说明:本文主要围绕基于 Spring Cloud 的博客系统项目开发过程中所涉及的技术内容展开,重点介绍系统开发中所使用的核心技术及其与实际业务场景的结合方式,对具体业务功能本身的描述相对较少。
目录
[一 系统设计](#一 系统设计)
[二 微服务拆分](#二 微服务拆分)
[三 业务模块](#三 业务模块)
[四 服务部署](#四 服务部署)
一 系统设计
1.服务拆分原则
(1)单一职责原则
一个微服务只负责一个功能或一个模块
(2)服务自治原则
服务之间的影响尽可能少,一个服务尽量不影响另一个服务
(3)单向依赖原则
微服务之间要做到单向依赖,严禁双向依赖,循环依赖
当无法避免双向依赖时,要用消息队列实现
二 微服务拆分
注:拆分没有标准,需要考虑维护成本,系统的可扩展性,软件的发布频率等,最重要的根据业务场景和团队的规划
1.拆分方案
(1)纵向拆分:
从业务维度来进行拆分,关系比较密切的拆分成一个微服务,关系比较远单独拆分成一个微服务
(2)横向拆分:
从公共且独立功能的维度来进行拆分,按照是否有公共地被多个服务调用,且依赖的资源独立不与其他服务耦合
注:企业中经常是纵向和横向结合
(3)基于稳定性分类:
把经常改动的分为一类,不经常改动的分为一类(比如日志服务监控服务一些基础架构)
这样不常改动的就不需要跟着一起重新部署,减少风险
(4)基于可靠性拆分:
可靠性高的核心模块放一块,可靠性不高的非核心模块放一块
(5)基于高性能拆分:
将性能要求比较高的单独拆分成一个服务,性能要求不高的可以放一起
注:拆分有多种方案,具体怎么拆分需要结合业务场景,遵循合适优于业界领先,避免过度设计
2.当前系统的架构和技术选型
(1)架构
①网关服务网关层)
②业务模块--博客服务/用户服务(服务层)
③公共SDK
(2)技术选型
①不同服务之间的调用传参使用fastjackson
②不同服务之间的调用使用OpenFeign,同时调用需要服务发现用Nacos
③测试使用Junit
④此处也对前端进行部署使用Ngnix
⑤为了提高速度,使用Redis缓存来提高查询效率(用户登录)
⑥涉及到发邮件,此处可使用rabbitmq来进行异步处理
3.工程搭建
本项目使用父子工程的方式进行搭建,统一管理
(1)本次项目共四个model
blog-common:公共的SDK,作为jar给其他项目进行使用,不需要部署,没有启动类
blog-info:博客服务,其下面再分两个model:blog-info-service和blog-info-api
user-info:用户服务,下面再分为两个model:user-info-service和user-info-api
(2)api包里需要加统一路径可以直接在每个路径都写或者@FeignCilent(value="blog-service",path="/blog")里写
(3)数据库的处理:
由原本的单库多表,变为多库多表,给每一个服务都单独建一个表
(4)关于统一结果返回处理:
不可再用,需要手动自己写统一结果返回
因为统一结果返回的HTTP传输的时候会封装一层
而Feign远程调用的时候也是用HTTP的方式,因此此时就会对其进行封装,因此其远程调用实际接收到的参数是Result<T>,即已经进行包装过的了,而Api接口里写得还是T,此时就无法正确接收,因此要把统一结果返回的advice去掉,直接在方法定义那个地方写Result<T>
三 业务模块
1.用户认证过滤
方式:定义全局过滤器--实现GlobalFilter,Ordered
给order返回一个很小的数,类似于-200,值越小,优先级越高
步骤:
1.设置通行白名单
2.进入方法后,获取当前路径判断是否在路径内
获取当前路径的方法
java
ServerHttpRequest request=exchange.getRequest();
String path=request.getURI().getPath();获取的话直接放行
java
if(whiteNames.contains(path)){
//继续执行核心逻辑
return chains.filter(exchange);
}3.如果不包含,则从Header里获取到对应的token,若获取不到,则拦截,若验证不出,也进行拦截
从请求里获取Header:
java
ServerHttpRequest request=exchange.getRequest();
String token=request.getHeader().getFirst("user_token");
java
//拦截对应返回的内容
//关键是处理响应
private Mono<Void> unauthorized(ServerWebExchange exchange,String errMsg){
log.error("用户认证失败,url={}",exchange.getRequest().getURI().getPath());
ServerHttpResponse response=exchange.getResponse();
response.setStatusCode(HttpStatus.UNAUTHORIZED()):
response.getHeaders.add(HttpHeaders.CONTENT_TYPE,MediaType.APPLICATION_JSON_VALUE);
//写入响应
Result result=Result.error(errMsg);
DataBuffer dataBuffer=response.bufferFactory()
.wrap(objectMapper.writeValueAsBytes(result))
response.writeWith(Mono.just(dataBuffer));
}4.若能正常获取并验证,则放行执行核心逻辑
测试逻辑:
1.白名单路径
2.非白名单路径
①无token/token非法
②有token
2.Nacos配置mysql数据源
(1)当前配置的白名单问题
目前白名单的配置是写死在程序里的,后面需求变更了,比如查看博客详情不需要登录也可以的时候,就又得改代码,重新打包部署上去,会很麻烦
因此此处我们可以利用Nacos提供的配置管理来进行解决
(2)问题:当前配置的信息存储在nacos根目录下的data目录下的derby-data目录下
在生产环境中,为了保证高性能和数据的持久化,我们使用关系型数据库(例如mysql)来作为Nacos的数据源
优点:
①数据持久化:配置信息不会因为Nacos重启等就消失
②高性能
③高可扩展性
④高可用性
⑤易于维护
(3)安装:
①确认nacos版本为2.2.3
②确认已安装mysql
③如果是别的数据库,则需要安装插件
④修改config/application.properties文件,进行对应配置
java
spring.datasource.platform=mysql
db.num=1
db.url.0=jdbc:mysql://你的数据库地址:端⼝/nacos?
characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=tru
e
db.user=你的数据库⽤⼾名
db.password=你的数据库密码⑤初始化数据库
建库
sql
create database if not exists nacos_config charset utf8mb4;执行数据库脚本
sql
SOURCE /nacos/conf/mysql-schema.sql;注:要如果nacos前面有目录的需要放完整路径
⑥重启nacos服务
3.从Nacos读取配置
(1)前提
Nacos配置mysql数据源已经配置好了,此时就可以进行配置白名单
(2)在Nacos里对应进行配置对应的白名单
(3)读取配置
示例:
java
package com.zhku.gateway.properties;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.cloud.context.config.annotation.RefreshScope;
import org.springframework.context.annotation.Configuration;
import java.util.List;
/**
* Created with IntelliJ IDEA.
* Description:
* User: 12290
* Date: 2026-05-12
* Time: 22:29
*/
@Data
@Configuration
@RefreshScope
@ConfigurationProperties("auth.white")
public class AuthWhiteNames {
private List<String> url;
}4.用户注册
(1)controller:
定义Request类
对其进行非空校验和不为空校验
以及要对其输入进行长度限制,以免插入到数据库时发生错误
(2)service层:
①对一些特殊的字段也需要对其进行校验
比如:用户名不能重复,密码格式,url格式,邮箱格式
②插入数据
(3)mapper层;
注:由于insert是直接使用的MyBatis-Plus的方法,因此要获取自增id需要加上
TableId(value="id",type=IdType.AUTO)
才能自动新增主键值
5.邮箱校验
正则表达式规则:
?:前面元素可选 0-1次
*:前面元素出现0-n次
+:前面的元素出现1-n次
^:正则表达式开始
$:正则表达式结束
{}:限制出现的次数
校验示例代码:
java
package com.zhku.common.utils;
/**
* Created with IntelliJ IDEA.
* Description:
* User: 12290
* Date: 2026-05-13
* Time: 21:10
*/
import org.springframework.util.StringUtils;
import java.util.regex.Pattern;
public class RegexUtil {
/**
* 匹配 邮箱:xxx@xx.xxx(形如:abc@qq.com)
* ^ 表示匹配字符串的开始。
* [a-z0-9]+ 表示匹配一个或多个小写字母或数字。
* ([._\\-]*[a-z0-9])* 表示匹配零次或多次下述模式:一个点、下划线、反斜杠或短横线,后面跟着一个或多个小写字母或数字。这部分是可选的,并且可以重复出现。
* @ 字符字面量,表示电子邮件地址中必须包含的"@"符号。
* ([a-z0-9]+[-a-z0-9]*[a-z0-9]+.) 表示匹配一个或多个小写字母或数字,后面可以跟着零个或多个短横线或小写字母和数字,然后是一个小写字母或数字,最后是一个点。这是匹配域名的一部分。
* {1,63} 表示前面的模式重复1到63次,这是对顶级域名长度的限制。
* [a-z0-9]+ 表示匹配一个或多个小写字母或数字,这是顶级域名的开始部分。
* $ 表示匹配字符串的结束。
*/
private static final String emailRegex = "^[a-z0-9]+([._\\\\-]*[a-z0-9])*@([a-z0-9]+[-a-z0-9]*[a-z0-9]+.){1,63}[a-z0-9]+$";
/**
* 进行简单校验, 为URL即可
* https://gitee.com/bubble-fish666/
* ^:匹配字符串的开始。
* (https?):匹配http或https。
* :\/\/:匹配://。
* ([a-zA-Z0-9.-]+):匹配域名,可以包含字母、数字、点和破折号。
* (:\d+)?:可选部分,匹配冒号和端口号。
* (\/[^\s]*)?:可选部分,匹配斜杠和路径,路径中不包含空白字符。
* (\?[^\s]*)?:可选部分,匹配查询参数,参数中不包含空白字符。
* $:匹配字符串的结束。
*/
private static final String urlRegex = "^(https?):\\/\\/([a-zA-Z0-9.-]+)(:\\d+)?(\\/[^\\s]*)?(\\?[^\\s]*)?$";
/**
* 邮箱:xxx@xx.xxx(形如:abc@qq.com)
*
* @param content
* @return
*/
public static boolean checkMail(String content) {
if (!StringUtils.hasText(content)) {
return false;
}
return Pattern.matches(emailRegex, content);
}
public static boolean checkURL(String content) {
if (!StringUtils.hasText(content)) {
return false;
}
return Pattern.matches(urlRegex, content);
}
public static void main(String[] args) {
System.out.println(checkMail("bite@126.com"));
}
}6.Redis
注:是否使用Redis要结合业务来进行考虑,因为任何技术的引入都是伴随着维护成本的,它提高查询速度的同时也需要在新增,删除,修改的时候进行维护
(1)介绍
适用于流量大的情况,可以减少数据库的压力,降低后端数据源的压力,提高访问的速度
Redis使用快照和日志的形式存储在硬盘上,即使断电也不会丢失
由于存储在内存上,所以迟早会有一天会内存爆满,所以Redis还提供了键值过期时间和内存溢出后的淘汰策略(即使你自己本身不设置也可能因为长期未使用而被删除)
(2)使用场景
①排行榜
②计数器:需要经常对数进行操作,如果频繁访问数据库压力会很大,Redis天然支持计数功能并且性能很好
③社交网络
比如赞,踩,关注数,粉丝数
④消息队列系统
(3)Redis的命令操作
①
安装:
java
