1. 研究背景
Transformer模型在序列回归任务中表现出色,但其性能高度依赖超参数(如自注意力头数)。传统手动调参效率低、易陷入局部最优。蜣螂优化算法(DBO)是一种新型群智能优化算法,具有较强的全局搜索能力,但其随机初始化可能导致种群多样性不足。引入混沌映射改进种群初始化,可提升算法收敛速度和解的质量,适用于Transformer超参数的自动寻优。
2. 主要功能
- 超参数优化 :自动搜索Transformer的最佳注意力头数(
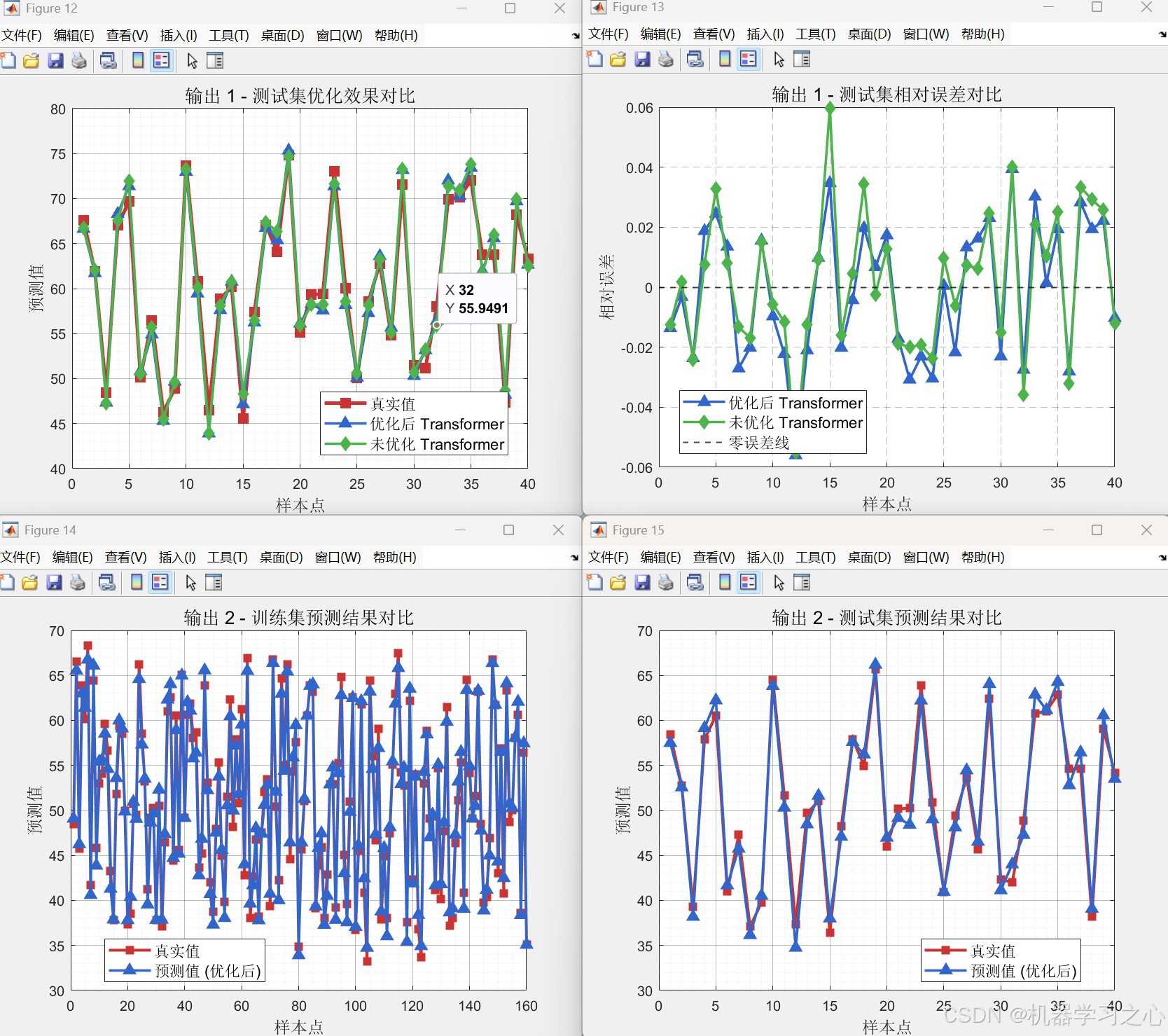
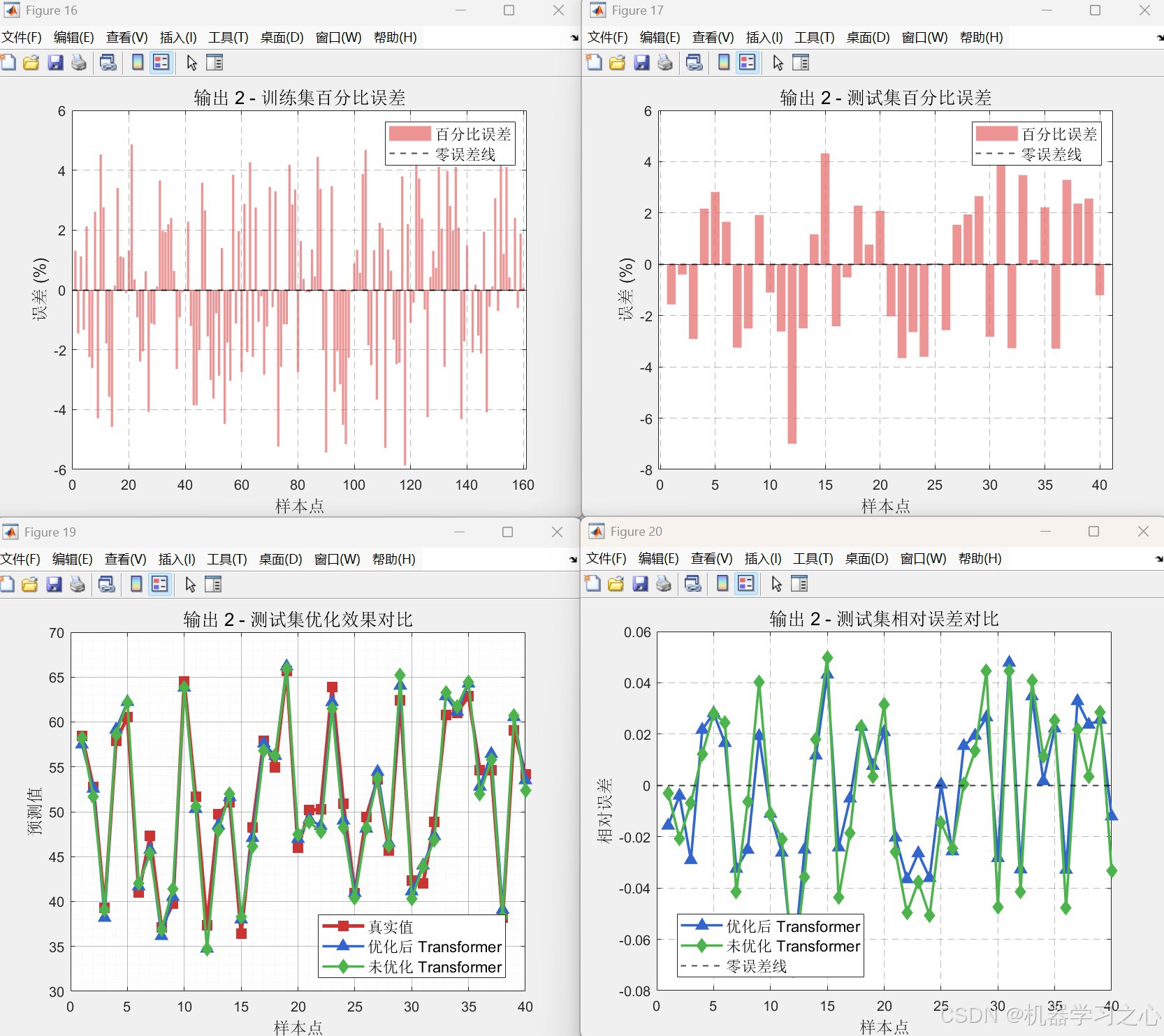
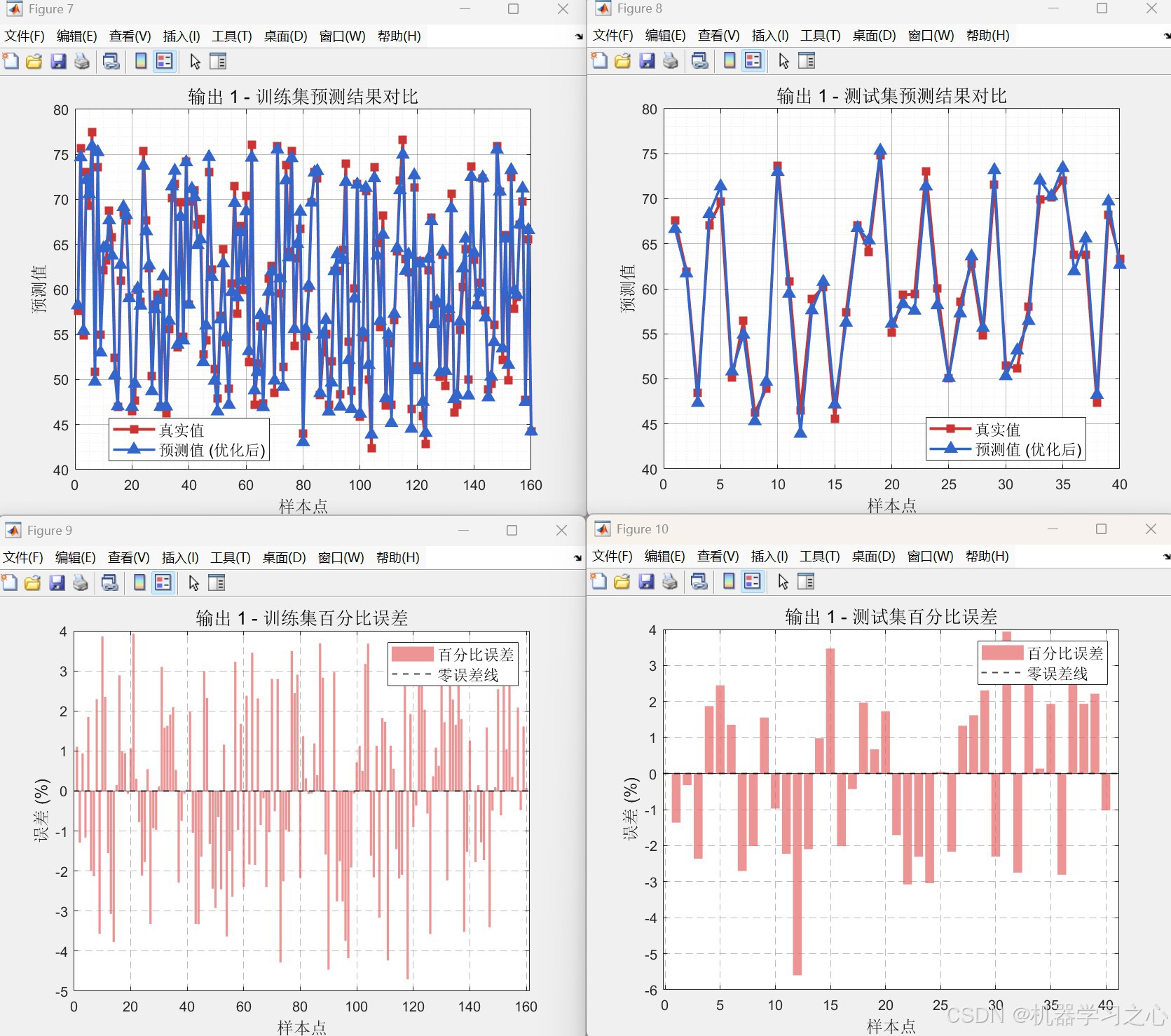
heads),最小化测试集RMSE。 - 性能对比:将优化后的Transformer与固定头数(heads=1)的未优化模型进行RMSE、R²、MAE多指标对比。
