元宝说,鸢尾花分类项目,是机器学习的Hello world。然后给了我一个完整的鸢尾花分类代码。
#鸢尾花分类项目from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_score,classification_reportimport pandas as pdimport numpy as np
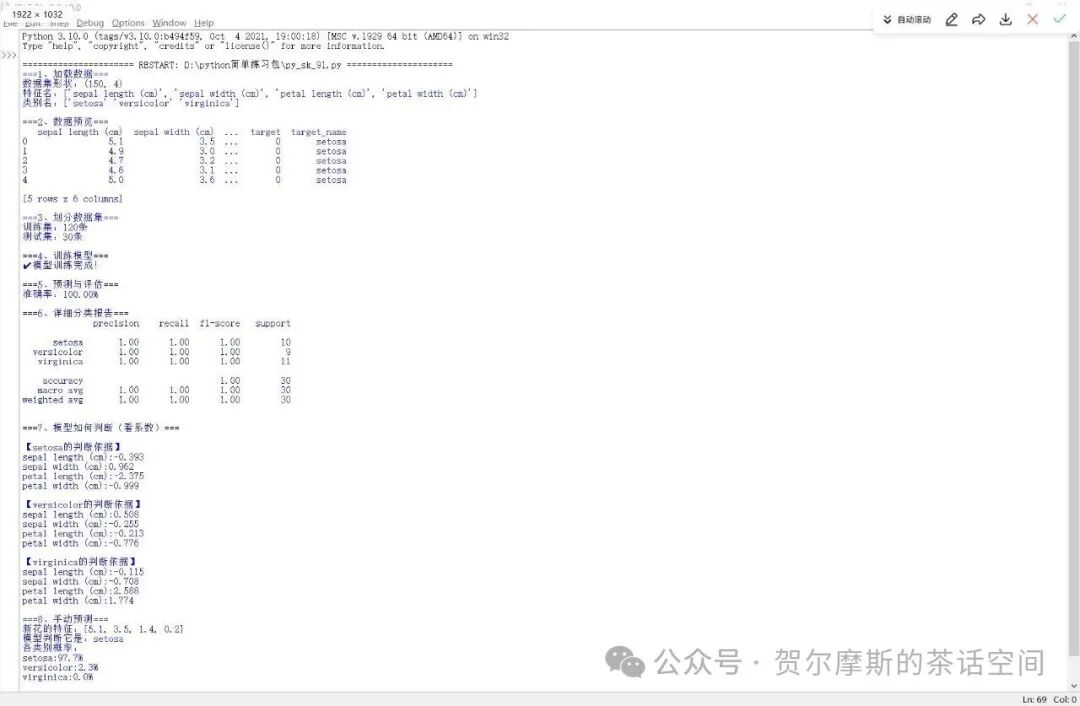
#1、加载数据print("===1、加载数据===")iris = load_iris()X = iris.data #特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度y = iris.target #标签:0=山鸢尾,1=变色鸢尾,2=维吉尼亚鸢尾
print(f"数据集形状:{X.shape}") #(150,4)表示print(f"特征名:{iris.feature_names}")print(f"类别名:{iris.target_names}")
#2、查看前5条数据print("\n===2、数据预览===")df = pd.DataFrame(X,columns = iris.feature_names)df['target'] = ydf['target_name'] = df['target'].map({0:'setosa',1:'versicolor',2:'virginica'})print(df.head())
#3、划分训练集和测试集print("\n===3、划分数据集===")X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2,random_state = 42)print(f"训练集:{X_train.shape[0]}条")print(f"测试集:{X_test.shape[0]}条")
#4、训练模型print("\n===4、训练模型===")model = LogisticRegression(max_iter = 200)model.fit(X_train,y_train)print("✔模型训练完成!")
#5、预测print("\n===5、预测与评估===")y_pred = model.predict(X_test)
#6、评估accuracy = accuracy_score(y_test,y_pred)print(f"准确率:{accuracy:.2%}")
#7、详细分类报告print("\n===6、详细分类报告===")print(classification_report(y_test,y_pred,target_names = iris.target_names))
#8、看看模型如何决策print("\n===7、模型如何判断(看系数)===")#逻辑回归是多分类,会为每个类别学一组系数for i,target_name in enumerate(iris.target_names): coef = model.coef_[i] print(f"\n【{target_name}的判断依据】") for j,feature_name in enumerate(iris.feature_names): print(f"{feature_name}:{coef[j]:.3f}")
#9、手动预测一朵新花print("\n===8、手动预测===")#随便构造一朵花的特征:花萼长5.1,花萼宽3.5,花瓣长1.4,花瓣宽0.2new_flower = [[5.1,3.5,1.4,0.2]]pred = model.predict(new_flower)pred_prob = model.predict_proba(new_flower)[0]
print(f"新花的特征:{new_flower[0]}")print(f"模型判断它是:{iris.target_names[pred[0]]}")print(f"各类别概率:")for i,name in enumerate(iris.target_names): print(f"{name}:{pred_prob[i]:.1%}")运行结果为:
先从引入的包开始看。
1、from sklearn.datasets import load_iris。
sklearn实际上是包scikit-learn的简称,如果在运行时候报错说,没有sklearn包。使用cmd命令行,应输入pip install scikit-learn下载安装,而不是pip install sklearn下载安装。
鸢尾花数据集是包scikit-learn里自带的数据集,load_iris函数的作用,就是从scikit-learn包里加载鸢尾花数据集(iris)。鸢尾花数据集,包含了3种鸢尾花(0-山鸢尾 setosa,1-变色鸢尾 versicolor,2-维吉尼亚鸢尾 virginica),150个样本,每种花各50个样本。每个样本有4个特征:花萼长度 sepal length (cm)、花萼宽度 sepal width (cm)、花瓣长度 petal length (cm)、花瓣宽度 petal width (cm)。
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

