本文将为你详细介绍如何用Radeon游戏卡打造AI工作站。AMD的ROCm平台让游戏卡真正具备了跑AI工作负载的能力,是NVIDIA CUDA生态之外一个强劲的选择。---
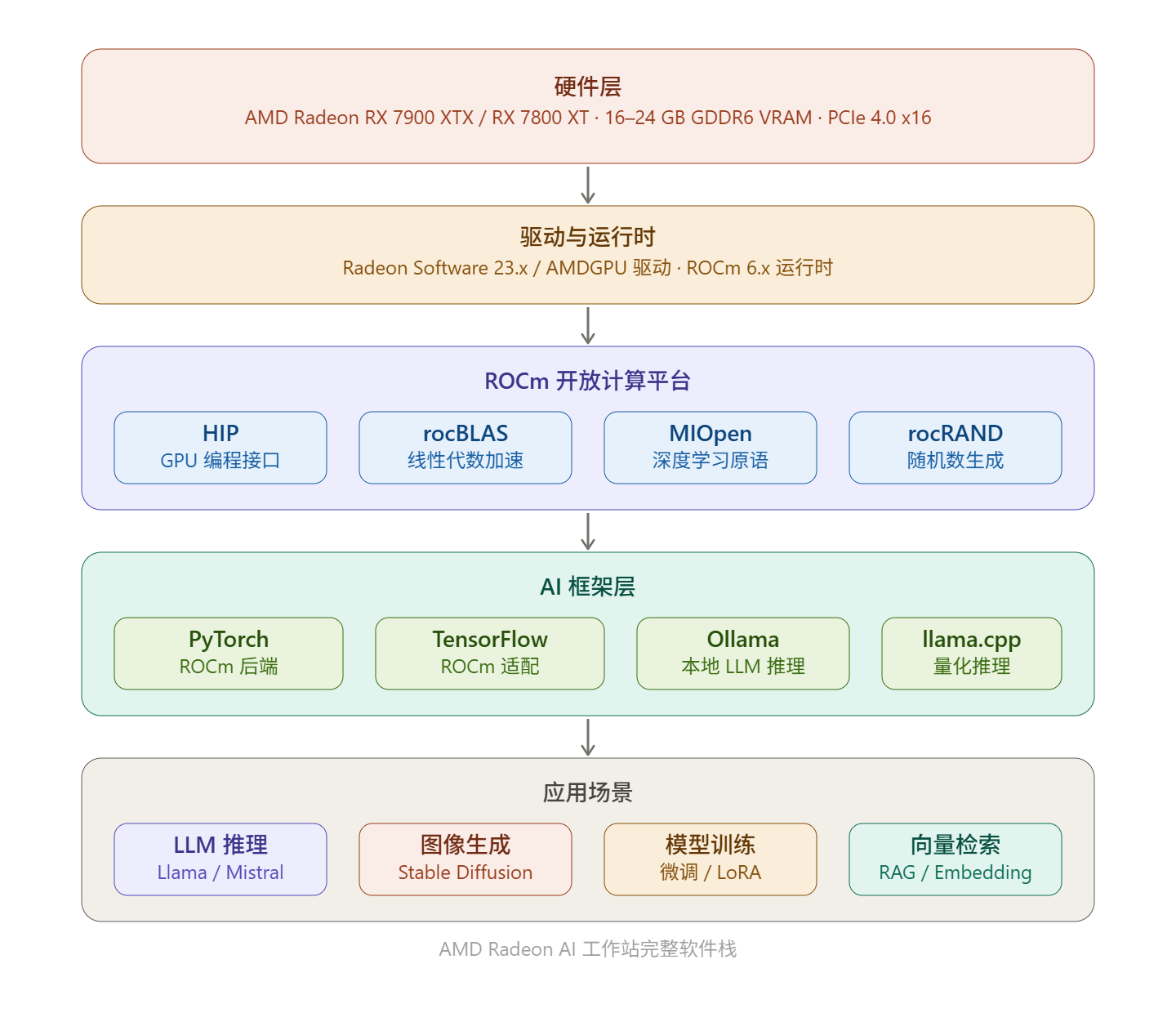
一、选卡策略:哪款 Radeon 最适合 AI?
