【iOS】源码学习-锁的原理
前言
在多线程编程中,为防止多线程同时修改统一数据导致的数据混乱、逻辑错乱甚至程序崩溃,锁确保了共享资源的线程安全。本篇博客笔者将主要介绍常见的锁及其底层分析。
不要将过多的其他操作代码放到锁里,否则一个线程执行的时候另一个线程就一直在等待,就无法发挥多线程的作用了。
锁的核心概念
锁的核心作用:保证临界区代码同一时刻仅允许一条线程执行,实现资源互斥访问,解决资源竞争问题。
锁核心分为两大类:
- 自旋锁:线程忙等待,不休眠,循环判断锁状态,CPU空转。适合加锁耗时极短的场景。
- 互斥锁:获取锁失败线程休眠,让出CPU,锁释放后唤醒。适合加锁耗时较长的场景。
递归锁、条件锁、读写锁、信号量均为两核心锁的上层封装。
锁的性能从高到低依次是:
OSSpinLock(自旋锁)->dispatch_semaphone(信号量)->pthread_mutex(互斥锁)->NSLock(互斥锁)->NSCondition(条件锁)->pthread_mutex(recursive 互斥递归锁)->NSRecursiveLock(递归锁)->NSConditionLock(条件锁)->synchronized(互斥锁)
锁的分类
锁大致分为以下几类:
- 自旋锁
在自旋锁中,线程会反复检查锁变量状态。抢锁失败时线程不会阻塞休眠,而是循环轮询判断锁是否释放,持续占用 CPU 空循环运行,属于忙等待。线程拿到锁之后不会自动释放,必须手动主动释放。自旋锁等待阶段不存在线程上下文切换,省去了调度切换的开销,因此适合锁占用时长很短的场景。
- 互斥锁
互斥锁是多线程编程里的同步机制,用来保障同一时刻只有一个线程操作全局变量等公共共享资源。加锁失败会导致线程阻塞休眠、释放CPU资源。存在上下文切换开销,适合持锁时间较长的场景。
- 条件锁
条件锁其实就是条件变量,需配合互斥锁使用。线程判断资源条件不满足时,释放互斥锁并休眠阻塞,其他线程更新资源满足条件后发送唤醒信号,休眠线程被唤醒,重新获取条件锁,确认条件达标后继续执行。
- 递归锁
递归锁是具备递归特性的互斥锁,允许同一线程对它连续多次加锁,且不触发死锁。但无论加锁多少次,每次加锁都要匹配一次解锁,全部解锁完毕才会真正释放锁,其他线程才能获取。而非递归锁不可重入,必须等锁释放后才可以再次获取锁。
- 信号量
信号量是功能更强的同步机制。信号量支持大于1的计数值,互斥锁等价于取值只能为0、1的二元信号量。信号量既能实现线程互斥,还能实现更加复杂的同步,能力范围远远大于普通锁。
- 读写锁
读写锁其实是一种特殊的自旋锁,它将共享资源的访问线程分为读者、写者两类。读者仅读取数据,写者负责修改数据。相比普通自旋锁,它大幅提升了并发能力。
读写锁的核心规则为:读读共享、写写互斥、读写互斥。同一时刻锁只能是多个读者持有或者单个写者持有,不允许读者和写者同时访问资源。锁被线程持有时,内核抢占机制失效。
读写锁的竞争规则为:若当前无读者和写者,写者可直接获取锁;若当前有读者或写者,写者会自旋等待直至锁完全空闲;若当前无写者,读者可以立即获取读锁;若已有写者持有锁,读者同样会自旋等待,直到写者释放锁。
现在基本不用读写锁,都采用dispatch_barrier_async(异步栅栏)、dispatch_barrier_sync(同步栅栏)栅栏函数来实现多读单写。
接下来具体看看几个锁的实现原理。
自旋锁
- OSSpinLock
OSSpinLock在底层纯自旋忙等待,线程不休眠。忙等待机制可能会造成任务的优先级反转,即高优先级任务一直等待,占用时间片,而低优先级的任务无法抢占时间片,会造成一直不能完成,锁未释放的情况,不安全。
