目录
[一、为什么 LLM 需要 Retriever](#一、为什么 LLM 需要 Retriever)
[二、Retriever 的本质](#二、Retriever 的本质)
[三、Retriever 工作流程](#三、Retriever 工作流程)
[四、Retriever 与数据库查询的区别](#四、Retriever 与数据库查询的区别)
[五、Retriever 的核心思想](#五、Retriever 的核心思想)
[六、Retriever 与 Embedding 的关系](#六、Retriever 与 Embedding 的关系)
[七、LangChain 中创建 Retriever](#七、LangChain 中创建 Retriever)
[八、Retriever 检索数据](#八、Retriever 检索数据)
[九、Retriever 工作原理](#九、Retriever 工作原理)
[十、Top-K 检索](#十、Top-K 检索)
[十二、MMR 检索策略](#十二、MMR 检索策略)
[十三、Score Threshold 检索](#十三、Score Threshold 检索)
[十四、构建 RAG 检索链](#十四、构建 RAG 检索链)
[十五、LCEL 结合 Retriever](#十五、LCEL 结合 Retriever)
[十六、Retriever 在 RAG 中的位置](#十六、Retriever 在 RAG 中的位置)
[十七、Retriever 与 Agent 的结合](#十七、Retriever 与 Agent 的结合)
[什么是 Retriever?](#什么是 Retriever?)
[Retriever 和 Embedding 的区别?](#Retriever 和 Embedding 的区别?)
[Retriever 和数据库查询区别?](#Retriever 和数据库查询区别?)
[Retriever 在 RAG 中作用是什么?](#Retriever 在 RAG 中作用是什么?)
[MMR 检索有什么作用?](#MMR 检索有什么作用?)
一、前言
在学习 LangChain 和 RAG(检索增强生成)时,经常会遇到一个核心组件:
Retriever很多初学者会产生疑问:
Retriever 是什么?
为什么已经有向量数据库了还需要 Retriever?
Retriever 和 Embedding 有什么关系?
Retriever 如何帮助 LLM 查询知识库?实际上:
Embedding 负责理解语义
VectorDB 负责存储向量
Retriever 负责查找知识可以说:
Retriever 是连接 LLM 和知识库之间最重要的一座桥梁。
本文将带你彻底理解:
什么是 Retriever
Retriever 的作用
Retriever 的工作原理
LangChain 中如何使用 Retriever
Retriever 与向量数据库的关系
如何实现动态知识库问答一、为什么 LLM 需要 Retriever
先看一个问题:
公司的报销流程是什么?如果直接问 LLM:
python
response = llm.invoke(
"公司的报销流程是什么?"
)模型会出现两种情况:
知道答案或者:
胡乱猜测(幻觉)因为:
公司内部制度
企业知识库
最新文档
业务数据根本不在模型训练数据中。
所以需要:
先找到相关资料
再让模型回答这就是:
Retriever存在的意义。
二、Retriever 的本质
Retriever 翻译:
检索器本质职责:
根据用户问题
从知识库中
找出最相关内容例如:
用户:
Spring IOC 是什么?知识库:
文档1:Spring IOC
文档2:Redis
文档3:MySQLRetriever:
返回文档1然后交给:
LLM生成答案。
三、Retriever 工作流程
整体架构:

流程:
用户提问
↓
Retriever检索
↓
获取相关文档
↓
拼接Prompt
↓
LLM生成答案四、Retriever 与数据库查询的区别
传统数据库:
sql
SELECT *
FROM employee
WHERE name='张三'依赖:
精确匹配Retriever:
语义匹配例如:
知识库:
Spring IOC 是控制反转思想用户:
Spring 如何实现依赖注入?虽然:
IOC
依赖注入不是同一个词。
但语义相关。
Retriever 仍然能找到。
五、Retriever 的核心思想
本质:
问题
↓
Embedding
↓
向量
↓
相似度计算
↓
最相关文档架构:

六、Retriever 与 Embedding 的关系
很多人容易混淆:
Embedding
Retriever实际上:
| 组件 | 职责 |
|---|---|
| Embedding | 文本转向量 |
| Vector DB | 存储向量 |
| Retriever | 查询向量 |
关系:

七、LangChain 中创建 Retriever
首先创建向量库。
python
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
db = Chroma.from_texts(
[
"Spring IOC 是控制反转",
"Redis 是内存数据库",
"MySQL 是关系型数据库"
],
embeddings
)将 VectorDB 转换为 Retriever:
python
retriever = db.as_retriever()就这么简单。
八、Retriever 检索数据
示例:
python
docs = retriever.invoke(
"Spring 如何实现依赖注入"
)
print(docs)结果:
Spring IOC 是控制反转因为:
语义最接近九、Retriever 工作原理
执行:
python
retriever.invoke(
question
)背后发生:
sequenceDiagram
User->>Retriever: Question
Retriever->>Embedding: 向量化
Embedding->>VectorDB: 查询
VectorDB->>Retriever: TopK文档
Retriever->>User: 返回结果十、Top-K 检索
默认:
返回最相关文档实际上可以:
返回前K条例如:
python
retriever = db.as_retriever(
search_kwargs={
"k":3
}
)表示:
返回前三条结果十一、相似度检索
Retriever 默认:
Similarity Search即:
余弦相似度公式:
Similarity
=
(A·B)
/
(|A|×|B|)含义:
越接近1
越相似十二、MMR 检索策略
问题:
Top3结果可能高度重复例如:
Spring教程1
Spring教程2
Spring教程3信息重复。
因此:
MMR出现。
全称:
Max Marginal Relevance最大边际相关性。
作用:
既相关
又多样化配置:
retriever = db.as_retriever(
search_type="mmr"
)十三、Score Threshold 检索
有时候:
找不到相关内容也不应该返回。
例如:
用户:
如何做红烧肉知识库:
Java
Spring
Redis显然不相关。
配置:
python
retriever = db.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={
"score_threshold":0.8
}
)含义:
低于0.8
直接丢弃十四、构建 RAG 检索链
最经典流程:
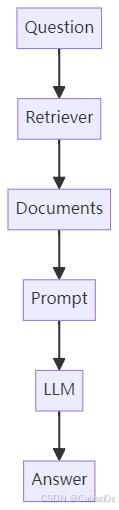
代码:
python
docs = retriever.invoke(question)
context = "\n".join(
doc.page_content
for doc in docs
)
prompt = f"""
请根据资料回答问题:
资料:
{context}
问题:
{question}
"""
answer = llm.invoke(prompt)十五、LCEL 结合 Retriever
LangChain 推荐:
LCEL写法。
python
chain = (
retriever
| prompt
| llm
)架构:

代码更优雅。
十六、Retriever 在 RAG 中的位置
完整 RAG:
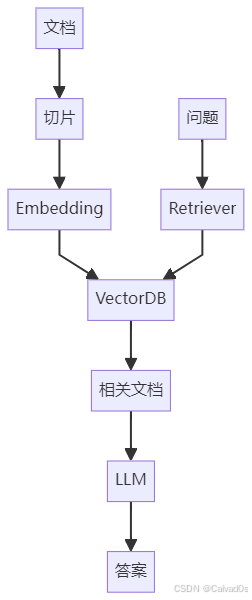
可以看到:
Retriever
是RAG最核心组件之一十七、Retriever 与 Agent 的结合
现代 Agent:
不仅能调用:
搜索引擎
数据库
API也能调用:
Retriever作为工具。
架构:
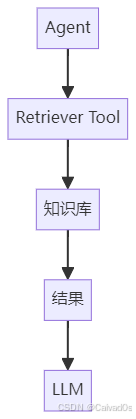
这样 Agent 就拥有:
企业知识查询能力十八、企业项目最佳实践
推荐组合:
OpenAI Embedding
+
Chroma/Milvus
+
Retriever
+
LangChain
+
GPT架构:

十九、面试高频问题
什么是 Retriever?
用于从知识库检索相关文档的组件Retriever 和 Embedding 的区别?
Embedding负责向量化
Retriever负责查询Retriever 和数据库查询区别?
数据库是关键词匹配
Retriever是语义匹配Retriever 在 RAG 中作用是什么?
负责检索上下文知识MMR 检索有什么作用?
避免结果高度重复二十、总结
Retriever 是 LangChain RAG 体系中的核心组件。
它解决的问题是:
如何让 LLM 从海量知识库中找到最相关的信息整个流程可以概括为:
用户问题
↓
Retriever
↓
知识库检索
↓
相关文档
↓
LLM生成答案可以这样理解:
Embedding
负责理解问题
VectorDB
负责保存知识
Retriever
负责寻找知识
LLM
负责组织答案因此:
如果说 Embedding 是知识库的索引技术,那么 Retriever 就是知识库的搜索引擎。
掌握 Retriever 后,你就真正进入了 RAG 与企业知识库系统开发的核心领域,为后续学习 Multi Retriever、Hybrid Search、Self Query Retriever、Agent Tool Calling 等高级技术打下坚实基础。