DolphinDB:以"存算一体"重新定义工业时序数据的边界
从百万测点的水电站到万台风机的风电场,从核反应堆的毫秒级监控到地震台网的实时波形分析------DolphinDB 正在成为工业物联网时代最坚实的数据底座。
一、时代背景:为什么工业物联网亟需新一代时序数据平台?
在智能制造深入推进的当下,工业现场产生的数据正经历指数级膨胀。一座大型水电站可能部署超过 200 万个传感器测点,每天涌出数百亿行时序数据;一条动力电池检测产线,每秒写入量突破百万数据点;而地震台网的高频波形数据,采样间隔可达毫秒甚至亚毫秒级别。
数据的采集能力早已不是瓶颈。真正的挑战在于:当海量高频的时序数据持续涌入,底层数据库如何兼顾高速写入、实时查询与深度分析?
1.1 行业普遍痛点
大量工业企业在数据平台建设中,掉入了相似的困境:
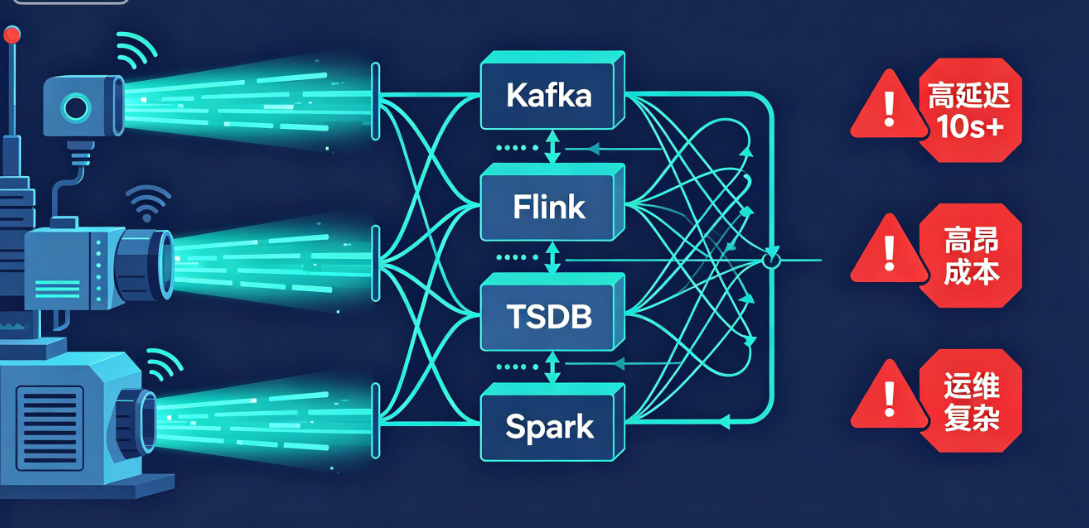
写入量大,查询卡顿。 传统架构往往采用 Kafka + Flink + TSDB + Spark 的"拼凑式"技术栈,数据在异构系统间反复搬运,端到端延迟动辄超过 10 秒。而在工业现场,设备的温度骤升或液压异常在毫秒间发生,数秒的监控延迟就可能导致严重后果。
计算能力薄弱,分析依赖外挂。 多数时序数据库遵循"重存储、轻计算"的产品路线,企业不得不额外搭建大数据分析平台。数据在不同系统间反复抽取、转换和加载,链路冗长、开发周期漫长,信息价值在流转中不断损耗。
智能化落地受阻。 当算法工程师希望利用 PB 级历史数据训练预测模型时,发现数据库缺乏内置计算算子,必须导出数据才能训练;训练好的模型又难以部署到实时数据流。存储与智能分析严重割裂,拖慢了 AI 赋能产业的节奏。
二、DolphinDB 是谁?
