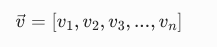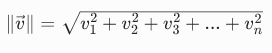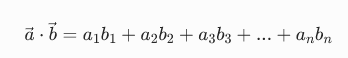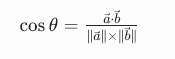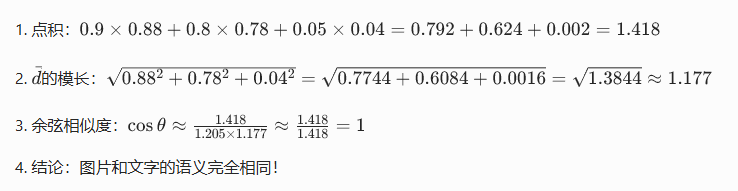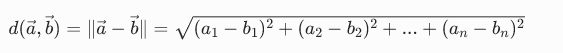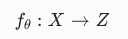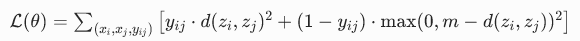内容参考于:图灵AI大模型全栈
本章用的百炼在线大模型是后付费模式,跟贷款一样,它先替你拿钱,然后你再还,这样要注意别欠的太多还不起了
传统的大模型会存在几个问题
1.幻觉
原因:数据多、数据噪音(谣言)、概率优先(不保证正确,只有找到的东西,大模型就会组合成一个看起来正常的答案)
2.跟新数据慢,比如数据的有效期只有一个星期,一个星期后需要再次给大模型数据
3.专业知识理解有限,大模型对于一个行业的知识可以学习到大约百分之80,剩下的百分之20它没办法学习到因为没有资料,就是说大模型的训练数据覆盖全网公开的文本,但是领域知识是很少的(就是每个人的看家本领可能就不会放到公开的网络中)
上方的三个问题,就是RAG出现的理由,RAG就是为了解决这三个问题

RAG概念
RAG(Retrieval Augmented Generation)通过检索外部数据(知识库),增强大模型的生成效果。
就是在调用大模型之前,先去找资料,这个资料是我们人提前准备好的,这样就能保证跟新数据块、减少幻觉、专业知识增强
RAG论文:https://arxiv.org/pdf/2312.10997
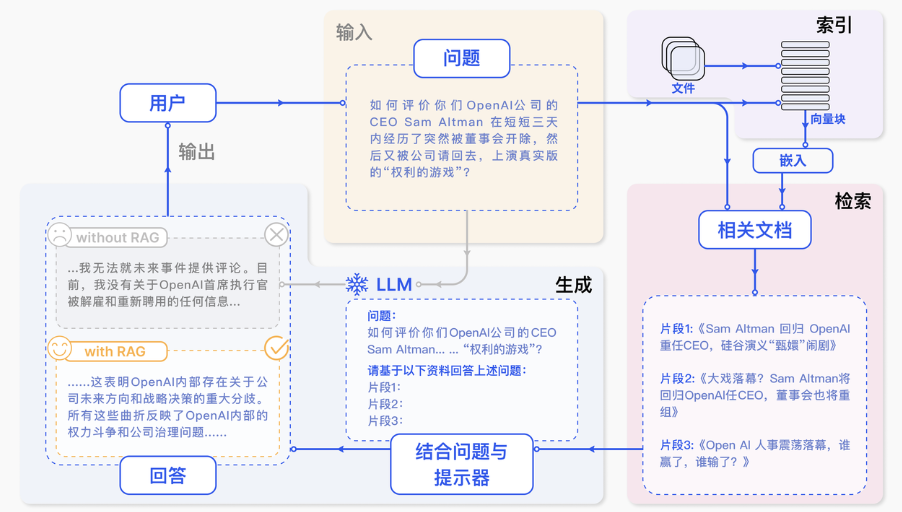
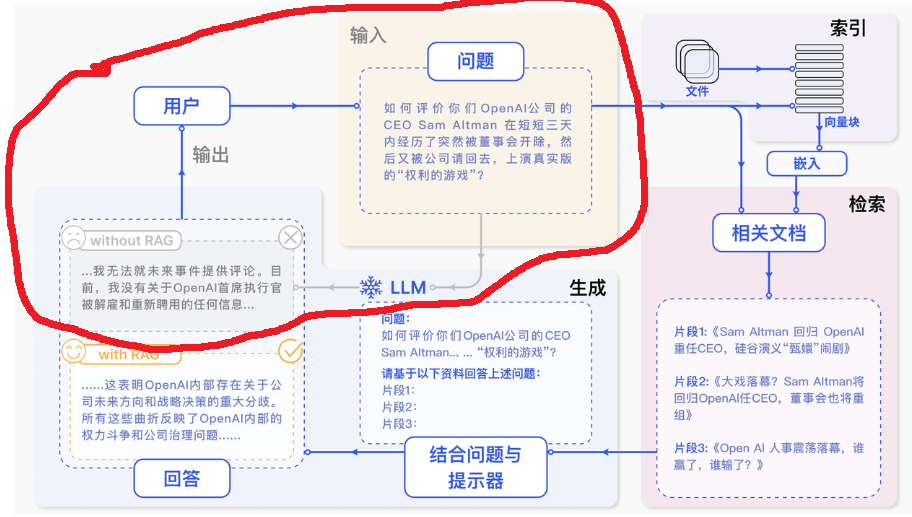
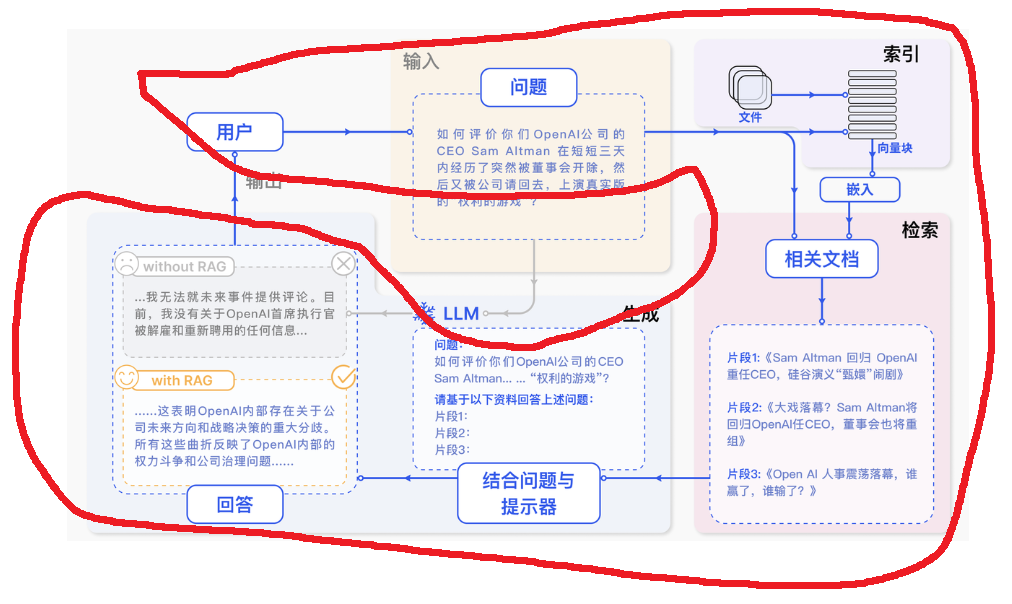
如下图是一个RAG和普通大模型的流程
如下图红框是使用普通大模型,直接把问题给大模型,我们问的问题是公司内部的,大模型就会不知道,这种事基本也不会有人跟它讲
如下图带着RAG后,输入一个问题后,先进行向量索引(去我们的知识库查资料),然后根据问题在资料中找到相关内容,然后把问题和相关资料拼接成提示词,然后在给大模型
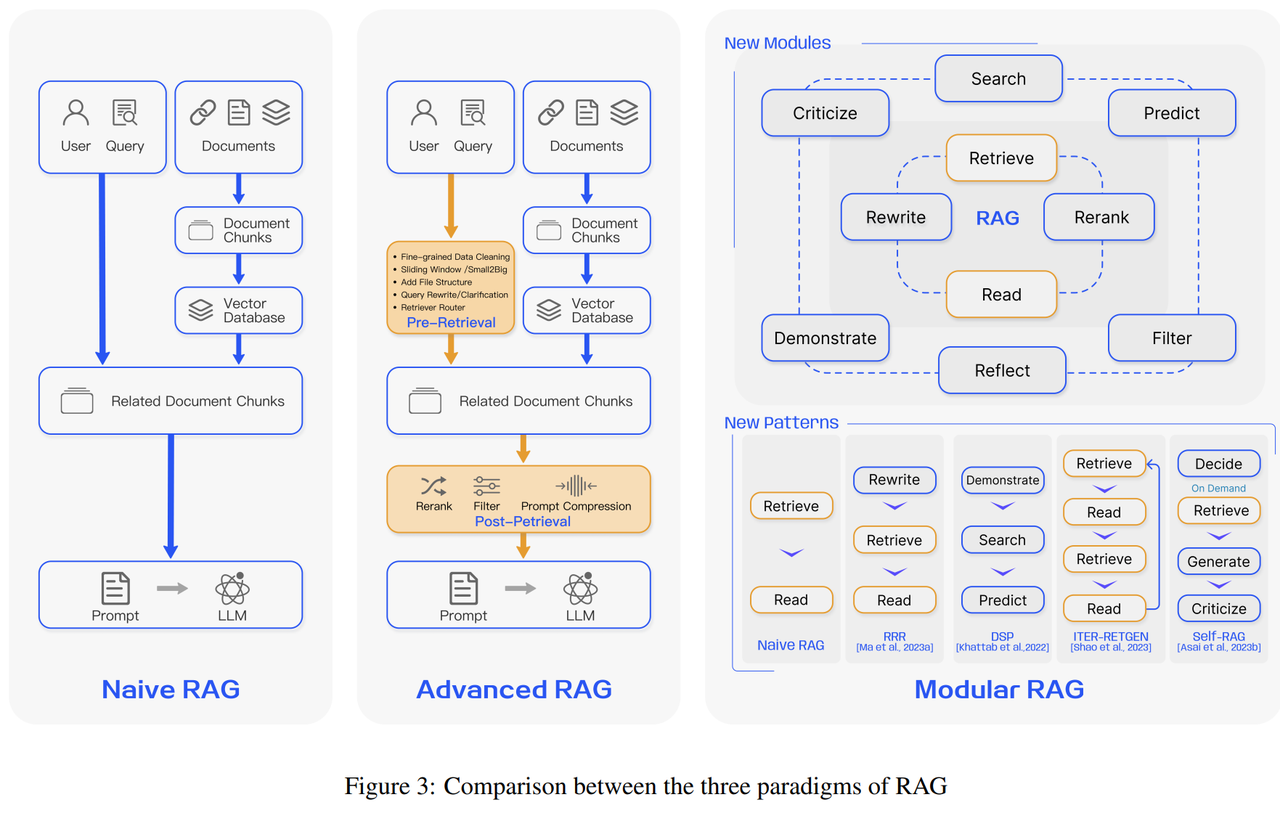
RAG现有三个阶段,如下图左边第一个就是普通RAG、中间的是高级RAG,右边第一个是模块化的RAG,模块RAG就是把高级RAG进行封装成模块,所以这里只细写高级RAG
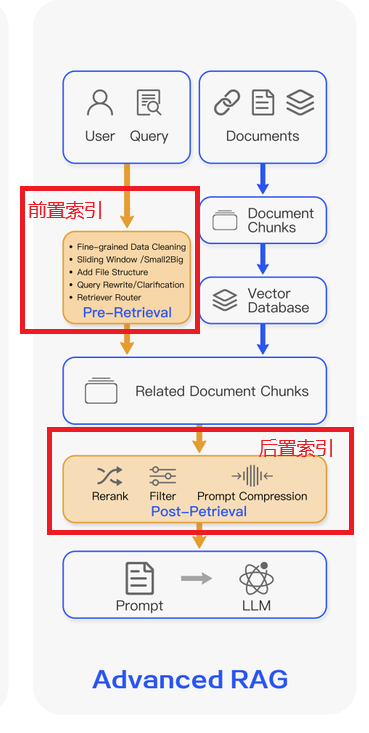
高级RAG,多了前置索引和后置索引,前置索引用来处理用户的问题,就是说用户可能并不会使用大模型(写的提示词不好),我们需要在前置索引里把用户的问题处理一下,让问题更加细节,然后再去我们的知识库查资料,然后后置索引是比如找到的资料很多,这多个资料里面肯定有不符合的,这里就要把它们筛选掉,然后整理一下,然后做压缩,就是说后置索引就是为了减少Token
上方提到了知识库(索引),那么这个索引怎么搞呢?
首先我们的知识的来源肯定是一个文档,文档里面有很多很多字成千上万的,知识库就是把这些文档搞成向量(向量是由多个小数组成的数组),然后把向量存放到数据库里,这个数据库就是索引,这里就有问题了,怎么把文档搞成向量呢?