可以用这一段代码,查看鸢尾花数据集。
from sklearn.datasets import load_iris
#加载数据集iris = load_iris()
#查看数据集的描述信息print(iris.DESCR)
#获取特征数据和目标标签X = iris.datay = iris.target
#输出前几个样本的特征和标签,查看数据结构print(X[:5])print(y[:5])运行结果为:
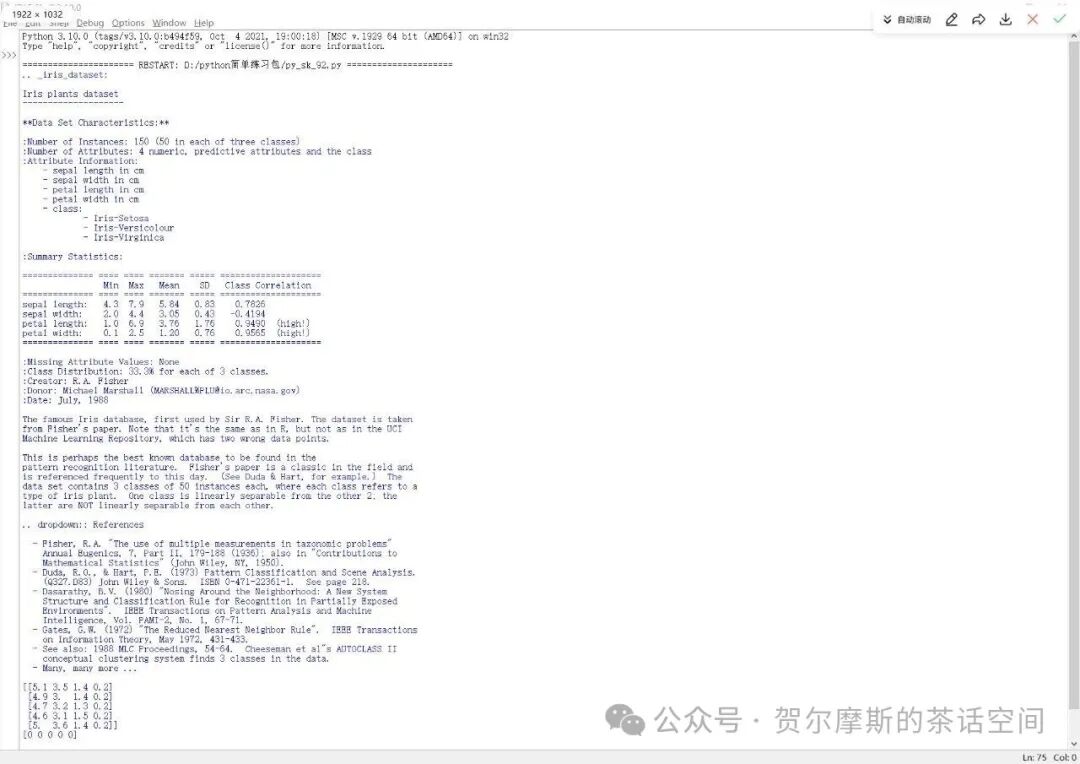
数据集的详细信息:
iris.data:包含特征的数据数组,形状为 (150, 4),即150个样本,每个样本有4个特征。
iris.target:包含目标标签的数组,形状为 (150,),即150个样本的标签。
iris.target_names:包含目标名称的数组,对于鸢尾花数据集,它包含三个类别名称:'setosa', 'versicolor', 'virginica'。
iris.feature_names:包含特征名称的数组,对于鸢尾花数据集,它包含四个特征名称:'sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'。
iris.DESCR:数据集的完整描述。
2、from sklearn.model_selection import train_test_split。
从scikit-learn包中,导入用于划分训练集和测试集的函数,这是机器学习中,数据预处理的关键步骤。train_test_split函数的作用,是将原始数据集,按比例,随机划分为训练集(Training Set)和测试集(Test Set)。训练集会用于模型训练,测试集用于评估模型性能。
常用参数说明:
*arrays:输入数据,通常为特征矩阵X和标签向量y。
test_size:测试集比例(默认为0.25),如0.2表示20%数据作为测试集。
train_size:训练集比例(可选,若未指定则自动不足)。
random_state:随机种子,确保结果可复现。
shuffle:是否打乱数据(默认True)。
stratify:按类别比例分层划分(适用于分类任务,如stratify = y)
