大模型分布式训练:把"大象"装进冰箱的终极指南
7.4 DeepSpeed ZeRO 系列:吃干榨净每一寸显存
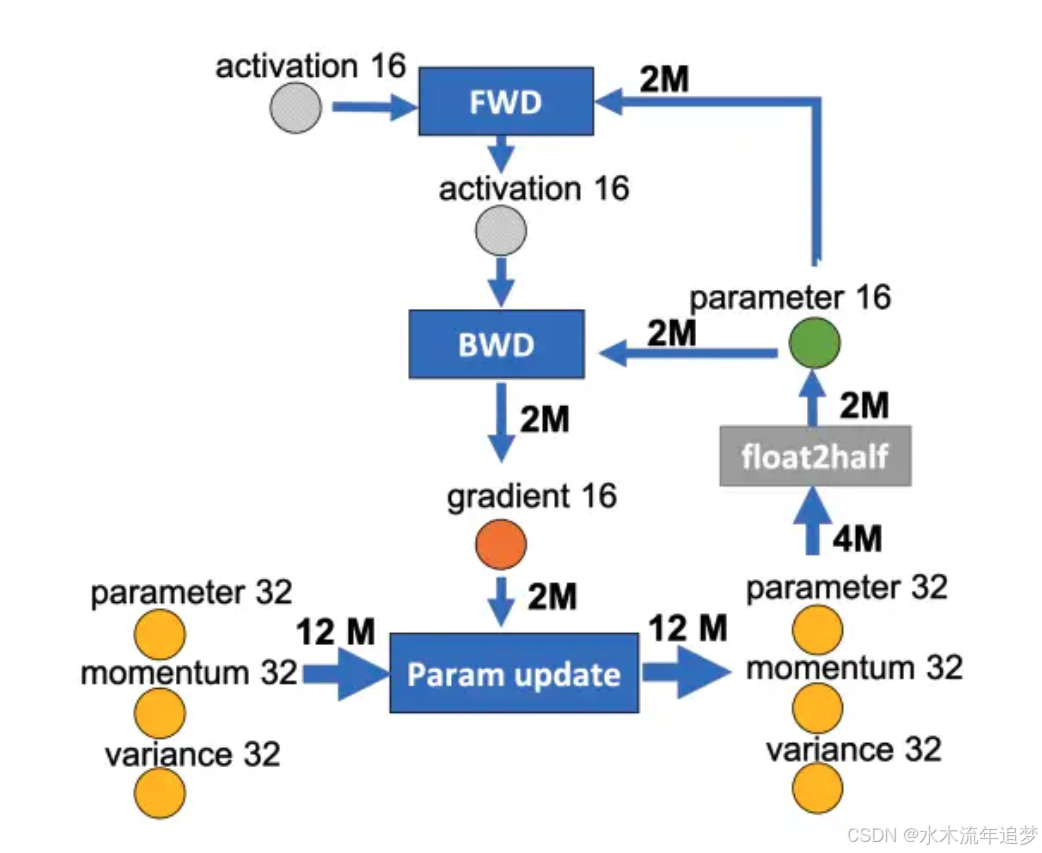
面对万亿级大模型,前面的招数还是不够用。微软的 DeepSpeed 敏锐地发现:显存不够,往往不是模型本身大,而是模型状态(Model States,包含优化器状态、梯度、模型参数)太占地方 。
在传统 DP 中,每张卡都死板地存着这三大件的完整副本,简直是极大的浪费 。ZeRO (零冗余优化器) 的核心哲学就是:分片存储,用时再取 。
它将优化做到了三个级别:
-
ZeRO-1 (PosP_{os}Pos): 只把占用最大的"优化器状态(如 Adam 的动量)"切成 NdN_dNd 块,每张卡只存一份。显存开销瞬间直降 4 倍 。
-
ZeRO-2 (Pos+gP_{os+g}Pos+g): 在第一步基础上,把"梯度"也切成 NdN_dNd 块。显存开销降幅达 8 倍 。
-
ZeRO-3 (Pos+g+pP_{os+g+p}Pos+g+p): 丧心病狂的终极形态。连"模型参数"本尊也切碎。算到哪一层,就通过网络向其他卡实时借参数。只要你的 GPU 数量足够多,理论上能训练无限大的模型 。
ZeRO-Offload:显存不够,内存来凑
如果即便切碎了,显存还是爆了怎么办?ZeRO-Offload 给出了绝杀:把参数下放到廉价的 CPU 和主板内存里 。
它巧妙地把高并发、高复杂度的前反向传播留在 GPU;把计算量小但极占空间的参数更新过程(Update)扔给 CPU 。由于传输的数据量恒定,随着卡数增加,CPU 的多核优势反而能缩短计算时间 。
7.5 Sequence Parallel:序列并行
在处理动辄 100K 上下的长文本时,Token 序列长度太长也会撑爆显存 。
-
核心思路: 把一长段话从中间劈开(例如 1024 长度劈成两个 512)。GPU 0 看上半段,GPU 1 看下半段 。
-
代价与收益: 前向和后向需要各进行一次 All-Gather 通信来交换拼接上下文线索 。代价是吞吐量会下降 10-25%,但换来的是显存峰值直线下降,从而使大模型阅读长篇巨著成为可能 。
7.6 Expert Parallelism:专家并行 (MoE专属)
