2026-05-07
复习和预习
昨天课堂内容
- 认证和授权
- Dashboard
- 动态卷供应
- StatefulSet
课前复习
- 认证和授权
- Dashboard
- 动态卷供应
- StatefulSet
今天课堂内容
- ETCD 存储系统
- 生产环境 Kubernetes 集群部署
- Kubernetes 集群升级
ETCD 存储系统
ETCD 存储系统介绍
ETCD 存储系统概述
- etcd,是一款开源、高度一致的分布式键值(key-value)存储系统。
- etcd,使用Go语言编写的,节点之间通信通过Raft共识算法处理。
- etcd,是 CoreOS 公司于 2013 年 6 月发起的开源项目,于 2018 年 12 月正式加入云原生计算基金会(CNCF-Cloud Native Computing Foundation),并由 CNCF 支持。
CNCF 是一个中立的基金会、云原生技术推广和普及的领导者。

ETCD 特点
- 读写性能强:官网给出的Benchmark,在2CPU、1.8G内存、SSD磁盘这样的配置下,单节点的写性能可以达到16K QPS,而先写后读也能达到12K QPS。
- 简单:安装配置简单,而且提供了 HTTP API 进行交互,使用也很简单。
- 支持HTTPS:更安全可靠。
- 跨平台支持:支持不同系统。
- 二进制文件小和社区活跃。
ETCD 应用场景
归根结底,etcd 是一个键值存储的组件,其功能都是基于其键值存储功能展开的。
从简单的 Web 应用程序到 Kubernetes 集群,任何复杂的应用程序都可以从 etcd 中读取数据或将数据写入 etcd。
-
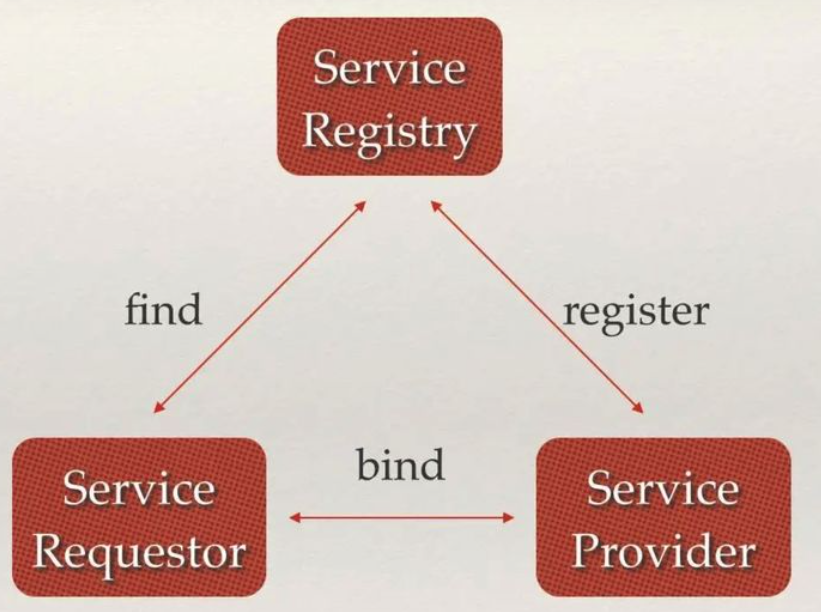
服务注册与发现:服务提供方向 ETCD 注册,服务请求方向 ETCD 查询服务方,随后与服务提供方建立连接。
-
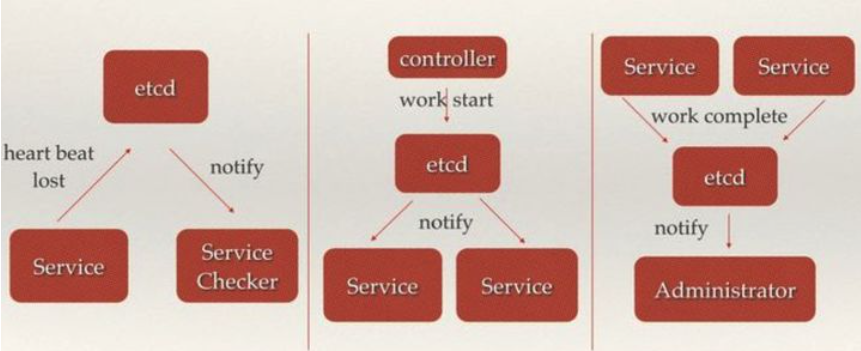
消息发布与订阅:在分布式系统中,最适用的一种组件间通信方式就是消息发布与订阅。即构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦主题有消息发布,就会实时通知订阅者。通过这种方式可以做到分布式系统配置的集中式管理与动态更新。

-
分布式通知与协调:与消息发布和订阅有些相似。
-
选主,在同一个分布式集群中,多个节点选举出主节点对外提供服务。
-
分布式锁 :当在分布式系统中,数据只有一份(或有限制),此时需要利用锁的技术控制某一时刻修改数据的进程数。分布式环境下下的锁不仅保证进程可见,还需要考虑进程与锁之间的网络问题。锁服务有两种使用方式:独占锁 ,即获取锁的用户最终只有一个可以得到;控制时序锁,即获得锁的用户都会按数序顺序执行。
单节点部署
提前设置:
- 主机名:etcd.laoma.cloud
- IP地址:10.1.8.10
bash
# 所有节点配置
root@etcd:~# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.1.8.10 etcd.laoma.cloud etcd
# 安装
root@etcd:~# apt install -y etcd-server etcd-client
# 安装完成后,etcd 会默认启用并启动
# 配置
root@etcd:~# cp /etc/default/etcd /etc/default/etcd.ori
root@etcd:~# vim /etc/default/etcd
bash
# 定义节点名称,默认为default
ETCD_NAME="default"
# 定义节点数据存储目录,默认/var/lib/etcd/default
ETCD_DATA_DIR="/var/lib/etcd/default"
# 定义对外提供服务的监听地址,本机机器执行etcdctl命令连接的监听
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://10.1.8.10:2379"
# 定义对外提供服务的监听地址,其他机器执行etcdctl命令连接的监听
ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379,http://10.1.8.10:2379"配置说明:
- 如果只需要服务器自己可以访问http://localhost:2379,则配置:
- ETCD_LISTEN_CLIENT_URLS="http://localhost:2379"
- ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379"
- 如果只需要服务器自己可以访问http://10.1.8.10:2379,则配置:
- ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://10.1.8.10:2379"
- ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379"
- 如果需要客户端和服务器都可以访问http://10.1.8.10:2379,则配置:
- ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://10.1.8.10:2379"
- ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379,http://10.1.8.10:2379"
bash
# 重启服务
root@etcd:~# systemctl restart etcd
# 验证状态
root@etcd:~# etcdctl member list
8e9e05c52164694d, started, default, http://localhost:2380, http://10.1.8.10:2379,http://localhost:2379, false
# 查询键值对列表
root@etcd:~# etcdctl put /xxx yyy
OK
root@etcd:~# etcdctl get /xxx
/xxx
yyy清除节点所有数据
bash
root@etcd:~# systemctl stop etcd.service
root@etcd:~# apt remove -y etcd-server etcd-client
root@etcd:~# rm -fr /var/lib/etcd/default多节点集群部署
部署集群
**实践:**先部署两节点环境,再添加增删节点。
所有节点配置
bash
root@etcdN:~# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
######### etcd cluster #########
10.1.8.11 etcd1.laoma.cloud etcd1
10.1.8.12 etcd2.laoma.cloud etcd2
10.1.8.13 etcd3.laoma.cloud etcd3
root@etcdN:~# apt update && apt install -y etcd-server etcd-client
root@etcdN:~# systemctl stop etcd.service
root@etcdN:~# rm -fr /var/lib/etcd/defaultetcd1 配置
bash
root@etcd1:~# cp /etc/default/etcd /etc/default/etcd.ori
root@etcd1:~# vim /etc/default/etcd
bash
ETCD_NAME="etcd1"
ETCD_DATA_DIR="/var/lib/etcd/default"
ETCD_LISTEN_PEER_URLS="http://localhost:2380,http://10.1.8.11:2380"
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://10.1.8.11:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.1.8.11:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379,http://10.1.8.11:2379"
ETCD_INITIAL_CLUSTER="etcd1=http://10.1.8.11:2380,etcd2=http://10.1.8.12:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcdcluster"
ETCD_INITIAL_CLUSTER_STATE="new"参数说明
bash
# ETCD_DATA_DIR 定义节点的数据存储目录,默认/var/lib/etcd/default
# ETCD_NAME 定义ETCD节点名称,默认为default
# ETCD_LISTEN_CLIENT_URLS 对外提供服务的监听地址,用于服务端自己
# ETCD_ADVERTISE_CLIENT_URLS 该节点对外提供服务的监听地址,用于客户端
# ETCD_LISTEN_PEER_URLS 定义ETCD监听URL,用于与其他节点心跳通讯
# ETCD_INITIAL_ADVERTISE_PEER_URLS 该节点同伴监听地址,这个值会告诉集群中其他节点
# ETCD_INITIAL_CLUSTER 集群中所有节点的信息
# ETCD_INITIAL_CLUSTER_TOKEN 集群的token,用于集群节点心跳通信认证,集群中所有节点统一。
# ETCD_INITIAL_CLUSTER_STATE 新建集群的时候,这个值为 new ;假如已经存在的集群,这个值为 existingetcd2 配置
bash
root@etcd2:~# cp /etc/default/etcd /etc/default/etcd.ori
root@etcd2:~# vim /etc/default/etcd
bash
ETCD_NAME="etcd2"
ETCD_DATA_DIR="/var/lib/etcd/default"
ETCD_LISTEN_PEER_URLS="http://localhost:2380,http://10.1.8.12:2380"
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://10.1.8.12:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.1.8.12:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379,http://10.1.8.12:2379"
ETCD_INITIAL_CLUSTER="etcd1=http://10.1.8.11:2380,etcd2=http://10.1.8.12:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcdcluster"
ETCD_INITIAL_CLUSTER_STATE="new"启动集群
bash
# etcd1 和 etcd2 节点启动服务
root@etcdN:~# systemctl start etcd
# 如果etcd节点之前是一个独立的集群,则需要删除/var/lib/etcd/default目录下所有文件再启动。
# 验证状态
root@etcd1:~# etcdctl member list
1b344327dd751339, started, etcd2, http://10.1.8.12:2380, http://10.1.8.12:2379,http://localhost:2379, false
5b1db881c63d5ce4, started, etcd1, http://10.1.8.11:2380, http://10.1.8.11:2379,http://localhost:2379, false验证部署
bash
root@etcd1:~# etcdctl put /users/user1/name laoma
OK
root@etcd2:~# etcdctl get /users/user1/name
/users/user1/name
laoma集群添加节点
更新现有集群中现有节点配置文件:
- 更新ETCD_INITIAL_CLUSTER参数,添加etcd3=http://10.1.8.13:2380
- 更新ETCD_INITIAL_CLUSTER_STATE为existing
更新 etcd1 配置文件
bash
root@etcd1:~# vim /etc/default/etcd
bash
ETCD_NAME="etcd1"
ETCD_DATA_DIR="/var/lib/etcd/default"
ETCD_LISTEN_PEER_URLS="http://localhost:2380,http://10.1.8.11:2380"
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://10.1.8.11:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.1.8.11:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379,http://10.1.8.11:2379"
ETCD_INITIAL_CLUSTER="etcd1=http://10.1.8.11:2380,etcd2=http://10.1.8.12:2380,etcd3=http://10.1.8.13:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcdcluster"
ETCD_INITIAL_CLUSTER_STATE="existing"
bash
# 重启etcd服务
root@etcd1:~# systemctl restart etcd更新 etcd2 配置文件
bash
root@etcd2:~# vim /etc/default/etcd
bash
ETCD_NAME="etcd2"
ETCD_DATA_DIR="/var/lib/etcd/default"
ETCD_LISTEN_PEER_URLS="http://localhost:2380,http://10.1.8.12:2380"
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://10.1.8.12:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.1.8.12:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379,http://10.1.8.12:2379"
ETCD_INITIAL_CLUSTER="etcd1=http://10.1.8.11:2380,etcd2=http://10.1.8.12:2380,etcd3=http://10.1.8.13:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcdcluster"
ETCD_INITIAL_CLUSTER_STATE="existing"
bash
# 重启 etcd 服务
root@etcd2:~# systemctl restart etcd集群添加节点
集群中任意节点执行以下指令添加节点
bash
root@etcd1:~# etcdctl member add etcd3 --peer-urls=http://10.1.8.13:2380输入内容如下:
bash
Member 2038744cfb6bf628 added to cluster f917ad0d43233ca7
ETCD_NAME="etcd3"
ETCD_INITIAL_CLUSTER="etcd2=http://10.1.8.12:2380,etcd3=http://10.1.8.13:2380,etcd1=http://10.1.8.11:2380"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.1.8.13:2380"
ETCD_INITIAL_CLUSTER_STATE="existing"etcd3 部署 etcd
bash
root@etcd3:~# apt install -y etcd-server etcd-client
root@etcd3:~# systemctl stop etcd.service
root@etcd3:~# rm -fr /var/lib/etcd/default
root@etcd1:~# scp /etc/default/etcd root@etcd3:/etc/default/etcd
root@etcd3:~# vim /etc/default/etcd
bash
ETCD_NAME="etcd3"
ETCD_DATA_DIR="/var/lib/etcd/default"
ETCD_LISTEN_PEER_URLS="http://localhost:2380,http://10.1.8.13:2380"
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://10.1.8.13:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.1.8.13:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379,http://10.1.8.13:2379"
ETCD_INITIAL_CLUSTER="etcd1=http://10.1.8.11:2380,etcd2=http://10.1.8.12:2380,etcd3=http://10.1.8.13:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcdcluster"
ETCD_INITIAL_CLUSTER_STATE="existing"
bash
# 启动etcd 服务
root@etcd3:~# systemctl start etcd
# 查看成员列表
root@etcd1:~# etcdctl member list
