目录
[1. 二叉搜索树(及变种:AVL、红黑树)](#1. 二叉搜索树(及变种:AVL、红黑树))
[2. 哈希表](#2. 哈希表)
[3. B树(N叉搜索树)](#3. B树(N叉搜索树))
[4. B+树(索引的核心数据结构)](#4. B+树(索引的核心数据结构))
[B+树 vs B树:优势在哪里?](#B+树 vs B树:优势在哪里?)
开篇:索引是什么?为什么需要它?
索引相当于书的目录 ,核心作用是加快查询速度。但索引并非"免费午餐",它有代价:
-
消耗额外存储空间;
-
可能拖慢增删改速度(因为删除/修改常搭配
where条件,若where能走索引查询,索引维护会有开销)。
通常索引利大于弊 :存储成本(硬盘便宜)不是核心矛盾;实际开发中读频率远高于写频率(比如"作业表"场景:同学查看作业是读操作,写入记录是写操作,读远多于写)。
候选数据结构:为什么选B+树?
索引需要高效的数据结构,我们逐一分析常见结构:
1. 二叉搜索树(及变种:AVL、红黑树)
-
二叉搜索树:查找时间复杂度平均O(logN) ,但最坏O(N)(退化成链表)。
-
AVL树:要求严格平衡(任何节点左右子树高度差≤1),查询快,但插入/删除需频繁调整树结构,开销大。
-
红黑树:做了权衡,不要求严格平衡,把查询稍慢一点(几乎感知不到),换取插入/删除效率提升。
但二叉搜索树(包括AVL、红黑树)作为索引的问题:树高过高(元素多时),IO访问次数多(数据库从硬盘读数据,IO是瓶颈)。
2. 哈希表
哈希表查找时间复杂度O(1),但缺陷明显:
-
仅支持相等条件查询 (如
=),不支持范围查询(< >)、模糊匹配; -
hash函数将key转为数组下标,无法利用数据的"有序性"。
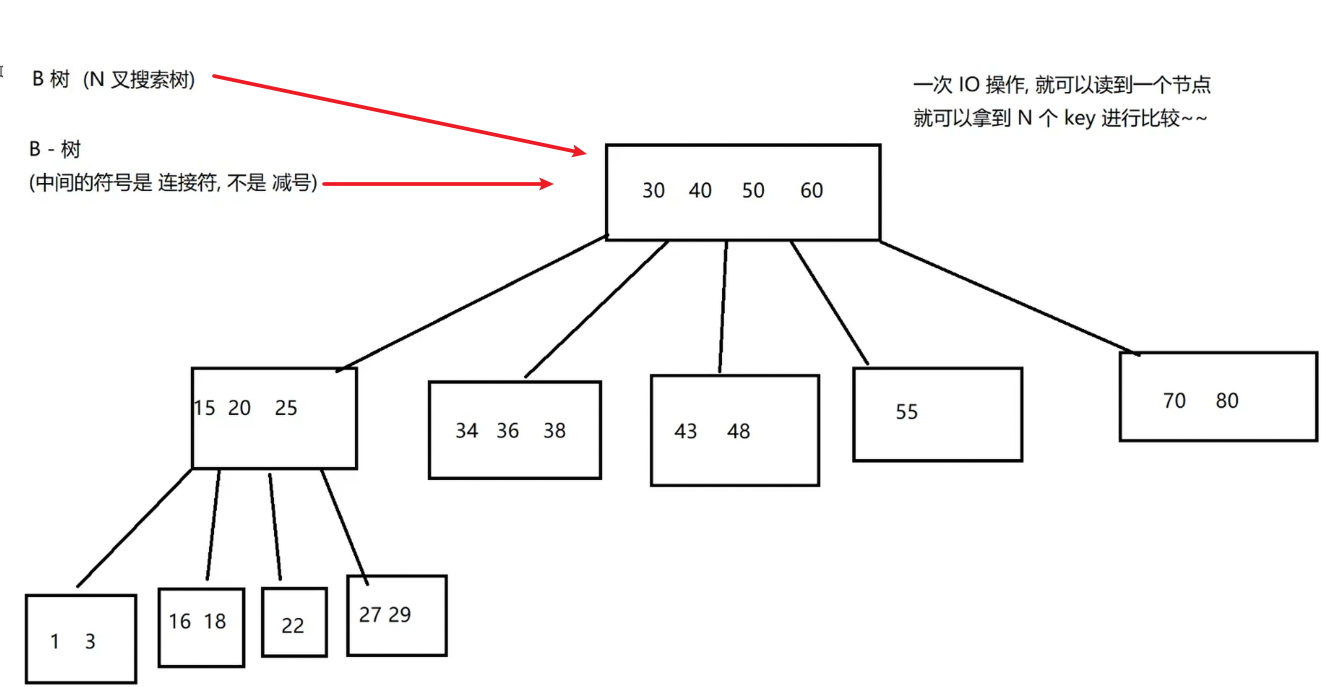
3. B树(N叉搜索树)
B树是多叉搜索树,改进了二叉树的树高问题:
-
每个节点存
N个值,划分N+1个区间; -
一次IO操作可读取一个节点,拿到
N个key比较,减少IO次数。
但B树仍有不足,于是有了B+树(索引的专属数据结构)。
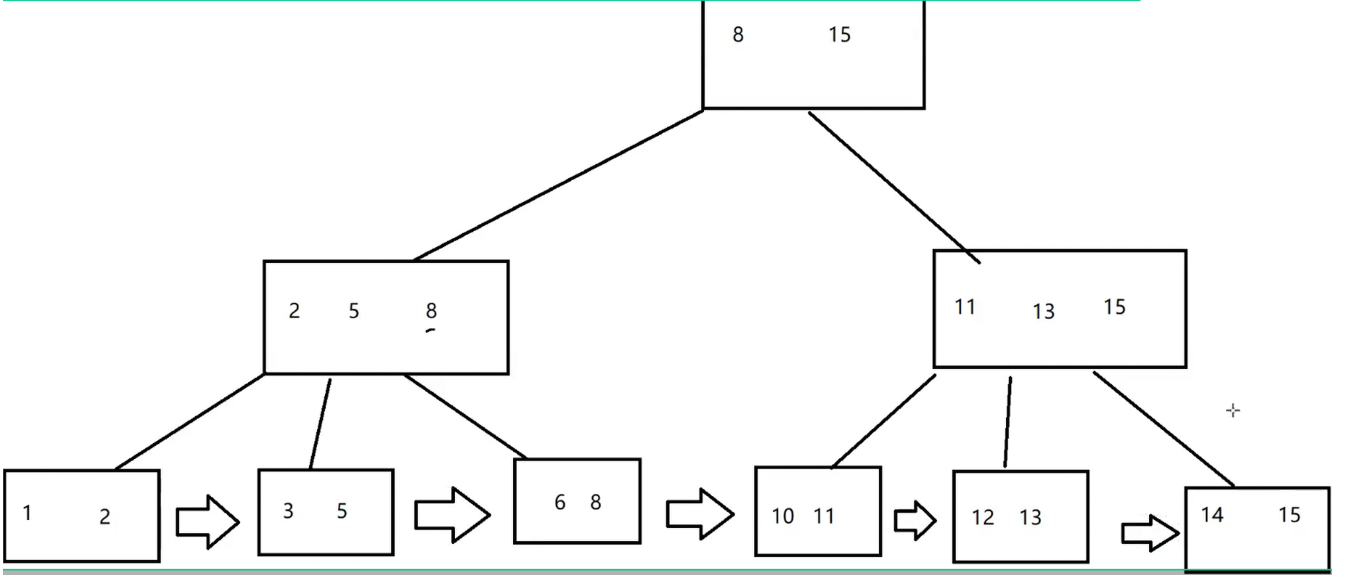
4. B+树(索引的核心数据结构)
B+树是B树的改进版,也是N叉搜索树,核心特点:
-
每个节点存
N个值,划分N个区间,其中的最后一个元素表示当前子树的最大值; -
叶子节点是数据全集 ,并通过双向链表串起来(方便范围查询);
-
非叶子节点只存索引key(子节点位置),叶子节点存完整数据行;
-
所有数据都在叶子节点,查询必须到叶子,开销稳定(比较次数相当);
-
N叉树高度更低(比红黑树更矮),IO次数更少。
B+树 vs B树:优势在哪里?
-
范围查询 :B+树叶子节点用双向链表连接,范围查询(如
between)只需遍历链表;B树范围查询需中序遍历,效率低。 -
空间利用:非叶子节点只存key,不存数据,更省内存,适合缓存。
-
查询稳定:每次查询都到叶子,中间比较次数相当,开销稳定。
-
树高更低:N叉结构让树高更矮,IO次数更少。
MySQL中的"页(page)":索引的物理载体
MySQL中,"页"是B+树上的节点:
-
数据页 :叶子节点,存储若干数据行(如学生表的
id, name, gender, age); -
索引页 :非叶子节点,只存
key和子节点位置(也是"页")。
数据库以页为单位从硬盘读取 ,利用局部性原理(程序访问某位置数据后,大概率访问附近数据),减少IO次数。
高频面试题回顾
面试中常问:
-
什么是索引?
-
索引使用的什么数据结构?(答:B+树,及对比AVL、红黑树、哈希表、B树的优劣)
总结
索引的本质是用空间换时间 ,核心数据结构是B+树(兼顾查询、插入删除、范围查询、IO效率)。理解B+树的结构(多叉、叶子链表、非叶子存key),以及MySQL"页"的设计,就能掌握索引底层逻辑。