具体示例:低优先级线程A拿到锁正在执行,高优先级线程B来抢锁,进入无限自旋忙等。iOS的调度规则是CPU时间片分给高优先级线程,即B。这样B死死占着CPU空转,低优先级A完全得不到调度时间,迟迟没法执行完成代码释放锁,高优先级的B也永远等不到锁,就会卡死。简单来说,就是高优先级自旋占用CPU,堵死了持有锁的低优先级线程运行机会。
因此OSSpinLock在iOS10之后就被废弃了。废弃后的替代方案是内部封装了os_unfair_lock。
- os_unfair_lock:项目常用
os_unfair_lock是优化版自旋锁,在内核调度层面做了优先级继承调度策略。竞争少时自旋,竞争多时线程休眠,兼顾性能与安全。os_unfair_lock解决了OSSpinLock优先级反转的问题,iOS10+可用,性能顶级。
unfair的含义:不保证等待线程的FIFO公平顺序,谁先抢到锁谁执行,牺牲绝对公平换极致性能与优先级安全,适用于业务场景。
objc
os_unfair_lock_t lock = &OS_UNFAIR_LOCK_INIT; // 创建锁并初始化
os_unfair_lock_lock(lock); // 加锁
os_unfair_lock_unlock(lock); // 解锁- atomic原子锁
atomic适用于OC中属性的修饰符,其自带一把自旋锁,但这个我们基本不用,属性我们常用nonatomic修饰。
之前看的settetr方法的底层实现里就有atomic加锁操作:
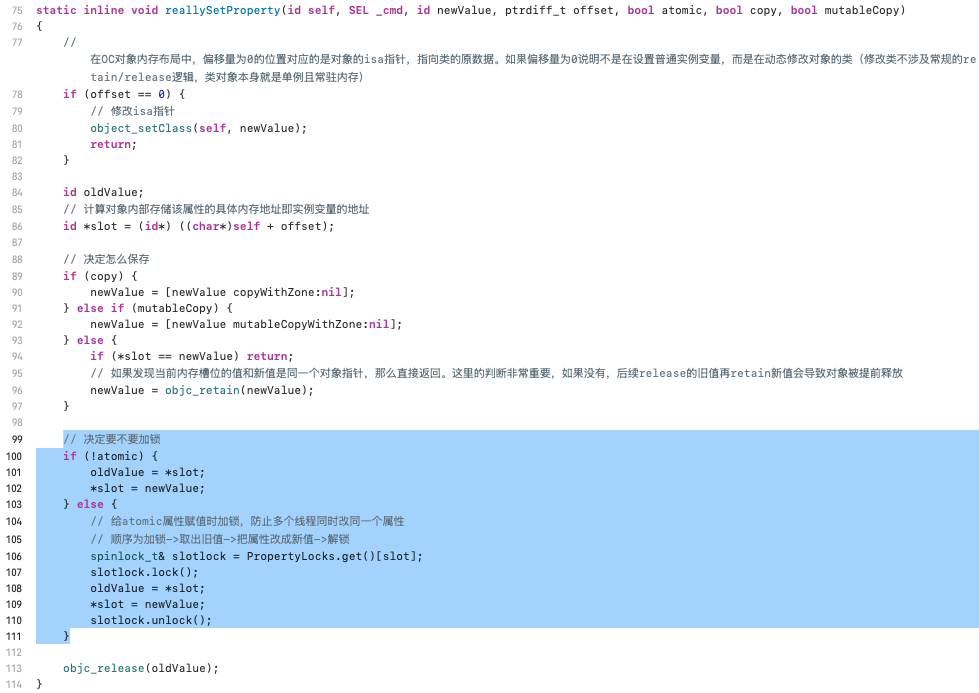
我们可以看到对atomic修饰的属性进行了spinlock_t加锁处理。其底层是通过os_unfair_lock替代OSSpinLock实现的加锁。同时为了防止哈希冲突,同时使用了加盐操作。
加盐操作:在哈希散列计算中混入额外固定常量值(盐值)参与哈希运算,扰动原始输入的哈希映射结果,优化哈希分布均匀度,防止哈希冲突。
getter方法中对atomic的处理也是大致相同的,这里不展示代码了。
但是我们要注意:atomic修饰的属性不绝对安全。只保护单次读写原子,不等于线程安全。
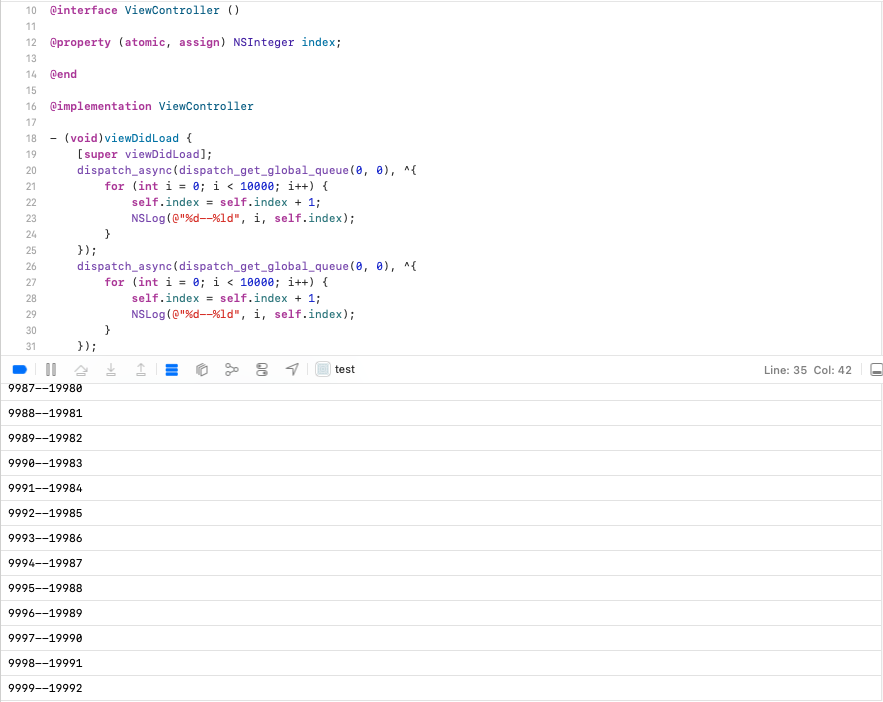
这个示例实际上会被编译器拆成三个独立指令:
- 读操作(该过程atomic会加锁,取值完整):
temp = self.index - 计算操作(纯CPU执行运算,无锁保护):
temp = temp + 1 - 写操作(该过程atomic会加锁,赋值完整):
self.index = temp
也就是atomic仅仅保护单独读、单独写这两步是原子不被打断的,但中间的计算步骤完全不受锁保护。因此两个循环各跑10000次,预期结果应该是20000,但实际数值却小于20000了,出现了数值丢失。
互斥锁
- pthread_mutex
pthread_mutex是系统POSIX标准C语言库底层API。线程加锁失败,不用忙等,而是阻塞线程并休眠。
objc
// 导入头文件
#import <pthread.h>
// 全局声明互斥锁
pthread_mutex_t _lock;
// 初始化互斥锁
pthread_mutex_init(&_lock, NULL);
// 加锁
pthread_mutex_lock(&_lock);
// 解锁
pthread_mutex_unlock(&_lock);
// 释放锁
pthread_mutex_destroy(&_lock);- NSLock
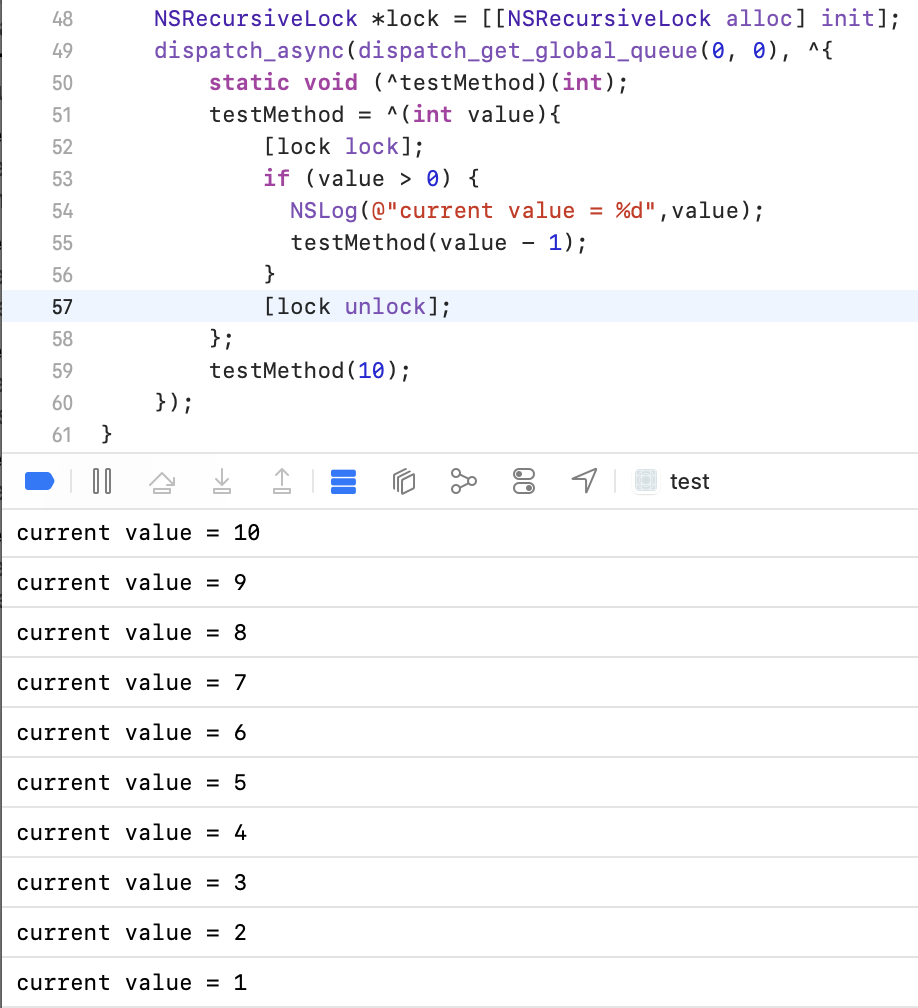
底层是基于pthread_mutex普通互斥锁的一个封装,是非递归互斥锁,如果发生递归调用,线程会阻塞锁死。
