NTIRE 2026 Challenge on Remote Sensing Infrared Image Super-Resolution第五名方案解读
论文:The First Challenge on Remote Sensing Infrared Image Super-Resolution at NTIRE 2026: Benchmark Results and Method Overview
一. 简介
NTIRE 的全称为New Trends in Image Restoration and Enhancement Challenges,即"图像复原和复原挑战中的新趋势",是CVPR(IEEE Conference on Computer Vision and Pattern Recognition)举办的极具影响力的计算机视觉底层任务比赛,主要涉及的研究方向有:图像超分辨率、图像去噪、去模糊、去摩尔纹、重建和去雾等。

其中在2026年,CVPR开展的NTIRE相关挑战有:
- 夜间图像去雾(NightTime Image Dehazing);
- 图像阴影去除(Image Shadow Removal);
- 3D内容超分辨率重建(3D Content Super-Resolution);
- 光场图像超分(Light Field Image Super-Resolution);
- 低光图像增强(Low Light Image Enhancement);
- 图像去噪(Image Denoising);
- 4倍图像超分辨率重建(Image Super-Resolution (x4));
- 遥感红外图像超分辨率重建(Remote Sensing Infrared Image Super-Resolution);
- 高效超分辨率重建(Efficient Super-Resolution);
- 3D内容复原和重建(3D Restoration and Reconstruction);
- 高效真实世界去模糊(Efficient Real-World Deblurring )。
同时,以上的这些挑战也蕴含着当前的一些研究难点及挑战,需要研究学者们集思广益,提出针对提升任务性能的想法,为共同解决近年来的难题贡献出一份力量。
本篇文章着重于NTIRE 2026 遥感红外图像超分辨率重建(Remote Sensing Infrared Image Super-Resolution) 挑战赛第五名队伍方案的解读,总结报告中能够提升任务的tricks,以期给相关的科研任务一些启发。
二、红外遥感超分比赛情况
共有 115 名参与者注册参加比赛,13 个团队成绩有效。各个队伍的成绩及排名如下:
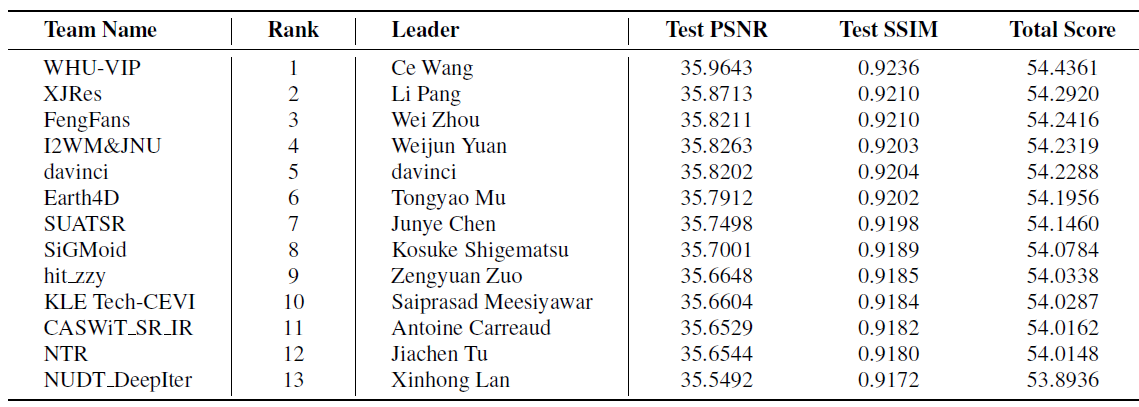
综合各个指标(PSNR/SSIM/LPIPS等)的判定标准下,几个有特色的队伍成绩如下:
| 排名 | 队伍 | 综合得分依据 | 方案关键词 |
|---|---|---|---|
| 1 | WHU-VIP | PSNR 第 1 + SSIM 第 1 | Quality-Aware、HAT、SatVideoIRSDT |
| 2 | XJRes | PSNR 第 2 + SSIM 第 2 | PFT、HAT、model ensemble、self-ensemble |
| 3 | FengFans | PSNR 第 4 + SSIM 第 2 | HAT、model ensemble、self-ensemble |
| 4 | I2WM&JNU | PSNR 第 3 + SSIM 第 5 | HAT、Mamba、model ensemble、self-ensemble |
| 5 | davinci | PSNR 第 5 + SSIM 第 4 | HAT、Mona |
亮点:前5名之间的差距已经非常小,PSNR差距在0.15 dB以内,都有使用HAT模型 ,说明Transformer-based 超分模型依然是主力。这很好理解,红外图像虽然纹理弱,但它在更大尺度上往往存在比较稳定的热分布模式与区域结构关系。Transformer 擅长建模长距离依赖,因此特别适合处理这种"局部纹理不足、全局结构重要"的视觉任务。
题外话:笔者觉得部分队伍的名字非常熟悉,仔细一看,XJRes原来是NTIRE 2026 Challenge on Nighttime Image Dehazing赛道的亚军队伍 ; I2WM&JNU是NTIRE 2026 Challenge on Image Super-Resolution (x4) 赛道的亚军队伍,也是NTIRE 2026 Challenge on Image Denoising赛道的亚军队伍。以上队伍实力强劲,在多个赛道都是佼佼者,salute!
