
本文记录我从零手写
std::list的完整过程:底层节点设计、迭代器封装原理、const 迭代器的合并技巧、深拷贝与初始化列表,以及每一个我曾经踩过的坑。代码完整可运行,适合正在学 C++ 数据结构的同学。也欢迎老师们的斧正。(结尾有完整List.h代码)
目录
[1. 为什么要手写 List?](#1. 为什么要手写 List?)
[2. List 的底层结构:带头循环双向链表](#2. List 的底层结构:带头循环双向链表)
[3. 节点设计:list_node](#3. 节点设计:list_node)
[4. 迭代器的本质:为什么链表不能用裸指针当迭代器](#4. 迭代器的本质:为什么链表不能用裸指针当迭代器)
[5. 迭代器封装:__list_iterator](#5. 迭代器封装:__list_iterator)
[6. const 迭代器:两个类太冗余了------用模板合并](#6. const 迭代器:两个类太冗余了——用模板合并)
[7. List 类的整体结构与初始化](#7. List 类的整体结构与初始化)
[8. push_back / push_front / insert:三者的关系](#8. push_back / push_front / insert:三者的关系)
[9. erase / pop_back / pop_front:迭代器失效问题](#9. erase / pop_back / pop_front:迭代器失效问题)
[10. 拷贝构造与赋值运算符:深拷贝的正确写法](#10. 拷贝构造与赋值运算符:深拷贝的正确写法)
[11. initializer_list:支持花括号初始化](#11. initializer_list:支持花括号初始化)
[12. 析构函数:clear() + delete head](#12. 析构函数:clear() + delete head)
[13. begin() / end():const 版本为什么不能乱加](#13. begin() / end():const 版本为什么不能乱加)
[14. 迭代器分类:为什么 list 不支持 sort 算法](#14. 迭代器分类:为什么 list 不支持 sort 算法)
[15. List 独有的算法:merge / unique / splice](#15. List 独有的算法:merge / unique / splice)
[16. 总结:链表 vs 顺序表的本质差异](#16. 总结:链表 vs 顺序表的本质差异)
1. 为什么要手写 List?
用过 std::list 之后,很多人会停留在"我知道它是双向链表"这个层面。但真正面试的时候,考官问的问题往往是:
- 为什么
list的迭代器不能it + 5,而vector可以? list::sort()和std::sort()有什么区别?为什么std::sort不能用在list上?- 迭代器失效在
list的insert和erase里分别是什么情况? const_iterator和iterator的底层是怎么实现的?
如果你没有亲手写过,这些问题很难回答得有说服力。
我的这篇文章就是把 list 从头到尾打开来看,每一行代码背后的原因都讲清楚。也欢迎老师们的斧正;
2. List 的底层结构:带头循环双向链表
std::list 的底层是带头节点的循环双向链表,这五个字每一个都有意义:
- 双向 :每个节点有
_next和_prev两个指针,可以往前走也可以往后走。 - 循环 :尾节点的
_next指向头节点,头节点的_prev指向尾节点,形成一个环。 - 带头节点 (哨兵节点):存在一个不存储有效数据的头节点
_head,专门用来简化边界处理。
为什么要带头节点?来对比一下:
不带头节点时,插入第一个元素需要特判:
if (head == nullptr) { head = newNode; }
else { ... }带头节点时 ,插入任何位置的逻辑完全统一,不需要特判。头节点永远在那里,begin() 就是 _head->_next,end() 就是 _head 本身。
可以这样想象这个结构(假设链表里有 1、2、3 三个元素):
┌───────────────────────────────┐
▼ │
_head ⇄ node:1 ⇄ node:2 ⇄ node:3 ──────┘
│ ▲
│ │
└──────────────────────┘
end() 返回 _head,begin() 返回 _head->_next(也就是 node:1)。当链表为空时,begin() == end(),循环自然退出。这是一个非常精妙的设计。
3. 节点设计:list_node
cpp
template<class T>