DolphinDB 是一款基于高性能时序数据库,集复杂分析与流计算于一体的实时计算平台。自 2016 年成立以来,DolphinDB 持续深耕时序数据的存储、计算与分析领域,先后获得国际权威机构认可------入选 Gartner《Hype Cycle for Data, Analytics and AI in China》报告,以及 Gartner《Innovation Insight: Data Infrastructure Evolves as the Foundation of D&A Ecosystem in China》报告。
DolphinDB 的技术能力已覆盖能源电力、核工业、智能制造、航空航天、地震监测、新能源等核心领域。
DolphinDB 的核心定位不是"又一个时序数据库",而是将数据存储、实时流计算、复杂批分析、AI 推理融为一体的一站式平台------打破传统架构中存储与计算、批处理与流处理、数据与模型之间的壁垒。
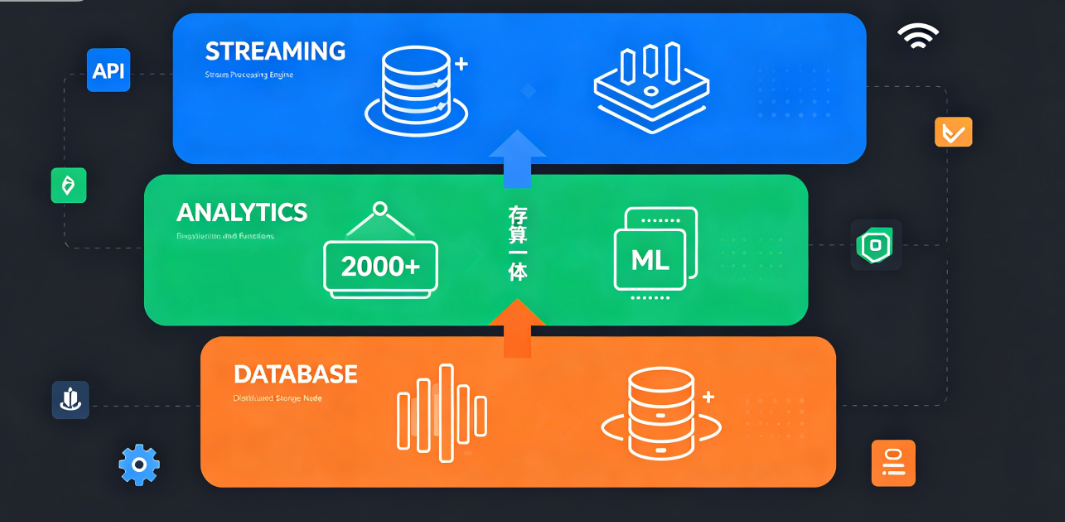
三、核心技术能力
3.1 多模存储引擎:一套平台覆盖所有数据类型
工业物联网场景中,数据形态远不止时序一种。设备台账是关系型数据,工艺参数需要实时更新,AI 模型涉及向量检索。DolphinDB 提供五大存储引擎,在一个平台内满足全部需求:
| 引擎 | 存储方式 | 核心优势 |
|---|---|---|
| TSDB | PAX 行列混存 | 大规模数据分析与高并发点查 |
| OLAP | 纯列式存储 | 长时间跨度聚合计算 |
| PKEY | 主键索引存储 | 支持 OLTP 系统 CDC 数据入库后高效分析 |
| IMOLTP | 内存行存 + B+ 树索引 | 高频高并发事务更新与查询 |
| VECTORDB | 向量索引 | 大规模向量数据快速近似检索 |
此外,DolphinDB 支持多种自适应压缩算法(LZ4、Delta-of-Delta、ZSTD、CHIMP、字典压缩),压缩比可达 4:1 至 10:1,存储成本降低 50% 以上。同时支持分级存储,区分热数据与冷数据,进一步优化存储资源使用。

3.2 分布式架构:弹性扩展与高可用
DolphinDB 采用自研分布式存储机制,数据有序分散在不同节点上,由控制节点统一管理分区元数据、副本信息与版本号,确保一致性。支持在线/离线扩容、横向与纵向扩展,提供无缝的数据迁移与再平衡技术。