1b344327dd751339, started, etcd2, http://10.1.8.12:2380, http://10.1.8.12:2379,http://localhost:2379, false
2038744cfb6bf628, started, etcd3, http://10.1.8.13:2380, http://10.1.8.13:2379,http://localhost:2379, false
5b1db881c63d5ce4, started, etcd1, http://10.1.8.11:2380, http://10.1.8.11:2379,http://localhost:2379, false集群删除节点
bash
# 删除etcd3
root@etcd1:~# etcdctl member remove 2038744cfb6bf628
Member 2038744cfb6bf628 removed from cluster f917ad0d43233ca7
root@etcd1:~# etcdctl member list
1b344327dd751339, started, etcd2, http://10.1.8.12:2380, http://10.1.8.12:2379,http://localhost:2379, false
ae40c1152eed3b3a, started, etcd1, http://10.1.8.11:2380, http://10.1.8.11:2379,http://localhost:2379, false
# 更新etcd1和etcd2节点配置文件为初始2节点集群配置,状态设置为existing
root@etcd1:~# vim /etc/default/etcd
ETCD_NAME="etcd1"
ETCD_DATA_DIR="/var/lib/etcd/default"
ETCD_LISTEN_PEER_URLS="http://localhost:2380,http://10.1.8.11:2380"
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://10.1.8.11:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.1.8.11:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379,http://10.1.8.11:2379"
ETCD_INITIAL_CLUSTER="etcd1=http://10.1.8.11:2380,etcd2=http://10.1.8.12:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcdcluster"
ETCD_INITIAL_CLUSTER_STATE="existing"
root@etcd2:~# vim /etc/default/etcd
ETCD_NAME="etcd2"
ETCD_DATA_DIR="/var/lib/etcd/default"
ETCD_LISTEN_PEER_URLS="http://localhost:2380,http://10.1.8.12:2380"
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://10.1.8.12:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.1.8.12:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379,http://10.1.8.12:2379"
ETCD_INITIAL_CLUSTER="etcd1=http://10.1.8.11:2380,etcd2=http://10.1.8.12:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcdcluster"
ETCD_INITIAL_CLUSTER_STATE="existing"
# 更新完成后建议etcd1和etcd2节点重启etcd服务
root@etcd1:~# systemctl restart etcd
root@etcd2:~# systemctl restart etcd**重要说明:**节点加入集群前,确保etcd数据目录不能有数据。
清理节点etcd3
bash
root@etcd3:~# systemctl stop etcd.service
root@etcd3:~# apt remove -y etcd-server etcd-client
root@etcd3:~# rm -fr /var/lib/etcd/defaultetcdctl 命令
etcd api 有两个版本V2和V3,可通过环境变量 ETCDCTL_API 设置,默认使用v3。
注意:所有节点ETCDCTL_API必须保持一致,support backup of v2 and v3 stores 。
配置补全
bash
root@etcd1:~# mkdir /etc/bash_completion.d
root@etcd1:~# etcdctl completion bash > /etc/bash_completion.d/etcdctl
root@etcd1:~# source /etc/bash_completion.d/etcdctl帮助信息
bash
root@etcd1:~# etcdctl -h
NAME:
etcdctl - A simple command line client for etcd3.
USAGE:
etcdctl [flags]
VERSION:
3.4.30
API VERSION:
3.4
COMMANDS:
alarm disarm Disarms all alarms
alarm list Lists all alarms
auth disable Disables authentication
auth enable Enables authentication
check datascale Check the memory usage of holding data for different workloads on a given server endpoint.
check perf Check the performance of the etcd cluster
compaction Compacts the event history in etcd
completion bash Generate the autocompletion script for bash
completion fish Generate the autocompletion script for fish
completion powershell Generate the autocompletion script for powershell
completion zsh Generate the autocompletion script for zsh
defrag Defragments the storage of the etcd members with given endpoints
del Removes the specified key or range of keys [key, range_end)
elect Observes and participates in leader election
endpoint hashkv Prints the KV history hash for each endpoint in --endpoints
endpoint health Checks the healthiness of endpoints specified in `--endpoints` flag
endpoint status Prints out the status of endpoints specified in `--endpoints` flag
get Gets the key or a range of keys
help Help about any command
lease grant Creates leases
lease keep-alive Keeps leases alive (renew)
lease list List all active leases
lease revoke Revokes leases
lease timetolive Get lease information
lock Acquires a named lock
make-mirror Makes a mirror at the destination etcd cluster
member add Adds a member into the cluster
member list Lists all members in the cluster
member promote Promotes a non-voting member in the cluster
member remove Removes a member from the cluster
member update Updates a member in the cluster
migrate Migrates keys in a v2 store to a mvcc store
move-leader Transfers leadership to another etcd cluster member.
put Puts the given key into the store
role add Adds a new role
role delete Deletes a role
role get Gets detailed information of a role
role grant-permission Grants a key to a role
role list Lists all roles
role revoke-permission Revokes a key from a role
snapshot restore Restores an etcd member snapshot to an etcd directory
snapshot save Stores an etcd node backend snapshot to a given file
snapshot status Gets backend snapshot status of a given file
txn Txn processes all the requests in one transaction
user add Adds a new user
user delete Deletes a user
user get Gets detailed information of a user
user grant-role Grants a role to a user
user list Lists all users
user passwd Changes password of user
user revoke-role Revokes a role from a user
version Prints the version of etcdctl
watch Watches events stream on keys or prefixes
OPTIONS:
--cacert="" verify certificates of TLS-enabled secure servers using this CA bundle
--cert="" identify secure client using this TLS certificate file
--command-timeout=5s timeout for short running command (excluding dial timeout)
--debug[=false] enable client-side debug logging
--dial-timeout=2s dial timeout for client connections
-d, --discovery-srv="" domain name to query for SRV records describing cluster endpoints
--discovery-srv-name="" service name to query when using DNS discovery
--endpoints=[127.0.0.1:2379] gRPC endpoints
-h, --help[=false] help for etcdctl
--hex[=false] print byte strings as hex encoded strings
--insecure-discovery[=true] accept insecure SRV records describing cluster endpoints
--insecure-skip-tls-verify[=false] skip server certificate verification (CAUTION: this option should be enabled only for testing purposes)
--insecure-transport[=true] disable transport security for client connections
--keepalive-time=2s keepalive time for client connections
--keepalive-timeout=6s keepalive timeout for client connections
--key="" identify secure client using this TLS key file
--password="" password for authentication (if this option is used, --user option shouldn't include password)
--user="" username[:password] for authentication (prompt if password is not supplied)
-w, --write-out="simple" set the output format (fields, json, protobuf, simple, table)key-value管理
创建 key-value
bash
root@etcd:~# etcdctl put /users/user1/name laoma
OK查询 key-value
bash
# 查看key-value
root@etcd:~# etcdctl get /users/user1/name
/users/user1/name
laoma
# 只查看value
root@etcd:~# etcdctl get /users/user1/name --print-value-only
laoma
# 只查看key
root@etcd:~# etcdctl get /users/user1/name --keys-only
/users/user1/name
# 再创建一些 key-value
root@etcd:~# etcdctl put /users/user1/age 18
root@etcd:~# etcdctl put /users/user2/name laowang
root@etcd:~# etcdctl put /usage/ls ls--help
root@etcd:~# etcdctl put /usage/cd cd--help
root@etcd:~# etcdctl put /registry/services/endpoints/laoma/web 10.224.225.98:80
# k8s将svc数据按如下格式命名存在etcd系统中:
# /registry/services/endpoints/namespace/svcname
# 查看以/开头的所有key
root@etcd:~# etcdctl get / --keys-only --prefix |grep -v '^$'
/registry/services/endpoints/laoma/web
/usage/cd
/usage/ls
/users/user1/age
/users/user1/name
/users/user2/name
# 查看以/users开头的所有key
root@etcd:~# etcdctl get /users --keys-only --prefix |grep -v '^$'
/users/user1/age
/users/user1/name
/users/user2/name
# 如何查看"特定目录"下有哪些文件或者子目录,例如/users
root@etcd:~# etcdctl get /users --keys-only --prefix |grep -v '^$'| awk -F '/' '{print "/"$2"/"$3}'| sort |uniq
/users/user1
/users/user2脚本查询
以上命令太繁琐,编写脚本 /usr/local/bin/etcdls 实现:
bash
#!/bin/bash
# 如果脚本未提供参数,查询的前缀设置为"/"
PREFIX=${1:-/}
# 统计以该前缀开头的"目录"数量
count=$(etcdctl get $PREFIX --keys-only --prefix |grep -v '^$'|egrep -o "$PREFIX[^/]*/" |sort |uniq|wc -l)
# 正则表达式说明 $PREFIX[^/]*/
## $PREFIX 变量
## [^/]* 变量后跟着任意数量的非/字符串
## 最后补1个/
# 如果数量等于1,则显示该目录下子条目
if [ $count -eq 1 ];then
etcdctl get $PREFIX --keys-only --prefix |grep -v '^$'|egrep -o "^$PREFIX[^/]*/[^/]*" | sort | uniq