struct list_node
{
T _date;
list_node<T>* _next;
list_node<T>* _prev;
list_node(const T& date = T())
: _date(date)
, _next(nullptr)
, _prev(nullptr)
{}
};几个细节值得说:
用 struct 而不是 class: struct 默认成员是 public 的,因为节点本身就是链表内部使用的工具,没有必要封装,直接访问更方便。
构造函数的默认参数 T(): 这是 C++ 的值初始化语法。如果 T 是 int,T() 就是 0;如果 T 是 string,T() 就是调用 string 的默认构造函数得到空字符串。这让头节点(哨兵节点)可以无参构造:
cpp
_head = new Node(); // 调用 list_node 的构造,T() 作为 _date 的初始值头节点的 _date 是什么值并不重要,我们永远不会去读它,所以用 T() 这个"万能默认值"就够了。
为什么节点类是模板类? 因为链表要存什么类型的数据,由用户决定。list<int> 的节点就是 list_node<int>,list<string> 的节点就是 list_node<string>。节点类型完全依赖于 T,所以必须是模板。
4. 迭代器的本质:为什么链表不能用裸指针当迭代器
vector 和 string 的迭代器,本质上就是裸指针:
// vector 的迭代器大概是这样 typedef T* iterator;
这是因为 vector 的内存是连续的,it + 1 自然就指向下一个元素,指针天然满足迭代器的所有要求,不需要额外封装。也可以说vector和string的指针天生丽质;
但 list 不行。链表的节点分散在内存各处,node + 1 根本不是下一个节点,而是完全无意义的内存地址。所以:
链表的迭代器不能是裸指针,而是一个封装了节点指针的类,这个类重载了
++、--、*、->等运算符,让它用起来"假装"像指针一样。
这就是迭代器封装存在的根本原因。迭代器是一层"语义适配器",把不同容器的遍历方式统一成同一套接口,让算法可以不关心底层是什么结构。
5. 迭代器封装:__list_iterator
cpp
template<class T>
struct __list_iterator
{
typedef list_node<T> Node;
typedef __list_iterator self;
Node* _node; // 迭代器内部只有一个成员:指向当前节点的指针
__list_iterator(Node* node) : _node(node) {}
T& operator*()
{
return _node->_date; // 解引用:返回节点里存的数据
}
T* operator->()
{
return &(_node->_date); // 返回数据的地址,用于 it->成员
}
self& operator++()
{
_node = _node->_next; // 前置++:走到下一个节点
return *this;
}
self& operator--()
{
_node = _node->_prev; // 前置--:走到上一个节点
return *this;
}
bool operator!=(const self& it) const
{
return _node != it._node; // 比较的是节点地址,不是数据
}
bool operator==(const self& it) const
{
return _node == it._node;
}
};逐个讲解每个运算符的意义:
operator* :*it 的语义是"取出迭代器指向的值"。对链表来说,就是取出当前节点的 _date。注意返回的是引用 T&,所以 *it = 10 这种修改也是合法的(可以对其进行修改)。
operator-> :这个稍微绕一点。it->a1 这样的写法,编译器会把它理解成 (it.operator->())->a1。也就是说,-> 运算符要返回一个指针(T*),编译器再对这个指针做一次 -> 访问。所以返回 &(_node->_date) 就能让 it->成员 正常工作。
operator++ :_node = _node->_next,走到链表的下一个节点。这就是为什么链表迭代器的 ++ 不能用指针算术实现------必须走 _next 指针。
operator!=:比较两个迭代器是否相等,比较的是内部存的节点指针是否相同,而不是数据值是否相同。这是迭代器语义:相等意味着"指向同一个位置"。
为什么可以用 Node* 隐式转换构造 iterator?
