在hive中执行如下sql
INSERT OVERWRITE TABLE XXX
SELECT * from XXX
数据最终是怎么存储到hdfs上的过程
执行的过程当中,打印出
如下的日志过程,本质上是一个在MapReduce中进行Shuffle的过程
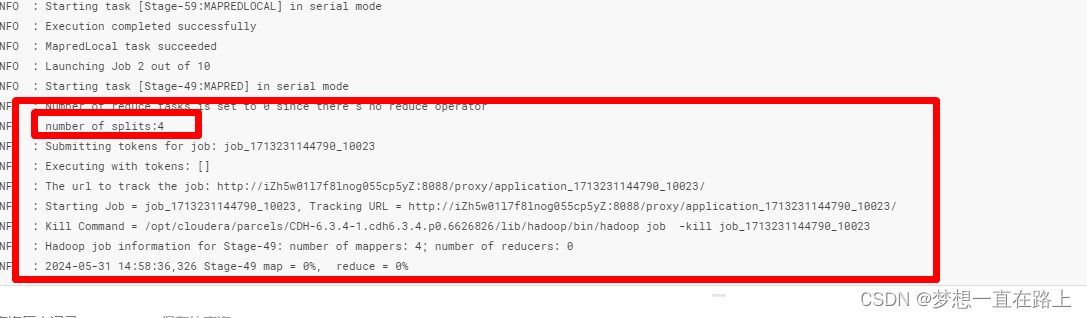
所以下面就Shuffle的过程进行分析
Shuffle 描述的是数据从 Map 端到 Reduce 端的过程,大致分为排序(sort)、溢写(spill)、合并(merge)、拉取拷贝(Copy)、合并排序(merge sort)这几个过程,大体流程如下:
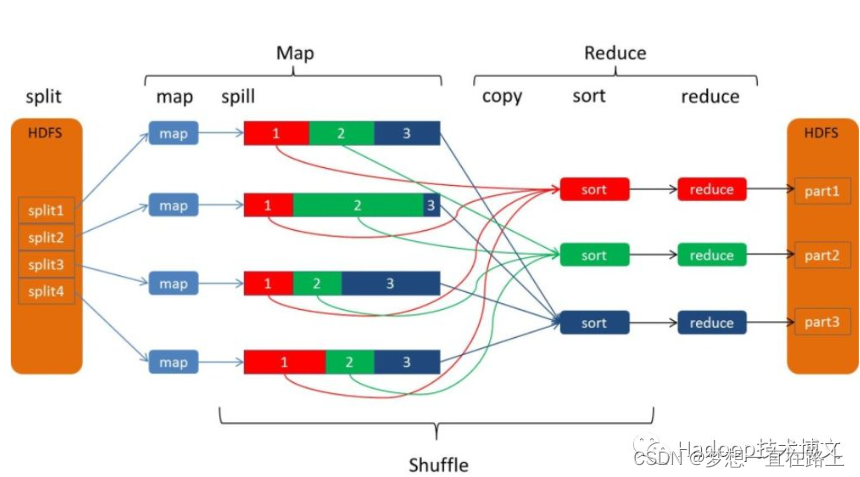
上图的 Map 的输出的文件被分片为红绿蓝三个分片,这个分片的就是根据 Key 为条件来分片的,分片算法可以自己实现,例如 Hash、Range 等,最终 Reduce 任务只拉取对应颜色的数据来进行处理,就实现把相同的 Key 拉取到相同的 Reduce 节点处理的功能。下面分开来说 Shuffle 的的各个过程。
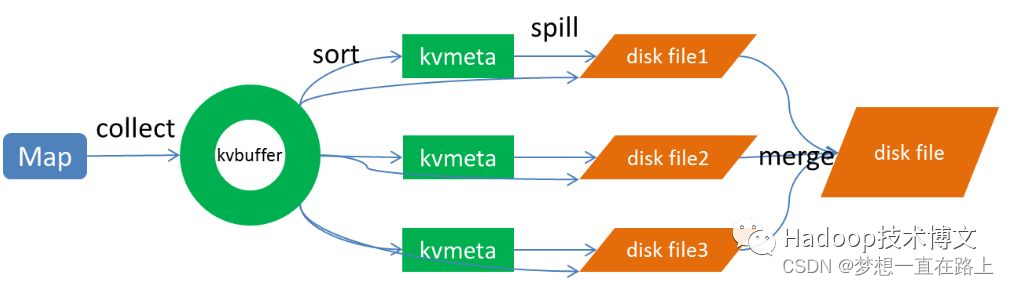
注意:
sqoop import实际上是把数据存放到hdfs对应路径上了,而不是"直接导入表里",
查询时,hive会从hdfs的路径上提取数据,再根据hive表的结构和定义,来向我们展示出类似表格的形式。