主力推荐:RX 7900 XTX(24 GB VRAM)
这张卡是目前性价比最高的 Radeon AI 工作站首选。24 GB GDDR6 显存意味着你可以不量化地跑 13B 参数模型,量化后可以跑 70B。与同价位的 NVIDIA 方案相比,显存容量领先一代。
次选:RX 7900 XT(20 GB)/ RX 7800 XT(16 GB)
如果预算有限,16 GB VRAM 足以运行 7B 模型不量化、13B 模型 4-bit 量化,日常推理绰绰有余。
关键指标对比
| 型号 | VRAM | 内存带宽 | AI 计算力 (FP16) | 适合场景 |
|---|---|---|---|---|
| RX 7900 XTX | 24 GB | 960 GB/s | 123 TFLOPS | 70B 量化推理、LoRA 微调 |
| RX 7900 XT | 20 GB | 800 GB/s | 103 TFLOPS | 13B 全精度、图像生成 |
| RX 7800 XT | 16 GB | 624 GB/s | 70 TFLOPS | 7B 推理、Stable Diffusion |
二、操作系统与 ROCm 安装
AMD 的 ROCm(Radeon Open Compute)是整个 AI 工作站的核心,相当于 NVIDIA 的 CUDA 生态。
推荐系统:Ubuntu 22.04 LTS(ROCm 官方最稳定支持)
bash
# 1. 添加 ROCm 仓库
wget https://repo.radeon.com/amdgpu-install/6.1/ubuntu/jammy/amdgpu-install_6.1.60101-1_all.deb
sudo dpkg -i amdgpu-install_6.1.60101-1_all.deb
# 2. 安装 ROCm 完整栈
sudo amdgpu-install --usecase=rocm,hip,mlsdk
# 3. 加入 render 用户组(必须)
sudo usermod -aG render,video $LOGNAME
# 4. 验证安装
rocminfo | grep -i "gfx"三、安装 AI 推理环境
方案 A:Ollama(最简单,强烈推荐新手)
bash
curl -fsSL https://ollama.com/install.sh | sh
# 拉取并运行 Llama 3.1 70B(量化版)
ollama run llama3.1:70b
# 查看显存占用
rocm-smiOllama 会自动检测 ROCm 环境并使用 GPU 加速,零配置。
方案 B:PyTorch + ROCm(开发者必选)
bash
# 安装 ROCm 版 PyTorch(以 ROCm 6.1 为例)
pip install torch torchvision torchaudio \
--index-url https://download.pytorch.org/whl/rocm6.1
# 验证 GPU 可用
python3 -c "import torch; print(torch.cuda.is_available())"
# 输出 True 即成功(ROCm 兼容 CUDA API)方案 C:Stable Diffusion(图像生成)
bash
# 使用 AUTOMATIC1111 WebUI,指定 ROCm
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
cd stable-diffusion-webui
# 启动时设置 HSA 显存分配(关键!)
HSA_OVERRIDE_GFX_VERSION=11.0.0 python launch.py \
--precision full --no-half四、关键调优技巧
这是区分"能跑"和"跑得好"的核心知识。
1. 解锁全部 VRAM 给 AI 进程
bash
# 关闭图形界面,释放显存给 AI 任务
sudo systemctl isolate multi-user.target
# 检查可用显存
rocm-smi --showmeminfo vram2. 设置 HSA_OVERRIDE_GFX_VERSION
许多 AI 工具的 ROCm 支持列表不包含最新显卡,这个环境变量可以强制兼容:
bash
# 对于 RDNA3 架构(RX 7000 系列)
export HSA_OVERRIDE_GFX_VERSION=11.0.0
# 写入 ~/.bashrc 永久生效
echo 'export HSA_OVERRIDE_GFX_VERSION=11.0.0' >> ~/.bashrc3. llama.cpp 高性能推理
bash
# 编译 ROCm 版 llama.cpp
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make GGML_HIPBLAS=1
# 运行(-ngl 参数控制 GPU 卸载层数)
./llama-cli -m llama-3.1-70b-Q4_K_M.gguf \
-n 512 --n-gpu-layers 80 --ctx-size 40964. 多卡配置(双卡 7900 XTX = 48 GB VRAM)
bash
# 指定使用哪块卡
export ROCR_VISIBLE_DEVICES=0,1
# PyTorch 多卡推理
python -c "
import torch
print('GPU count:', torch.cuda.device_count())
"五、典型工作流推荐
| 目标 | 工具链 | 显存需求 |
|---|---|---|
| 本地 LLM 对话助手 | Ollama + Open WebUI | ≥ 8 GB |
| 图像生成工作室 | ComfyUI + SDXL | ≥ 12 GB |
| 代码补全服务 | Tabby / Continue + Codestral | ≥ 8 GB |
| 模型 LoRA 微调 | Axolotl + PyTorch ROCm | ≥ 16 GB |
| RAG 知识库 | LangChain + Chroma + Ollama | ≥ 8 GB |
六、ROCm vs CUDA:坦诚的评估
ROCm 已经非常成熟,但有几点需要了解:
优势:更大显存(同价位)、开源生态、无需 CUDA 许可、Ollama/llama.cpp/ComfyUI 均有良好支持。
局限 :部分模型库(如 Flash Attention 2)的 ROCm 移植比 CUDA 版本稍慢;TensorFlow 的 ROCm 支持不如 PyTorch 完善;Windows 下 ROCm 支持有限,强烈建议用 Linux。
整体来看,用 RX 7900 XTX 做推理工作站,今天已经完全可以投入生产使用。