因为构造函数 __list_iterator(Node* node) 是单参数构造函数,C++ 允许单参数构造函数做隐式转换。所以在 begin() 和 end() 里,直接 return _head->_next 就能自动构造出一个 iterator,不需要显式写 return iterator(_head->_next)(当然显式写更清晰)。
6. const 迭代器:两个类太冗余了------用模板合并
当前代码里,写了两个几乎一模一样的类:__list_iterator 和 __list_const_iterator,区别只是 operator* 返回 T& 还是 const T&。
这太冗余了。两个类,两倍的维护成本,改一处还要改另一处,非常容易出 bug。
标准库的做法是:把这两个类合并成一个模板,用额外的模板参数来区分。
cpp
// Ref 是 T& 还是 const T&
// Ptr 是 T* 还是 const T*
template<class T, class Ref, class Ptr>
struct __list_iterator
{
typedef list_node<T> Node;
typedef __list_iterator<T, Ref, Ptr> self;
Node* _node;
__list_iterator(Node* node) : _node(node) {}
Ref operator*()
{
return _node->_date; // 如果 Ref 是 const T&,这里就是只读的
}
Ptr operator->()
{
return &(_node->_date); // 如果 Ptr 是 const T*,外面就不能通过它修改
}
self& operator++()
{
_node = _node->_next;
return *this;
}
self& operator--()
{
_node = _node->_prev;
return *this;
}
bool operator!=(const self& it) const
{
return _node != it._node;
}
bool operator==(const self& it) const
{
return _node == it._node;
}
};然后在 list 类里这样 typedef:
cpp
template<class T>
class list
{
public:
// 普通迭代器:Ref = T&,Ptr = T*
typedef __list_iterator<T, T&, T*> iterator;
// const 迭代器:Ref = const T&,Ptr = const T*
typedef __list_iterator<T, const T&, const T*> const_iterator;
// ...
};原理是什么?
当你实例化 iterator(也就是 __list_iterator<T, T&, T*>)时,Ref 就是 T&,operator* 返回的是可修改的引用。
当你实例化 const_iterator(也就是 __list_iterator<T, const T&, const T*>)时,Ref 就是 const T&,operator* 返回的是只读引用,编译器不允许通过它修改数据。
两个类型在编译期就区分开了,运行时没有任何开销。 这是 C++ 模板的经典用法:用类型参数来定制行为,代码复用,零运行时开销。
这个技巧值得记下来,STL 源码里大量使用这种模式。
7. List 类的整体结构与初始化
cpp
template<class T>
class list
{
typedef list_node<T> Node;
public:
typedef __list_iterator<T> iterator;
typedef __list_const_iterator<T> const_iterator;
private:
Node* _head; // 哨兵头节点
size_t _size; // 当前元素数量
};为什么要存 _size?
size() 是一个常用操作。如果不存 _size,每次调用 size() 就要遍历整个链表数节点,O(n)。存了 _size,每次插入删除时维护它,size() 就是 O(1)。以空间换时间,完全值得。
初始化:empty_init()
cpp
void empty_init()
{
_head = new Node(T()); // 创建哨兵头节点,数据无意义
_head->_next = _head; // 指向自己
_head->_prev = _head; // 指向自己
_size = 0;
}空链表的状态:头节点的 _next 和 _prev 都指向自己,形成一个只有哨兵节点的环。此时 begin() 返回 _head->_next(就是 _head 本身),end() 返回 _head,两者相等,范围 for 或 while 循环立即退出------逻辑完全一致,不需要特判空链表。
默认构造函数:
cpp
list()
{
empty_init();
}
list(const list<T>& lt)
{
empty_init();
// 再拷贝节点
}直接调用 empty_init() 就够了。把初始化逻辑抽出来放在 empty_init() 里,是因为拷贝构造函数里也需要做同样的初始化,这样就不用重复代码。
"默认构造和拷贝构造都需要创建空链表,
所以干脆把这部分单独写成函数,
