MCP 模型上下文协议
MCP的全称是模型上下文协议。它是一个开放标准,规定了如何将外部工具(如数据库、API、本地文件等)的描述和调用方式统一地提供给大语言模型。通俗地讲,MCP给"工具调用"定义了一套通用的格式和交互流程。它强调让LLM主动触发工具,而不是被动响应。MCP于2024年11月左右首次发布,这在整个AI agent演进中算是一个里程碑。
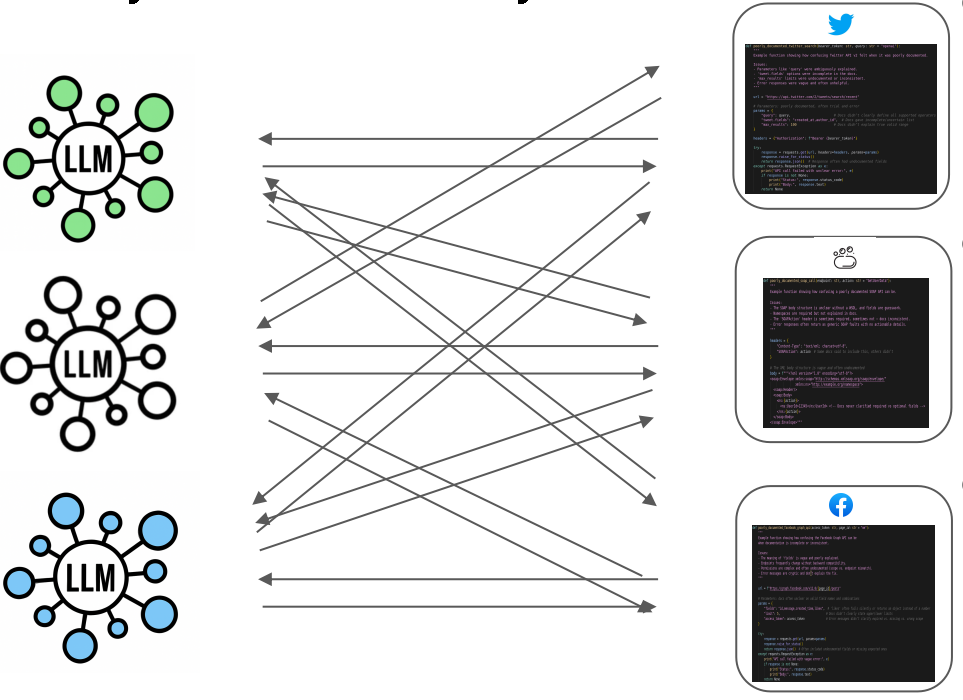
如果没有统一协议,你需要为每一个LLM应用和每一个工具之间编写专用连接器------这就是M×N的集成复杂度。
一方面,不同的LLM输出的工具调用格式不同,需要针对性的解析器做正则匹配。 另
一方面,不同工具的调用方式、认证方式、传输协议等不同,需要针对性地设计协议来接收LLM端的请求。
所以,仅仅基于function calling,需要单独开发N*M次来实现N个LLM应用和M个工具的对接。
MCP最核心的两点贡献