三、数据集介绍
本次挑战赛使用了官方提供的 InfraredSR数据集 ,所有低分辨率(LR)图像均由高分辨率(HR)红外图像经过4倍双三次下采样生成。数据集一共包含 1341 对 LR/HR 图像,其中包含1019对训练集,100对验证集,222对测试集。如下图展示,InfraredSR 数据集覆盖了多种典型红外遥感场景,包含不同地面覆盖类型、建筑物分布及地形特征,具有较好的代表性与多样性。

评价指标 :所有参赛队伍按照综合图像质量评估(IQA)得分进行排名,该分数通过将选手重建的高分辨率图像与测试集中的真实高分辨率图像(Ground Truth,GT)进行比较计算得出。官方 IQA 计分公式为:
S c o r e = P S N R + 20 × S S I M Score = PSNR + 20 \times SSIM Score=PSNR+20×SSIM
四、第五名方案解读
第五名队伍davinci 针对遥感红外图像超分任务,采用了一种轻量化适配器微调 的方案。与前四名队伍不同,davinci的核心思路是:不重新训练整个模型,而是在预训练的HAT模型中插入轻量级可训练模块------Mona(Multi-cognitive Visual Adapter),仅更新适配器参数,实现高效的任务迁移和超分性能提升 。Mona是一种新型视觉适配器微调方法,通过引入多认知视觉滤波器 和输入分布优化,仅调整约5%~10%的骨干网络参数,就能在多个视觉任务中取得超越全参数微调的效果。该方案在保持较低计算成本的同时,成功将预训练的HAT模型适配到红外遥感图像超分任务,最终在13支参赛队伍中位列第5名。davinci团队方案的核心设计如下:
- 预训练HAT模型:作为骨干网络,提供强大的自然图像超分基础能力;
- Mona适配器注入:在HAT的注意力层和FFN层之后插入Mona模块,仅训练适配器参数;
- 轻量化微调:骨干网络参数冻结,仅更新Mona模块,大幅降低训练成本和存储开销。
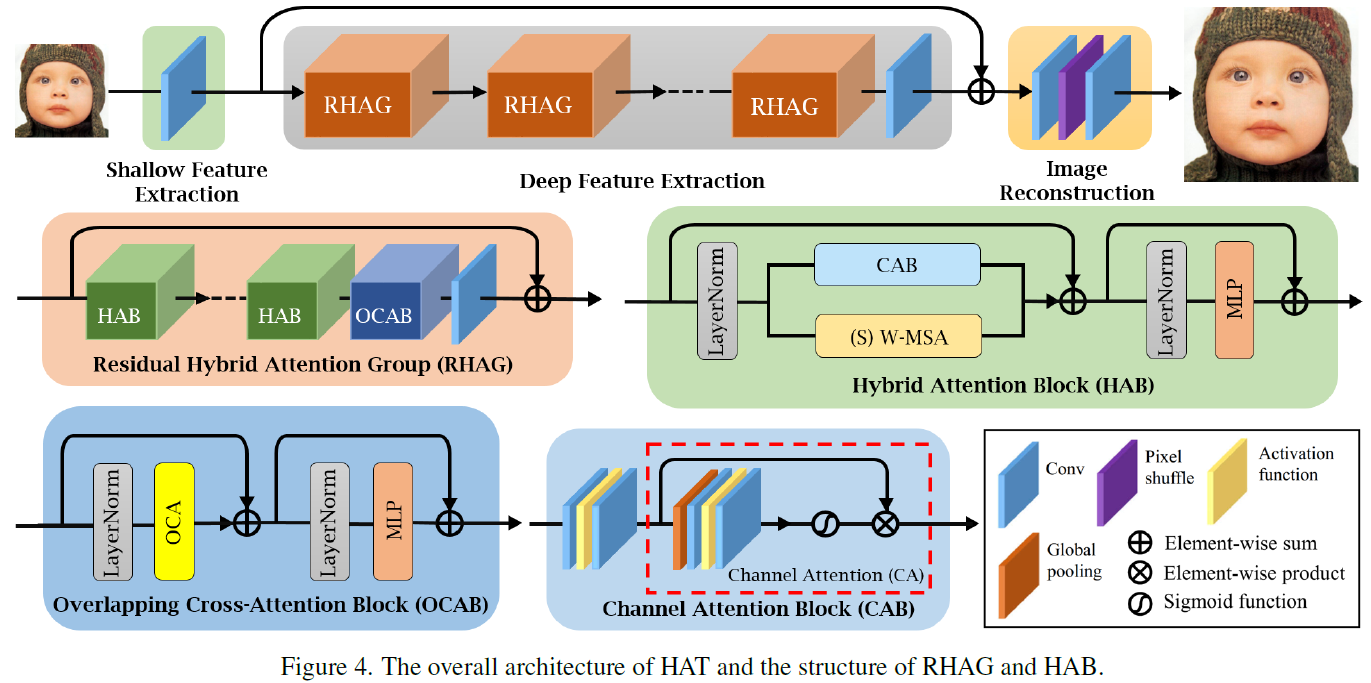
1. HAT骨干网络
davinci采用**HAT(Hybrid Attention Transformer)**作为骨干网络。HAT在标准窗口自注意力的基础上,引入了两个有效的机制:
- 重叠交叉注意力(Overlapping Cross-Attention, OCA):相邻窗口共享键值区域,允许跨窗口边界进行信息交换,避免了全局注意力的二次计算开销;
