其他监督学习算法(了解)
监督学习算法详解
监督学习是一种基于带标签数据进行建模的机器学习方法,其核心思想是通过学习输入特征与输出标签之间的映射关系,对未知数据进行预测。常见任务包括分类(预测离散类别)和回归(预测连续数值)。
常用算法
线性回归(Linear Regression):假设输入与输出存在线性关系,适用于回归任务,优点是简单高效,缺点是无法处理非线性关系。
逻辑回归(Logistic Regression):用于二分类,通过 Sigmoid 函数输出概率,适合线性可分问题。
K近邻(KNN):基于距离度量的懒惰学习方法,分类或回归均可,计算量大且对高维数据不友好。
决策树(Decision Tree):通过特征递归分裂构建树结构,易解释但易过拟合。
支持向量机(SVM):通过最大化间隔实现分类,适合高维数据,但计算复杂度高。
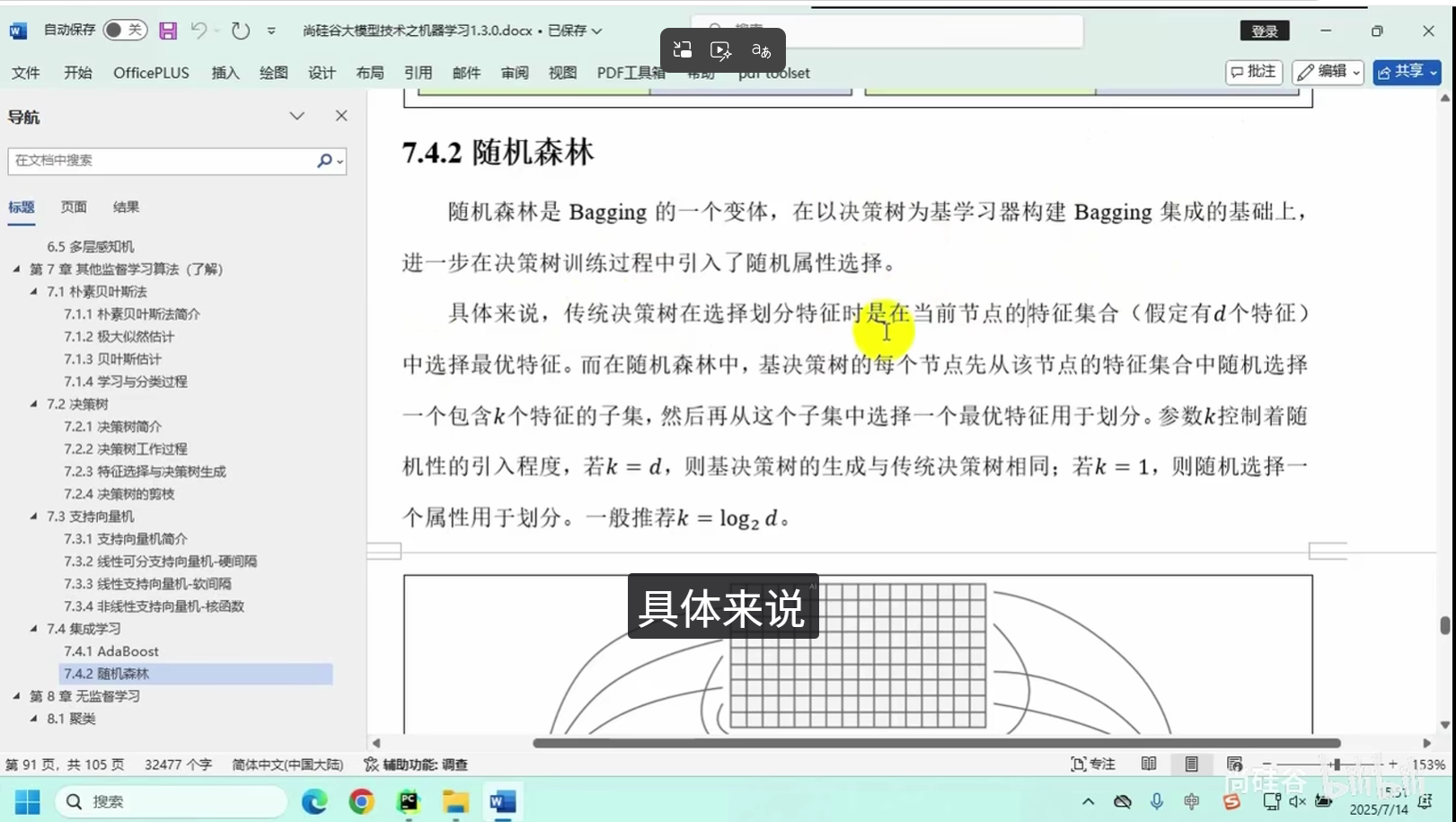
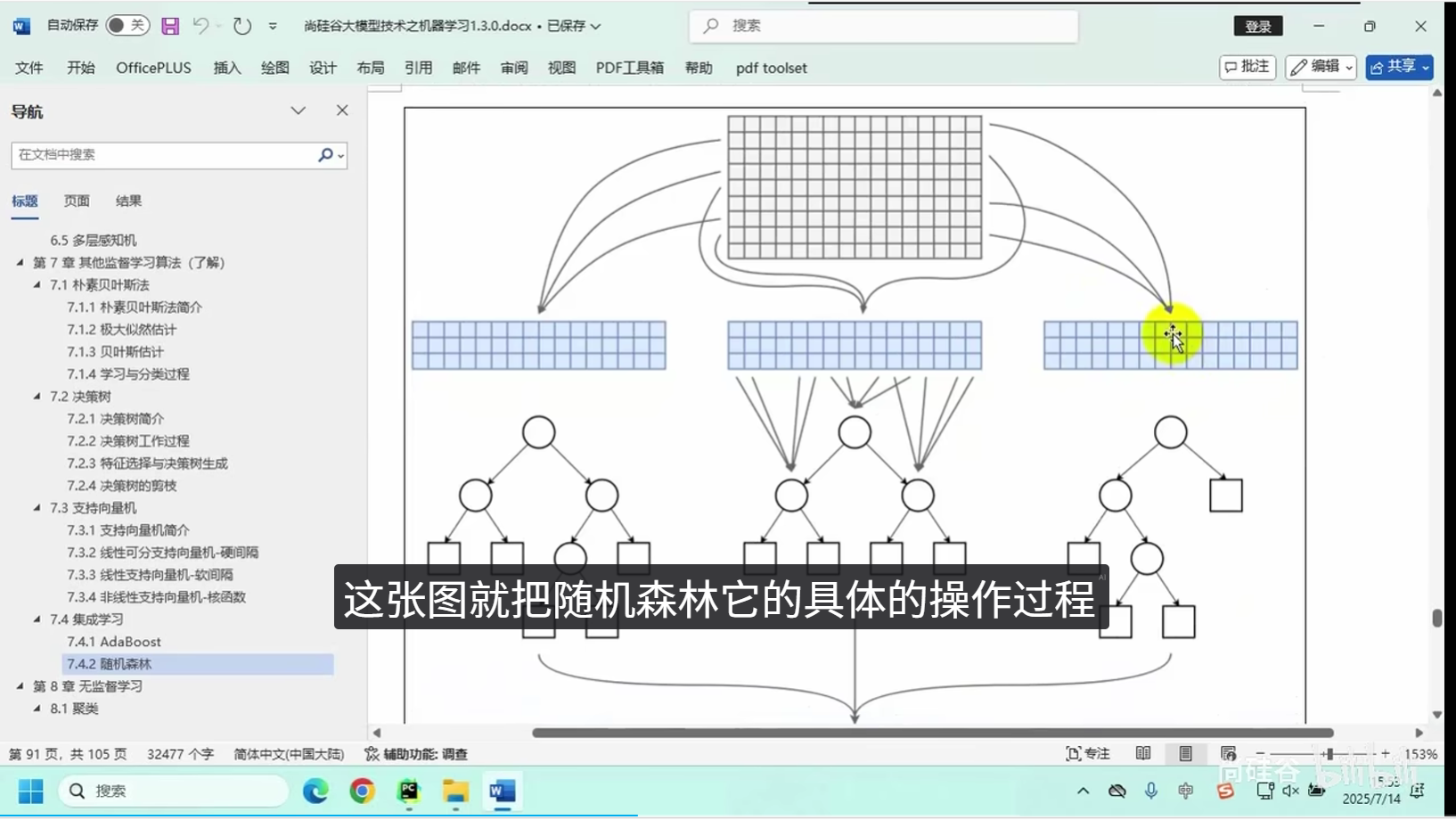
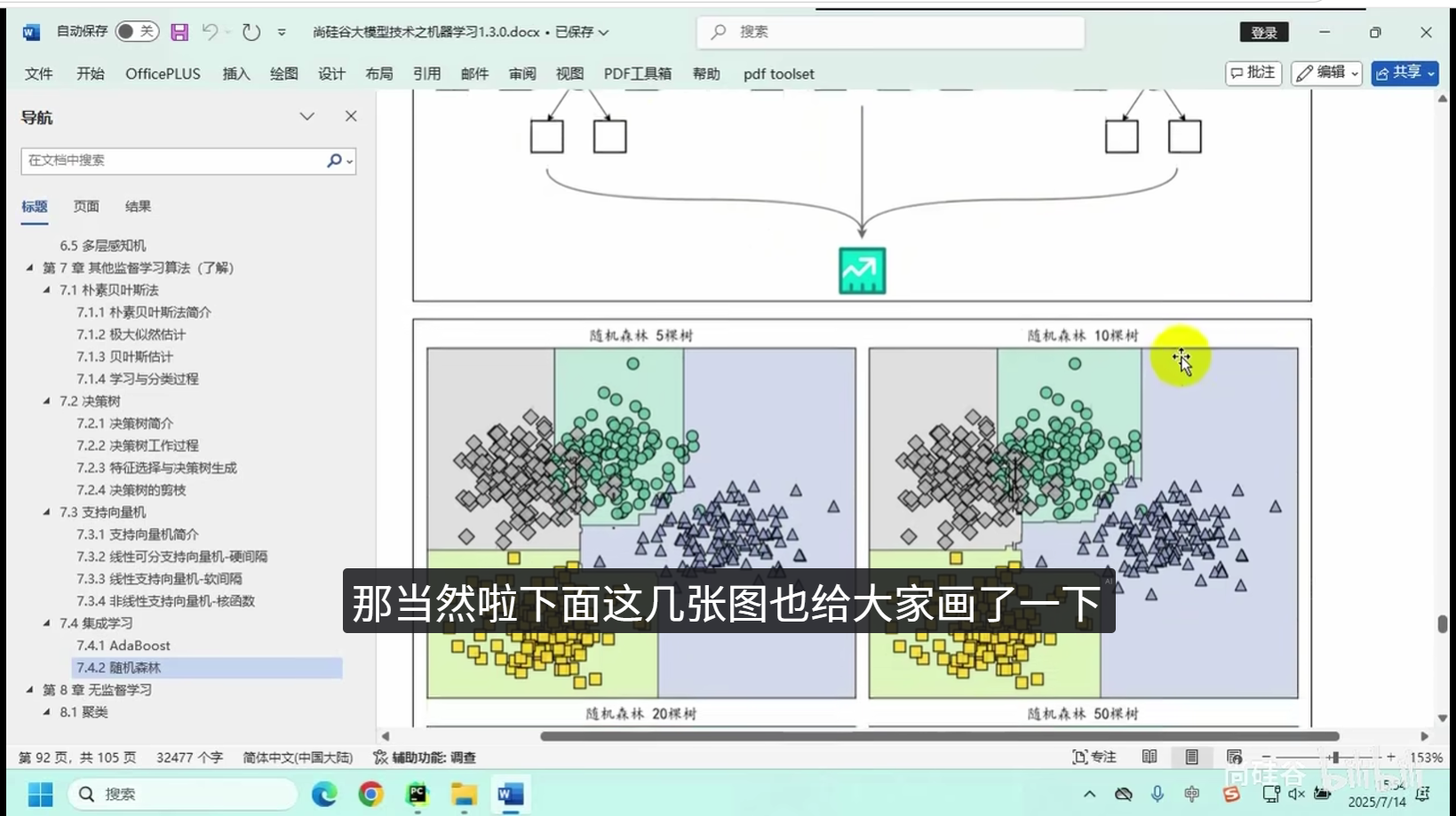
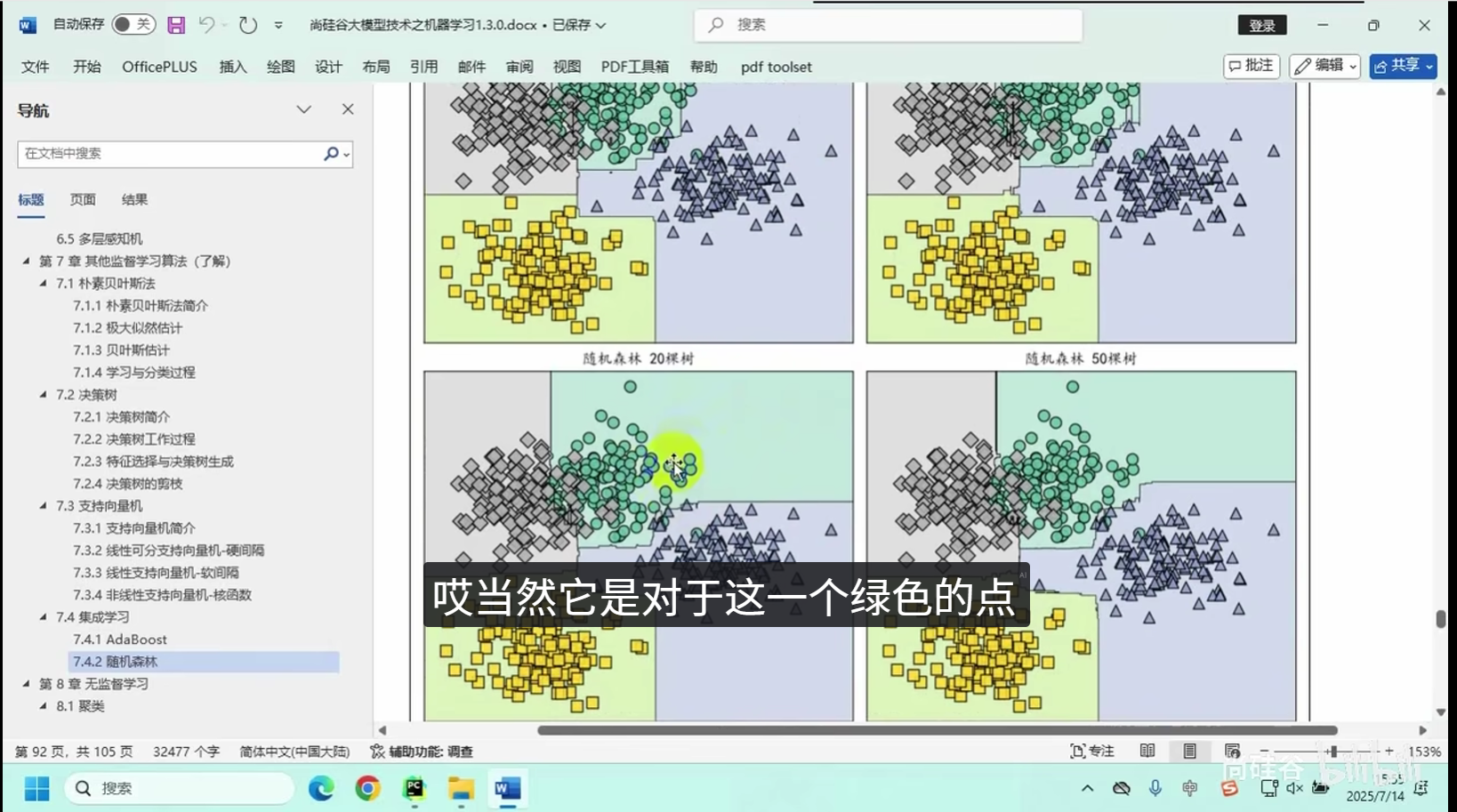
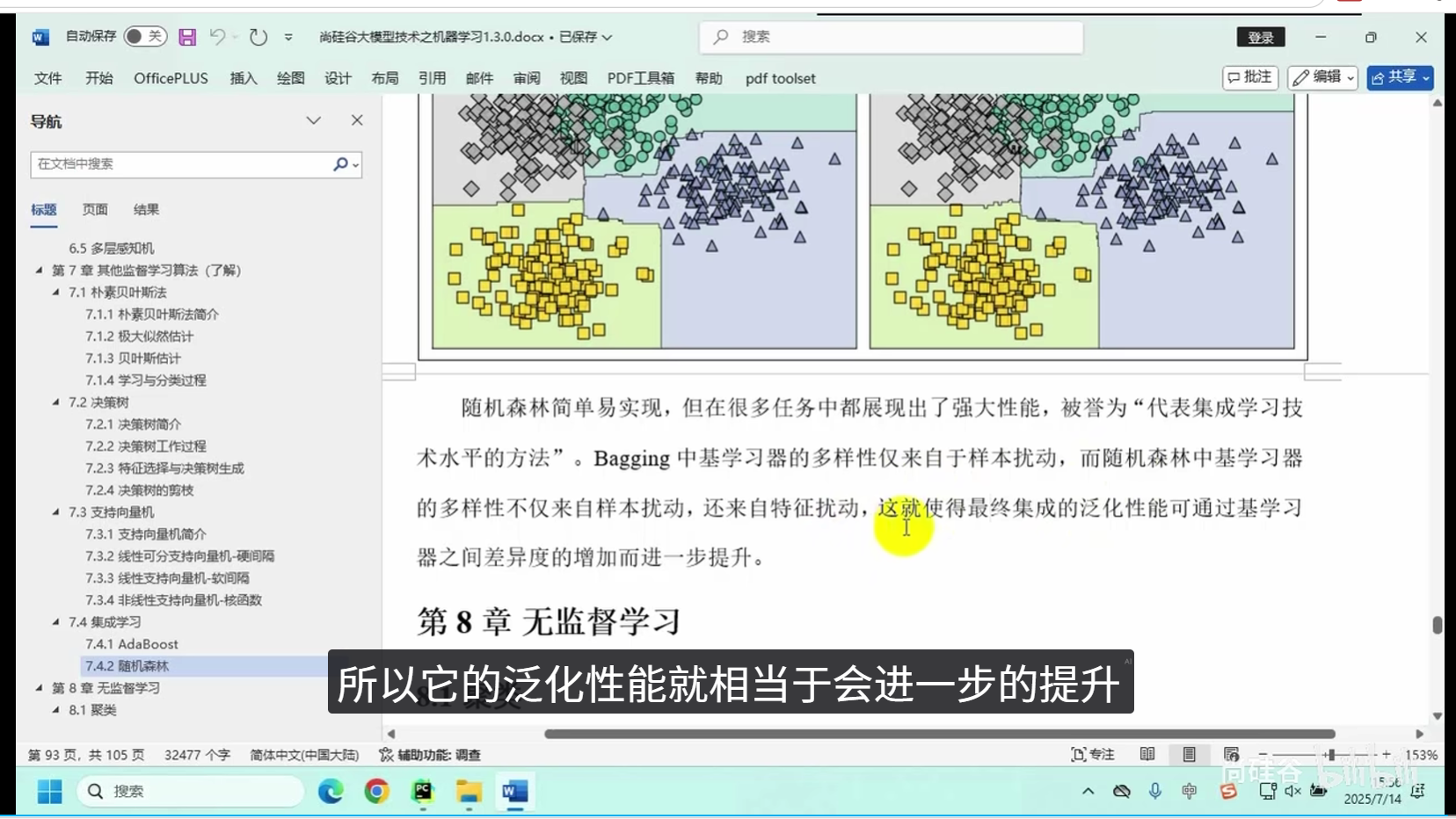
随机森林(Random Forest):集成多棵决策树,提升泛化能力,适合高维特征场景。