对 LLM 侧:MCP 客户端将任意 LLM 私有的工具调用输出(如 OpenAI、Anthropic 各自的格式)统一转换成 JSON-RPC 2.0 格式的请求。
对工具侧:每个工具只需封装成一个 MCP 服务器,按标准协议接收请求,并将认证、参数映射、错误处理等细节封装在内部,返回统一的JSON-RPC 2.0格式的响应。
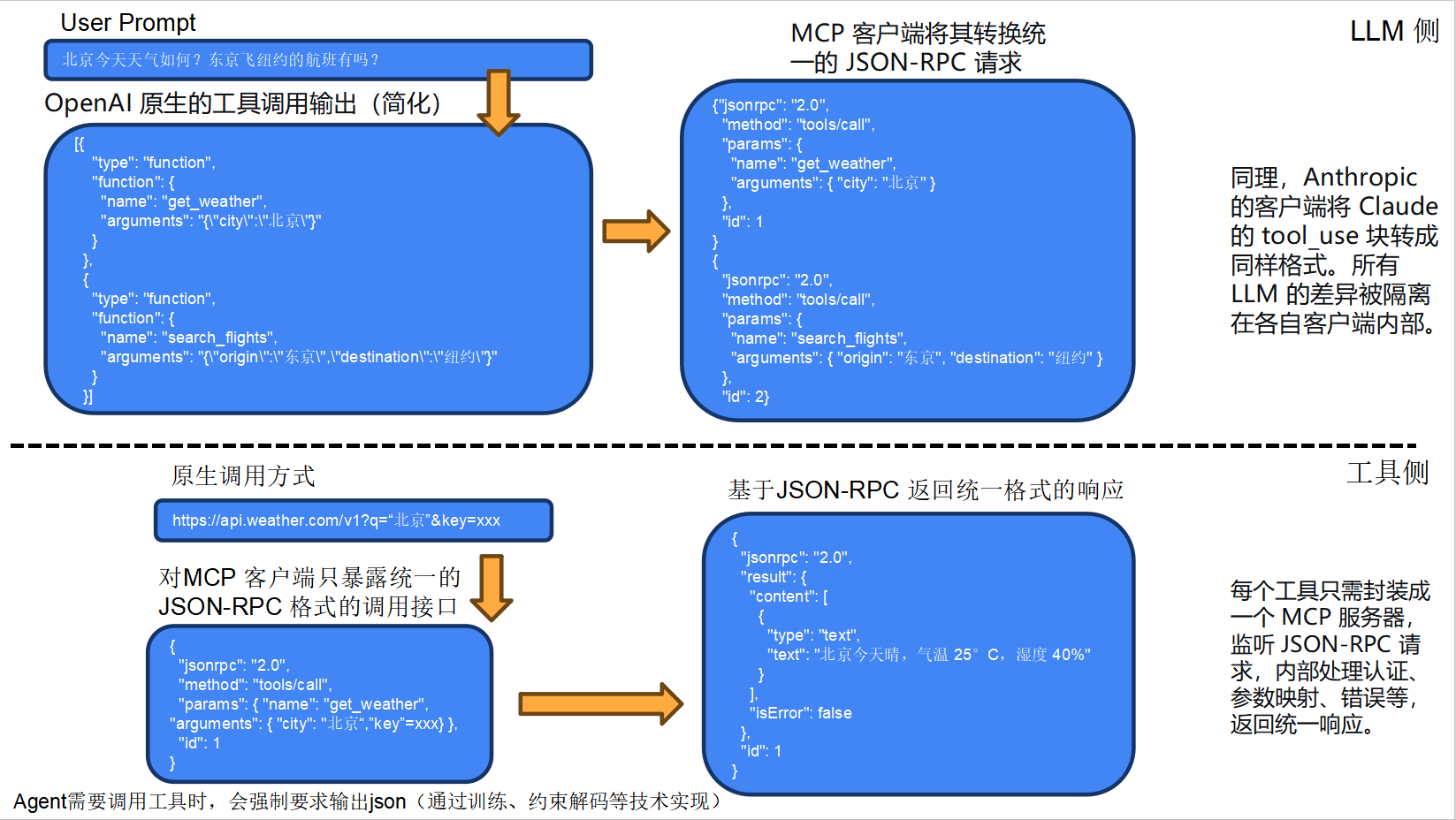
这两点共同实现了 集成复杂度从 M×N 降为 M+N 的目标,这也是 MCP 作为"标准化协议"最核心的价值。
Terminology
Host:
LLM应用,如 Cursor、Claude Desktop
MCP Client:
嵌入在Host中的库,与每个服务器保持会话。对于WorkBuddy来说,已经内置MCP Client,可以通过~/.workbuddy/mcp.json文件配置MCP Server。