论文:DBCopilot: Scaling Natural Language Querying to Massive Databases
⭐⭐⭐⭐
Code: DBCopilot | GitHub
一、论文速读
论文认为目前的 Text2SQL 研究大多只关注具有少量 table 的单个数据库上的查询,但在面对大规模数据库和数据仓库的查询时时却力显不足。本文提出的 DBCopilot 能够在大规模数据库上查询模式不可知的 NL question。
论文指出,实现这个的核心是:从能够构建各种 NL question 到海量数据库模型元素的 semantic mapping,从而能够自动识别目标数据库并过滤出最少的相关 tables。但目前的基于 LLM 的方法有两个主要挑战:
- 由于 token 限制,无法将所有 schema 都输入给 LLM
- LLM 仍然难以有效利用长上下文中的信息
而在解决可扩展性的问题时,主要有基于 retrieval 的方法和基于 fine-tune 的方法,但是,
- 基于 retrieval 的方法往往是将 doc 视为检索对象,忽略了 DB 和 DB table 之间的关系;
- fine-tune LLM 来为其注入 schema 的相关知识是资源密集型的方式,且有时候 LLM 是无法微调的
DBCopilot 的做法如下图所示:

主要分成两步:
- Schema Routing:输入 user question,使用 DSI 技术找到所需要用的 DB 和 DB tables,也就是 DB schema。
- SQL Generation:输入 user question、DB schema,通过 prompt LLM 生成 SQL query。
二、问题定义
2.1 Schema-Agnostic NL2SQL
Schema-Agnostic NL2SQL 指的是:只给定 user question 而不给定预期的 SQL query schema(DB 和 DB tables),来生成一个可以在一个数据库集合中的某个 DB 上执行的 SQL。
像之前 WikiSQL 数据集上,都是指定 question 在哪个 DB 上的。
2.2 Schema Linking VS. Schema Routing
在以往的 NL2SQL 中,Schema Linking 的 input 是 question 和 schema,用于寻找 NL question 中提及到的 schema 元素(比如 tables、columns 或者 database value),可以被视作是一个 NL question 和 DB elements 之间的桥梁。
Schema Routing 的 input 只有不知道 schema 的 question,它的输出是一个 indexed or memorized schema。
三、方法
3.1 Schema Routing
本文使用一个轻量级的 seq2seq 模型来作为 router,实现将 NL 识别出对应的 DB schema。
由于 space schema 很大(是 table 和 column 的笛卡尔积)、且 DB schema 可以发生变化,因此本文提出了一个 relation-aware、end-to-end joint retrieval 方法来解决 schema routing 问题。
具体做法是,先为 databases 构建一个 schema graph,然后设计一个 schema 序列化算法来将一个 schema 转化为 token-sequence,利用 graph-based contrained decoding 解码算法来让 seq2seq 模型生成 routing 的结果 DB schema。
3.1.1 Schema Graph
schema graph 包含了 databases 的 schema 信息,这个 graph 的 nodes 包含三类:
- v s v_s vs:一个特殊节点,指代含有所有 databases 的集合
- database
- DB table
graph 的 edge 包含两类:
- Inclusion relation:表示一个 db 是否是一个 db collection 的一部分;或者一个 table 是否属于一个 db
- Table relation:包含显式的 PRIMARY-FOREIGN 关系和隐式的 FOREIGN-FOREIGN 关系
隐式的 FOREIGN-FOREIGN 关系指的是:A 表和 B 表的某个 column 共同连接到另一个 C 表的 key
由此,任何有效的 SQL query schema 都是这个 schema graph 上的一个 trail(或者叫一个 path)。
3.1.2 Schema Serialization
这个序列化算法将一个 SQL query schema 序列化为一个 token seq,当然也可以将一个 token seq 解码出一个 DB schema。
具体的做法可以参考原论文,这里主要是基于 DFS(深度优先遍历)的思想。
有了这个序列化算法,当我们训练 seq2seq 的 schema router 模型时,由于需要监督它的 training data 是 (NL question, DB schema) pair,其中的 DB schema 就是序列化了的 schema。另外,router 的输出是一个 token seq,也需要反序列化将其转为结构化的 DB schema。
3.1.3 graph-based 的解码算法
在让 schema router 生成 token seq 时,为保证其生成的 schema 的有效性,每一个自回归生成的 step 中,都受到一个动态前缀树的约束,这个 tree 包含了解码后 schema 元素的可能访问节点的名称,如下图所示:
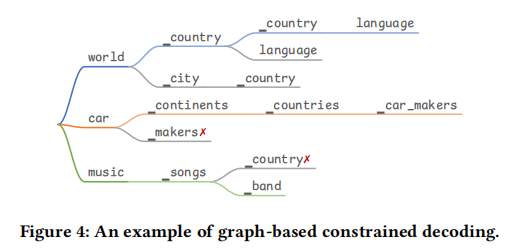
这样,每个生成 step 的可用 tokens 都可以通过搜索前缀树来获得,前缀就是在最后一个元素分隔符之后生成的 token。同时这里使用 diverse beam search 来生成多个候选序列。
3.1.4 schema router 的训练和推理
我们需要使用 (NL question, DB schema) 这样的 pairs 来作为 training data 来训练 router,但是目前缺少这样的训练资料。所以,本文提出了使用一个训练数据合成方法来生成 question-schema pairs。
这个训练数据合成方法具体来说就是:茨贝格 schema graph 中采样出一批合法的 schema,然后对每一个 schem 生成一个 pseudo-question,如下图所示:

具体的这个模型的训练可以参考原论文。
由此就可以得到用于训练 schema router 的 question-schema pairs。
之后,我们就可以训练 Schema Router 了。训练数据集是 { ( N i , S i ) } \{(N_i, S_i)\} {(Ni,Si)},也就是 quetsion-schema pairs,模型的训练损失函数如下:
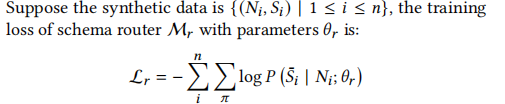
训练出来之后,就可以使用 graph-based 的解码算法来做推理了。
3.2 SQL Generation
通过将 NL2SQL 任务解耦为 schema routing 和 SQL generation 两个部分,DB Copilot 可以与现在的 LLM-advanced NL2SQL 的解决方案进行融合,无论是 in-context prompt engineering 方法或者特定的 NL2SQL LLM。
前面的 schema router 可以为 NL 生成来自多个 db 的多个 schemas,这里探索了 3 种 prompt 策略来为 LLM 选择和合并这些不同的 DB schema:
- Best Schema Prompting :从 schema router 种选择生成的最高概率的 schema 来 instruct LLM
- 实验发现这种方式是最优的
- Multiple Schema Prompting:将 beam search 得到的多个 table schemas 简单连接起来一起用来 instruct LLM。
- Multiple Schema COT Prompting:使用多个 candidate schemas 通过 COT 来 instruct LLM
四、实验
论文在 Spider、Bird、Fiben 数据集上对 schema retrieval 和 NL2SQL 两个任务上进行实验对比,DBCopilot 有不错的表现。
这里 NL2SQL 任务并没有与其他 SOTA 模型做实验对比
五、总结
本文提出了 DBCopilot 模型,给出了一种将 NL 查询扩展到大规模数据库的思路,通过 LLM 协作来解决模式无关的 NL2SQL 任务。
总之,DBCopilot 突破了 NL2SQL 的界限,使得研究人员能够更好地执行数据可访问性的策略。