14、开窗(开列)函数
官网链接:Window Functions - Apache AsterixDB - Apache Software Foundation
14.1 基础使用
开窗函数格式: 开窗函数 over(partition by 分组字段名 [order by 排序字段名 asc|desc] [rows between 开窗开始 and 开窗结束])
partition by: 按照谁进行分组
order by: 对分组后的数据进行排序
rows between and: 限定窗口统计数据范围
开窗函数分类:
第一类: 编号相关。
row_number(): 123456。不管数据有没有重复,单调递增往后进行编号
rank(): 123446。如果遇到相同数据,那么会重复编号,并且会占用后续的编号
dense_rank(): 123445。如果遇到相同数据,那么会重复编号,但是不会占用后续的编号
第二类: 聚合函数。count()、sum()、avg()、max()、min()....
第三类: 取值函数。ntile()、lag()、lead()、first_value()、last_value()示例:
use day09;
-- 创建表
create table pv_tb(
cookieid string,
datestr string,
pv int
)row format delimited fields terminated by ',';
-- 导入数据
load data inpath '/dir/website_pv_info.txt' into table pv_tb;
-- 验证数据
select * from pv_tb;
-- 编号相关的窗口函数
select
cookieid,
datestr,
pv,
-- row_number:用的最多。单调递增的进行编号,不管重复数据
row_number() over(partition by cookieid order by pv asc) as rs1,
-- rank:单调递增的进行编号,如果遇到重复数据,编号是相同,同时会占用后面的编号资格
rank() over(partition by cookieid order by pv asc) as rs2,
-- dense_rank:单调递增的进行编号,如果遇到重复数据,编号是相同,同时不会占用后面的编号资格
dense_rank() over(partition by cookieid order by pv asc) as rs3
from pv_tb;
select
cookieid,
datestr,
pv,
row_number() over(partition by cookieid order by pv asc) as rn,
-- 如果有order by那么窗口的大小是慢慢逐渐放大的
sum(pv) over(partition by cookieid order by pv asc) as sum_result,
-- 如果没有order by那么窗口的大小直接彻底放大到最大
sum(pv) over(partition by cookieid) as sum_result2
from pv_tb;窗口的运行原理:

针对sum(pv) over(partition by cookieid order by pv asc) as sum_result语句

14.2 控制数据范围
开窗函数控制范围: rows between 范围开始 and 范围结束
具体的语法含义:
1- 范围开始
