文章目录
- 前言
- 一、ResNet
- 二、ResNeXt
- 三、Res2Net
- 四、SeNet
- 五、ResNeSt
- 六、DenseNet
- 七、CSPNet
- [Pytorch Model Code](#Pytorch Model Code)
- 总结
前言
Backbone作为一切深度学习任务的基础,不论是理论还是实际应用都有重要的意义,本文针对经典Backbone进行总结,这些Backbone也是面试常见的问题,卷积网络主要以ResNet和其各种变体为主。
一、ResNet
paper:Deep Residual Learning for Image Recognition
网络结构:
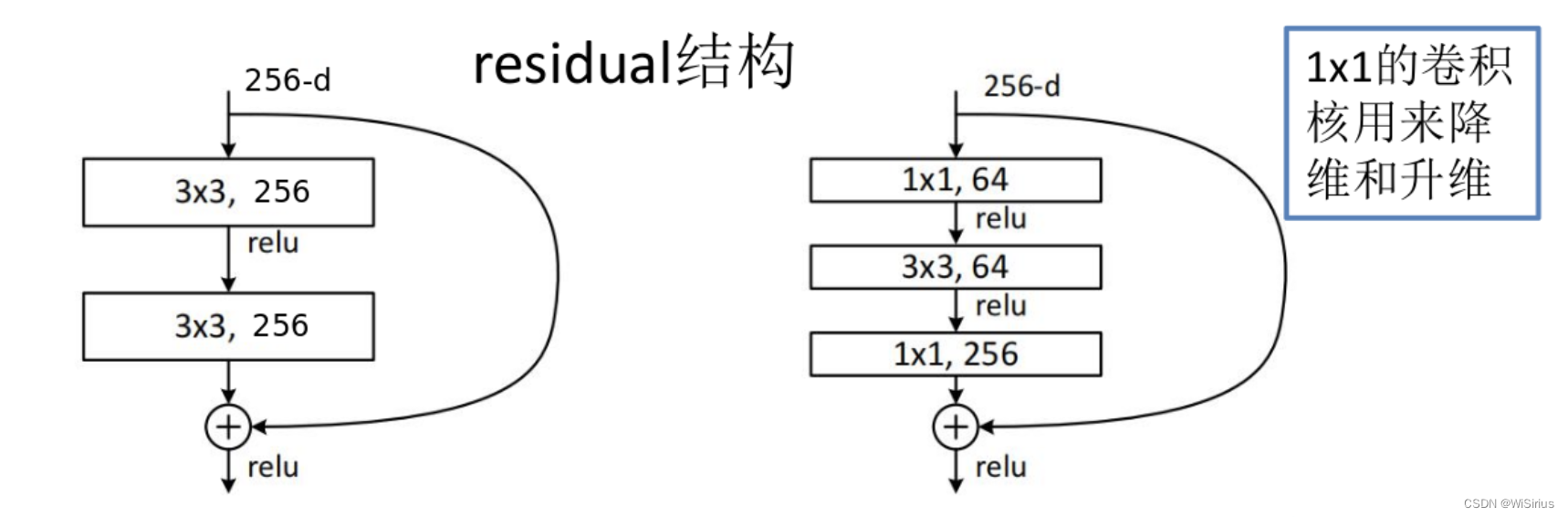
Tips:
- 针对问题:残差神经网络针对网络退化现象(随着网络加深,准确率降低,引入的激活越来越多,到后来学习恒等变换都很难)提出解决方法,在线性和非线性寻找平衡。
2)残差的作用:缓解梯度消失。梯度能无损的回传到网络的各个层,有效抑制梯度消失的现象 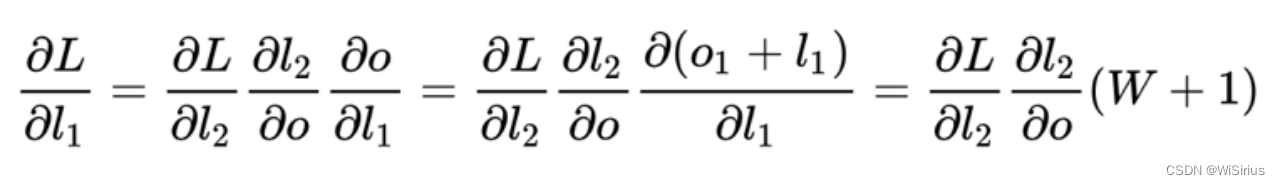
梯度不衰减的传递回去,避免梯度消失(常规网络是梯度累乘)
二、ResNeXt
paper:Aggregated Residual Transformations for Deep Neural Networks
