1.数据库分类
分为关系型数据库和非关系型数据库等(这里只介绍关系型了) ,关系数据库中的数据项被组织为一系列具有行和列的表。关系型和非关系型数据库最本质的区别 就是关系型 以数据和数据之间存在的关系 维护数据,而非关系型 存储数据的时候,数据和数据之间没什么特定的关系 ;这里使用Linux安装的MySQL关系型数据库了,还是**8.0+**以上的版本。
2.SQL
SQL(结构化查询语言<-Structured Query Language),用于数据库存储数据以及查询、更新、管理关系数据库,每个关系型数据库都支持SQL语言/SQL标准。
3.常见数据库
MySQL,Oracle,SQLServer,IBM Db2,MariaDB,PostgreSQL,MongoDB,Redis等。
4.MySQL内部数据组织方式是按库、表、数据三级结构组织的
5. 数据库的基本操作
5.1 查看数据库
show databases; # 查看数据库
show databases like '%记忆中模糊的数据库名%'; # 查看和期望命名匹配的数据库,这里的%是通配符
show create database 数据库名; # 查看数据库的创建信息
默认安装MySQL自带的数据库有 information_schema,这个是存储系统中一些数据库对象信息 ,如列信息、权限信息等;还有 mysql,这是核心数据库,用来存放存储用户、用户访问权限 等管理信息,比如user表中的root用户的密码修改;performance_schema 这是用来收集数据库服务器性能参数; sys 数据库是用来提供一些视图,让开发者和使用者更方便查看性能问题。
5.2 创建数据库
create database 数据库名; # 创建数据库,失败了就换个名字创建(如果有提示数据库已存在)
create database 数据库名 character set utf8mb4 collate utf8_bin; #MySQL 8.0默认就是utf8mb4的字符集编码
后面的一些关键字都用大写了,可以提高可读性,SQL语法对大小写不敏感
5.3 删除数据库
DROP DATABASES 数据库名; #删除数据库
5.4 修改数据库
ALTER DATABASE 数据库名 CHARACTER SET utf8 COLLATE utf8_bin; #把数据库编码改成utf8
5.5 使用数据库
USE 数据库名; #一个数据库系统MySQL管理多个数据库,所以要先使用才能操作数据库中的表和数据。
- 数据库中表的操作
创建表
sql
SHOW TABLES;
SHOW TABLES LIKE '%模糊查找的表名%';
CREATE TABLE 表名(列1 类型1, 列2 类型2); #创建表,先是列在是类型
DROP TABLE 表名;
SHOW CREATE TABLE 表名; # 查看表的创建过程
ALTER TABLE 表名 CHARACTER SET utf8 COLLATE utf8_bin; # 改表的编码过程
DESC 表名; # 看看表的结构
# 可以跟创建库来对应着来记忆对表的数据的操作
sql
# 添加表的数据
INSERT INTO 表名 (列名) VALUES (值) ;
INSERT INTO 表名 SET 列名 = 值; # 添加数据
#查询表数据
SELECT * from 表名;
#修改表数据
UPDATE 表名 SET 列 = 值;
#删除表的数据
DELETE FROM 表名;
#这里 UPDATE 和 DELETE 要配合WHERE使用,防止对整个表进行操作- 常见的数据类型
整数:INT、BIGINT、TINYINT 分别是占用4字节,8字节,1字节
浮点数:FLOAT、DOUBLE 分别占用4字节和8字节
