前言
回顾专栏前文,我们从CNN基础出发,陆续学习了ResNet分类、YOLO目标检测、U-Net系列语义分割模型。以U-Net为代表的卷积神经网络,凭借轻量化、小样本友好、部署便捷等优势,长期占据遥感分割主流地位,也是入门、毕设与中小型项目的首选方案。
但随着高分辨率遥感影像普及、复杂地物场景增多、全域大范围智能解译需求提升,CNN固有局限性逐渐凸显:卷积操作侧重局部特征提取,长距离依赖建模能力弱,面对大范围连片地物、跨区域相似地物、复杂纹理交错场景时,容易出现全局语义理解不足、大尺度地物分割断层、同类地物区分困难等问题。
近年来,基于Transformer 架构的视觉模型快速崛起,凭借强大的全局建模能力,成为计算机视觉新方向。其中 SegFormer 作为轻量化Transformer分割代表作,兼顾精度、速度与算力成本,在遥感领域落地速度极快。
本期我们对比CNN与Transformer的核心差异,详解SegFormer架构特性与遥感适配优势,梳理轻量高精度分割模型选型方案,分析视觉大模型在遥感解译中的落地现状,最后结合业务场景给出完整选型指南,帮大家完成从传统CNN分割到前沿Transformer分割的技术进阶。
一、CNN模型局限性 & Transformer核心优势
1.1 传统CNN分割模型的短板
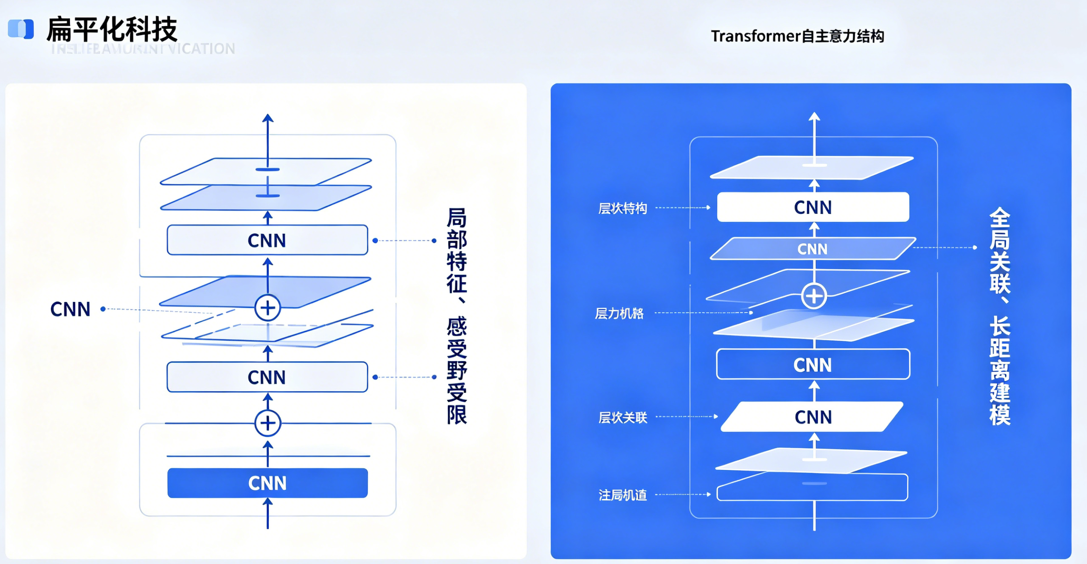
无论是U-Net、U-Net++还是Attention UNet,核心特征提取单元均为卷积核,受结构原理限制,存在四大行业痛点:
- 全局感知能力弱
卷积仅在局部窗口内提取特征,依靠多层堆叠扩大感受野,无法直接建立远距离像素、地物之间的关联。面对跨图幅河流、连片林地、全域建成区等大尺度地物,易出现分割断裂、区域不连贯问题。 - 长距离依赖建模困难
遥感影像中,相同地物会分散分布在画面不同位置,CNN难以捕捉全局同类别语义关联,容易出现"同物异分"。 - 复杂场景泛化不足
针对云雾干扰、地形起伏、多角度俯拍影像,纯卷积网络对全局语义的判别能力有限,极端场景下精度下滑明显。 - 特征融合方式单一
依赖跳跃连接、浅层注意力做特征补强,架构上限固定,很难进一步挖掘影像深层全局信息。
1.2 Transformer架构的核心优势
Transformer依托自注意力机制(Self-Attention) 打破局部窗口限制,和CNN形成能力互补,尤其适配高分遥感复杂场景:
- 全局建模能力拉满
通过注意力权重计算,直接对整张影像所有像素建立关联,精准捕捉长距离地物依赖关系,河流、道路、林地等线性/连片地物分割完整性大幅提升。 - 语义理解更全面
不只学习纹理、边缘、光谱等浅层特征,更擅长理解地物空间分布、拓扑关系等高层语义,大幅降低同谱异物、同物异谱带来的错分率。 - 多尺度特征自适应融合
天然适配遥感影像"大小目标混杂"的特点,自动权衡微小地物细节与大范围地物全局特征,兼顾精度与完整性。 - 扩展性极强
架构可灵活缩放,既能做成轻量化模型适配工程部署,也可升级为超大视觉模型,支撑海量遥感数据批量解译。
CNN与Transformer结构对比图
二、轻量级高精度遥感分割模型选型
在Transformer系列模型中,并非所有架构都适合遥感落地。结合算力门槛、标注数据量、推理速度、分割精度四大维度,筛选出工程与科研通用的轻量高阶模型,同时区分适用场景。
2.1 标杆模型:SegFormer
SegFormer 是目前遥感领域使用率最高、综合表现最优的Transformer分割模型,也是本期重点讲解内容。
核心遥感适配特点
- 轻量化设计
摒弃传统Transformer复杂位置编码,结构精简,硬件要求友好,消费级显卡即可完成训练与推理,对比Swin-UNet等模型,推理速度提升30%以上。 - 多级特征融合
采用分层Transformer编码器+简易解码器结构,同时保留浅层细节与深层语义,完美适配遥感"小目标+大区域"共存的特征。 - 小样本表现优异
相较于纯大模型,SegFormer对标注数据需求量适中,几百至千余张切片即可达到理想精度,契合遥感标注成本高的现状。 - 多波段兼容性强
网络输入层改造简单,可快速适配RGB、多光谱、高光谱遥感影像,适配高分、哨兵、Landsat等主流数据源。
适配场景
全域土地利用精细分割、河道路网提取、城乡建成区监测、生态植被全覆盖分析,科研论文基线、工程项目主力模型。
2.2 其他主流轻量Transformer分割模型
-
Swin-UNet
CNN与Swin Transformer混合架构,局部细节保留能力强,密集建筑、细碎地块分割效果突出;缺点是参数量偏大,推理速度较慢。
适配场景:城镇密集居民区、农田地块精细提取。
-
ConvNeXt
