上篇热文:Linux线程控制:从用户态控制到内核级克隆全链路解析
目录
[引言:Linux 下的"线程"究竟是什么?](#引言:Linux 下的“线程”究竟是什么?)
[一、揭秘线程 ID 与进程地址空间布局](#一、揭秘线程 ID 与进程地址空间布局)
[1. 虚拟地址 vs LWP:pthread_t 的物理本质](#1. 虚拟地址 vs LWP:pthread_t 的物理本质)
[2. 原生线程库 NPTL 的内存布局](#2. 原生线程库 NPTL 的内存布局)
[3. 解密 pthread_join 返回 22 的深层原因](#3. 解密 pthread_join 返回 22 的深层原因)
[1. 普通全局变量 vs 线程局部存储](#1. 普通全局变量 vs 线程局部存储)
[2. __thread 的局限性与现代 C++ 的演进](#2. __thread 的局限性与现代 C++ 的演进)
[现代 C++ 解决方案:thread_local](#现代 C++ 解决方案:thread_local)
[三、原生线程库 NPTL 与 clone 底层源码追溯](#三、原生线程库 NPTL 与 clone 底层源码追溯)
[1. 空间的申请与 struct pthread (TCB) 的定位](#1. 空间的申请与 struct pthread (TCB) 的定位)
[2. 深入内核:clone 系统调用与资源共享](#2. 深入内核:clone 系统调用与资源共享)
[四、面向对象思想下的 C++ 优雅线程封装](#四、面向对象思想下的 C++ 优雅线程封装)
[1. 解决方案:静态成员函数桥接与 this 指针穿透](#1. 解决方案:静态成员函数桥接与 this 指针穿透)
[2. 修复 static int gnum 头文件重包含 Bug](#2. 修复 static int gnum 头文件重包含 Bug)
[3. 最终源码](#3. 最终源码)
引言:Linux 下的"线程"究竟是什么?
在传统的操作系统教科书中,进程是资源分配的最小单位,线程是 CPU 调度的最小单位。但在 Linux 内核的设计者眼中,Linux 并没有真正意义上的"线程"概念。
Linux 统一使用 task_struct 结构体来描述所有的执行流。无论是进程还是线程,在 CPU 看来都是一个 task_struct(进程控制块,PCB)。
-
如果两个
task_struct拥有完全独立的进程虚拟地址空间(mm_struct),那它们就是两个不同的进程; -
如果两个