else
# 如果数量不等于1,则显示该前缀匹配的目录条目
etcdctl get $PREFIX --keys-only --prefix |grep -v '^$'|egrep -o "^$PREFIX[^/]*" | sort | uniq
fi
bash
root@etcd:~# chmod +x /usr/local/bin/etcdls查询效果如下:
bash
root@etcd:~# etcdls
/registry
/usage
/users
root@etcd:~# etcdls /us
/usage
/users
root@etcd:~# etcdls /user
/users/user1
/users/user2更新 value
bash
root@etcd:~# etcdctl put /users/user1/name laohu
OK
root@etcd:~# etcdctl get /users/user1/name --print-value-only
laohu删除 key
bash
root@etcd:~# etcdctl del /users/user2/name
1
root@etcd:~# etcdctl get /users/user2/name --print-value-only
root@etcd:~# etcdls /users/user
/users/user1/age
/users/user1/name仔细观察:当删除/users/user2/name时 /users/user2条目也没有了。
动态监控 key 值
bash
[root@etcd bin]# etcdctl put /users/user1/name laoma1
OK
[root@etcd bin]# etcdctl put /users/user1/name laoma2
OK
# 当执行以上命令时,watch结果如下:
root@etcd:~# etcdctl watch /users/user1/name
PUT
/users/user1/name
laoma1
PUT
/users/user1/name
laoma2user 管理
bash
root@etcd:~# etcdctl user -h
NAME:
user - User related commands
USAGE:
etcdctl user <subcommand> [flags]
API VERSION:
3.3
COMMANDS:
add Adds a new user
delete Deletes a user
get Gets detailed information of a user
grant-role Grants a role to a user
list Lists all users
passwd Changes password of user
revoke-role Revokes a role from a user
......role 管理
bash
root@etcd:~# etcdctl role -h
NAME:
role - Role related commands
USAGE:
etcdctl role <subcommand> [flags]
API VERSION:
3.3
COMMANDS:
add Adds a new role
delete Deletes a role
get Gets detailed information of a role
grant-permission Grants a key to a role
list Lists all roles
revoke-permission Revokes a key from a role
......member 管理
bash
root@etcd:~# etcdctl member -h
NAME:
member - Membership related commands
USAGE:
etcdctl member <subcommand> [flags]
API VERSION:
3.3
COMMANDS:
add Adds a member into the cluster
list Lists all members in the cluster
remove Removes a member from the cluster
update Updates a member in the cluster查询 Kubernetes 数据
Kubernetes从 1.13 版本开始,默认使用etcd v3 API。数据存放在以 /registry 中。
确保master节点安装了etcdctl工具。
bash[root@master30 ~]# apt install etcd-client -y
我们以集成 etcd 静态 pod 的Kubernetes为例,讲解如何查询。
在master节点创建脚本/usr/local/bin/etcdls,内容如下:
bash
#!/bin/bash
export ETCDCTL_API=3
key_file=/etc/kubernetes/pki/etcd/server.key
cert_file=/etc/kubernetes/pki/etcd/server.crt
cacert_file=/etc/kubernetes/pki/etcd/ca.crt
endpoints=https://127.0.0.1:2379
# 如果脚本未提供参数,查询的前缀设置为"/"
PREFIX=${1:-/}
tmpfile=$(mktemp)
etcdctl --key=${key_file} --cert=${cert_file} --cacert=${cacert_file} --endpoints=${endpoints} get $PREFIX --keys-only --prefix |grep -v '^$'|egrep "$PREFIX[^/]*/" > $tmpfile
# 统计以该前缀开头的"目录"数量
count=$(cat $tmpfile | egrep -o "$PREFIX[^/]*/" | sort | uniq | wc -l )
# 如果数量等于1,则显示该目录下子条目
if [ $count -eq 1 ];then
cat $tmpfile | egrep -o "^$PREFIX[^/]*/[^/]*" | sort | uniq
else
# 如果数量不等于1,则显示该前缀匹配的目录条目
cat $tmpfile | egrep -o "^$PREFIX[^/]*" | sort | uniq
fi
# 清理临时文件
rm -f $tmpfile在 master 节点创建脚本/usr/local/bin/etcdget,内容如下:
bash
#!/bin/bash
export ETCDCTL_API=3
key_file=/etc/kubernetes/pki/etcd/server.key
cert_file=/etc/kubernetes/pki/etcd/server.crt
cacert_file=/etc/kubernetes/pki/etcd/ca.crt
endpoints=https://127.0.0.1:2379
etcdctl --key=${key_file} --cert=${cert_file} --cacert=${cacert_file} --endpoints=${endpoints} get $*以查询 service 数据为例
bash
[root@master30 ~]# etcdls /registry/ser
/registry/serviceaccounts
/registry/services
[root@master30 ~]# etcdls /registry/services
/registry/services/endpoints
/registry/services/specs
[root@master30 ~]# etcdls /registry/services/endpoints
/registry/services/endpoints/default
/registry/services/endpoints/kube-system
[root@master30 ~]# etcdls /registry/services/endpoints/kube-system
/registry/services/endpoints/kube-system/kube-dns
[root@master30 ~]# etcdls /registry/services/endpoints/kube-system/kube-dns
[root@master30 ~]# etcdget /registry/services/endpoints/kube-system/kube-dns --print-value-only
# 除了/registry/apiregistration.k8s.io是直接存储JSON格式的,其他资源是通过 protobuf 格式存储,这么做的原因是为了性能。
# 使用 strings 命令可解码原文,该工具由 binutils 包提供
[root@master30 ~]# etcdget /registry/services/endpoints/kube-system/kube-dns --print-value-only | strings
# openshift 项目已经开发了一个强大的辅助工具 etcdhelper 可以读取 etcd 内容并解码proto。数据的备份和恢复
- etcd v3 可以同时备份和恢复 v2和v3创建的数据。
- etcd v2 无法备份 v3 创建的数据,也无法恢复v3 创建的数据。
物理备份和恢复
单节点集群
备份
bash
# 准备测试数据
root@etcd:~# etcdctl put /users/user1/name laoma
root@etcd:~# etcdctl put /users/user1/age 18
root@etcd:~# etcdctl put /users/user2/name laowang
root@etcd:~# etcdctl put /usage/ls ls--help
root@etcd:~# etcdctl put /usage/cd cd--help
# 停止 etcd 集群,备份数据目录
root@etcd:~# systemctl stop etcd.service
root@etcd:~# cp -a /var/lib/etcd/default /var/lib/etcd/default.bak删除数据
bash
# 启动etcd集群
root@etcd:~# systemctl start etcd.service
# 删除测试数据
root@etcd:~# etcdctl del /users/user2/name 恢复
bash
# 停止 etcd 集群,恢复数据目录
root@etcd:~# systemctl stop etcd.service
root@etcd:~# mv /var/lib/etcd/default /var/lib/etcd/default.bad
root@etcd:~# cp -a /var/lib/etcd/default.bak /var/lib/etcd/default
root@etcd:~# chown -R etcd:etcd /var/lib/etcd/default/
root@etcd:~# systemctl start etcd.service
# 验证恢复
root@etcd:~# etcdctl get /users/user2/name
/users/user2/name
laowang多节点集群
备份
bash
# 准备测试数据
root@etcd1:~# etcdctl put /users/user1/name laoma
root@etcd1:~# etcdctl put /users/user1/age 18
root@etcd1:~# etcdctl put /users/user2/name laowang
root@etcd1:~# etcdctl put /usage/ls ls--help
root@etcd1:~# etcdctl put /usage/cd cd--help
# 所有节点停止 etcd 服务,备份数据目录
root@etcdN:~# systemctl stop etcd.service
root@etcdN:~# cp -a /var/lib/etcd/default /var/lib/etcd/default.bak删除数据
单节点删除数据即可。
bash
# 启动etcd集群
root@etcd1:~# systemctl start etcd.service
# 删除测试数据
root@etcd1:~# etcdctl del /users/user2/name 恢复
bash
# 所有节点停止 etcd 服务,恢复数据目录
root@etcdN:~# systemctl stop etcd.service
root@etcdN:~# mv /var/lib/etcd/default /var/lib/etcd/default.bad
root@etcdN:~# cp -r /var/lib/etcd/default.bak /var/lib/etcd/default
root@etcdN:~# chown -R etcd:etcd /var/lib/etcd/default/
root@etcdN:~# systemctl start etcd.service
# 验证恢复
root@etcdN:~# etcdctl get /users/user2/name
/users/user2/name
laowang逻辑备份与恢复
单节点集群
备份
bash
# 确保使用 API 3
root@etcd:~# export ETCDCTL_API=3
# 备份数据到文件 snapshot.db
root@etcd:~# etcdctl snapshot save snapshot.db
Snapshot saved at snapshot.db恢复
bash
# 停止etcd服务并删除数据目录 /var/lib/etcd/default/
root@etcd:~# systemctl stop etcd
root@etcd:~# mv /var/lib/etcd/default /var/lib/etcd/default.old
# 恢复快照文件snapshot.db到目录/var/lib/etcd/default/
root@etcd:~# etcdctl snapshot restore snapshot.db --data-dir=/var/lib/etcd/default/
# 更改文件所有权,并启动etcd服务
root@etcd1:~# chown -R etcd:etcd /var/lib/etcd/default
root@etcd1:~# systemctl start etcd.service多节点集群
备份
因为多节点集群之间数据是一致的,所以多节点集群备份,只需要在单个节点备份即可。
bash
# 确保使用 API 3
root@etcd:~# export ETCDCTL_API=3
# 备份数据到文件snapshot1.db
root@etcd1:~# etcdctl snapshot save /root/snapshot1.db
Snapshot saved at snapshot.db
# 将备份文件同步到所有节点恢复
bash
# 停止所有节点etcd服务并删除数据目录 /var/lib/etcd/default/
root@etcdN:~# systemctl stop etcd
root@etcdN:~# rm -fr /var/lib/etcd/default/
# 所有节点恢复快照文件snapshot1.db到目录/var/lib/etcd/default/
root@etcd1:~# etcdctl snapshot restore /root/snapshot1.db \
--data-dir=/var/lib/etcd/default
root@etcd1:~# chown -R etcd:etcd /var/lib/etcd/default
root@etcd1:~# systemctl start etcd
root@etcd2:~# etcdctl snapshot restore /root/snapshot1.db \
--data-dir=/var/lib/etcd/default
root@etcd2:~# chown -R etcd:etcd /var/lib/etcd/default
root@etcd2:~# systemctl start etcd
root@etcd3:~# etcdctl snapshot restore /root/snapshot1.db \
--data-dir=/var/lib/etcd/default
root@etcd3:~# chown -R etcd:etcd /var/lib/etcd/default
root@etcd3:~# systemctl start etcdKubernetes 备份和恢复
bash
# 准备工作
[root@master30 ~]# export ETCDCTL_API=3
[root@master30 ~]# key_file=/etc/kubernetes/pki/etcd/server.key
[root@master30 ~]# cert_file=/etc/kubernetes/pki/etcd/server.crt
[root@master30 ~]# cacert_file=/etc/kubernetes/pki/etcd/ca.crt
[root@master30 ~]# endpoints=https://127.0.0.1:2379
# 创建一个应用
[root@master30 ~]# kubectl create deployment web --image=httpd --replicas=2
# 备份
[root@master30 ~]# etcdctl --key=${key_file} --cert=${cert_file} --cacert=${cacert_file} --endpoints=${endpoints} snapshot save snapshot.db
# 删除应用
[root@master30 ~]# kubectl delete deployments.apps web