该示例展示了数据加载 → 划分 → 模型训练 → 预测评估的完整流程。
典型应用场景
图像识别:如人脸识别、目标检测。
自然语言处理:情感分析、文本分类、命名实体识别。
医学诊断:疾病预测、影像分析。
金融风控:信用评分、欺诈检测。
注意事项
数据标注成本高:需大量高质量标签数据。
过拟合风险:可用正则化、交叉验证、集成学习缓解。
数据偏差:需保证训练数据分布与实际应用一致。
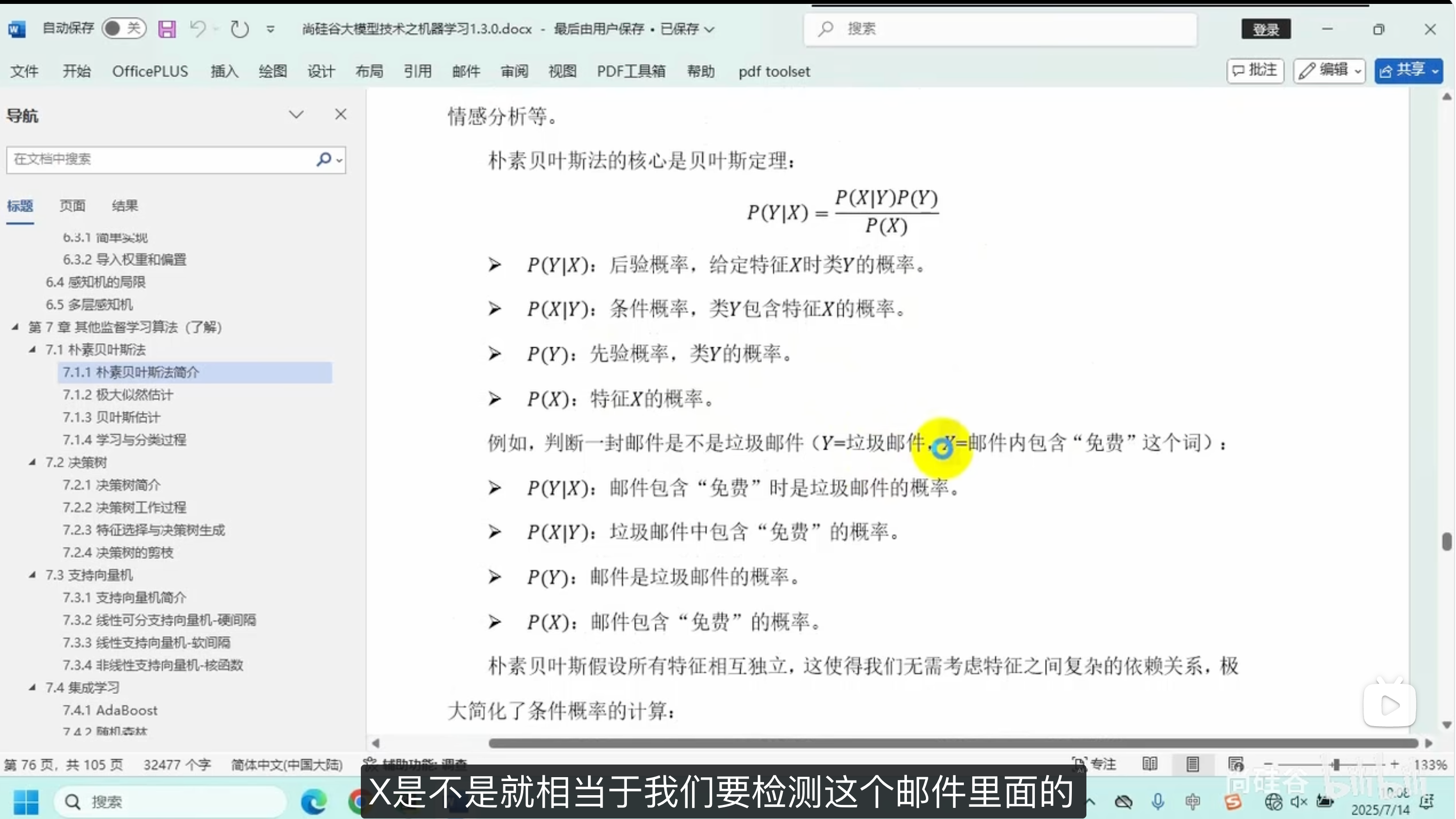
朴素贝叶斯法
朴素贝叶斯法简介
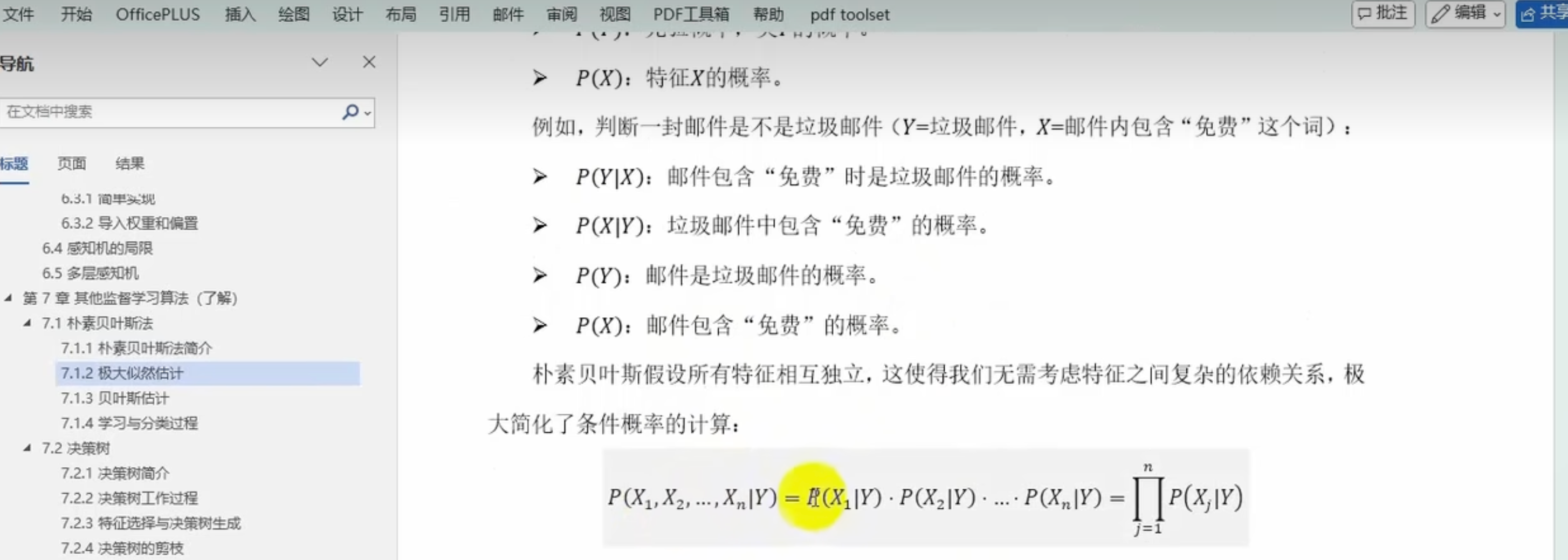