在搞成向量之前还有一个问题,一个文档中是有很多字的,把这么多字搞成一个向量肯定不现实,向量里面的内容后很庞大,会很消耗Token,所以要对文档进行分块
分块策略:
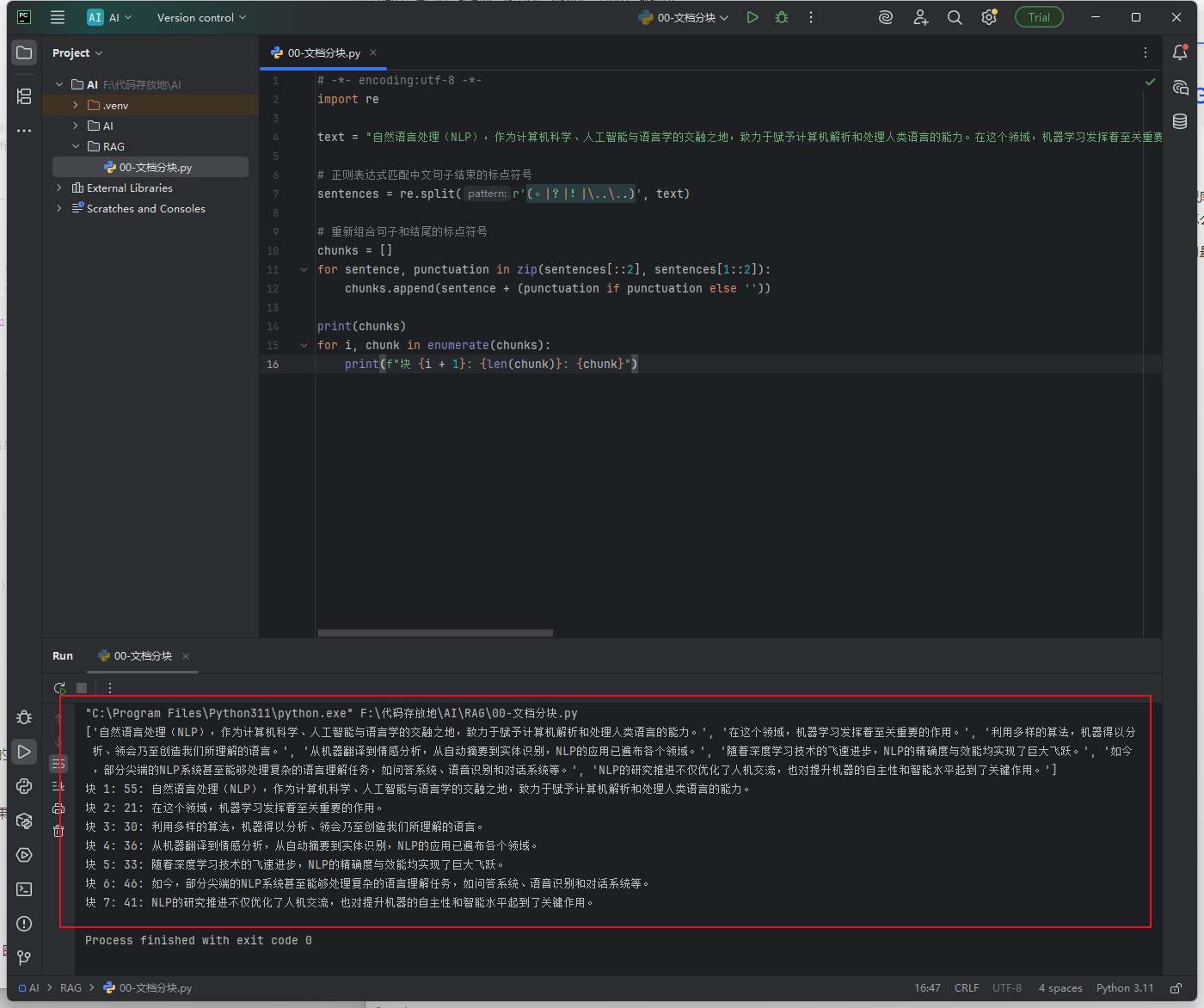
- 按照句子来切分,如下图句子分块就是通过标点符号来拆分文档,这个方式有个缺点,如果标点符号用的不好或者说一句话很长,就会形成拆分出来的内容有的很短有的很长
python# 1. 导入Python自带的正则表达式工具包 re # 正则表达式:专门用来按【自定义规则】处理字符串(比如匹配、分割、查找文字) import re # 2. 定义一个字符串变量 text,存放我们要处理的长中文文本 # 这就是需要被拆分成句子的原始内容 text = "自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。" # 3. 核心步骤:用正则表达式分割文本,得到【句子片段+标点符号】的混合列表 # re.split(规则, 文本):按照【规则】把字符串切成一段一段的,返回列表 # 正则规则详解(小白版): # r'...':原始字符串,防止转义字符出错 # (。|?|!|\..\..):括号表示【保留分割符】,| 表示"或者" # 。:中文句号 ?:中文问号 !:中文感叹号 # \..\..:匹配中文省略号(.在正则里是特殊符号,加\表示就是普通的点) # 最终效果:遇到 句号/问号/感叹号/省略号 就分割,并且**保留这些标点符号** sentences = re.split(r'(。|?|!|\..\..)', text) # 4. 创建空列表 chunks,用来存放【拼接好的完整句子】(句子主体 + 结尾标点) chunks = [] # 5. 循环:把分割后的【句子片段】和【标点符号】一对一对拼接起来 # 知识点1:sentences[::2] → 列表切片:从第0位开始,每隔1个取1个(取 0、2、4...位 → 纯句子内容) # 知识点2:sentences[1::2] → 从第1位开始,每隔1个取1个(取 1、3、5...位 → 对应的标点符号) # 知识点3:zip() → 把两个列表按顺序配对,比如 [句子1,句子2] 和 [标点1,标点2] → 配对成(句子1,标点1)、(句子2,标点2) for sentence, punctuation in zip(sentences[::2], sentences[1::2]): # 拼接句子:如果有标点就加上,没有就不加(防止空值报错) # sentence:纯句子文字 punctuation:对应的结尾标点 complete_sentence = sentence + (punctuation if punctuation else '') # 把拼接好的完整句子,添加到 chunks 列表里 chunks.append(complete_sentence) # 这行是调试代码,注释掉了:直接打印所有完整句子,方便检查分割结果 # print(chunks) # 6. 遍历最终的完整句子列表,打印输出结果 # enumerate(chunks):给每个句子加一个【序号】,i是序号(从0开始),chunk是当前句子 for i, chunk in enumerate(chunks): # 格式化打印: # 块 {i + 1}:序号从1开始(更符合阅读习惯) # {len(chunk)}:当前句子的【字符长度】(统计有多少个字+符号) # {chunk}:完整的句子内容 print(f"块 {i + 1}: {len(chunk)}: {chunk}")
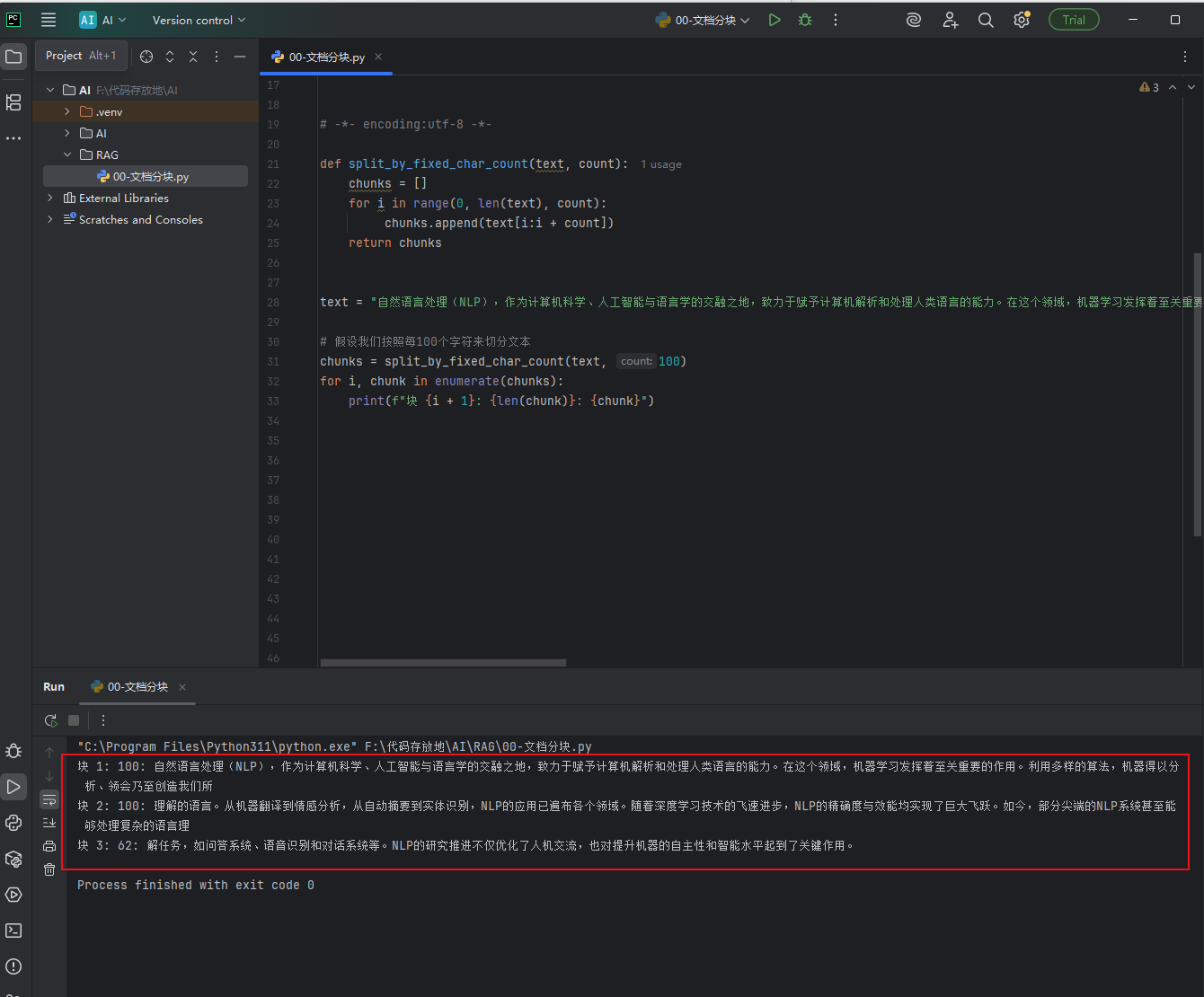
- 按照字符数来切分,如下图按照固定的句子长度来拆,会导致缺失语义,就是读不懂
python# 【第一步:定义一个 自定义函数】 # 函数名:split_by_fixed_char_count # 作用:专门用来把一段长文本,按照【你指定的字符个数】切成一小段一小段 # 参数1:text → 要被切分的原始长文本 # 参数2:count → 你想每多少个字符切一刀(比如count=100,就是每100个字符分一块) def split_by_fixed_char_count(text, count): # 创建一个空列表 chunks # 作用:用来存放切分好的所有「文本小块」,相当于一个空盒子,准备装切好的片段 chunks = [] # 【核心循环:开始切文本】 # range(0, len(text), count) → 生成切分的起始位置数字 # 小白翻译: # 0 → 从文本的第0个字符开始切(文本的第一个字符就是第0位) # len(text) → 切到文本的最后一个字符为止(不超出文本长度) # count → 每隔 count 个字符,切一刀(比如count=100,就每数100个字符切一次) # i → 每次循环的「起始切割位置」 for i in range(0, len(text), count): # 文本切片:text[i:i + count] # 小白翻译:从第i个字符开始,往后数 count 个字符,截取出这一段文本 # 把截好的小块,添加到 chunks 列表里(装进盒子) chunks.append(text[i:i + count]) # 函数执行完毕,返回切好的所有文本小块 return chunks # 【第二步:准备要处理的原始长文本】 # 定义变量 text,存放我们需要切分的大段中文 text = "自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。" # 【第三步:调用函数,执行切分】 # 传入两个参数:原始文本text + 每100个字符切一刀 # 把切好的结果,存到变量 chunks 里 chunks = split_by_fixed_char_count(text, 100) # 【第四步:遍历打印结果,清晰展示每一块】 # enumerate(chunks):给每一个文本小块,自动加上编号(从0开始) # i → 编号(0、1、2...),chunk → 当前的文本小块内容 for i, chunk in enumerate(chunks): # 格式化打印: # 块 {i + 1} → 编号从1开始(更符合我们日常看序号的习惯) # {len(chunk)} → 打印当前小块的【实际字符个数】(验证是不是100个) # {chunk} → 打印文本小块的具体内容 print(f"块 {i + 1}: {len(chunk)}: {chunk}")