task_struct共享同一个进程虚拟地址空间,将进程内的资源(代码、数据、堆、文件描述符等)合理分配并同时运行,那么它们就是同一个进程内的多个线程。
因此,在 Linux 之下,线程又被称为轻量级进程(LWP, Light Weight Process)。系统调度的基本单位是 LWP,而在 CPU 眼中,这些 LWP 相比传统进程要更加轻量化,因为它们切换时不需要切换地址空间,甚至不需要刷新 TLB(转译后备缓冲区)。
本文将从底层的虚拟地址空间布局出发,结合 Linux 的原生线程库(NPTL)源码,深入探究线程的物理本质,并在此基础上实现一个优雅的 C++ 面向对象线程封装类。
一、揭秘线程 ID 与进程地址空间布局
1. 虚拟地址 vs LWP:pthread_t 的物理本质
在 Linux 终端中,我们使用 ps -aL 命令可以查看到线程的 LWP 标识:
$ ps -al
PID LWP TTY TIME CMD
195828 195828 pts/1 00:00:00 main
195828 195829 pts/1 00:00:00 Thread-0
195828 195830 pts/1 00:00:00 Thread-1其中 LWP 是内核层面的线程 ID,它是系统全局唯一的,内核调度器正是通过这个 LWP ID 来区分和调度不同的执行流。
然而,在 C++ 代码中调用 pthread_self() 或通过 pthread_create 的第一个参数获取的线程 ID(pthread_t),却是一个极其庞大的十六进制数值。例如我们在测试中打印的结果:
cpp
#include <iostream>
#include <cstdio>
#include <string>
#include <vector>
#include <unistd.h>
#include <pthread.h>
void *threadrun(void *args)
{
printf("threadrun new thread tid=0x%lx\n", pthread_self());
pthread_detach(pthread_self());
std::string name = static_cast<const char *>(args);
int cnt = 3;
while (cnt)
{
std::cout << name << " is running" << std::endl;
cnt--;
sleep(1);
}
std::cout << name << " is quit..." << std::endl;