在可靠性方面,提供控制节点、数据节点、客户端三层高可用方案,搭配异步复制机制,保障单节点故障下业务持续运行,并具备全面的备份与恢复能力。
3.3 流批一体:一套代码搞定实时与历史
DolphinDB 允许开发者使用同一套脚本同时处理历史批量分析与实时流数据监控。研发环境中的分析模型可以直接无缝部署到生产环境的实时数据流中,且流计算与批计算结果完全一致。
内置 10+ 流式计算引擎,实现亚毫秒级延迟的流数据处理:
- 时间序列聚合引擎:滑动窗口、累计窗口的实时聚合
- 横截面处理引擎:同一时刻多实体的截面分析
- 响应式状态引擎:复杂事件处理延迟低至 0.02 毫秒
- 异常检测引擎:实时捕捉数据异常模式
- 会话窗口引擎:处理不规则时间间隔数据流
- 多表关联引擎:异构频率数据实时关联
- CEP 引擎:复杂事件模式检测与触发
3.4 全栈计算分析:2000+ 函数与 AI 融合
DolphinDB 内置超过 2000 个高度优化的专业函数,覆盖时序处理、信号处理、统计分析、机器学习等领域,支持用户自定义函数。所有函数均经过向量化优化------以滑动窗口计算为例,增量计算模式将复杂度从 O(n) 降至 O(1)。
在 AI 融合方面,DolphinDB 原生支持 Tensor 数据格式,内置轻量化机器学习推理模块,并集成 libTorch、XGBoost 等插件,实现"数据清洗→特征提取→模型推理"在数据库内部闭环完成。

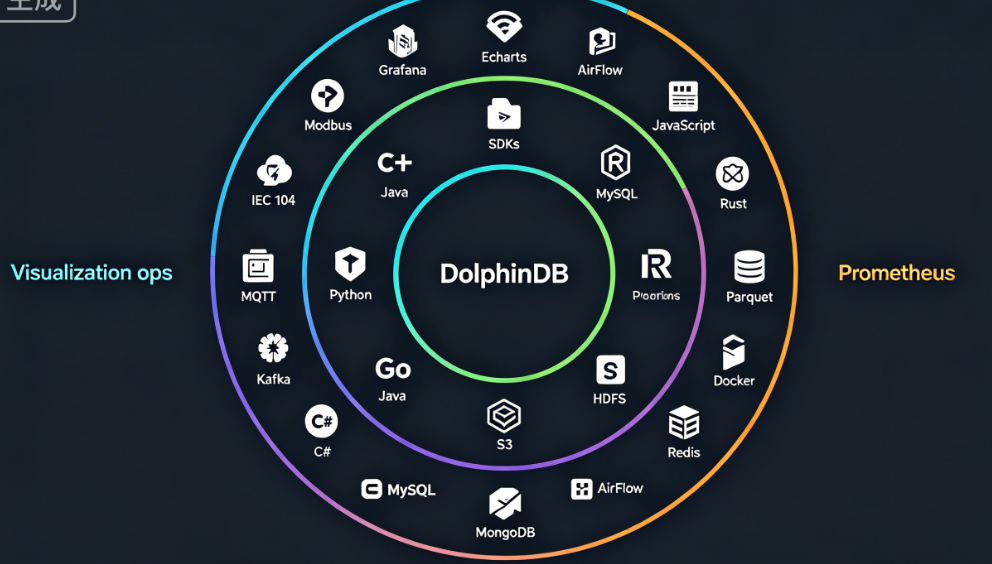
3.5 丰富的协议与生态支持
DolphinDB 深度适配工业物联网的协议与工具链:
- 工业协议:原生支持 MQTT、OPC、OPC UA/DA、Modbus、IEC 104 等主流工业通信协议
- 编程语言 SDK:C++、Java、C#、Python、Go、R、JavaScript、RUST 全覆盖
- 可视化工具:Grafana、SmartBI、Echarts、Redash、Node-RED 等
- 调度与运维:DolphinScheduler、AirFlow、Prometheus、Kerberos、Docker