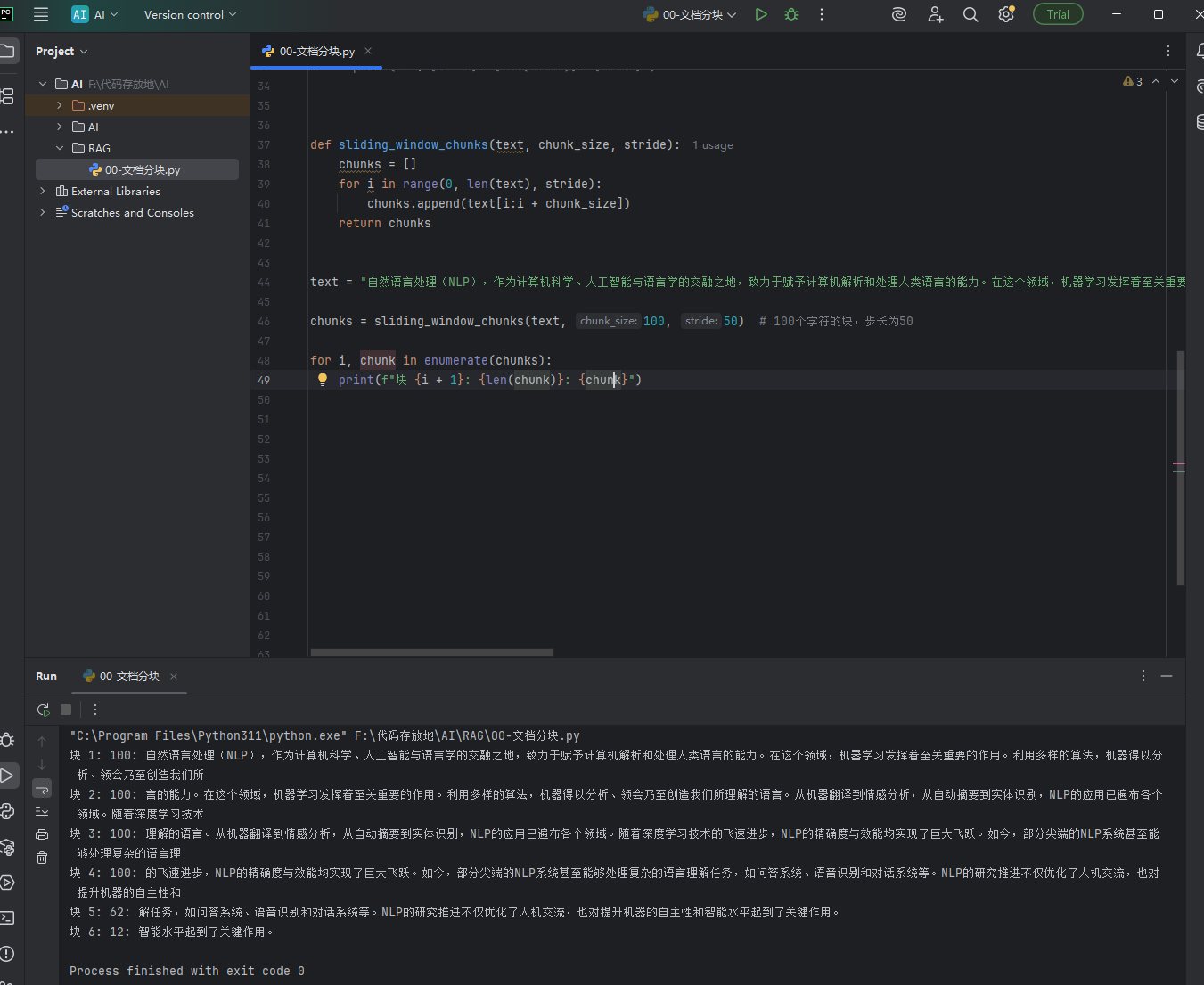
- 按固定字符数 结合overlapping window(固定字符+重叠),重叠的意思是,比如123456,以5字符拆一段,2个字符做重叠就会变成第一段是12345,第二段是456,就是第二段通过读取第一段末尾几个字符来保证语义,如下图,它的效果容易产生最后一个无用、重复太多、内容太大,会导致频繁处理重复内容
python# 【核心概念:滑动窗口】 # 比喻:就像一个固定大小的"窗户",在文本上从左往右滑动 # chunk_size:窗户的大小(固定框住多少个字符) # stride:窗户每次滑动的距离(每次挪几步) # 特点:和上一个代码不同!这个会产生【重叠的文本块】(上一个是不重叠的) # 定义函数:滑动窗口切分文本 # 函数名:sliding_window_chunks # 参数1:text → 要切分的原始长文本 # 参数2:chunk_size → 每一块的固定大小(比如100,就是每块最多100个字符) # 参数3:stride → 滑动步长(比如50,就是窗户每次向右挪50个字符) def sliding_window_chunks(text, chunk_size, stride): # 创建空列表 chunks,用来存放切好的所有文本块 chunks = [] # 核心循环:控制窗户滑动的起始位置 # range(0, len(text), stride) 翻译: # 从第0个字符开始 → 到文本最后一个字符结束 → 每次跳 stride 个字符 # i = 0 → 50 → 100 → 150... (因为步长stride=50) for i in range(0, len(text), stride): # 文本切片:从位置 i 开始,截取 【chunk_size 个字符】 # 重点:即使后面字符不够,也会截取剩下的所有字符 chunks.append(text[i:i + chunk_size]) # 切分完成,返回所有文本块 return chunks # 定义需要处理的原始文本 text = "自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。" # 调用滑动窗口函数 # chunk_size=100 → 每块大小100个字符 # stride=50 → 每次向右滑动50个字符 # 结果:每一块和上一块会【重叠50个字符】 chunks = sliding_window_chunks(text, 100, 50) # 遍历打印结果 # i:块的编号(从0开始),chunk:当前文本块内容 for i, chunk in enumerate(chunks): # 打印格式:块编号+字符长度+内容 print(f"块 {i + 1}: {len(chunk)}: {chunk}")
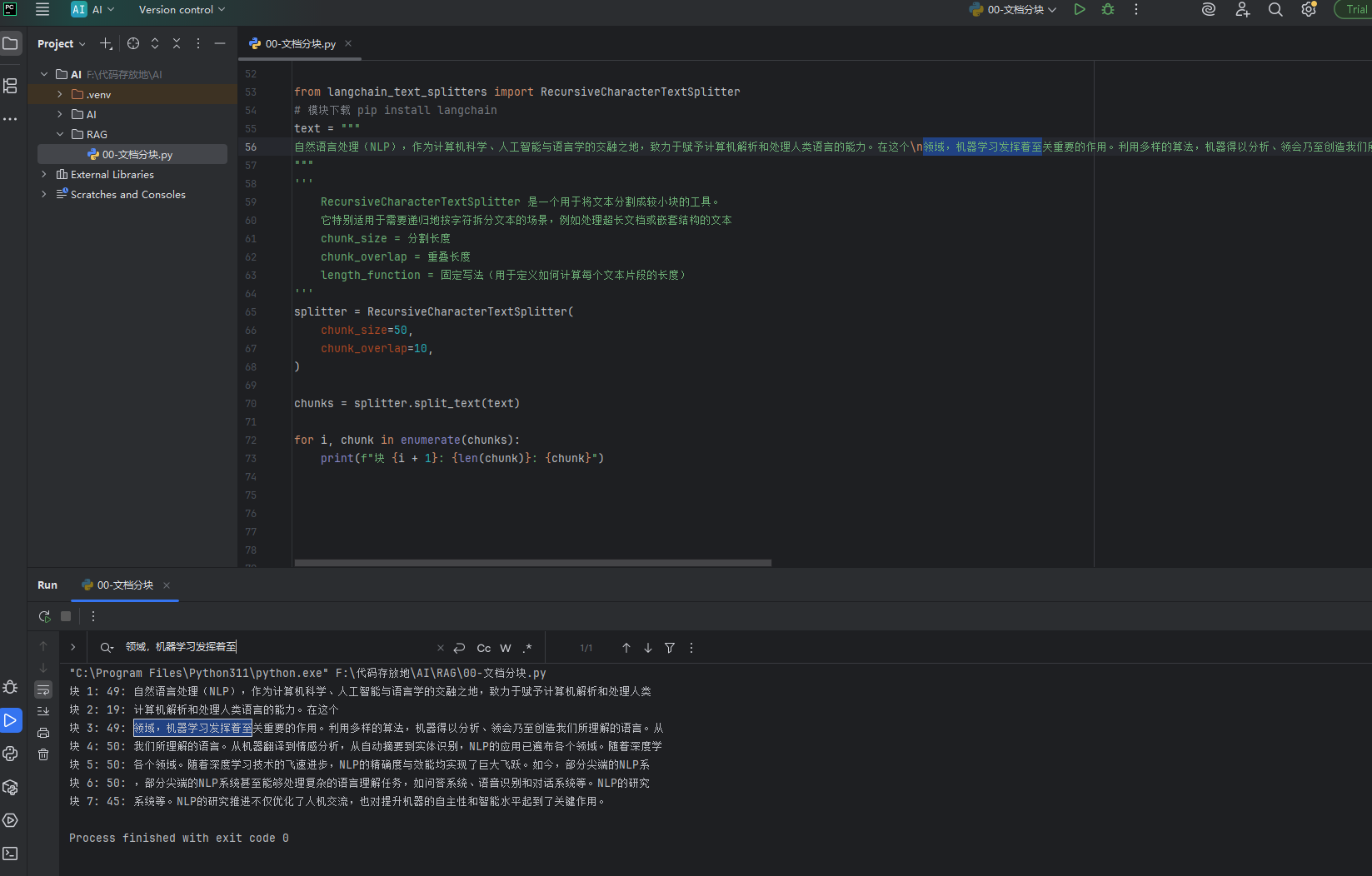
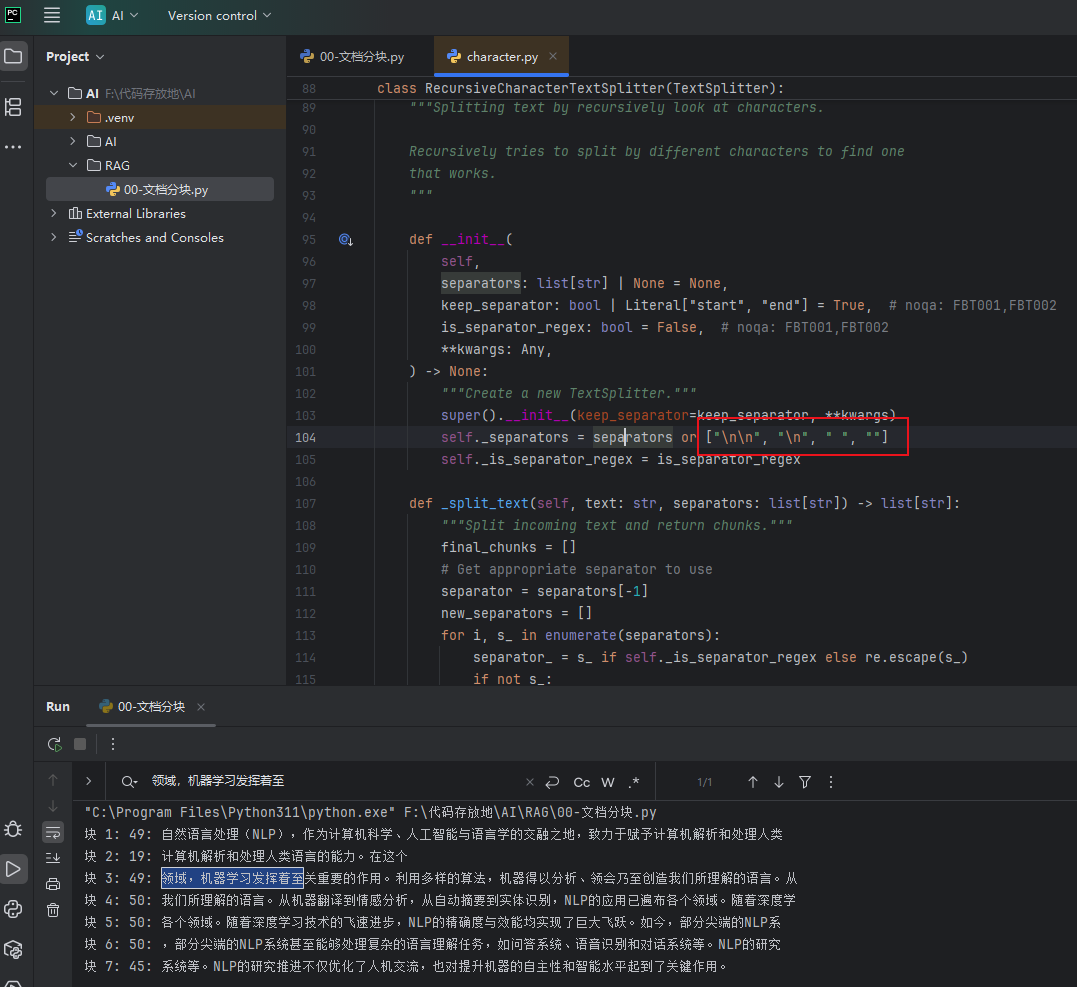
- 递归方法 RecursiveCharacterTextSplitter,它是最常用的,它整合了上方的三种,别人已经实现好了我们可以直接用,,这里使用langchain_text_splitters库来实现,如下图它可以根据固定字符数和重叠
在它的源码中默认的句子切分策略,可以通过给RecursiveCharacterTextSplitter传separators=xxxx,xxx参来修改,它是优先使用separators来拆分,然后在使用
python# 导入LangChain智能文本分割器(专业AI文档分割工具) from langchain_text_splitters import RecursiveCharacterTextSplitter # 安装命令:pip install langchain # 待分割的长文本(三引号支持多行文本) text = """ 自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个 领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。 """ # ===================== 核心:所有可传递参数完整版 ===================== # 【所有参数都在这里了!】 带默认值的参数=不写也能用,小白按需修改即可 splitter = RecursiveCharacterTextSplitter( # --------------------- 【基础核心参数】最常用,必看 --------------------- chunk_size=50, # 每块文本的【最大长度】(字符数) # 默认值:4000 # 作用:控制小块大小,不能超过模型输入限制 chunk_overlap=10, # 块与块之间的【重叠字符数】 # 默认值:200 # 作用:保留上下文,防止语义断裂 length_function=len, # 计算文本长度的函数 # 默认值:len(按字符数计算) # 作用:固定写法,小白不用改! # --------------------- 【高级拆分参数】进阶使用 --------------------- separators=["\n\n", "\n", ",", "。", " "], # 拆分优先级列表(递归拆分规则) # 默认值:["\n\n", "\n", " ", ""] # 作用:按顺序拆分!先按双换行→单换行→逗号→句号→空格→字符 is_separator_regex=False, # 分隔符是否为【正则表达式】 # 默认值:False # 作用:True=支持正则拆分,False=普通字符,小白默认False keep_separator=True, # 分割后【是否保留分隔符】(句号/逗号/换行) # 默认值:True # 作用:True=保留标点,语义完整;False=删掉标点 strip_whitespace=True, # 自动去除文本首尾的空白字符(空格、换行、制表符) # 默认值:True # 作用:清理无用空白,让文本更整洁 # --------------------- 【极少用参数】底层配置,小白不用动 --------------------- add_start_index=False, # 是否记录每个块在原文的起始位置 ) # 执行分割:把长文本切成语义完整的小块 chunks = splitter.split_text(text) # 遍历打印结果:编号 + 字符长度 + 内容 for i, chunk in enumerate(chunks): print(f"块 {i + 1}: {len(chunk)}: {chunk}")