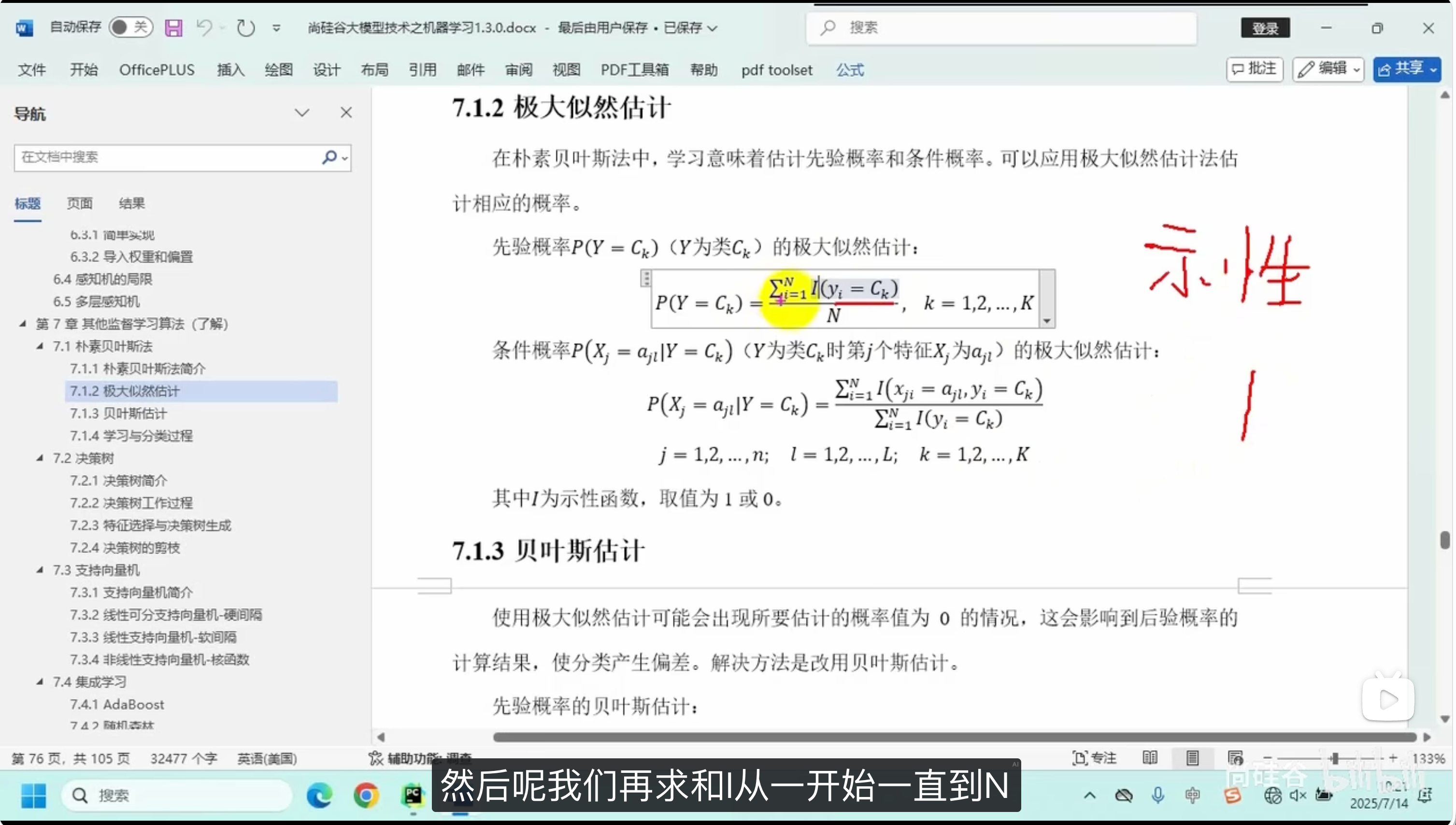
极大似然估计
贝叶斯估计

学习与分类过程

决策树
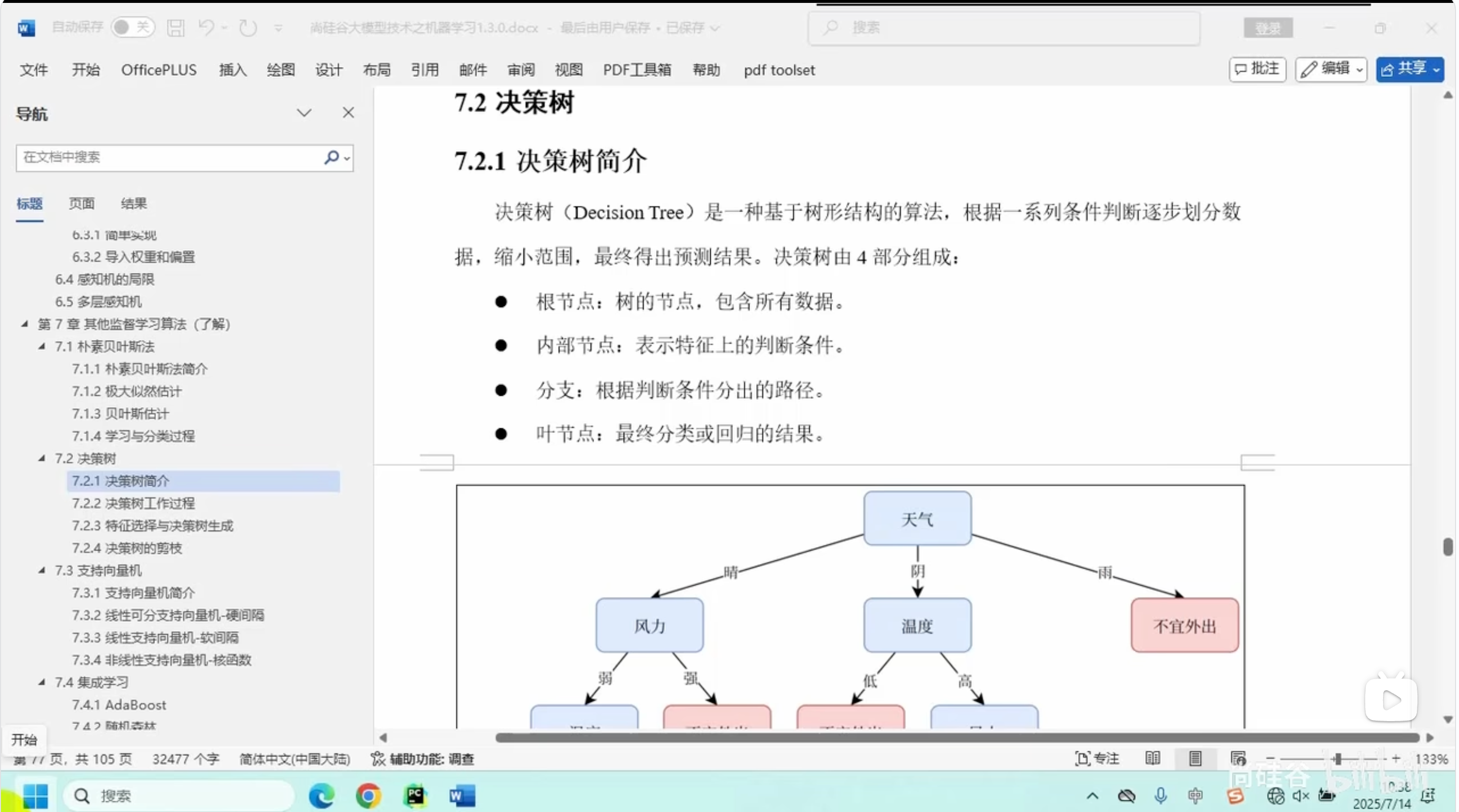
决策树简介
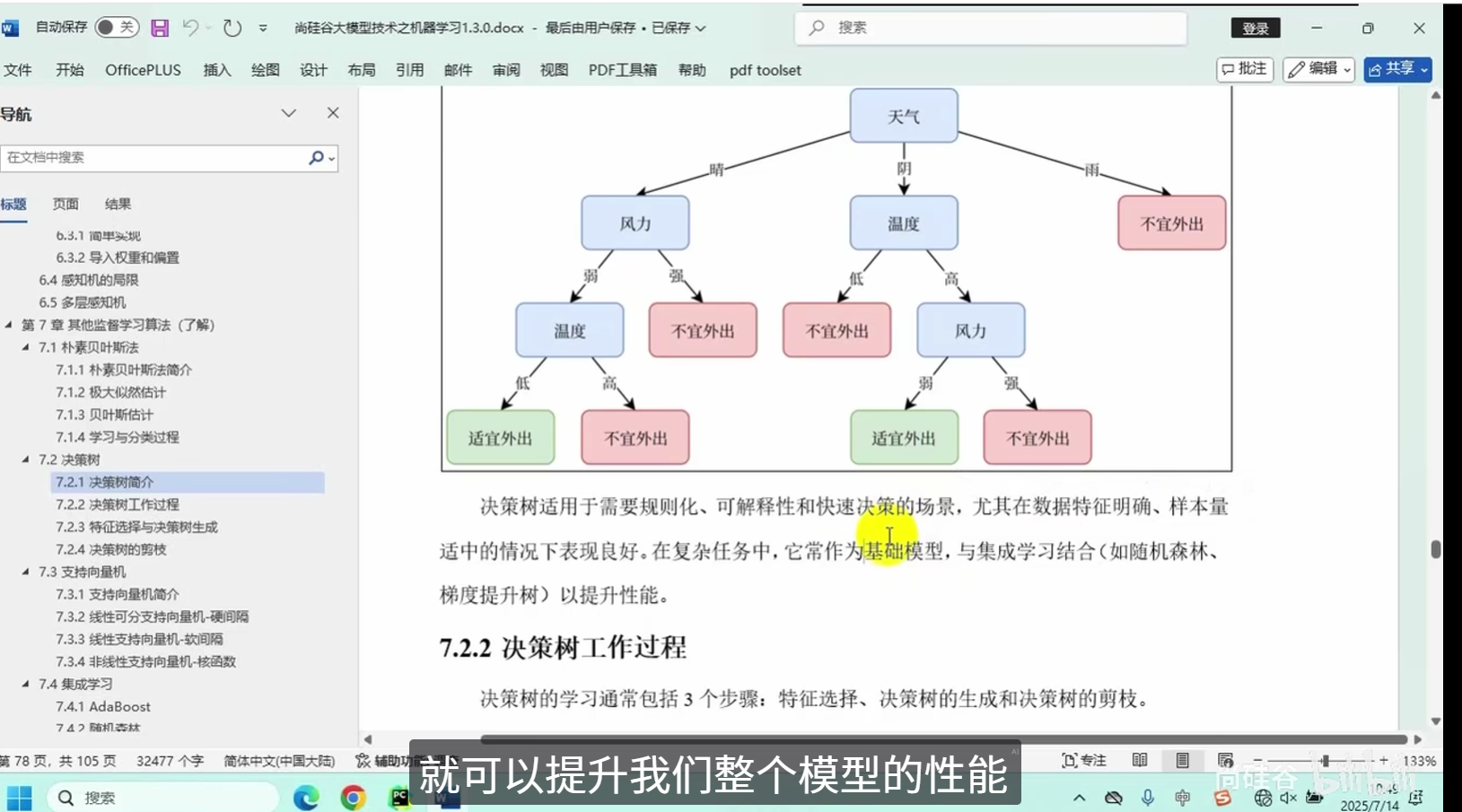
决策树工作过程
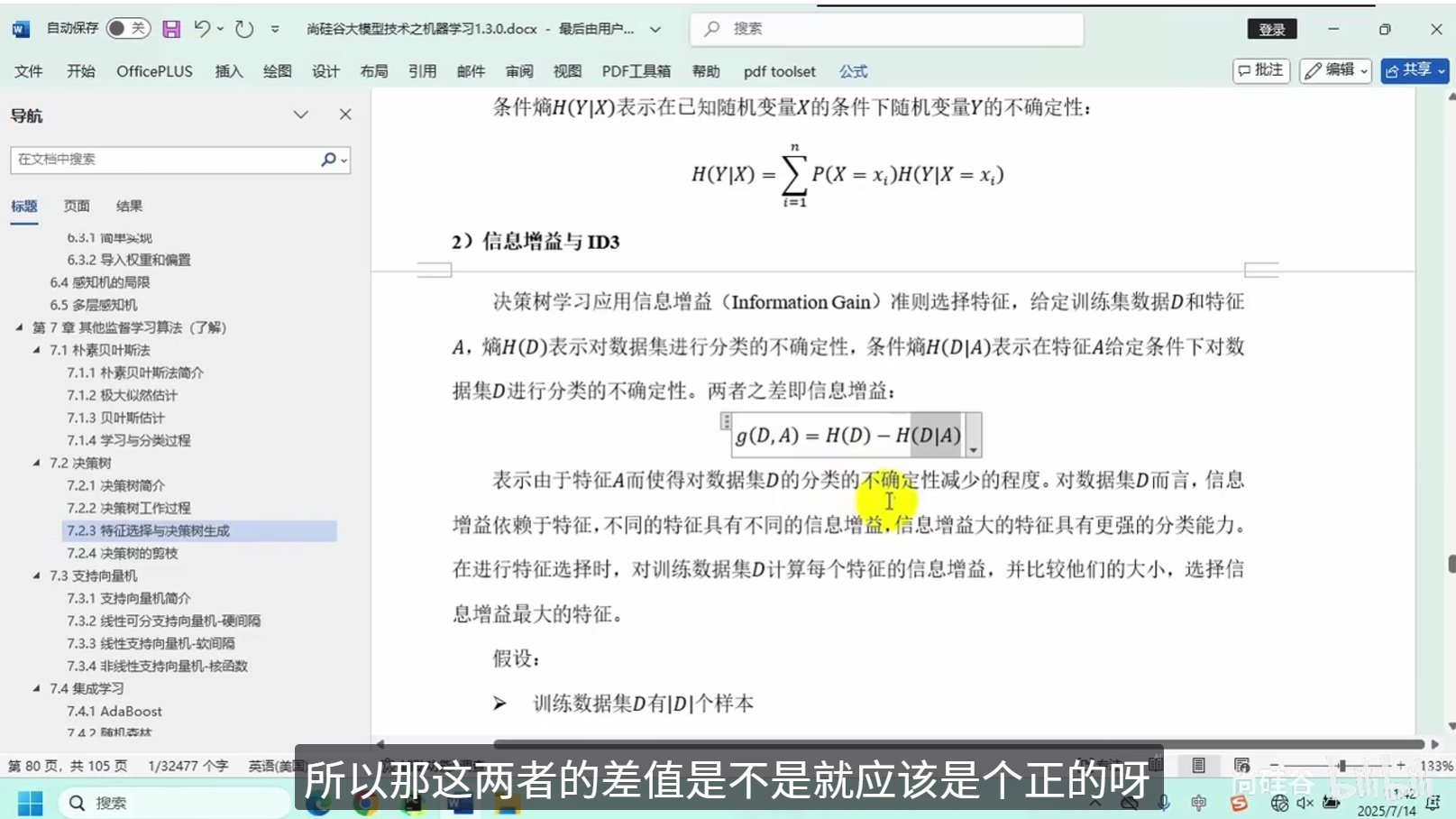
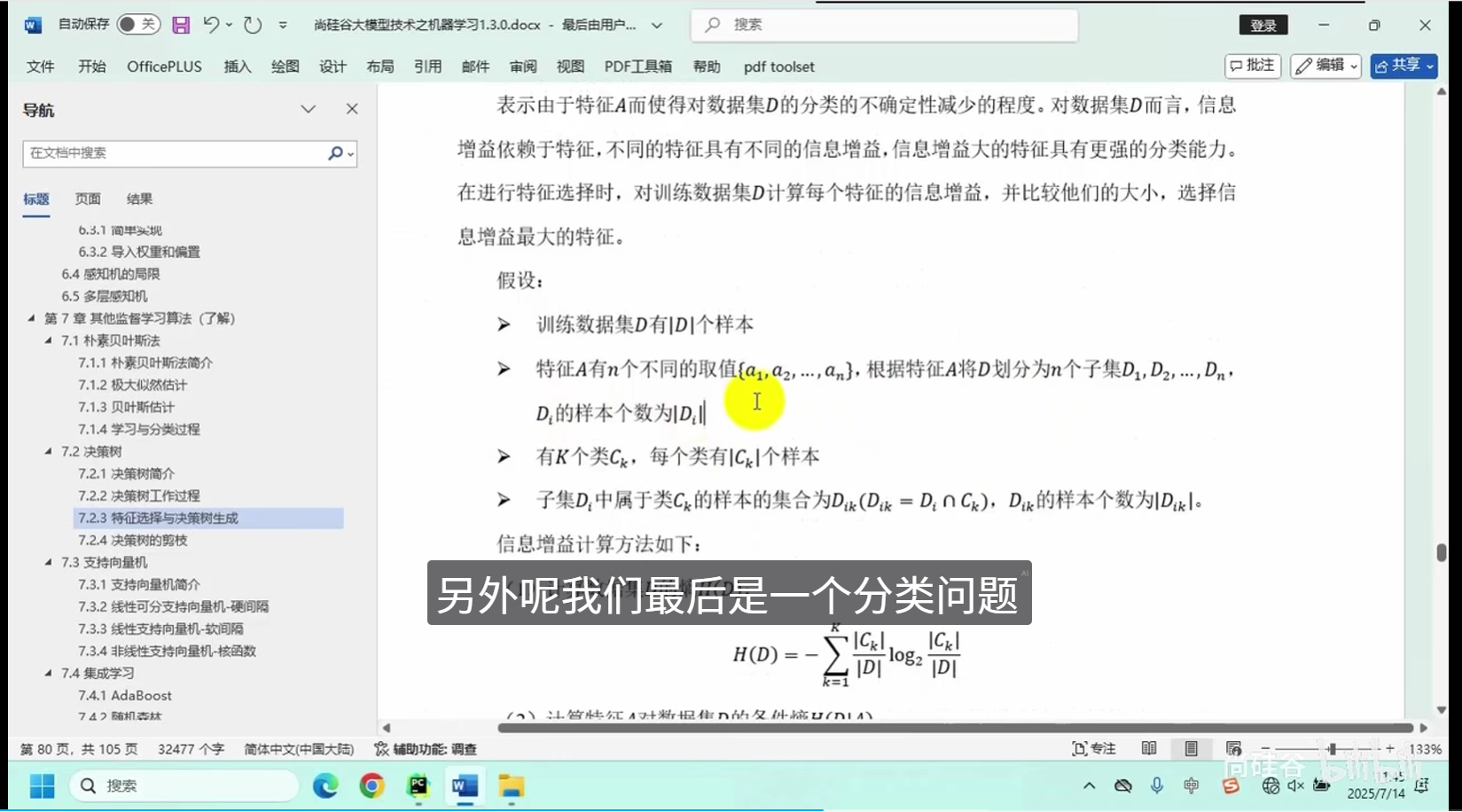
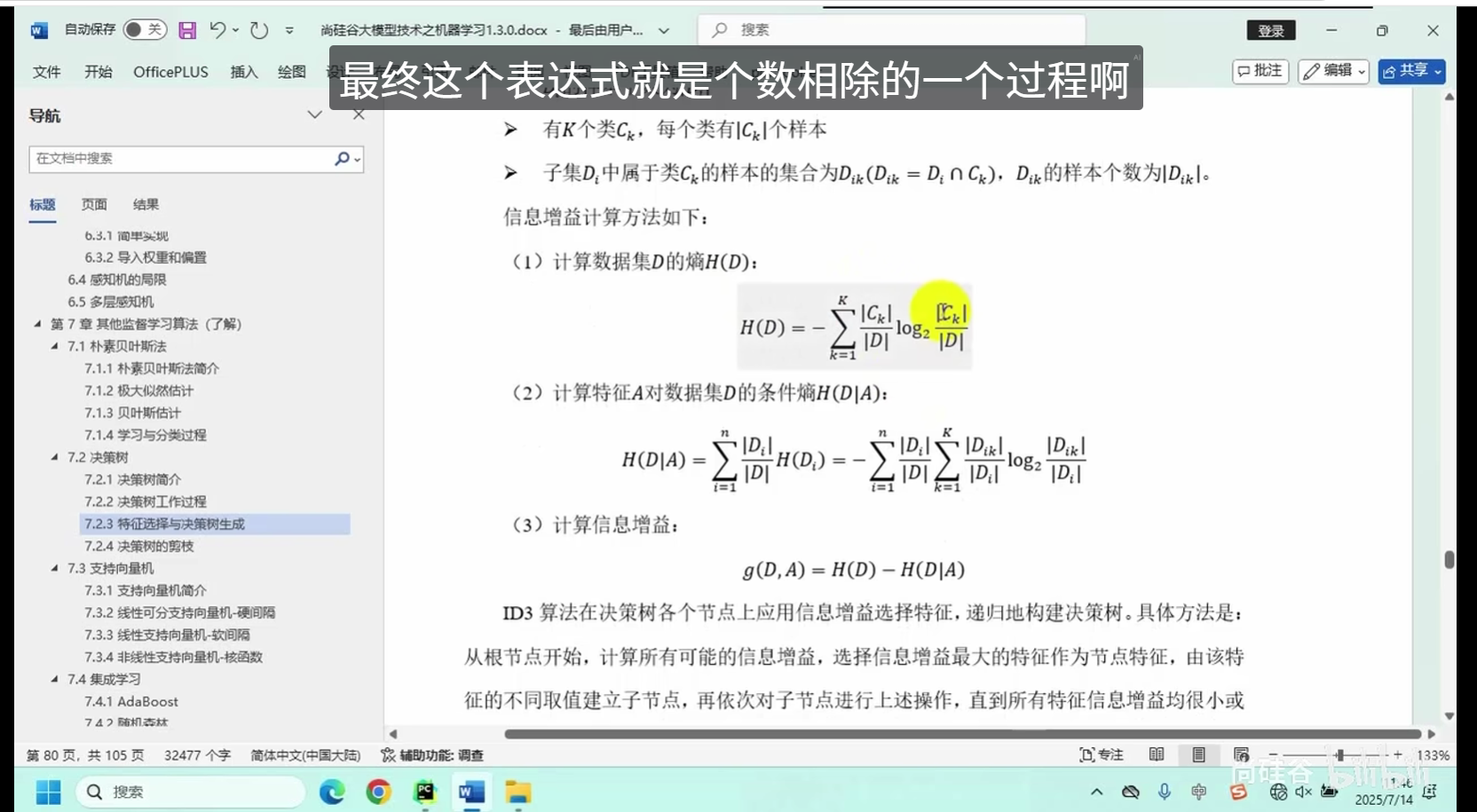