借鉴Transformer思想优化的新型卷积网络,介于CNN与Transformer之间,兼顾卷积的高效性与全局建模能力,上手成本低。
适配场景:原有CNN项目升级、追求速度与精度平衡的常规分割任务。
SegFormer遥感分割效果图

三、大模型在遥感解译中的落地现状
随着视觉大模型(Vision LLM)技术快速发展,"大模型+遥感"成为行业前沿方向,我们区分技术形态、落地场景、现存问题客观解读,区分科研探索与工程实用边界。
3.1 主流落地形态
- 通用视觉大模型微调
基于SAM、CLIP等开源通用视觉大模型,使用遥感数据集做二次微调,实现语义分割、目标检测、地物分类等任务。优势是零样本、少样本能力极强,少量标注数据即可完成任务;缺点是模型体量巨大,对GPU显存要求极高。 - 遥感专属大模型
基于海量公开遥感数据集(BigEarthNet、SEN12、WHU等)训练行业专属大模型,针对性学习遥感光谱、纹理、俯视角特征,比通用大模型适配性更强,是目前科研机构重点研发方向。 - 大模型+小模型联动方案
工业界主流落地模式:大模型做粗筛选、场景判别、样本扩充;轻量化Transformer/CNN模型做精细分割、定位。高低搭配,兼顾精度、速度与算力成本。
3.2 应用场景
- 大范围国土普查、跨区域遥感数据批量解译;
- 灾害应急监测(地震、洪水、火灾),支持无标注/少标注快速识别;
- 遥感影像智能解译平台、云端一体化服务系统搭建。
3.3 当前落地难点
- 算力成本高昂:千亿级参数大模型需要高性能集群支撑,普通企业、个人研究者难以负担;
- 实时推理受限:大模型推理延迟高,无法满足移动端、实时监测等低延迟需求;
- 专业适配不足:通用大模型对地物光谱、遥感几何特征理解有限,复杂地形、云雾区域仍存在错分;
- 部署流程复杂:模型压缩、量化、部署优化技术门槛高,短期内难以全面替代轻量化模型。
总结 :现阶段轻量化Transformer(SegFormer)是落地首选;超大视觉模型更多用于前沿研究、云端大型平台、应急少样本场景,个人项目、常规工程暂不建议盲目使用。
四、不同场景模型选型对比总结
结合前文所有模型(CNN系列 + Transformer系列),按照任务类型、数据条件、硬件配置、精度需求整理完整选型方案,方便大家直接对照选用。
多模型场景选型对比表
选型速览
-
入门学习、算力弱、样本少、快速出结果
优先选择:原生U-Net / Attention UNet(CNN)
特点:上手简单、调参成熟、部署零压力,满足基础分割需求与毕设要求。
-
常规工程项目、中等精度、兼顾速度与效果
优先选择:SegFormer / ConvNeXt(轻量Transformer/混合架构)
特点:全局语义强,地物完整性高,硬件门槛适中,目前行业主流方案。
-
密集地物、细碎目标、超高精度科研实验
优先选择:Swin-UNet
特点:细节提取能力拉满,适合建筑集群、农田、小型地物精细分割。
-
少样本、零样本、大范围云端解译、前沿研究
优先选择:遥感专属大模型 / SAM微调
特点:样本依赖极低,功能强大,仅推荐专业团队、科研机构使用。
-
线性地物(河流、道路、海岸线)提取
优先选择:SegFormer
特点:全局建模优势完美发挥,有效解决线条断裂、不连贯问题。
五、本期核心总结
- 传统CNN受限于卷积局部特性,全局感知、长距离依赖建模能力不足,复杂遥感场景存在明显瓶颈;Transformer依靠自注意力机制,补齐全局语义短板,是分割技术演进的主流方向。
- SegFormer 是当前遥感领域综合实力最强的轻量化Transformer模型,兼顾精度、速度、算力与适配性,优先推荐工程与科研落地。
- 视觉大模型是遥感未来趋势,但现阶段受算力、部署、适配性限制,暂无法全面普及,高低模型联动是工业界主流思路。
- 模型选型不以"新老"论优劣,结合样本数量、硬件条件、业务精度、场景特征综合判断,合适的才是最优解。
环境依赖安装
bash
# 一键安装所需依赖,适配遥感影像与Transformer模型
pip install torch torchvision timm einops rasterio albumentations -i https://pypi.tuna.tsinghua.edu.cn/simple一、Swin-UNet 遥感适配代码(支持多波段)
适配 RGB/4波段多光谱遥感影像,面向密集建筑、细碎地块分割场景,全中文注释。
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops import rearrange
import timm
# -------------------------- 基础模块定义 --------------------------
class PatchEmbed(nn.Module):