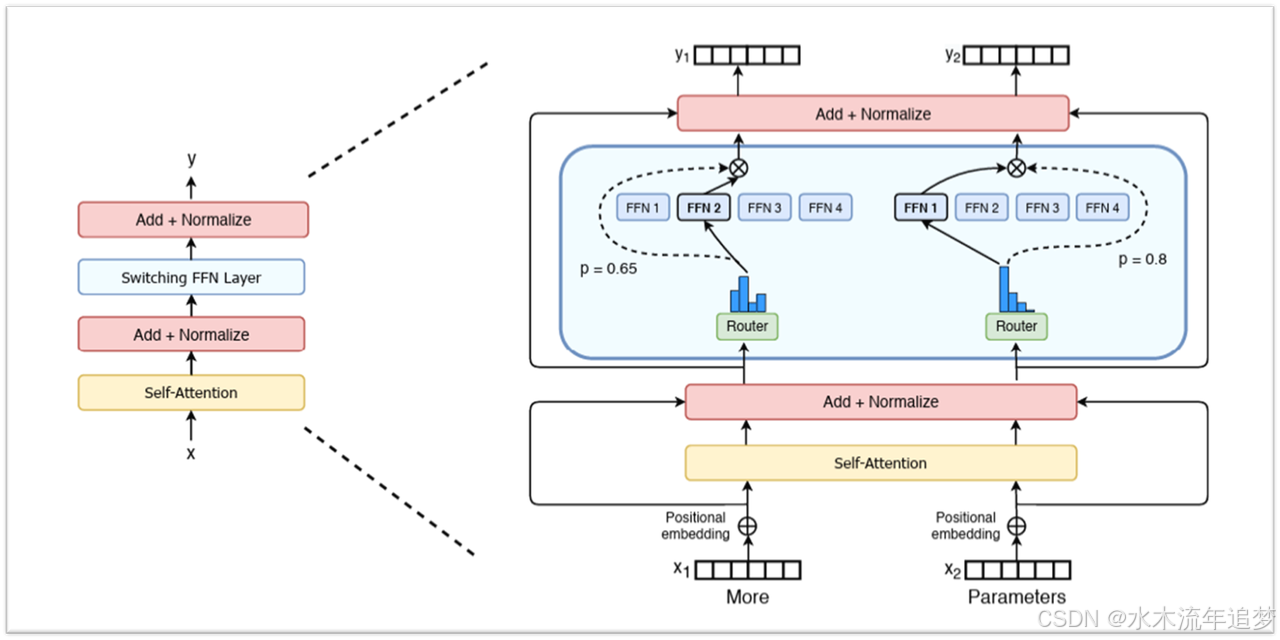
大模型走向 MoE(混合专家架构)后,迎来了一种新的并行方式 。
-
核心思路: Transformer 里养了一批"术业有专攻"的专家网络。每次推理时,门控机制会只挑出最契合的 top-k 个专家来工作,其他专家全程摸鱼 。
-
物理部署: 我们把不同的专家丢到不同的物理显卡上 。
-
通信挑战: 当数据流过来时,需要进行疯狂的 All-To-All 点对点通信,把不同的 token 快递到对应专家的显卡上 。由于它利用了稀疏激活的特性,实际的吞吐量(Token/s)能得到惊人的翻倍提升 。
7.7 终极总结与面试必考指北
在工业界,大模型的训练绝非使用单一策略,而是"我全都要"的3D/4D混合并行组合拳 。
性能权衡速查表:
| 策略类别 | 并发度优势 | 吞吐量表现 | 通信压力分析 |
|---|---|---|---|
| DP / EP | 最优。所有 GPU 同步推进,没人闲着 。 | EP 利用 MoE 的稀疏性,大幅提升实际产出 Token/s 。 | DP 只需做梯度同步。EP 需要频繁的跨卡交换 。 |
| TP / PP / SP | 存在跨卡同步或流水线等待,短期内必定存在 GPU 空闲的 Bubble 。 | PP 必须扣除不可避免的气泡时间;TP 和 SP 严重受制于通信带宽压降 。 | TP 每层都要做 All-Gather;PP 仅在流水线边界少量通信;SP 有跨卡交换 。 |
如果你正在准备大模型相关的面试,请务必吃透以下 5 个核心问题:
-
参数量 vs 显存占用: 面对不同参数规模,如何通过切分网络或 ZeRO 策略极限压榨显存峰值?
-
通信带宽 vs 延迟: 深入辨析 All-Reduce、All-Gather、All-To-All 的底层机制,什么场景下谁会成为系统瓶颈?
-
并发度 & 气泡 (Bubble): 在 Pipeline 管线并行中,如何通过设计 micro-batch 数量和 stage 平衡来消灭计算气泡?
-
MoE 路由与负载: 专家并行中,如何设计健壮的 Top-k 门控机制,防止某个专家被瞬间打满(专家热点),而其他专家无所事事?
-
混合并行设计: 给定千卡集群,如何拍板 DP + TP + PP + SP 的最优拓扑结构与调优思路?
bash
print('hello')