在当今信息高速流动的数字化时代,了解公众对某一事件或话题的关注热度及其变化趋势,已经成为许多领域的重要基础。无论是企业制定营销策略、政府监测社会舆情,还是学者开展社会科学研究,都需要依赖真实、及时的数据支持。而百度作为中国使用最广泛的搜索引擎和内容平台,其推出的"百度热搜"榜单,正是反映当下公众注意力焦点与社会情绪波动的重要窗口。
百度热搜基于百度海量用户的搜索行为、新闻阅读、资讯流转等数据,通过算法实时计算并呈现当前最受关注的热点话题。与百度指数强调长期关键词趋势不同,百度热搜更侧重于"此时此刻"什么事件正在快速升温、什么话题引发了广泛讨论。例如,我们可以通过热搜榜观察"神舟十九号发射""某地突发天气预警"或"热门电视剧大结局"等话题的瞬时热度,进而快速把握社会脉搏。
本项目利用 Python 及其强大的网络请求库(如 requests),实现对百度热搜数据的自动抓取。针对数据加密、动态加载内容以及网站反爬策略等关键问题进行深入分析与应对。
一、百度热搜是什么?
首先,我们需要了解百度热搜的数据从哪里来。
百度热搜的数据源于百度搜索平台和百度资讯流:用户输入关键词搜索、点击新闻、浏览信息流内容,这些行为都会被百度记录下来,并通过算法计算每条话题的综合热度,最终形成实时更新的热搜榜单。与百度指数反映长期搜索趋势不同,百度热搜更强调"即时性"和"爆发性",它反映了网民当前最关心的公共事件、娱乐八卦、社会新闻等话题。
官方介绍,百度热搜是百度基于全网网民的主动行为(搜索、浏览、分享)与热点内容流转情况,实时推出的热点排行榜。
百度热搜:百度热搜

我们第一步先找到门店数据的存储位置,然后看3个关键部分标头、负载、 预览;
标头:通常包括URL的连接,也就是目标资源的位置;
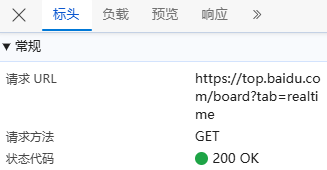
负载:对于GET请求:负载通常包含了传递的参数,有些网页负载可能为空,或者没有负载,因为所有参数都通过URL传递,这里我们可以看到关键词,查询日期,还是明文,没有进行加密;
预览:指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段,结合响应我们可以知道,百度热搜是把整个内容集成在HTML中;

接下来就是数据获取部分,先讲一下方法思路,一共三个步骤;
方法思路
- 找到对应热搜指数数据存储位置并保存到本地csv;
- 我们通过get请求来查询所有榜单数据;
- 把热搜指数数据增加定时获取功能;
因为是get请求,我们可以不带表头进行请求,同时根据具体的热度和标题字段获取具体数值,另外简单的获取还不够,我们还需要关注热搜在时间轴上的动态变化,这里我们设置15分钟进行一次抓取,有需要的可以进行调整;
完整代码#运行环境 Python 3.11
python
import requests
import re
import json
import csv
import time
from datetime import datetime
def fetch_baidu_hot():
"""抓取百度热搜,返回数据行列表"""
url = "https://top.baidu.com/board?tab=realtime"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
}
try:
response = requests.get(url, headers=headers, timeout=10)
response.encoding = "utf-8"