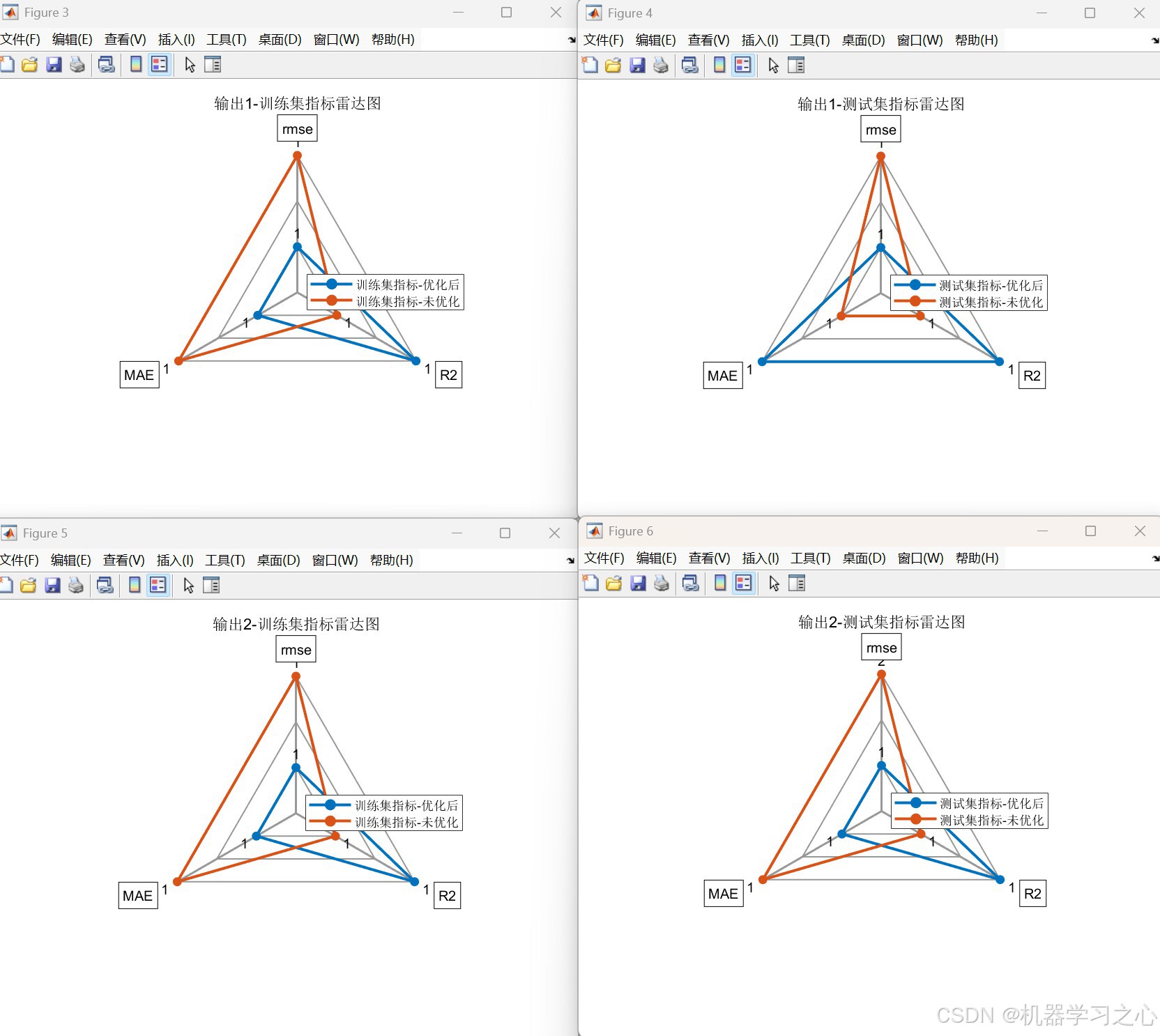
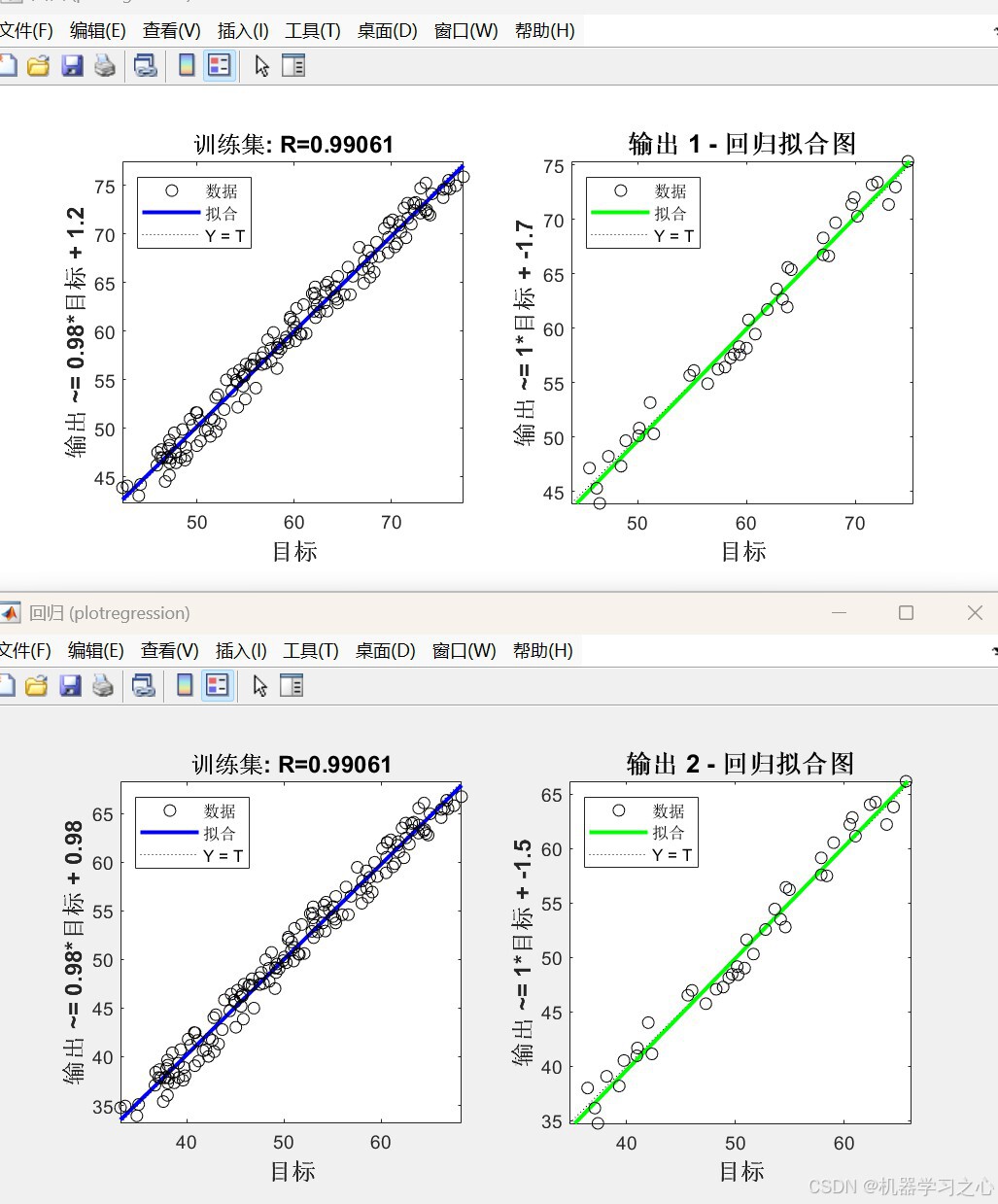
- 多样可视化:收敛曲线、预测对比图、相对误差图、回归拟合图、雷达图等。
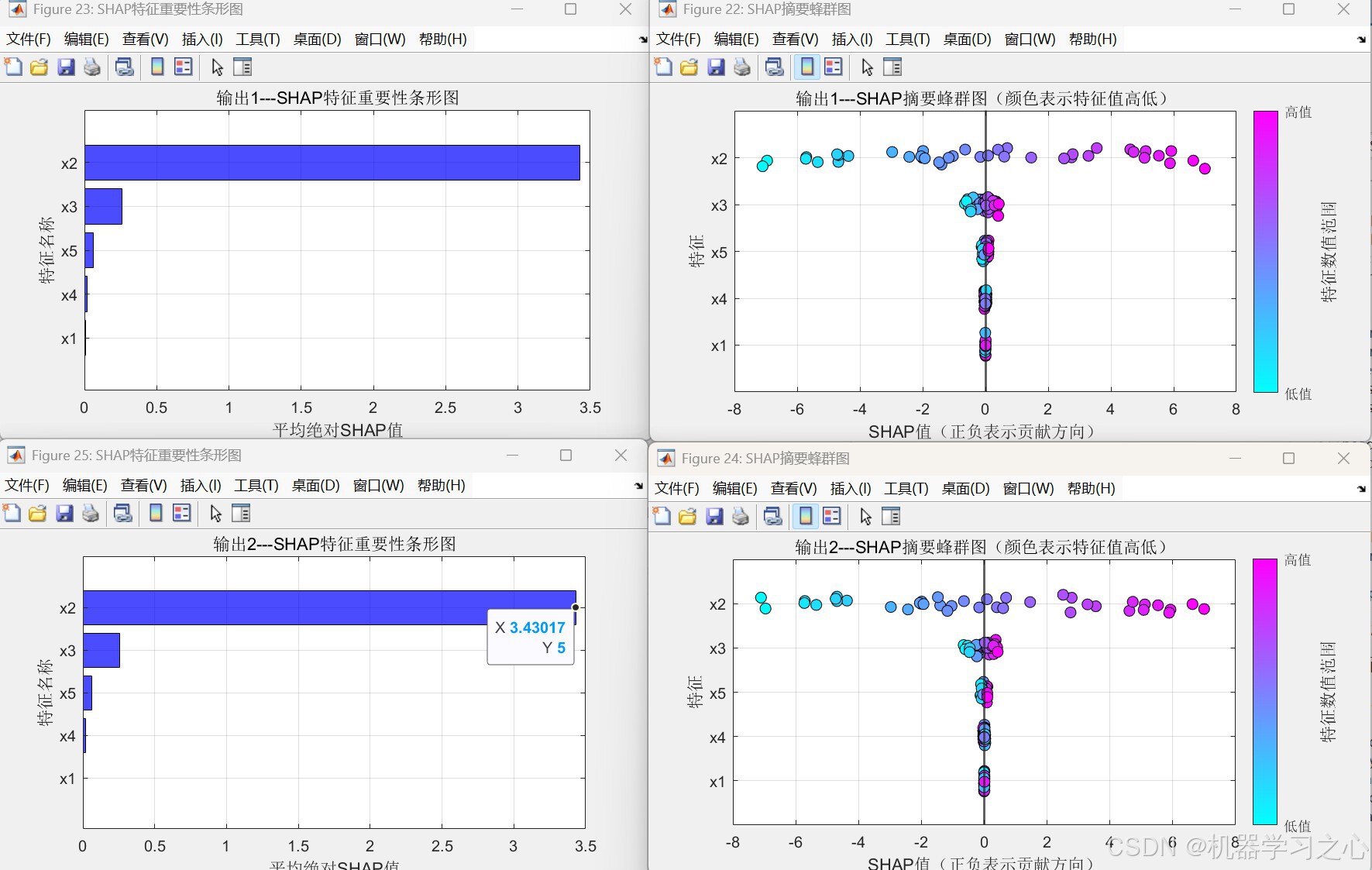
- SHAP分析:计算并可视化输入特征对每个输出的贡献(蜂群图、条形图),增强模型可解释性。
- 新数据预测:支持输入新样本,自动归一化、预测并反归一化输出结果。
3. 算法步骤
-
数据预处理
- 读取
回归数据.xlsx,提取输入X(5维)和输出Y(2维)。 mapminmax归一化到0,1,按比例划分为训练集和测试集,转为cell格式供Transformer使用。