相比ResNet对残差块进行了改进,将中间卷积改成了分组卷积 ,通道数改变了,基本结构和Inceptionv4类似,不过Inceptionv4的并行分支是通道连接然后进行1x1conv。ResNetXt是每个分支末尾进行1x1卷积通道相同,然后相加,在残差相加。另外ResNeXt使用了一种等效合并的方式(将多分支合并为一个分组卷积)
网络结构 :
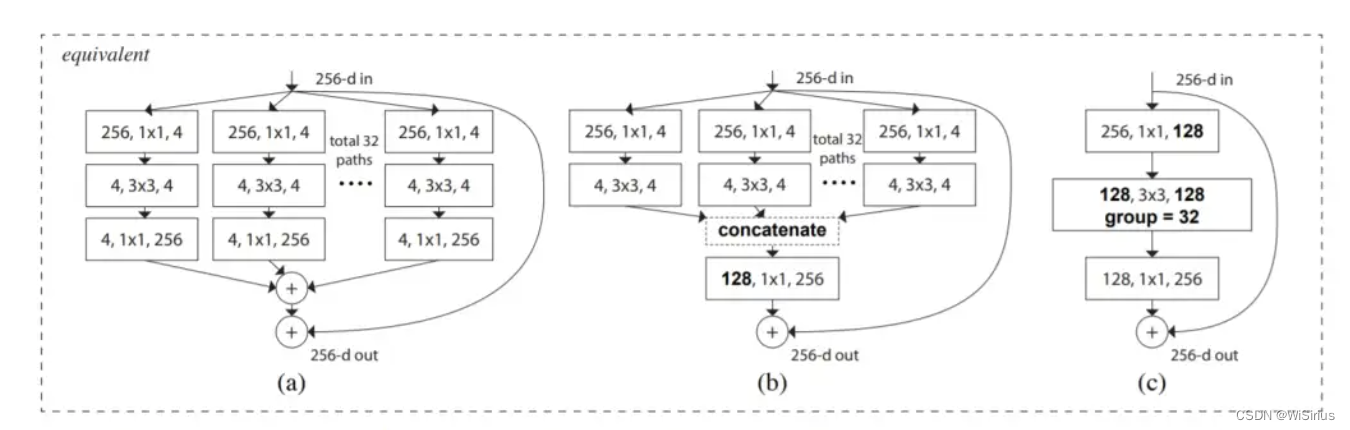
Tips :典型的并行卷积获取多角度特征,网络也更轻量了一些
三、Res2Net
paper:Res2Net: A New Multi-scale Backbone Architecture
网络结构 :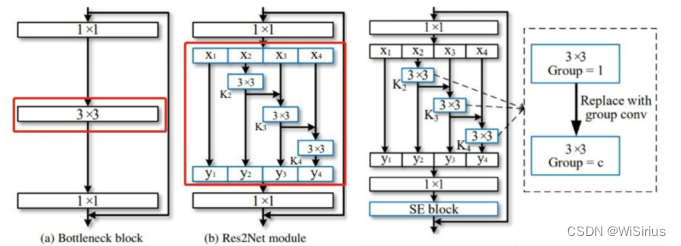
将残差块1x1输出特征拆分4个部分(其实也是分组),分4个分支,1分支直连,2分支经过3x3卷积然后一个直连,一个给融合下一条分支,达到一个多尺度融合的目的。
Tips :在单个残差块内构造具有等级制的类似残差连接。Res2Net在粒度级别表示多尺度特征,并增加了每个网络层的感受野。
四、SeNet
paper:Squeeze-and-Excitation Networks
网络结构 :
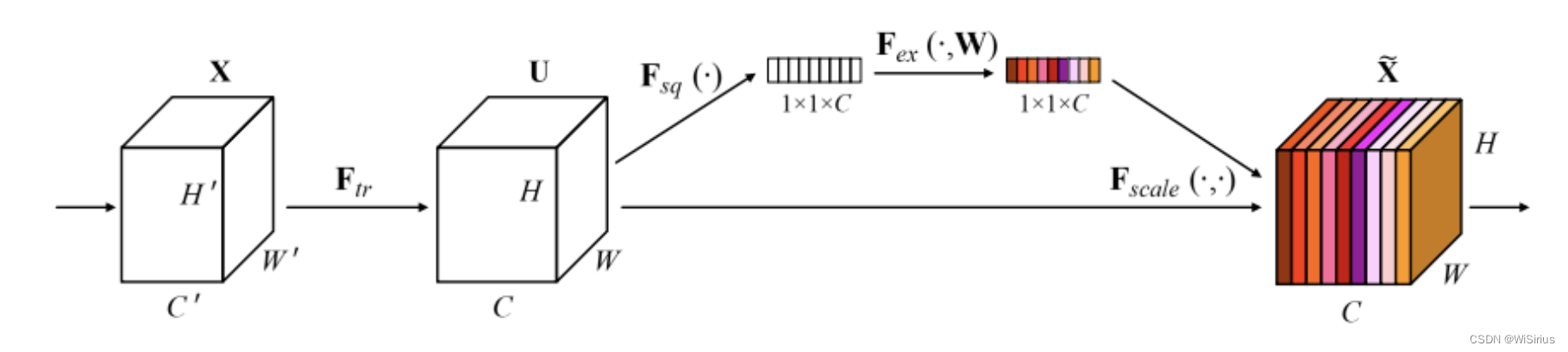