- 插件生态:涵盖 Kafka、MySQL、ODBC、HDFS、HBase、MongoDB、Redis、Amazon S3、Parquet、HDF5 等数十种数据源与工具
3.6 轻量部署与信创适配
DolphinDB 整体安装包仅 MB 级别,支持 Windows 和 Linux 双平台。在信创生态方面:
- CPU 适配:MIPS、龙芯 LoongArch、ARM v8、x86
- 操作系统适配:UOS、麒麟 KYLIN、NeoKYLIN、LINX-TECH、KOS
- 安全能力:完善的权限管控与审计机制,满足等保合规要求
四、行业解决方案实战
DolphinDB 的技术能力已在众多行业真实场景中经受了极限检验。以下七类典型解决方案,覆盖了工业物联网中最核心的数据处理场景。
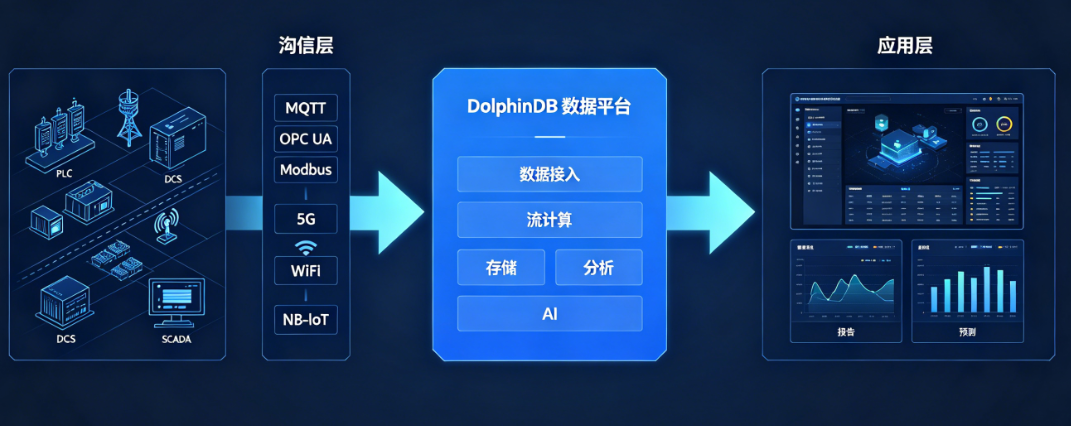
4.1 工业物联网数据底座
DolphinDB 作为统一的工业数据汇聚平台,可将来自 SCADA、PLC、DCS 等系统的数据统一接入,实现设备数据采集→存储→计算→分析→可视化的全链路闭环。通过内置的 MQTT、RESTful API、Socket 等接口,支持 NB-IoT、CAT.1、WiFi、RFID、5G 等多种接入方式。
4.2 设备状态监测与预测性维护
通过 DolphinDB 的实时流计算引擎与内置异常检测算子,对设备运行数据进行实时监测,在故障发生前发出毫秒级预警。同时支持历史数据回放功能,可将故障时段的数据按原始时间戳回放,帮助工程师快速定位问题根因。
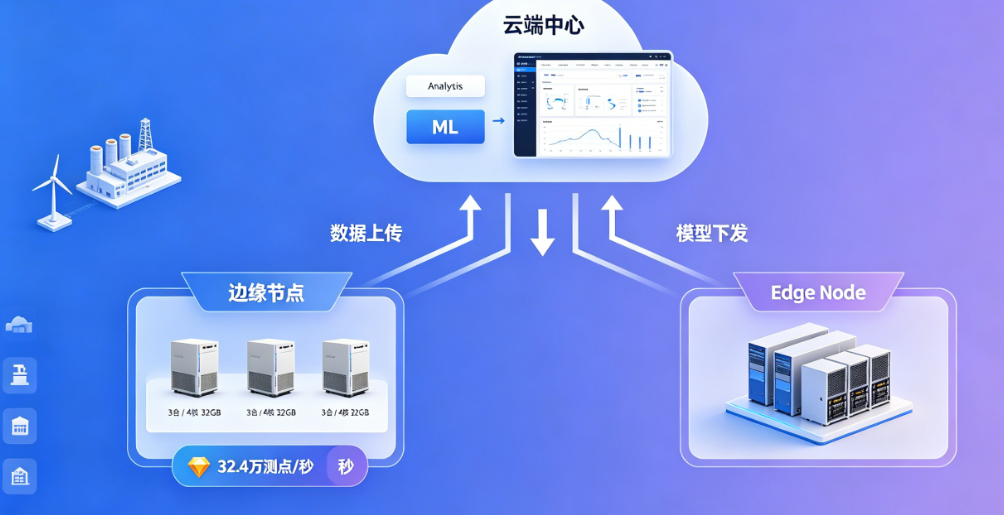
4.3 云边协同:32.4 万测点/秒的极致吞吐
在边缘计算场景中,DolphinDB 展现了惊人的轻量高效能力------仅需 3 台服务器、4 核 32GB 内存 的边缘部署,即可实现 32.4 万测点/秒的稳定数据接入与实时处理。边缘节点负责数据预处理与本地缓存,云端进行全量汇聚与深度分析,实现"边端敏捷、云端智慧"的协同架构。
4.4 水厂集中监控:12 座水厂、10 万+设备的统一管控
某水务集团需要对 12 座水厂、10 万余台设备进行集中统一监控。原有的分散式数据管理方案难以实现跨厂区联动分析。
DolphinDB 为其构建了统一的监控数据平台:
- 全集团水厂数据实时汇聚与集中存储
- 多厂区数据联动查询响应达到秒级