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadrun, (void *)"thread-1");
printf("new thread tid=0x%lx\n", tid);
printf("main thread tid=0x%lx\n", pthread_self());
sleep(1);
int n = pthread_join(tid, nullptr);
std::cout << "main thread, n = " << n << std::endl;
}得到的结果:
cpp
$ ./createThread
new thread tid=0x7166327ff6c0
main thread tid=0x716632ea8740
threadrun new thread tid=0x7166327ff6c0
thread-1 is running
main thread, n = 22
thread-1 is running上述的一串tid,它们不是LWP,是虚拟地址。
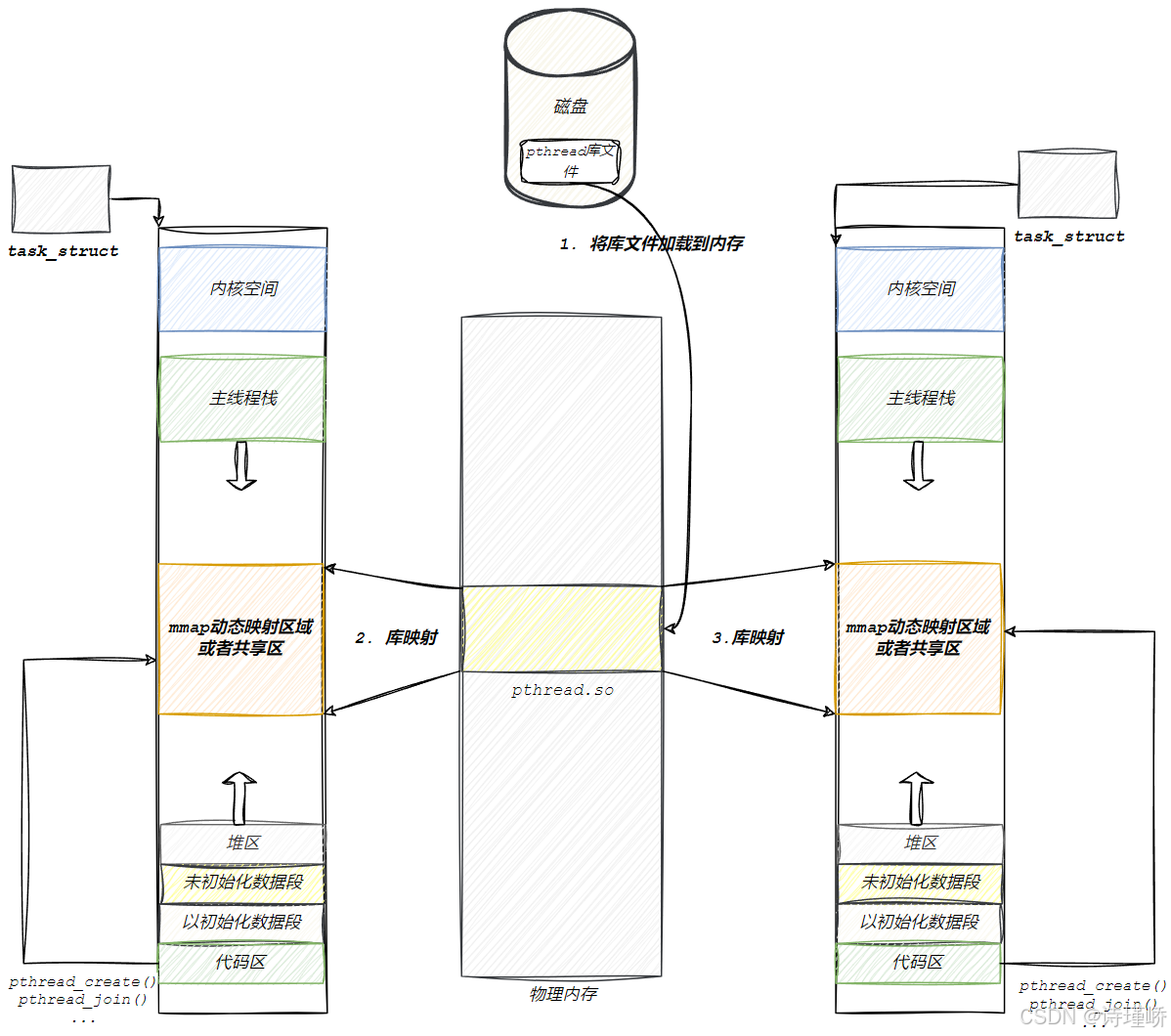
根据pthread库(见下图),可以得到程序要加载到内存,变成进程,形成地址空间,它所依赖的动态库也要加载到内存。

为什么内核调度的 LWP 只有十几万,而我们在应用层拿到的 pthread_t 却是一个类似 0x7166327ff6c0 的内存地址?
答案是:pthread_t 的本质就是共享区(mmap 映射区)内该线程控制块(TCB)的虚拟起始地址!
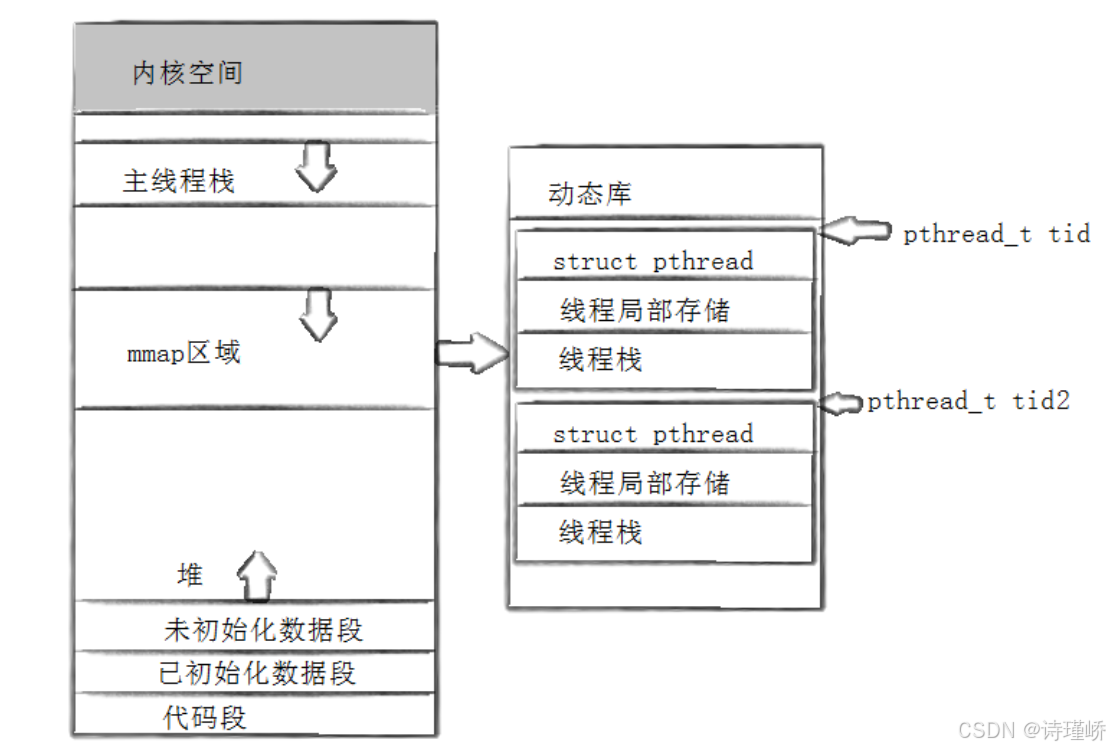
2. 原生线程库 NPTL 的内存布局
Linux 提供的 pthread 库并不是在内核中实现的,而是一个位于用户空间的动态库(Native POSIX Thread Library, NPTL)。当一个程序被加载并转为进程时,其依赖的动态库 libpthread.so 会被加载到物理内存中,并映射到进程地址空间的 mmap 区域(共享区)。
为了管理多个线程,NPTL 库必须在用户空间为每一个线程维护相关的属性和运行时状态。因此,库在共享区中为每个线程申请了一块连续的内存空间,其结构布局如下图所示:
进程虚拟地址空间 (32位系统范围: 0 ~ 4GB - 1)
+-----------------------------------------+
| 内核空间 |
+-----------------------------------------+