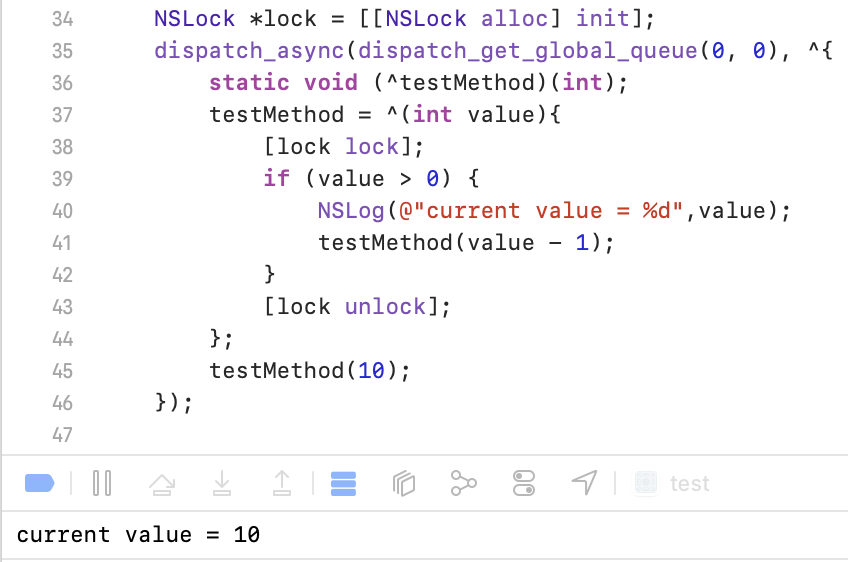
这里我们会发现线程阻塞锁死,只输出了10。这是因为第一层调用testMethod(10),加锁成功,然后打印,继续执行testMethod(9);第二层调用testMethod(9),再次执行加锁,NSLock不允许同一线程重复加锁,线程原地阻塞等待解锁,永远等不到,程序停滞,后面逻辑全不执行。
我们可以通过把NSLock挪到递归外,只给业务代码加锁来解决这个问题。
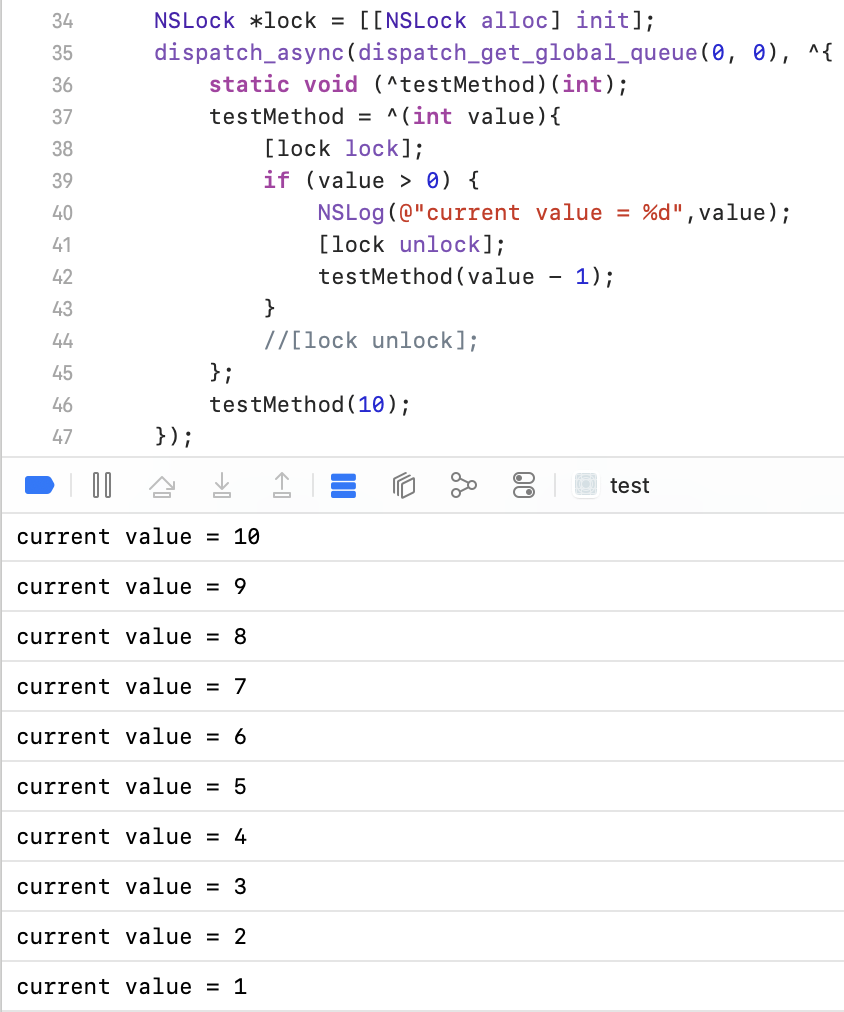
- NSRecursiveLock
NSRecursiveLock底层有一个PTHREAD_MUTEX_RECURSIVE标识,也可以用来解决上面递归嵌套调用的问题。
POSIX pthread互斥锁类型枚举宏用来定义一把锁是否支持同一线程重复递归加锁,属于C底层锁属性配置。主要有两种核心锁类型:
- PTHREAD_MUTEX_NORMAL:默认类型。即同一个线程不能连续多次lock,同一个线程第二次调用pthread_mutex_lock直接死锁、线程永久阻塞。谁加锁必须谁解锁,跨线程解锁直接崩溃。
- PTHREAD_MUTEX_RECURSIVE:递归类型。即同一线程没调用一次lock,计数+1,且必须同等次数的unlock,计数归零后锁才真正释放。允许递归嵌套、循环里反复加锁,不会自己卡死自己。
三种锁的底层枚举原理:
- NSLock:底层封装pthread_mutex_t,默认属性是非递归,PTHREAD_MUTEX_NORMA默认类型。
- NSRecursiveLock:底层pthread_mutexattr_settype设置为PTHREAD_MUTEX_RECURSIVE递归类型。
- os_unfair_lock:完全不支持递归加锁,同一线程重复lock直接崩溃,比NSLock更加严苛。
但是在外层再加一个for循环又会出现报错:
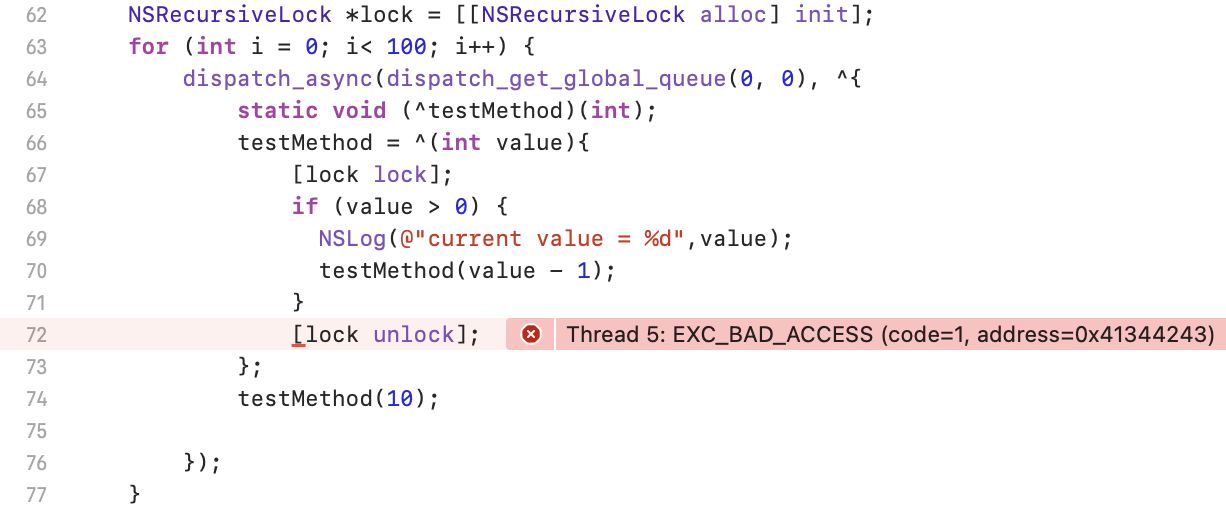
这是因为for循环创建了100个并发任务到全局队列,所有任务共用同一把NSRecursiveLock锁,每个任务都递归地获取lock。这样多个线程用同一把递归锁执行长时间递归任务时,会导致被频繁地在不同线程间转移,由于递归锁的计数是线程绑定的,线程切换时状态管理混乱,最终导致某些线程永远等不到锁释放,形成死锁。
可以通过使用串行队列来解决这个问题,要确保让每个任务都有自己的锁对象就可以避免这个问题。
- @synchronized互斥递归锁
开启汇编调试,发现其底层执行是调用objc_sync_enter和objc_sync_exit方法。具体来看一下这两个方法:
- objc_sync_enter:
obj存在时,通过id2data方法获取对应的syncData,然后对threadCount和lockCount执行递增操作。
objc
int objc_sync_enter(id obj)
{
int result = OBJC_SYNC_SUCCESS;
if (obj) { // 传入不为nil
SyncData* data = id2data(obj, ACQUIRE); // 核心
ASSERT(data);
data->mutex.lock(); // 加锁
} else { // 传入nil
// @synchronized(nil) does nothing
if (DebugNilSync) {
_objc_inform("NIL SYNC DEBUG: @synchronized(nil); set a breakpoint on objc_sync_nil to debug");