- 通过 DDL/DML 统一管理,运维效率大幅提升
- 支持历史趋势回溯与设备状态对比分析

4.5 地震监测:从 MiniSeed 波形到智能预警
地震台网数据的处理具有极高的专业性与实时性要求。DolphinDB 在地震监测领域的应用涵盖:
- 原生支持 MiniSeed 格式的地震波形数据,支持台网标识(sid)+ 采样率等多维索引
- 采用 lz4 + delta 压缩策略,海量波形数据存储成本大幅降低
- 集成 FilterPicker、RTSeis 等专业地震分析工具,以及 TensorFlow 机器学习框架,实现从波形采集→事件检测→智能预警的闭环
- 基于 DolphinDB 的 MiniSeed 插件,地震波形数据可直接入库分析,无需格式转换
4.6 多源异构数据融合
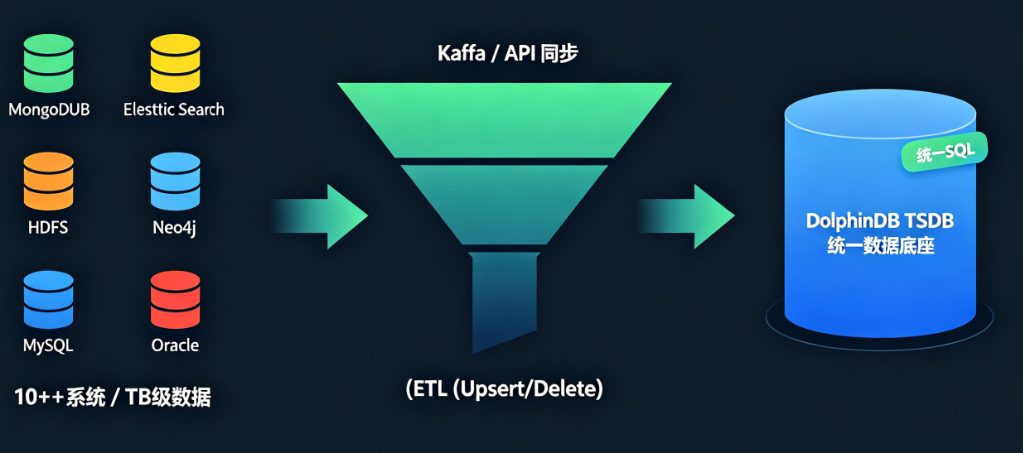
某企业原有系统涉及 MongoDB、Oracle、MySQL 等多种数据库,加上 Java 自建的数据处理模块,整体 TB 级数据分散在 10 余个系统中,SQL 语法不统一,分析效率低下。
DolphinDB 为其构建了统一数据底座:
- 通过 Kafka、MQTT、MySQL、Oracle 等多源数据同步插件,将分散数据统一汇聚至 DolphinDB
- 内置 ETL 能力,支持 Upsert、Delete 等增量同步操作
- 基于 TSDB 引擎进行统一存储与查询,SQL 语法一致,开发效率显著提升
4.7 替代 MySQL:时序场景的性能跃迁
在大量工业项目中,MySQL 因其普及度高被选作时序数据存储方案,但面对百万级高频写入与复杂时序查询时,性能瓶颈暴露无遗。DolphinDB 可作为 MySQL 的时序数据"加速引擎":
- 完全兼容 MySQL 的写入协议,迁移成本极低
- 数据从 MySQL 通过 ETL 工具同步至 DolphinDB,历史查询性能提升数十倍
- 复杂时序聚合、窗口计算等操作在 DolphinDB 内高效完成
- MySQL 继续承担事务型业务,DolphinDB 负责分析型工作负载------各司其职,整体性能最优
五、更多行业标杆实践
5.1 某特大型钢铁企业:从人工经验到算法寻优
某特大型钢铁集团的焙烧工艺参数调整长期依赖人工经验,传统"施耐德 Ampla + SQL Server + Flink"方案下,单次产线调整周期长达半年。