日期:YEAR、TIME、DATE、DATETIME、TIMESTAMP;DATETIME的格式包括年月日 时分秒。
字符串:CHAR、**VARCHAR、**TEXT、LOGTEXT、BLOB
- 特殊关键字
有where、distinct、limit、as、order by、group by 、还有聚合函数,这些后面都会使用。
9. SQL的执行顺序
先是(1) FROM xx (2) WHERE 对原始数据过滤 (3) GROUP BY 分组 (4) HAVING (5)SELECT xx
(6) ORDER BY (7) LIMIT
- 数据完整性
数据完整性就是要保证降低用户在实际使用中出错的可能性,提高数据库的使用效率;分为实体完整性、域完整性、参照完整性 ;实体完整性就是保证表中的每一行数据都是表中唯一的实体(一个表中每一条数据都应该是唯一的,完全可以由主键实现)。域完整性就是保证数据的字段的取值在一个合理范围。参照完整性就是确保相关联的表间的数据应该保持一致,参照完整性是通过外键和主键来维护,外键是维护参照完整性的一种强有力的维护手段,但参照完整性 不等于 外键。
11. 多表问题
数据库设计范式,有第一范式:原子性;第二范式:确保表中的每列都和主键相关(就是所有非主键字段完全依赖主键,不能产生部分依赖 ),第三范式:建立在第二范式之上,要确保所有非主键字段直接依赖主键,不能产生传递依赖。
多表查询,又有交叉连接、内连接、左外右外连接、自连接、子查询、联合查询等。
交叉连接:对两个表数据进行合并,合并的方式就是对两个表的所有数据做笛卡尔积 ,如果想过滤不想看的数据可以用 WHERE关键字,交叉连接使用的关键字是 CROSS JOIN。
内连接:内连接也是做笛卡尔积,但建议在过滤的时候使用 ON 关键字,内连接的关键字是 INNER JOIN。
外连接:分为左外连接和右外连接,关键字分别是 LEFT OUTER JOIN (LEFT JOIN)或 RIGHT OUTER JOIN (RIGHT JOIN) 简写,对左连接而言 LEFT 左边是称为主表 ,而LEFT 右边的表称为副表,右连接同理。对于左连接或右连接,主表中的数据一定会出现在最终的结果中。
自连接:就是自己表和自己表连接。
子查询:可以使用IN 或 EXISTS 关键字。
联合查询:使用 UNION 关键字,但相同结果会去重。
- C的AIP使用
后续代码中在说,现在先提一个在SQL的API编程中,对于字符串要使用单引号。
13. 事务
事务是组成逻辑的一组SQL操作,这些操作要么都成功执行,要么都不成功执行。构成事务的三个操作:开启事务、回滚、提交。分别是begin/start transaction, rollback, commmit。
四大基本特征ACID :(1)原子性 atomicity (2)一致性 consistency (3)隔离性 isolation(4)持久性 durability
原子性:全做或者不做,事务的所有操作要么全部执行成功,要么全部失败。
一致性:数据始终有效,数据库从一种正确的状态到另一种正确状态。
隔离性:事务互不干扰。
持久性:一旦提交,永久保存,也就是事务一旦提交成功,随后断电啥的,数据也不会丢失。
14.隔离级别
并发产生的四个问题:脏写(Dirty Write)、脏读(Dirty Read)、不可重复读(Nonrepeatable Read)、幻读(Phantom Read)
脏写:对数据进行了覆盖,导致结果不对。也就是多个事务并发一起写数据的时候,先执行的事务所写的数据被后面的数据覆盖了,导致数据的最终结果可能不对,就好像先提交的事务没执行一样。
脏读:读到了一个还没有提交的数据。
不可重复读:在同一个事务内,针对同一个数据,前后读取的数据不一样,即不可重复读。
幻读:在同一个事务,任何一条数据的内容前后读取一致,但前后数据的条数不一定一致。