| 主线程栈 | <-- 默认自顶向下生长,独占进程栈区
+-----------------------------------------+
| |
| mmap 动态库映射区 (共享区) |
| |
| +-----------------------------------+ |
| | pthread.so | |
| +-----------------------------------+ |
| | [struct pthread (TCB)] | | <-- pthread_t tid 指向这里!
| | [线程局部存储 (TLS)] | |
| | [线程栈 (大小默认 8MB)] | | <-- 子线程的局部变量都分配在这里
| +-----------------------------------+ |
| | [struct pthread (TCB2)] | | <-- pthread_t tid2 指向这里!
| | [线程局部存储 (TLS2)] | |
| | [线程栈2] | |
| +-----------------------------------+ |
| |
+-----------------------------------------+
| 堆 | <-- 自底向上生长
+-----------------------------------------+
| 未初始化/初始化数据 |
+-----------------------------------------+
| 代码区 |
+-----------------------------------------+-
主线程栈:位于地址空间的标准栈区。
-
子线程栈 :并不在标准栈区!它们是 NPTL 库在共享区中通过
mmap系统调用申请的匿名私有映射区(通常为 8\\text{MB})。这也是为什么子线程的栈不能像进程栈那样"动态无限增长",它是一块固定大小的堆栈。 -
线程描述符(TCB) :即
struct pthread结构体,位于线程栈的头部(或尾部,取决于具体的 TLS 架构)。应用层拿到的pthread_t tid本质上就是这个结构体在共享区中的虚拟地址。
3. 解密 pthread_join 返回 22 的深层原因
在编写多线程程序时,常有以下代码逻辑:
void *threadrun(void *args) {
pthread_detach(pthread_self()); // 线程自自分离
// 执行一些任务...