- 读取
-
DBO参数初始化
- 设定种群数
N=10,最大迭代M=10,搜索边界[2,20],维度dim=1。 - 选择混沌映射类型
label=1(Tent映射)生成初始种群。
- 设定种群数
-
适应度函数定义(
fit.m)- 输入:
heads。 - 构建Transformer网络(2个自注意力层,
Channels = heads*4),训练200轮,返回测试集RMSE作为适应度值。
- 输入:
-
DBO迭代寻优
- 生产者更新 :按比例
P_percent=0.2选择生产者,根据随机数采用两种搜索策略(局部扰动或角度偏转)。 - 跟随者/小偷更新:其余个体根据当前最优解和随机扰动更新位置。
- 边界处理,更新个体极值和全局最优解,记录收敛曲线。
- 生产者更新 :按比例
-
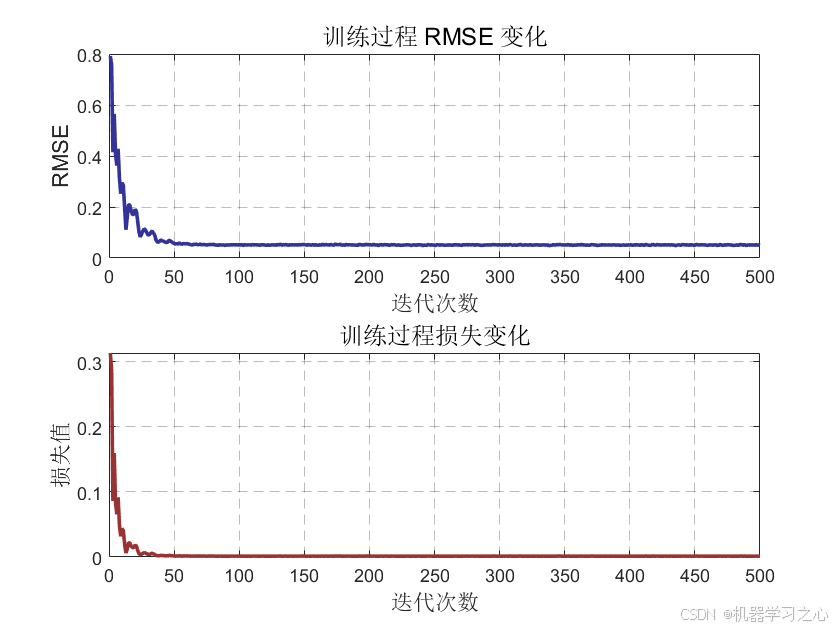
