引言
在操作系统的设计中,进程是资源分配的基本单位,其核心特征之一便是独立性。每个进程都拥有自己独立的地址空间,并被操作系统精心隔离------一个进程的崩溃通常不会波及整个系统,数据也天然受到保护。这种"独善其身"的设计,为系统的稳定性与安全性筑起了坚固的基石。
然而,这种独立性是一把双刃剑。它带来的副作用同样明显:一个进程无法轻易访问另一个进程持有的数据,如同一个个彼此隔绝的信息孤岛。当一项复杂任务需要多个进程分工协作时,这种隔离就成了天然的障碍。比如,一个数据采集进程如何将海量信息传递给分析处理进程?一个界面进程如何响应来自后台计算进程的完成通知?
正是这种"需要协作"与"天然隔离"之间的矛盾,催生了进程间通信这项关键技术。它要解决的核心问题,就是在不破坏安全隔离这一根本优势的前提下,在不同进程间开辟出高效、受控的数据通道。
1. 进程间通信介绍
IPC(Inter-Process Communication),即进程间通信,是指在不同进程之间传递数据、同步协作的一套机制。
由于每个进程都拥有独立的地址空间,无法直接访问彼此的内存,因此通信必须通过内核中转 来实现。这揭示了进程间通信的本质:让不同的进程看到同一份资源(内存),从而具备通信的条件 。这份共享资源由操作系统提供,并需要配套创建、使用、销毁等管理能力。为此,操作系统必须提供一系列**系统调用(System Call)**来实现进程级的通信能力,这就要求设计出一套统一的通信接口。
有了接口,自然需要相应的实现方案,进而催生了各类通信标准。例如经典的 System V 标准,便由全球顶尖的技术专家共同制定,为进程间通信的规范化奠定了基础。
1-1 进程间通信的目的
进程间通信主要服务于以下几种场景:
-
数据传输:一个进程需要将它的数据发送给另一个进程。
-
资源共享:多个进程之间共享同一份资源。
-
事件通知:一个进程需要向另一个或一组进程发送消息,通知它们发生了某种事件(例如子进程终止时要通知父进程)。
-
进程控制:某些进程希望完全控制另一个进程的执行(如调试器进程),此时控制进程希望能够拦截目标进程的所有陷入和异常,并及时感知其状态变化。
1-2 进程间通信的发展
进程间通信的演进脉络,大致可以划分为以下几个阶段:
-
1970s:管道与信号的诞生,迈出了跨进程交互的第一步。
-
1980s:System V IPC 三剑客(消息队列、共享内存、信号量)与 BSD Socket 相继出现,奠定了经典通信范式。
-
1990s:POSIX 标准对 IPC 进行统一规范,提升了可移植性。
-
2000s:Linux 融合各家之长,持续增强 IPC 能力。
-
2010s 至今:通信机制逐渐框架化,并向分布式场景延伸。
1-3 进程间通信的分类
根据发展阶段与实现标准,进程间通信机制可分为以下几大类: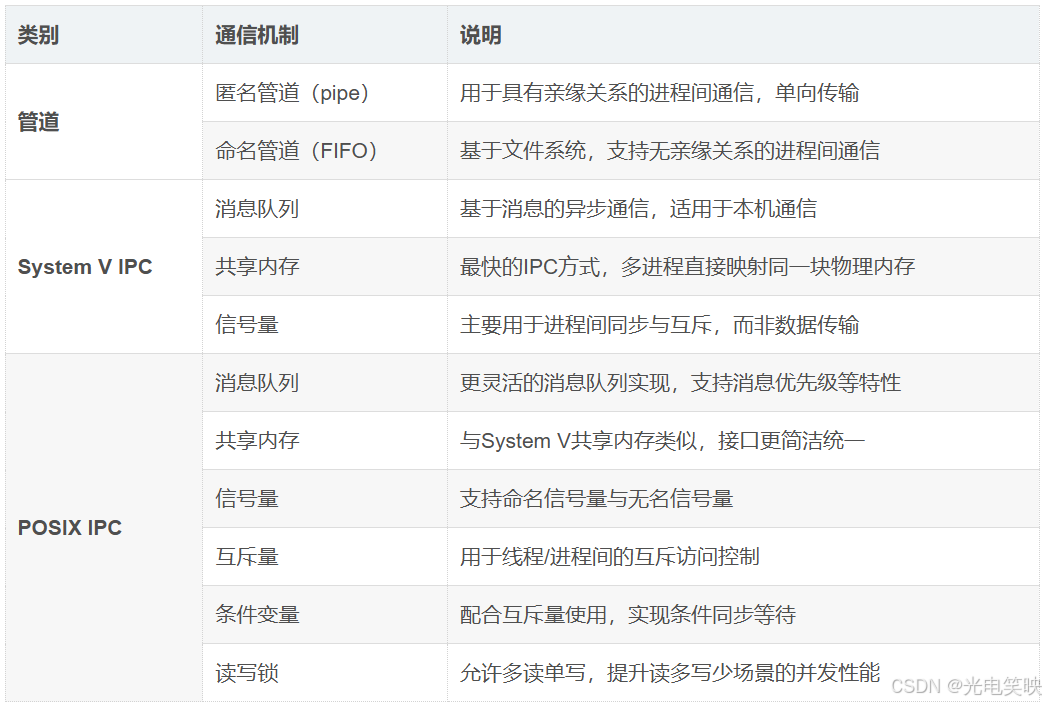
2. 管道
2.1 什么是管道
概念 :管道是一种特殊的通信机制,它将一个进程的标准输出直接连接到另一个进程的标准输入,形成一个单向的数据流通道。简单来说,一个进程将数据写入管道的写端 ,另一个进程从管道的读端读取数据。
bash
who | wc -l这里的 | 就是管道符号,who 的输出通过管道直接传给 wc -l 作为输入。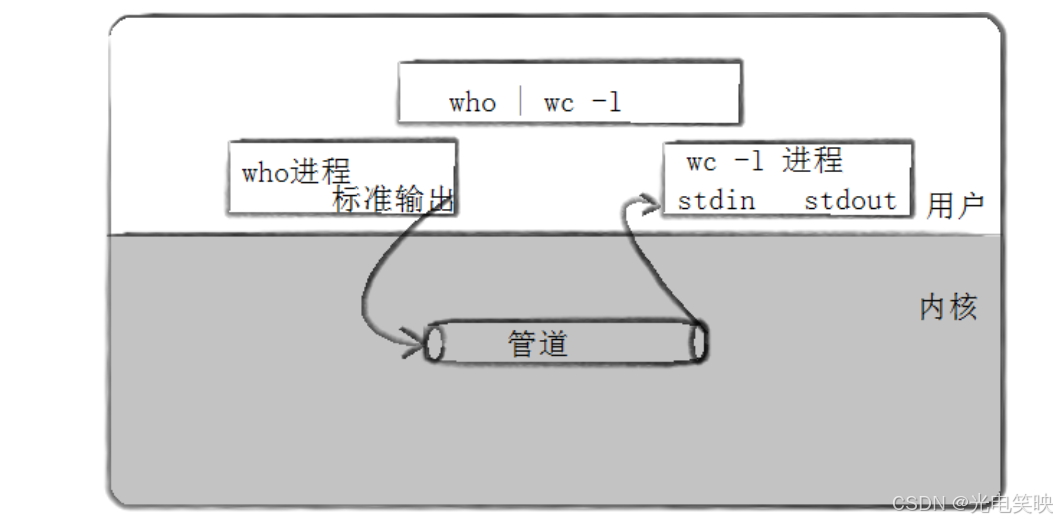
核心特性:
-
管道是一种特殊的文件类型 ,但它并不在磁盘上占用实际的物理空间。管道的数据存在于内核的内存缓冲区中,是内存级别的文件,数据交换直接在内存中进行,无需读写磁盘。
-
基于文件的理念,让不同进程看到同一份资源------这就是管道的通信本质。
-
管道隶属于文件系统,但存在于内存中,完美体现了"Linux 一切皆文件"的设计哲学。
管道是 Unix 中最古老的进程间通信形式。我们把从一个进程连接到另一个进程的数据流称为一个"管道"。
2.2 匿名管道
匿名管道是 Unix/Linux 系统中最古老、最基础的进程间通信方式之一。它本质上是一段由内核维护的内存缓冲区 ,以字节流的形式在两个进程之间建立单向数据传输通道。