from sklearn.model_selection import train_test_split
#假设X是特征,y是目标变量X_train,X_test,y_train,y_test = train_test_split( X,y, test_size = 0.2, #把数据集分成80%训练集和20%测试集 random_state = 42 #固定随机状态,使得结果可复现)3、from sklearn.linear_model import LogisticRegression。
这一句的作用,是引入scikit-learn包里的逻辑回归模型,这是用于分类任务的经典线性模型。
from sklearn.linear_model import LogisticRegressionfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split
#加载数据iris = load_iris()X,y = iris.data,iris.target
#划分训练集和测试集X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.25,random_state = 42)
#创建逻辑回归模型model = LogisticRegression()
#训练模型model.fit(X_train,y_train)
#预测y_pred = model.predict(X_test)
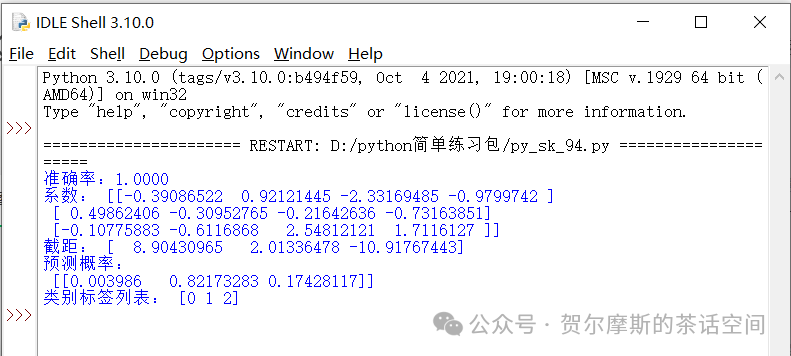
#评估准确率accuracy = model.score(X_test,y_test)print(f"准确率:{accuracy:.4f}")print("系数:",model.coef_)print("截距:",model.intercept_)print("预测概率:\n",model.predict_proba(X_test[:1]))print("类别标签列表:",model.classes_)运行结果:
我问了一下元宝,逻辑回归模型是什么意思,能不能解释一下呢?元宝给我的解释,有点长。