模型重建与评估
- 采用最优
bestheads重新训练Transformer(500轮),预测训练集和测试集。 - 同时运行未优化模型(
yuantrans.m,heads=1),计算各指标并生成对比图表。
- 采用最优
-
SHAP值分析
shapley_function.m遍历特征子集,计算每个样本的Shapley值,绘制蜂群图(特征贡献分布)和条形图(全局重要性)。
-
新数据预测
newpre.m读取新的多输入.xlsx,归一化后预测,反归一化并输出到新的输出.xlsx。
4. 技术路线
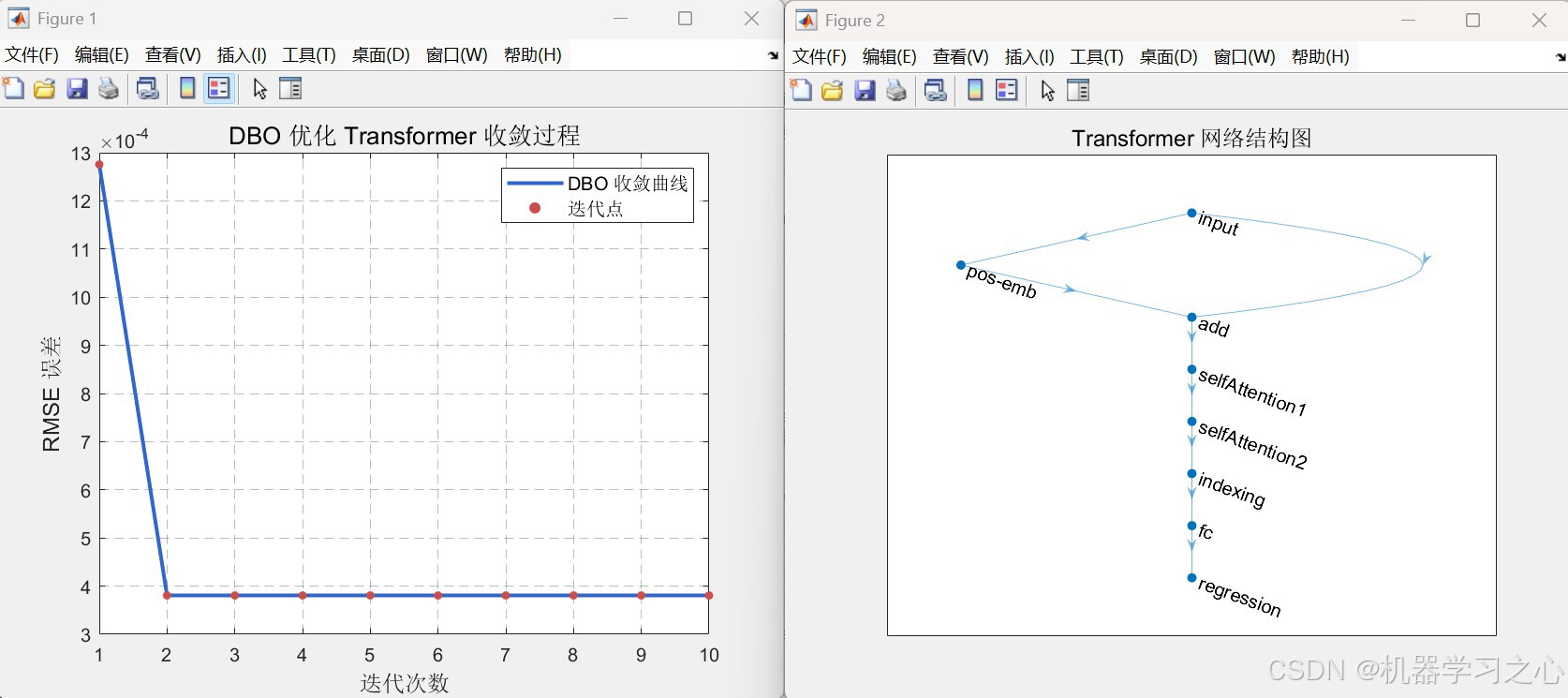
数据加载 → 归一化 → 训练/测试划分 → 混沌映射初始化种群
↓
DBO迭代:种群更新(生产者、小偷)→ 适应度计算(训练Transformer)
↓