也存在一些构建Agent的框架,如LangChain,可以通过langchain-mcp-adapters库实例化MCP Client,并配置可以访问的MCP Server。
MCP Server:
轻量级包装器,暴露一个或多个工具,例如"获取邮件摘要"函数。如FastMCP是一个用于构建MCP Server的Python框架。
Tool:
可调用的函数(数据源、API等)
MCP的调用流程
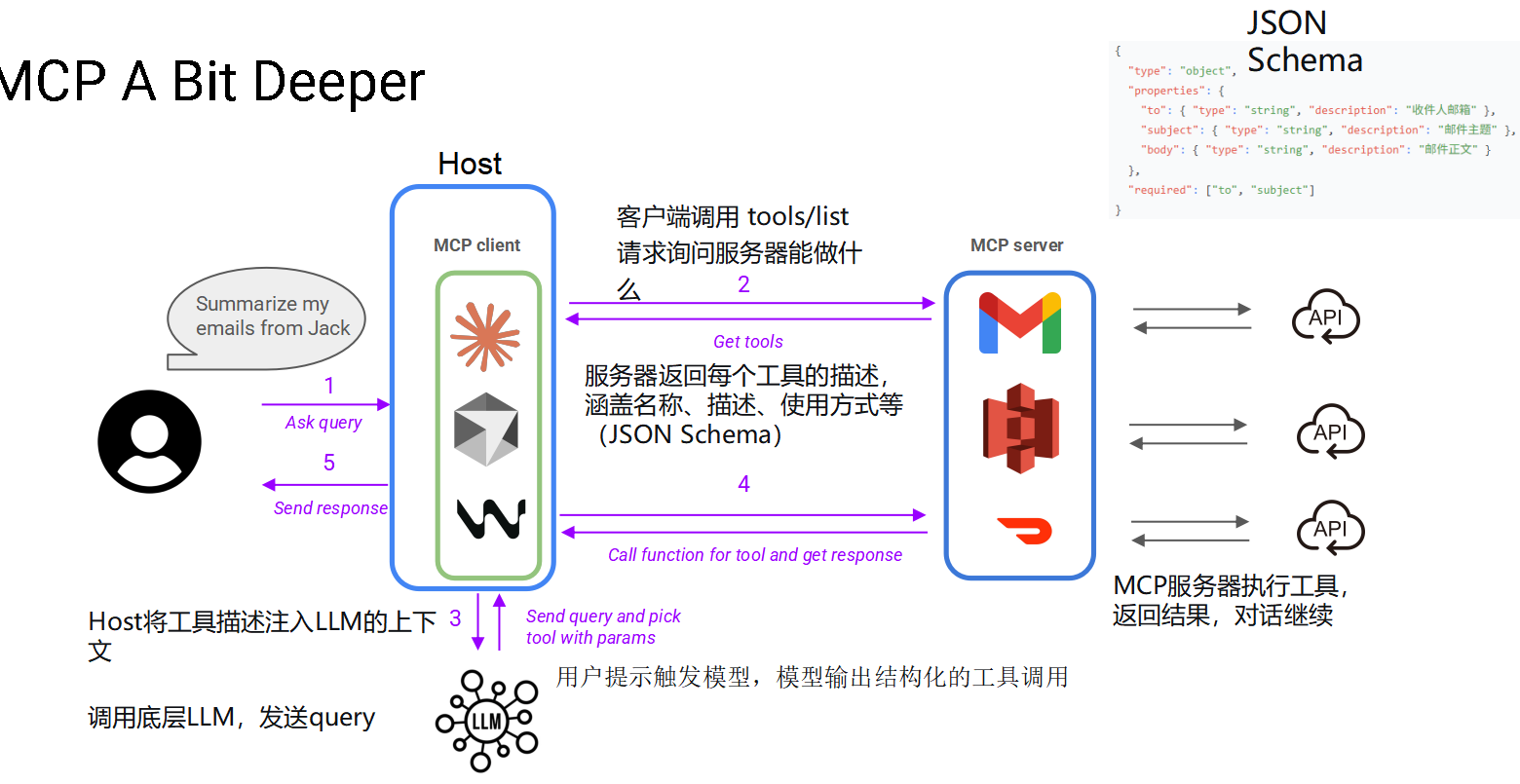
1. 用户发起请求 (Step 1)
-
动作:用户向 MCP Host(例如一个支持 MCP 的聊天界面)提问:"Summarize my emails from Jack"(总结 Jack 发来的邮件)。
-
对应图示 :箭头 1,紫色
Ask query。
2. 发现可用工具 (Step 2 - 核心机制)
-
动作:Host 中的 MCP Client 向 MCP Server 询问:"你有什么工具能用?"