return nullptr;
}
int main() {
pthread_t tid;
pthread_create(&tid, nullptr, threadrun, nullptr);
sleep(1);
int n = pthread_join(tid, nullptr); // 主线程尝试等待
std::cout << "main thread, n = " << n << std::endl;
}运行后,主线程打印出 main thread, n = 22。
在 Linux 头文件 <asm-generic/errno-base.h> 中,我们可以找到这个错误码的定义:
#define EINVAL 22 /* Invalid argument */为什么会产生 EINVAL (22) 错误? 默认情况下,新创建的线程是 joinable 的。如果一个线程退出了而主线程不去 pthread_join 等待它,它的 TCB 及栈资源就无法释放,进而产生"线程层面的内存泄漏"。 但是,如果在新线程的执行流中,调用了 pthread_detach(pthread_self()) 将自己设置为分离(Detached)状态,这等同于告诉系统:"我退出时会自动释放所有资源,不需要任何人来等待我。"
在多线程规范中,joinable 和 detached 是完全互斥的状态。 当主线程对一个已经被设置为分离状态的线程强行调用 pthread_join 时,NPTL 库检测到这一状态冲突,就会立即拒绝等待,并向调用者返回 EINVAL(错误码 22)。因此,在实际开发中,必须在"主动等待(Join)"与"自动回收(Detach)"之间做出唯一选择。
二、线程局部存储(TLS)深入探究
1. 普通全局变量 vs 线程局部存储
由于多个线程共享同一个地址空间,定义在类外的普通全局变量会被所有线程共同访问。我们通过一段实验代码来观察普通全局变量 g_cnt:
cpp
int g_cnt = 1;
void *threadrun(void *args)
{
std::string name = static_cast<const char *>(args);
int cnt = 3;
while (true)
{
printf("%s, g_cnt: %d, &g_cnt: %p\n", name.c_str(), g_cnt, &g_cnt);
g_cnt++;
cnt--;
sleep(1);
}
std::cout << name << " is quit..." << std::endl;
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadrun, (void *)"thread-1");
while(true)
{
printf("%s, g_cnt: %d, &g_cnt: %p\n", "main-thread", g_cnt, &g_cnt);
sleep(1);
}
sleep(1);
int n = pthread_join(tid, nullptr);
}结果:
cpp
$ ./createThread
main-thread, g_cnt: 1, &g_cnt: 0x5680d6710010
thread-1, g_cnt: 1, &g_cnt: 0x5680d6710010
main-thread, g_cnt: 2, &g_cnt: 0x5680d6710010
thread-1, g_cnt: 2, &g_cnt: 0x5680d6710010
main-thread, g_cnt: 3, &g_cnt: 0x5680d6710010
thread-1, g_cnt: 3, &g_cnt: 0x5680d6710010
main-thread, g_cnt: 4, &g_cnt: 0x5680d6710010
thread-1, g_cnt: 4, &g_cnt: 0x5680d6710010
main-thread, g_cnt: 5, &g_cnt: 0x5680d6710010
thread-1, g_cnt: 5, &g_cnt: 0x5680d6710010
thread-1, g_cnt: 6, &g_cnt: 0x5680d6710010
main-thread, g_cnt: 6, &g_cnt: 0x5680d6710010可以看到,main-thread 和 thread-1 访问的 g_cnt 地址完全一致(0x5680d6710010,位于进程的数据段中),一个线程修改,另一个线程立即感知。
如果我们希望每个线程都拥有一份独立的、互不干扰的全局变量拷贝 ,我们应该怎么做? Linux 提供了极其便利的编译器修饰符 __thread:
__thread int g_cnt = 1; // 线程局部存储 (TLS)启用该修饰符后的运行结果:
cpp
$ ./createThread
main-thread, g_cnt: 1, &g_cnt: 0x73537e0e673c
thread-1, g_cnt: 1, &g_cnt: 0x73537ddff6bc
main-thread, g_cnt: 1, &g_cnt: 0x73537e0e673c
thread-1, g_cnt: 2, &g_cnt: 0x73537ddff6bc
main-thread, g_cnt: 1, &g_cnt: 0x73537e0e673c