相似度的说明,可能很难看懂,这里简单说,如下图是一个带有数字的图片,右边黑色框出来的就是图片深色的部分也就是1这个数字,可以看到右边黑框以外其它位置的数字都是0,这说明这地方没有像素,有像素的地方就是我们的1,或者是用来表示1的像素点,这就可以搞成一个向量(数组),通过这种特征就可以进行文字识别

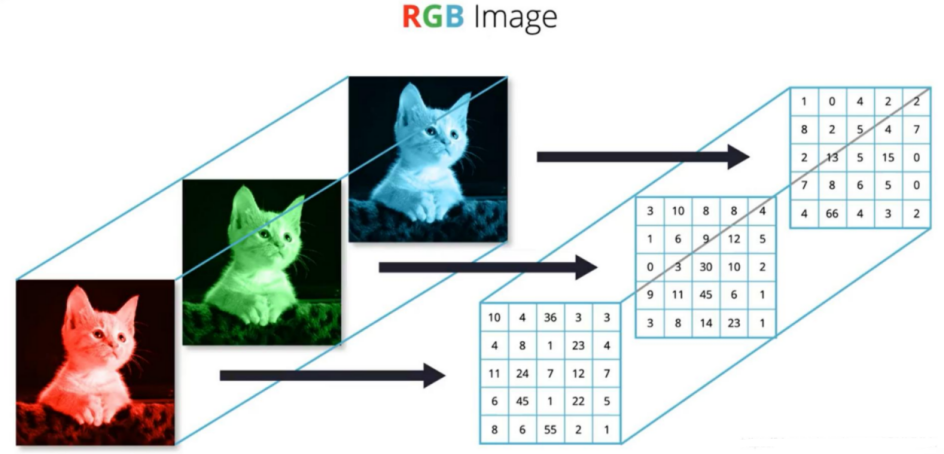
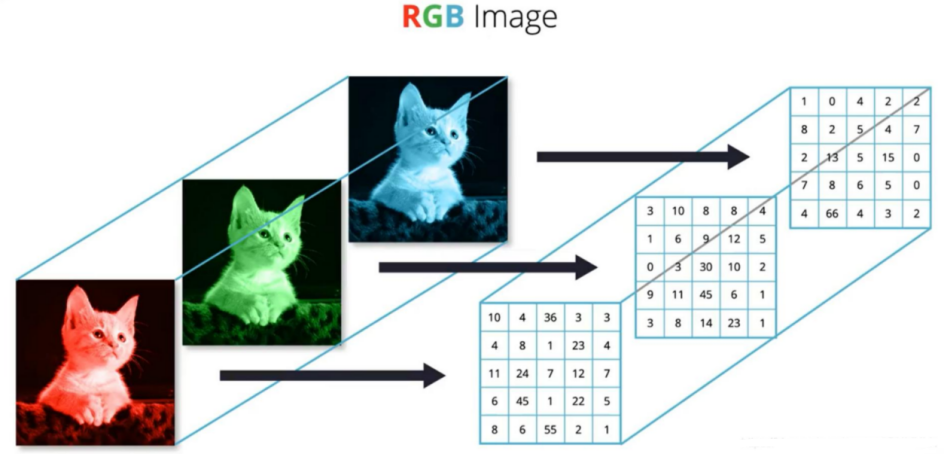
下图是一个猫咪,是彩色的图片,彩色的图标是通过R、G、B,也就是红绿蓝组成的,然后把它们的R、G、B都拿出来就可以组成一个向量,通过像素点的描述就可以进行图片识别
我们的文字都是通过编码来的比如UTF8编码,它包含了全国的文字 ,这么庞大的文字大模型肯定一次没办法搞定,我们的电脑也没办法一次性处理这么多文字,然后就有一个表示学习的概念,就是说让ai自己找文字和文字之间的特征,就是让ai把文字搞成向量,这个向量就是用来描述一个或一个词或一句话,市面上有训练好的向量模型,我们可以直接使用
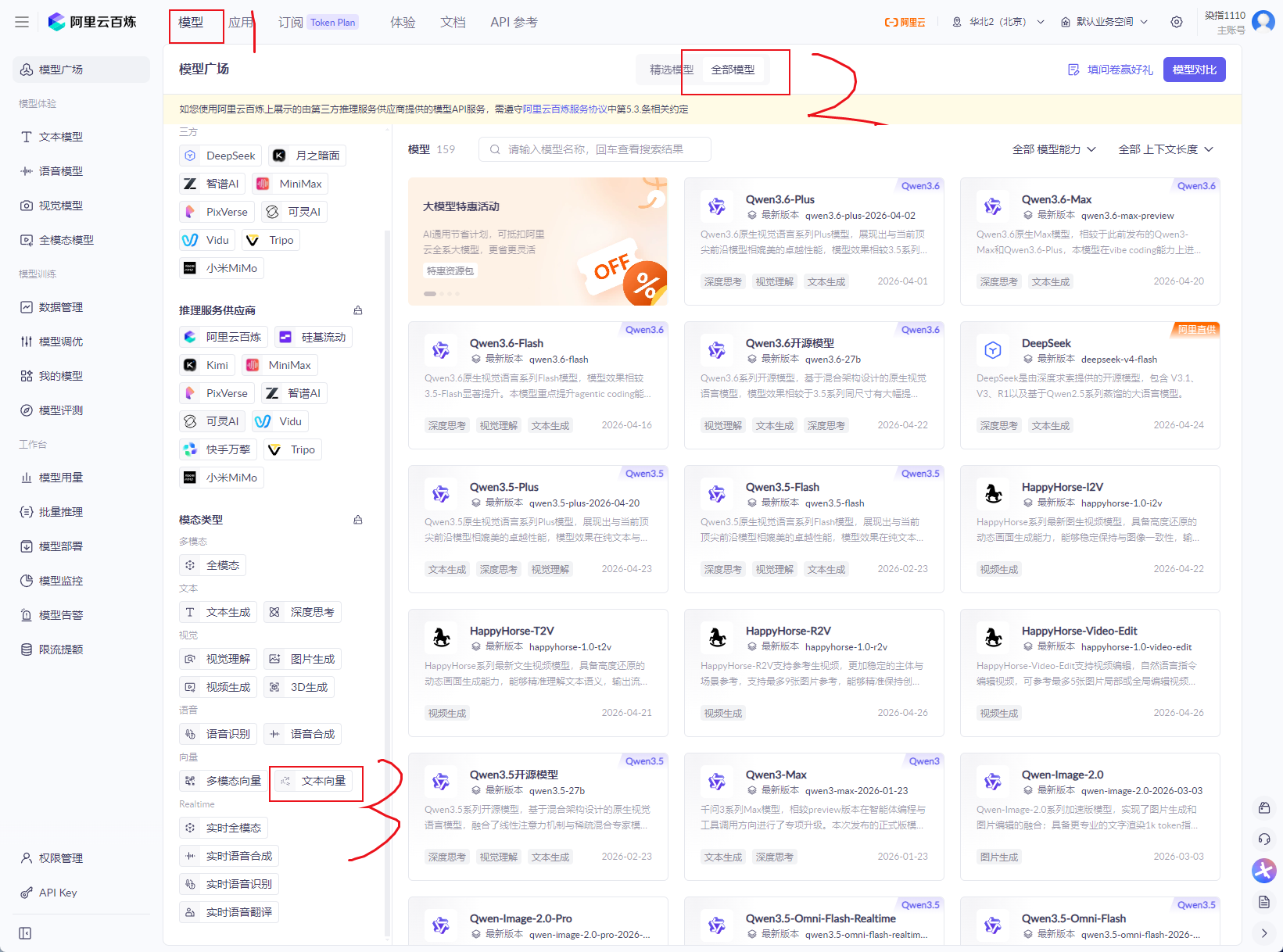
向量模型,这里使用阿里百炼里面的
来到官网:https://bailian.console.aliyun.com/
登录账号后参考下图顺序
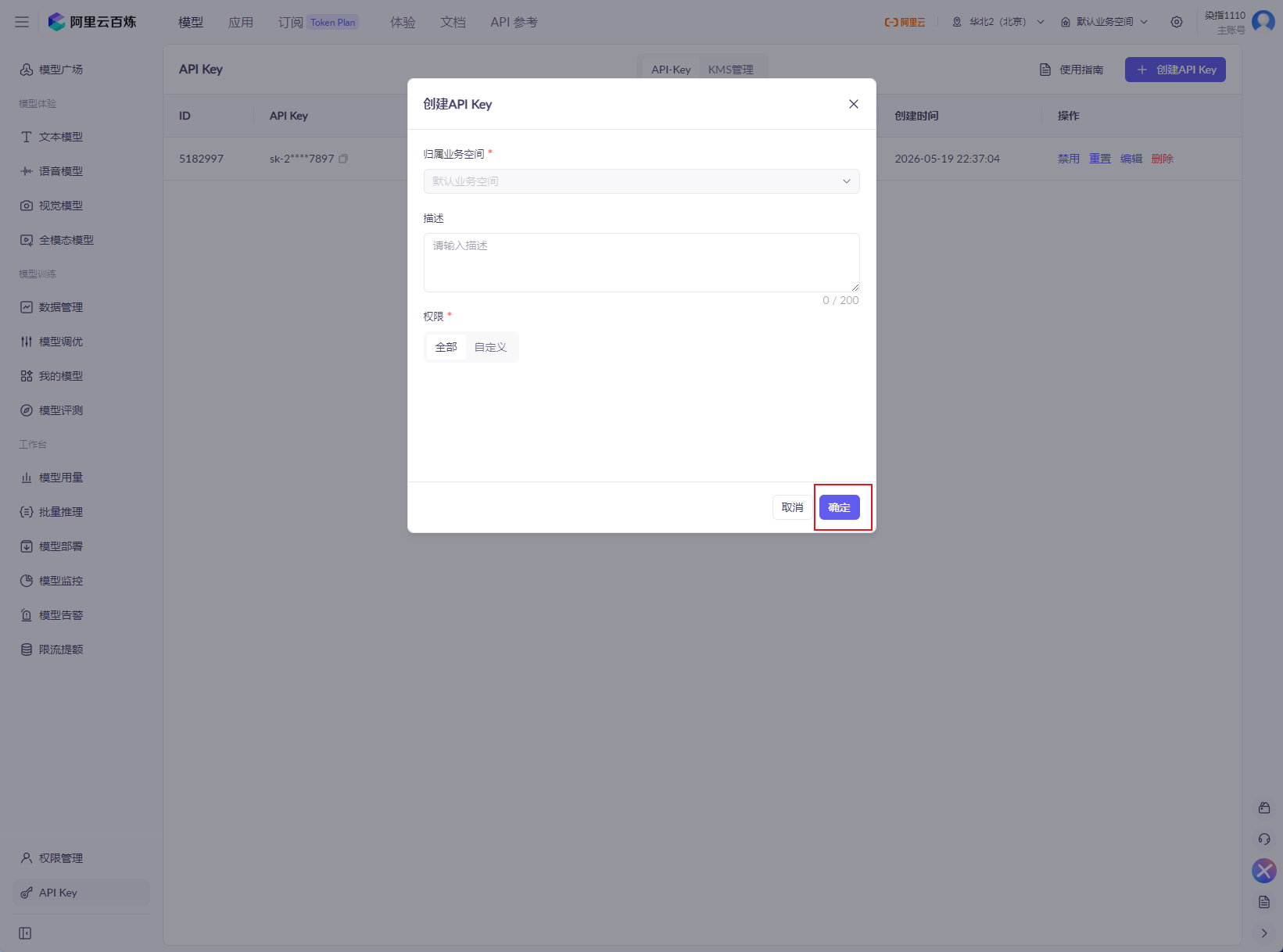
然后选择下图红框的模型
然后点击获取APIKey
然后点击确定,点击确定后会给你一个key
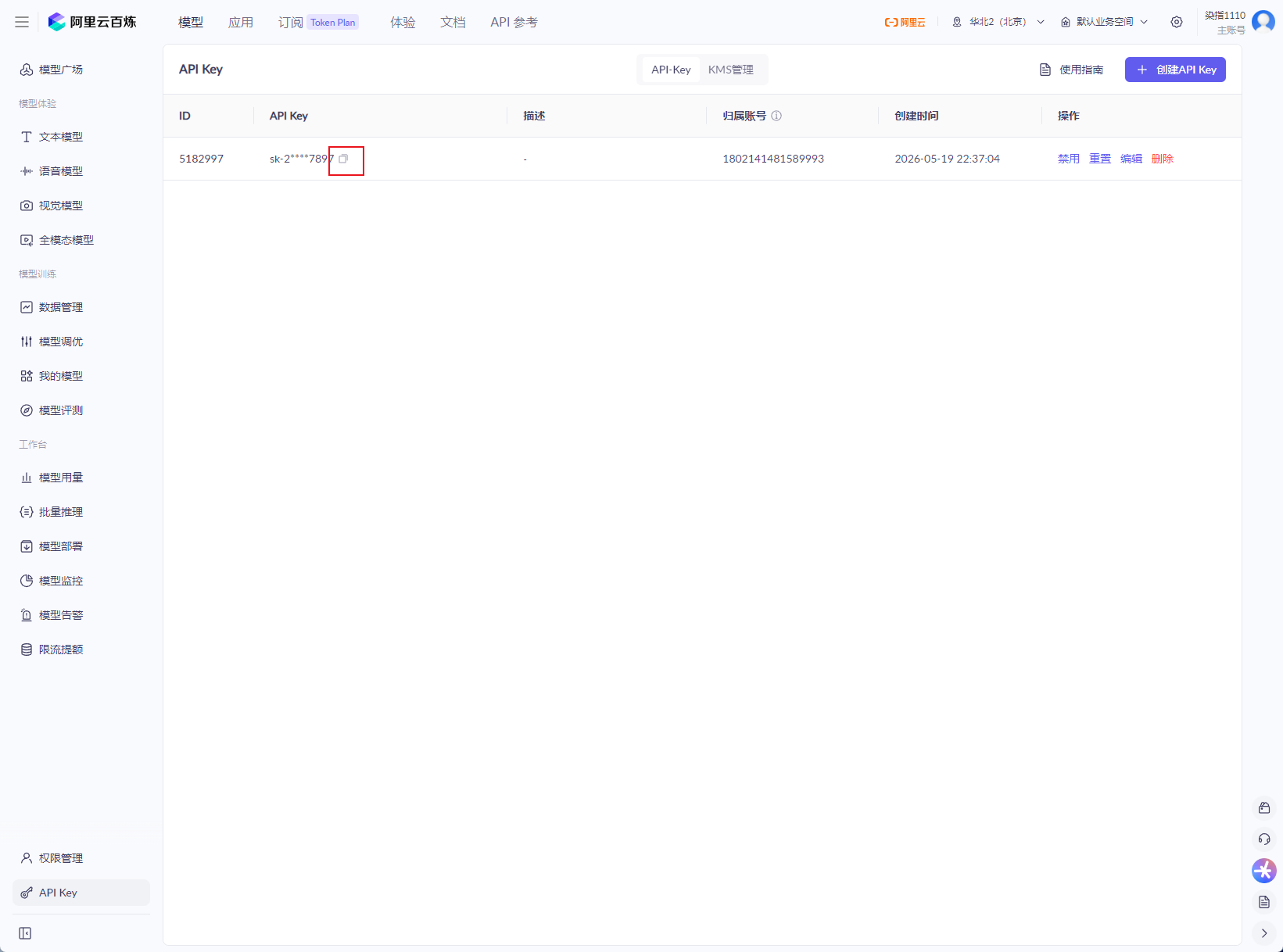
点击下图红框可以复制,这个一会要用
然后点击下图红框
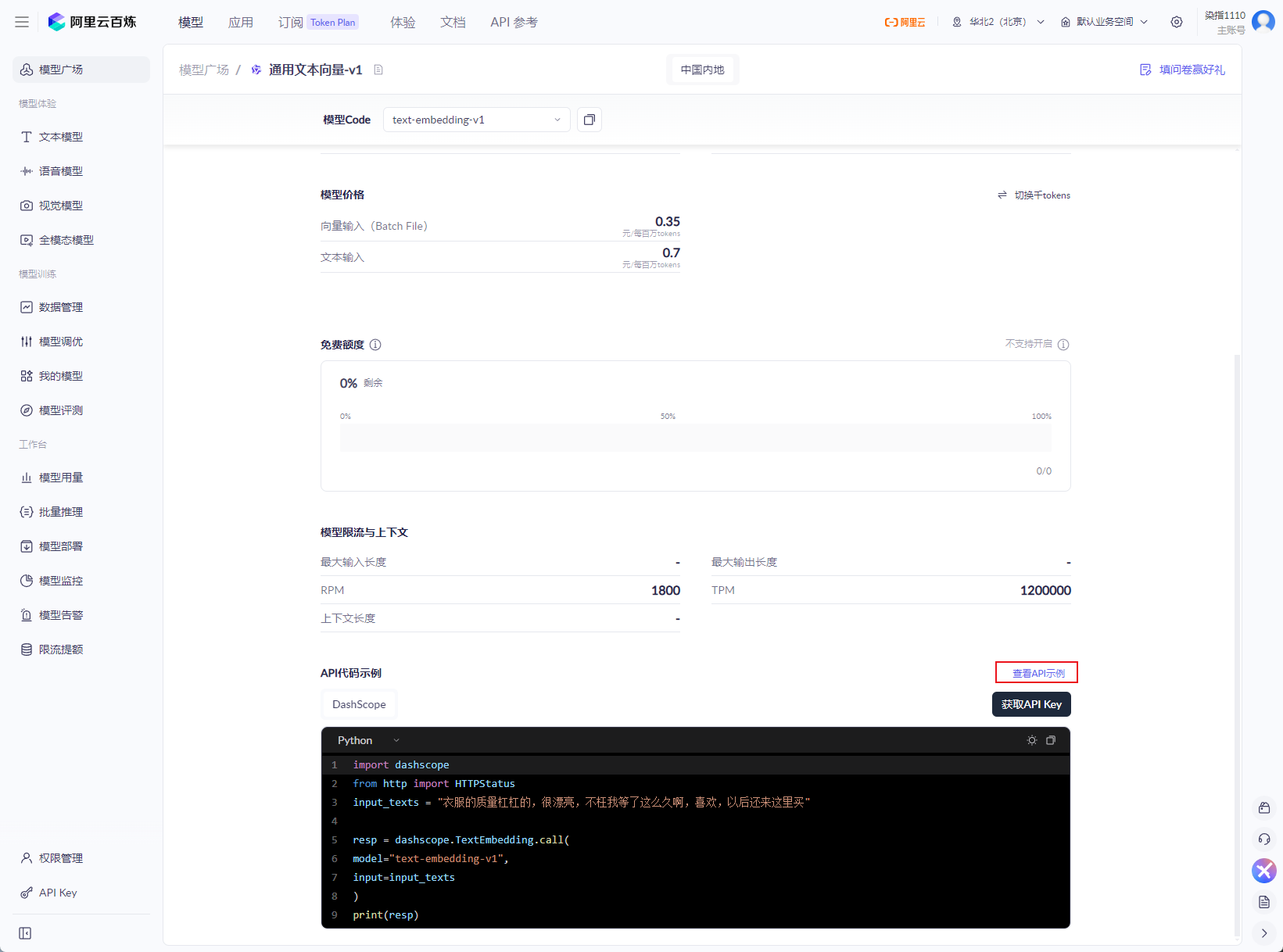
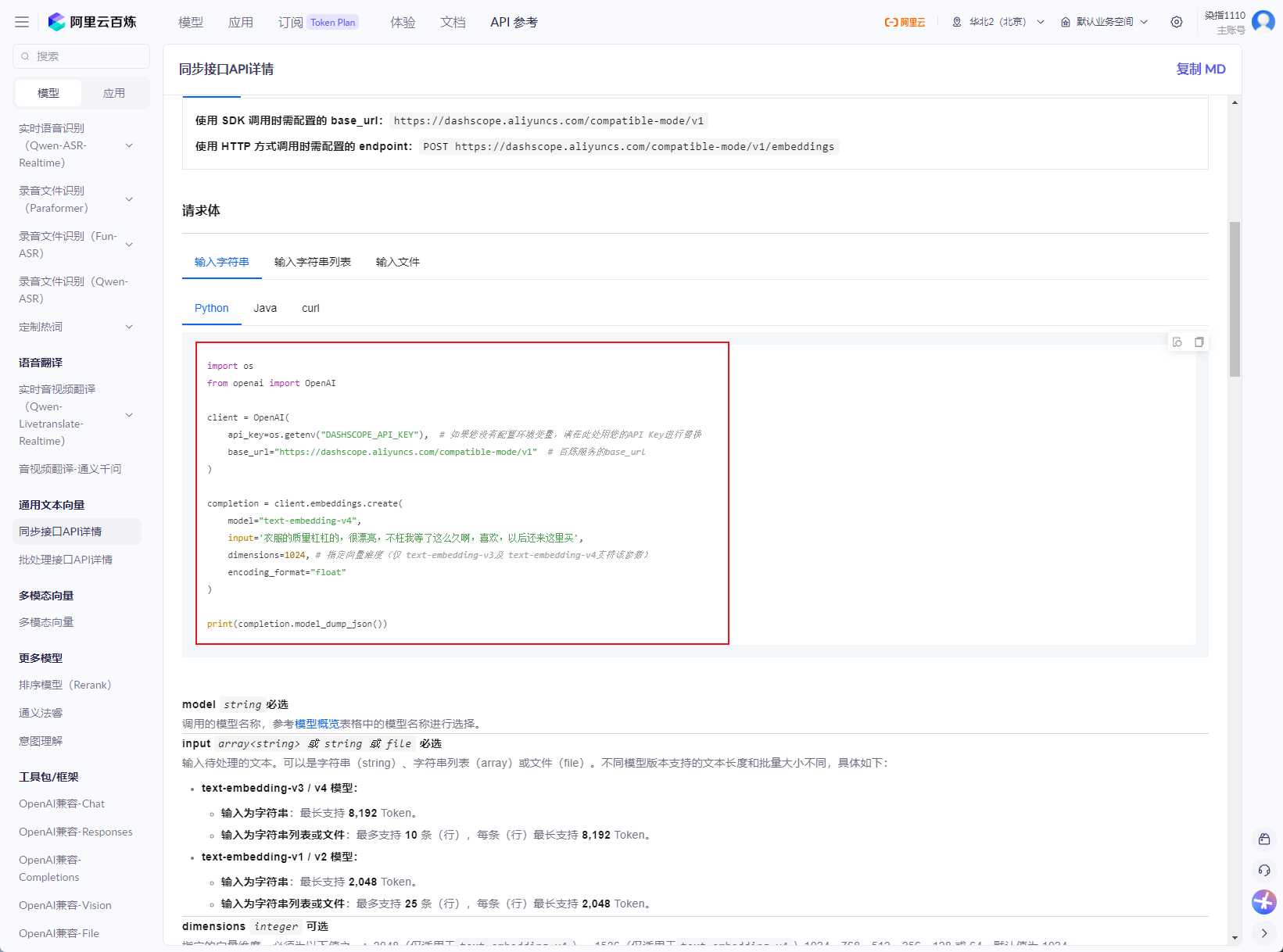
这里有调用示例
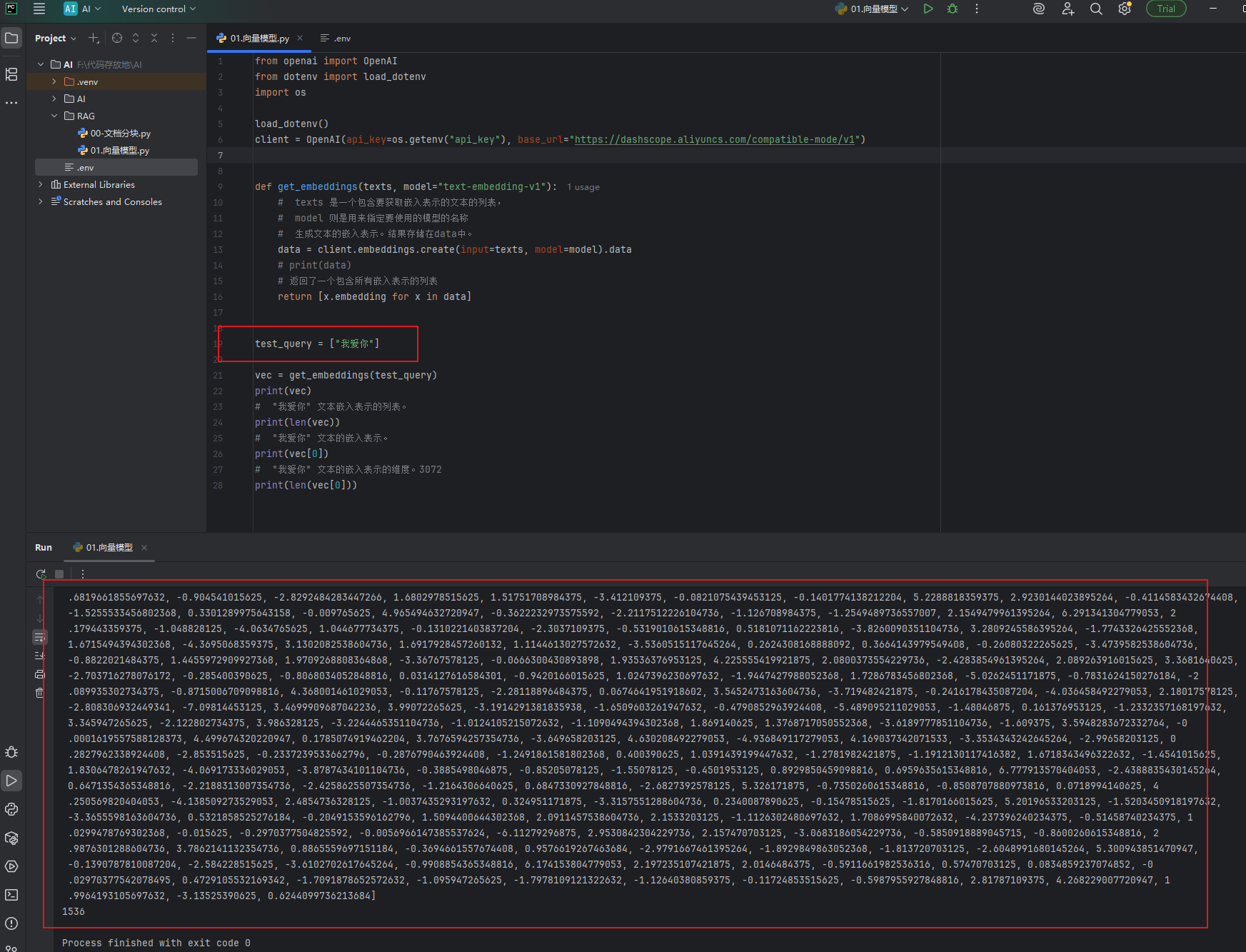
如下图,我爱你这三个字的向量
python# ===================== 1. 导入需要的工具库 ===================== # 导入OpenAI官方的Python客户端库 # 注意:阿里云DashScope提供了【完全兼容OpenAI接口】的服务,所以可以直接用OpenAI的库调用阿里云的模型 from openai import OpenAI # 导入dotenv库:用来读取 .env 文件里的环境变量 # 作用:把敏感的API密钥存在单独的文件里,不会直接写在代码中泄露 from dotenv import load_dotenv # 导入Python内置的os库:用来读取系统环境变量 import os # ===================== 2. 加载环境变量 ===================== # 执行load_dotenv():自动读取当前目录下 .env 文件里的所有配置 # 你需要在代码同目录下创建一个名为 .env 的文件,里面写一行:api_key=你的阿里云API密钥,这里写刚刚获取的APIKey load_dotenv() # ===================== 3. 初始化API客户端 ===================== # 创建OpenAI客户端对象,用来和阿里云的API服务器通信 client = OpenAI( # 从环境变量中读取你自己的阿里云API密钥(替换成你在阿里云控制台获取的DashScope API Key) api_key=os.getenv("api_key"), # 阿里云兼容OpenAI接口的基础地址(固定写法,不能改!) base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) # ===================== 4. 定义获取文本嵌入向量的函数 ===================== # 函数名:get_embeddings # 作用:输入一段或多段文本,返回AI生成的【文本嵌入向量】(把文字变成AI能看懂的数字数组) # 参数1:texts → 要生成向量的文本列表(可以一次传多个文本批量处理) # 参数2:model → 指定使用的嵌入模型名称,默认用阿里云的text-embedding-v1 def get_embeddings(texts, model="text-embedding-v1"): # 调用客户端的embeddings.create方法,向阿里云API发送请求 # input=texts:传入要处理的文本列表 # model=model:指定使用的模型 # .data:API返回结果中,真正包含向量数据的部分 data = client.embeddings.create(input=texts, model=model).data # 处理返回结果:提取每个文本对应的嵌入向量,组成一个新列表返回 # x.embedding:每个结果对象中存储向量的属性 return [x.embedding for x in data] # ===================== 5. 测试代码:生成"我爱你"的嵌入向量 ===================== # 定义测试文本:注意必须是列表格式!哪怕只有一个文本也要用[]包起来 test_query = ["我爱你"] # 调用函数,生成向量,结果存在vec变量中 vec = get_embeddings(test_query) # 打印完整的向量列表(因为传了1个文本,所以列表里只有1个向量) print(vec) # 打印向量列表的长度:结果是1 → 表示生成了1个文本的向量 print(len(vec)) # 打印第一个(也是唯一一个)向量的具体内容:一串3072个数字组成的数组 print(vec[0]) # 打印单个向量的维度:结果是3072 → 阿里云text-embedding-v1模型输出的向量是3072维 print(len(vec[0]))env文件内容
处理使用百炼这种在线平台的,也可以使用我们本地的,下发可以下载一个模型