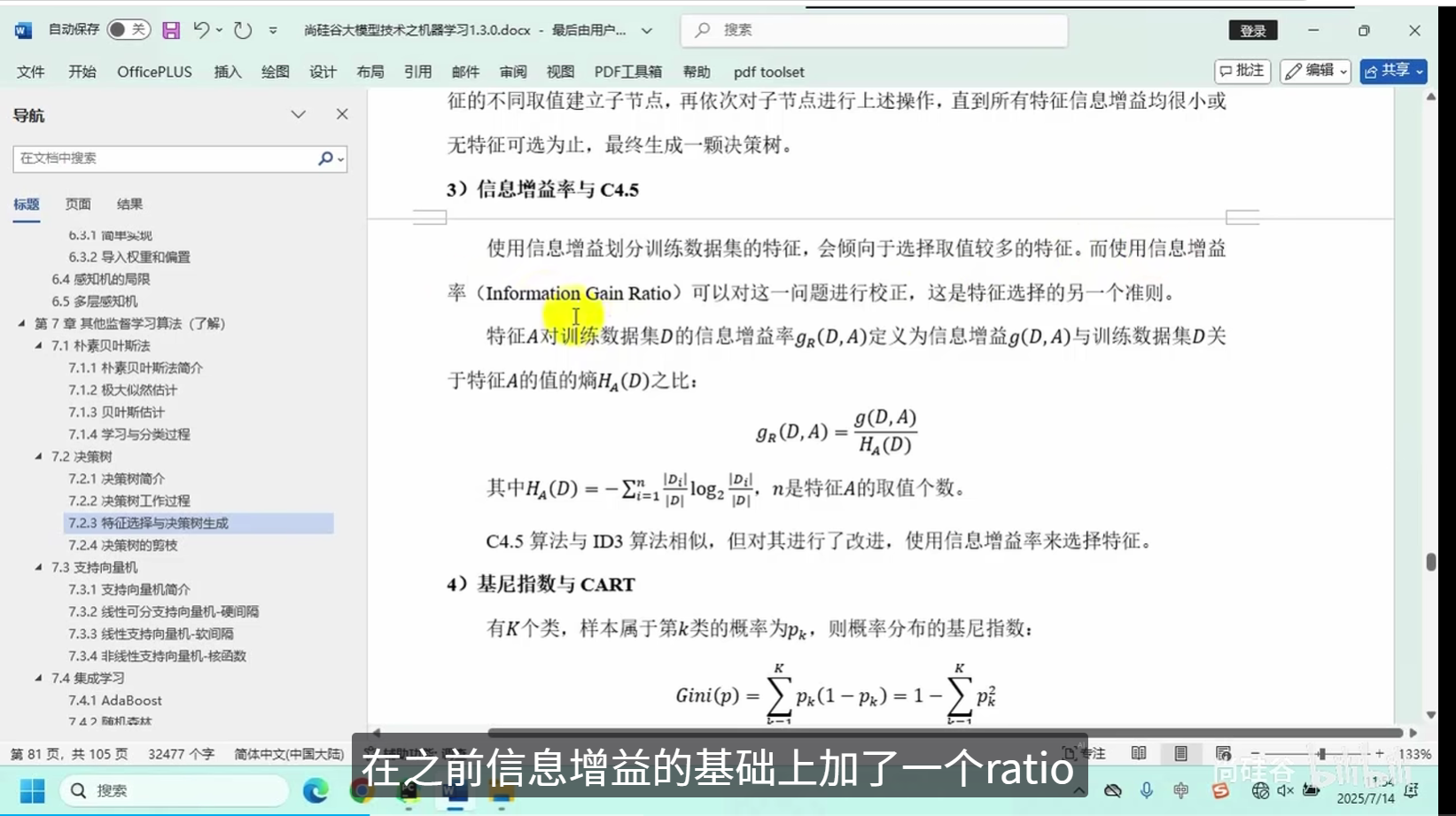
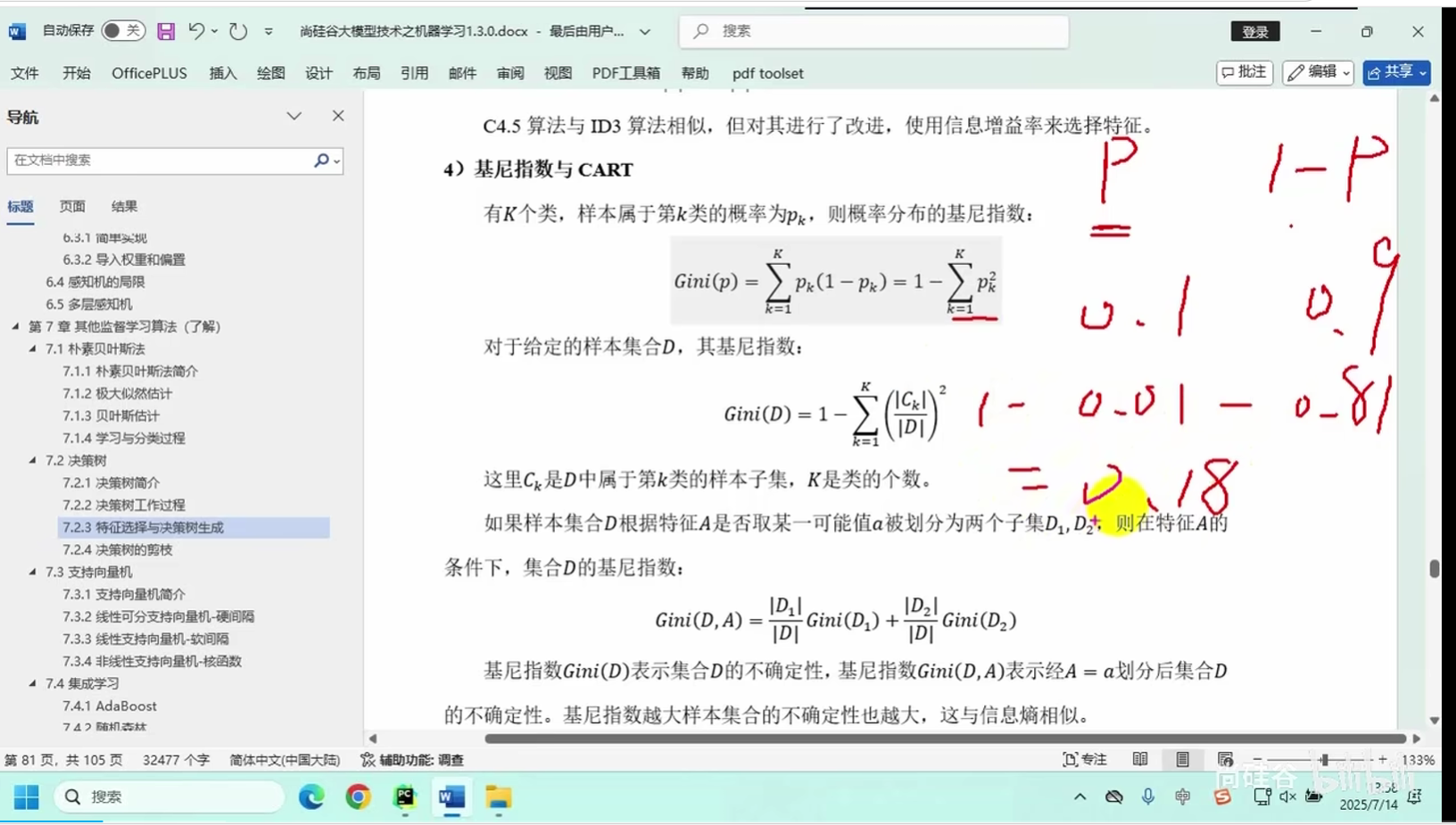
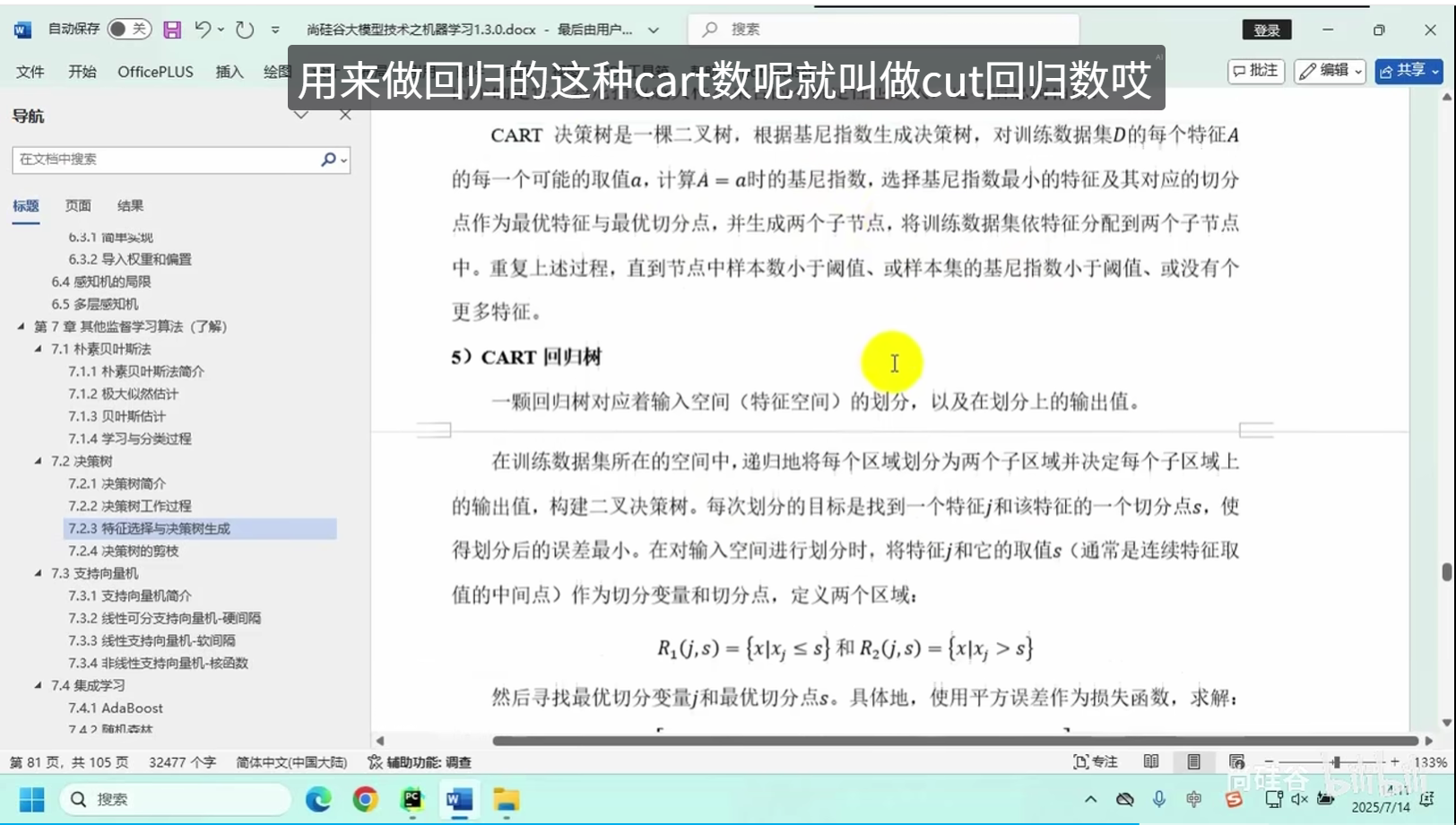
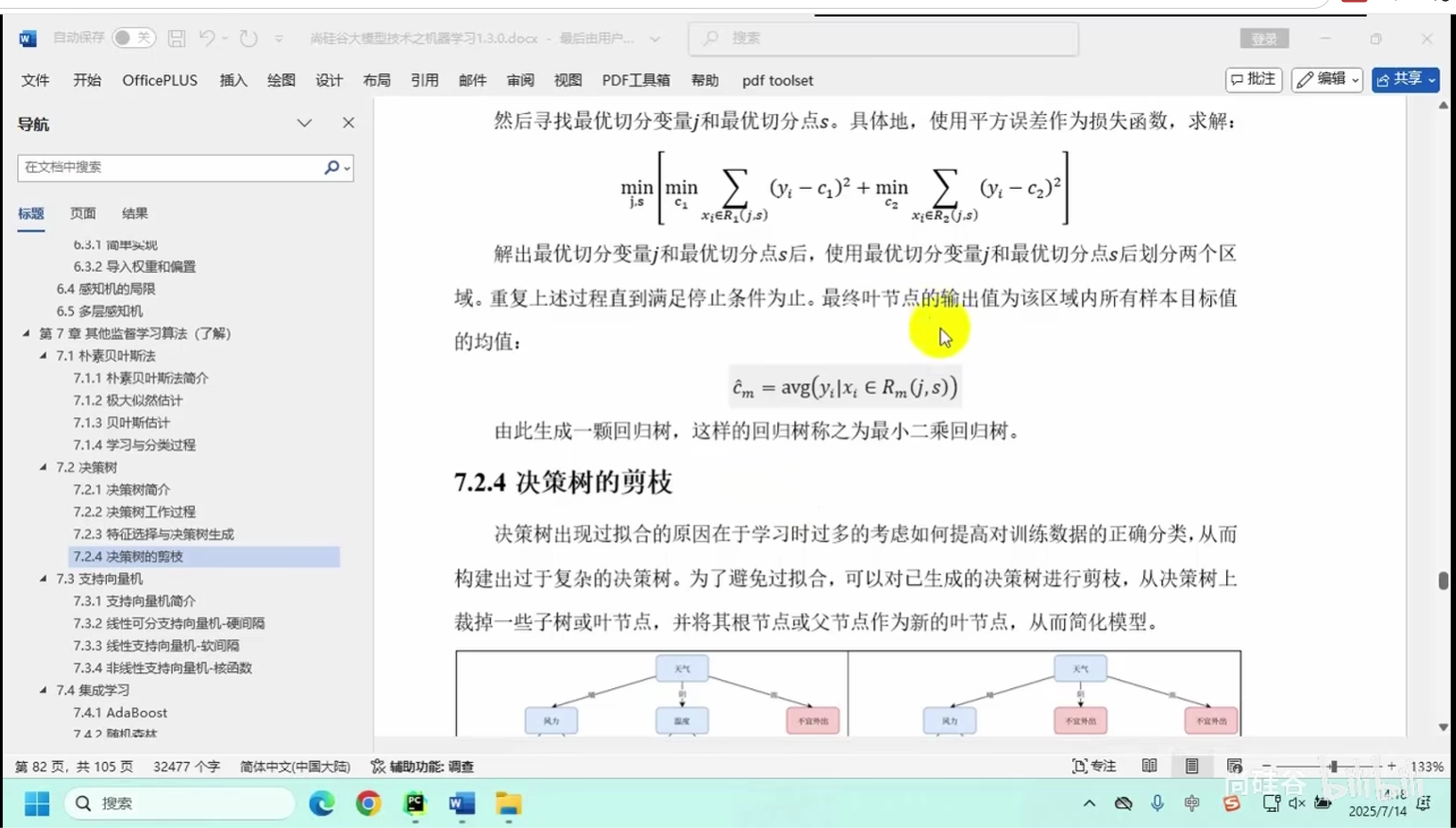
特征选择与决策树生成
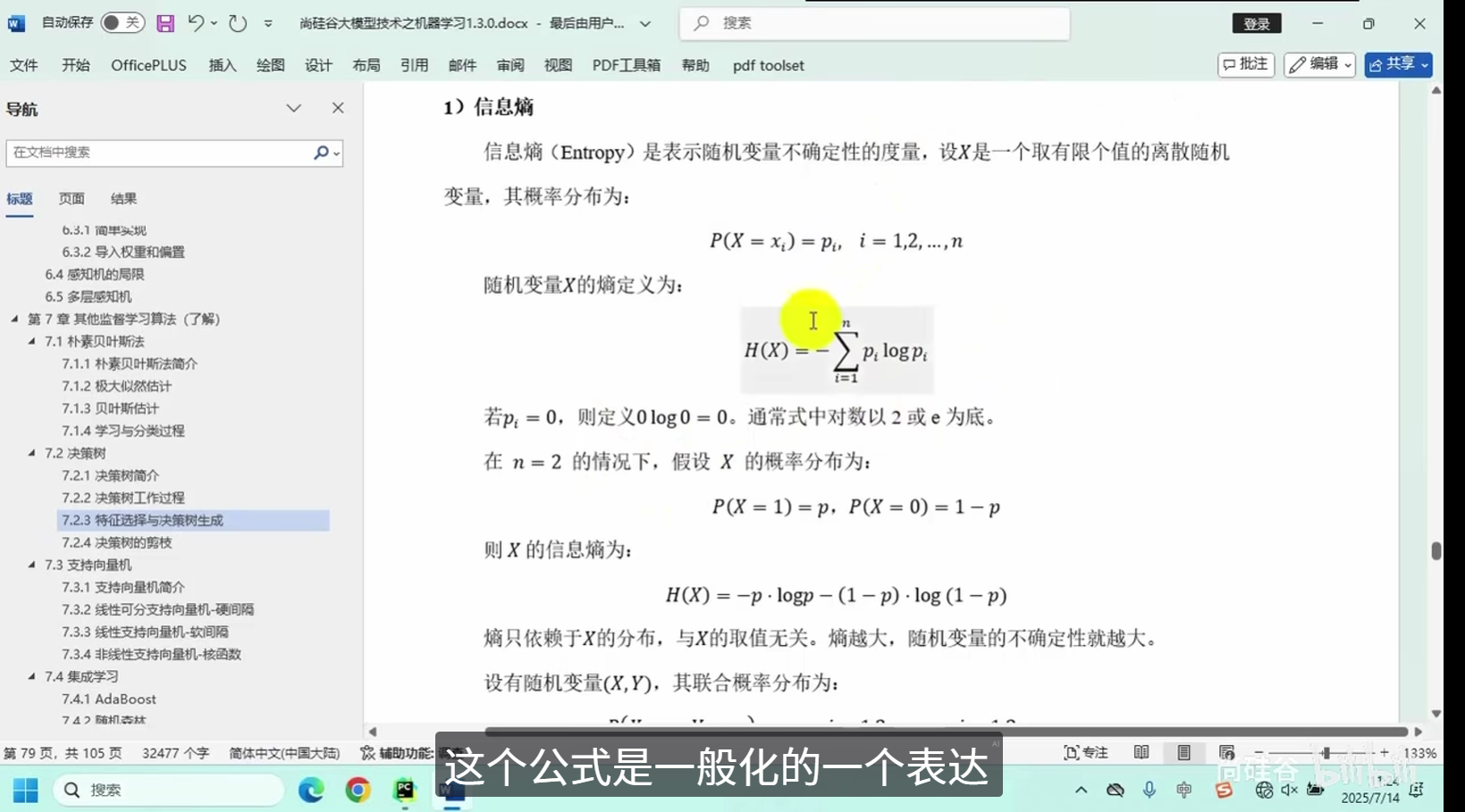
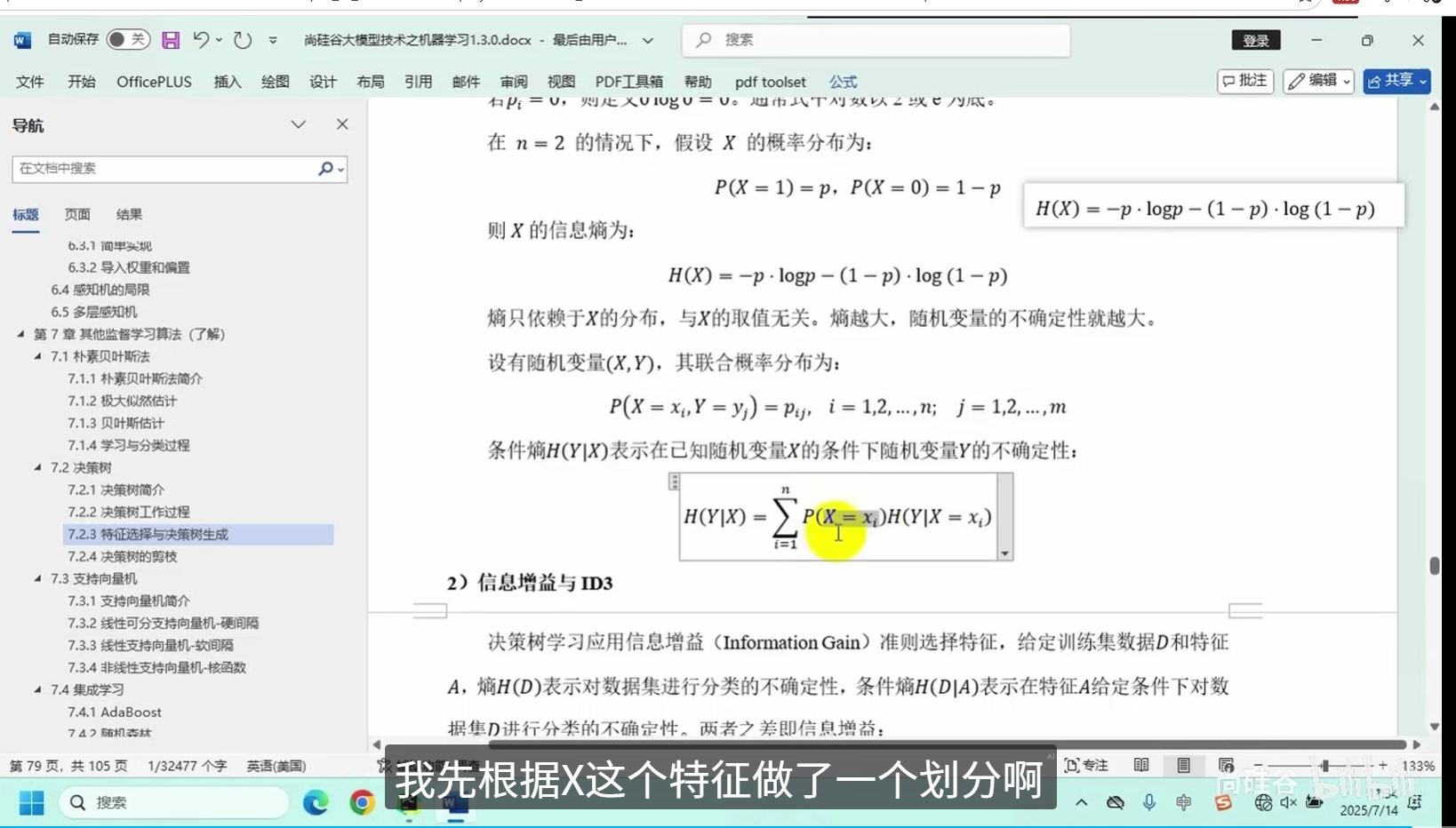
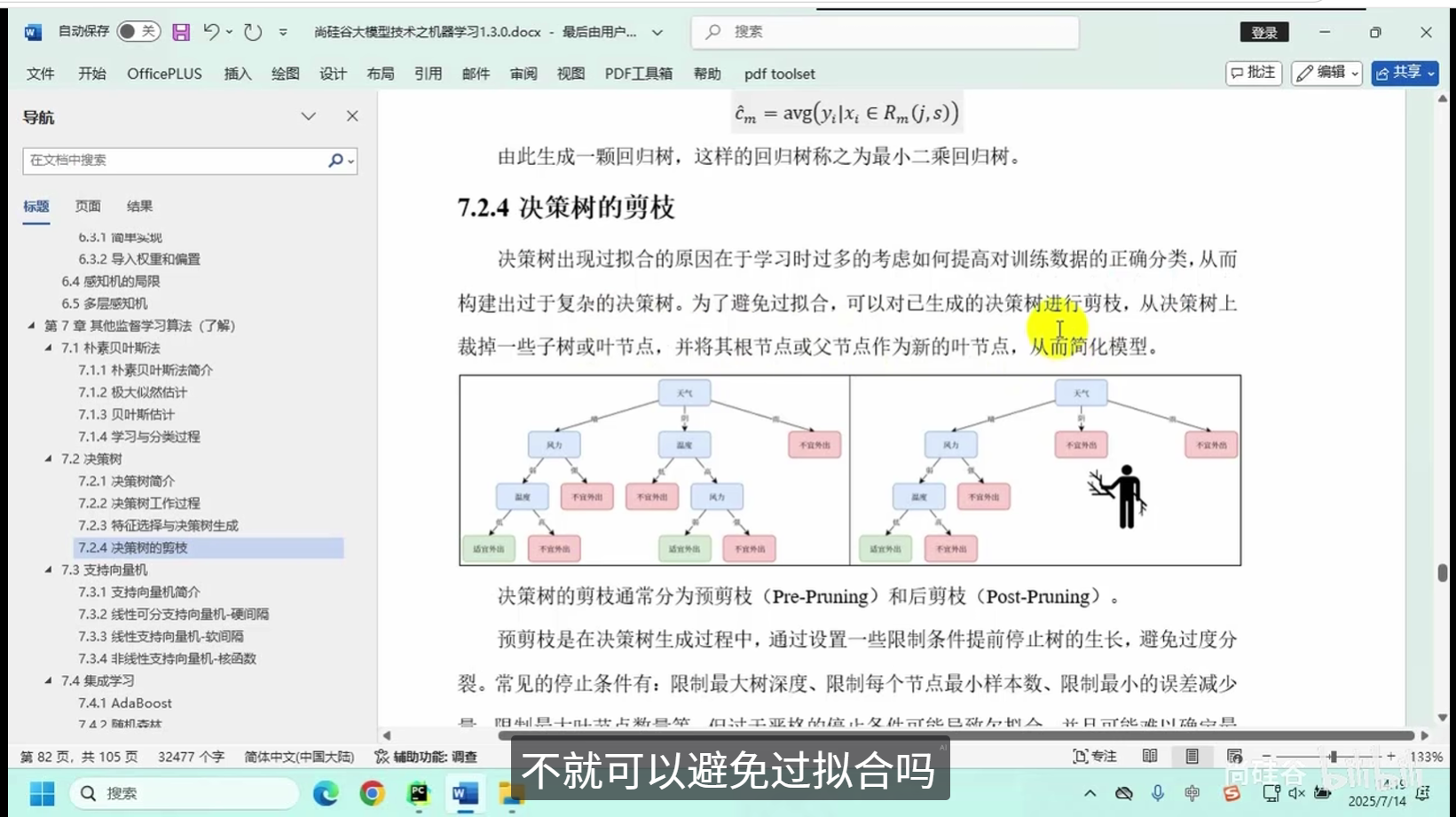
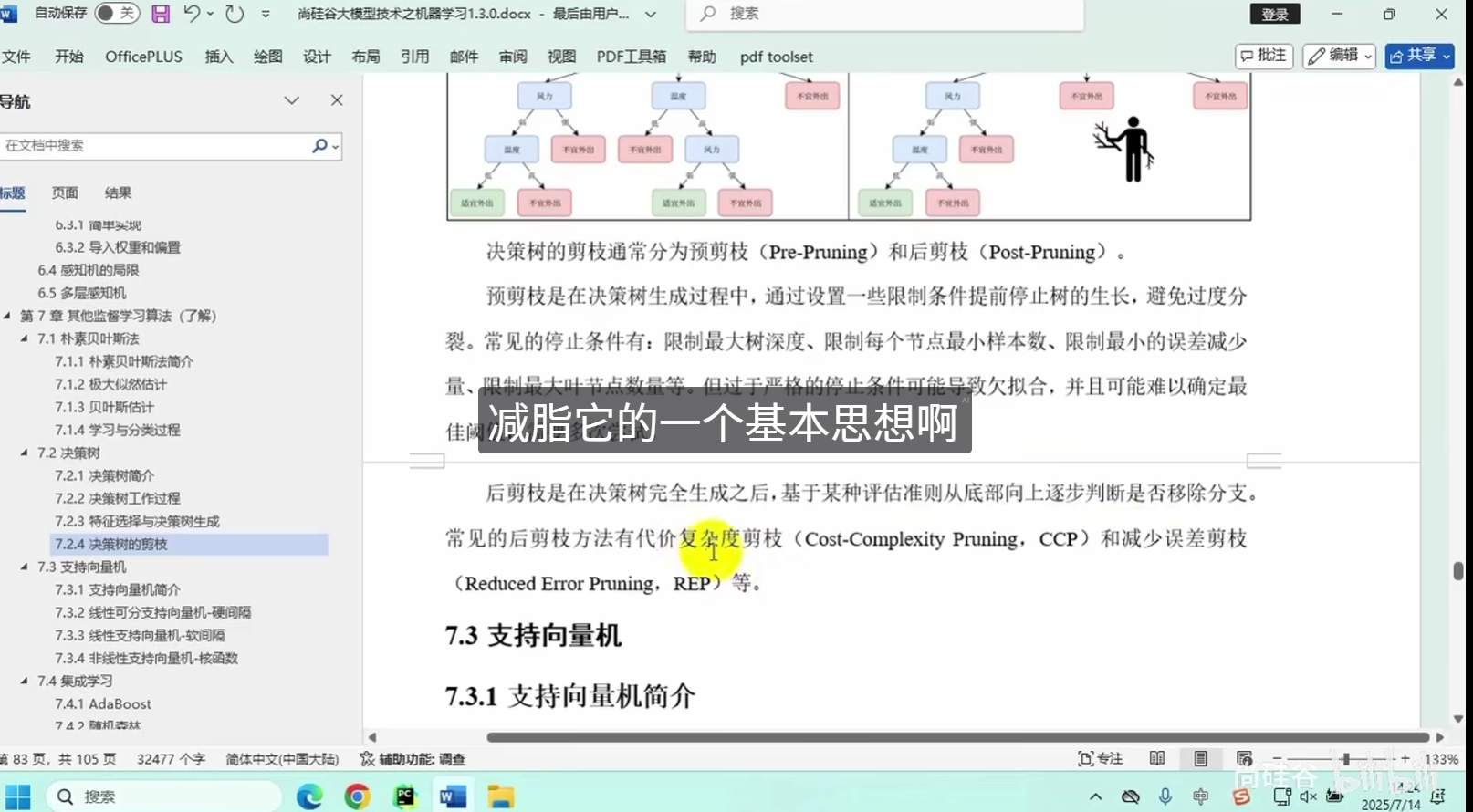