thread-1, g_cnt: 3, &g_cnt: 0x73537ddff6bc
main-thread, g_cnt: 1, &g_cnt: 0x73537e0e673c
thread-1, g_cnt: 4, &g_cnt: 0x73537ddff6bc
main-thread, g_cnt: 1, &g_cnt: 0x73537e0e673c
thread-1, g_cnt: 5, &g_cnt: 0x73537ddff6bc发生了神奇的变化:
-
两个线程访问的
g_cnt地址变得截然不同。main-thread对应0x73537e0e673c,而thread-1对应0x73537ddff6bc。 -
thread-1线程将g_cnt自增到了 2,而主线程中的g_cnt依然保持着 1。它们之间彻底完成了写隔离。 -
观察这两个新地址,它们都位于系统的 0x7353... 虚拟地址区间内。结合前面的内存布局图,这说明启用
__thread后,该变量的存储位置从进程的数据段,搬移到了共享区内每个线程各自的线程局部存储(TLS)区。
2. __thread 的局限性与现代 C++ 的演进
虽然 __thread 能够极高地提升多线程并发性能(避免了加锁竞争全局资源),但它具有非常致命的局限:它只能用于修饰 POD(Plain Old Data)基本数据类型 (如 int、double、指针、不含构造/析构函数的 C 风格结构体等)。
如果我们尝试用它修饰 C++ 中的 std::string 或其他自定义类:
__thread std::string g_name = "thread"; // 编译报错!这是因为 __thread 是 GNU 编译器提供的一种相对底层的内置修饰,它在程序和库加载阶段由 ELF 动态链接器直接初始化分配,完全无法支持 C++ 的面向对象特性(如动态调用类的构造函数、析构函数进行内存的申请与释放)。
现代 C++ 解决方案:thread_local
为了解决这一痛点,C++11 标准正式引入了关键字 thread_local。 thread_local 不仅能够自动适配基本类型,而且完美支持自定义类的对象。当一个线程启动时,修饰的自定义类会被在 TLS 区动态构造;当线程退出时,TLS 区的析构函数也会被自动触发,从根本上保障了多线程下 C++ 对象的生命周期安全。
三、原生线程库 NPTL 与 clone 底层源码追溯
通过阅读 glibc 线程库的底层源码,我们能清晰地探知在应用层调用 pthread_create 时,系统到底发生了什么。
1. 空间的申请与 struct pthread (TCB) 的定位
在 pthread_create.c 源码中:
int _pthread_create_2_1(newthread, attr, start_routine, arg) {
...
// 1. 申请线程描述符、线程栈及 TLS 空间
struct pthread *pd = NULL;
int err = ALLOCATE_STACK(iattr, &pd);
...
// 2. 将外部回调函数及参数填入控制块中
pd->start_routine = start_routine;
pd->arg = arg;
...
// 3. 将线程控制块 pd 的虚拟地址强制转换为 pthread_t 类型,返回给上层用户!
*newthread = (pthread_t)pd;
...
// 4. 正式创建内核执行流
err = create_thread(pd, iattr, STACK_VARIABLES_ARGS);
...
}这段源码铁证如山地证明了:我们在上层拿到的 pthread_t,正是 struct pthread 结构体在虚拟内存中的首地址 pd。
而在 allocatestack.c 中,我们可以看到,在缓存不命中时,底层调用 mmap 分配了匿名内存:
mem = mmap (NULL, size, prot, MAP_PRIVATE | MAP_ANONYMOUS | ARCH_MAP_FLAGS, -1, 0);随后通过体系结构计算(例如针对本地线程数据的对齐要求),在这块连续内存的末尾或特定偏移处,牢牢地锁定了 pd 的地址:
#if TLS_TCB_AT_TP
pd = (struct pthread *) ((char *) mem + size - coloring) - 1;
#endif2. 深入内核:clone 系统调用与资源共享
在 create_thread 内部,NPTL 库会调用核心函数 do_clone。该函数在底层汇编中,直接发起了 Linux 特有的系统调用 clone:
int clone_flags = (CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGNAL |
CLONE_SETTLS | CLONE_PARENT_SETTID | CLONE_CHILD_CLEARTID |
CLONE_SYSVSEM | CLONE_DETACHED | 0);
if (ARCH_CLONE (fct, STACK_VARIABLES_ARGS, clone_flags,
pd, &pd->tid, TLS_VALUE, &pd->tid) == -1) { ... }这就是 Linux 线程创建的最底层真相!这些传入的克隆标志位(Flags)深度决定了"轻量级进程"与普通进程的区别:
-