- 即调用
tools/list接口。
- 即调用
-
服务器响应:MCP Server 返回一个 JSON Schema 列表,描述其拥有的所有工具。
- 关键点 :如图所示,返回的信息包含工具的名称、描述(用途)、以及使用该工具所需的参数格式(JSON Schema)。比如图中显示的 Gmail 工具,需要
to、subject等参数。
- 关键点 :如图所示,返回的信息包含工具的名称、描述(用途)、以及使用该工具所需的参数格式(JSON Schema)。比如图中显示的 Gmail 工具,需要
3. 注入信息给 LLM (Step 3)
-
动作 :Host 将 MCP Server 返回的**工具描述(JSON Schema)**注入到 LLM 的上下文中。
-
结果:LLM 现在知道了"我可以用哪些外部工具,以及如何调用它们"。
-
动作:Host 此时会向 LLM 发送用户的原始查询内容。
4. LLM 决定调用工具 (Step 4)
-
动作 :LLM 分析用户需求。它意识到要"总结邮件",需要调用邮件工具。于是,LLM 会输出结构化的工具调用指令 (例如:Call function
get_emailswith params{from: "Jack"})。 -
执行:MCP Client 接收这个指令,通过网络(箭头 4)告诉 MCP Server 执行这个函数。
-
服务器行动:MCP Server 执行内部逻辑(例如调用真实的 Gmail/Outlook API,如右侧图示),获取邮件数据。
5. 返回结果 (Step 5)
-
动作:MCP Server 将执行结果(例如 Jack 的邮件正文)返回给 Host。
-
进一步处理:Host 可以将这些结果数据再次发给 LLM,让 LLM 生成最终的自然语言回复(例如:"Jack 这一周发来了3封关于项目进度的邮件...")。
-
最终:Host 将最终的答案"Send response"展示给用户。
问题是
当MCP服务器暴露的工具数量很多(比如几十个)时,现有的LLM Agent难以准确选择合适的工具------模型容易混淆或漏选。
每个工具的描述(名称、参数schema、示例)会占用宝贵的上下文窗口,如果工具太多,可能挤占用户对话空间。
Agent Skills 智能体技能(封装的MCP文件夹)
Agent Skills设计了一套基于文件夹的标准化格式(以SKILL.md为核心)与渐进式披露的加载机制,先将精简的技能描述载入上下文进行智能匹配,再于需要时按需调用完整指令与脚本,从而大幅提升上下文利用效率并降低运行成本。
Skill 是一个语义完整的能力单元,它封装了一组相关的 MCP 工具、调用逻辑 和触发条件。对 LLM 而言,Skill 像一个"可调用的高级函数",而非零散的底层工具。如下是WorkBuddy的marketplace中的一个案例:ArXiv论文追踪。
先找到要用的文件夹(工具集),然后再选择要用的工具MCP。