既然是内存级别的文件,没有文件名,也不需要路径------这就是"匿名"的由来。通常用于具有亲缘关系 (父子进程)的进程间通信。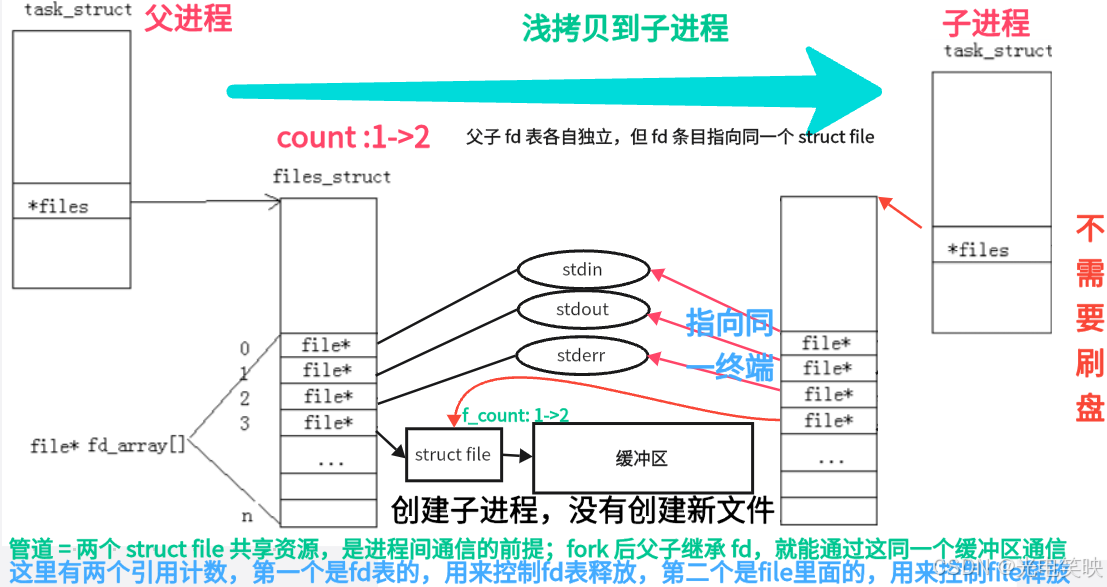
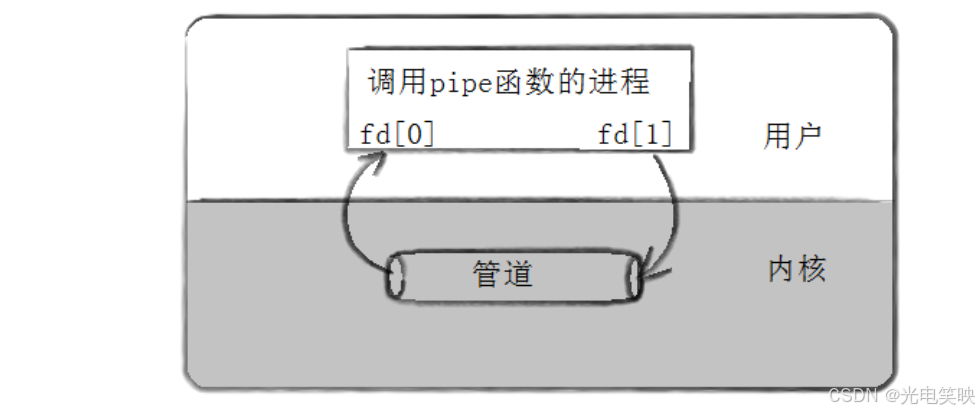
pipe() 函数
cpp
#include <unistd.h>
int pipe(int fd[2]);-
功能:创建一个匿名管道。
-
参数 :
fd是一个长度为 2 的整型数组。-
fd[0]--- 管道的读端(记忆:0 像嘴巴,用来读) -
fd[1]--- 管道的写端(记忆:1 像钢笔,用来写)
-
-
返回值 :成功返回
0,失败返回-1并设置errno。
2.3 站在文件描述符角度------深度理解管道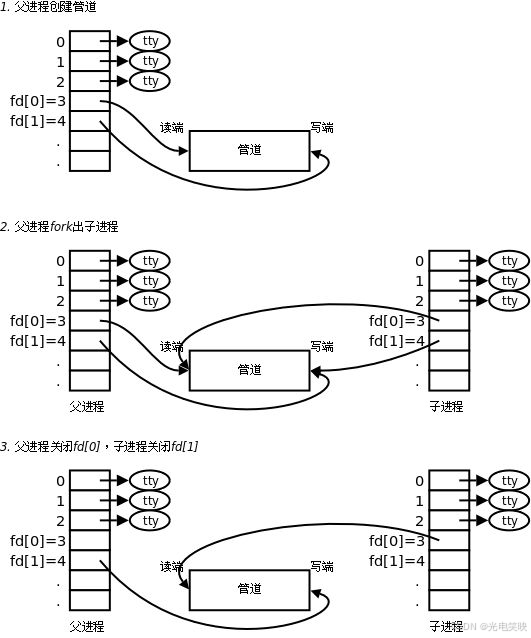
2.3.1 文件描述符分配验证
cpp
#include <unistd.h>
#include <iostream>
int main()
{
int fds[2] = {0};
int n = pipe(fds);
if (n < 0)
{
perror("pipe fail");
return 1;
}
std::cout << "fds[0](读端): " << fds[0] << std::endl;
std::cout << "fds[1](写端): " << fds[1] << std::endl;
return 0;
}运行结果:
cpp
fds[0](读端): 3
fds[1](写端): 42.3.2 注意概念区分
数组下标 fd[0]、fd[1] 中的 0 和 1,与标准输入输出的文件描述符编号 0 和 1,是两个不同层面的概念 。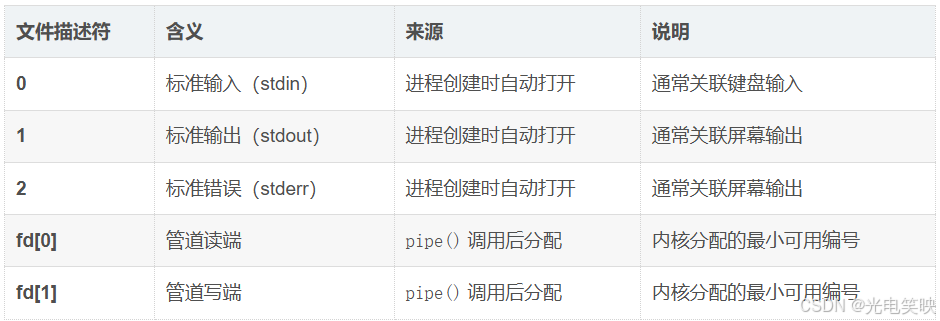
由于标准输入(0)、标准输出(1)、标准错误(2)已被占用,pipe() 分配的文件描述符通常为 3 和 4。
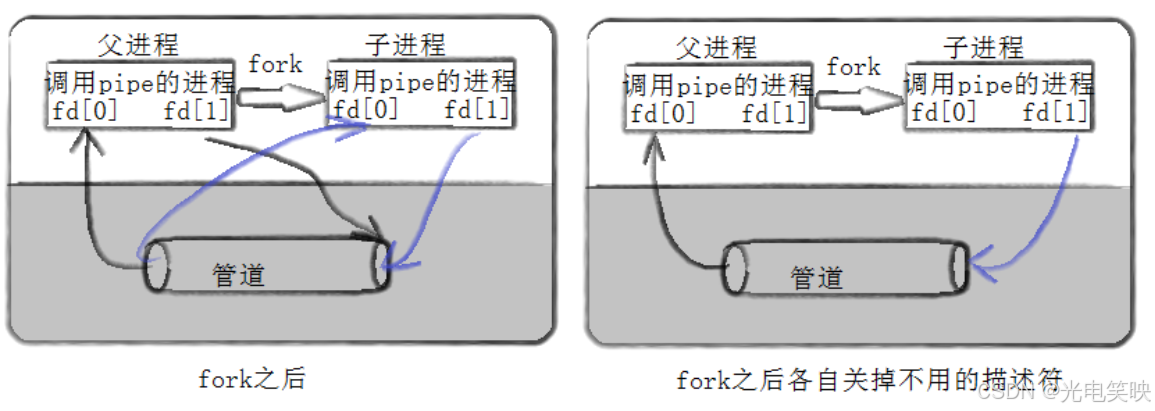
2.4 用 fork 共享管道
2.4.1 共享原理
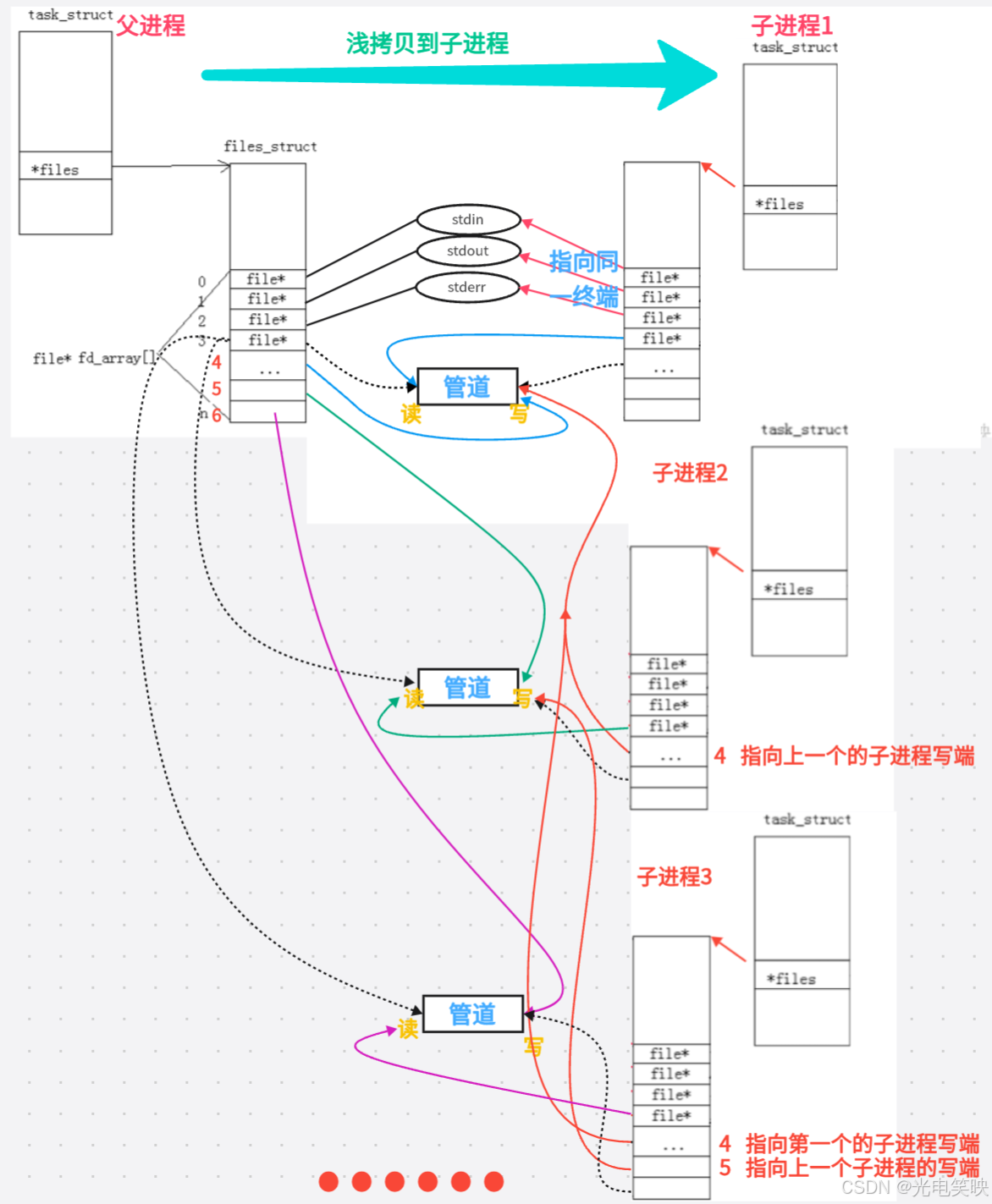
父进程创建管道后,调用 fork() 创建子进程。由于子进程会继承父进程的文件描述符表,父子进程便能看到同一个管道,从而实现通信。
2.4.2 关键惯例:关闭不需要的一端
当父进程关闭读端 fd[0]、子进程关闭写端 fd[1] 后,管道中的数据流向就被明确为:父进程 → 管道 → 子进程,实现从父到子的单向通信。
这个操作带来两个好处:
-
明确通信方向:避免进程误用错误端口。
-
正确触发 EOF :当写端关闭后,读端才能收到
read()返回 0,避免永久阻塞。

2.5 站在内核角度------管道本质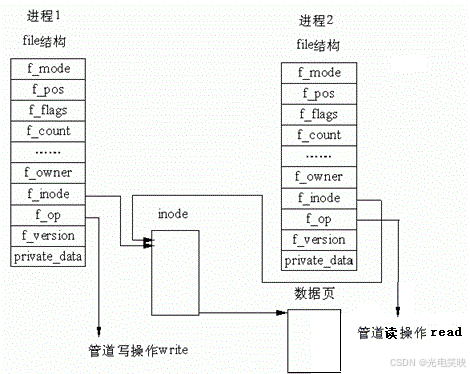
管道本质上就是内核中的一块缓冲区,以文件的形式呈现给用户态。看待管道,就如同看待文件一样------管道的使用和文件一致,完美体现了"Linux 一切皆文件"的设计思想。
2.6 管道通信实例
2.6.1 基础示例:从键盘读取,写入管道,读出并打印
cpp
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int main(void)
{
int fds[2];
char buf[100];
int len;
if (pipe(fds) == -1)
perror("make pipe"), exit(1);
// 从标准输入读取
while (fgets(buf, 100, stdin))
{
len = strlen(buf);
// 写入管道
if (write(fds[1], buf, len) != len)
{
perror("write to pipe");