apt install redis -y其他命令
java
#查看Redis状态
systemctl status redis-server
#启动redis
service redis-server start
#停⽌redis服务
service redis-server stop
#重启redis服务
service redis-server restart②进入到Redis的客户端
java
redis-cli常见命令:
set key value
get key
del key
exists key
set key value ex time:设置过期时间,需要写毫秒
ttl key:查看距离过期还剩的时间
expire key time:通过expire设置过期时间
keys *:查看当前有哪些key
注:这个命令在集群环境要慎用,后果相当于在mysql里使用了*,在集群环境下数据量是非常大的,使用这个命令会非常地慢,非常地卡顿
官方文档:https://redis.io/docs/latest/commands/set//
模式介绍:
?:0-1个
*:0-n个
^:排除
ae:只ae
(4)Redis集成SpringBoot
①添加Redis依赖
java
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>②添加Redis配置
java
spring:
data:
redis:
host: 127.0.0.1
port: 8880
# 连接超时时间
timeout: 60s
lettuce:
pool:
# 最大连接数(负数表示无限制)
max-active: 8
# 最大空闲连接
max-idle: 8
# 最小空闲连接
min-idle: 0
# 获取连接最大等待时间
max-wait: 5s③使用封装好的StringRedisTemplate
当出现connection,要考虑:
(Ⅰ)Redis服务是否启动
(Ⅱ)Redis端口号是否开放--要么开放端口号要么使用隧道
注:因为黑客容易顺着6379或者3306这样的端口爬进来,因此此处建议使用隧道(端口转发)
配置隧道,比如源主机为localhost,倾听端口为8880,此时目标主机和目标端口配置为Redis的,此时请求localhost:8880,请求就会转移到服务器上的6379端口
(5)使用Redis注意事项
①使用Redis需要进行对数据进行维护,当数据增删改的时候,Redis也要对应进行维护
②数据一致性,数据库与Redis的数据一致性,考虑当数据库成功而Redis失败,或Redis成功而数据库失败要如何处理,二者不为同一个数据库,此时就为分布式事务
(6)封装Redis统一工具类
①当前要使用自动注入的类对象,并没法,因为sdk下不存在启动类,无法被扫描到
此时在sdk获取不到,但是在使用的地方就可以使用,此处使用构造方法的形式来设置参数,要求其他服务使用时将这个对象进行传入进行构造
注:对于其他服务来说,RedisUtil属于第三方jar包,因此需要使用@Bean的方式来进行注入,无法使用五大注解来直接交给Spring进行管理
示例:
Redis工具类
java
package com.zhku.common.utils;
import com.zhku.common.exception.BlogException;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.StringRedisTemplate;
import java.util.concurrent.TimeUnit;
/**
* Created with IntelliJ IDEA.
* Description:
* User: 12290
* Date: 2026-05-14
* Time: 10:23
*/
@Slf4j
public class RedisUtil {
StringRedisTemplate stringRedisTemplate;
public RedisUtil(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
public boolean set(String key,String value){
try{
if(key!=null&&value!=null){
stringRedisTemplate.opsForValue().set(key,value);
return true;
}else{
log.error("key is null");
return false;
}
} catch (Exception e) {
log.error("redis set error,key={},value={},e:{}",key,value,e);
return false;
}
}
public String get(String key){
try{
return key==null?null:stringRedisTemplate.opsForValue().get(key);
}catch (Exception e){
log.error("redis get error,key={},e:{}",key,e);
return null;
}
}
public boolean hashKey(String key){
try{
return key==null?false:stringRedisTemplate.hasKey(key);
}catch(Exception e){
log.error("redis hashKey error,key={},e:{}",key,e);
return false;
}
}
public boolean set(String key,String value,long timeout){
try{
if(key!=null&&value!=null){
if (timeout > 0) {
stringRedisTemplate.opsForValue().set(key,value,timeout, TimeUnit.SECONDS);
}else {
stringRedisTemplate.opsForValue().set(key, value);
}
return true;
}else{
log.error("key is null");
return false;
}
} catch (Exception e) {
log.error("redis set error,key={},value={},e:{}",key,value,e);
return false;
}
}
}需要对第三方的类的bean来进行配置
java
package com.zhku.user.config;
import com.zhku.common.utils.RedisUtil;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.core.StringRedisTemplate;
/**
* Created with IntelliJ IDEA.