两边都调用。"
8. push_back / push_front / insert:三者的关系
先看 insert,因为 push_back 和 push_front 都是基于它实现的:
cpp
void insert(iterator pos, const T& x)
{
Node* node = new Node(x); // 创建新节点
Node* prev = pos._node->_prev; // pos 的前一个节点
Node* cur = pos._node; // pos 本身
// 把新节点插入 prev 和 cur 之间
node->_next = cur;
cur->_prev = node;
node->_prev = prev;
prev->_next = node;
++_size;
}插入的逻辑是:在 pos 指向的节点之前插入新节点。画图理解:

四步指针操作的顺序有讲究------核心原则是不要在还需要用到某个指针的时候就把它覆盖掉 。代码里先用局部变量保存了 prev 和 cur,所以顺序可以随意,都是安全的。
基于 insert 实现 push_back 和 push_front:
cpp
void push_back(const T& x)
{
insert(end(), x); // 在 end()(也就是头节点)之前插入 = 尾部插入
}
void push_front(const T& x)
{
insert(begin(), x); // 在第一个有效节点之前插入 = 头部插入
}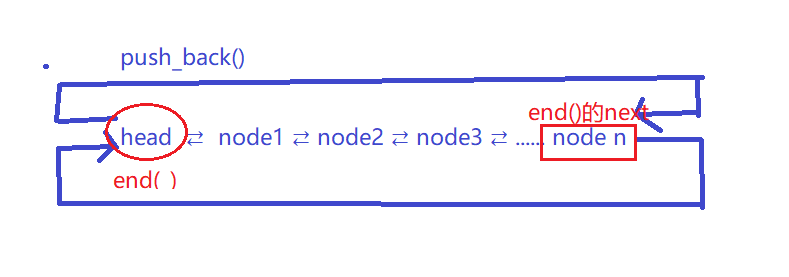

这是非常优雅的设计思路:用最通用的函数实现特殊情况,而不是每个函数都单独写逻辑 。push_back 就是"在 end() 前插入",push_front 就是"在 begin() 前插入",完全复用 insert,没有任何重复代码。
代码里注释掉了一个手写版 push_back:
cpp
// 注释掉的版本,正确但冗余
void push_back(const T& x)
{
Node* tail = _head->_prev;
Node* newnode = new Node(x);
tail->_next = newnode;
newnode->_prev = tail;
newnode->_next = _head;
_head->_prev = newnode;
++_size;
}两个版本逻辑完全等价,但复用 insert 的版本更简洁。
9. erase / pop_back / pop_front:迭代器失效问题
cpp
iterator erase(iterator pos)
{
assert(pos != end()); // 不能删头节点(哨兵节点)
Node* prev = pos._node->_prev;
Node* next = pos._node->_next;
prev->_next = next;
next->_prev = prev;
delete pos._node; // 释放被删节点的内存
--_size;
return next; // 返回下一个位置的迭代器!
}迭代器失效------这是 list 最重要的细节之一:
-
insert不会造成迭代器失效 。insert只是把新节点接入链表,原有节点的地址和_next/_prev指向都还有效,所有已有迭代器还是能正常工作。 -
erase会造成迭代器失效 。delete pos._node之后,pos内部的_node指针指向的内存被释放,pos成了悬空迭代器,再对pos做任何操作(包括++pos)都是未定义行为。
所以 erase 设计成返回下一个有效位置的迭代器,让调用者可以安全地继续遍历。
正确的遍历删除写法:
cpp
auto it = lt.begin();
while (it != lt.end())
{
if (*it % 2 == 0)
{
it = lt.erase(it); // erase 返回下一个位置,赋值给 it
}
else
{
++it;
}
}常见错误写法(会崩溃):
cpp
// 错误!
for (auto it = lt.begin(); it != lt.end(); ++it)
{
if (*it % 2 == 0)
lt.erase(it); // erase 之后 it 失效,++it 是未定义行为
}pop_back 和 pop_front:
cpp
void pop_back()
{
erase(--end()); // end() 是头节点,-- 走到最后一个有效节点
}
void pop_front()
{
erase(begin());
}同样完全复用 erase。
10. 拷贝构造与赋值运算符:深拷贝的正确写法
链表和 string 一样,是"持有堆上资源"的类,必须手动实现深拷贝,否则默认的浅拷贝会导致 double free。
拷贝构造函数:
cpp
list(const list<T>& lt)
{
empty_init(); // 先初始化自己为空链表
for (auto& e : lt)
{
push_back(e); // 把对方每个元素复制过来
}
}逻辑非常清晰:先建立一个空的自己,然后把对方的数据一个一个 push_back 进来。每个节点都是新 new 的,完全独立,不共享任何内存。
赋值运算符(copy-and-swap 惯用法):
cpp
list<T>& operator=(const list<T> lt) // 注意:参数是值传递,不是引用!