- 通道注意力块(Channel Attention Block, CAB):在每个Transformer块中集成的压缩-激励风格模块,用于重新校准通道维度的特征响应,提升表示能力。
HAT模型在ImageNet和DF2K数据集上进行了预训练,具备强大的自然图像低层特征表示能力。在微调过程中,davinci冻结HAT骨干网络的所有参数,仅训练插入的Mona适配器模块。
2. Mona适配器模块
Mona(Multi-cognitive Visual Adapter)是一种专为视觉任务设计的轻量级适配器微调方法,旨在打破传统全参数微调在视觉识别任务中的性能瓶颈。其核心设计如下所示:
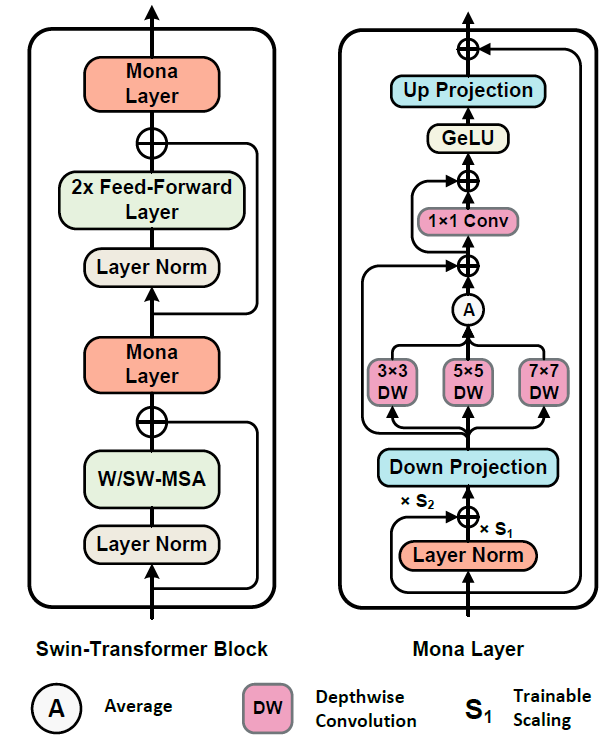
2.1 输入分布优化
Mona在适配器前端加入了分布适配层 ,用于调整从固定主干网络传递过来的特征分布,使其更适合适配器的处理,从而提高微调效率。具体实现中,Mona使用可学习的缩放参数对LayerNorm的输出进行调制:
x = L a y e r N o r m ( x ) ⋅ S 1 + x ⋅ S 2 x=LayerNorm(x)⋅S_1+x⋅S_2 x=LayerNorm(x)⋅S1+x⋅S2
2.2 多认知视觉滤波器
Mona的核心创新在于引入了多尺度深度可分离卷积来增强适配器对视觉信号的处理能力。与传统的线性适配器不同,Mona专门针对视觉任务设计,使用三种不同尺寸的卷积核(3×3、5×5、7×7)并行处理特征,并进行平均融合:
python
class MonaOp(nn.Module):
def __init__(self, in_features):
super().__init__()
self.conv1 = nn.Conv2d(in_features, in_features, kernel_size=3, padding=3 // 2, groups=in_features)
self.conv2 = nn.Conv2d(in_features, in_features, kernel_size=5, padding=5 // 2, groups=in_features)
self.conv3 = nn.Conv2d(in_features, in_features, kernel_size=7, padding=7 // 2, groups=in_features)
self.projector = nn.Conv2d(in_features, in_features, kernel_size=1, )
def forward(self, x):
identity = x