CLONE_VM:共享进程的虚拟内存空间(mm_struct)。子进程和父进程运行在同一地址空间下。 -
CLONE_FS:共享文件系统信息(根目录、当前工作目录等)。 -
CLONE_FILES:共享文件描述符表(一个线程打开了文件,其他线程立即可用该 fd 进行读写)。 -
CLONE_SIGNAL:共享信号处理方式(信号处理函数、屏蔽字等)。
四、面向对象思想下的 C++ 优雅线程封装
为了让原生 pthread 库更符合 C++ 面向对象的直觉,我们应当将底层的线程创建、状态维护、等待和解耦逻辑,高内聚地封装进一个独立的 C++ 类中。
这里存在一个 C++ 经典的多线程封装难题:pthread_create 要求的入口函数指针格式是 void* (*)(void*)(C 风格静态函数指针),但 C++ 类中的非静态成员函数,会默认在第一个参数中隐式携带 this 指针(即 void* Class::(void*) 的格式),这会导致类型不匹配。
1. 解决方案:静态成员函数桥接与 this 指针穿透
我们可以在类内声明一个 static void *routine(void *args),该静态函数在内存中具有固定的全局位置,完美适配原生库。同时,我们在 pthread_create 创建线程时,将对象自身的 this 指针作为参数传入 。 在 routine 内部,通过 static_cast<Thread *>(args) 找回对象指针,从而完美实现从"静态 C 接口"向"类内非静态 C++ 执行流"的穿透。
2. 修复 static int gnum 头文件重包含 Bug
在头文件中,若定义 static int gnum = 1;,会导致每个包含该头文件的编译单元都生成一个独立的、局部的 gnum 变量拷贝。这在多源文件大项目中会导致各个编译单元的线程名称编号独立重复,无法实现全局唯一的顺序增长。
在现代 C++(C++17 起)中,我们可以使用极其优雅的 inline 全局变量 语法来修补它,确保全局仅有一份唯一的 gnum:
inline static int gnum = 1; // 跨编译单元唯一,完美解决 Bug3. 最终源码
Makefile:
cpp
CXX = g++
CXXFLAGS = -std=c++11 -Wall -g
TARGET = testThread
SRCS = Main.cc
OBJS = $(SRCS:.cc=.o)
$(TARGET): $(OBJS)
$(CXX) $(CXXFLAGS) -o $@ $^
%.o: %.cc Thread.hpp
$(CXX) $(CXXFLAGS) -c -o $@ $<
clean:
rm -f $(OBJS) $(TARGET)
.PHONY: clean
cpp
#include <iostream>
#include <unistd.h>
#include <vector>
#include "Thread.hpp"
void Hello()
{
char name[64];
pthread_getname_np(pthread_self(), name, sizeof(name));
int cnt = 5;
while (cnt--)
{
std::cout << "hello thread: " << name << std::endl;
sleep(1);
}
}
int main()
{
std::vector<Thread> threads;
for (int i = 0; i < 10; i++)
{
threads.emplace_back(Hello);
}
for (auto &thread : threads)
thread.start();
// for(auto &thread : threads)
// thread.detach();
// for (auto &thread : threads)
// thread.start();
for (auto &thread : threads)
thread.join();
// Thread t(Hello);
// t.start();
// sleep(5);
// t.stop();
// t.join();
// sleep(3);
return 0;
}Thread.hpp:
cpp
#ifndef __THREAD_HPP
#define __THREAD_HPP
#include <iostream>
#include <string>
#include <unistd.h>
#include <functional>
#include <pthread.h>
#include <sys/syscall.h>
using func_t = std::function<void()>;
enum class TSTATUS
{
THREAD_NEW,
THREAD_RUNNING,
THREAD_STOP
};
// bug
// static int gnum = 1;
// 使用 C++17 inline 特性,确保头文件在被多处 include 时,gnum 全局仅有一份,避免编号重复的Bug
#if __cplusplus >= 201703L
inline static int gnum = 1;
#else
static int gnum = 1; // C++11 兼容降级
#endif
class Thread
{
private:
// 线程底层运行环境的数据采集
void getprocessid()