基于 DolphinDB 构建的"机理模型+数据模型"融合实时参数寻优系统,利用内置随机森林、拟牛顿法等算法,实现了产线调整周期从半年压缩至数天,物料浪费减少 30%,年节省焦炭约 1.2 万吨。方案复用于化工、冶金等场景,复用率达 90%。
5.2 某动力电池企业:万亿级实验数据的百倍提速
某头部动力电池企业的实验室检测设备每秒产生超百万数据点,年积累实验数据量达万亿级。原有的分库分表方案导致数据同步延迟高、历史查询慢。
DolphinDB 为其打造实验数据实时分析平台,利用秒级 CDC 实时同步与流计算框架,实现了每秒百万条数据实时处理、监控预警延迟控制在 100 毫秒以内,万亿级历史数据复杂查询从数十分钟骤降至秒级,整体处理时效提升超百倍。
5.3 某国家级核能科研机构:安全分析的效率飞跃
核工业对数据处理的精准度与时效性有着极严苛的要求。该机构借助 DolphinDB 的一站式分析能力与内置机器学习组件,将核反应堆海量运行数据的实时清洗、分析与 AI 预测整合在同一平台内,整体数据处理与分析效率提升 10 倍。
5.4 某特大型能源集团与航天科研机构
在跨地域、超大规模发电设备运行数据的统一汇聚与实时预警调度中,DolphinDB 凭借高可靠的实时计算能力提供了坚实支撑;在精密装备测试与遥测数据处理任务中,其高并发吞吐能力与丰富的库内分析函数保障了测试数据的瞬时反馈与深度挖掘。

六、服务与支持
DolphinDB 提供完善的服务保障体系,覆盖从方案咨询、架构设计、部署实施到持续运维的全生命周期。无论企业规模大小,都能获得与自身需求匹配的技术支持。
七、结语
从 12 座水厂 10 万+设备的集中监控到地震台网的实时波形分析,从核反应堆的安全决策到动力电池万亿级实验数据的百倍提速------DolphinDB 正在以"存算一体、流批一体、AI 融合"的产品理念,重新定义工业时序数据处理的可能性边界。
在数据驱动的时代,选择一个不仅能"存得下",更能"算得快""析得深""用得好"的时序数据平台,不再是锦上添花,而是业务竞争力的根基。
DolphinDB------让每一毫秒的数据价值都不被辜负。

了解更多技术详情,请访问 DolphinDB 官方文档:https://docs.dolphindb.cn/zh/