break;
}
memset(buf, 0x00, sizeof(buf));
// 从管道读取
if ((len = read(fds[0], buf, 100)) == -1)
{
perror("read from pipe");
break;
}
// 写入标准输出
if (write(1, buf, len) != len)
{
perror("write to stdout");
break;
}
}
return 0;
}2.6.2 父子进程通信示例
cpp
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <cstdio>
#include <iostream>
#include <cstring>
// 子进程:向管道写入数据
void ChildWrite(int wfd)
{
//char buff[1024] = {0} 是防御性编程的好习惯------确保缓冲区初始为全零,避免脏数据干扰。
char buff[1024]={0};
int cnt =0;
while(true)
{
//注意几乎所有的对字符串操作的c接口都会自动在结尾放一个\0
snprintf(buff,sizeof(buff),"I am child pid:%d\n cnt=%d",getpid(),cnt++);
write(wfd,buff,strlen(buff));//默认加了\0
sleep(1);
}
}
// 父进程:从管道读取数据
void FatherRead(int rfd)
{
char buff[1024]={0};
while(true)
{ //读的时候要自己加\0
ssize_t n=read(rfd,buff,sizeof(buff)-1);
if(n>0)
{
buff[n]=0;
std::cout<<"receive child messeage:"<<buff<<std::endl;
}
}
}
int main()
{
// 1. 创建管道:fds[0] 为读端,fds[1] 为写端
int fds[2] = {0};
if (pipe(fds) < 0)
{
std::cerr << "pipe fail" << std::endl;
return 1;
}
// 2. 创建子进程
pid_t id = fork();
if (id == 0)
{
// 子进程:关闭读端,只保留写端
close(fds[0]);
ChildWrite(fds[1]);
close(fds[1]);
return 0;
}
// 3. 父进程:关闭写端,形成"子写父读"的单向通道
close(fds[1]);
FatherRead(fds[0]);
close(fds[0]);
return 0;
}进程状态监控:
bash
while :; do ps ajx | head -1 && ps ajx | grep testpipe | grep -v grep; sleep 1; done运行结果:
父子进程均处于 S+(可中断睡眠)状态,由内核调度和管道的阻塞机制自然同步,无需额外的同步手段。
这部分涉及同步与多线程的相关知识,我们会在后续章节中详细展开。
2.6.3 创建进程池处理任务
进程池是一种预先创建多个子进程 的技术。父进程将任务通过管道分发给子进程处理,避免了频繁 fork 带来的开销,同时充分利用多核 CPU 的并行能力。
基本原理
进程池的核心思路巧妙利用了管道的阻塞特性:
-
父进程没有发送任务 时,子进程
read()阻塞等待(管道为空,写端未关闭)。 -
父进程写入一条消息 ,对应子进程立即读到并执行一次任务。
-
执行完毕后子进程再次
read(),继续阻塞等待下一条命令。
这本质上就是父进程通过管道控制子进程的暂停与唤醒 ------管道不仅是数据通道,更是一种天然的进程同步机制。
解决字节流问题:任务码
管道是面向字节流的,那如何让子进程知道"一次读多少、读到的是什么"?