{
_pid = getpid();
}
void getlwp()
{
// syscall(SYS_gettid) 获取 Linux 原生的轻量级进程 LWP ID
_lwpid = syscall(SYS_gettid);
}
// 核心桥接静态函数:消除 C++ 隐式 this 指针带来的不兼容问题
static void *routine(void *args)
{
Thread *ts = static_cast<Thread *>(args); // 找回 C++ 类对象指针
ts->getprocessid();
ts->getlwp();
// 使用非标准、但 Linux 支持的动态库 API,在系统层面给当前 LWP 线程重命名,方便调试
pthread_setname_np(pthread_self(), ts->Name().c_str());
// 触发用户绑定的具体业务回调方法
ts->_func();
return nullptr;
}
public:
// 构造函数:初始化状态、等待机制,生成全局唯一的线程名称
Thread(func_t f) : _joinable(true), _status(TSTATUS::THREAD_NEW), _func(f)
{
_name = "thread-" + std::to_string(gnum++);
}
// 启动线程
void start()
{
if (_status == TSTATUS::THREAD_RUNNING)
{
std::cout << "thread is already running" << std::endl;
return;
}
// 关键调用:将 this 指针作为 args 传入
int n = pthread_create(&_tid, nullptr, routine, this); // 传this指针
(void)n;
_status = TSTATUS::THREAD_RUNNING;
}
// 异常/外部主动终止线程(不推荐滥用,容易引发锁未释放造成的死锁)
void stop()
{
if (_status == TSTATUS::THREAD_RUNNING)
{
int n = pthread_cancel(_tid);
(void)n;
_status = TSTATUS::THREAD_STOP;
}
else
{
std::cout << "thread status is : THREAD_NEW or THREAD_STOP! stop error" << std::endl;
}
}
// 等待线程回收
void join()
{
if (_joinable)
{
int n = pthread_join(_tid, nullptr);
(void)n;
printf("lwp: %d, name: %s, join success\n", _lwpid, _name.c_str());
}
else
{
// 如果外部调用过 detach 导致分离,join 就会返回错误码(如 22)
printf("lwp: %d, name: %s, join failed, because thread is detach\n", _lwpid, _name.c_str());
}
}
// 将线程置于分离状态,退出后由系统自动回收 TCB 资源
void detach()
{
if (_joinable && _status == TSTATUS::THREAD_RUNNING)
{
_joinable = false;
int n = pthread_detach(_tid);
(void)n;
}
}
std::string Name()
{
return _name;
}
~Thread()
{
// 析构防护:如果用户忘记 join 也忘记 detach,应当在析构时进行分离,避免资源泄漏
if (_status == TSTATUS::THREAD_RUNNING && _joinable)
{
pthread_detach(_tid);
}
}
private:
pthread_t _tid; // 应用层线程虚拟地址 ID (pthread_t)
pid_t _pid; // 所属进程 PID
pid_t _lwpid; // 内核真实调度的 LWP ID
std::string _name; // 线程友好名字
bool _joinable; // 是否可等待
TSTATUS _status; // 线程当前运行状态
func_t _func; // 线程核心执行回调方法
};
#endif五、总结与启示
通过本文的深入探索,我们打通了 Linux 线程从内核态到应用层再到面向对象封装的完整通路:
-
本质认识:Linux 所谓的线程只是共享地址空间的轻量级进程(LWP)。
-
布局真相:`pthread_t` 返回的庞大数值是用户空间动态库(NPTL)中线程控制块(TCB)的虚拟起始地址。线程专属的局部变量、子线程栈全都在共享区内分配。
-
并发加速:借助 `__thread` 或现代 C++ 的 `thread_local`,可以将变量私有化到 TCB 内的局部存储空间中,从而在极高并发下规避锁竞争。
-
封装实践:基于 C++ 优雅的类封装,通过 `this` 指针穿透解决了静态 C 接口与类内成员方法的不兼容问题,提供了一套逻辑内聚、状态完整且自动防泄漏的底层开发工具。
本章完。