- Huggingface:https://huggingface.co/
- Hugging Face 是一个专注于 机器学习 (尤其是自然语言处理,NLP)的开源平台和社区,提供从模型开发、训练、部署到共享的一站式工具和资源
- 国内的镜像地址:https://hf-mirror.com/
- 魔搭社区:https://www.modelscope.cn/my/overview
在网址中找到自己需要的文本向量模型,模型的下载推荐使用下发的Python代码,它是通过魔搭社区下载
python# ===================== 整体作用说明 ===================== # 这段代码的功能:从【阿里魔搭社区(ModelScope)】一键下载 BGE 中文嵌入大模型到你电脑本地 # 为什么要下载本地模型? # 1. 不用调用在线API,完全免费,没有调用次数限制 # 2. 速度更快,不用联网也能用 # 3. 数据安全,所有文本都在本地处理,不会上传到云端 # 4. BGE是目前中文效果最好的嵌入模型之一,专门用来做RAG知识库、文本相似度匹配 # ===================== 1. 导入下载工具 ===================== # 从 modelscope 库中导入 snapshot_download 函数 # snapshot_download:魔搭官方提供的【一键下载整个模型仓库】的工具 # 会自动下载模型的所有文件(权重、配置、说明文档等),还支持断点续传 from modelscope import snapshot_download # 【必须先执行的安装命令】 # 如果运行报错找不到 modelscope,就在终端输入下面这行安装 # pip install modelscope # ===================== 2. 执行模型下载 ===================== # 调用 snapshot_download 函数,下载指定模型到本地 # 返回值 model_dir:模型下载完成后,本地的完整文件夹路径 model_dir = snapshot_download( # 第一个参数:模型在魔搭社区的【唯一ID】(固定写法,不能改) # BAAI/bge-large-zh-v1.5:北京智源研究院开源的 大尺寸 中文 嵌入模型 v1.5版本 # 模型大小:约1.3GB,下载前请确保D盘有至少2GB可用空间 "BAAI/bge-large-zh-v1.5", # 第二个参数:模型在你电脑上的【保存路径】 # 注意:Windows系统路径有两种正确写法,推荐用第一种(原始字符串) # 写法1(推荐):r"D:\LLM\Local_model" → 加r前缀,不用管反斜杠转义 # 写法2:"D:\\LLM\\Local_model" → 用两个反斜杠代替一个 # ❌ 错误写法:"D:\LLM\Local_model" → 单个反斜杠会被当成转义字符,导致路径错误 cache_dir=r"D:\LLM\Local_model" ) # 下载完成后,打印模型的本地完整路径 print(f"✅ 模型下载完成!本地路径:{model_dir}")下载完成就是一些权重文件
到这我们就有了向量,也就说我们现在可以把文档进行分块,然后进行向量,接下来是索引的功能,也就是怎么就通过我们的问题找到了我们知识库里的参考资料呢?
这也就是向量的相似度的计算
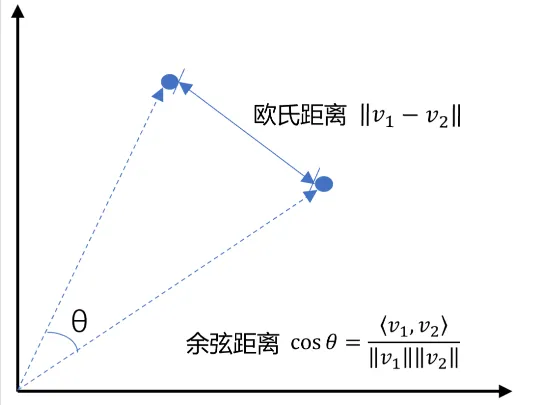
计算方式有余弦相似度和欧式距离L2
余弦相似度
欧式距离L2
余弦相似度和欧式距离L2说明


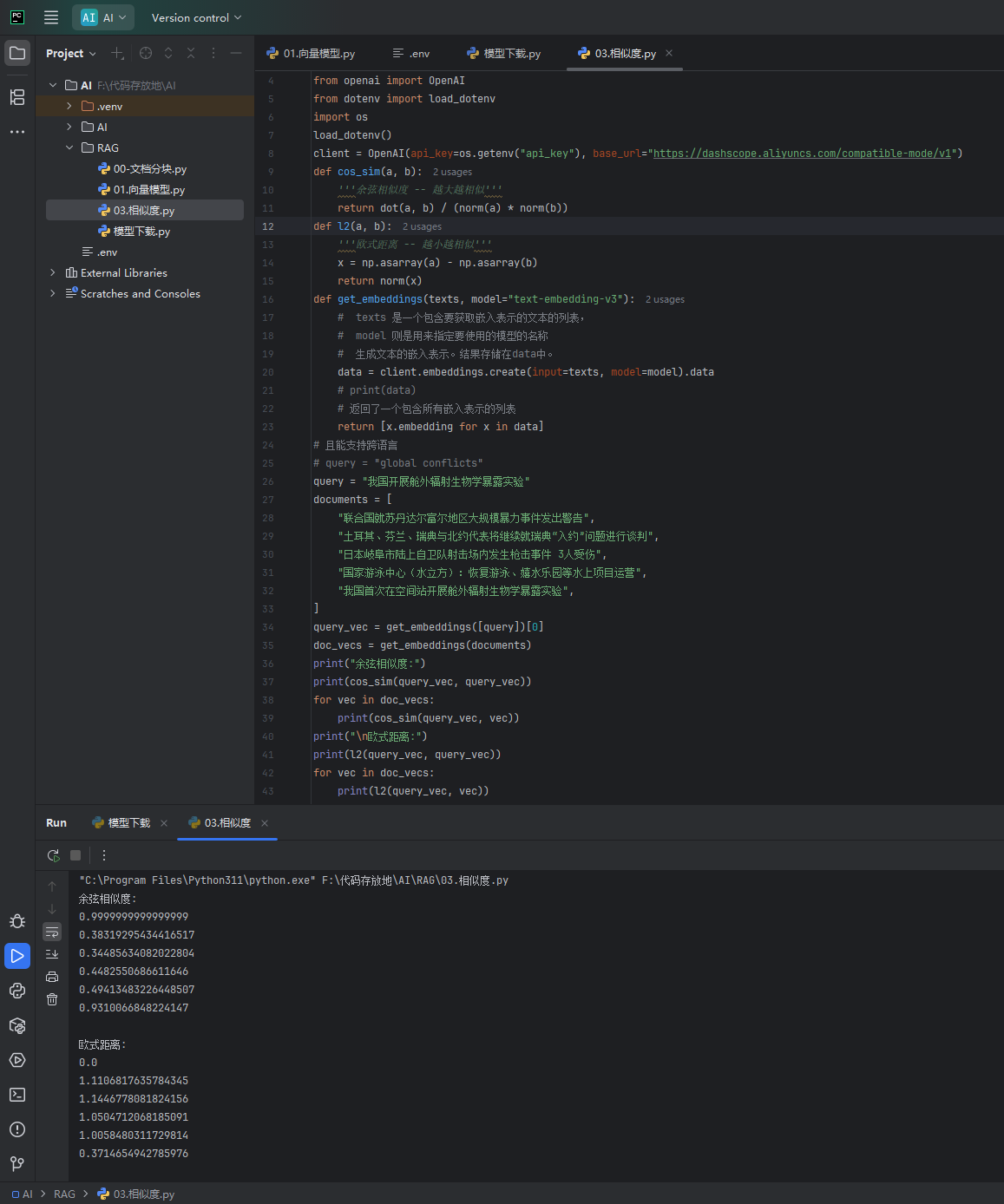
如下图:通过把问题进行向量,然后把知识进行分块和向量,然后进行余弦计算和欧氏距离计算就可以得到相似度了,也就是可以通过问题找到资料了,这里要注意,我们问题使用的向量模型和知识库使用的向量模型要一致,否则会不准,因为不同的模型训练的资料不同会导致权重不一样,也就导致向量不一样
python
# ===================== 1. 导入需要的工具库 =====================
# 导入numpy库:Python最常用的数值计算库,专门处理数组、矩阵、数学运算
import numpy as np
# 从numpy中单独导入点积函数dot和范数函数norm,后面计算相似度会用到
from numpy import dot
from numpy.linalg import norm
# 导入OpenAI客户端库:阿里云DashScope提供了完全兼容OpenAI的接口,所以可以直接用这个库
from openai import OpenAI
# 导入dotenv库:用来读取 .env 文件里的敏感配置(比如API密钥)
from dotenv import load_dotenv
# 导入Python内置的os库:用来读取系统环境变量
import os
# ===================== 2. 加载环境变量和初始化API客户端 =====================
# 自动读取当前目录下 .env 文件里的所有配置
# 你需要在代码同目录下创建 .env 文件,内容为:api_key=你的阿里云DashScope API密钥
load_dotenv()
# 创建OpenAI客户端,用来和阿里云服务器通信
client = OpenAI(
# 从环境变量中读取你的API密钥(替换成你自己在阿里云控制台获取的密钥)
api_key=os.getenv("api_key"),
# 阿里云兼容OpenAI接口的固定基础地址,不能修改
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# ===================== 3. 定义两个相似度计算函数 =====================
# 函数1:余弦相似度计算
# 作用:计算两个向量之间的夹角余弦值,用来衡量文本的相似程度
# 结果范围:[-1, 1] → 越接近1,两个文本越相似;越接近-1,越相反;0表示无关
def cos_sim(a, b):
'''余弦相似度 -- 数值越大,两个文本越相似'''
# 公式:两个向量的点积 ÷ (向量a的长度 × 向量b的长度)
return dot(a, b) / (norm(a) * norm(b))
# 函数2:欧式距离计算
# 作用:计算两个向量在空间中的直线距离,也用来衡量文本相似程度
# 结果范围:[0, +∞) → 越接近0,两个文本越相似;数值越大,差异越大
def l2(a, b):