{
swap(lt);
return *this;
}这里利用了一个巧妙的技巧:
- 参数
lt是值传递 ,也就是说调用赋值运算符时,编译器会先调用拷贝构造函数 生成一份lt的副本。 - 然后我们把自己(
*this)和这份副本swap。 - 副本(现在持有我们原来的数据)在函数结束时析构,自动释放旧资源。
效果:
*this拿到了lt的深拷贝内容,旧资源被安全释放,完全不需要手动delete。lt 生命周期结束
↓
自动析构
↓
释放 a 原来的资源
swap 的实现:
cpp
void swap(list<T>& lt)
{
std::swap(_head, lt._head);
std::swap(_size, lt._size);
}只交换两个指针和一个整数,O(1),不管链表多长都是三次赋值。
11. initializer_list:支持花括号初始化
有了这个构造函数:
cpp
list(initializer_list<T> il)
{
empty_init();
for (auto& e : il)
{
push_back(e);
}
}就可以这样写:
cpp
list<int> li0({1, 2, 3, 4}); // 直接构造
list<int> li1 = {1, 2, 3, 4, 5}; // 隐式类型转换构造
const list<int>& li3 = {1, 2, 3}; // const 引用绑定临时对象initializer_list 是什么?
{1, 2, 3, 4} 这个花括号列表,编译器会把它识别成一个 std::initializer_list<int> 类型的临时对象,内部是一个指向常量数组的指针和长度。然后这个对象作为参数传给我们的构造函数,我们在里面遍历它。
第三行 const list<int>& li3 = {1, 2, 3} 的解释:
{1, 2, 3} 会先构造一个 list<int> 的临时对象(调用 initializer_list 构造函数),然后 const 引用绑定这个临时对象。C++ 规定,const 引用可以延长临时对象的生命周期,让它活到引用离开作用域为止。
注意:不能用非 const 引用绑定临时对象,因为临时对象具有常性,不可修改。
12. 析构函数:clear() + delete head
cpp
~list()
{
clear(); // 删除所有有效节点
delete _head; // 删除哨兵头节点
_head = nullptr;
}
void clear()
{
auto it = begin();
while (it != end())
{
it = erase(it); // erase 返回下一个位置
}
}为什么 clear() 和析构函数要分开?
clear() 只清空有效数据节点,但保留哨兵头节点(_head),清空后链表仍然是合法的空链表状态,可以继续使用。
析构函数不仅要 clear(),还要把哨兵头节点本身也 delete 掉,因为对象要彻底销毁了。
13. begin() / end():const 版本为什么不能乱加
cpp
iterator begin()
{
return iterator(_head->_next);
}
const_iterator begin() const // 注意这里的 const
{
return const_iterator(_head->_next);
}
iterator end()
{
return _head;
}
const_iterator end() const
{
return _head;
}这里有两个重载版本,不能随意合并或省略。
为什么需要两个版本?
当你有一个 const list<int>& lt,调用 lt.begin() 时,this 是 const list<int>*,只能调用 const 成员函数。如果没有 const_iterator begin() const 这个版本,编译就会报错。
函数后面的 const 是什么意思?
成员函数后面加 const,表示"这个函数不会修改对象的成员变量",同时允许 const 对象调用它。本质上是把 this 指针的类型从 list<T>* 变成 const list<T>*。
为什么普通 begin() 不能加 const?
如果写成:
cpp
const_iterator begin() const // 只有 const 版本那么普通的 list<int> lt 调用 lt.begin() 得到的是 const_iterator,*it 是只读的,就不能写 *it = 10 这样的修改操作了。这不符合普通迭代器的语义。
所以这两个函数缺一不可 ,根据调用对象是否是 const 来自动选择。
14. 迭代器分类:为什么 list 不支持 sort 算法
C++ 把迭代器按能力分成五类(从弱到强):
| 迭代器类型 | 支持的操作 | 典型容器 |
|---|---|---|
| Input Iterator | 单次向前 ++ |
输入流 |
| Forward Iterator | 多次向前 ++ |
forward_list、unordered_map |
| Bidirectional Iterator | ++ 和 -- |
list、map、set |
| Random Access Iterator | ++、--、it+n、it[n]、比较 |
vector、string、deque |
| Output Iterator | 单次写入 | 输出流 |
list 的迭代器是双向迭代器(Bidirectional Iterator) ,可以 ++ 和 --,但不支持 it + 5、it[3] 这种随机访问。
为什么 std::sort 不能用在 list 上?