获得最优头数 → 训练最终Transformer → 预测反归一化 → 精度指标
↓
对比未优化Transformer → 雷达图/误差图/拟合图
↓
SHAP分析 → 新数据预测(可选)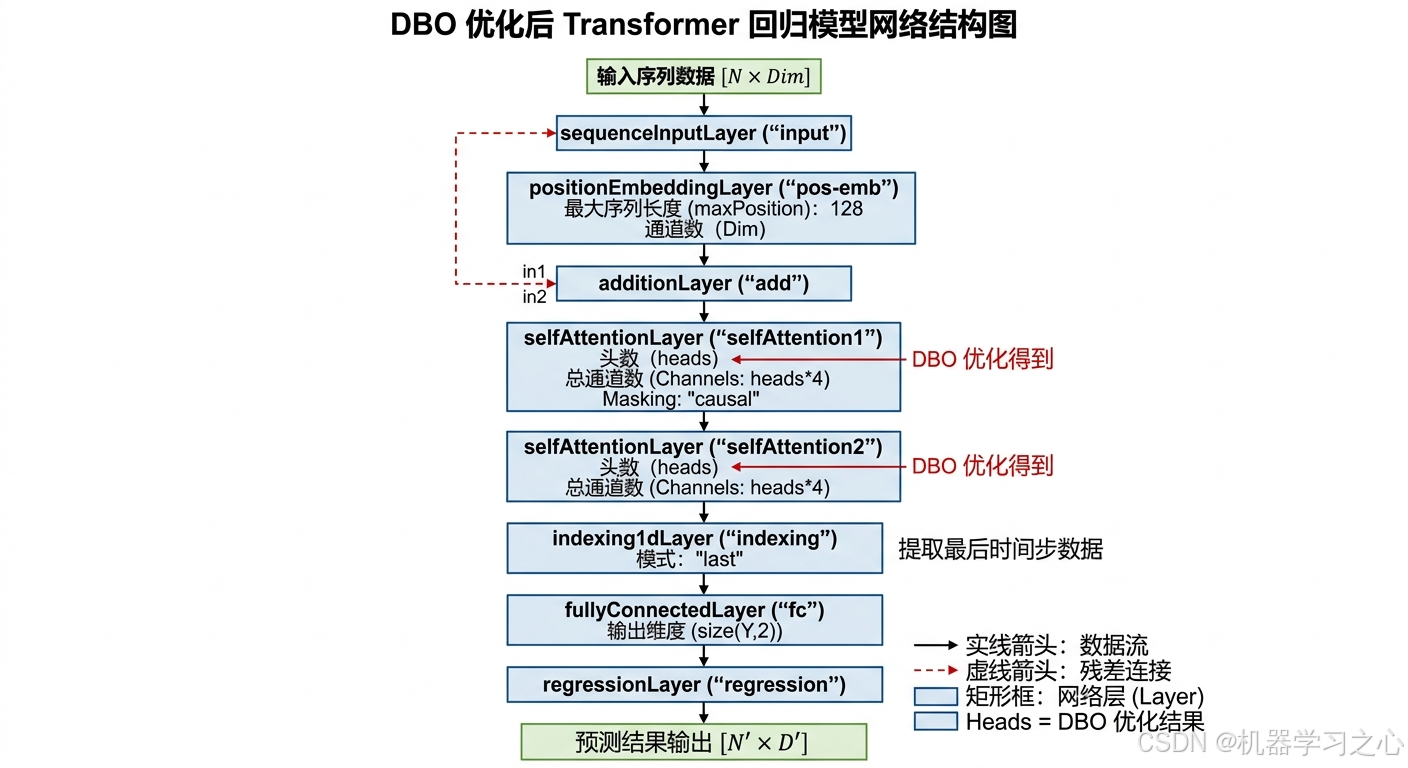
5. 核心公式与原理
-
Tent混沌映射
xn+1={xn/μ,0≤xn<μ(1−xn)/(1−μ),μ≤xn≤1x_{n+1} = \begin{cases} x_n / \mu, & 0 \le x_n < \mu \\ (1-x_n)/(1-\mu), & \mu \le x_n \le 1 \end{cases}xn+1={xn/μ,(1−xn)/(1−μ),0≤xn<μμ≤xn≤1其中 μ=1.2,生成遍历性更好的初始种群。
-
DBO生产者更新(代码中主要策略)
- 策略1(r2<0.9):