'''欧式距离 -- 数值越小,两个文本越相似'''
# 先把两个向量转换成numpy数组,再相减得到差值向量
x = np.asarray(a) - np.asarray(b)
# 计算差值向量的长度,就是两个向量之间的欧式距离
return norm(x)
# ===================== 4. 定义获取文本嵌入向量的函数 =====================
# 函数作用:输入一段或多段文本,返回AI生成的文本嵌入向量(把文字变成AI能计算的数字数组)
# 参数1:texts → 要生成向量的文本列表(必须是列表格式,哪怕只有一个文本)
# 参数2:model → 指定使用的嵌入模型,这里用最新的text-embedding-v3(效果比v1更好)
def get_embeddings(texts, model="text-embedding-v3"):
# 调用阿里云API,发送生成向量的请求
# input=texts:传入要处理的文本列表
# model=model:指定使用的模型
# .data:API返回结果中真正包含向量数据的部分
data = client.embeddings.create(input=texts, model=model).data
# 提取每个文本对应的嵌入向量,组成新列表返回
# x.embedding:每个结果对象中存储向量的属性
return [x.embedding for x in data]
# ===================== 5. 测试:计算查询文本和多个文档的相似度 =====================
# 定义查询文本:我们要找和这句话最相似的文档
query = "我国开展舱外辐射生物学暴露实验"
# 定义待匹配的文档列表:我们要从这些文档中找出和查询最相关的
documents = [
"联合国就苏丹达尔富尔地区大规模暴力事件发出警告",
"土耳其、芬兰、瑞典与北约代表将继续就瑞典"入约"问题进行谈判",
"日本岐阜市陆上自卫队射击场内发生枪击事件 3人受伤",
"国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营",
"我国首次在空间站开展舱外辐射生物学暴露实验",
]
# 生成查询文本的嵌入向量
# [query]:把单个文本包装成列表,符合函数要求
# [0]:因为函数返回的是列表,我们只需要第一个(也是唯一一个)向量
query_vec = get_embeddings([query])[0]
# 批量生成所有待匹配文档的嵌入向量
doc_vecs = get_embeddings(documents)
# ===================== 6. 打印计算结果 =====================
print("=== 余弦相似度计算结果(越接近1越相似) ===")
# 先打印查询文本和自己的相似度(应该是1.0,完全相同)
print(f"查询文本和自己的相似度:{cos_sim(query_vec, query_vec):.4f}")
# 循环计算查询文本和每个文档的相似度
for i, vec in enumerate(doc_vecs):
similarity = cos_sim(query_vec, vec)
print(f"和文档{i+1}的相似度:{similarity:.4f} → {documents[i]}")
print("\n=== 欧式距离计算结果(越接近0越相似) ===")
# 先打印查询文本和自己的距离(应该是0.0,完全相同)
print(f"查询文本和自己的距离:{l2(query_vec, query_vec):.4f}")
# 循环计算查询文本和每个文档的距离
for i, vec in enumerate(doc_vecs):
distance = l2(query_vec, vec)
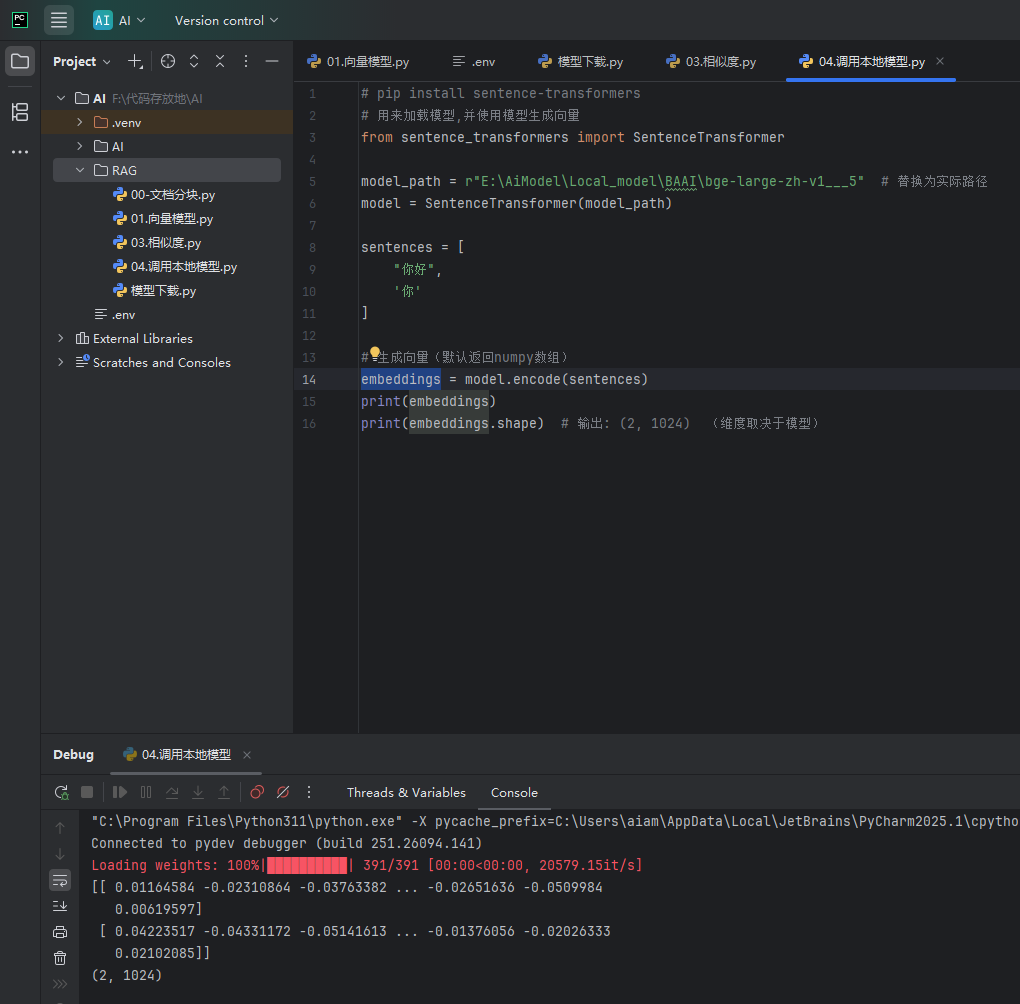
print(f"和文档{i+1}的距离:{distance:.4f} → {documents[i]}")这种向量的模型是很消耗Token的,因为知识库的文档肯定会成千上万的,所以一般会使用本地模型,本地模型的下载上方说过,这写下载好的模型怎样调用,如下图调用本地模型
python
# ===================== 整体作用说明 =====================
# 这段代码的功能:加载你电脑本地已经下载好的 BGE 中文嵌入模型
# 把任意中文文本转换成 AI 能计算的数字向量(文本嵌入)
# 完全离线运行,不用联网,没有调用次数限制,速度比在线API快很多
# 生成的向量可以直接用来做:文本相似度匹配、RAG知识库检索、语义搜索
# 【必须先执行的安装命令】
# 如果运行报错找不到 sentence-transformers,就在终端输入下面这行安装
# pip install sentence-transformers
# ===================== 1. 导入核心工具 =====================
# 从 sentence_transformers 库中导入 SentenceTransformer 类
# SentenceTransformer:专门用来加载和使用各种嵌入模型的工具
# 是目前最流行、最简单的本地嵌入模型调用方式,支持几乎所有开源嵌入模型
from sentence_transformers import SentenceTransformer
# ===================== 2. 指定本地模型路径 =====================
# 把这里的路径替换成你自己电脑上 BGE 模型的实际文件夹路径
# 注意:Windows系统路径必须加 r 前缀!防止反斜杠转义导致路径错误
# 路径要精确到模型的根文件夹(里面包含 config.json、pytorch_model.bin 等文件)
model_path = r"E:\AiModel\Local_model\BAAI\bge-large-zh-v1___5"
# ===================== 3. 加载本地模型到内存 =====================
# 创建 SentenceTransformer 对象,传入本地模型路径
# 这一步会把模型文件从硬盘加载到电脑内存中
# 第一次加载会慢一点(几秒钟),加载完成后后续生成向量速度极快
model = SentenceTransformer(model_path)