# 恢复验证
[root@master30 ~]# rm -fr /var/lib/etcd/
[root@master30 ~]# etcdctl --key=${key_file} --cert=${cert_file} --cacert=${cacert_file} --endpoints=${endpoints} snapshot restore snapshot.db --data-dir=/var/lib/etcd --name=master30.laoma.cloud --initial-cluster=master30.laoma.cloud=https://10.1.8.30:2380 --initial-advertise-peer-urls=https://10.1.8.30:2380
# 说明:
# master30.laoma.cloud是master节点主机名
# 10.1.8.30 是 master30 节点主机 ip
[root@master30 ~]# kubectl get deployments.apps生产环境 Kubernetes 集群部署
高可用概述
Kubernetes中的业务系统,通过控制器实现业务的负载均衡和高可用。
Kubernetes集群采用单节点Master架构存在的问题:
- 一旦Master故障,将导致整个集群不可用。
- 单节点Master工作负载能力有限。
为了实现没有单点故障的目标,需要为以下几个组件建立高可用方案:
- etcd
- kube-apiserver
- kube-controller-manager与kube-scheduler
- kube-dns
Etcd 集群高可用
Etcd集群高可用方案:
-
独立的etcd集群,使用3台或者5台服务器运行etcd集群。采用这项策略的主要动机是etcd集群的节点增减都需要显式的通知集群,保证etcd集群节点稳定可以更方便的用程序完成集群滚动升级,减轻维护负担。如果此时在etcd集群前构建一套高可用+负载均衡服务器,则etcd集群的节点增减将不用通知Kubernetes集群。
-
Kubernetes中运行etcd集群,在Kubernetes Master上用static pod的形式来运行etcd,并将多台Kubernetes Master上的etcd组成集群。在这一模式下,各个服务器的etcd实例被注册进了Kubernetes当中,虽然无法直接使用kubectl来管理这部分实例,但是监控以及日志搜集组件均可正常工作。在这一模式运行下的etcd可管理性更强。
-
self-hosted etcd集群,使用CoreOS提出的self-hosted etcd方案,将本应在底层为Kubernetes提供服务的etcd运行在Kubernetes之上。实现Kubernetes对自身依赖组件的管理。在这一模式下的etcd集群可以直接使用etcd-operator来自动化运维,最符合Kubernetes的使用习惯。
这三种思路均可以实现etcd高可用的目标,但是在选择过程中却要根据实际情况做出一些判断:
- 预算充足但保守的项目选方案一
- 想一步到位并愿意承担一定风险的项目选方案三
- 折中一点选方案二
kube-apiserver 高可用
apiserver本身是一个无状态服务,要实现其高可用,在于如何将运行在多台服务器上的apiserver用一个统一的外部入口暴露给所有Node节点和客户端。
对于这种无状态服务的高可用,有两种方案:
-
使用外部负载均衡器,不管是使用公有云提供的负载均衡器服务或是在私有云中使用LVS或者HaProxy自建负载均衡器都可以归到这一类。如何保证负载均衡器的高可用,则是选择这一方案需要考虑的新问题。
-
在网络层做负载均衡,比如在Master节点上用BGP做ECMP,或者在Node节点上用iptables做NAT都可以实现。采用这一方案不需要额外的外部服务,但是对网络配置有一定的要求。
这两种思路均可以实现 kube-apiserver 高可用的目标,但要根据实际情况做出选择:
- 建议在公有云上的集群多考虑方案一
- 建议在私有云上的集群多考虑方案二,因为私有云环境中需要额外维护负载均衡器
kube-controller-manager与kube-scheduler
这两项服务是Master节点的一部分,他们的高可用相对容易,仅需要运行多份实例即可。
目前在多个Master节点上采用static pod模式部署这两项服务的方案比较常见。
kube-dns
严格来说kube-dns并不算是Master组件的一部分,因为它是可以跑在Node节点上,并用Service向集群内部提供服务的。
为了避免单点故障,请将kube-dns的replicas值设为2或者更多,并用anti-affinity将他们部署在不同的Node节点上。
高可用架构


高可用实践
实验拓扑
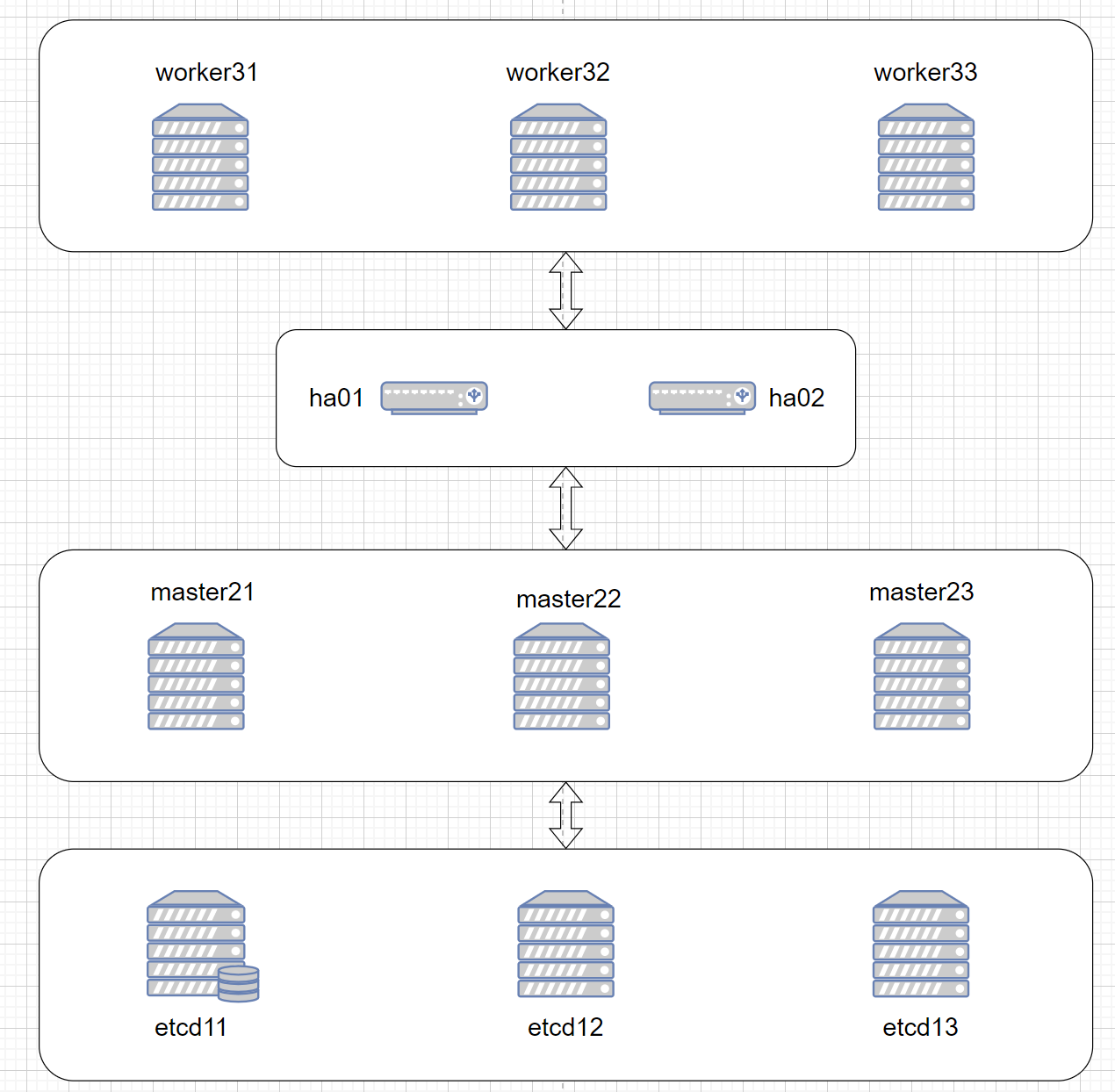
主机清单
| 集群 | 节点 | 地址 | 角色 |
|---|---|---|---|
| 高可用 | ha01.laoma.cloud | 10.1.8.101 | 高可用和负载均衡 |
| 高可用 | ha02.laoma.cloud | 10.1.8.102 | 高可用和负载均衡 |
| etcd | etcd11.laoma.cloud | 10.1.8.111 | etcd 节点 |
| etcd | etcd12.laoma.cloud | 10.1.8.112 | etcd 节点 |
| etcd | etcd13.laoma.cloud | 10.1.8.113 | etcd 节点 |
| Kubernetes | master21.laoma.cloud | 10.1.8.121 | master 节点 |
| Kubernetes | master22.laoma.cloud | 10.1.8.122 | master 节点 |
| Kubernetes | master23.laoma.cloud | 10.1.8.123 | master 节点 |
| Kubernetes | worker31.laoma.cloud | 10.1.8.131 | worker 节点 |
| Kubernetes | worker32.laoma.cloud | 10.1.8.132 | worker 节点 |
| Kubernetes | worker33.laoma.cloud | 10.1.8.133 | worker 节点 |
主机硬件配置清单
- Kubernetes节点:2 CPU、4G 内存
- 其他节点:1 CPU、1G 内存
准备虚拟机-base 模版
安装系统
Ubuntu 2404 系统安装
最小化安装系统,不需要swap分区,按以下要求分区。
- /boot 2G
- / 90G
安装基础软件包
bash
root@ubuntu2404:~# apt update && apt install -y vim bash-completion open-vm-tools apt-transport-https lrzsz unzip配置仓库源
操作系统仓库
操作系统仓库换成华为云的仓库,速度更快。
bash
root@ubuntu2404:~# cat /etc/apt/sources.list.d/ubuntu.sources
Types: deb
URIs: http://mirrors.huaweicloud.com/ubuntu/
Suites: noble noble-updates noble-backports
Components: main restricted universe multiverse
Signed-By: /usr/share/keyrings/ubuntu-archive-keyring.gpg
#Types: deb
#URIs: http://security.ubuntu.com/ubuntu/
#Suites: noble-security
#Components: main restricted universe multiverse
#Signed-By: /usr/share/keyrings/ubuntu-archive-keyring.gpgcontainerd 仓库
bash
# 导入 containerd 仓库 key
root@ubuntu2404:~# curl -fsSL https://mirrors.huaweicloud.com/docker-ce/linux/ubuntu/gpg | gpg --dearmour -o /etc/apt/trusted.gpg.d/containerd.gpg
# 添加 containerd 仓库
root@ubuntu2404:~# cat << 'EOF' > /etc/apt/sources.list.d/docker-ce.list
deb [arch=amd64] https://mirrors.huaweicloud.com/docker-ce/linux/ubuntu noble stable
EOFkubernetes 仓库
由于 Kubernetes 官方变更了仓库的存储路径以及使用方式,使用 1.28 及以上版本,需按照新版配置方法进行配置。
该文档示例为配置 1.30 版本,如需其他版本请在对应位置字符串替换即可。比如需要安装 1.29 版本,则需要将如下配置中的 v1.30 替换成 v1.29。
目前该源支持 v1.24 - v1.30 版本,后续版本会持续更新。
bash
# 添加 kubernetes 仓库 key
root@ubuntu2404:~# curl -fsSL https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.30/deb/Release.key | gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
# 添加 kubernetes 仓库
root@ubuntu2404:~# echo "deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.30/deb/ /" > /etc/apt/sources.list.d/kubernetes.list
# 更新仓库源
root@ubuntu2404:~# apt update设置 IP
bash
root@ubuntu2404:~# mkdir /etc/netplan/origin
root@ubuntu2404:~# mv /etc/netplan/*yaml /etc/netplan/origin
root@ubuntu2404:~# cat > /etc/netplan/00-static.yaml <<EOF
network:
ethernets:
ens32:
dhcp4: no
addresses:
- 10.1.8.10/24
routes:
- to: default
via: 10.1.8.2
nameservers:
addresses:
- 10.1.8.2
- 223.5.5.5
version: 2
EOF
root@ubuntu2404:~# chmod 600 /etc/netplan/00-static.yaml
root@ubuntu2404:~# netplan apply设置 /etc/hosts
bash
root@ubuntu2404:~# cat << 'EOF' >> /etc/hosts
####### kubernetes #####
10.1.8.100 k8s.laoma.cloud k8s
10.1.8.101 ha01.laoma.cloud ha01
10.1.8.102 ha02.laoma.cloud ha02
10.1.8.111 etcd11.laoma.cloud etcd11
10.1.8.112 etcd12.laoma.cloud etcd12
10.1.8.113 etcd13.laoma.cloud etcd13
10.1.8.121 master21.laoma.cloud master21
10.1.8.122 master22.laoma.cloud master22
10.1.8.123 master23.laoma.cloud master23
10.1.8.131 worker31.laoma.cloud worker31
10.1.8.132 worker32.laoma.cloud worker32
10.1.8.133 worker33.laoma.cloud worker33
EOF配置对时
bash
root@ubuntu2404:~# apt-get install -y chrony
# 以下步骤可以省略
root@ubuntu2404:~# systemctl enable chrony --now设置 ssh
bash
# 避免ssh服务器对客户端IP进行反向解析为域名,客户端可以快速与服务器建立连接
root@ubuntu2404:~# echo 'UseDNS no' >> /etc/ssh/sshd_config
# 避免ssh客户端校验服务器公钥,否则首次连接需要交互输入yes
root@ubuntu2404:~# echo 'StrictHostKeyChecking no' >> /etc/ssh/ssh_config
# 生成秘钥
root@ubuntu2404:~# ssh-keygen -N '' -f ~/.ssh/id_rsa -t rsa
# 配置免密登录自己
root@ubuntu2404:~# ssh-copy-id root@localhost配置 IPVS
bash
# 1. 安装 ipvs 依赖包
[root@ubuntu2404 ~]# apt install -y iptables ipvsadm ipset conntrack
# 2-1. 加载基础网络模块:临时加载(立即生效)
[root@ubuntu2404 ~]# modprobe overlay
[root@ubuntu2404 ~]# modprobe br_netfilter
# 模块功能说明:
# br_netfilter:允许桥接设备(Linux 网桥)通过 iptables 过滤,是 Kubernetes 网络通信必需。
# overlay:Overlay 文件系统模块,容器运行时(containerd/docker)分层镜像必备。
# 2-2. 加载 ipvs 内核模块:临时加载(立即生效)
[root@ubuntu2404 ~]# modprobe ip_vs
[root@ubuntu2404 ~]# modprobe ip_vs_rr
[root@ubuntu2404 ~]# modprobe ip_vs_wrr
[root@ubuntu2404 ~]# modprobe ip_vs_lc
[root@ubuntu2404 ~]# modprobe ip_vs_sh
[root@ubuntu2404 ~]# modprobe nf_conntrack
# 模块功能说明:
# ip_vs:IPVS 核心模块,实现四层负载均衡,是 kube-proxy ipvs 模式的基础。
# ip_vs_rr:IPVS 轮询调度算法,按顺序依次分发请求。
# ip_vs_wrr:加权轮询,按后端节点权重分配流量。
# ip_vs_lc:最少连接调度,优先发给连接数最少的节点。
# ip_vs_sh:源地址哈希,保证同一客户端 IP 始终访问同一后端。
# nf_conntrack:连接跟踪,记录网络连接状态,保证数据包正确转发。
# 3 永久加载模块(重启生效)
# systemd-modules-load.service 会自动加载改配置文件
[root@ubuntu2404 ~]# cat > /etc/modules-load.d/k8s-net.conf << EOF
# K8s 基础网络
br_netfilter
overlay
# IPVS 必需
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_lc
ip_vs_sh
nf_conntrack
EOF设置脚本
bash
root@ubuntu2404:~# cat > /usr/local/bin/sethost <<'EOF'
#!/bin/bash
# 以 root 身份运行
[ $UID -ne 0 ] && echo 'Please run as root.' && exit 1
# 指定接口名称
net_config=/etc/netplan/00-installer-config.yaml
# 指定域名称
domain=laoma.cloud
# 脚本使用说明
usage (){
echo "Usage: $0 101-102 | 111-113 | 121-123 | 131-133"
exit 1
}
# 设置 IP 地址
function set_ip () {
# 修改网卡配置文件IP
IP=10.1.8.$1
sed -ri "s#10.1.8.[0-9]{,3}/#$IP/#g" ${net_config}
# 设置网卡文件权限
chmod 600 ${net_config}
# 激活IP
netplan apply
}
# 设置主机名
function set_hostname () {
HOSTNAME_END=$[ $1 - 100 ].$domain
# 获取主机名
case $1 in
10[1-2])
HOSTNAME=ha0${HOSTNAME_END}
;;
11[1-3])
HOSTNAME=etcd${HOSTNAME_END}
;;
12[1-3])
HOSTNAME=master${HOSTNAME_END}
;;
13[1-3])
HOSTNAME=worker${HOSTNAME_END}
;;
*)
usage
;;
esac
# 设置主机名
hostnamectl hostname $HOSTNAME
}
# 定义 main 函数调用功能函数
function main() {
# 设置主机名
set_hostname $1
# 设置 IP
set_ip $1
# 显示修改结果
bash -c 'clear;hostname;echo;ip -br a;echo'
# 关机打快照
while true
do
echo -ne "Press the \033[1;31mEnter\033[0;39m key, and the system will shut down in 5 seconds.";read
echo -e "Press \033[1;35mCTRL+C\033[0;39m to cancel the shutdown."