}
objc_sync_nil();
}
return result;
}- objc_sync_exit:
obj存在时,通过id2data方法获取对应的syncData,然后对threadCount和lockCount执行递减操作。
objc
int objc_sync_exit(id obj)
{
int result = OBJC_SYNC_SUCCESS;
if (obj) { // 传入不为nil
SyncData* data = id2data(obj, RELEASE);
if (!data) {
result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR;
} else {
bool okay = data->mutex.tryUnlock(); // 解锁
if (!okay) {
result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR;
}
}
} else { // 传入nil
// @synchronized(nil) does nothing
}
return result;
}然后来具体看一下SyncData:
objc
typedef struct alignas(CacheLineSize) SyncData {
struct SyncData* nextData; // 类似于链表的结构
DisguisedPtr<objc_object> object; // 锁住的对象
int32_t threadCount; // 有多少线程使用了这个锁
recursive_mutex_t mutex; // 递归锁
} SyncData;SyncData封装了recursive_mutex_t属性,可以确认@synchronized确实是一个递归互斥锁,且是通过链表的形式存储的。
再看一下id2data方法的具体实现:
objc
// p1:锁住的对象 p2:枚举值,标记本次调用id2data的目的场景
// 枚举值:ACQUIRE表示进入@synchronized要加锁 RELEASE表示离开@synchronized要解锁 CHECK表示只查询,不加锁也不解锁
static SyncData* id2data(id object, enum usage why)
{
spinlock_t *lockp = &LOCK_FOR_OBJ(object);
SyncData **listp = &LIST_FOR_OBJ(object);
SyncData* result = NULL;
#if SUPPORT_DIRECT_THREAD_KEYS
// TLS:Thread Local Storage,线程本地存储
// 第一步:先查本地的局部线程缓存
// Check per-thread single-entry fast cache for matching object
bool fastCacheOccupied = NO;
// 通过KVC方式获取线程绑定的data
SyncData *data = (SyncData *)tls_get_direct(SYNC_DATA_DIRECT_KEY);
// 如果线程缓存中有data
if (data) {
fastCacheOccupied = YES;
// 如果在线程空间找到了data
if (data->object == object) {
// Found a match in fast cache.
uintptr_t lockCount;
result = data;
