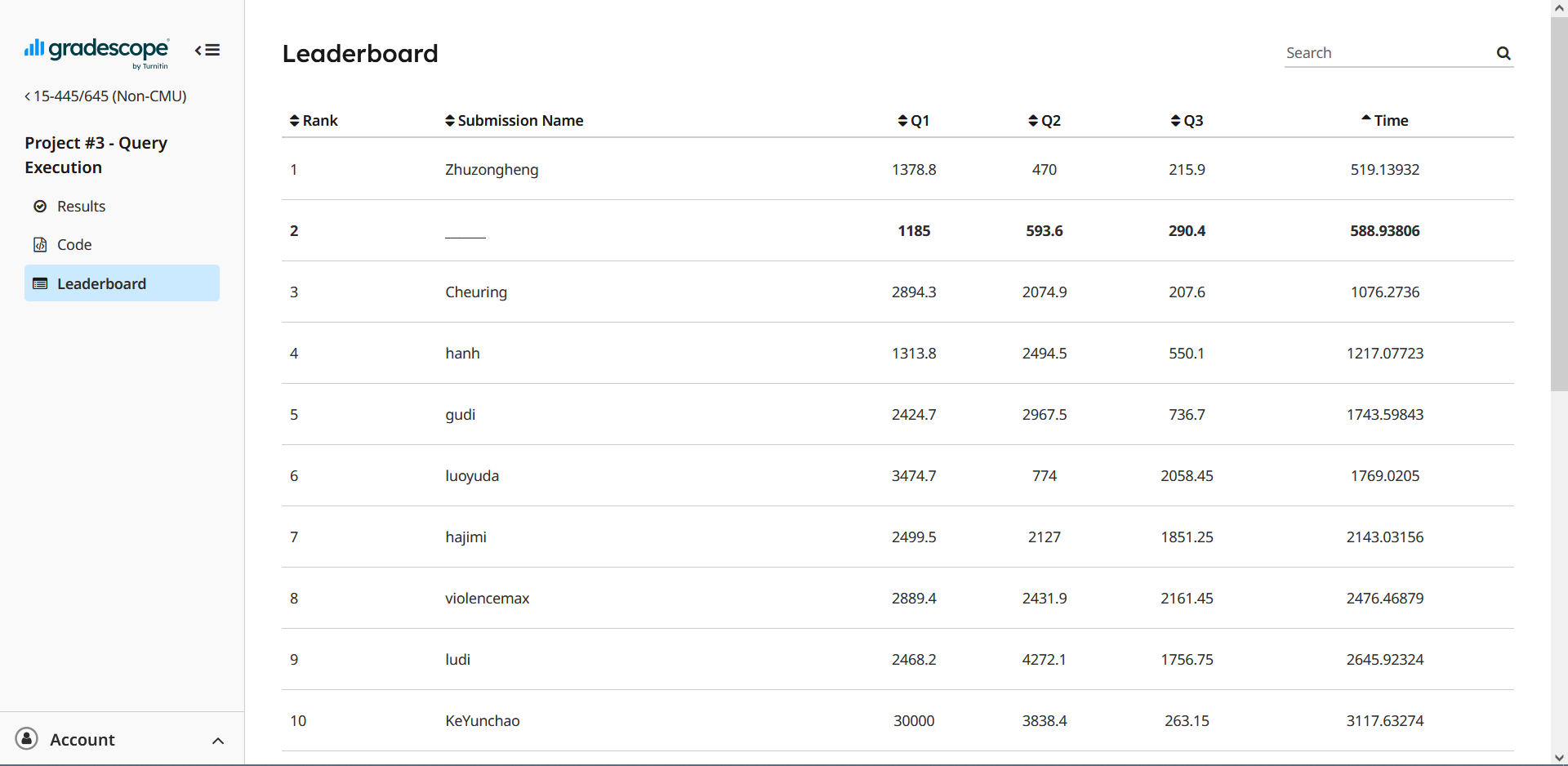
5.7 提交
最后也是拿下了单项第一、总分第二的成绩,只能说侥幸吧:
6.总结
又要设计算子又要写优化器,特别是还有一个完全要我自己发挥的 IntermediateResultPage,搞得差不多全部时间都浪费在思考 HashJoinExecutor 上,这次 project 真给我写力竭了。
虽然感觉写优化比设计算子要简单(