隔离级别有四种:读未提交(READ UNCOMMITTED)、读已提交(READ COMMITTED)、可重复读(REPEATABLE READ)、可串行化/序列化(SERIALIZABLE)。
事务隔离级别对比如下图
脏写都能隔离,也就是都不存在这种情况了。

15. MySQL数据库的内部结构
如下图MySQL数据库系统的内部构成。
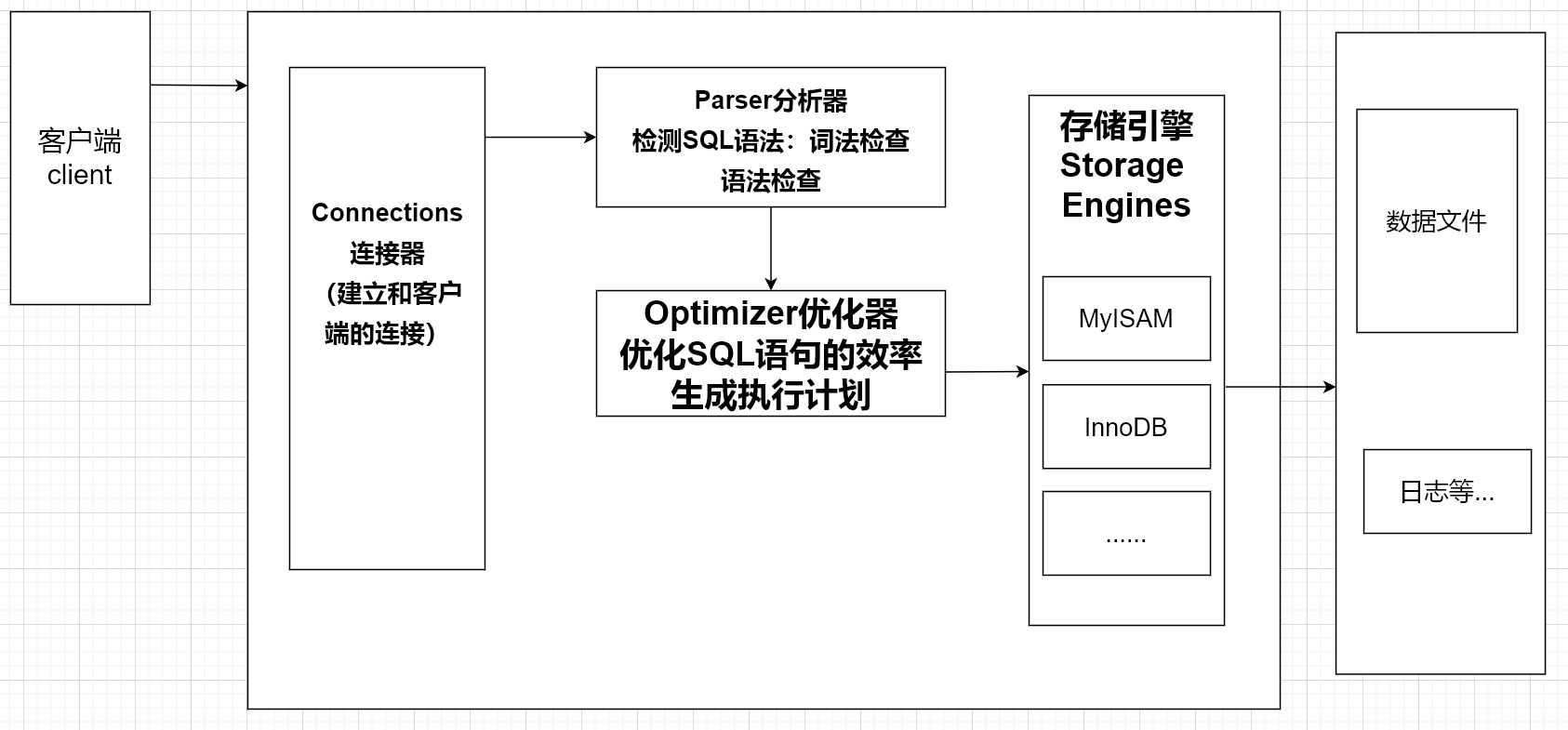
数据库有很多种引擎,主要了解MyISAM和InnoDB
MyISAM(MySQL5.5版本之前的默认存储引擎),而InnoDB(5.5以及之后默认的存储引擎)。MySQL数据库服务器,是由数据管理系统和数据两部分构成,而这个管理系统的设计是一种单进程多线程架构。
MyISAM存储引擎的特点:不支持事务、不支持行索引、支持表索引、不支持外键,所以从单线程角度,MyISAM效率比InnoDB高点(因为单线程直接抢表,可以访问整表的数据),但并发没有InnoDB程度高,底层有三个文件,数据和索引分开存放。
InnoDB的特点:支持事务、支持行锁、支持表锁、支持外键,并发程度比MyISAM高,底层只有一个文件(.idb结尾的),数据和索引存储在一块。
16.索引
索引是数据结构,能提高查询效率。(MySQL底层使用的是B+树)
16.1 MyISAM存储引擎
MyISAM的主键索引,通过主键索引 访问叶子节点上存储结果,不是一条条数据,而是数据的物理地址。而非主键索引,和主键索引访问的也是物理地址。
16.2 InnoDB存储引擎
InnoDB在主键索引上访问到的是数据本身,这也验证了前面的InnoDB是数据和索引存一块,而MyISAM是数据和索引分开存放。而非主键索引,通过非主键索引访问叶子上存储的结果是主键索引的值 ,那么无法获取完整数据,需要回到主键索引上拿到数据(这里称为回表);如果用非主键索引要查找的字段正好在索引上,那么可以直接找到,不用回表,这样称为索引覆盖。
17.聚集索引和非聚集索引
聚集索引也称聚簇索引,是索引和数据存放在一起的;非聚集索引也称非聚簇索引,是索引和数据分开放的。
18.慢日志查询
就是提供了一种记录运行慢的SQL语句的一种日志文件。
19.执行计划
只需要在待查询的SQL语句前加上 EXPLAIN关键字就可以了。

(1) id
id相同,执行顺序由上至下;id不同,id越大,越先执行。
(2) select_type
这个字段表示select的查询类型,例如普通、联合、子查询等。
(3) table
这个字段表示表的名字,显示的是别名。
(4) partitions
设置分区的时候才有意义。
(5) type
表示用哪种方式来查询表,查询效率如下(左边最快) **system > const > eq_ref > ref > range > index > ALL;**system表示系统表,往往不用磁盘I/O;const 常量连接,基本上是主键命中时的查询速度;ef_ref 多表查询时,主键索引或唯一索引作为关联条件进行的查找;ref 非主键或非唯一索引的等值扫描;range 范围扫描; index 全索引扫描;ALL全表扫描,速度最慢。
(6) possible_keys
查询中可能用到的索引
(7) key
SQL执行中实际用到的索引
(8) key_len
这里涉及计算,例如varchar(20),在utr8mb4编码下的大小就是83 = 20 * 4 + 1 + 2,这里的1是允许为NULL的情况,VARCHAR占2的额外开销。
(9) ref
表示将哪个字段和key列所用的字段进行比较
(10) rows
大概估算查找所需记录的行数
(11) filtered
预估有多少行会通过查询条件的过滤。
(12) Extra
如果出现了 Using filesort 就是对数据使用了外部的索引排序,也称文件排序,不是按表内索引进行顺序读取,效率低。