// 通过KVC获取lockCount和lockCount来记录被锁了几次
lockCount = (uintptr_t)tls_get_direct(SYNC_COUNT_DIRECT_KEY);
if (result->threadCount <= 0 || lockCount <= 0) {
_objc_fatal("id2data fastcache is buggy");
}
switch(why) {
// 当前线程重复加锁,增加重入次数
case ACQUIRE: {
lockCount++;
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount);
break;
}
// 当前线程释放锁,减少重入次数
case RELEASE:
lockCount--;
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount);
if (lockCount == 0) {
// remove from fast cache
// 重入次数为0,移出快速缓存
tls_set_direct(SYNC_DATA_DIRECT_KEY, NULL);
// atomic because may collide with concurrent ACQUIRE
OSAtomicDecrement32Barrier(&result->threadCount);
}
break;
case CHECK:
// do nothing
break;
}
return result;
}
}
#endif
// 第二步:再查当前线程的SyncCache
// Check per-thread cache of already-owned locks for matching object
SyncCache *cache = fetch_cache(NO);
if (cache) {
unsigned int i;
// 遍历总表
for (i = 0; i < cache->used; i++) {
SyncCacheItem *item = &cache->list[i];
if (item->data->object != object) continue;
// Found a match.
result = item->data;
if (result->threadCount <= 0 || item->lockCount <= 0) {
_objc_fatal("id2data cache is buggy");
}
switch(why) {
// 同一线程再次进入,增加重入次数
case ACQUIRE:
item->lockCount++;
break;
// 退出同步块,减少重入次数
case RELEASE:
item->lockCount--;
if (item->lockCount == 0) {
// remove from per-thread cache
// 当前线程完全释放该锁,从缓存中移除
cache->list[i] = cache->list[--cache->used];
// atomic because may collide with concurrent ACQUIRE
OSAtomicDecrement32Barrier(&result->threadCount);
}
break;
case CHECK:
// do nothing
break;
}
return result;
}
}
// Thread cache didn't find anything.