决策树的剪枝
支持向量机
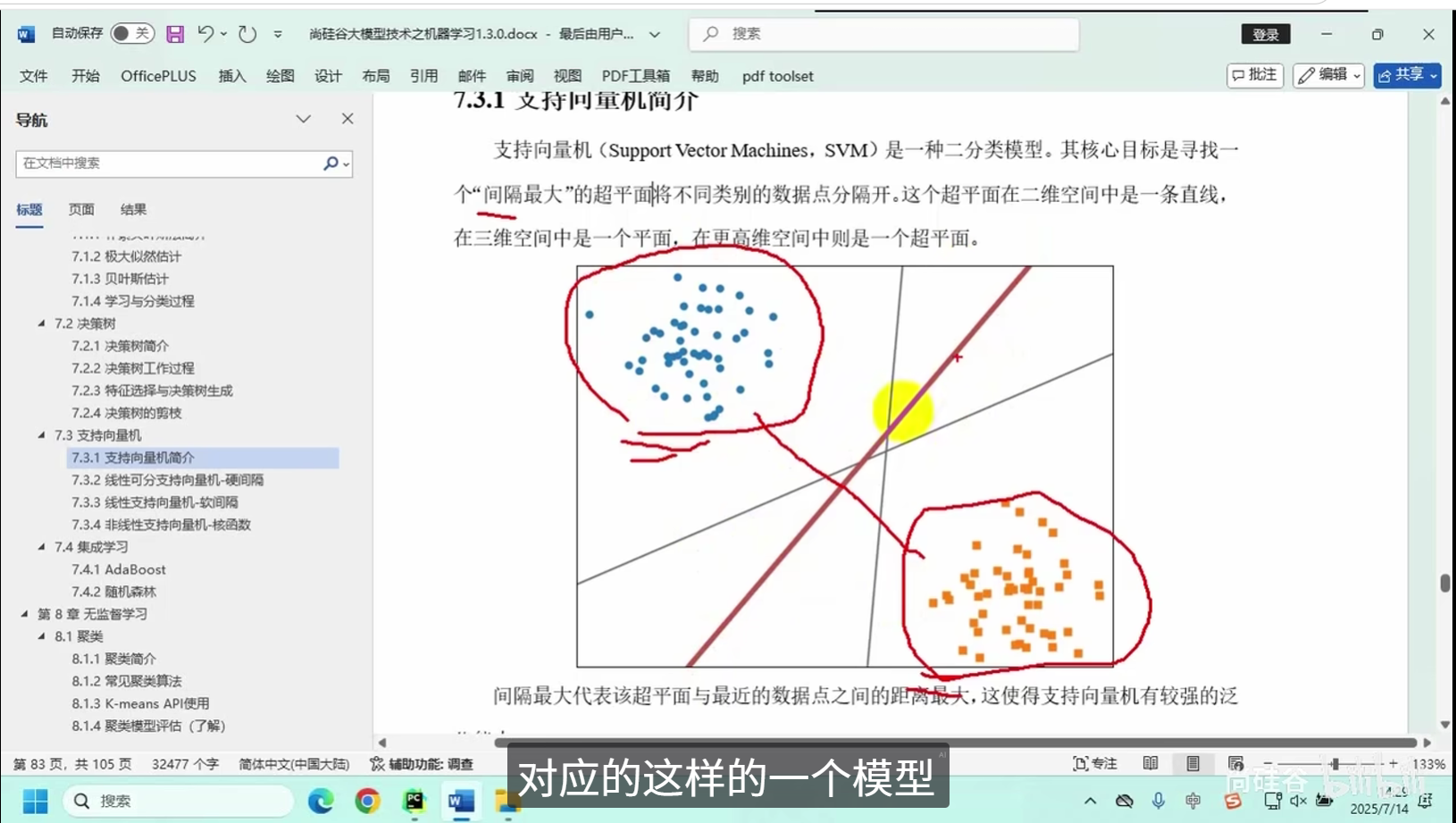
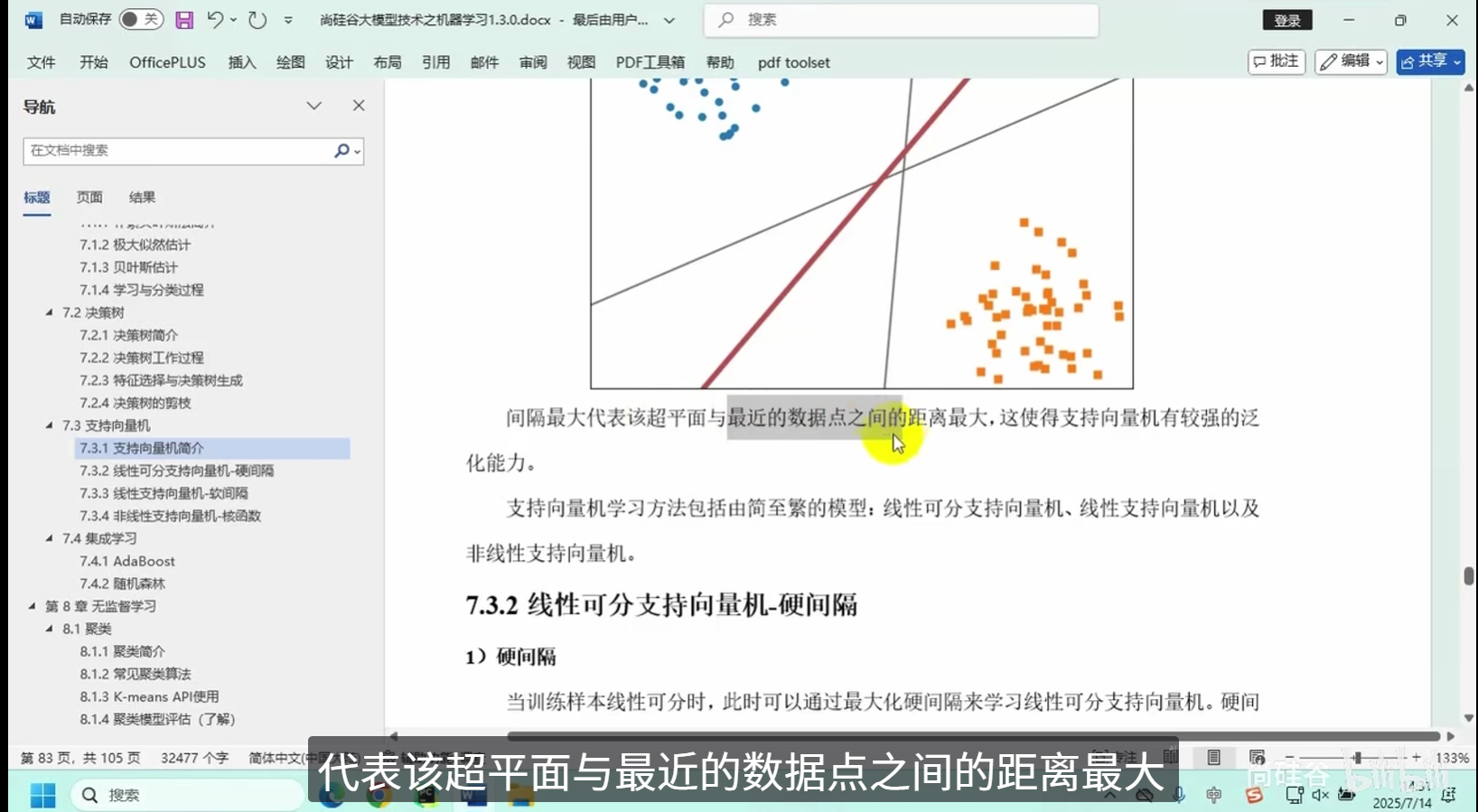
支持向量机简介
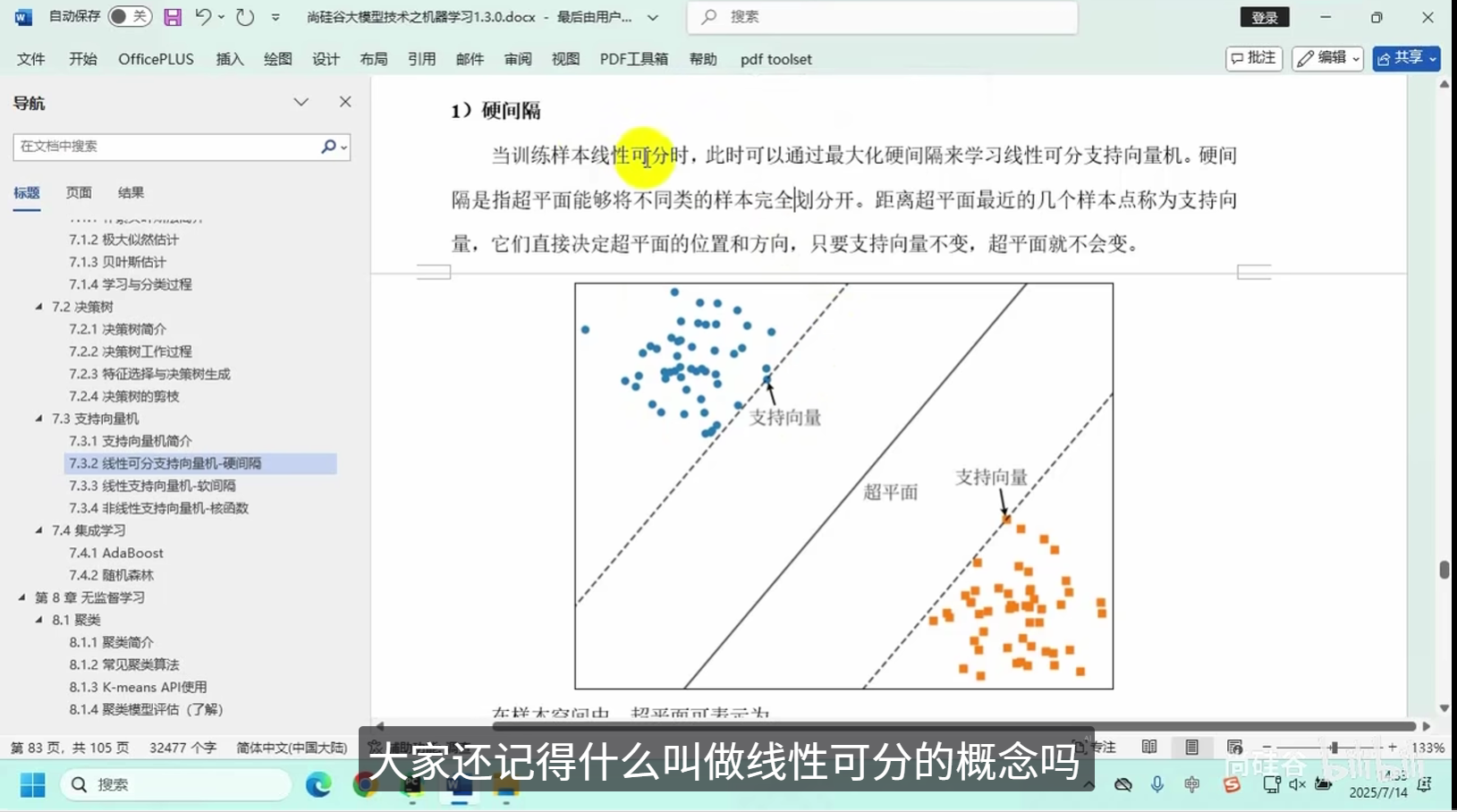
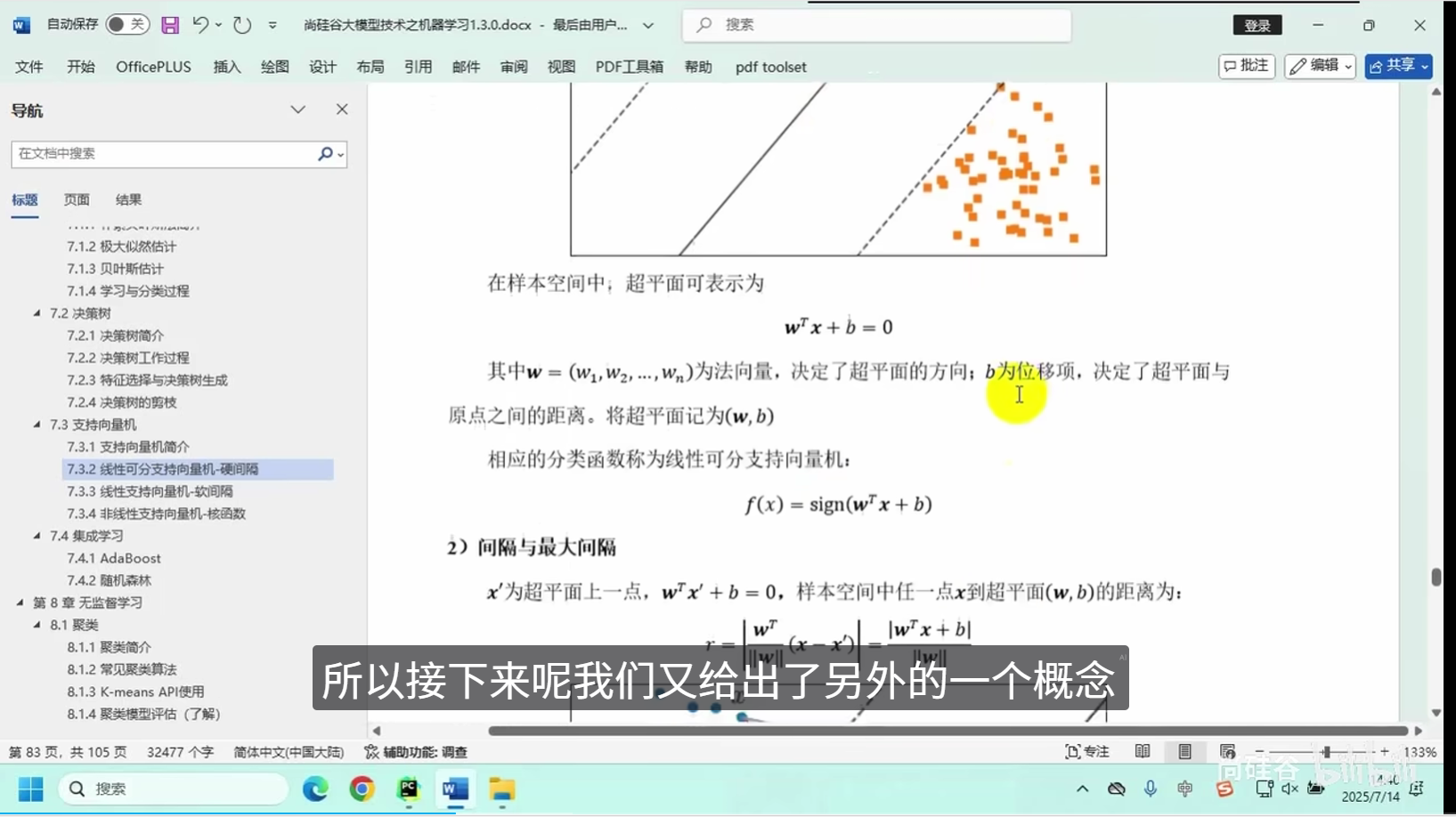
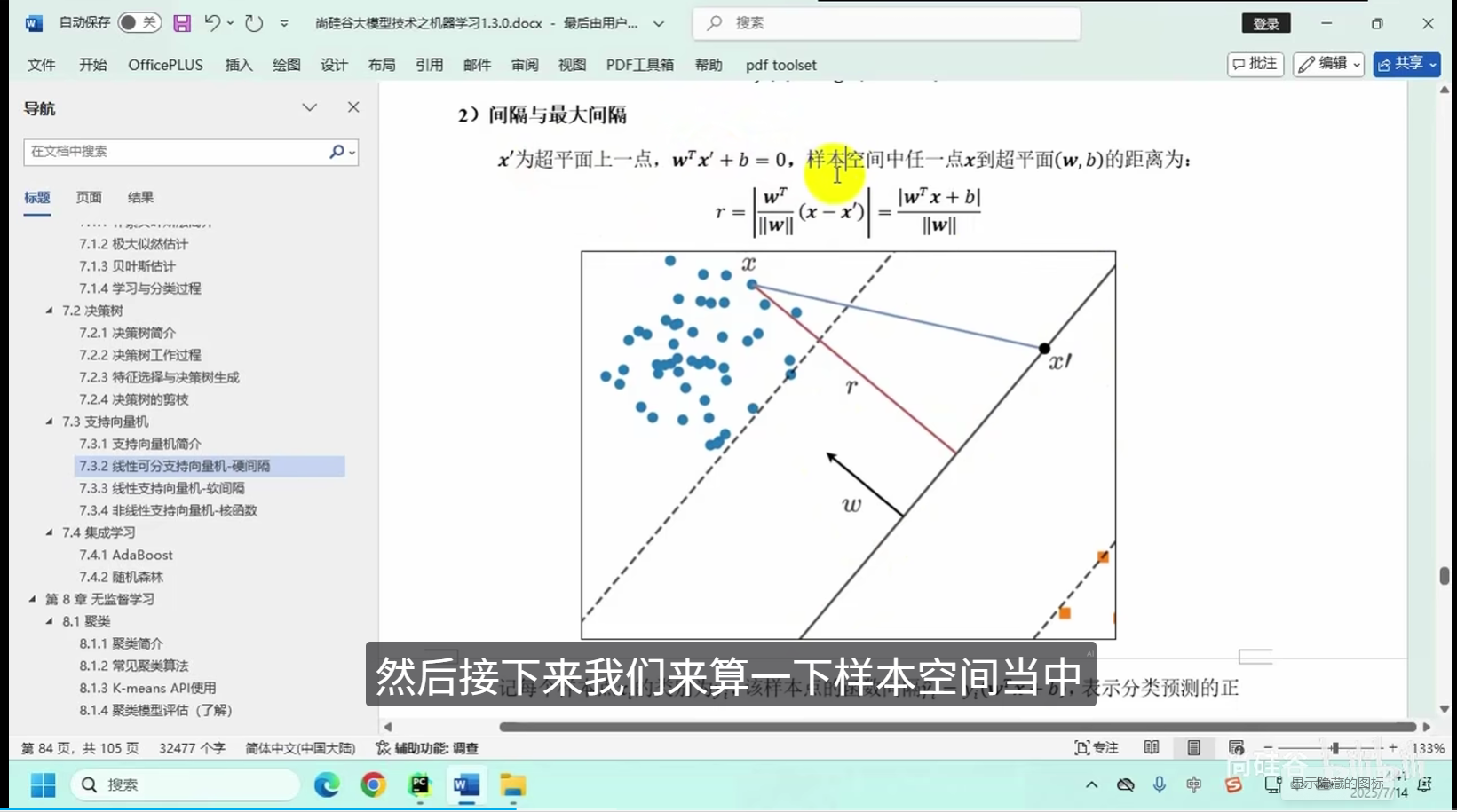
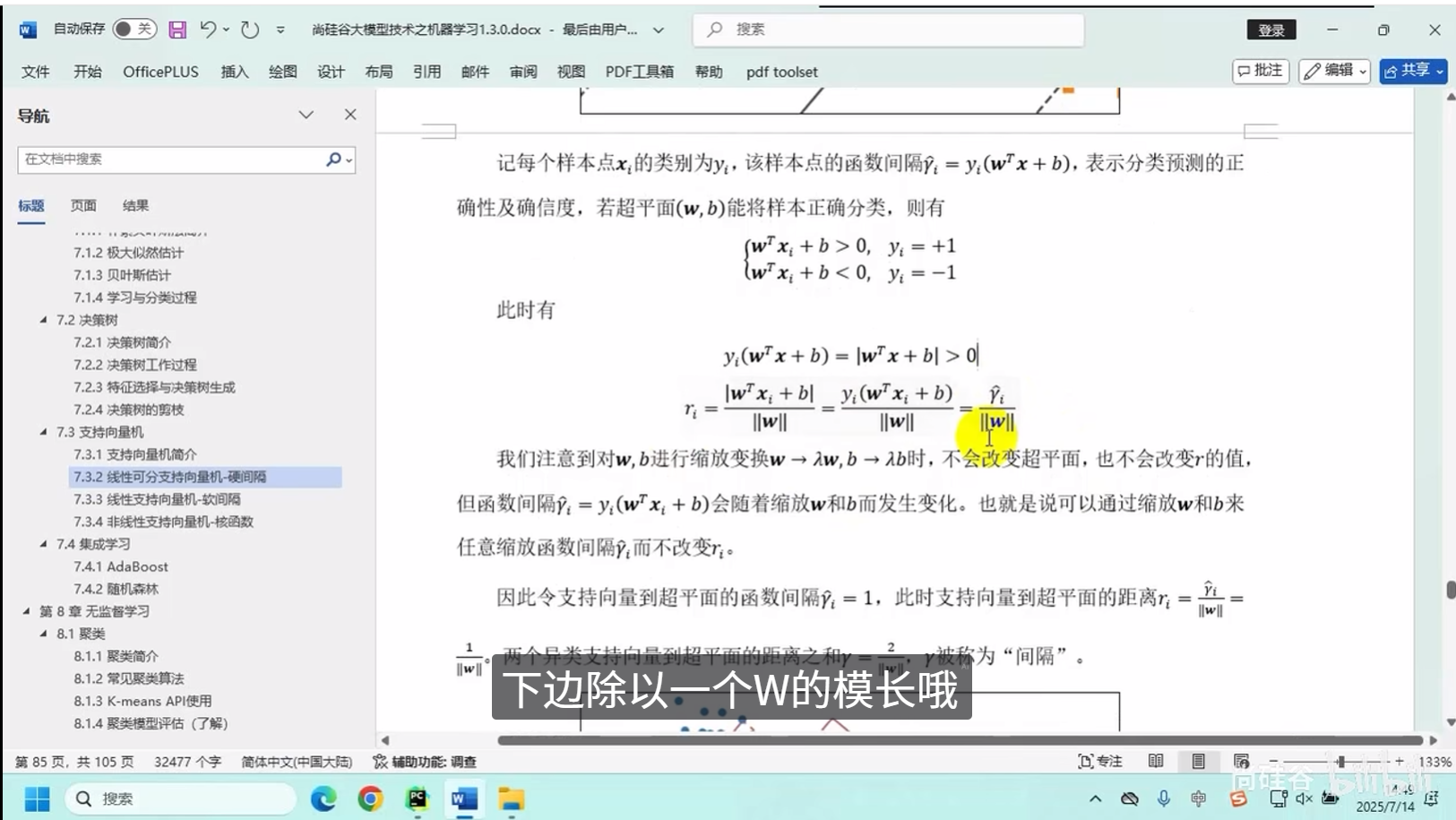
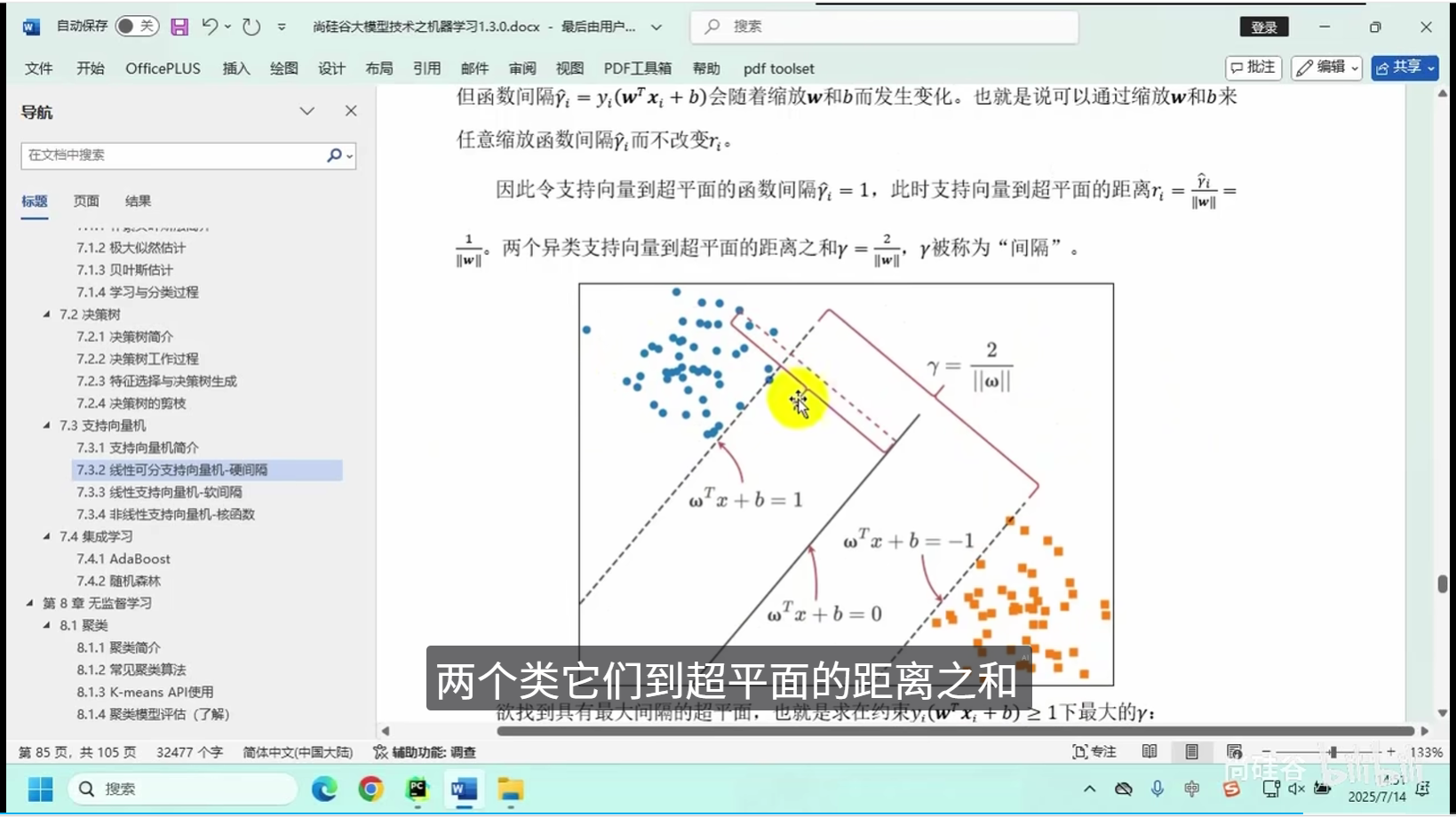