SENet虽然不算是一个经典的backbone,但是其思想影响了后续很多backbone的设计。SENet首次**将通道注意力概念引入深度网络,让卷积网络有了全局信息的感知能力。通过挤压操作提取网络中的空间信息,激励操作则根据这些信息调整网络中的通道权重。**这种网络结构能够有效地提高网络的表现,尤其是在处理图像分类等任务时。挤压和激励网络可以与现有的最先进的CNN结合使用,以实现更高的性能提升。
目前先进的卷积网络中的模块都基于这个思想,如经典的CBAM模块。
Tips:在transformer使用之前让CNN免除了局部感受野的限制,能够捕获一定全局信息,并根据这些信息对特征作出调整。
五、ResNeSt
paper:ResNeSt : Split-Attention Networks
网络结构 :
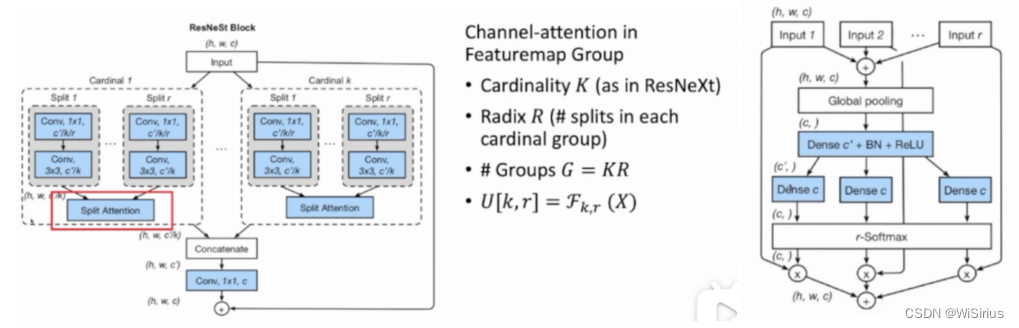
将输入分成K个cardinal,每个cardinal分成R个组,故特征共被分成了K*R个组。每个cardinal执行split attention。split attention是分开的SE模块,每小组(split)特征会根据大组(cardinal)特征生成一个对应的向量,乘上原来的特征,然后再相加。
实际情况,网络同样采样类似ResNeSt的情况进行模块合并(分组卷积+SE+残差)。
其设计类似ResNeXt,只不过加了一个SE模块
六、DenseNet