// Walk in-use list looking for matching object
// Spinlock prevents multiple threads from creating multiple
// locks for the same new object.
// We could keep the nodes in some hash table if we find that there are
// more than 20 or so distinct locks active, but we don't do that now.
// 第三步:进入全局SyncData链表查找
lockp->lock();
{
SyncData* p;
SyncData* firstUnused = NULL;
for (p = *listp; p != NULL; p = p->nextData) {
if ( p->object == object ) {
// 找到对象对应的SyncData
result = p;
// atomic because may collide with concurrent RELEASE
OSAtomicIncrement32Barrier(&result->threadCount);
goto done;
}
if ( (firstUnused == NULL) && (p->threadCount == 0) )
firstUnused = p;
}
// no SyncData currently associated with object
// 找不到RELEASE或CHECK时直接结束
if ( (why == RELEASE) || (why == CHECK) )
goto done;
// an unused one was found, use it
// 第一次进入没有找到,复用空闲的SyncData
if ( firstUnused != NULL ) {
result = firstUnused;
result->object = (objc_object *)object;
result->threadCount = 1;
goto done;
}
}
// Allocate a new SyncData and add to list.
// XXX allocating memory with a global lock held is bad practice,
// might be worth releasing the lock, allocating, and searching again.
// But since we never free these guys we won't be stuck in allocation very often.
// 第四步:没有可复用的SyncData,就新建一个
posix_memalign((void **)&result, alignof(SyncData), sizeof(SyncData)); // 创建赋值
result->object = (objc_object *)object;
result->threadCount = 1;
new (&result->mutex) recursive_mutex_t(fork_unsafe_lock);
result->nextData = *listp;
*listp = result;
done:
lockp->unlock();
if (result) {
// Only new ACQUIRE should get here.
// All RELEASE and CHECK and recursive ACQUIRE are
// handled by the per-thread caches above.
if (why == RELEASE) {
// Probably some thread is incorrectly exiting
// while the object is held by another thread.
return nil;
}
if (why != ACQUIRE) _objc_fatal("id2data is buggy");
if (result->object != object) _objc_fatal("id2data is buggy");
#if SUPPORT_DIRECT_THREAD_KEYS
if (!fastCacheOccupied) { // 判断是否支持栈存缓存、是否支持KVC形式赋值存入tls
// Save in fast thread cache
// 保存到线程快速缓存
tls_set_direct(SYNC_DATA_DIRECT_KEY, result);