准确率和类别标签,我能看懂。但是,斜率、截距、预测概率,这3项,是什么意思呢?元宝给我的回答是:

其中,这3条是最核心的功能
#创建逻辑回归模型model = LogisticRegression()
#训练模型model.fit(X_train,y_train)
#预测y_pred = model.predict(X_test)创建模型,实际上是创建一个线性函数。训练模型,是把X_train和y_train两个训练集的数据,投喂给这个线性函数,让这个线性函数自动调整系数和截距,目标是让这个线性函数完成后,成为数据不同的类别的分界线。预测,是用测试集X_test的值代入到这个训练完成了模型中,看看这个模型能不能把测试集X_test的数据分类到正确的类别里。
X_train训练集,是花的4个特征:花萼长度 sepal length (cm)、花萼宽度 sepal width (cm)、花瓣长度 petal length (cm)、花瓣宽度 petal width (cm)。
y_train训练集,是花的对应的种类,一条X_train训练集数据包括4项,对应一条y_train训练集的花的种类。
X_test测试集,也是花的4个特征,但是没有用于训练模型阶段,而是用于测试阶段。
y_test测试集,也是花的对应的种类,但是没有用于训练模型阶段,而是用于测试阶段。
#评估准确率accuracy = model.score(X_test,y_test)print(f"准确率:{accuracy:.4f}")评估准确率,就是把X_test测试集,代入模型,计算得到预测的y集,用预测的y集和y_test测试集的值进行对比。评估准确率,就是预测的y集和y_test测试集的值一致的比例。
4、from sklearn.metrics import accuracy_score,classification_report。
sklearn.metrics这个包里存放的是一些用于评估模型的指标函数。 这一句说的是,从sklearn.metrics包里,引入accuracy_score和classification_report两个指标函数。
accuracy_socre是准确率,计算模型预测正确的样本数,占样本总数的比例。
classification_report是生成分类报告函数,作用是生成包含精确度(Precision)、召回率(Recall)、F1分数(F1-score)和支持数(Support)的详细报告。
精确率(Precision):预测为正类中实际为正的比例。
召回率(Recall):实际为正类中被正确预测的比例。
F1-score:精确率与召回率的调和平均。
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

Support:每个类别的真实样本数。
Macro Average(宏平均) 是一种在多分类任务中评估模型性能的指标,它通过计算每个类别的评估指标(如精确率、召回率、F1分数)的算术平均值来得到,且每个类别权重相等。
weighted avg(加权平均)是一种考虑每个数据点权重的平均值计算方法,其核心公式为:加权平均数 = Σ(数据点 × 权重) / Σ权重。它广泛应用于分类模型评估、成绩计算、金融分析等领域,能更真实地反映不同重要性数据的综合水平。
在机器学习中,weighted avg 用于多类别分类任务的性能评估,通过将每个类别的指标(如精确率、召回率、F1-score)按其样本数量加权求和,再除以总样本数,从而避免样本不均衡对结果的影响。例如,若某一类样本量远大于其他类,其表现对整体评估结果的影响更大。
相比 macro avg(宏平均,对所有类别等权处理),weighted avg 更适合样本分布不均的场景,因为它赋予样本量大的类别更高权重,使评估结果更具代表性。
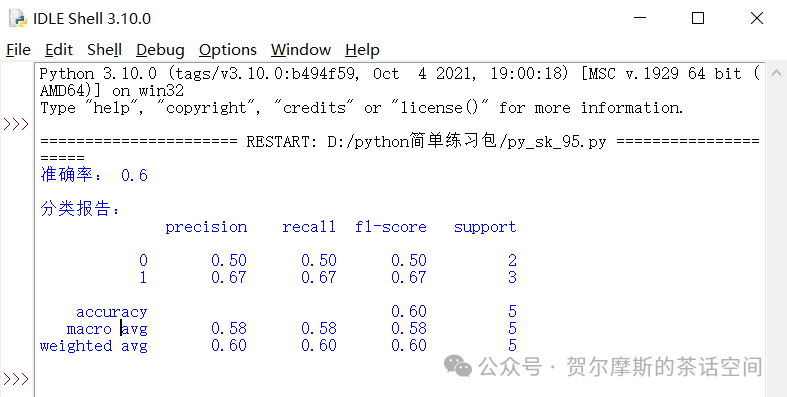
from sklearn.metrics import accuracy_score,classification_reportimport numpy as np
y_true = [0,1,0,1,1]y_pred = [0,1,1,1,0]
print("准确率:",accuracy_score(y_true,y_pred))print("\n分类报告:")print(classification_report(y_true,y_pred))y_true和y_pred,5项里只有3项是一样的,所以,准确率应该是60%。
运行结果:
5、
import pandas as pd
import numpy as np
引入pandas包和numpy包,这两个包是很常用的处理数据和处理矩阵的包。不过,我感觉,这个鸢尾花数据集的分类,不用加这两个包,好像也没问题。有点多余。
我出于好奇这三种鸢尾花的样子长什么样,去网上查了一下,鸢尾花其实原产于我国,我今天是第一次知道,又涨知识了。我让豆包帮我制作了3幅鸢尾花的工笔画图片。

山鸢尾

变色鸢尾

维吉尼亚鸢尾
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可