paper: Densely Connected Convolutional Networks
网络结构 :

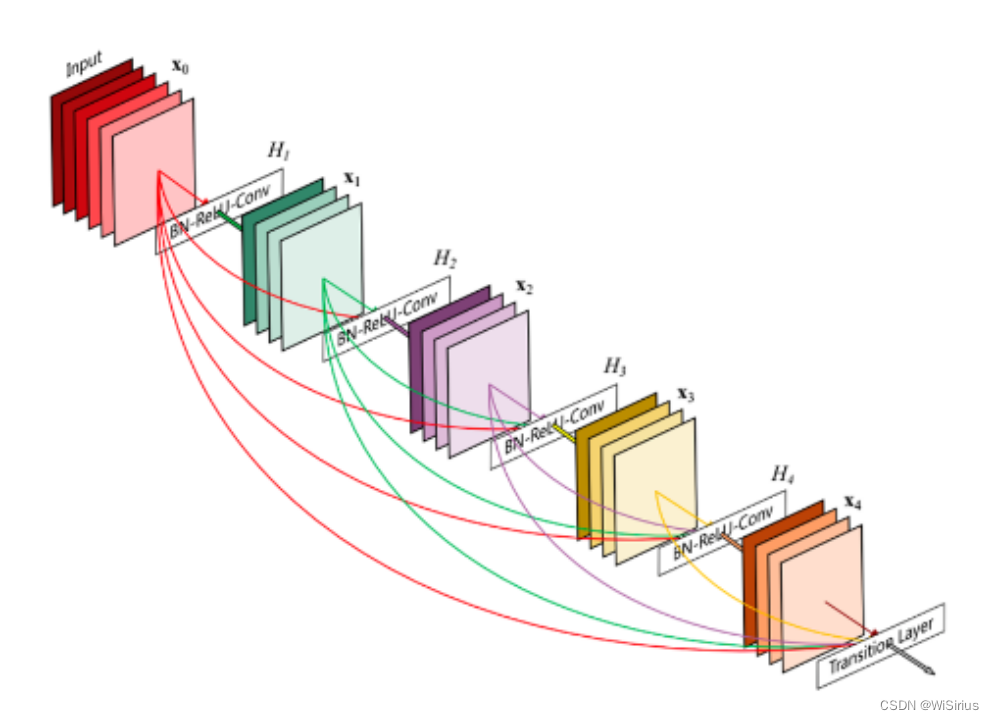
DenseNet是在ResNet后的又一个基础backbone,其连接架构类似ResNet,但把残差结构的相加换成了cat,继续传播。并且它的连接是前面所有层的连接,第3层的输入是原特征和第1层 第2层的输出。
上图是一个DenseBlock,另外还有一个Transition模块,用于降维 。
简单说下DenseNet的反向传播------
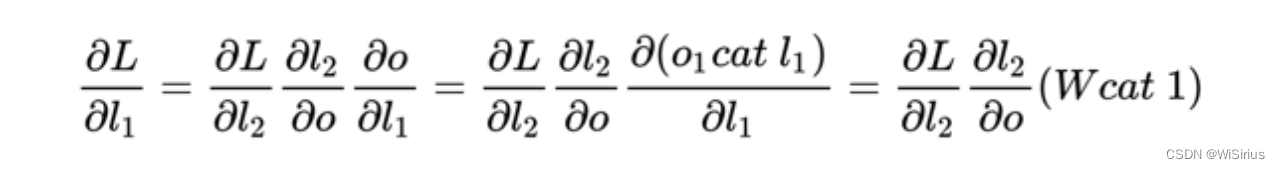
Tips :DenseNet的出发点在于通过不断的连接前面的层来恢复崩溃信息。
七、CSPNet
paper:CSPNet: A New Backbone that can Enhance Learning Capability of CNN
网络结构 :
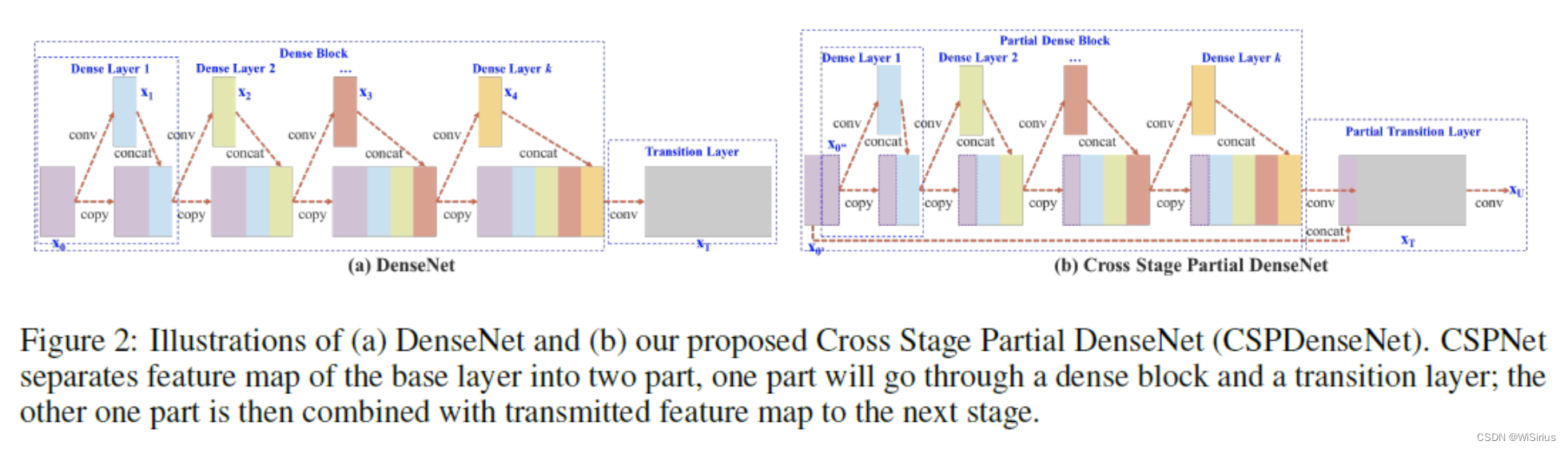
了解yolo的同学们相信对CSPNet都不陌生,CSP的设计主要针对DenseNet。其围绕的中心思想是网络优化中的重复梯度信息,以此来优化之前网络中所需要的大量推理计算问题。