html_content = response.text
# 提取 s-data 中的 JSON 数据
json_match = re.search(r'<!--s-data:({.*?})-->', html_content, re.DOTALL)
if not json_match:
print(f"[{datetime.now()}] 未找到 JSON 数据")
return []
json_str = json_match.group(1)
hot_data = json.loads(json_str)
cards = hot_data.get('data', {}).get('cards', [])
if not cards:
print(f"[{datetime.now()}] 未找到热搜卡片")
return []
# 提取普通热搜和置顶热搜
hot_list = cards[0].get('content', [])
top_list = cards[0].get('topContent', [])
rows = []
timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
# 置顶热搜(排名写字符串 "置顶")
for item in top_list:
rows.append({
'rank': "置顶",
'title': item.get('query', ''),
'hot_score': item.get('hotScore', ''),
'hot_change': item.get('hotChange', ''),
'description': item.get('desc', ''),
'timestamp': timestamp
})
# 普通热搜(排名从1开始编号)
for idx, item in enumerate(hot_list, start=1):
rows.append({
'rank': idx, # 整数
'title': item.get('query', ''),
'hot_score': item.get('hotScore', ''),
'hot_change': item.get('hotChange', ''),
'description': item.get('desc', ''),
'timestamp': timestamp
})
print(f"[{timestamp}] 抓取成功,共 {len(rows)} 条热搜(置顶 {len(top_list)} 条,普通 {len(hot_list)} 条)")
return rows
except Exception as e:
print(f"[{datetime.now()}] 抓取失败:{e}")
return []
def append_to_csv(rows, filename='baidu_hot_history.csv'):
"""追加数据到CSV文件,如果文件不存在则写入表头"""
if not rows:
return
file_exists = False
try:
with open(filename, 'r', encoding='utf-8-sig'):
file_exists = True
except FileNotFoundError:
file_exists = False
with open(filename, 'a', newline='', encoding='utf-8-sig') as f:
fieldnames = ['rank', 'title', 'hot_score', 'hot_change', 'description', 'timestamp']
writer = csv.DictWriter(f, fieldnames=fieldnames)
if not file_exists:
writer.writeheader()
writer.writerows(rows)
def main():
"""主循环:每15分钟抓取一次"""
print("百度热搜定时抓取启动,每15分钟抓取一次...")
while True:
rows = fetch_baidu_hot()
if rows:
append_to_csv(rows)
print(f"已追加 {len(rows)} 条记录到 baidu_hot_history.csv")
else:
print("本次抓取无数据,跳过写入")
print("等待15分钟后进行下一次抓取...")
time.sleep(15 * 60)
if __name__ == "__main__":
main()脚本运行结束,会在脚本运行对应文件夹下,生成一个baidu_hot_history.csv的文件;
获取数据标签如下:排名(rank)、title(标题)、hot_score(热搜指数)、hot_change(热搜变化)、description(热搜描述)、timestamp(获取时间戳);
**这里有一个tips:**现在这里的 time.sleep(15 * 60),也就是15分钟的获取频率,可以根据需求调整,虽然是get请求,但是也不建议太频繁的请求频率;
接下来,我们进行看图说话:
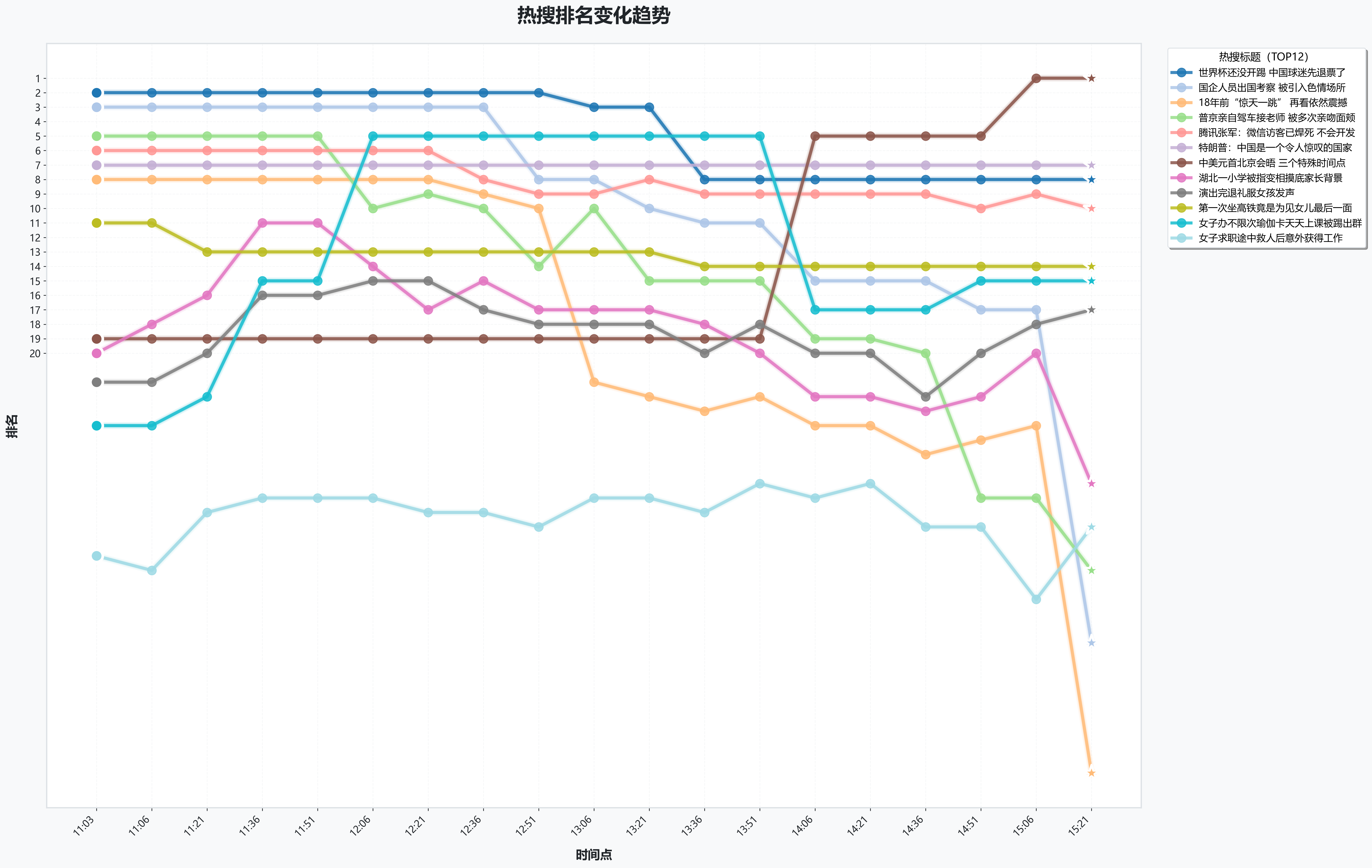
上层热搜(排名1---8位)整体稳定性较高。"某热门综艺决赛夜争议"与"一线城市楼市新政出台"长期占据前两位,表现出较强的持续关注度。
中层热搜(排名9---15位)波动相对频繁。"十年前经典影视剧翻红"从靠前位置逐步下滑至末位,而"某科技巨头发布新款手机"则从较后位置跃升至榜首,显示出重大商业事件所具备的突发冲击力。
下层热搜(排名16位以后)变化最为剧烈,多条曲线出现大幅升降,反映出长尾话题更替速度较快的特点。
午后时段是排名变化的关键转折点。此前,多数热搜排名相对平稳,曲线呈水平或缓坡状态;此后,多条曲线出现明显拐点------"某科技巨头发布新款手机"从后排急速攀升至前列,"健身博主因教程争议道歉"也从相对靠后位置跃升至中位,表明午后信息发布频率增加,用户关注度发生显著转移。
临近傍晚时,变化尤为剧烈:"十年前经典影视剧翻红"从较后位置骤降至末位,"素人因街头采访走红"则从中位快速上升至更靠前的位置,凸显出日间与傍晚交界前后热点话题的快速迭代特征。
从生命周期来看,热搜话题可分为三类:
一是"常青型 ",如"某热门综艺决赛夜争议"全程稳居前三,持续时间超过数小时;
二是"波动型 ",如"知名歌手演唱会意外中断"从较前位置波动下降至中后段,呈现缓慢衰退趋势;
三是"突发型",如"某科技巨头发布新款手机"在监测后期突然闯入前列,属于典型的突发性热点。
整体而言,约四成的热搜在监测时段内保持稳定排名,三成呈现缓慢下滑,另有三成出现明显波动或突发性变化。这反映出百度热搜平台既存在持续关注的存量话题,也有不断涌入的增量热点,形成了动态平衡的内容生态。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。