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)1);
} else
#endif
{
// Save in thread cache
// 保存到当前线程的SyncCache
if (!cache) cache = fetch_cache(YES);
cache->list[cache->used].data = result;
cache->list[cache->used].lockCount = 1;
cache->used++;
}
}
return result;
}SyncCache是一个结构体,主要用来存储线程的本地缓存数据。
objctypedef struct { SyncData *data; unsigned int lockCount; // number of times THIS THREAD locked this block } SyncCacheItem; typedef struct SyncCache { unsigned int allocated; unsigned int used; SyncCacheItem list[0]; // 用于存储线程,其中data用于存储SyncData和lockCount } SyncCache;
其中我们对比一下TLS和SyncCache:
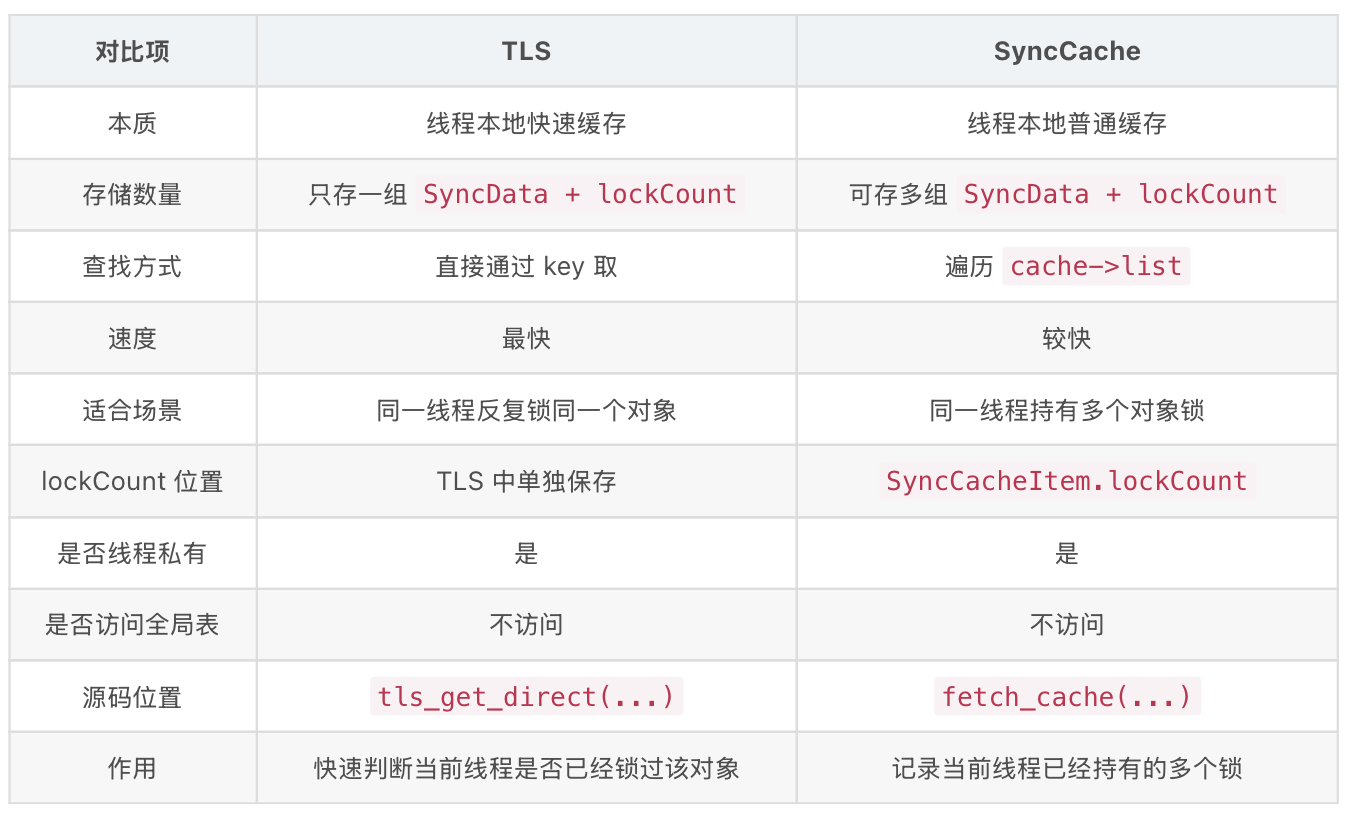
总结一下整个流程:
- 在TLS线程局部存储中查询。(TLS只存一组,即最近一次使用锁的对象及其嵌套锁计数)
通过tls_get_direct获取线程绑定的SyncData,检查data->object是否与传入的对象匹配。如果匹配执行相应的加锁或者解锁操作,若归零则移除TLS缓存并递减 threadCount。如果出现threadCount<=0或者lockCount<=0,触发崩溃。反之在SyncData中查询。 - 在SyncData线程存储中查询。(线程可存多组锁对象,支持多锁交替使用)
通过fetch_cache(NO)获取线程缓存池,遍历SyncCacheItem数组,检查item->data->object是否匹配,然后执行对应的加锁解锁操作,若归零则从数组中移除并递减 threadCount。同样如果出现threadCount<=0或者lockCount<=0,触发崩溃。反之在全局链表中查询。 - 在全局链表中查询并创建SyncData节点。(找到或新建最后都要放入当前线程的缓存中去)
- 如果全局链表中找到对应SyncData的object,说明该object已经被创建。可能是其他线程正在使用,也可能是用过还未释放。此时直接复用已有的节点。
- 如果全局链表中没有找到,但是有空闲的SyncData节点,可以进行复用空闲节点。
- 如果全局链表里完全没有可用的SyncData,那就创建一个新的SyncData。
简单来说:
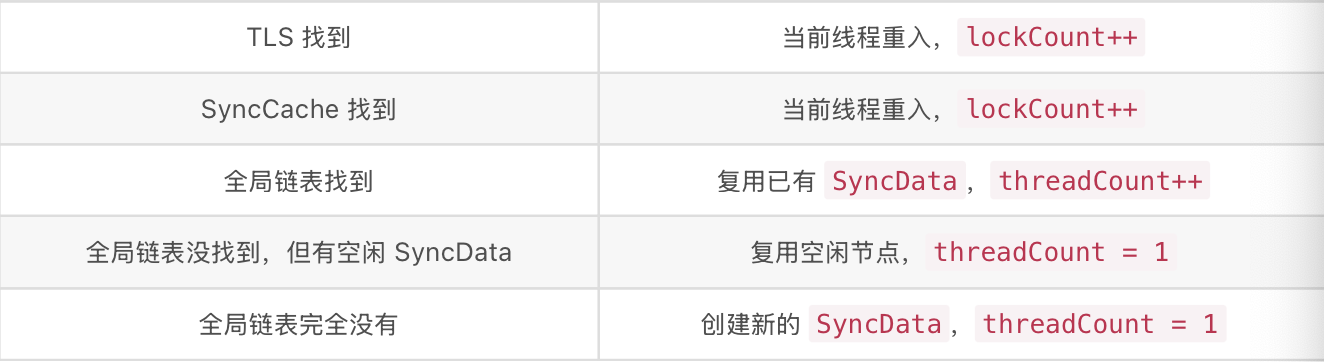
@synchronized也存在坑点:
因为@synchronized是靠对象内存地址来区分锁的,因此在循环里反复更换锁对象可能会导致互斥实效或者底层锁缓存频繁销毁崩溃。必须用一个全程不变的固定对象来当作锁载体。
看下具体示例: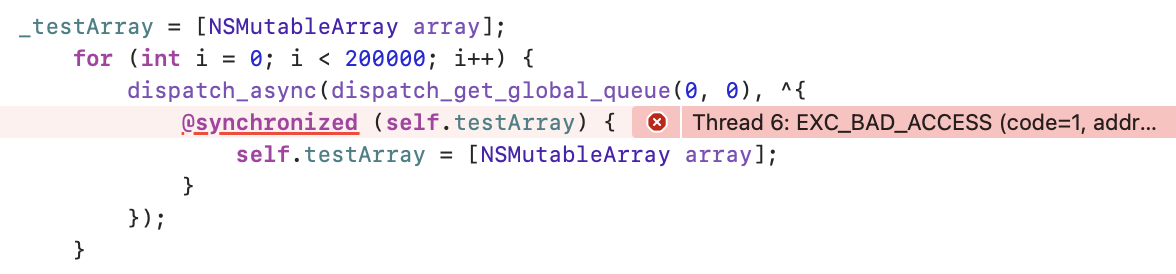
这里报错的主要原因在于:
- 锁对象动态变更,互斥完全失效。
@synchronized的锁载体是self.testArray指向的数组实例,循环里不断执行[NSMutableArray array]会频繁生成全新数组对象。不同线程锁住的是完全不同的内存对象,彼此之间没有互斥约束,同步保护彻底失效,多线程无序覆盖赋值,内存错乱崩溃。
- 底层SyncData频繁创建销毁,引发底层内存异常
@synchronized依靠对象地址作为key,去全局哈希表匹配SyncData锁结构体。数组对象频繁新建、旧对象被释放回收会疯狂触发SyncData的新建、标记回收、销毁逻辑,极易造成哈希链表断裂、内存碎片、野指针、内存管理异常等,直接触发闪退。
因此,我们在选择对象的时候,使用一个独立且稳定的锁对象作为锁可以有效避免锁对象动态变化带来的负面效果。
也可以通过控制线程的并发量来避免资源耗尽,即改用串行队列或限制并发数量。
条件锁
- NSCondition
NSCondition底层封装pthread_mutex和pthread_cond_t条件变量。在日常开发中使用较少,线程需要满足条件才会往下走,否则会堵塞等待,直到条件满足。适配生产者消费者模型。
生产者消费者模型:经典多线程协同模型。
- 生产者线程:负责生产数据、任务、资源,把产物存入缓冲区。
- 消费者线程:负责取出缓冲区里的数据,执行业务逻辑。
- 缓冲区:中间仓库,存放生产出来的内容,有容量上限。
NSCondition源码:
苹果开源了Swift Foundation库,用Swift封装一层pthread原语,对外暴露一模一样的NSCondition OC/Swift共用 API。