答案很简单:规定父进程每次只写一个 int(4 字节),子进程每次只读一个 int。
cpp
// 父进程:固定写入 4 字节
write(pipefd, &cmd, sizeof(int));
// 子进程:固定读取 4 字节
read(rfd, &cmd, sizeof(int));这个 int 被称为任务码,不同的数值代表不同的任务类型。由于读写双方约定好了固定长度,自然就绕过了粘包、半包等字节流带来的边界问题。
基本架构 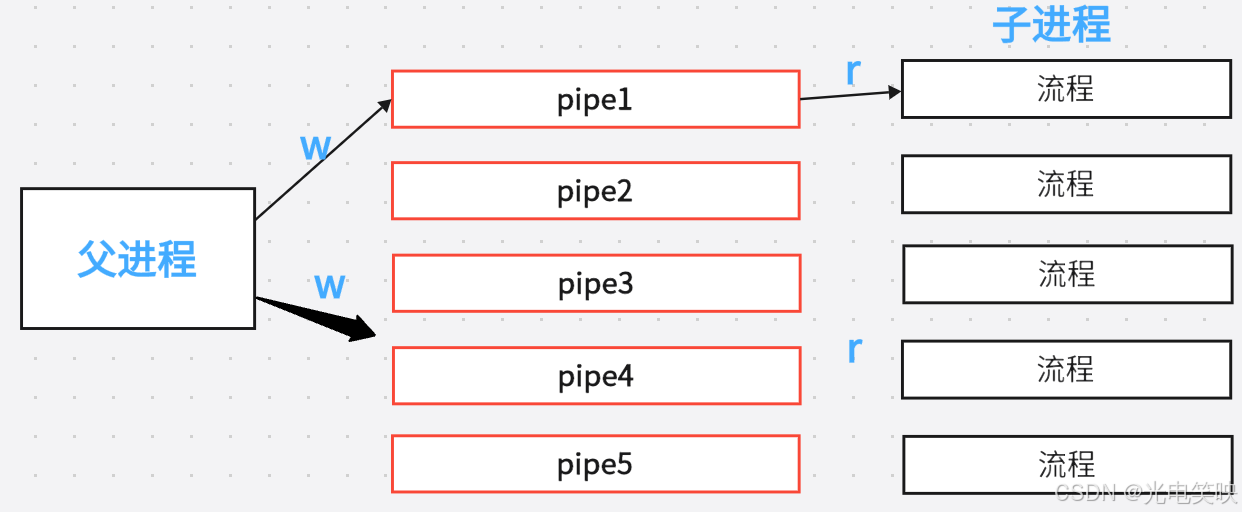
工作流程 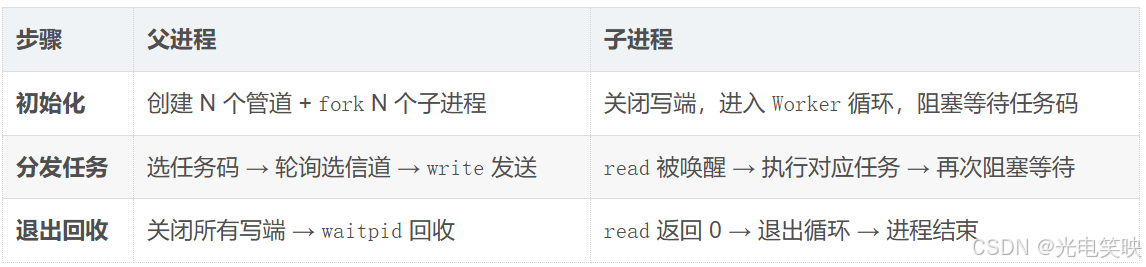
解决负载均衡问题
如果将所有的任务交给某一个或某几个子进程,就会出现忙的忙死,闲的闲死 的负载不均问题。因此,父进程在分配任务时需要将工作量均匀分摊到所有子进程。
常见的子进程选择策略有三种: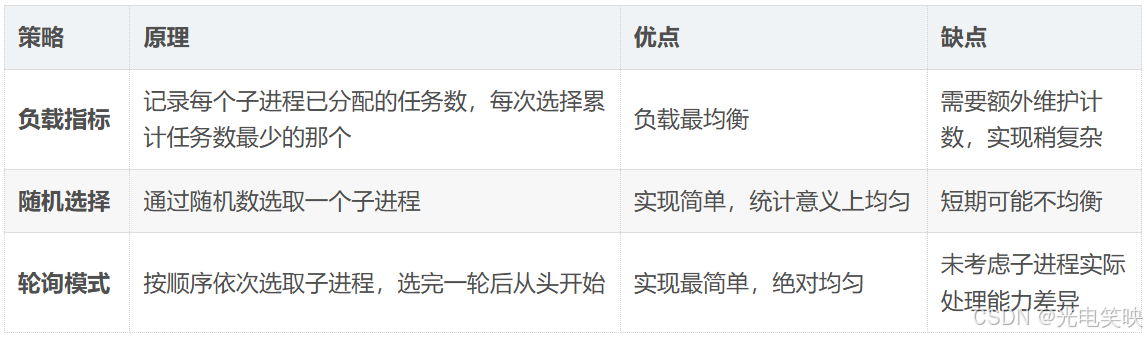
本节将采用轮询模式。
实现代码
文件后缀说明 
Task.hpp
cpp
#pragma once
#include<iostream>
#include<vector>
#include<ctime>
typedef void (*func_t)();
///////////////////////debug//////////////////////////
void PrintLog()
{
std::cout<<"我是一个打印日志的任务"<<std::endl;
}
void Download()
{
std::cout<<"我是一个下载的任务"<<std::endl;
}
void Upload()
{
std::cout<<"我是一个上传的任务"<<std::endl;
}
/////////////////////////////////////////////////////
class TaskManager
{
public:
TaskManager()
{
srand(time(nullptr));
}
~TaskManager(){}
void Register(func_t t)
{
_tasks.push_back(t);
}
int Code()
{
return rand()%_tasks.size();
}
void Execute(int code)
{
if(code>=0&&code<_tasks.size())
{
_tasks[code]();//函数指针回调
}
}
private:
std::vector<func_t> _tasks;
};ProcessPool.hpp
cpp
#pragma once
// #ifndef XXX_H
// #define XXX_H
// // 头文件内容
// #endif
//这两个写法等价
#include<unistd.h>
#include<cstdlib>
#include<vector>
#include<sys/wait.h>
#include<iostream>
#include<string>
#include"Task.hpp"
//先描述
class channel
{
public:
channel(int wfd,pid_t id)
:_wfd(wfd)
,_id(id)
{
_name= "channel:wfd=" + std::to_string(wfd) + " id=" + std::to_string(id);
}
~channel() {}
std::string GetChannelName()
{
return _name;
}
int GetChannel_wfd()
{
return _wfd;
}
pid_t GetChannel_id()
{
return _id;
}
void Send(int code)
{