X_{new} = X + 0.3\|X - X_{worst}\| + a \\cdot 0.1 \\cdot XX
其中a = \\pm1 ,,,XX为上一代位置。 - 策略2(r2≥0.9):
Xnew=X+tan(θ)⋅∣X−XX∣X_{new} = X + \tan(\theta) \cdot |X - XX|Xnew=X+tan(θ)⋅∣X−XX∣,θ 随机取自 0∼π。
- 策略1(r2<0.9):
-
Transformer前向计算
输入序列 → 位置编码 → 自注意力(因果掩码+普通)→ 取最后时间步 → 全连接层 → 回归输出(MSE损失)。
-
Shapley值
ϕj=∑S⊆F∖{j}∣S∣!(∣F∣−∣S∣−1)!∣F∣!fS∪{j}(xS∪{j})−fS(xS) \phi_j = \sum_{S \subseteq F \setminus \{j\}} \frac{|S|!(|F|-|S|-1)!}{|F|!} f_{S \\cup \\{j\\}}(x_{S \\cup \\{j\\}}) - f_S(x_S) ϕj=S⊆F∖{j}∑∣F∣!∣S∣!(∣F∣−∣S∣−1)!fS∪{j}(xS∪{j})−fS(xS)遍历特征子集,计算特征 ( j ) 的边际贡献加权和。
6. 参数设定
| 模块 | 参数 | 设定值 |
|---|---|---|
| DBO | 种群规模 N | 10 |
| 最大迭代 M | 10 | |
| 生产者比例 P_percent | 0.2 | |
| 混沌映射 label | 1 (Tent) | |
| 搜索空间 | 2, 20 | |
| 优化中Transformer | 最大训练轮数 | 200 |
| 学习率 | 0.01 | |
| 学习率下降因子 | 0.1 (第150轮) | |
| 最终Transformer | 最大训练轮数 | 500 |
| 学习率下降时刻 | 第200轮 | |
| 未优化Transformer | 最大训练轮数 | 100 |
| 学习率下降时刻 | 第50轮 | |
| 头数 heads | 1 |
7. 运行环境
- 软件:MATLAB(R2024b推荐)
- 数据文件 :
回归数据.xlsx、新的多输入.xlsx
8. 应用场景
- 多输入多输出回归预测:如工程系统中的性能参数预测、环境监测、金融时间序列预测等,实例数据为5个输入特征→2个输出目标。
- 超参数敏感的深度学习模型:适用于任何可通过少量超参数(如注意力头数)调节性能的Transformer回归任务,可扩展至其他参数(如学习率、层数)的优化。
- 特征重要性分析需求:借助SHAP值解释各输入变量对输出的影响,辅助领域知识验证与特征筛选。