传统的DenseNet如上图(a)所示,CSPDenseNet如上图(b)所示。简单来看,CSPDenseNet就是将输入的feature map按照channel分成了两个部分,其中一个部分正常进行Dense Block的操作,另一个部分直接进行Concat操作。由于每个Dense Block操作的输入通道都变少了(第一个直接减少,后面Concat的通道数变少),所以能减少计算量。

进行Concat的方式,有上图几种。图(c)的方式,会让大量的梯度信息被重复利用,有利于学习;下图(d)的方式,梯度流被阻断,不能复用梯度信息。但由于Transition层的输入通道比 (c)要少,因此能大大减少计算复杂度。本文采用的( b )就是结合了(c)和(d)的优点。
Tips :
1)避免梯度信息复用,更丰富的梯度组合强化了CNN的学习能力;
2)降低计算成本,减少内存占用;
Pytorch Model Code
目前我将这些模型的基本架构整理了一下,大部分是从原作者的架构中拆出和从其它作者中找到的(感谢各路大神),经过测试均没有问题,后续将会整理更多模型架构,一起进步!!!
github :https://github.com/sirius541/pytorch_model_collection
总结
本文主要介绍这些年比较经典的backbone的一些优势和特点,目前主流的backbone都以transformer为框架进行迭代,不过CNN的backbone是基础中的基础,能很好的帮助初学者理解相关理论和设计理念,也是必须要掌握的技术。