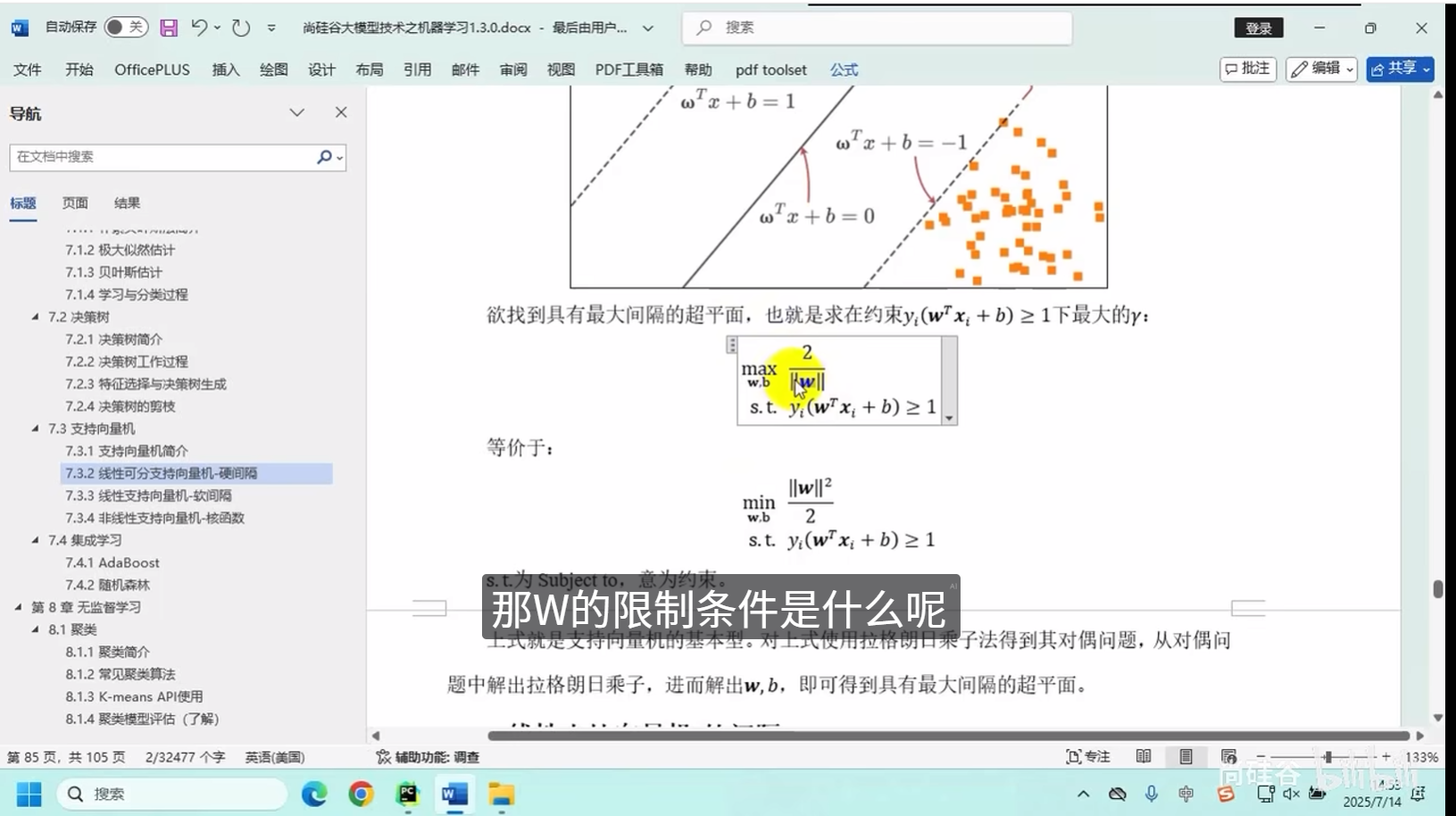
线性可分支向量机-硬间隔
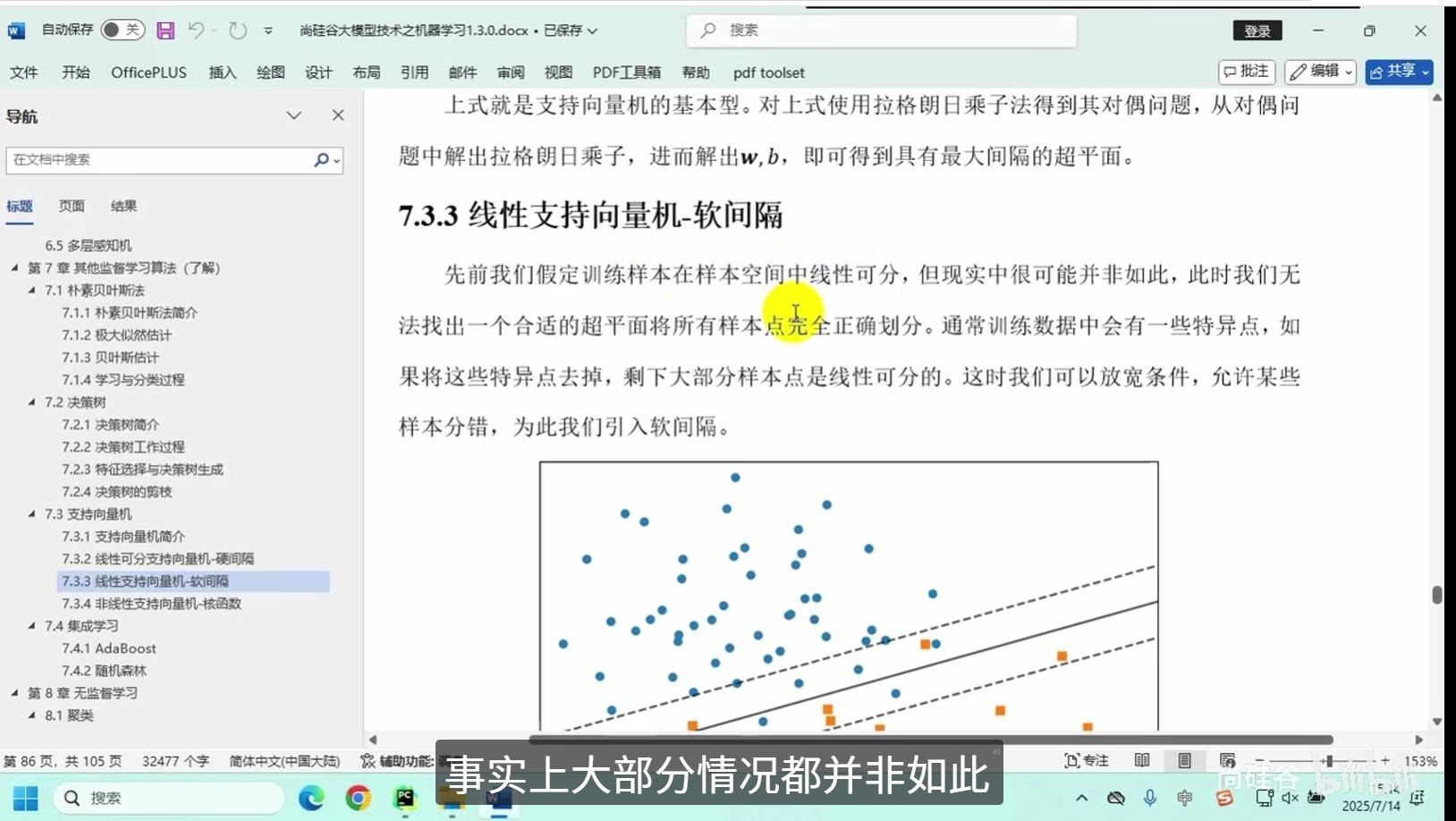
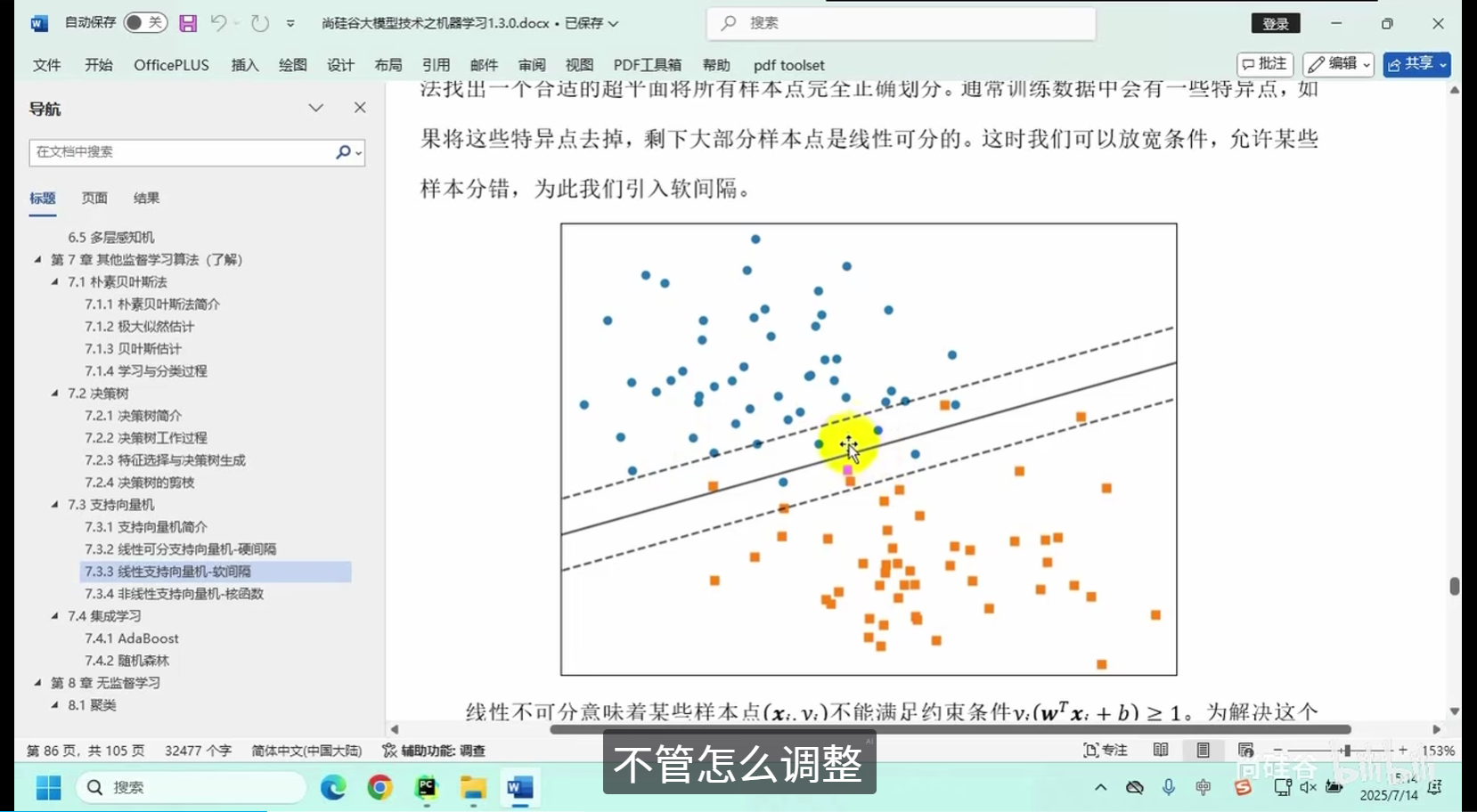
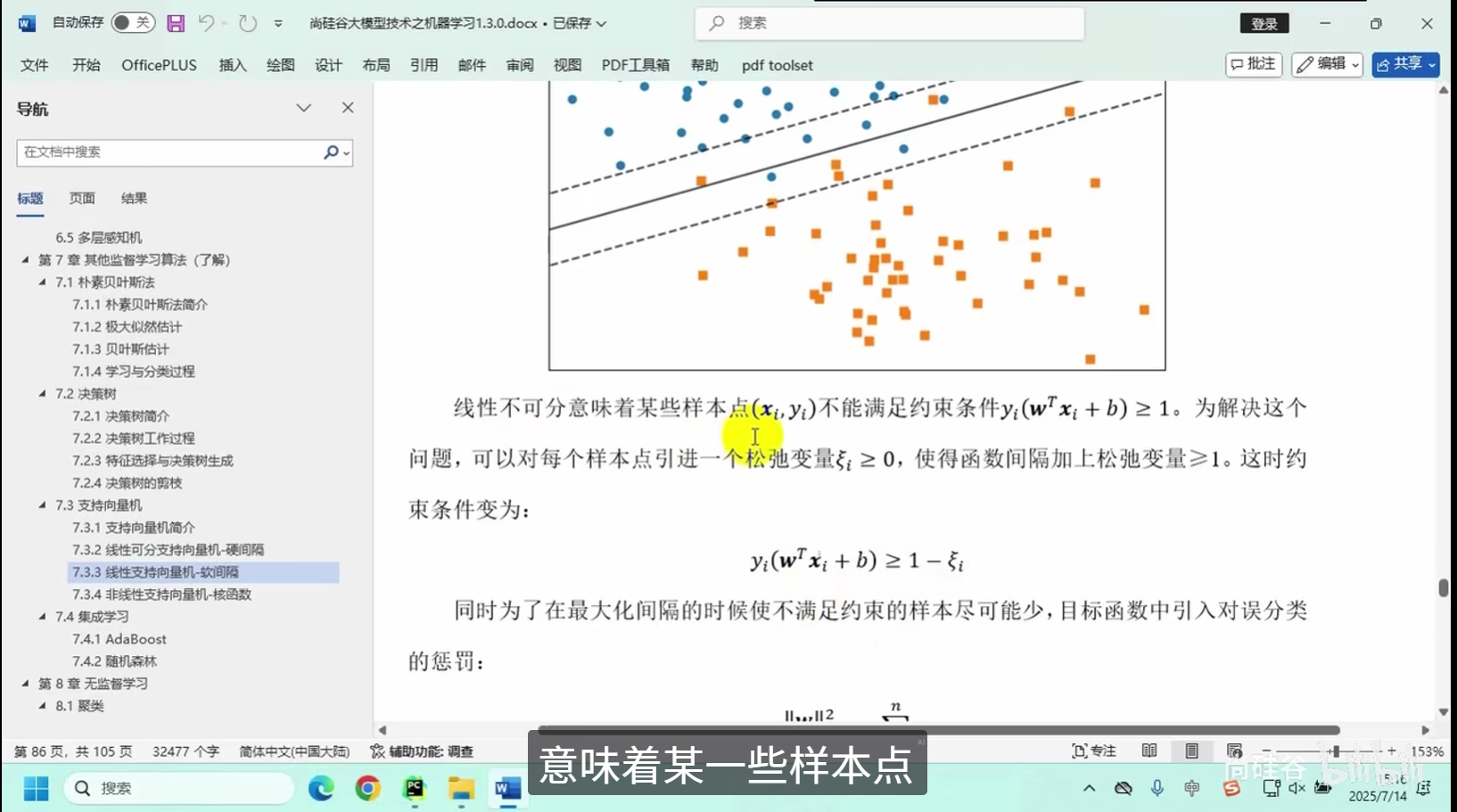
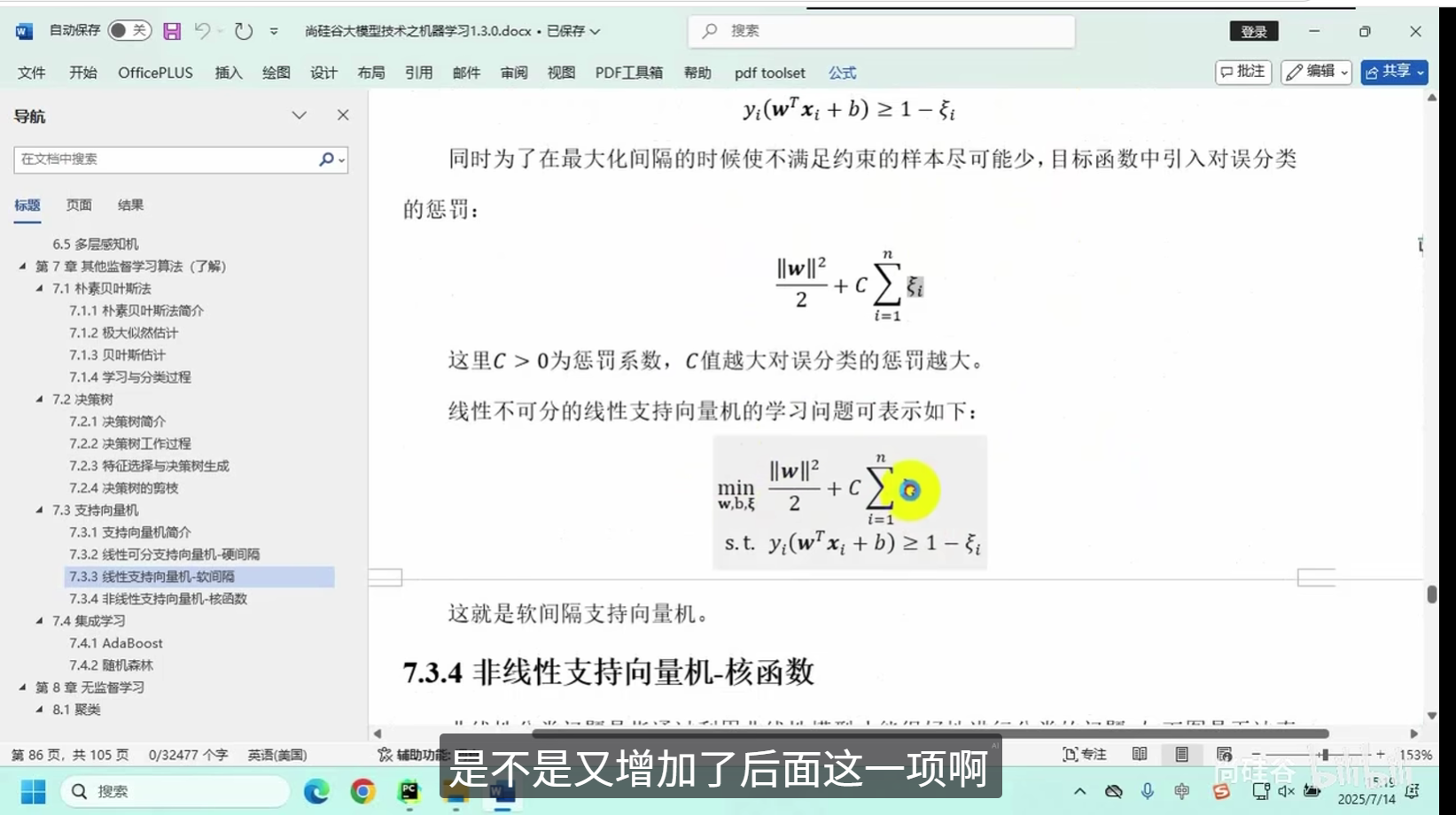
线性支持向量机-软间隔
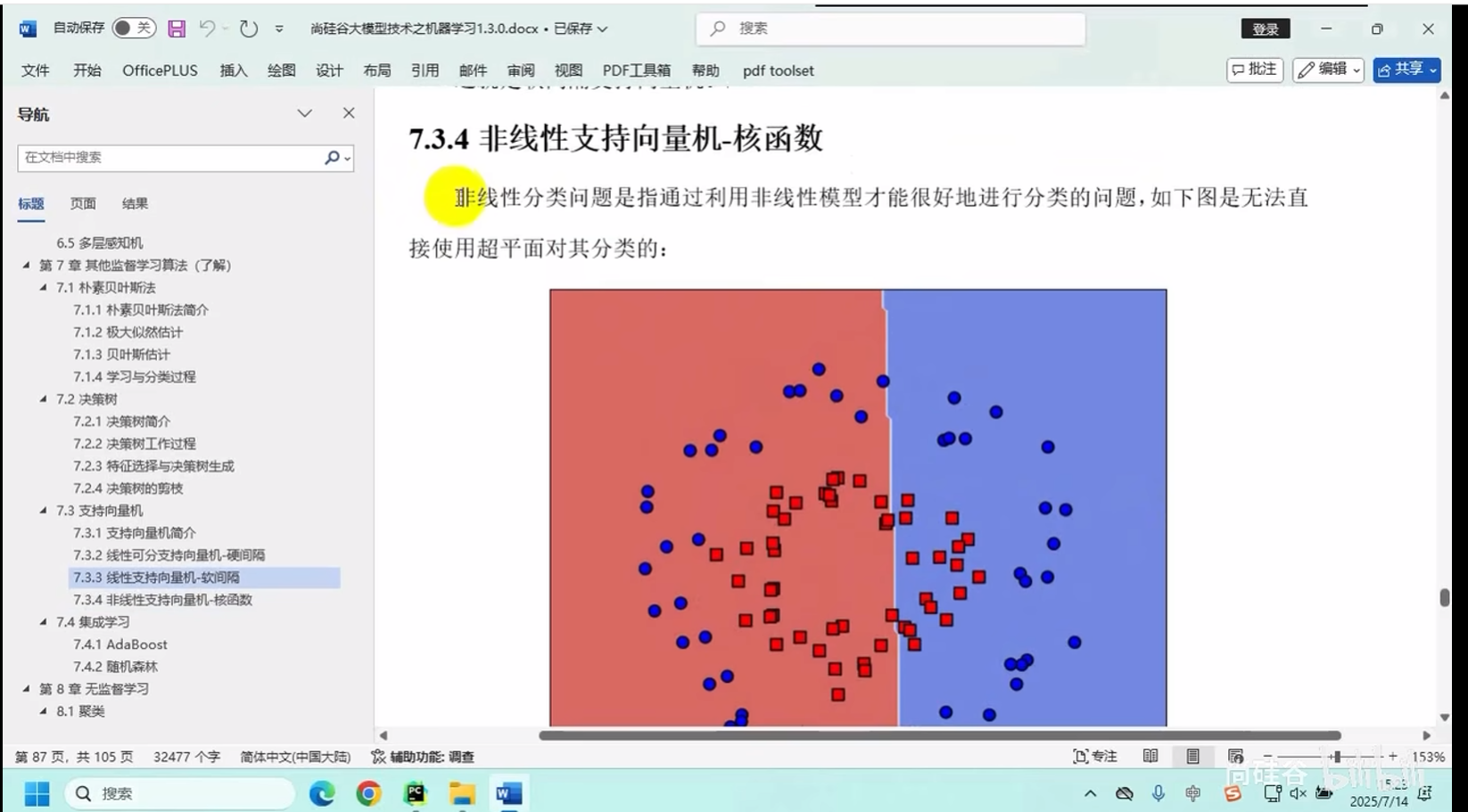