int n= write(_wfd,&code,sizeof(code));//写入后子进程被唤醒
if(n<0)
{
perror("write fail");
return;
}
//(void)n;//编译不告警
}
private:
int _wfd;
pid_t _id;
std::string _name;
//int _loadnum;
//累计所分配的任务数
};
//再组织
class channelManager
{
public:
channelManager()
:_next(0)
{}
~channelManager() {}
void InsertChannel(int wfd,pid_t id)
{//构建channel对象,并push到vector里面
//也可以用emplace_back接口避免创建临时对象
// channel c(wfd,id);
//_channels.push_back(c);
_channels.emplace_back(wfd,id);
}
channel& Select()
{
if(_channels.empty())
{
std::cerr << "错误:无可用子进程" << std::endl;
exit(1);
}
// // 先确保 _next 在有效范围内
// _next %= _channels.size();
// auto& c = _channels[_next];
// _next++;
// return c;
int idx = _next++ % _channels.size();
return _channels[idx];
}
void PrintChannels()
{
for(auto& chs:_channels)
{
std::cout<<chs.GetChannelName()<<std::endl;
}
std::cout<<std::endl;
}
void CloseAll()
{
for(auto& c:_channels)
{
close(c.GetChannel_wfd());
}
}
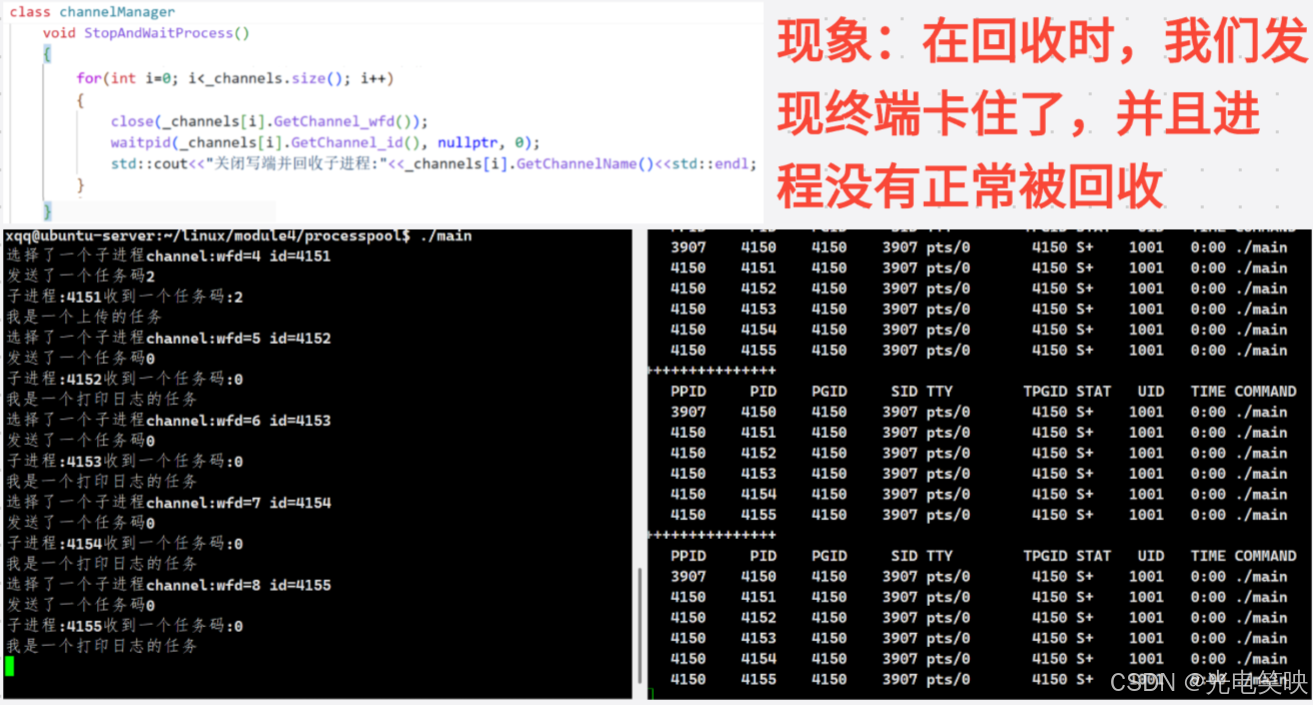
void StopAndWaitProcess()
{
//bug
// for(int i=0; i<_channels.size(); i++)
// {
// close(_channels[i].GetChannel_wfd());
// waitpid(_channels[i].GetChannel_id(), nullptr, 0);
// std::cout<<"关闭写端并回收子进程:"<<_channels[i].GetChannelName()<<std::endl;
// }
// //解决方案一:倒着关
// for(int i=_channels.size()-1; i>=0; i--)
// {
// close(_channels[i].GetChannel_wfd());
// waitpid(_channels[i].GetChannel_id(), nullptr, 0);
// std::cout<<"关闭写端并回收子进程:"<<_channels[i].GetChannelName()<<std::endl;
// }
// 解决方案二
for(int i=0; i<_channels.size(); i++)
{
close(_channels[i].GetChannel_wfd());
waitpid(_channels[i].GetChannel_id(), nullptr, 0);
std::cout<<"关闭写端并回收子进程:"<<_channels[i].GetChannelName()<<std::endl;
}
}
private:
std::vector<channel> _channels;
int _next;
};
//默认信道数