unbounded preceding: 从窗口开始
数字 preceding: 前几行数据
2- 范围结束
unbounded following: 到窗口结束
数字 following: 后几行数据
3- 特殊的,既能够作为范围开始,也能够作为范围结束
current row: 当前行示例:
-- 控制窗口统计的数据范围
select
cookieid,
datestr,
pv,
sum(pv) over(partition by cookieid order by pv rows between unbounded preceding and current row) as rs1,
sum(pv) over(partition by cookieid order by pv rows between 2 preceding and current row) as rs2,
sum(pv) over(partition by cookieid order by pv rows between unbounded preceding and unbounded following) as rs3,
sum(pv) over(partition by cookieid order by pv rows between 2 preceding and unbounded following) as rs4,
sum(pv) over(partition by cookieid order by pv rows between 2 preceding and 2 following) as rs5,
sum(pv) over(partition by cookieid order by pv rows between current row and unbounded following) as rs6
from pv_tb;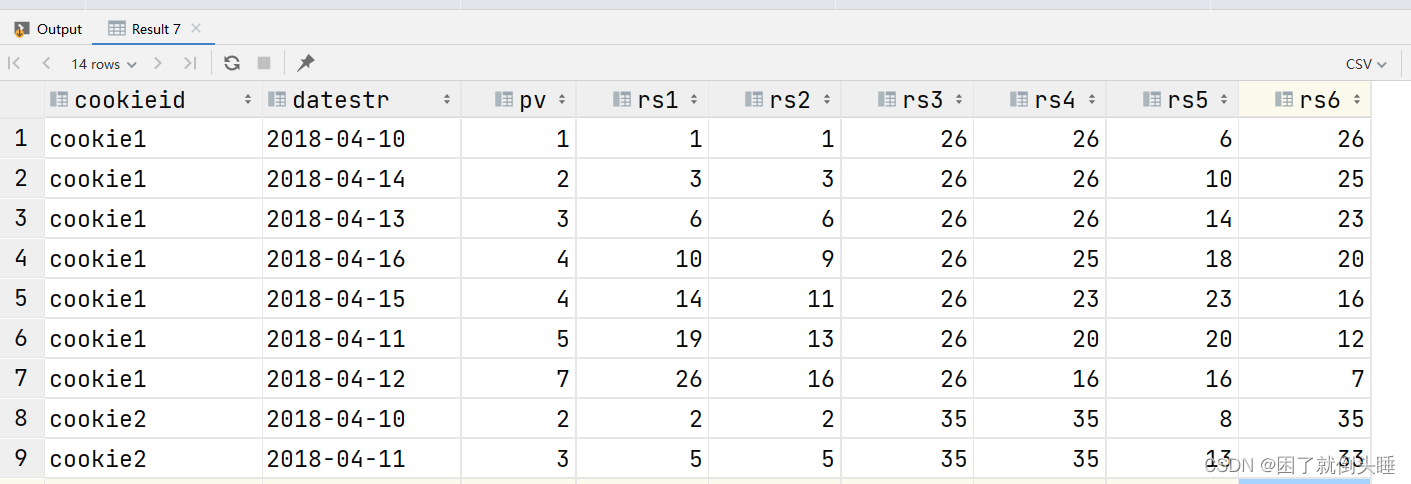
14.3 其他开窗函数
ntile(n): 将窗口内的数据分配到n个桶里面去,返回的结果是桶的编号。可以使用在数据抽样中
lag: 取窗口中上一行的数据
lead: 取窗口中下一行的数据
first_value: 取窗口中第一行的数据
last_value : 取窗口中最后一行的数据示例:
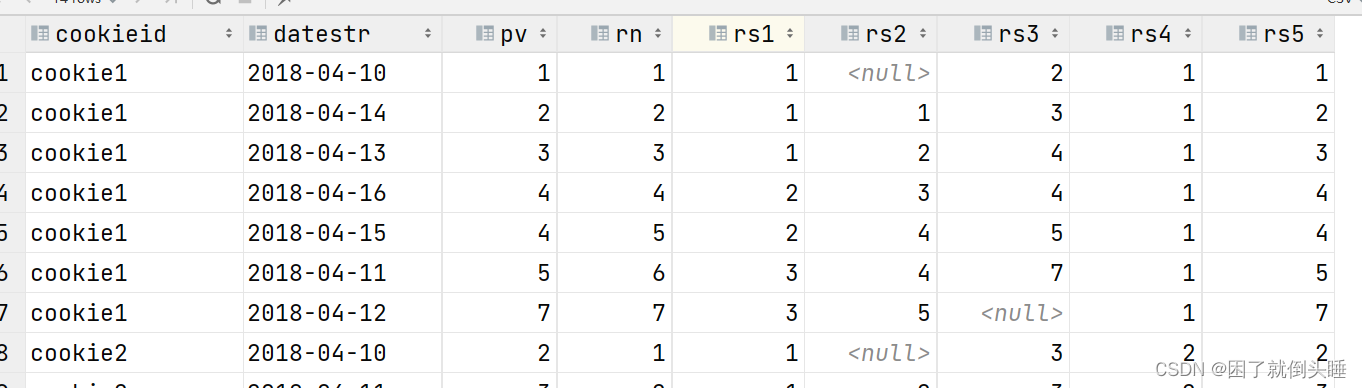
-- 其他函数
select
cookieid,
datestr,
pv,
row_number() over(partition by cookieid order by pv asc) as rn,
-- ntile(n):将窗口内的数据分配到n个桶里面去,返回的结果是桶的编号
ntile(3) over(partition by cookieid order by pv asc) as rs1,
-- 取窗口中上一行的数据
lag(pv) over(partition by cookieid order by pv asc) as rs2,
-- 取窗口中下一行的数据
lead(pv) over(partition by cookieid order by pv asc) as rs3,
-- 取窗口中第一行的数据
first_value(pv) over(partition by cookieid order by pv asc) as rs4,
-- 取窗口中最后一行的数据
last_value(pv) over(partition by cookieid order by pv asc) as rs5
from pv_tb;