for i in {5..1}
do
echo "The system will shut down in $i seconds."
sleep 1
done
echo "Shutdown system Now." && init 0
done
}
# 执行 main 函数
main $*
EOF
root@ubuntu2404:~# chmod +x /usr/local/bin/sethost打快照-base
关闭虚拟机,打快照,名称base。
bash
root@ubuntu2404:~# init 0准备虚拟机-k8s 模版
提示:基于上个虚拟机原有快照base继续配置系统。
关闭 swap
如果有 swap 分区,需要关闭。kubernetes不需要swap分区。
bash
root@ubuntu2404:~# swapoff -a && sed -i '/^.*swap/d' /etc/fstab
root@ubuntu2404:~# rm -f /swap.img配置 containerd
bash
[root@ubuntu2404 ~]# apt-get install -y containerd.io=1.7.20-1 cri-tools
# 设置crictl的runtime-endpoint
root@ubuntu2204:~# crictl config runtime-endpoint unix:///var/run/containerd/containerd.sock
[root@ubuntu2404 ~]# containerd config default > /etc/containerd/config.toml
# 修改 SystemdCgroup 和 sandbox_image
[root@ubuntu2404 ~]# sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml
[root@ubuntu2404 ~]# sed -i 's|sandbox_image = ".*"|sandbox_image = "registry.k8s.io/pause:3.9"|' /etc/containerd/config.toml
# 配置镜像仓库加速
[root@ubuntu2404 ~]# vim /etc/containerd/config.toml
toml
# 查找 mirrors行
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
# 添加如下四行记录,注意缩进
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://docker.m.daocloud.io","https://docker.1ms.run","https://docker.xuanyuan.me"]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."registry.k8s.io"]
endpoint = ["https://k8s.m.daocloud.io","https://registry.cn-hangzhou.aliyuncs.com/google_containers"]
bash
# 重启服务
[root@ubuntu2404 ~]# systemctl restart containerd.service
# containerd 服务,默认已经设置开机启动,并启动crictl 走的是 containerd CRI 接口 ,会读取 /etc/containerd/config.toml 里的 registry.mirrors 配置。
下载测试:
bash
[root@ubuntu2404 ~]# crictl pull busybox
Image is up to date for sha256:925ff61909aebae4bcc9bc04bb96a8bd15cd2271f13159fe95ce4338824531dd安装 nerdctl 和 cni plugin
nerdctl 项目地址:https://github.com/containerd/nerdctl/releases
cni 插件项目地址:https://github.com/containernetworking/plugins/releases
bash
# 下载并安装
[root@ubuntu2404 ~]# wget http://192.168.46.100/01.softwares/03.stage-3/nerdctl-1.7.7-linux-amd64.tar.gz
[root@ubuntu2404 ~]# tar -xf nerdctl-1.7.7-linux-amd64.tar.gz -C /usr/bin/
# 下载 nerdctl 所需要的 cni 插件
[root@ubuntu2404 ~]# wget http://192.168.46.100/01.softwares/03.stage-3/cni-plugins-linux-amd64-v1.6.0.tgz
[root@ubuntu2404 ~]# mkdir -p /opt/cni/bin
[root@ubuntu2404 ~]# tar -xf cni-plugins-linux-amd64-v1.6.0.tgz -C /opt/cni/binnerdctl 走的是 containerd 原生 API ,不会读取 CRI 专属的 registry 配置,而是用自己独立的镜像源配置。
nerdctl 有自己的配置文件,需要单独配置 Docker Hub 加速。
bash
# 配置 docker.io 镜像加速
mkdir -p /etc/containerd/certs.d/docker.io
cat > /etc/containerd/certs.d/docker.io/hosts.toml << EOF
server = "https://registry-1.docker.io"
[host."https://09def58152000fc00ff0c00057bad7e0.mirror.swr.myhuaweicloud.com"]
capabilities = ["pull", "resolve"]
EOF
# 配置 registry.k8s.io 镜像加速
mkdir -p /etc/containerd/certs.d/registry.k8s.io
cat > /etc/containerd/certs.d/registry.k8s.io/hosts.toml << EOF
server = "https://registry.k8s.io"
# 首选 DaoCloud
[host."https://k8s.m.daocloud.io"]
capabilities = ["pull", "resolve"]
# 次选 Mirrorify
[host."https://k8s.mirrorify.net"]
capabilities = ["pull", "resolve"]
# 兜底阿里云(如有账号)
[host."https://registry.cn-hangzhou.aliyuncs.com/google_containers"]
capabilities = ["pull", "resolve"]
override_path = true
EOF下载测试:
bash
[root@ubuntu2404 ~]# nerdctl pull nginx
docker.io/library/nginx:latest: resolved |++++++++++++++++++++++++++++++++++++++|
index-sha256:7f0adca1fc6c29c8dc49a2e90037a10ba20dc266baaed0988e9fb4d0d8b85ba0: done |++++++++++++++++++++++++++++++++++++++|
manifest-sha256:f1e4ce3095f46ab65fd053991508a2433e2d7b45f6d8260c93d69c37d4307350: done |++++++++++++++++++++++++++++++++++++++|
config-sha256:a716c9c12c382ab51a71127f1dd9440af118939b92af2814d14f6232bb6105d4: done |++++++++++++++++++++++++++++++++++++++|
elapsed: 0.3 s total: 0.0 B (0.0 B/s)安装 kubernetes 软件包
bash
# 查看版本
[root@ubuntu2404 ~]# apt list kubeadm -a|head
WARNING: apt does not have a stable CLI interface. Use with caution in scripts.
Listing...