cpp
// std::sort 的模板声明大概是这样:
template<class RandomAccessIterator>
void sort(RandomAccessIterator first, RandomAccessIterator last);std::sort 要求随机访问迭代器 ,内部算法(通常是快速排序/堆排序/插入排序混合)需要 it + n 来随机跳跃。list 的迭代器做不到这个,编译时就会报错。
编译器用 type tag(类型标签)来在编译期区分这些迭代器:
每种迭代器有一个对应的 tag 结构体(如 bidirectional_iterator_tag、random_access_iterator_tag),模板函数可以通过这些 tag 实现编译期分发,对不同类型的迭代器走不同的实现路径。这是 C++ 模板元编程的基础技巧之一。
list 自带的 sort 成员函数:
cpp
lt.sort(); // list 的成员函数,使用归并排序,O(n log n)list 自己实现了一个 sort,基于归并排序。归并排序非常适合链表:合并两个有序链表只需要改指针,不需要移动数据,完全在 O(1) 空间内完成。
所以记住这个结论:list 要排序,用 lt.sort(),不要用 std::sort(lt.begin(), lt.end())------后者编译失败。
15. List 独有的算法:merge / unique / splice
merge:合并两个有序链表
cpp
list<int> a = {1, 3, 5};
list<int> b = {2, 4, 6};
a.merge(b); // a 变成 {1, 2, 3, 4, 5, 6},b 变成空合并两个有序链表,结果仍然有序。时间复杂度 O(n),操作的是指针,不复制数据。
unique:去除相邻重复元素
cpp
list<int> lt = {1, 1, 2, 3, 3, 3, 4};
lt.unique(); // 变成 {1, 2, 3, 4}注意 unique 只能去除相邻 重复。如果链表是 {1, 2, 1},unique 之后还是 {1, 2, 1},因为两个 1 不相邻。所以通常要先 sort() 再 unique()。
splice:粘接链表
cpp
list<int> a = {1, 2, 3};
list<int> b = {4, 5, 6};
auto it = a.end();
a.splice(it, b); // 把 b 整个插入 a 的末尾
// a = {1, 2, 3, 4, 5, 6},b 变成空splice 是 O(1) 的(仅改指针),不复制数据,极其高效。
这三个算法是 list 独有的,vector 没有,因为它们都依赖链表改指针的 O(1) 操作。
16. 总结:链表 vs 顺序表的本质差异
手写完 list 之后,很多问题的答案就清晰了:
| 对比维度 | list(链表) |
vector(顺序表) |
|---|---|---|
| 内存布局 | 分散,各节点独立 | 连续内存块 |
| 迭代器类型 | 双向迭代器,需要封装类 | 随机访问迭代器,裸指针 |
it + n |
❌ 不支持,O(n) 才能到 | ✅ 直接指针算术,O(1) |
| 头尾插入删除 | ✅ O(1) | 头部 O(n),尾部 O(1) |
| 中间插入删除 | ✅ O(1)(找到位置后) | O(n)(需要移动元素) |
insert 迭代器失效 |
❌ 不失效 | ✅ 失效(可能重新分配) |
erase 迭代器失效 |
✅ 仅被删节点失效 | ✅ 被删之后所有失效 |
支持 std::sort |
❌ 用 lt.sort() |
✅ |
| 缓存友好性 | 差(随机内存访问) | 好(连续内存,预取友好) |
什么时候用 list?
- 频繁在中间或头部插入删除。
- 需要稳定的迭代器(
insert不会失效)。 - 需要
splice、merge等链表专属操作。
什么时候用 vector?