conv1_x = self.conv1(x)
conv2_x = self.conv2(x)
conv3_x = self.conv3(x)
x = (conv1_x + conv2_x + conv3_x) / 3.0 + identity
identity = x
x = self.projector(x)
return identity + x这种多尺度特征融合的设计,使得Mona能够更好地捕捉不同感受野下的视觉特征,提升模型对视觉信息的理解能力。
2.3 残差连接与降维升维
Mona模块内部包含:
- 降维投影:将高维特征压缩到较低维度的中间空间,降低计算开销;
- 多认知卷积处理:在低维空间中进行多尺度深度可分离卷积特征提取;
- 升维投影:将处理后的特征映射回原始维度;
- 跳跃连接:保证信息流的通畅,增强模型的适应能力。
2.4 模块集成方式
Mona适配器被插入到HAT骨干网络的注意力层之后和FFN层之后:
python
x = self.attn(x, hw_shape) + x # 注意力层输出
x = self.mona1(x, hw_shape) # Mona适配器1
x = self.ffn(x, identity=identity) # FFN层输出
x = self.mona2(x, hw_shape) # Mona适配器2这种设计使得Mona能够同时作用于注意力和前馈网络两个分支,实现更全面的特征适配。
3. 微调策略
训练配置:
- 骨干网络:预训练的HAT模型,参数完全冻结
- 可训练模块:仅Mona适配器参数(约5%~10%的骨干网络参数量)
- 损失函数:L1损失
- 优化器:Adam(默认参数)
- 训练目标:将HAT适配到红外遥感图像超分任务
核心优势:
- 参数效率:仅需训练少量新增参数,大幅降低存储和计算成本;
- 避免过拟合:在小规模红外数据集上,冻结预训练特征可以有效防止过拟合;
- 即插即用:Mona模块可方便地插入现有Transformer架构中,无需重新设计网络结构。
五、总结
davinci的方案提供了一个有价值的思路:在目标任务数据有限的情况下,使用轻量级适配器微调预训练大模型,往往比从头训练或全参数微调更加高效 。Mona适配器通过多尺度深度可分离卷积和输入分布优化,在仅调整约5%~10%参数的情况下,成功将自然图像超分模型迁移到红外遥感领域。这项工作的核心启示在于:轻量化适配器微调是跨领域迁移学习中值得关注的方向,尤其在训练数据有限、计算资源受限的场景下具有重要应用价值。
最后感谢小伙伴们的学习噢~