def __init__(self, patch_size=4, in_chans=3, embed_dim=96):
super().__init__()
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.proj(x)
B, C, H, W = x.shape
x = rearrange(x, 'b c h w -> b (h w) c')
return x, H, W
# -------------------------- Swin-UNet 主干网络 --------------------------
class SwinUNet_RS(nn.Module):
def __init__(self, in_channels=4, num_classes=4, embed_dim=96):
"""
:param in_channels: 输入波段数,RGB=3,哨兵多光谱=4
:param num_classes: 分割类别数
:param embed_dim: 基础嵌入维度
"""
super().__init__()
# 替换输入层,适配遥感多波段
self.patch_embed = PatchEmbed(patch_size=4, in_chans=in_channels, embed_dim=embed_dim)
# 加载Swin Transformer主干
self.swin_backbone = timm.create_model(
'swin_tiny_patch4_window7_224',
pretrained=False,
embed_dim=embed_dim
)
# 解码器上采样模块
self.up1 = nn.ConvTranspose2d(embed_dim * 2, embed_dim, 2, stride=2)
self.up2 = nn.ConvTranspose2d(embed_dim, embed_dim // 2, 2, stride=2)
# 输出分割头
self.out = nn.Conv2d(embed_dim // 2, num_classes, kernel_size=1)
def forward(self, x):
B = x.shape[0]
# 嵌入层
x, H, W = self.patch_embed(x)
# Swin Transformer 特征提取
x = self.swin_backbone.forward_features(x)
# 维度还原
x = rearrange(x, 'b (h w) c -> b c h w', h=H, w=W)
# 上采样解码
x = self.up1(x)
x = self.up2(x)
# 输出分割掩码
out = self.out(x)
return out
# -------------------------- 模型测试 --------------------------
if __name__ == "__main__":
# 模拟 4波段 512*512 遥感影像
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
rs_img = torch.randn(1, 4, 512, 512).to(device)
model = SwinUNet_RS(in_channels=4, num_classes=4).to(device)
pred = model(rs_img)
print(f"✅ Swin-UNet 推理完成,输出尺寸: {pred.shape}")二、SegFormer 遥感适配代码(轻量化首选)
当前遥感工程、论文主流模型,全局建模能力强,适配河流、道路、全域土地分割。
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
# -------------------------- SegFormer 核心模块 --------------------------
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = nn.GELU()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
# -------------------------- 遥感版 SegFormer --------------------------
class SegFormer_RS(nn.Module):