# ===================== 4. 准备要生成向量的文本 =====================
# 定义一个列表,存放所有需要生成向量的文本
# 支持批量处理:一次可以传入任意多个文本,模型会一次性生成所有向量
sentences = [
"你好",
"你"
]
# ===================== 5. 核心:生成文本嵌入向量 =====================
# 调用模型的 encode 方法,传入文本列表
# 作用:把每一段文本转换成对应的数字向量
# 返回值 embeddings:是一个 numpy 数组,形状为 (文本数量, 向量维度)
# 默认返回 numpy 数组,也可以通过参数 convert_to_tensor=True 转换成 PyTorch 张量
embeddings = model.encode(sentences)
# ===================== 6. 打印结果查看 =====================
# 打印所有生成的向量
# 你会看到一堆浮点数组成的数组,每个文本对应一个1024个数字的数组
print("生成的文本向量:")
print(embeddings)
# 打印向量的形状(维度信息)
# 输出结果:(2, 1024)
# 解释:
# 第一个数字 2 → 表示我们传入了2个文本,生成了2个向量
# 第二个数字 1024 → 表示每个向量有1024个维度(BGE-large-zh-v1.5的固定维度)
print("\n向量形状:")
print(embeddings.shape)下放是ai生成的关于相似度详细的说明,可能生成的不好,可以自己问ai
向量的说明(AI 数据的本质)
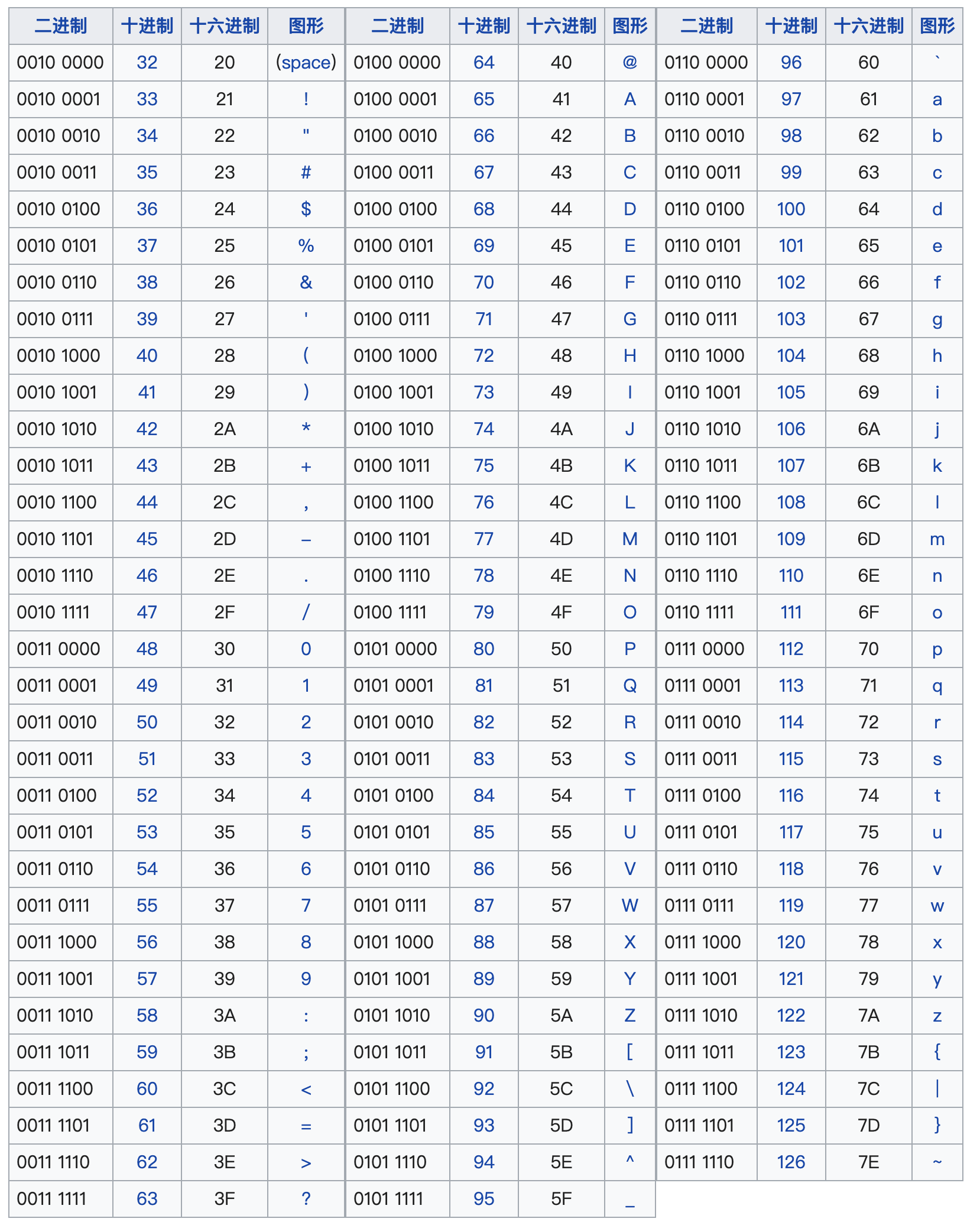
电脑天生只认识0 和 1(二进制) ,所有数据(文字、图片、声音)最终都要转成 0 和 1 才能存进电脑。但这些「存储用的数字」有一个致命问题:完全不能表达语义,AI 根本看不懂。
1. 第一层:最底层的存储数字(无任何语义)
所有数据的终极形态都是二进制,这是电脑的物理限制。
- 规则:用 8 个 0/1 组成 1 个字节(Byte),表示 0-255 的整数
- 示例:
- 数字
5→ 二进制00000101- 字母
A→ 二进制01000001- 纯黑像素 → 二进制
00000000- 纯白像素 → 二进制
11111111问题 :这些数字是人为规定的,和语义毫无关系。比如:
- 字母
A(65)和B(66)数字差 1,但语义上只是相邻字母- 中文「我」(25105)和「你」(20320)数字差 4785,但语义上都是人称代词,非常接近
- 两张不同角度的苹果图片,像素数字可能差很多,但语义上都是苹果
2. 第二层:人类设计的编码(解决「存」,不解决「懂」)
为了存不同类型的数据,人类设计了各种编码规则,但本质还是「人为规定的数字映射」。
(1)文字编码:ASCII → Unicode → UTF-8
- ASCII
:给 128 个英文字母 / 符号分配 0-127 的数字
- 示例:
a→97,b→98,1→49
- Unicode
:给全球所有字符(中文、日文、 emoji 等)分配唯一数字
- 示例:「我」→U+6211(十进制 25105),「爱」→U+7231(十进制 29233)
- UTF-8
:把 Unicode 数字转成二进制存储的规则(中文用 3 个字节)
- 示例:「我」→二进制
11100110 10001000 10001001(2)图片编码:像素数字
- 灰度图:每个像素 1 个数字(0 = 纯黑,255 = 纯白)
- 彩色图(RGB):每个像素 3 个数字(R 红、G 绿、B 蓝,各 0-255)
- 示例:纯红像素→255, 0, 0,纯蓝像素→0, 0, 255
核心问题 :所有这些编码都只是「存储工具」,数字的大小和语义没有任何关联。AI 拿到这些数字,只能存,不能计算「两个东西像不像」。
第三层:向量(Embedding)------AI 的「语义编码」(解决「懂」)
为了让 AI 能理解语义,科学家发明了向量(嵌入) :让 AI 自己从海量数据中学习,把每个文字 / 图片 / 声音,转成一串能表达语义的数字数组。
核心规则:
- 语义越接近的两个东西,它们的向量在「n 维空间」里的距离就越近
- 向量的每个数字,对应一个 AI 学习到的「语义特征」(比如「是否是水果」「是否是红色」「是否是动物」)
向量的定义公式(结合 AI 语义解释)
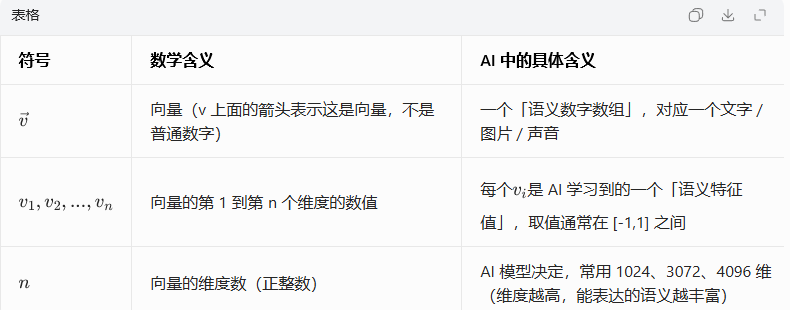
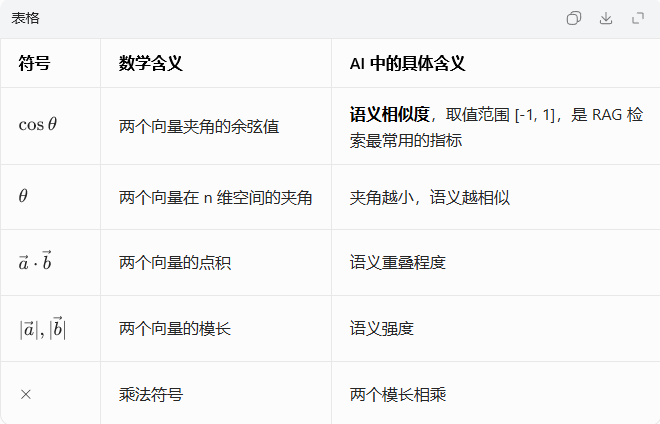
符号全解释(结合 AI):
示例(3 维向量,方便理解):
这就是 AI 能「看懂」图片和文字都是红苹果的原因!它们的向量在 3 维空间里几乎重合。
二、向量的核心公式 ------ 全都是为了「计算语义相似度」
向量的所有公式,本质上都是为了计算两个向量在 n 维空间里的「距离」或「夹角」,从而判断它们的语义相似度。下面每个公式都结合「AI 语义」来解释。
1. 向量的模长(大小)公式 ------ 语义的「强度」
符号全解释(结合 AI):
一步一步示例计算:
计算文字「红苹果」的向量a=0.9,0.8,0.05的模长:
AI 中的意义:如果有另一个向量e=0.45,0.4,0.025(模长≈0.602),它的语义是「有点像红苹果」,强度只有a的一半。
2. 向量的点积公式 ------ 语义的「重叠程度」
符号全解释(结合 AI):
一步一步示例计算:
3. 余弦相似度公式 ------RAG 检索的核心(只看语义,不看强度)
符号全解释(结合 AI):
核心优势:
余弦相似度只看向量的方向(语义),不看模长(强度)。比如:
- 「非常红的苹果」和「有点红的苹果」,模长不同,但方向几乎一样,余弦相似度≈1
- 这正是我们需要的:只要语义相同,不管强度如何,都算相似
一步一步示例计算:
计算「红苹果」a=0.9,0.8,0.05和「香蕉」b=0.85,0.1,0.03的余弦相似度:
再计算「红苹果」a和红苹果图片d=0.88,0.78,0.04的余弦相似度:
4. 欧氏距离公式 ------ 另一种相似度计算(看空间直线距离)
符号全解释(结合 AI):
一步一步示例计算:
三、完整流程串联:从原始数据到 AI 理解