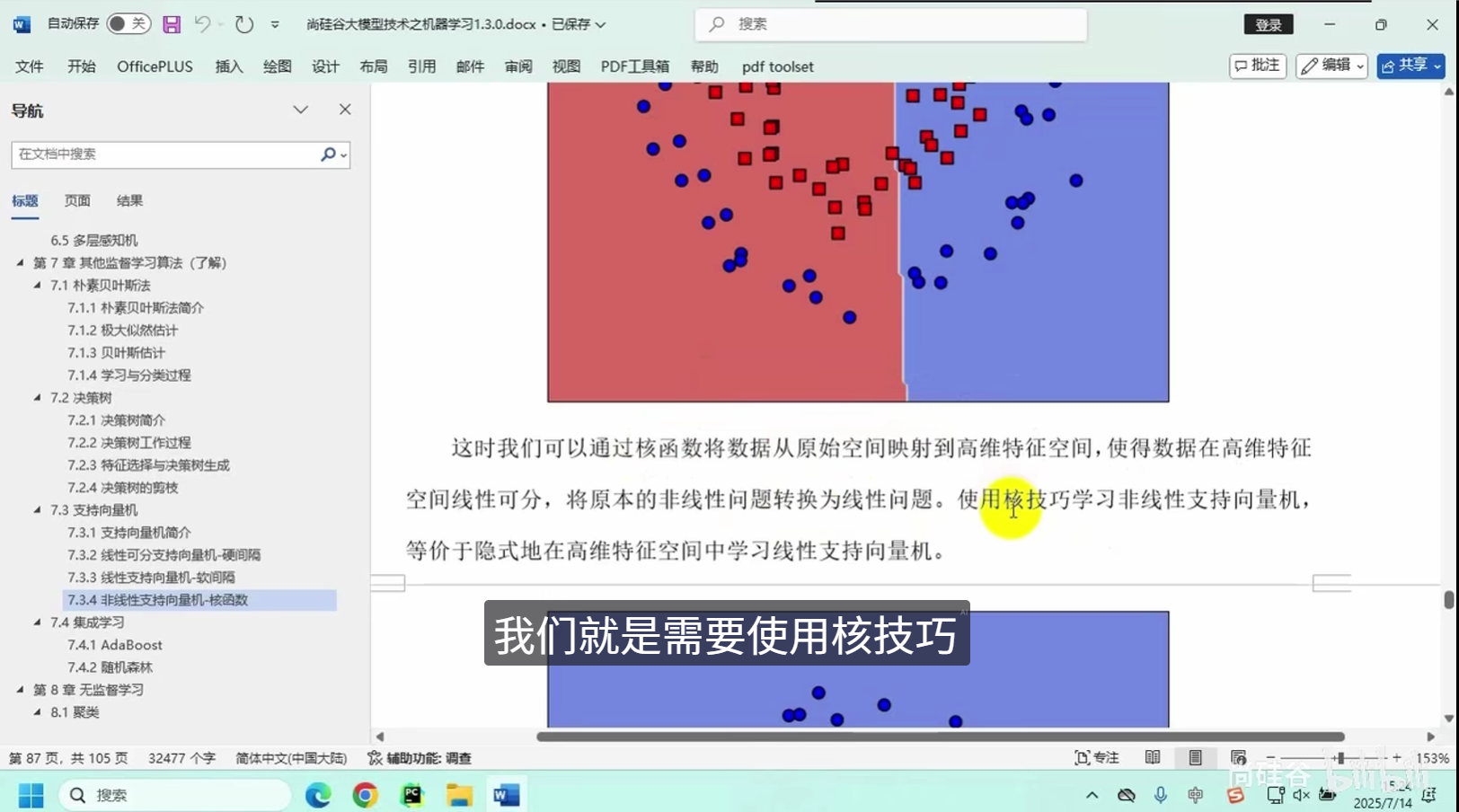
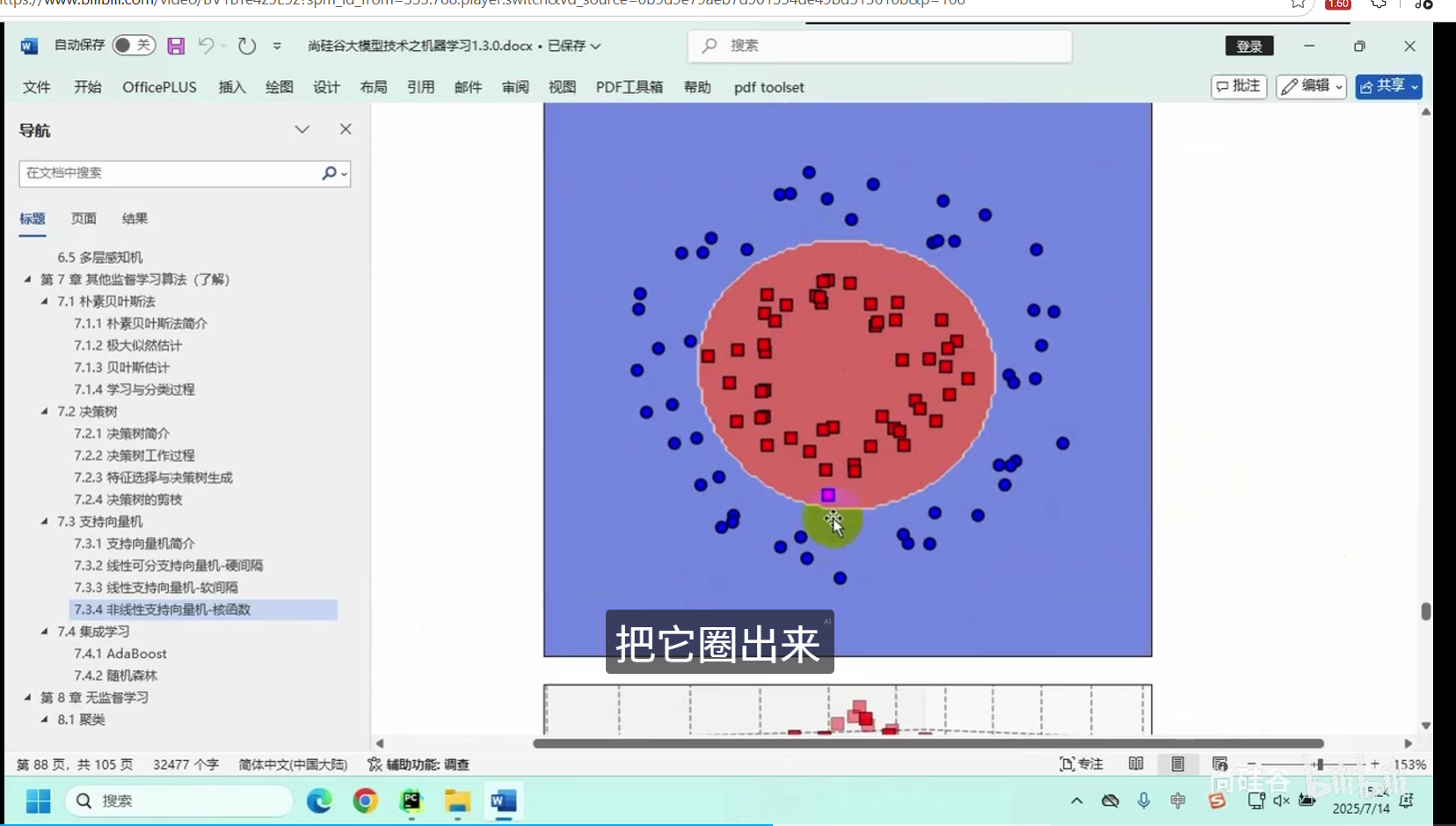
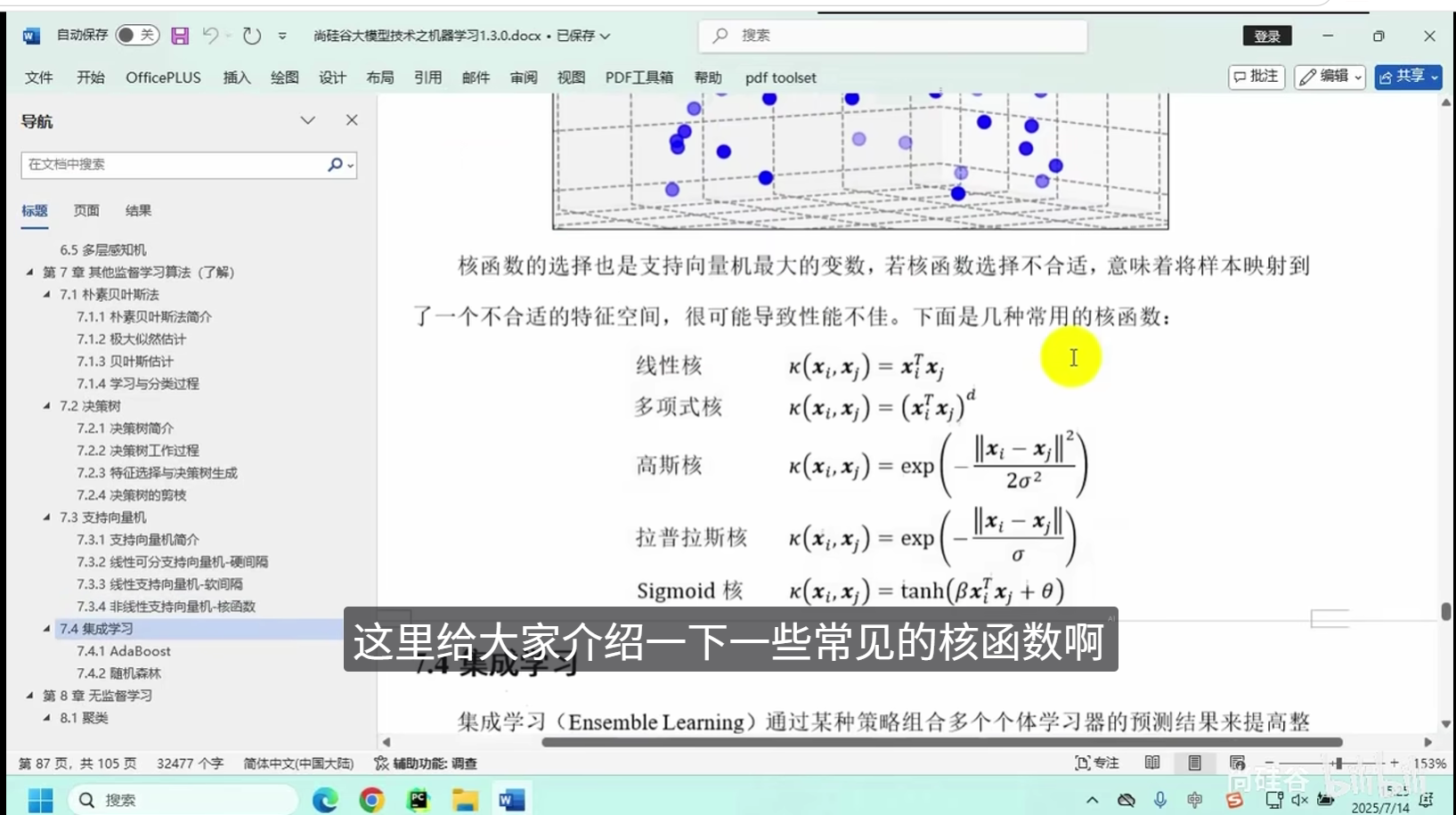
非线性支持向量机-核函数
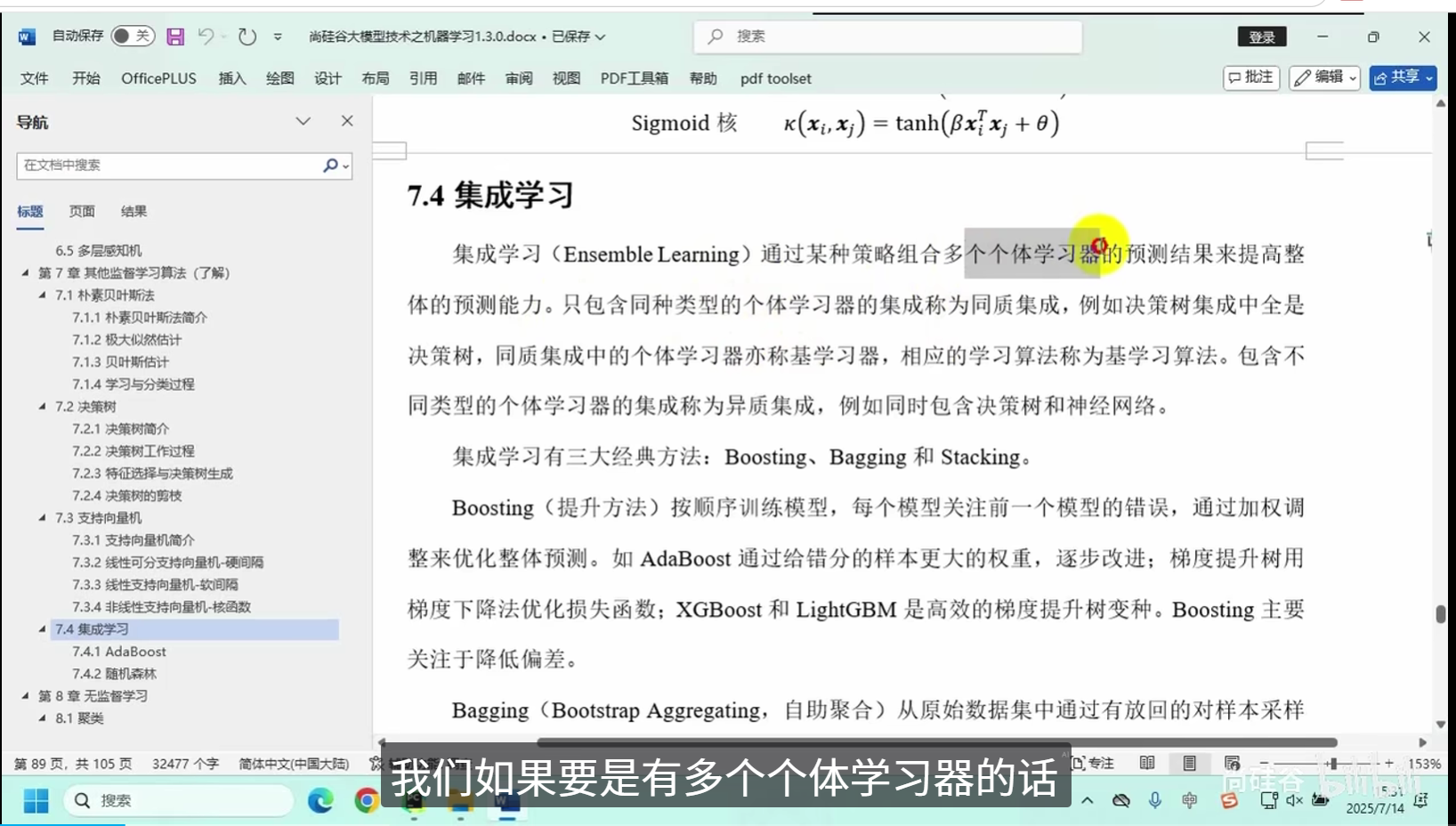
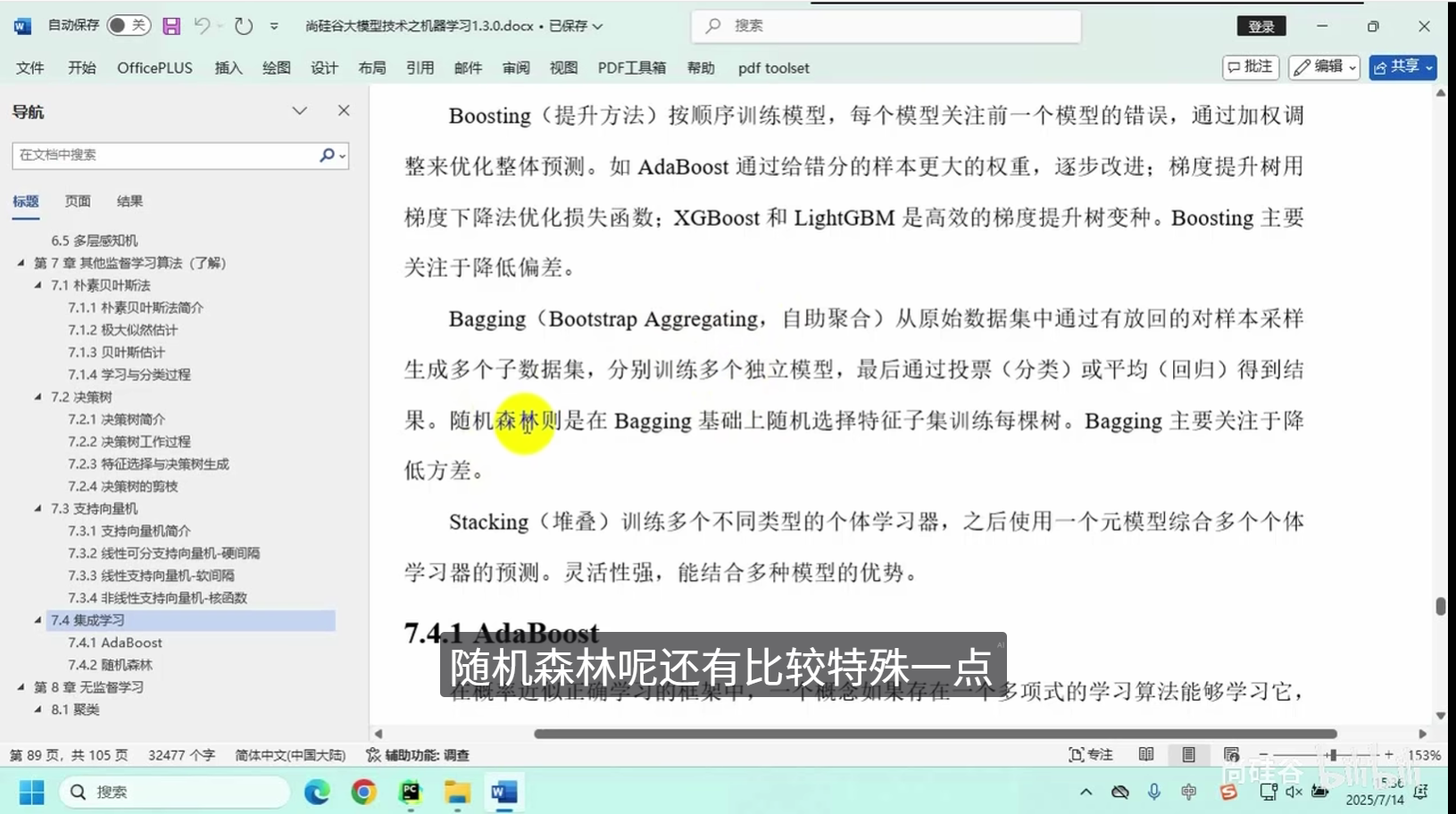
集成学习
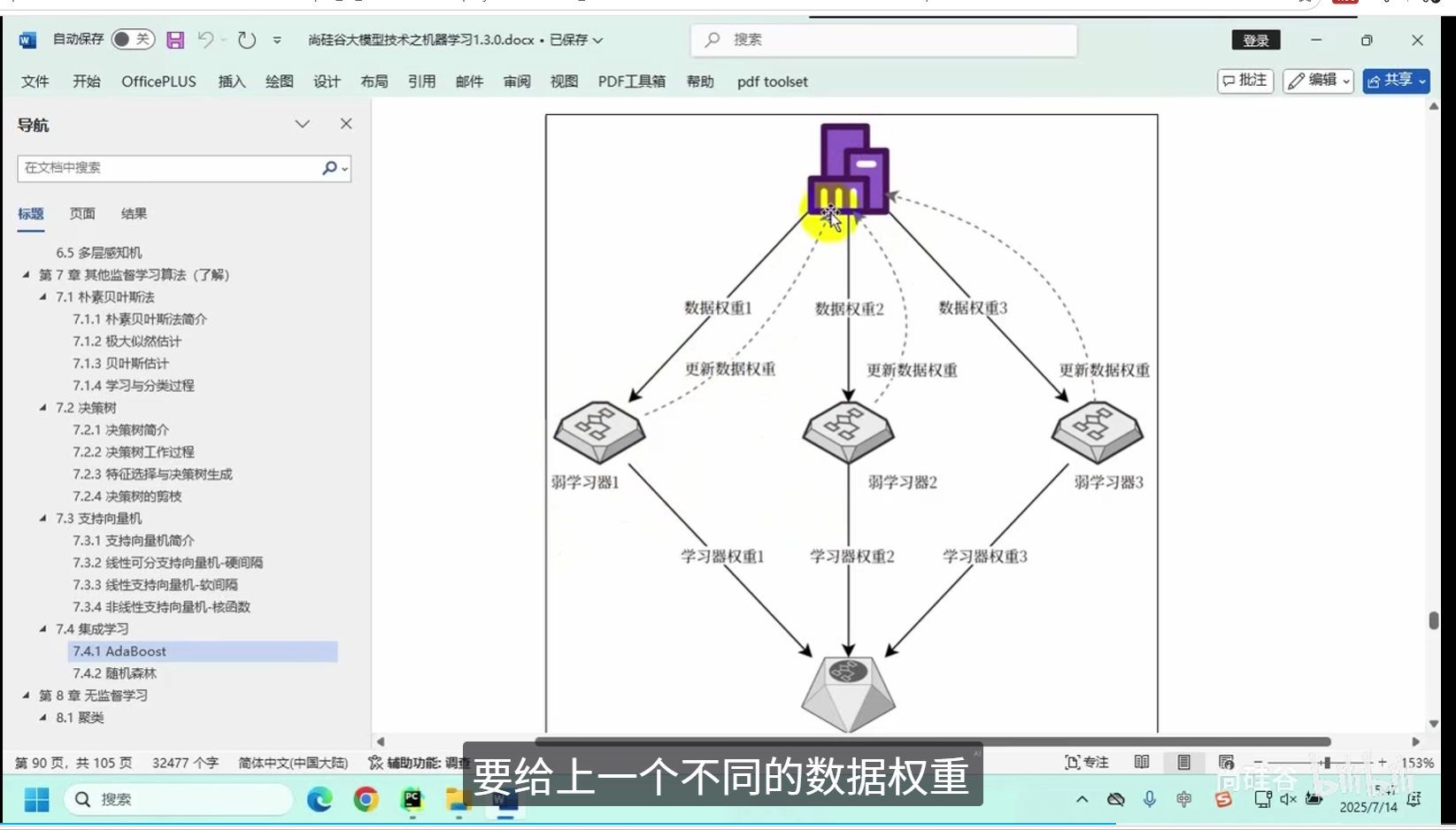
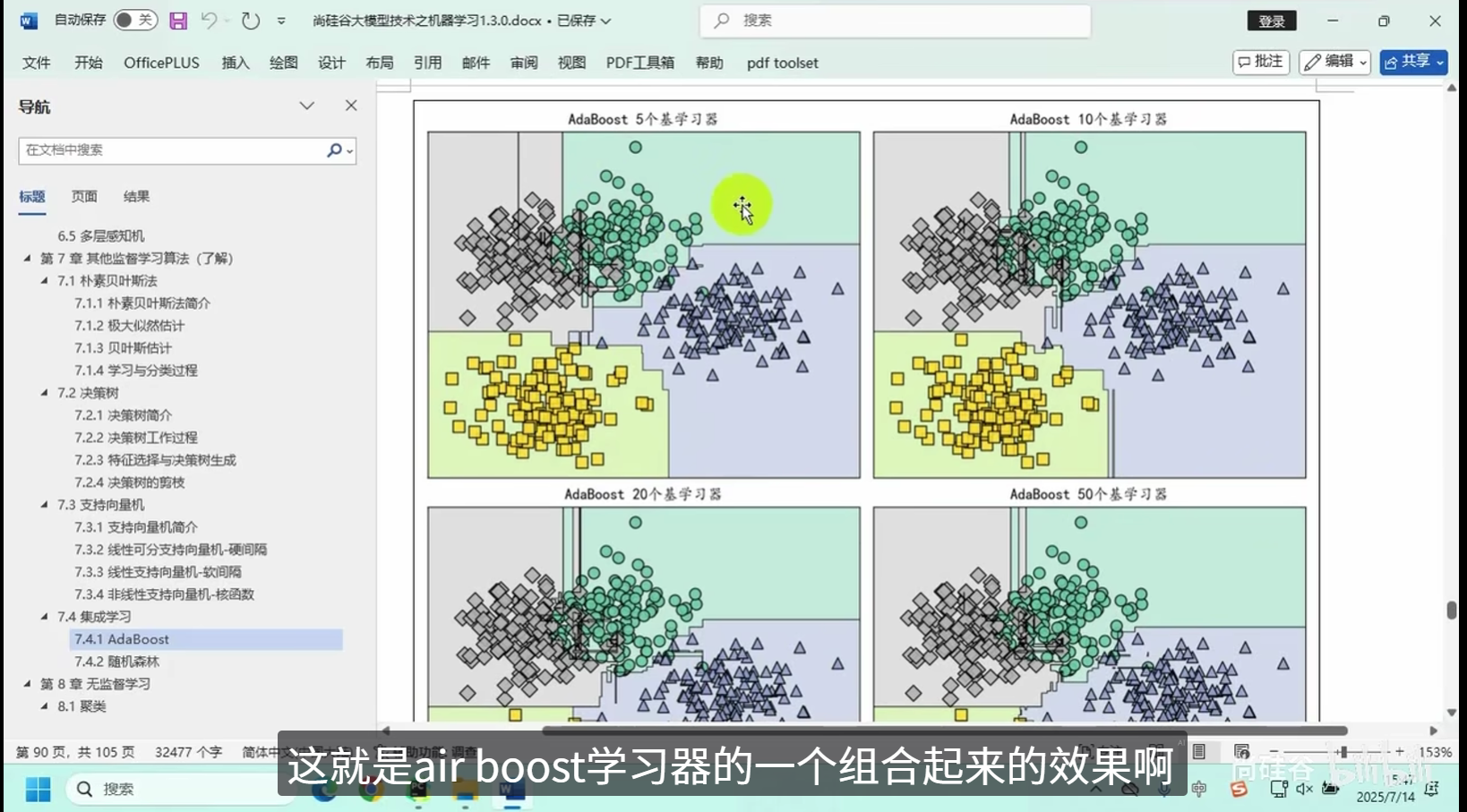
AdaBoost

随机森林