kubeadm/unknown 1.30.2-1.1 amd64
kubeadm/unknown 1.30.1-1.1 amd64
kubeadm/unknown 1.30.0-1.1 amd64
kubeadm/unknown 1.30.2-1.1 arm64
kubeadm/unknown 1.30.1-1.1 arm64
kubeadm/unknown 1.30.0-1.1 arm64
kubeadm/unknown 1.30.2-1.1 ppc64el
[root@ubuntu2404 ~]# apt install -y kubeadm=1.30.2-1.1 kubelet=1.30.2-1.1 kubectl=1.30.2-1.1
# 设置 kubelet 服务
[root@ubuntu2404 ~]# systemctl enable kubelet --now此时kubelet服务处于activating,等 kubernetes 安装完成后状态变更为active。
配置相关命令补全
bash
# 配置 crictl 命令自动补全
[root@ubuntu2404 ~]# mkdir /etc/bash_completion.d
[root@ubuntu2404 ~]# crictl completion bash > /etc/bash_completion.d/crictl
[root@ubuntu2404 ~]# source /etc/bash_completion.d/crictl
# 配置 nerdctl 命令自动补全
[root@ubuntu2404 ~]# nerdctl completion bash > /etc/bash_completion.d/nerdctl
[root@ubuntu2404 ~]# echo 'export CONTAINERD_NAMESPACE=k8s.io' >> /etc/bash_completion.d/nerdctl
[root@ubuntu2404 ~]# source /etc/bash_completion.d/nerdctl注意 :此处必须设置变量 CONTAINERD_NAMESPACE,否则 nerdctl 默认将镜像导入到 default 命名空间,导致 k8s 无法使用镜像。k8s 默认使用 k8s.io 命名空间中镜像。
bash
# 配置 kubectl 命令补全
[root@ubuntu2404 ~]# kubectl completion bash > /etc/bash_completion.d/kubectl
[root@ubuntu2404 ~]# source /etc/bash_completion.d/kubectl
# 配置 kubeadm 命令补全
[root@ubuntu2404 ~]# kubeadm completion bash > /etc/bash_completion.d/kubeadm
[root@ubuntu2404 ~]# source /etc/bash_completion.d/kubeadm打快照-k8s
关闭虚拟机,打快照,名称k8s。
bash
root@ubuntu2404:~# init 0准备集群节点
通过 base 快照克隆ha节点和etcd节点机器。
通过 k8s 快照克隆 k8s 节点机器。
使用sethost脚本设置主机名和IP地址。
bash
root@ubuntu2404:~# sethost
Usage: /usr/local/bin/sethost 101-102 | 111-113 | 121-123 | 131-133
root@ubuntu2404:~# sethost 101部署 Etcd 集群
bash
# 所有etcd节点配置
root@etcdN:~# apt update && apt install -y etcd-server etcd-client
root@etcdN:~# systemctl stop etcd.service
root@etcdN:~# rm -fr /var/lib/etcd/default
# etcd11节点配置
root@etcd11:~# cp /etc/default/etcd /etc/default/etcd.ori
root@etcd11:~# cat > /etc/default/etcd <<'EOF'
ETCD_NAME="etcd11"
ETCD_DATA_DIR="/var/lib/etcd/default"
ETCD_LISTEN_PEER_URLS="http://localhost:2380,http://10.1.8.111:2380"
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://10.1.8.111:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.1.8.111:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379,http://10.1.8.111:2379"
ETCD_INITIAL_CLUSTER="etcd11=http://10.1.8.111:2380,etcd12=http://10.1.8.112:2380,etcd13=http://10.1.8.113:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
EOF
# etcd12节点配置
root@etcd12:~# cp /etc/default/etcd /etc/default/etcd.ori
root@etcd12:~# cat > /etc/default/etcd <<'EOF'
ETCD_NAME="etcd12"
ETCD_DATA_DIR="/var/lib/etcd/default"
ETCD_LISTEN_PEER_URLS="http://localhost:2380,http://10.1.8.112:2380"
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://10.1.8.112:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.1.8.112:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379,http://10.1.8.112:2379"
ETCD_INITIAL_CLUSTER="etcd11=http://10.1.8.111:2380,etcd12=http://10.1.8.112:2380,etcd13=http://10.1.8.113:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
EOF
# etcd3节点配置
root@etcd13:~# cp /etc/default/etcd /etc/default/etcd.ori
root@etcd13:~# cat > /etc/default/etcd <<'EOF'
ETCD_NAME="etcd13"
ETCD_DATA_DIR="/var/lib/etcd/default"
ETCD_LISTEN_PEER_URLS="http://localhost:2380,http://10.1.8.113:2380"
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://10.1.8.113:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.1.8.113:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379,http://10.1.8.113:2379"
ETCD_INITIAL_CLUSTER="etcd11=http://10.1.8.111:2380,etcd12=http://10.1.8.112:2380,etcd13=http://10.1.8.113:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
EOF
# 所有节点启用并启动服务
root@etcdN:~# systemctl enable etcd
root@etcdN:~# systemctl start etcd
# 验证集群状态
root@etcd11:~# etcdctl member list
56ee9a8b1143f1f6, started, etcd12, http://10.1.8.112:2380, http://10.1.8.112:2379,http://localhost:2379, false
b09f448fe279511f, started, etcd11, http://10.1.8.111:2380, http://10.1.8.111:2379,http://localhost:2379, false
b83c09e0fc6318a6, started, etcd13, http://10.1.8.113:2380, http://10.1.8.113:2379,http://localhost:2379, false配置补全
bash
root@etcdN:~# mkdir /etc/bash_completion.d
root@etcdN:~# etcdctl completion bash > /etc/bash_completion.d/etcdctl
root@etcdN:~# source /etc/bash_completion.d/etcdctl部署 Keepalived 集群
bash
# 所有 HA 节点安装keepalived
root@haN:~# apt install -y keepalived
# ha2修改配置文件
root@ha02:~# cp /etc/keepalived/keepalived.conf{.sample,}
root@ha02:~# cat > /etc/keepalived/keepalived.conf <<'EOF'
! Configuration File for keepalived
global_defs {
router_id ha02
}
vrrp_instance k8s {
state BACKUP
interface ens32
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.1.8.100/24
}
}
EOF
# 启用并启动安装keepalived服务
root@ha02:~# systemctl enable keepalived.service
root@ha02:~# systemctl restart keepalived.service
root@ha02:~# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
ens32 UP 10.1.8.102/24 fe80::20c:29ff:fea5:36a1/64
# ha1修改配置文件
root@ha01:~# cp /etc/keepalived/keepalived.conf{.sample,}
root@ha01:~# cat > /etc/keepalived/keepalived.conf <<'EOF'
! Configuration File for keepalived
global_defs {
router_id ha01
}
vrrp_instance k8s {
state MASTER
interface ens32
virtual_router_id 51
priority 200
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.1.8.100/24
}
}
EOF
# 启用并启动安装keepalived服务
root@ha01:~# systemctl enable keepalived.service
root@ha01:~# systemctl restart keepalived.service
root@ha01:~# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
ens32 UP 10.1.8.101/24 10.1.8.100/24 fe80::20c:29ff:fe39:b65c/64 部署 Haproxy 集群
提示:所有 HA 节点都部署Haproxy 集群
bash
# 安装软件包
root@haN:~# apt install -y haproxy
# 更改haproxy.cfg
root@haN:~# cat >> /etc/haproxy/haproxy.cfg <<'EOF'
# 新增统计面板配置
listen stats
bind *:1080 # 监听 1080 端口(可自定义,如 8080)
mode http
stats enable # 启用统计面板
stats uri /haproxy-stats # 访问路径(如 http://HA节点IP:1080/haproxy-stats)
stats refresh 3s # 页面自动刷新间隔
stats auth admin:123456 # 登录账号密码(生产环境务必修改)
stats hide-version # 隐藏 HAProxy 版本(安全)
# 新增 k8s 面板配置
listen k8s
mode tcp
bind *:6443
balance roundrobin
server master21 10.1.8.121:6443 check inter 3000ms fall 3 rise 2
server master22 10.1.8.122:6443 check inter 3000ms fall 3 rise 2
server master23 10.1.8.123:6443 check inter 3000ms fall 3 rise 2
EOF
root@haN:~# systemctl enable haproxy
root@haN:~# systemctl restart haproxy.service验证配置

部署 Kubernetes 集群
初始化集群
bash
# 生成初始化配置,并且根据需求进行更改,后续可以使用选项--config指定配置文件
[root@master21 ~]# kubeadm config print init-defaults | tee kubeadm-config.yaml
#导入k8s镜像
tar -xvf k8s-1.30.2-images-all.tar.gz;for image in k8s-1.30.2-images/*; do nerdctl load -i $image; done
scp k8s-1.30.2-images/kube-proxy-v1.30.2.tar k8s-1.30.2-images/pause-3.9.tar worker31:
scp k8s-1.30.2-images/kube-proxy-v1.30.2.tar k8s-1.30.2-images/pause-3.9.tar worker32:
scp k8s-1.30.2-images/kube-proxy-v1.30.2.tar k8s-1.30.2-images/pause-3.9.tar worker33:
ssh worker31 'for image in *tar;do nerdctl load -i $image;done'
ssh worker32 'for image in *tar;do nerdctl load -i $image;done'
ssh worker33 'for image in *tar;do nerdctl load -i $image;done'
# 按需修改
[root@master21 ~]# vim kubeadm-config.yaml
bash
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
apiServer:
timeoutForControlPlane: 4m0s
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
# 添加控制平面
controlPlaneEndpoint: "10.1.8.100:6443"
# 修改etcd
etcd:
external:
endpoints:
- "http://10.1.8.111:2379"
- "http://10.1.8.112:2379"
- "http://10.1.8.113:2379"
dns: {}
controllerManager: {}
scheduler: {}
# 按需修改,实验环境使用提前导入的镜像 | 阿里云镜像:imageRepository: registry.aliyuncs.com/google_containers
imageRepository: registry.k8s.io
# 设置版本
kubernetesVersion: 1.30.2
networking:
# 设置域名
dnsDomain: kubernetes.laoma.cloud
# 设置pod子网
podSubnet: 10.224.0.0/16
serviceSubnet: 10.96.0.0/12
---
# 添加kube-proxy配置
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
ipvs:
scheduler: rr
clientConnection:
kubeconfig: /var/lib/kube-proxy/kubeconfig.conf
bash
# 初始化集群
[root@master21 ~]# kubeadm init --config kubeadm-config.yaml
bash
[init] Using Kubernetes version: v1.30.2
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master21.laoma.cloud] and IPs [10.96.0.1 10.1.8.121 10.1.8.100]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] External etcd mode: Skipping etcd/ca certificate authority generation
[certs] External etcd mode: Skipping etcd/server certificate generation
[certs] External etcd mode: Skipping etcd/peer certificate generation
[certs] External etcd mode: Skipping etcd/healthcheck-client certificate generation
[certs] External etcd mode: Skipping apiserver-etcd-client certificate generation
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "super-admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests"
[kubelet-check] Waiting for a healthy kubelet. This can take up to 4m0s
[kubelet-check] The kubelet is healthy after 502.28234ms
[api-check] Waiting for a healthy API server. This can take up to 4m0s
[api-check] The API server is healthy after 5.043608027s
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node master21.laoma.cloud as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node master21.laoma.cloud as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule]
[bootstrap-token] Using token: b0pnwt.1o94h2j82okh7gzt
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join 10.1.8.100:6443 --token b0pnwt.1o94h2j82okh7gzt \
--discovery-token-ca-cert-hash sha256:0bd96f3415a5913f0fe28e6ad29c6bdfd487f4f7f46aa2dcfdf13f3bca00464f \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 10.1.8.100:6443 --token b0pnwt.1o94h2j82okh7gzt \
--discovery-token-ca-cert-hash sha256:0bd96f3415a5913f0fe28e6ad29c6bdfd487f4f7f46aa2dcfdf13f3bca00464f 配置凭据
bash
[root@master21 ~]# mkdir -p $HOME/.kube
[root@master21 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master21 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config部署网络
这里采用 calico 网络。
官方地址:http://projectcalico.org 或者 https://www.tigera.io/project-calico/
产品文档:https://projectcalico.docs.tigera.io/about/about-calico
下载 calico 配置
bash
[root@master21 ~]# wget --no-check-certificate https://raw.githubusercontent.com/projectcalico/calico/v3.30.7/manifests/calico.yaml导入 calico 镜像
bash
# 1. 先给 master21 本地导入 calico 镜像
for img in calico_*.tar; do
echo "✅ 本地导入镜像:$img"
nerdctl load -i "$img"
done
# 2. 批量发送到其他节点 + 远程导入
for host in master{22..23} worker{31..33}
do
echo -e "\n==================================="
echo "正在处理节点:$host"
echo "==================================="
scp calico_*.tar $host:/root/
ssh $host "cd /root && for img in calico_*.tar; do echo '✅ 远程导入:\$img'; nerdctl load -i \$img; done"
done修改 pod 网络
bash
# 查看集群 pod 网络范围
[root@master21 ~]# kubectl get cm -n kube-system kubeadm-config -o yaml|grep podSubnet
podSubnet: 10.224.0.0/16
# 更改 calico.yml,确保 CALICO_IPV4POOL_CIDR 与集群初始化的pod网络一致。
[root@master21 ~]# sed -i "s|# - name: CALICO_IPV4POOL_CIDR|- name: CALICO_IPV4POOL_CIDR|g" calico.yaml
[root@master21 ~]# sed -i "s|# value: \"192.*| value: \"10.224.0.0/16\"|g" calico.yaml下载镜像
bash
[root@master21 ~]# grep image: calico.yaml | uniq
image: docker.io/calico/cni:v3.30.7
image: docker.io/calico/node:v3.30.7
image: docker.io/calico/kube-controllers:v3.30.7
# 如果没有,执行以下命令导入
nerdctl load -i calico_cni-v3.30.7.tar
nerdctl load -i calico_node-v3.30.7.tar
nerdctl load -i calico_kube-controllers-v3.30.7.tar
nerdctl load -i pause-3.9.tar
# 所有节点下载以上镜像
[root@all-node ~]# nerdctl pull docker.io/calico/cni:v3.30.7
[root@all-node ~]# nerdctl pull docker.io/calico/node:v3.30.7
[root@all-node ~]# nerdctl pull docker.io/calico/kube-controllers:v3.30.7部署 calico 网络
bash
[root@master21 ~]# kubectl apply -f calico.yamlmaster 节点加入集群
注意:master22 和 master23 节点 加入集群,过程相同。
bash
# 将master21节点目录/etc/kubernetes/pki/中以下文件拷贝过来到其他master节点
- ca.crt
- ca.key
- sa.key
- sa.pub
- front-proxy-ca.crt
- front-proxy-ca.key
[root@master22-23 ~]# mkdir -p /etc/kubernetes/pki
[root@master22-23 ~]# scp master21:/etc/kubernetes/pki/{ca.crt,ca.key,front-proxy-ca.crt,front-proxy-ca.key,sa.key,sa.pub} /etc/kubernetes/pki/
# 其他master节点加入集群
[root@master21 ~]# kubeadm token create --print-join-command
[root@master22-23 ~]# kubeadm join 10.1.8.100:6443 --token b0pnwt.1o94h2j82okh7gzt \
--discovery-token-ca-cert-hash sha256:0bd96f3415a5913f0fe28e6ad29c6bdfd487f4f7f46aa2dcfdf13f3bca00464f \
--control-plane #--control-plane一定要加
bash
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[preflight] Running pre-flight checks before initializing the new control plane instance
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master22.laoma.cloud] and IPs [10.96.0.1 10.1.8.122 10.1.8.100]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Valid certificates and keys now exist in "/etc/kubernetes/pki"
[certs] Using the existing "sa" key
[kubeconfig] Generating kubeconfig files
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[check-etcd] Skipping etcd check in external mode
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-check] Waiting for a healthy kubelet. This can take up to 4m0s
[kubelet-check] The kubelet is healthy after 504.174675ms
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap
[control-plane-join] Using external etcd - no local stacked instance added
The 'update-status' phase is deprecated and will be removed in a future release. Currently it performs no operation
[mark-control-plane] Marking the node master22.laoma.cloud as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node master22.laoma.cloud as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule]
This node has joined the cluster and a new control plane instance was created:
* Certificate signing request was sent to apiserver and approval was received.