const int default_num=5;
//进程池
class processpool
{
public:
///processpool()=default;
processpool(int num) :_process_num(num)
{
_tm.Register(PrintLog);
_tm.Register(Download);
_tm.Register(Upload);
}
~processpool()
{_cm.StopAndWaitProcess();}
void work(int rfd)
{
while(true)
{
// debug
// std::cout<<"我是子进程,我的rfd是:"<<rfd<<std::endl;
// sleep(5);
int code=0;
ssize_t n = read(rfd,&code,sizeof(code));//读取4byte
if(n>0)
{ //不符合规范就跳出
if(sizeof(code)!=n)
{
continue;
}
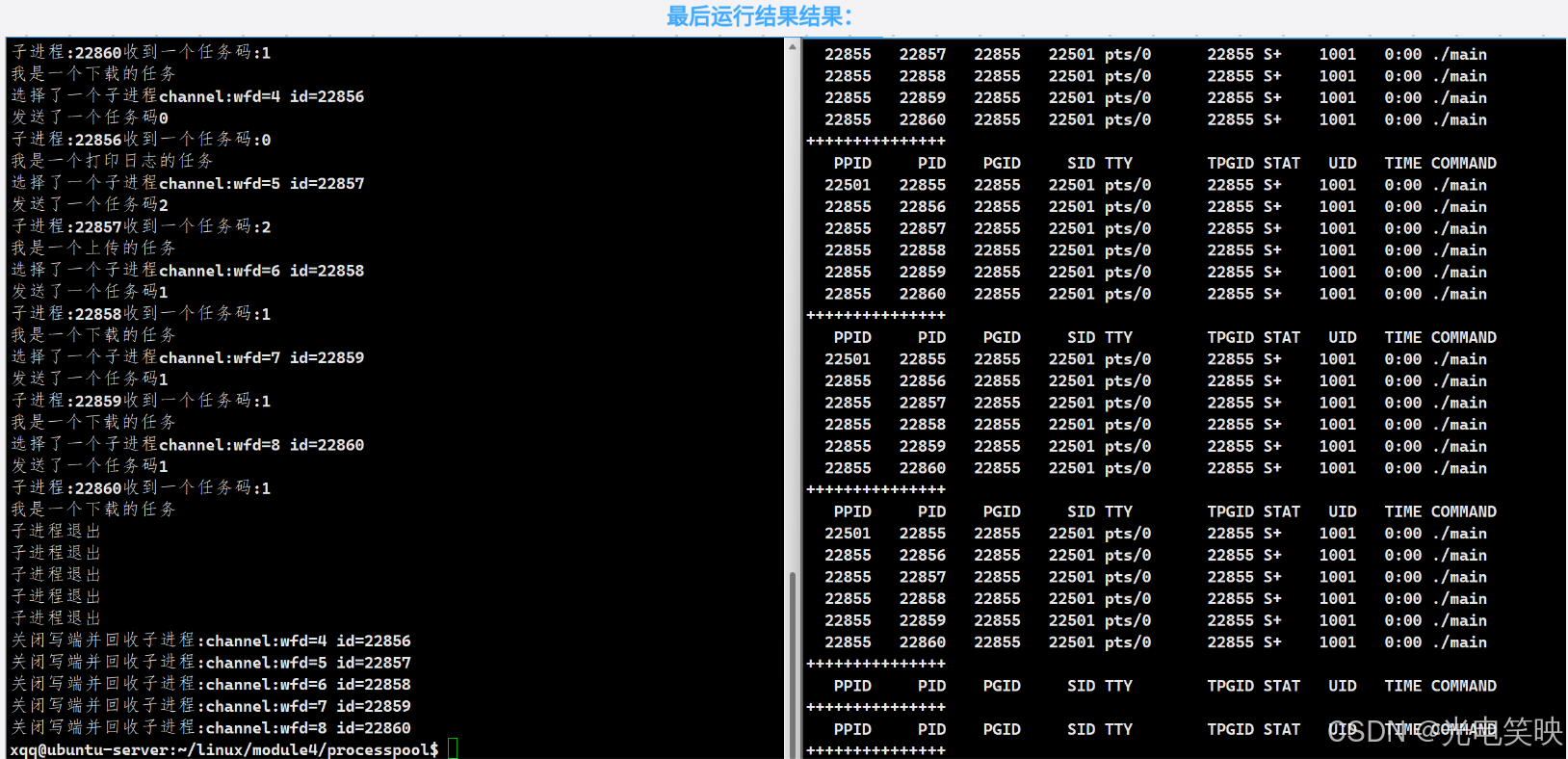
std::cout<<"子进程:"<<getpid()<<"收到一个任务码:"<<code<<std::endl;
_tm.Execute(code);//执行任务
}
else if(n==0)//服务端将写端关闭
{
std::cout<<"子进程退出"<<std::endl;
break;
}
else//<0 (-1)读失败
{
std::cerr<< "读取错误" << std::endl;
break;
}
}
}
bool create()
{
//子进程会exit(0)不会干扰循环
for(int i=0;i<_process_num;i++)
{
//创建管道以及子进程
int fds[2]={0};
int n=pipe(fds);
if(n<0)
{
perror("pipe fail");
return false;
}
pid_t id=fork();
if(id<0)
{
perror("fork fail");
return false;
}
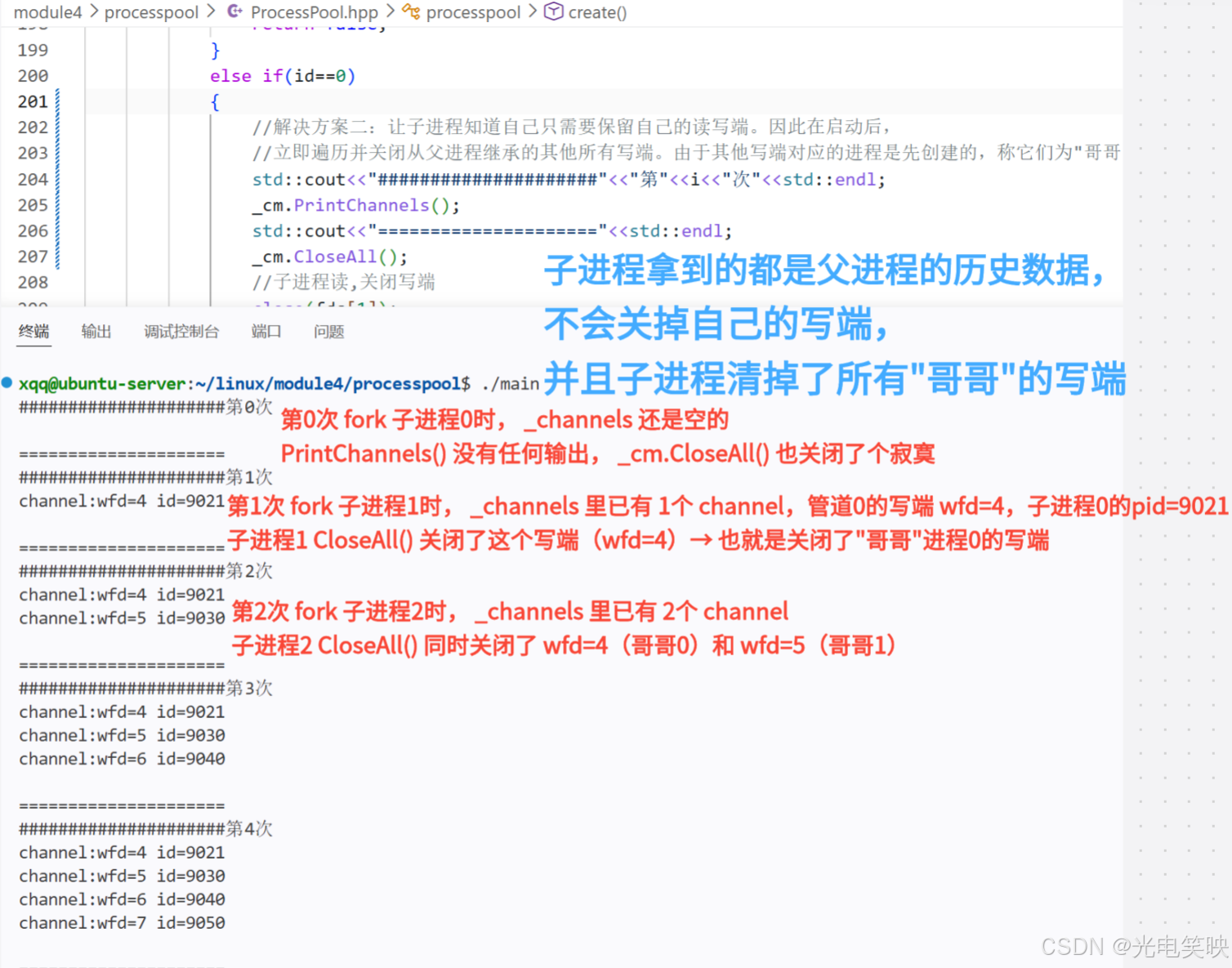
else if(id==0)
{
//解决方案二:让子进程知道自己只需要保留自己的读写端。因此在启动后,
//立即遍历并关闭从父进程继承的其他所有写端。由于其他写端对应的进程是先创建的,称它们为"哥哥"进程。
std::cout<<"#####################"<<"第"<<i<<"次"<<std::endl;
_cm.PrintChannels();
std::cout<<"====================="<<std::endl;
_cm.CloseAll();
//子进程读,关闭写端
close(fds[1]);
work(fds[0]);
close(fds[0]);
exit(0);
}
else
{
sleep(1);
//父进程写,关闭读端
close(fds[0]);
//父进程知道自己的写端fds[1],和子进程是谁,pid,构建channel并管理
_cm.InsertChannel(fds[1],id);
}
}
return true;
}
void Debug()
{
_cm.PrintChannels();
}
void RunTask()
{
//先选择任务
int task_code=_tm.Code();
//再选择信道(子进程)
auto& c=_cm.Select();
std::cout<<"选择了一个子进程"<<c.GetChannelName()<<std::endl;
//再发送任务
c.Send(task_code);
std::cout<<"发送了一个任务码"<<task_code<<std::endl;
}
void Stop()
{