现在把所有内容串起来,看一个完整的「AI 看懂数据并回答问题」的过程:
示例:用户问「什么水果是红色的?」
四、终极总结(一张图的逻辑)
原始数据(文字/图片) ↓ 存储编码(二进制/ASCII/Unicode/像素)→ 只能存,不能懂 ↓ 向量(Embedding)→ AI学习的语义数字,$\vec{v} = [v_1, v_2, ..., v_n]$ ↓ 相似度计算(余弦相似度$\cos\theta$ / 欧氏距离$d$)→ 找到最相似的内容 ↓ AI理解与生成 → 输出符合事实的回答核心结论:
- AI 中数据的本质是「数字」,但只有向量是「有语义的数字」
- 向量的所有公式,都是为了计算语义相似度
- 向量是连接「人类能看懂的原始数据」和「电脑能计算的数字」的唯一桥梁
一、先搞懂:为什么必须要有表示学习?
1. 传统手动编码的致命缺陷
前面讲的 ASCII、Unicode、像素、甚至 One-hot 编码,都是人类手动设计的规则,它们有两个无法解决的问题:
(1)维度灾难(One-hot 编码)
(2)语义鸿沟(所有手动编码)
手动编码的数字和语义完全无关:
- 「我」(Unicode=25105)和「你」(Unicode=20320)数字差 4785,但语义都是人称代词,非常接近
- 「猫」(Unicode=29483)和「狗」(Unicode=29399)数字差 84,但语义都是动物,非常接近
- 两张不同角度的苹果图片,像素数字可能差 90%,但语义完全相同
2. 表示学习的核心思想
放弃人类手动设计编码,让 AI 自己从海量数据中学习出 "最好的数字表示"。
- 什么是 "最好的表示"?
- 维度低(几百 / 几千维,不是几万维)
- 语义越接近的东西,向量距离越近
- 向量的每个维度对应一个可解释的语义特征(比如 "是否是水果"" 是否是红色 ")
二、表示学习的定义与核心公式
1. 表示学习的严格定义
表示学习是一种机器学习技术,它通过自动学习一个映射函数,将原始的高维、无意义的存储数据,转换为低维、有语义的向量表示。
2. 表示学习的核心映射公式
符号全解释(结合 AI 语义):
通俗翻译:
3. 表示学习的目标函数(AI 怎么 "学会" 好的表示)
表示学习的目标是:让相似的原始数据,在表示空间中距离更近;让不同的原始数据,在表示空间中距离更远。
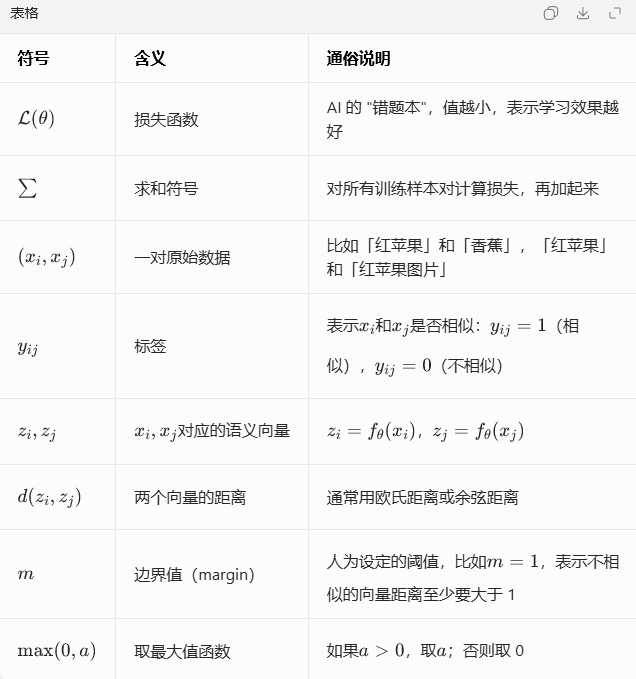
最常用的目标函数(对比损失函数):
符号全解释(一步一步讲):
目标函数的通俗解释:
三、表示学习 vs Embedding:过程 vs 结果
很多人会混淆这两个概念,这里用翻译官类比彻底讲清楚:
- 表示学习:训练一个 "翻译官" 的过程。这个翻译官的任务是:把人类能看懂的文字 / 图片,翻译成 AI 能看懂的 "语义数字"(向量)。
- Embedding(嵌入 / 向量):翻译官翻译出来的结果。也就是那个低维的数字数组。
再用公式对应:
四、表示学习的学习过程示例(一步一步)
用我们之前的 3 维语义空间例子,看 AI 是怎么通过表示学习,自动发现 "水果、红色、动物" 这三个语义特征的:
1. 准备训练数据
AI 会看到海量的文本和图片对:
- 相似对:「红苹果」和「红苹果图片」、「香蕉」和「香蕉图片」、「猫」和「猫图片」
- 不相似对:「红苹果」和「猫」、「香蕉」和「狗」、「红苹果」和「汽车」
2. 初始化模型参数
一开始,AI 的参数(\theta)是随机的,生成的向量也是随机的:
- 「红苹果」→ (0.1, 0.5, 0.3)
- 「香蕉」→ (0.7, 0.2, 0.6)
- 「猫」→ (0.4, 0.8, 0.1)
此时,「红苹果」和「猫」的距离比「红苹果」和「香蕉」的距离更近,完全不符合语义。
3. 计算损失函数
4. 反向传播调整参数
AI 通过反向传播算法,计算每个参数(\theta)对损失的贡献,然后调整参数,让损失变小。
- 比如:把「红苹果」向量的第 1 维调大(水果程度变高),第 3 维调小(动物程度变低)
- 把「猫」向量的第 1 维调小(水果程度变低),第 3 维调大(动物程度变高)
5. 重复迭代
五、表示学习的主流类型
1. 监督式表示学习
- 特点:需要人工标注数据(告诉 AI 哪些是相似的,哪些是不相似的)
- 缺点:标注成本高,数据量有限
- 示例:早期的图像分类模型(AlexNet)
2. 无监督式表示学习
- 特点:不需要任何标注,AI 自己从数据中发现规律
- 优点:可以利用海量无标注数据
- 示例:聚类算法、主成分分析(PCA)
3. 自监督式表示学习(现在的主流)
- 特点:自己给自己造标签,从数据本身生成监督信号
- 优点:标注成本为 0,可以利用互联网上的所有数据
- 现在所有的大模型和 Embedding 模型,都是自监督表示学习的结果:
- BERT:掩码语言模型(MLM)→ 遮住句子中的一个词,让 AI 预测这个词
- GPT:自回归语言模型 → 给定前面的词,预测下一个词
- CLIP:对比学习 → 让文字和对应的图片向量靠近,和不对应的图片向量远离
六、表示学习在 RAG 中的核心作用
RAG 的整个流程,完全依赖表示学习生成的高质量 Embedding 向量:
- 索引阶段:用表示学习模型,把所有文档转成语义向量,存入向量数据库
- 检索阶段:用同一个表示学习模型,把用户问题转成语义向量,然后计算和文档向量的相似度,找到最相关的文档
- 生成阶段:把相关文档和用户问题一起传给大模型,生成回答
如果表示学习模型不好,生成的向量语义不准,那么检索就会找到不相关的文档,RAG 的回答就会出现幻觉、错误。
七、更新完整流程:从原始数据到 AI 理解
现在把表示学习加入到我们之前的完整流程中:
原始数据(文字/图片) ↓ 存储编码(二进制/ASCII/Unicode/像素)→ 只能存,不能懂 ↓ 表示学习(训练映射函数$f_\theta$)→ AI自动学习语义表示的过程 ↓ 向量(Embedding)→ $z=f_\theta(x)$,AI能理解的语义数字 ↓ 相似度计算(余弦相似度$\cos\theta$ / 欧氏距离$d$)→ 找到最相似的内容 ↓ AI理解与生成 → 输出符合事实的回答
八、终极总结
- 表示学习是 AI 理解世界的核心:没有它,AI 永远只能处理 "存储用的数字",永远看不懂语义
- 表示学习的本质:让 AI 自动学习一个映射函数,把高维无意义的原始数据,转成低维有语义的向量
- 表示学习 vs Embedding:过程 vs 结果
- RAG 的基石:RAG 的检索精度,完全取决于表示学习模型生成的 Embedding 质量