* The Kubelet was informed of the new secure connection details.
* Control plane label and taint were applied to the new node.
* The Kubernetes control plane instances scaled up.
To start administering your cluster from this node, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Run 'kubectl get nodes' to see this node join the cluster.
bash
# 准备凭据文件
[root@master22-23 ~]# mkdir -p $HOME/.kube
[root@master22-23 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master22-23 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/configworker 节点加入集群
bash
# 所有 worker 节点加入集群
[root@workerN ~]# kubeadm join 10.1.8.100:6443 --token b0pnwt.1o94h2j82okh7gzt \
--discovery-token-ca-cert-hash sha256:0bd96f3415a5913f0fe28e6ad29c6bdfd487f4f7f46aa2dcfdf13f3bca00464f 验证安装结果
确认集群状态
bash
# 确认当前集群节点状态
[root@master21 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master21.laoma.cloud Ready control-plane 14m v1.30.2
master22.laoma.cloud Ready control-plane 9m47s v1.30.2
master23.laoma.cloud Ready control-plane 9m15s v1.30.2
worker31.laoma.cloud Ready <none> 8m18s v1.30.2
worker32.laoma.cloud Ready <none> 8m17s v1.30.2
worker33.laoma.cloud Ready <none> 8m15s v1.30.2
# 确认pod状态
[root@master21 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-564985c589-v9njx 1/1 Running 0 10m
calico-node-bdzbb 1/1 Running 0 8m48s
calico-node-h6rrw 1/1 Running 0 10m
calico-node-mhsf2 1/1 Running 0 10m
calico-node-nl94k 1/1 Running 0 9m45s
calico-node-rb29r 1/1 Running 0 8m47s
calico-node-t9swg 1/1 Running 0 8m45s
coredns-7b5944fdcf-5sd4q 1/1 Running 0 14m
coredns-7b5944fdcf-gkgfp 1/1 Running 0 14m
kube-apiserver-master21.laoma.cloud 1/1 Running 0 14m
kube-apiserver-master22.laoma.cloud 1/1 Running 0 10m
kube-apiserver-master23.laoma.cloud 1/1 Running 0 9m44s
kube-controller-manager-master21.laoma.cloud 1/1 Running 0 14m
kube-controller-manager-master22.laoma.cloud 1/1 Running 0 10m
kube-controller-manager-master23.laoma.cloud 1/1 Running 0 9m43s
kube-proxy-7ww8c 1/1 Running 0 9m45s
kube-proxy-df46r 1/1 Running 0 8m48s
kube-proxy-dglmh 1/1 Running 0 8m45s
kube-proxy-q7wrv 1/1 Running 0 8m47s
kube-proxy-v68gp 1/1 Running 0 14m
kube-proxy-vhr5n 1/1 Running 0 10m
kube-scheduler-master21.laoma.cloud 1/1 Running 0 14m
kube-scheduler-master22.laoma.cloud 1/1 Running 0 10m
kube-scheduler-master23.laoma.cloud 1/1 Running 0 9m44s部署测试资源
bash
[root@master21 ~]# kubectl create deployment webapp --image=nginx --replicas 3
[root@master21 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
webapp-7fb6dc88f9-48kcx 1/1 Running 0 57s 10.224.113.129 worker32.laoma.cloud <none> <none>
webapp-7fb6dc88f9-9z87c 1/1 Running 0 57s 10.224.19.1 worker31.laoma.cloud <none> <none>
webapp-7fb6dc88f9-wtn6t 1/1 Running 0 57s 10.224.162.129 worker33.laoma.cloud <none> <none>
# 3个 pod 分布在3个节点
# 准备 pod 页面
[root@master21 ~]# \
for pod in $(kubectl get pods -o name | awk -F/ '{print $2}')
do
kubectl exec -it $pod -- bash -c "echo $pod > /usr/share/nginx/html/index.html"
done
[root@master21 ~]# kubectl expose deployment webapp --port 80 --target-port 80
[root@master21 ~]# kubectl get svc webapp
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
webapp ClusterIP 10.102.27.219 <none> 80/TCP 13s
# 验证效果
[root@master21 ~]# for i in {1..30};do curl -s 10.102.27.219:80;done|sort |uniq -c
9 webapp-7fb6dc88f9-48kcx
10 webapp-7fb6dc88f9-9z87c
11 webapp-7fb6dc88f9-wtn6t高可用测试
- 关闭任意 master 节点,验证集群是否可用。
- 关闭任意 worker 节点,验证集群是否可用。
- 关闭任意 etcd 节点,验证集群是否可用。
- 关闭任意 ha 节点,验证集群是否可用。
Kubernetes 集群升级
学习参考:kubernetes 升级
升级必要性
- 功能性增强。
- 漏洞修复。
- 等等
升级注意事项
- 如果 Kubernetes 集群只有一个master节点,则升级 master 节点过程中将导致集群不可用。
- 如果 Kubernetes 集群只有两个worker节点,则升级第二个 worker 节点时,负载会在第一个worker节点重建,进而导致应用短暂不可用,不可用时间取决于pod重建时间。
升级流程
-
从节点角度看:先逐个升级 master 节点,再逐个升级 worker 节点。
-
从软件层面看:任何节点都需要先升级kubeadm,再利用 kubeadm 升级各个组件,最后升级kubelet和kubectl等。
升级步骤
本次实验环境:从kubernetes 1.30.2 升级到 1.30.4。
升级前准备
bash
# 确认当前安装的版本
[root@master30 ~]# kubectl version
Client Version: v1.30.2
Kustomize Version: v5.0.4-0.20230601165947-6ce0bf390ce3
Server Version: v1.30.2
[root@master30 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master30.laoma.cloud Ready control-plane 53d v1.30.2
worker31.laoma.cloud Ready <none> 53d v1.30.2
worker32.laoma.cloud Ready <none> 53d v1.30.2
# 确认仓库中提供的版本
[root@master30 ~]# apt list kubeadm -a|grep amd64
WARNING: apt does not have a stable CLI interface. Use with caution in scripts.
kubeadm/unknown 1.30.4-1.1 amd64 [upgradable from: 1.30.2-1.1]
kubeadm/unknown 1.30.3-1.1 amd64
kubeadm/unknown,now 1.30.2-1.1 amd64 [installed,upgradable to: 1.30.4-1.1]
kubeadm/unknown 1.30.1-1.1 amd64
kubeadm/unknown 1.30.0-1.1 amd64升级 master
升级 kubeadm
bash
# 升级 kubeadm
[root@master30 ~]# apt install -y kubeadm=1.30.4-1.1如果 kubeadm 被hold住了,使用以下命令解除。
bash# 升级 kubeadm [root@master30 ~]# apt-mark unhold kubeadm
升级 master 节点组件
bash
# 升级帮助
[root@master30 ~]# kubeadm upgrade apply --help
# --dry-run 模拟升级
# --etcd-upgrade 升级 etcd,默认值true。设置为 false 则不升级etcd。
# -f, --force 强制升级,即使部分条件不满足。使用该选项还可以避免二次确认升级。
# 升级计划
[root@master30 ~]# kubeadm upgrade plan
bash
[preflight] Running pre-flight checks.
[upgrade/config] Reading configuration from the cluster...
[upgrade/config] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[upgrade] Running cluster health checks
[upgrade/health] FATAL: [preflight] Some fatal errors occurred:
[ERROR CreateJob]: Job "upgrade-health-check-tk52j" in the namespace "kube-system" did not complete in 15s: no condition of type Complete
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
bash
[root@master30 ~]# kubeadm upgrade plan
bash
[preflight] Running pre-flight checks.
[upgrade/config] Reading configuration from the cluster...
[upgrade/config] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[upgrade] Running cluster health checks
[WARNING CreateJob]: Job "upgrade-health-check-c45nc" in the namespace "kube-system" did not complete in 15s: no condition of type Complete
[upgrade] Fetching available versions to upgrade to
[upgrade/versions] Cluster version: 1.30.2
[upgrade/versions] kubeadm version: v1.30.4
W0905 09:07:28.918665 63943 version.go:104] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable.txt": Get "https://cdn.dl.k8s.io/release/stable.txt": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
W0905 09:07:28.919004 63943 version.go:105] falling back to the local client version: v1.30.4
[upgrade/versions] Target version: v1.30.4
[upgrade/versions] Latest version in the v1.30 series: v1.30.4
Components that must be upgraded manually after you have upgraded the control plane with 'kubeadm upgrade apply':
COMPONENT NODE CURRENT TARGET
kubelet master30.laoma.cloud v1.30.2 v1.30.4
kubelet worker31.laoma.cloud v1.30.2 v1.30.4
kubelet worker32.laoma.cloud v1.30.2 v1.30.4
Upgrade to the latest version in the v1.30 series:
COMPONENT NODE CURRENT TARGET
kube-apiserver master30.laoma.cloud v1.30.2 v1.30.4
kube-controller-manager master30.laoma.cloud v1.30.2 v1.30.4
kube-scheduler master30.laoma.cloud v1.30.2 v1.30.4
kube-proxy 1.30.2 v1.30.4
CoreDNS v1.11.1 v1.11.1
etcd master30.laoma.cloud 3.5.12-0 3.5.12-0
You can now apply the upgrade by executing the following command:
kubeadm upgrade apply v1.30.4
_____________________________________________________________________
The table below shows the current state of component configs as understood by this version of kubeadm.
Configs that have a "yes" mark in the "MANUAL UPGRADE REQUIRED" column require manual config upgrade or
resetting to kubeadm defaults before a successful upgrade can be performed. The version to manually
upgrade to is denoted in the "PREFERRED VERSION" column.
API GROUP CURRENT VERSION PREFERRED VERSION MANUAL UPGRADE REQUIRED
kubeproxy.config.k8s.io v1alpha1 v1alpha1 no
kubelet.config.k8s.io v1beta1 v1beta1 no
_____________________________________________________________________升级 master 组件
bash
[root@master30 ~]# kubeadm upgrade apply v1.30.4 --force
bash
[preflight] Running pre-flight checks.
[upgrade/config] Reading configuration from the cluster...
[upgrade/config] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[upgrade] Running cluster health checks
[WARNING CreateJob]: Job "upgrade-health-check-wpclk" in the namespace "kube-system" did not complete in 15s: no condition of type Complete
[upgrade/version] You have chosen to change the cluster version to "v1.30.4"
[upgrade/versions] Cluster version: v1.30.2
[upgrade/versions] kubeadm version: v1.30.4
[upgrade/prepull] Pulling images required for setting up a Kubernetes cluster
[upgrade/prepull] This might take a minute or two, depending on the speed of your internet connection
[upgrade/prepull] You can also perform this action in beforehand using 'kubeadm config images pull'
W0905 09:12:29.406987 66867 checks.go:844] detected that the sandbox image "registry.aliyuncs.com/google_containers/pause:3.9" of the container runtime is inconsistent with that used by kubeadm.It is recommended to use "registry.k8s.io/pause:3.9" as the CRI sandbox image.
[upgrade/apply] Upgrading your Static Pod-hosted control plane to version "v1.30.4" (timeout: 5m0s)...