swift
open class NSCondition: NSObject, NSLocking {
internal var mutex = _MutexPointer.allocate(capacity: 1)
internal var cond = _ConditionVariablePointer.allocate(capacity: 1)
// 初始化
public override init() {
pthread_mutex_init(mutex, nil)
pthread_cond_init(cond, nil)
}
// 析构
deinit {
// 销毁pthread内核资源
pthread_mutex_destroy(mutex)
pthread_cond_destroy(cond)
// 解除Swift托管内存
mutex.deinitialize(count: 1)
cond.deinitialize(count: 1)
// 释放堆内存
mutex.deallocate()
cond.deallocate()
}
// 加锁
open func lock() {
pthread_mutex_lock(mutex)
}
// 解锁
open func unlock() {
pthread_mutex_unlock(mutex)
}
// 无限等待
open func wait() {
pthread_cond_wait(cond, mutex)
}
// 限时等待
open func wait(until limit: Date) -> Bool {
guard var timeout = timeSpecFrom(date: limit) else {
return false
}
return pthread_cond_timedwait(cond, mutex, &timeout) == 0
}
// 唤醒通知方法
// 单发唤醒:只唤醒等待队列里随机一个阻塞线程
open func signal() {
pthread_cond_signal(cond)
}
// 广播全唤醒:一次性唤醒条件变量下所有阻塞的线程
open func broadcast() {
pthread_cond_broadcast(cond) // wait signal
}
// 附加属性
open var name: String?
}根据源码,NSCondition的使用:
objc
NSCondition *condition = [[NSCondition alloc] init]
[condition lock];
[condition unlock];
// 让当前线程处于等待状态
[condition wait];
// CPU发信号告诉线程不用等待,可以继续执行
[condition signal];- NSConditionLock
NSConditionLock底层是NSCondition的二次封装,绑定整型condition条件值。一旦一个线程获得锁,其他线程一定等待。
objc
// 初始化条件锁,设置内部condition初始值
NSConditionLock *conditionLock = [[NSConditionLock alloc] initWithCondition:2];
// 普通加锁:只判断这把锁有没有被其他线程占用,不判断内部condition的值
[conditionLock lock];
// 条件加锁:只有同时满足当前锁没有被其他线程占用、内部condition=A两个条件,才能继续执行
[conditionLock lockWhenCondition:A条件];
// 普通解锁:只释放锁,不修改内部 condition的值
[conditionLock unlock];
// 条件解锁:释放锁,同时把内部condition修改为A条件
[conditionLock unlockWithCondition:A条件];
// 带超时的条件加锁:在A时间之前等待condition=A条件。条件满足并成功拿到锁,返回YES;超时还没拿到锁,返回NO
BOOL result = [conditionLock lockWhenCondition:A条件 beforeDate:A时间];
if (result) {
// 成功拿到锁,可以执行临界区代码
[conditionLock unlock];
} else {
// 没有拿到锁,不能调用 unlock
}总结一下几个主要的锁:
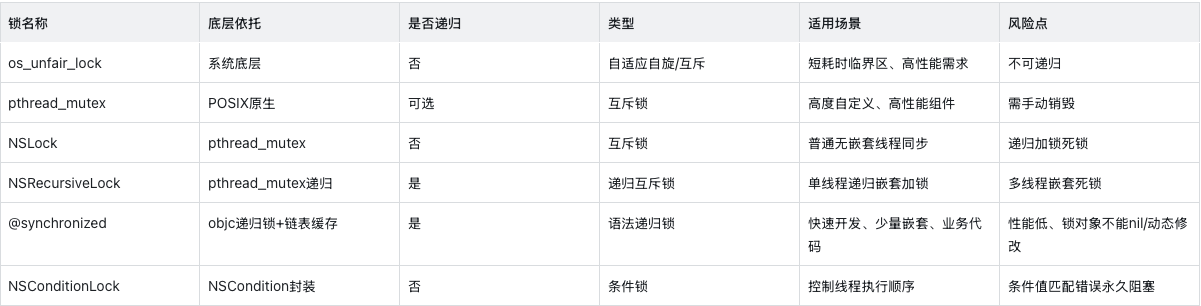
总结
- 如果只是简单使用(如涉及线程安全),使用NSLock。
- 如果是循环嵌套,推荐使用递归锁,性能比@synchronized好。
- 如果在循环嵌套中,还有多线程影响(如等待、死锁等),使用@synchronized。