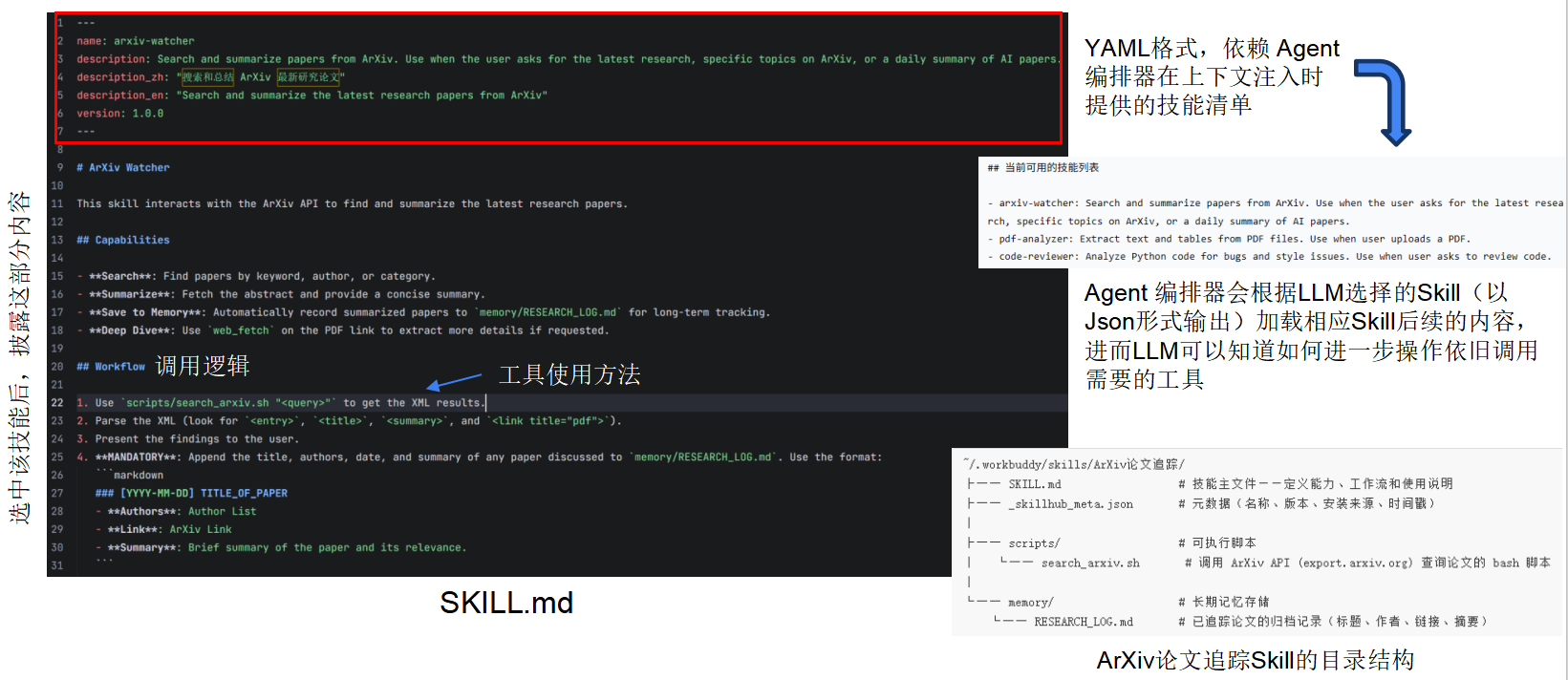
一开始LLM只能看到红框的部分,是Skills的描述,当LLM决定调用这个工具箱里的某个MCP时再展开,以解决上下文过长和技能匹配困难的问题。
工具选择困难:LLM 只需从相对少量 Skills(例如 5~10 个)中选择,而非从几十、几百个工具中选择。因为Skill实现了分层决策:先选 Skill → Skill 内部再选工具(可由更小的模型或确定性代码完成)
上下文挤占问题:初始只加载 Skills 的简要列表(每个 Skill 一行描述,约 50 token),选中后根据需要动态加载内部工具详情。
Harness Engineering
Agent = Model + Harness
模型是无状态的、没有工具、无上下文、无记忆。
Harness 是除此之外其他东西,可以把一个无状态的语言模型,变成一个能持续产出工作的编码 Agent。
一个类比:Harness是操作系统(OS);模型是 CPU。没有 OS ------ 没有内存管理、没有 I/O、没有进程隔离、没有调度 ------ 一颗 CPU 没办法和文件、网络、用户发生有用的交互。Harness 就是这一层 OS,它给模型一个结构化的运行环境,并负责模型和外部世界之间每一次交互的中介。
Claude Code 是一个 Harness。Trae 是一个 Harness。Cursor 是一个 Harness。它们包的是不同的模型,或者是同一个模型在不同配置下的样子,但在结构上做的都是同一件事:把模型的原始能力,变成可以应用到真实工作上的形态。
Agent Harness 的七大组件(并无定论)
上下文加载
在模型对任何任务采取行动之前,Harness 会先注入上下文:项目规则、架构约束、工作流指令、工具相关的指引。Claude Code 中的 CLAUDE.md 就是这一层的入口。
工具层
MCP工具集合
编排层
对复杂任务进行拆分和子agent任务派发。
权限层
确定运行边界。可以写入哪些目录、可以执行哪些命令、能不能访问网络。
执行钩子
在模型发起动作之前或之后运行的确定性代码。如拦截一次文件写入,按规定格式输出,在失败时阻止该动作,并向模型返回一个结构化错误。
记忆与状态管理
哪些状态会被带到下一次,上下文变得过大时如何压缩,解决记忆容量的问题。
会话命周期
任务从哪里开始,到哪里结束,中断后如何继续。
作业
根据本节课的内容,借助Trae、Cursor、CodeBuddy等AI IDE构建一个自己的MCP工具(参考https://github.com/modelcontextprotocol使用任意语言的SDK工具构建),并接入一个LLM应用(如WorkBuddy、Claude Code)
参考:https://github.com/yz1019117968/ai_coding_experiments/blob/main/mcp/code_analyzer_server.py