[upgrade/etcd] Upgrading to TLS for etcd
[upgrade/staticpods] Preparing for "etcd" upgrade
[upgrade/staticpods] Current and new manifests of etcd are equal, skipping upgrade
[upgrade/etcd] Waiting for etcd to become available
[upgrade/staticpods] Writing new Static Pod manifests to "/etc/kubernetes/tmp/kubeadm-upgraded-manifests3246055680"
[upgrade/staticpods] Preparing for "kube-apiserver" upgrade
[upgrade/staticpods] Renewing apiserver certificate
[upgrade/staticpods] Renewing apiserver-kubelet-client certificate
[upgrade/staticpods] Renewing front-proxy-client certificate
[upgrade/staticpods] Renewing apiserver-etcd-client certificate
[upgrade/staticpods] Moved new manifest to "/etc/kubernetes/manifests/kube-apiserver.yaml" and backed up old manifest to "/etc/kubernetes/tmp/kubeadm-backup-manifests-2024-09-05-09-12-29/kube-apiserver.yaml"
[upgrade/staticpods] Waiting for the kubelet to restart the component
[upgrade/staticpods] This can take up to 5m0s
[apiclient] Found 1 Pods for label selector component=kube-apiserver
[upgrade/staticpods] Component "kube-apiserver" upgraded successfully!
[upgrade/staticpods] Preparing for "kube-controller-manager" upgrade
[upgrade/staticpods] Renewing controller-manager.conf certificate
[upgrade/staticpods] Moved new manifest to "/etc/kubernetes/manifests/kube-controller-manager.yaml" and backed up old manifest to "/etc/kubernetes/tmp/kubeadm-backup-manifests-2024-09-05-09-12-29/kube-controller-manager.yaml"
[upgrade/staticpods] Waiting for the kubelet to restart the component
[upgrade/staticpods] This can take up to 5m0s
[apiclient] Found 1 Pods for label selector component=kube-controller-manager
[upgrade/staticpods] Component "kube-controller-manager" upgraded successfully!
[upgrade/staticpods] Preparing for "kube-scheduler" upgrade
[upgrade/staticpods] Renewing scheduler.conf certificate
[upgrade/staticpods] Moved new manifest to "/etc/kubernetes/manifests/kube-scheduler.yaml" and backed up old manifest to "/etc/kubernetes/tmp/kubeadm-backup-manifests-2024-09-05-09-12-29/kube-scheduler.yaml"
[upgrade/staticpods] Waiting for the kubelet to restart the component
[upgrade/staticpods] This can take up to 5m0s
[apiclient] Found 1 Pods for label selector component=kube-scheduler
[upgrade/staticpods] Component "kube-scheduler" upgraded successfully!
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster
[upgrade] Backing up kubelet config file to /etc/kubernetes/tmp/kubeadm-kubelet-config1570193532/config.yaml
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
[upgrade/successful] SUCCESS! Your cluster was upgraded to "v1.30.4". Enjoy!
[upgrade/kubelet] Now that your control plane is upgraded, please proceed with upgrading your kubelets if you haven't already done so.kubeadm upgrade apply 做了以下工作:
- 检查你的集群是否处于可升级状态:
- API 服务器是可访问的
- 所有节点处于
Ready状态 - 控制面是健康的
- 强制执行版本偏差策略。
- 确保控制面的镜像是可用的或可拉取到服务器上。
- 如果组件配置要求版本升级,则生成替代配置与/或使用用户提供的覆盖版本配置。
- 升级控制面组件或回滚(如果其中任何一个组件无法启动)。
- 应用新的
CoreDNS和kube-proxy清单,并强制创建所有必需的 RBAC 规则。 - 如果旧文件在 180 天后过期,将创建 API 服务器的新证书和密钥文件并备份旧文件。
升级其他 master 节点
bash
[root@master30 ~]# kubeadm upgrade nodekubeadm upgrade node 在其他控制平节点上执行以下操作:
- 从集群中获取 kubeadm
ClusterConfiguration。 - (可选操作)备份 kube-apiserver 证书。
- 升级控制平面组件的静态 Pod 清单。
- 为本节点升级 kubelet 配置
驱逐 master 节点
bash
# 驱逐 master节点,并设置为不可调度
[root@master30 ~]# kubectl drain master30.laoma.cloud --ignore-daemonsets
[root@master30 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master30.laoma.cloud Ready,SchedulingDisabled control-plane 42h v1.30.2
worker31.laoma.cloud Ready <none> 42h v1.30.2
worker32.laoma.cloud Ready <none> 42h v1.30.2升级 kubelet 和 kubectl
bash
# 升级 kubectl和kubelet
[root@master30 ~]# apt install -y kubelet=1.30.4-1.1 kubectl=1.30.4-1.1
# 重启 kubelet 服务
[root@master30 ~]# systemctl restart kubelet.service取消节点不可调度
bash
# 设置master节点可调度
[root@master30 ~]# kubectl uncordon master30.laoma.cloud
# 验证结果
[root@master30 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master30.laoma.cloud Ready control-plane 48m v1.30.4
worker31.laoma.cloud Ready <none> 37m v1.30.2
worker32.laoma.cloud Ready <none> 37m v1.30.2升级 worker
升级 worker31
bash
# 升级kubeadm
root@worker31:~# apt install -y kubeadm=1.30.4-1.1
# 升级 worker节点组件
root@worker31:~# kubeadm upgrade node
# 以上命令在工作节点上完成以下工作:
# 1.从集群取回 kubeadm ClusterConfiguration。
# 2.为本节点升级 kubelet 配置。
# 驱逐节点上 pod,并取消节点不可调度
[root@master30 ~]# kubectl drain worker31.laoma.cloud --ignore-daemonsets
[root@master30 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master30.laoma.cloud Ready control-plane 50m v1.30.4
worker31.laoma.cloud Ready,SchedulingDisabled <none> 39m v1.30.2
worker32.laoma.cloud Ready <none> 39m v1.30.2
# 升级 kubectl 和 kubelet
root@worker31:~# apt install -y kubelet=1.30.4-1.1 kubectl=1.30.4-1.1
# 重启kubelet服务
root@worker31:~# systemctl restart kubelet.service
# 取消节点不可调度
[root@master30 ~]# kubectl uncordon worker31.laoma.cloud
[root@master30 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master30.laoma.cloud Ready control-plane 51m v1.30.4
worker31.laoma.cloud Ready <none> 40m v1.30.4
worker32.laoma.cloud Ready <none> 40m v1.30.2升级 worker32
bash
# 升级 kubeadm
root@worker32:~# apt install -y kubeadm=1.30.4-1.1
# 升级 worker 节点组件
root@worker32:~# kubeadm upgrade node
# 驱逐节点上pod,并取消节点不可调度
[root@master30 ~]# kubectl drain worker32.laoma.cloud --ignore-daemonsets
[root@master30 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master30.laoma.cloud Ready control-plane 52m v1.30.4
worker31.laoma.cloud Ready <none> 40m v1.30.4
worker32.laoma.cloud Ready,SchedulingDisabled <none> 40m v1.30.2
# 升级 kubectl 和 kubelet
root@worker32:~# apt install -y kubelet=1.30.4-1.1 kubectl=1.30.4-1.1
# 重启 kubelet 服务
root@worker32:~# systemctl restart kubelet.service
# 取消节点不可调度
[root@master30 ~]# kubectl uncordon worker32.laoma.cloud
[root@master30 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master30.laoma.cloud Ready control-plane 53d v1.30.4
worker31.laoma.cloud Ready <none> 53d v1.30.4
worker32.laoma.cloud Ready <none> 53d v1.30.4
# 确认集群版本
[root@master30 ~]# kubectl version
Client Version: v1.30.4
Kustomize Version: v5.0.4-0.20230601165947-6ce0bf390ce3
Server Version: v1.30.4从故障状态恢复
如果 kubeadm upgrade 失败并且没有回滚,例如由于执行期间节点意外关闭, 你可以再次运行 kubeadm upgrade。 此命令是幂等的,并最终确保实际状态是你声明的期望状态。
要从故障状态恢复,你还可以运行 kubeadm upgrade apply --force 而无需更改集群正在运行的版本。
在升级期间,kubeadm 向 /etc/kubernetes/tmp 目录下的如下备份文件夹写入数据:
kubeadm-backup-etcd-<date>-<time>kubeadm-backup-manifests-<date>-<time>
kubeadm-backup-etcd 包含当前控制面节点本地 etcd 成员数据的备份。 如果 etcd 升级失败并且自动回滚也无法修复,则可以将此文件夹中的内容复制到 /var/lib/etcd 进行手工修复。如果使用的是外部的 etcd,则此备份文件夹为空。
kubeadm-backup-manifests 包含当前控制面节点的静态 Pod 清单文件的备份版本。 如果升级失败并且无法自动回滚,则此文件夹中的内容可以复制到 /etc/kubernetes/manifests 目录实现手工恢复。 如果由于某些原因,在升级前后某个组件的清单未发生变化,则 kubeadm 也不会为之生成备份版本。
31.laoma.cloud Ready,SchedulingDisabled 39m v1.30.2
worker32.laoma.cloud Ready 39m v1.30.2
升级 kubectl 和 kubelet
root@worker31:~# apt install -y kubelet=1.30.4-1.1 kubectl=1.30.4-1.1
重启kubelet服务
root@worker31:~# systemctl restart kubelet.service
取消节点不可调度
root@master30 \~# kubectl uncordon worker31.laoma.cloud
root@master30 \~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master30.laoma.cloud Ready control-plane 51m v1.30.4
worker31.laoma.cloud Ready 40m v1.30.4
worker32.laoma.cloud Ready 40m v1.30.2
#### 升级 worker32
```bash
# 升级 kubeadm
root@worker32:~# apt install -y kubeadm=1.30.4-1.1
# 升级 worker 节点组件
root@worker32:~# kubeadm upgrade node
# 驱逐节点上pod,并取消节点不可调度
[root@master30 ~]# kubectl drain worker32.laoma.cloud --ignore-daemonsets
[root@master30 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master30.laoma.cloud Ready control-plane 52m v1.30.4
worker31.laoma.cloud Ready <none> 40m v1.30.4
worker32.laoma.cloud Ready,SchedulingDisabled <none> 40m v1.30.2
# 升级 kubectl 和 kubelet
root@worker32:~# apt install -y kubelet=1.30.4-1.1 kubectl=1.30.4-1.1
# 重启 kubelet 服务
root@worker32:~# systemctl restart kubelet.service
# 取消节点不可调度
[root@master30 ~]# kubectl uncordon worker32.laoma.cloud
[root@master30 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master30.laoma.cloud Ready control-plane 53d v1.30.4
worker31.laoma.cloud Ready <none> 53d v1.30.4
worker32.laoma.cloud Ready <none> 53d v1.30.4
# 确认集群版本
[root@master30 ~]# kubectl version
Client Version: v1.30.4
Kustomize Version: v5.0.4-0.20230601165947-6ce0bf390ce3
Server Version: v1.30.4从故障状态恢复
如果 kubeadm upgrade 失败并且没有回滚,例如由于执行期间节点意外关闭, 你可以再次运行 kubeadm upgrade。 此命令是幂等的,并最终确保实际状态是你声明的期望状态。
要从故障状态恢复,你还可以运行 kubeadm upgrade apply --force 而无需更改集群正在运行的版本。
在升级期间,kubeadm 向 /etc/kubernetes/tmp 目录下的如下备份文件夹写入数据:
kubeadm-backup-etcd-<date>-<time>kubeadm-backup-manifests-<date>-<time>
kubeadm-backup-etcd 包含当前控制面节点本地 etcd 成员数据的备份。 如果 etcd 升级失败并且自动回滚也无法修复,则可以将此文件夹中的内容复制到 /var/lib/etcd 进行手工修复。如果使用的是外部的 etcd,则此备份文件夹为空。
kubeadm-backup-manifests 包含当前控制面节点的静态 Pod 清单文件的备份版本。 如果升级失败并且无法自动回滚,则此文件夹中的内容可以复制到 /etc/kubernetes/manifests 目录实现手工恢复。 如果由于某些原因,在升级前后某个组件的清单未发生变化,则 kubeadm 也不会为之生成备份版本。