- 需要随机访问(
v[i])。 - 遍历性能要求高(缓存友好)。
- 大部分操作是尾部追加。
理解了底层,这个选择就不再是"记结论",而是自然而然的推导。
完整代码 在文章开头给出的
List.h中,可以直接编译运行。建议自己动手改一改:比如把__list_iterator和__list_const_iterator合并成三参数模板版本,是非常好的练习。"为了贴近经典 STL 写法这里用 typedef,
现代 C++ 更推荐 using。"
代码参考 namespace Jianyi 的实现
cpp
#pragma once
#include<iostream>
#include<assert.h>
using namespace std;
namespace Jianyi
{
template<class T>
struct list_node
{
T _date;
list_node<T>* _next;
list_node<T>* _prev;
list_node(const T& date = T())
:_date(date)
,_next(nullptr)
,_prev(nullptr)
{ }
};
template<class T>
struct __list_iterator
{
typedef list_node<T> Node;
typedef __list_iterator self;
Node* _node;
__list_iterator(Node* node)
:_node(node)
{
}
T* operator->()
{
return &(_node->_date);
}
T& operator*()
{
return _node->_date;
}
const T& operator*()const
{
return _node->_date;
}
self& operator++()
{
_node = _node->_next;
return *this;
}
self& operator--()
{
_node = _node->_prev;
return *this;
}
bool operator!=(const self& it)const
{
return _node != it._node;//只是看指针是否相等
}
bool operator==(const self& it)const
{
return _node == it._node;//只是看指针是否相等
}
};
template<class T>
struct __list_const_iterator
{
typedef list_node<T> Node;
typedef __list_const_iterator self;
Node* _node;
__list_const_iterator(Node* node)
:_node(node)
{
}
const T* operator->()
{
return &(_node->_date);
}
const T& operator*()
{
return _node->_date;
}
const T& operator*()const
{
return _node->_date;
}
self& operator++()
{
_node = _node->_next;
return *this;
}
self& operator--()
{
_node = _node->_prev;
return *this;
}
bool operator!=(const self& it)const
{
return _node != it._node;//只是看指针是否相等
}
bool operator==(const self& it)const
{
return _node == it._node;//只是看指针是否相等
}
};
template<class T>
class list
{
typedef list_node<T> Node;
public:
typedef __list_iterator<T> iterator;
typedef __list_const_iterator<T> const_iterator;
void empty_init()
{
_head = new Node(T());
_head->_next = _head;
_head->_prev = _head;
_size = 0;
}
list()
{
empty_init();
}
list(const list<T>& lt)
{
empty_init();
for (auto& e : lt)
{
push_back(e);
}
}
list(initializer_list<T>il)
{
empty_init();
for (auto& e : il)
{
push_back(e);
}
}
void swap(list<T>& lt)
{
std::swap(_head, lt._head);
std::swap(_size, lt._size);
}
//现代
list<T>& operator=(const list<T> lt)
{
swap(lt);
return *this;
}
~list()
{
clear();
delete _head;
_head = nullptr;
}
void clear()
{
auto it = begin();
while (it != end())
{
it = erase(it);
}
}
iterator erase(iterator pos)
{
assert(pos != end());
Node* prev = pos._node->_prev;
Node* next = pos._node->_next;
prev->_next = next;
next->_prev = prev;
delete pos._node;
--_size;
return next;
}
void pop_front()
{
erase(begin());
}
void pop_back()
{
erase(--end());
}
/*void push_back(const T& x)
{
Node* tail = _head->_prev;
Node* newnode = new Node(x);
tail->_next = newnode;
newnode->_prev = tail;
newnode->_next = _head;
_head->_prev = newnode;
++_size;
}*/
void insert(iterator pos, const T& x)
{
Node* node = new Node(x);
Node* prev = pos._node->_prev;
Node* cur = pos._node;
node->_next = cur;
cur->_prev = node;
node->_prev = prev;
prev->_next = node;
++_size;
}
void push_back(const T& x)
{
insert(end(), x);
}
void push_front(const T& x)
{
insert(begin(), x);
}
size_t size()const
{
return _size;
}
bool empty()const
{
return _size == 0;
}
iterator end()
{
return _head;
}
const_iterator end()const
{
return _head;
}
iterator begin()
{
return iterator(_head->_next);
}
const_iterator begin()const
{
return const_iterator(_head->_next);
}
private:
Node* _head;
size_t _size;
};
template<class Container>
void print_container(const Container& con)
{
list<int>::const_iterator it = con.begin();
while (it != con.end())
{
//*it += 10;
cout << *it << " ";
++it;
}
cout << endl;
}
void list_text01();
void list_text02();
}