//关闭所有的父进程写端,并且回收所有子进程
_cm.StopAndWaitProcess();
}
private:
channelManager _cm;
int _process_num;
TaskManager _tm;
};
cpp
#include"ProcessPool.hpp"
int main()
{
//创建进程池对象
processpool pp(default_num);
//启动进程池
pp.create();
// pp.Debug();
// sleep(1000);//主进程不退出
//自动派发任务
int cnt=5;
while(cnt--)//主进程发送任务
{
pp.RunTask();
sleep(1);
}
//pp.Stop();//交给RAII自动管理,回收
return 0;
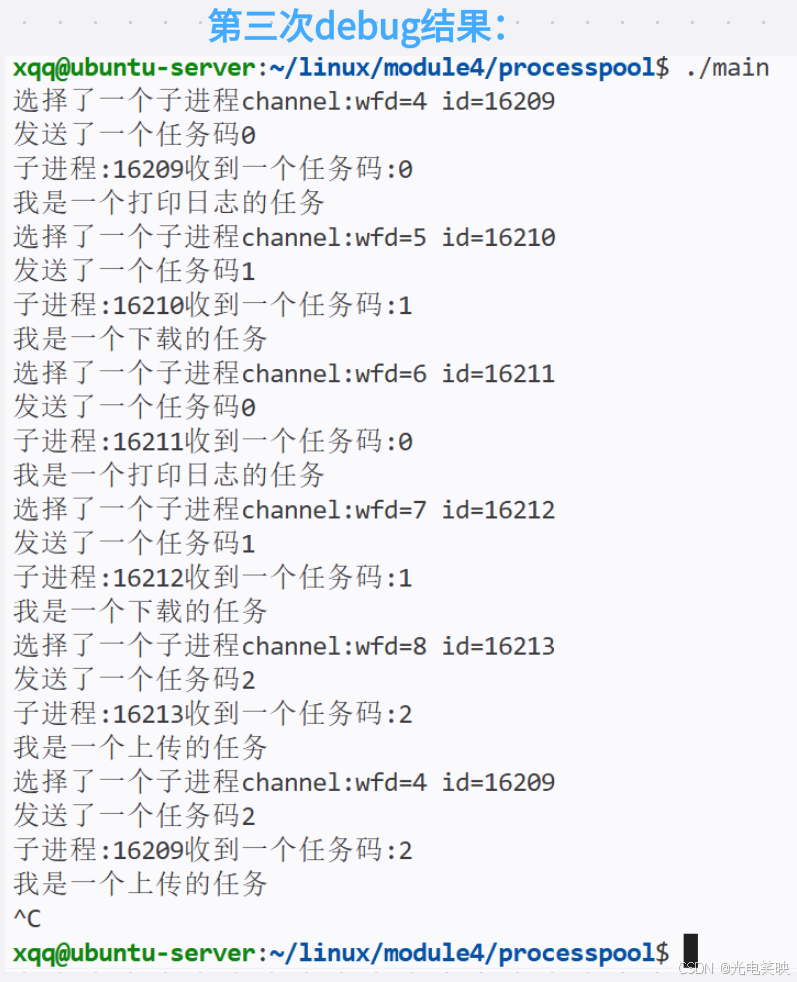
}debug结果:
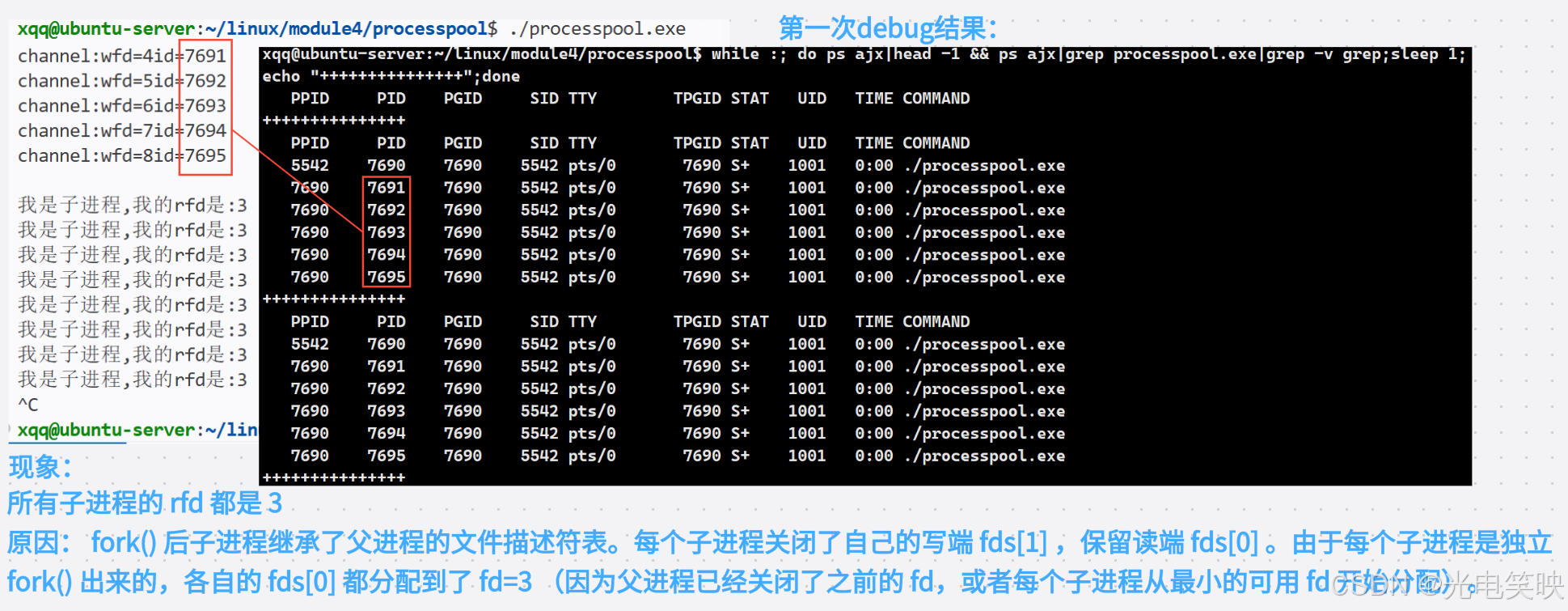
- 第一次debug
- 第二次debug
- 第三次debug
- 关于兄弟进程的问题
假如此时总共有5个子进程,那么第一个子进程的写端就有5个指向(父进程和其它的子进程,自己的写端关闭),接下来也同理,第二个子进程写端有四个指向......当我们close时只将父进程的写端关闭,以第一个管道为例,那么管道文件的引用计数就从5->4,文件没有真正被关闭,那么read读的时候就一直阻塞着,这就是为什么卡在那里
下面给出两种方案解决:
**方案一:**由于计数是逐级递减的,最后一个进程的管道写端计数只有父进程,于是解方案一就是从最后一个进程开始关闭,也就是倒着关
方案二(推荐):每个子进程 fork 后立即关闭所有继承的兄弟写端
下面给出具有调试信息的运行结果方便理解:
最终运行结果:

架构总结
三层组件
核心设计要点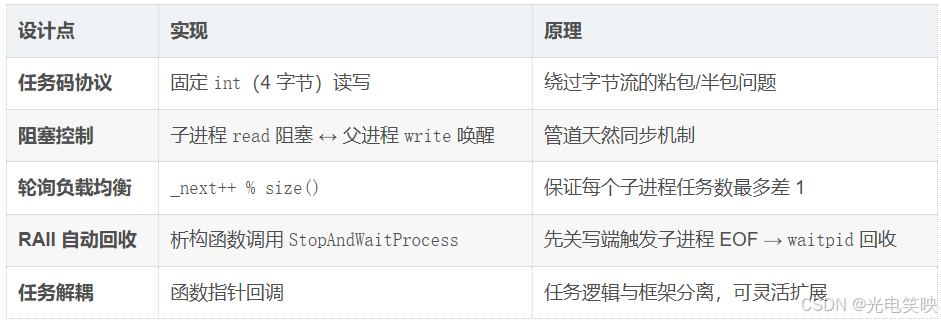
总结 :进程池是管道通信的完整工程实践 ------用
channel封装单向信道,用channelMannager管理信道集合并实现轮询分发,用TaskManager解耦任务逻辑,用固定长度的任务码协议规避字节流边界问题,最终构建了一个父进程通过管道精准控制子进程暂停与唤醒的 Master-Worker 模式。
2.7 管道读写规则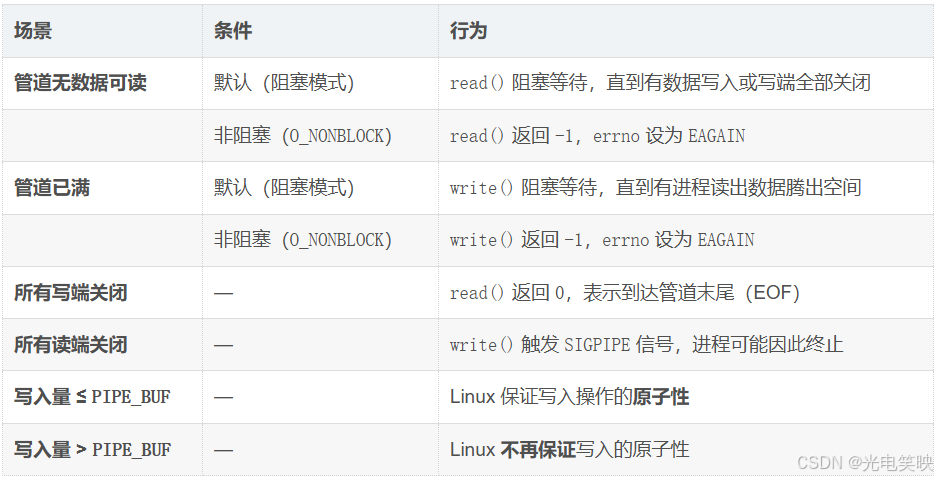
2.8 验证管道通信的四种情况
前置概念:管道数据的消费特性
管道是流式消费 ------数据一旦被
read()读出,就从内核缓冲区中永久移除,不需要也不存在手动清空操作。
这意味着管道的读写是一个动态平衡过程:写入端往缓冲区填充数据,读取端从缓冲区取走数据,取走的空间立刻可以被新数据覆盖。
四种场景详解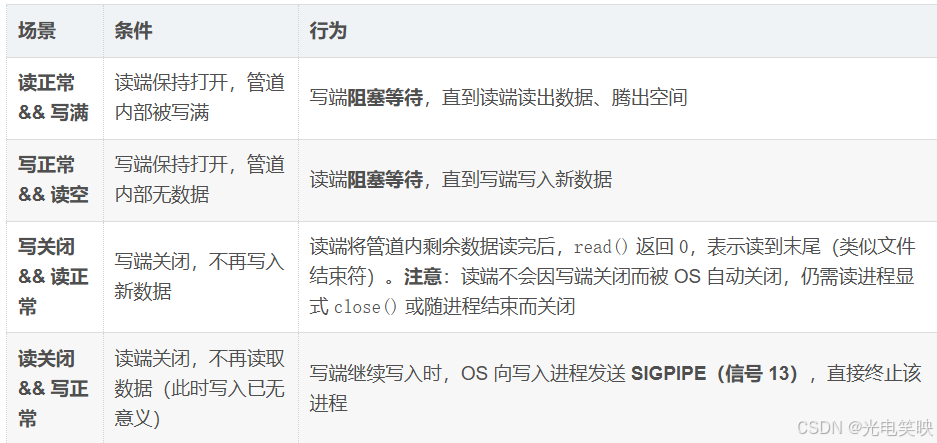
读正常 && 写满
当写入速度远大于读取速度时,内核缓冲区会被迅速填满。此后每次腾出少量空间,写入端都会立刻将其填满,直到再次阻塞。
以 PIPE_BUF = 4096 字节为例:
初始:缓冲区满(4096/4096)→ write() 阻塞
父进程 read(buff, 1024) → 读出 1024 字节,缓冲区变为 3072/4096
→ write() 解除阻塞
→ 子进程立刻写入 1024 字节,缓冲区再次满(4096/4096)
→ write() 再次阻塞
... 循环往复:腾出一点 → 填入一点 → 再次阻塞 ...管道就像一个固定大小的水桶------流出多少空间,就立刻能被填入多少数据,缓冲区始终逼近满水位。
写正常 && 读空
当读取速度大于写入速度时,管道数据一进入就被立刻读走,大部分时间处于空状态。这就是 2.6.2 节父子进程通信示例 所演示的场景:子进程每秒写入一次,父进程阻塞等待并立即读出。
补充:一次 read() 能读多少数据?