* Description:
* User: 12290
* Date: 2026-05-14
* Time: 10:47
*/
@Configuration
public class RedisConfig {
@Bean
public RedisUtil redisUtil(StringRedisTemplate stringRedisTemplate) {
RedisUtil redisUtil = new RedisUtil(stringRedisTemplate);
return redisUtil;
}
}②优化:对于这个RedisConfig如果其他的地方也需要使用Redis,那么就需要再写一次,因此可以把它提取到公共sdk,就不会重复写
问题:但是此时这个Config不在扫描路径无法配置对应的bean
方法:
①在对应启动类上加@ComponentScan--指定对应扫描路径
②在对应启动类上加@Import--指定扫描的类
③自动装配
在公共SDK下配置需要Spring进行管理的类
如何配置:resources下META-INF下spring下的`的org.springframework.boot.autoconfigure.AutoConfiguration.imports文件
配置完整路径
java
com.zhku.common.config.RedisConfig当前存在的问题:当前这样配置,无论当前服务是否需要这个类都会自动进行装配,我们希望做到需要的时候才进行装配
解决方法:使用@Contional注解
(7)Condtional注解的使用
①作用:使bean的配置在满足某些条件下才进行自动配置
②使用:写一个继承Condition接口的类,重写match方法,令其满足改条件的时候才进行bean的配置
写完直接使用@Conditonal(JDK21Conditon.class)
③扩展注解:
ConditionOnBean:当容器中存在指定bean的时候,该bean才会进行配置
ConditionOnMissingBean:当容器中不存在指定bean的时候,该bean才会被注册
ConditionOnClass:当类路径上存在该类时,才会进行配置
ConditionOnMissingClass:当类路径上不存在该类时,才会进行配置
ConditionOnProperties:可以指定配置文件的属性和值,当配置文件中存在指定的属性和值时,该bean才会进行配置
ConditionOnMissingProperties:可以指定配置文件的属性和值,当配置文件中不存在指定的属性和值时,该bean才会进行配置
说明:这些注解是类级别或者方法级别的注解
④针对RedisUtil的使用:
要求:当当前服务使用到Redis的时候则需要对RedisUtil来进行装配,当用不上的时候就不需要装配
抓住特性:使用Redis的都需要配置Redis的相关配置,通过相关服务是否配置了Redis相关配置来决定是否配置RedisUtil
方法:使用@ConditionalOnProperties(prefix="spring.data.redis",name="host")
7.fastjson
(1)常用的Json工具
Jackson:Spring内置的json工具,不需要引入依赖
Gson:谷歌旗下的json工具
fastjson:阿里巴巴开源的json工具,具有高性能
(2)使用
①引入依赖
XML
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.52</version>
<scope>compile</scope>
</dependency>②使用对应方法
java
//将对象转换成json字符串
String jsonString=JSON.toJSONString(obj);
//将json字符串转换成对象
Object obj=JSON.parseJSON(jsonString);(3)统一封装
原因:因为其使用的时候可能会抛异常,因此在工具类里进行统一的判断以及异常处理
具体异常处理要选择直接返回null还是进行抛出要取决于业务,根据业务来进行选择
示例:
java
package com.zhku.common.utils;
import com.alibaba.fastjson2.JSON;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;
/**
* Created with IntelliJ IDEA.
* Description:
* User: 12290
* Date: 2026-05-14
* Time: 22:39
*/
@Slf4j
@Component
public class JsonUtil <T>{
public static String toJSONString(Object object) {
try{
return object==null?null: JSON.toJSONString(object);
}catch (Exception e){
log.error("Json转换为字符串失败!");
return null;
}
}
public T parseString(String jsonString,Class<T> clazz){
try{
if(jsonString==null|| StringUtils.hasText(jsonString)){
return null;
}
return JSON.parseObject(jsonString,clazz);
}catch (Exception e){
log.error("Json转换为字符串失败!");
return null;
}
}
}8.用户注册的完善
(1)引入Redis
①引入处:
当用户注册时将用户信息存入Redis
当用户登录时去Redis查询对应用户信息,查询不到去数据库里进行查询,然后再次存储到Redis中
②引入前缀:相同的key可能存储着不同业务模块的内容,使用前缀将其分开,避免数据重叠
因此此处的key需要进行封装,此处的buildKey在多个模块都需要使用到,因此需要将其放到公共sdk里
9.常见面试题:redis数据和mysql数据的一致性问题
(1)问题
redis中存储的是a,mysql存储的是b,一般是更新和删除会存在这样的问题
(2)示例
以用户更新为例,用户更新时,需要同时更新redis中的数据和MySQL中的数据
建议先更新mysql,再更新redis
此时存在三种情况
①全部成功
②一个成功,一个失败:mysql更新成功,redis更新失败
③全部失败
(3)常见策略
①读:先从缓存中读,缓存不存在,从数据库中读,更新redis
②写:
(Ⅰ)延迟双删(常用):数据更新时,先插入数据库,数据库插入成功后,删除redis,如果删除出现异常,那就再次删除
或者延迟一段时间后再删除一次(即使第一次删除成功第二次保险起见也可以再删除一次)
redis在公司集群的可用性是99.9%,也就是删除Redis失败的可能率是0.1%,再次删除失败的可能性就是0.01%,此时的redis的可用性已经是很高了,可以满足大多数的情况
(Ⅱ)异常更新:基于消息队列,异步更新数据
(Ⅲ)使用mysql的binlog订阅同步功能:使用这个去同步redis的数据
10.RabbitMQ
(1)应用场景
用户注册成功之后给用户发送邮件,但是这个邮件发送是否成功并不影响用户注册,因此可以使用RabbitMQ来进行解耦
(2)介绍
开源的消息代理和队列服务器,广泛用于实现消息队列和事件通知,MQ多用于分布式系统之间的通信
系统间的通信方式通常有两种:
(1)同步通信:直接调用对方的服务,一方数据可以直接到达另一方
(2)异步通信:数据发送之后,先放到一个容器临时存储起来,当达到某一条件时,再从容器发送另一方,容器的一个具体实现就是MQ
RabbitMQ就是MQ的一种实现
例如仓库一样,采购部门往仓库里面存储东西,到一定情况仓库就往生产部门里发送东西,仓库用来存储东西,发送东西,而MQ用于存储消息,发送消息
(3)MQ作用
①异步解耦:在工作中,有些操作可能非常地耗时,但是不需要立刻返回结果,可以使用RabbitMQ来进行解耦,比如注册成功后给用户发送短信和邮件通知,这些通知的发送并不影响用户的成功注册,因此可以先存储到MQ中后续再进行实现
②流量削峰:有的时候会存在访问量剧增的情况,但是我们如果以这个峰值作为基准去投入资源,那么流量过后多余的资源就会造成浪费,使用MQ可以使关键组件支撑突发访问情况带来的压力,不会因为突发的流量崩溃,MQ可以控制流量,将请求排队,然后系统根据自己的能力逐步进行处理
就比如景区平时人流量就是只能处理一千,但是节假日人流量可能达到了一万,此时如果专门为了节假日多招一些员工,那么当节假日结束之后这些员工就浪费多余了,而此时使用MQ就相当于给景区进行限流排队,然后根据景区的处理能力一千来逐步进行处理
③异步通信
④消息分发:有的时候多个系统需要对同一份数据做出响应,此时可以使用消息分发,比如支付系统发送成功后,发送支付成功消息,其他系统订阅该消息,无需轮询数据库
⑤延迟通知:用于在特定时间后发送通知的场景,比如支付超过一定时间,告诉用户超时未支付
(4)主流的MQ产品
①Kafka:主要用于日志采集和传输,功能简单,如果有日志采集的需求,首选Kafka
②RocketMQ:用于可靠性高,并发比较大的场景,但是支持客户端语言比较少,社区活跃度一般,适用于类似互联网金融
③RabbitMQ:支持几乎所有主流语言,开源提供的界面比较友好,性能较好,吞吐量达到万级,社区活跃较好,适合中小公司,数据量不多,并发不大的场景
(5)安装
①安装Erlang:
java
#更新软件包
sudo apt-get update
#安装erlang
sudo apt-get install erlang②安装Rabbit-MQ
java
#更新软件包
sudo apt-get update
#安装rabbitmq
sudo apt-get install rabbitmq-server
#确认安装结果
systemctl status rabbitmq-server③安装管理界面
java
rabbitmq-plugins enable rabbitmq_management④启动服务并访问
java
sudo service rabbitmq-server start访问http://(对应ip):15672/
注:界面默认端口号为15672,服务端通信是5672
因此这两个端口号都需要进行开放才能访问到
进入界面需要进行登录,初始账号和密码是guest,但是这个只能在本地登录,我们需要创建用户
(6)创建用户并分配权限
①创建用户:
java
rabbitmqctl add_user ${账号名} ${密码}②分配权限
java
rabbitmqctl set_user_tags ${账号名} ${角色名}对应的角色:
Administrator: 超级管理员,可登陆管理控制台(启⽤management plugin的情况下),可查看所
有的信息,并且可以对⽤⼾,策略(policy)进⾏操作
Monitoring: 监控者,可登陆管理控制台(启⽤management plugin的情况下),同时可以查看
rabbitmq节点的相关信息(进程数,内存使⽤情况,磁盘使⽤情况等)。
Policymaker: 策略制定者,可登陆管理控制台(启⽤management plugin的情况下),同时可以对
policy进⾏管理。但⽆法查看节点的相关信息.
Management :普通管理者,仅可登陆管理控制台(启⽤management plugin的情况下),⽆法看到
节点信息,也⽆法对策略进⾏管理.
Impersonator:模拟者,⽆法登录管理控制台。
None: 其他⽤⼾,⽆法登陆管理控制台,通常就是普通的⽣产者和消费者。
(7)核心概念
RabbitMQ是一个生产者消费者模型
①生产者:消息的发送方,在实际应用中,消息通常是带有一定业务逻辑结构的数据,比如JSON字符串,消息可以带有一定的标签,RabbitMQ会根本标签进行一定的路由,把消息发送到感兴趣的消费者
②消费者:消息的接收方,消费的过程中,消息的标签会被丢掉,消费者只能消费,但不知道生产者是谁
③Broker:RabbitMQ服务器
生产者想把消息发送给Broker,需要先建立连接
④connection:连接,客户端与RabbitMQ之间的连接是TCP连接,连接的端口号是5672,负责客户端和服务器之间所有的数据和控制信息
生产者与Broker建立连接后,要想把消息发送给Broker,需要通过channel来进行发送
消费者想要接收消息也是如此,需要先建立连接,然后再通过channel进行发送
⑤channel:通道,信道,一个connection可以有多个chanel,消息的发送和接收都是基于channel的
⑥VirtualHost:虚拟机,类似于mysql的database,起到了一个逻辑隔离的作用,当不同的用户使用同一个RabbitMQServer的时候,可以虚拟地划分出多个VHost,每个用户在自己的VHost上创建queue和exchange
类似于公司里大家创建了一个mysql集群,大家一起用,但是在用的时候大家创建出自己的数据库,互不影响
⑦Queue:队列,消息存放的地方
⑧Exchange:分发消息,根据一定的规则,将消息发送到对应的队列,不同的交换机的类型不同,分发的规则也不相同
整个过程类似于寄件收件,生产者是发件人,消费者是收件人,Broker是物流,生产者寄件后通过Exchange根据当前的地址来进行分发,分发到指定的站点Queue
(8)AMQP协议核心工作流程
首先生产者和Broker(RabbitMQ服务器)建立连接,然后通过channel来对消息进行发送,消息发送首先到Exchange交换机,然后通过一定的路由规则分发到对应的Queue,然后消息者再通过和Broker建立连接并且通过channel的方式来接收消息进行消费
说明:RabbitMQ就是对AMQP协议的Erlang实现
(9)RabbitMQ的工作模式
①简单模式:一个生产者对应发送消息到一个队列,被一个消费者消费
②工作模式:一个生产者对应发送消息到一个队列,被两个消费者进行消费,此时两个消费者是合作模式,共同完成一个工作任务
③广播(Publish)模式(fanout):生产者发送一个消息,两个队列都进行了订阅,两个队列都能分发到,类似于广播的效果
④路由(Routing)模式(direct):交换机根据标签发送给不同的队列,交换机根据 routing key 精确匹配,把消息发到绑定了对应 key 的队列。一个队列也可以绑定多个 key。
⑤Topics模式(topic):交换机根据通配符标签来将消息发送给不同的队列
(10)基于SpringBoot进行RabbitMQ开发
①引入依赖
java
<!--RabbitMQ相关依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>②编写yml配置,基本信息进行配置
java
# 配置 RabbitMQ 的基本信息
spring:
rabbitmq:
host: 对应ip
port: 5672 # 默认为5672
username: study
password: study
virtual-host: zhku # 默认值为 /
java
# amqp://username:password@Ip:port/virtual-host
spring:
rabbitmq:
addresses: amqp://study:study@对应ip:5672/zhku③编写生产者代码
需要声明一个队列,@Bean注入一个队列,这里的Queue是一个类,刚刚引入依赖里带的
简单示例:
java
package com.zhku.user.config;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.QueueBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.stereotype.Component;
/**
* Created with IntelliJ IDEA.
* Description:
* User: 12290
* Date: 2026-05-16
* Time: 19:04
*/
@Configuration
public class RabbitMqConfig {
@Bean
public Queue queue() {
return QueueBuilder.durable("hello").build();
}
}定义生产者,并发送消息--使用RabbitTemplate(RabbitMQ的客户端)\
使用convertAndSend():填写对应的交换机,标签,以及消息内容
示例:
java
package com.zhku.user;
import org.junit.jupiter.api.Test;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
/**
* Created with IntelliJ IDEA.
* Description:
* User: 12290
* Date: 2026-05-16
* Time: 19:09
*/
@SpringBootTest
public class RabbitMqTest {
@Autowired
RabbitTemplate rabbitTemplate;
@Test
public void send(){
rabbitTemplate.convertAndSend("","hello","hello,rabbitmq!");
}
}④编写消费者代码+定义监听类,使用@RabbitListener注解完成队列监听
示例:
java
package com.zhku.user.listener;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
/**
* Created with IntelliJ IDEA.
* Description:
* User: 12290
* Date: 2026-05-16
* Time: 19:12
*/
@Component
public class HelloRabbitMqListener {
@RabbitListener(queues = "hello")
public void handler(Message message) {
System.out.println("接收到信息:"+message);
}
}⑤运行观察结果
(11)交换机类型
fanout(广播):将消息发送给所有绑定的队列,不涉及routingkey和bindingkey,只要有绑定即可
direct(定向):将消息交给所有符合指定routing key的队列
topic(通配):将消息交给符合routing pattern(路由模式)的队列
补充:
RoutingKey:生产者发送消息给交换机时绑定RoutingKey
BindingKey:交换机与队列绑定时的key
11.用户服务引入RabbitMQ
①引入依赖
②配置rabbitmq基本信息,配置手动确认
bash
spring:
rabbitmq:
# 配置 RabbitMQ 的基本信息
addresses: amqp://study:study@你的ip:5672/zhku
listener:
simple:
acknowledge-mode: manual # 配置手动确认区分:
自动确认:消费者从Broker获取消息,Broker就认为消息消费成功,从Broker中把消息删除
手动确认:消费者从Broker获取消息,还需要手动向Broker发送ack进行确认,Broker才会删除该消息
③定义用户队列和用户交换机,进行用户队列和用户交换机的绑定
④在用户注册成功处进行消息发送,指定交换机和队列名称,并且发送用户信息
注:此处的用户信息合理是需要重新定义一个类,消费者需要的信息我们才进行发送,而不是所有的信息都进行发送
⑤编写消费者并写方法对消息进行处理,处理成功进行确认,失败进行否定确认
如何进行确认?每个消息有一个id,该id在信道上唯一,可以在发送的消息里获取其id,然后通过信道来进行确认和否定确认,对于否定确认,还需要设置是否重新放回队列
补充:上面展示的是第一种写法,还可以使用下面这种写法
12.邮箱发送
(1)引入依赖
XML
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-mail</artifactId>
</dependency>(2)配置
java
spring:
mail:
host: smtp.qq.com # 需要在设置中开启 SMTP
username: XXXXX@qq.com # 发件人的邮箱
password: XXXXXXXX # 邮箱授权码,并非个人密码
default-encoding: UTF-8 # 字符集编码,默认 UTF-8说明:
host:指的是你所使用的服务器地址,写对应的即可
password:对于qq账号来说指的是授权码,需要在qq邮箱开启STMP服务
(3)代码编写
使用JavaSender类对象
①创建一个邮件消息
②创建MimeMessageHelper
③设置
setFrom--发件人邮箱和名称
setTo--收件人邮箱
setSubject--设置主题
setText--设置内容,后面可设置html是否生效
13.邮箱发送引入项目中
(1)由于其他地方也可能用到邮箱,因此提取到公共sdk,方便后续统一进行使用,但是由于其内部需要使用自动注入对象JavaMailSender,但是又不在启动类的扫描路径下,因此需要采用Redis的那种自动装配的方案
回顾一下Redis的自动装配方案:当时需要使用RedisTemplate对象,由于无法直接注入,因此采用了构造方法的方式,将对象传入,然后写了一个配置类将Redis进行配置,此时的构造就需要把对象传入,但是由于这个配置类还是不在扫描路径内,所以只能在resources下的META-INF下spring下org.springframework.boot.autoconfigure.AutoConfiguration.imports来进行自动装配,将这个配置类写入,并且在配置类的使用@Conditional注解来限制哪些引入包的类需要注入该对象
因此此处也采用这种自动装配的方式
(2)代码中的一些属性如何获取?--从配置文件获取,spring将我们上面的配置内容封装了一个对象
MailProperties,我们只需要在构造方法里注入这个对象,然后需要什么内容就可以直接从里面获取
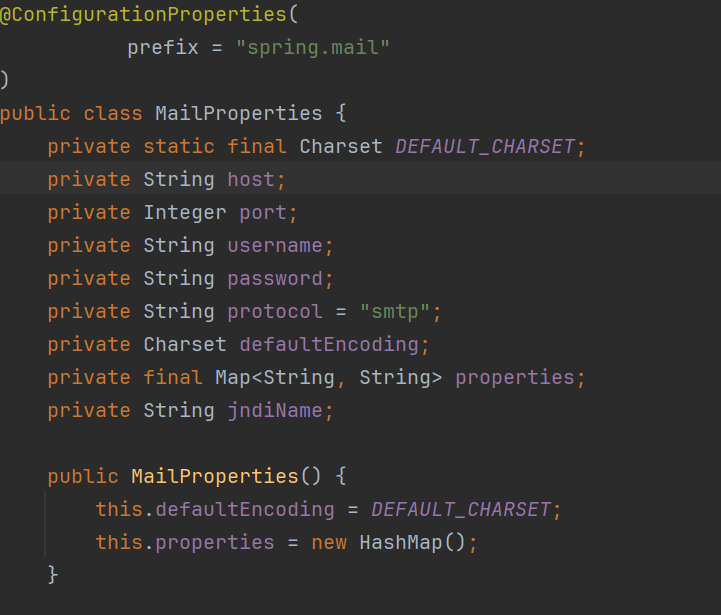
包括我们自己额外需要再配置什么内容,但是该类的的属性里不包含我们也可以把它配置在properties下,然后通过get方法去获取
(3)Mail类代码示例:
java
package com.zhku.common.utils;
import jakarta.mail.MessagingException;
import jakarta.mail.internet.MimeMessage;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.mail.MailProperties;
import org.springframework.mail.javamail.JavaMailSender;
import org.springframework.mail.javamail.MimeMessageHelper;
import java.io.UnsupportedEncodingException;
/**
* Created with IntelliJ IDEA.
* Description:
* User: 12290
* Date: 2026-05-17
* Time: 12:06
*/
public class Mail {
private JavaMailSender mailSender;
private MailProperties properties;
public Mail(JavaMailSender mailSender, MailProperties properties) {
this.mailSender = mailSender;
this.properties=properties;
}
public void send(String to,String subject,String content) throws MessagingException, UnsupportedEncodingException {
MimeMessage message=mailSender.createMimeMessage();
MimeMessageHelper helper=new MimeMessageHelper(message);
String personal=properties.getProperties().get("personal");
helper.setFrom(properties.getHost(),personal);
helper.setTo(to);
helper.setSubject(subject);
helper.setText(content,true);
mailSender.send(message);
}
}完整配置项:
java
spring:
mail:
host: smtp.qq.com
port: 465
username: 你的qq号
password: 对应的授权码/密码
protocol: smtps
default-encoding: UTF-8
properties:
personal: 发件者名称
mail:
smtp:
auth: true
ssl:
enable: true四 服务部署
1.前端服务部署(Windows)
(1)Ngnix介绍
Ngnix是一个静态资源的服务器,当只有静态资源时,可以使用Nginx来实现服务部署
(2)下载Nginx
去官网找稳定版本,下载后放到想要的目录然后进行解压缩,解压缩后直接运行nginx.exe,访问127.0.0.1:80,如果能访问成功,说明启动成功
官网:https://nginx.org/en/download.html
(3)如何关闭nginx
①任务管理器,结束进程暴力关闭
②命令关闭:首先进入到nginx安装目录,然后关闭nginx
通过该命令:
java
.\nginx.exe -s stop(4)如何对前端代码进行部署
①打开安装目录下的conf目录下的nginx.conf,修改location配置
将root改为对应要部署的前端代码的路径,然后index修改为一开始默认打开的页面,一般为登录页面
②需要统一修改一下前缀url:http://127.0.0.1:10030,要不然其就直接默认是当前端口拼接上请求路径了
在ajaxSend里统一对url进行处理
③处理跨域问题
跨域:跨域是指浏览器阻止前端网页从一个域名向另一个域名的服务器发送请求
具体来说,只要协议,域名,端口号有一个不同,都被视为跨域请求
配置网关项目允许跨域,在网关服务里进行配置
java
spring:
cloud:
gateway:
# 网关全局跨域配置
globalcors:
# 解决 OPTIONS 请求被拦截的问题
add-to-simple-url-handler-mapping: true
cors-configurations:
'[/**]':
allowedOriginPatterns: "*" # 设置允许跨域的来源
allowedMethods: "*"
allowedHeaders: "*"
allowCredentials: true2.服务部署
(1)环境准备
按照一下顺序检查环境是否准备好:
Mysql:对应的库和表是否都建立好
Redis
RabbitMq
Nacos
Nginx
(2)云服务器部署前端代码
①安装
java
#更新软件包
sudo apt-get update
#安装nginx
sudo apt-get install nginx
#查看nginx版本
nginx -v
#启动nginx
systemctl start nginx
#查看nginx状态
systemctl status nginx②手动修改一下访问的url
注:在生产环境有域名映射,不需要反复修改,当前是需要修改
③压缩前端代码,打包上传,再进行解压缩(可存于/var/www/blog下)
④修改配置文件,找到目录/etc/nginx/sites-enabled,修改default文件
修改root为项目地址以及index为登录页面
⑤重启nginx
java
systemctl restart nginx3.后端部署
关键:修改不同环境下的配置文件
(1)多环境配置
①写多个不同环境的配置文件
②使用---来区分环境配置,不同环境下值不同使用变量来进行配置
使用这种防守,需要在部署的时候指定当前的环境是什么环境
(2)公共SDK的拉取方式
对于公共sdk,maven仓库无法拉取到因此解决方式如下:
①将公共sdk进行install,上传到本地,然后在引用的地方加上路径,让它从本地进行读取该包
示例:
XML
<dependency>
<groupId>org.example</groupId>
<artifactId>product-api</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- scope 为system. 此时必须提供systemPath即本地依赖路径. 表⽰maven不会去中央
仓库查找依赖-->
<scope>system</scope>
<systemPath>D:/Maven/.m2/repository/org/example/product-api/1.0-
SNAPSHOT/product-api-1.0-SNAPSHOT.jar</systemPath>
</dependency>以及对应打包的依赖也要设置<includeSystemScope>true</includeSystemScope>
XML
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<includeSystemScope>true</includeSystemScope>
</configuration>
</plugin>
</plugins>
</build>②直接对整个父工程进行打包,不要单独打包
公共jar跳过打包的pom配置
XML
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>