def __init__(self, in_channels=4, num_classes=4, embed_dim=64):
"""
:param in_channels: 影像波段数
:param num_classes: 分割类别数
:param embed_dim: 特征维度
"""
super().__init__()
# 输入卷积,适配多波段遥感影像
self.stem = nn.Conv2d(in_channels, embed_dim, 4, stride=4)
# Transformer 编码器
self.attn = Attention(embed_dim, num_heads=8)
self.mlp = Mlp(embed_dim, embed_dim * 4)
# 简易解码器
self.decoder = nn.ConvTranspose2d(embed_dim, embed_dim, 4, stride=4)
# 分割输出头
self.seg_head = nn.Conv2d(embed_dim, num_classes, 1)
def forward(self, x):
B, C, H, W = x.shape
# 下采样 + 维度转换
x = self.stem(x)
_, c, h, w = x.shape
x = x.permute(0, 2, 3, 1).reshape(B, h*w, c)
# 自注意力全局建模
x = self.attn(x)
x = self.mlp(x)
# 维度还原
x = x.reshape(B, h, w, c).permute(0, 3, 1, 2)
# 上采样解码
x = self.decoder(x)
# 输出分割结果
out = self.seg_head(x)
return out
# -------------------------- 模型测试 --------------------------
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 4波段 512*512 遥感切片
rs_img = torch.randn(1, 4, 512, 512).to(device)
model = SegFormer_RS(in_channels=4, num_classes=4).to(device)
pred = model(rs_img)
print(f"✅ SegFormer 推理完成,输出尺寸: {pred.shape}")三、通用IoU/mIoU精度评估工具(分割通用)
适配以上所有分割模型,自动计算单类别IoU与全局mIoU,论文/项目精度统计专用:
python
import numpy as np
import torch
def seg_metric(pred_mask: torch.Tensor, gt_mask: torch.Tensor, num_classes: int):
"""
语义分割 IoU / mIoU 计算
:param pred_mask: 模型预测掩码 (B, H, W)
:param gt_mask: 真值标签掩码 (B, H, W)
:param num_classes: 分割总类别数
:return: mIoU, 每一类IoU列表
"""
iou_list = []
for cls in range(num_classes):
pred = (pred_mask == cls).float()
gt = (gt_mask == cls).float()
intersection = torch.sum(pred * gt)
union = torch.sum(pred) + torch.sum(gt) - intersection
iou = intersection / (union + 1e-6)
iou_list.append(iou.item())
mIoU = np.mean(iou_list)
return mIoU, iou_list
# 测试调用
if __name__ == "__main__":
# 模拟预测与标签
pred = torch.randint(0, 4, (1, 512, 512))
gt = torch.randint(0, 4, (1, 512, 512))
miou, cls_iou = seg_metric(pred, gt, 4)
print(f"全局mIoU: {miou:.4f}")
print(f"各类别IoU: {cls_iou}")📌 下期预告
遥感模型轻量化与部署实战:模型剪枝、量化、ONNX转换、端侧部署全流程,让高精度分割模型在普通电脑、嵌入式设备上高效运行。