read() 每次读取的数据量,取决于以下两个值中的较小者 :
两种典型情况对比 :
2.9 实验验证:管道缓冲区大小与写满阻塞
验证代码
cpp
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <iostream>
int main()
{
// 1. 创建管道
int fds[2] = {0};
if (pipe(fds) < 0)
{
std::cerr << "pipe fail" << std::endl;
return 1;
}
// 2. 创建子进程
pid_t id = fork();
char ch = 0;
int cnt = 1;
if (id == 0)
{
// 子进程:只写不读
close(fds[0]);
while (true)
{
write(fds[1], &ch, 1); // 每次写入 1 字节
std::cout << "写入次数: " << cnt++ << std::endl;
}
close(fds[1]);
return 0;
}
// 3. 父进程:关闭写端,但从不读取(验证写满阻塞)
close(fds[1]);
waitpid(id, nullptr, 0);
close(fds[0]);
return 0;
}运行结果
cpp
写入次数: 65534
写入次数: 65535
写入次数: 65536
^C ← 此时子进程阻塞,等待父进程读取子进程在第 65536 次写入后阻塞。65536 字节 ÷ 1024 = 64 KB,恰好等于 Linux 管道的默认缓冲区容量。
系统参数验证
cpp
$ ulimit -a | grep pipe
pipe size (512 bytes, -p) 8 # 512 × 8 = 4096 字节
$ cat /proc/sys/fs/pipe-max-size
1048576 # 1MB,缓冲区最大上限三个关键数值 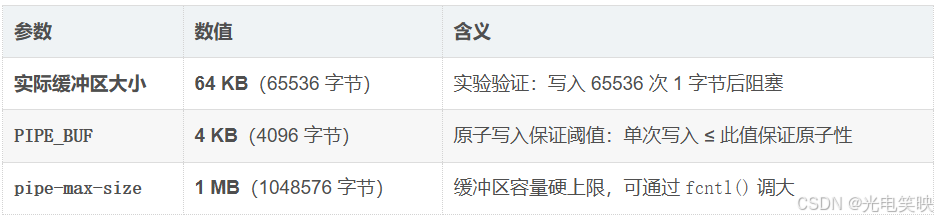
三者关系
cpp
pipe-max-size = 1MB ← 硬上限(天花板)
│
└── 默认缓冲区 = 64KB ← 实验写满值(可调,上限 1MB)
│
└── PIPE_BUF = 4KB ← 原子写入保证线
│
└── 单次 write ≤ 4KB → 原子写入,多进程不穿插什么是原子性?
原子性 = 不可分割。一个原子操作要么全部完成,要么完全不执行,不存在"做了一半"的中间状态。
在管道中的具体含义:
示例:两个进程同时向同一管道写入:
cpp
进程A: write(fd, "AAAA", 4); // ≤ PIPE_BUF,原子
进程B: write(fd, "BBBB", 4); // ≤ PIPE_BUF,原子管道中一定是 AAAABBBB 或 BBBBAAAA,两个完整消息互不穿插。如果写入超过 4KB,则可能出现 AAAA...BBBB...AAAA... 的数据被撕裂现象。
2.10 管道特点总结
-
亲缘关系限制 :只能用于具有共同祖先的进程(通常由父进程创建管道后
fork,父子进程共用)。 -
自带同步机制:内核会对管道操作进行同步与互斥,保证读写的有序性。
-
面向字节流:数据以连续的字节序列传输,接收方每次可读取任意数量的字节。这一特性带来两个衍生问题:
-
写入简单,读取困难:写入端知道要发什么,但读取端不知道数据全貌、消息边界在哪,需要自行处理粘包和半包问题。
-
无消息边界:写入三次可能被一次读出,写入一次也可能被分三次读出。
-
-
生命周期随进程:一般而言,进程退出时管道自动释放。
-
半双工通信:数据只能单向流动。如需双向通信,必须创建两个管道。
半双工与全双工
匿名管道天生是半双工的。双向通信需创建两个管道:
cpp
父进程 ←------ 管道1 ------ 子进程(子写父读)
父进程 ------ 管道2 ------→ 子进程(父写子读)3.命名管道
3.1 为什么需要命名管道?
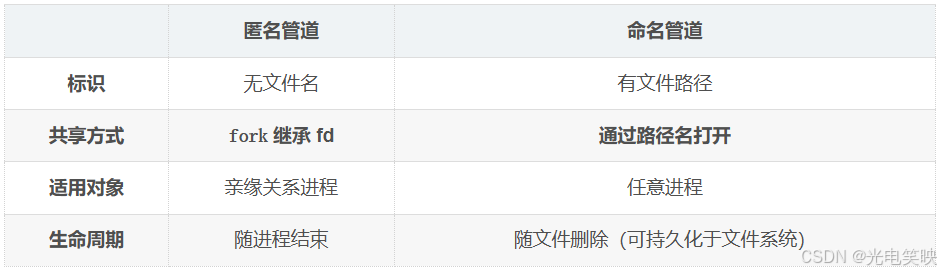
匿名管道的一个核心限制是:只能在具有共同祖先(亲缘关系)的进程间通信 。因为它没有名字,只能通过 fork 继承文件描述符来共享。
如果想让两个完全不相关的进程 交换数据,就需要用到命名管道。
3.2 什么是命名管道?
命名管道,也称为 FIFO 文件,是一种特殊类型的文件。它与匿名管道的本质相同------都是内核中的一块内存缓冲区,数据在内存中直接传输。但关键区别在于:
命名管道有一个文件名,存在于文件系统中,作为不同进程访问同一个管道的"接头暗号"。
3.3 核心特性
-
命名管道在文件系统上表现为一个特殊类型的文件,有对应的路径名作为标识符。
-
不同进程只需打开同一个文件路径,就能访问同一个命名管道,实现跨进程通信。
-
它并不实际存储数据 。磁盘上的映像只是一个"路标",大小始终为 0。所有数据仍然在内核内存缓冲区中流动,不会刷新到磁盘。
3.4 创建命名管道:mkfifo()
cpp
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);-
功能:创建一个命名管道(FIFO 文件)。
-
参数:
-
pathname:管道的路径名(路径 + 文件名),作为不同进程访问的标识。 -
mode:权限位,指定文件权限。实际创建权限会受umask影响(最终权限 =mode & ~umask)。
-
-
返回值 :成功返回
0,失败返回-1并设置errno。

可以看到 命名管道是特殊文件类型 pipe,命名管道(FIFO 文件)
删除命名管道方法:
