前言
近年来,大语言模型 (LLM) 已经成为人工智能领域最热门的研究方向之一,并在各种任务中展现出前所未有的性能。然而,由于商业利益的驱动,许多最具竞争力的模型,例如 GPT、Gemini 和 Claude,其训练细节和数据来源往往被隐藏在专有接口背后。这限制了学术界对 LLM 的深入研究和应用。
为了解决这一问题,研究团队开源了 MAP-Neo,一个高性能、透明的双语大语言模型,旨在推动 LLM 研究的民主化。MAP-Neo 拥有 70 亿参数,从头开始训练,并使用了 4.5T 经过精心清洗和筛选的高质量 token。
-
Huggingface模型下载: https://huggingface.co/m-a-p/neo_7b
-
AI 快站模型免费加速下载: https://aifasthub.com/models/ m-a-p
技术特点
MAP-Neo 的透明性和高性能源于其独特的设计和训练策略:
- 全流程透明: 与现有许多开源 LLM 不同,MAP-Neo 秉持着完全透明的理念,不仅公开了模型权重,还提供了完整的训练代码、预训练数据以及数据清洗流程,方便研究人员复现和验证模型。
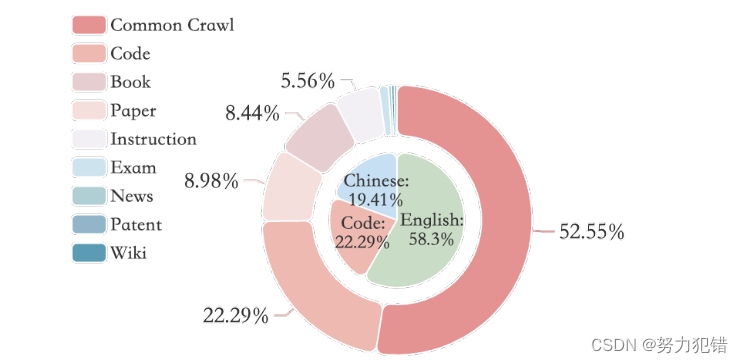
- 高质量数据训练: MAP-Neo 使用了名为 Matrix Data Pile 的预训练语料库,包含 4.5T 高质量 token,其中 52.55% 来自 Common Crawl,22.29% 来自编程代码,其余部分来自学术论文、书籍和其他印刷材料。研究团队针对不同的数据来源和内容类型,制定了相应的清洗和过滤策略,以确保数据的质量和多样性。
-
高效的训练架构: MAP-Neo 在 Megatron-LM 框架的基础上进行了改进,增强了其对大型数据集训练的支持,并引入了 NEO Scaling Law,用于优化使用来自不同语料库的预训练数据集来扩展 LLM。
-
精心设计的模型架构: MAP-Neo 采用 Transformer 解码器架构,并整合了 RoPE Embeddings、RMSNorm 以及 SwiGLU 等技术,以提高模型的效率和性能。此外,MAP-Neo 还采用了多阶段的训练策略,包括基础阶段和衰减阶段。
性能表现
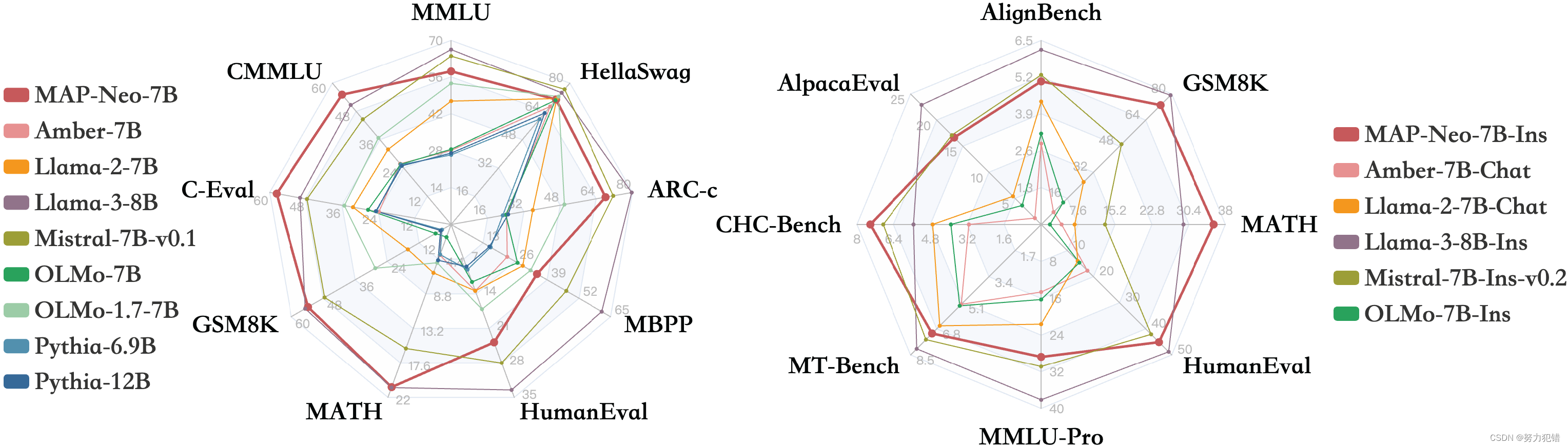
MAP-Neo 在多项任务中都展现出令人印象深刻的性能,超越了同等规模的其他开源 LLM,例如 LLaMA-3 和 Mistral-7B:
-
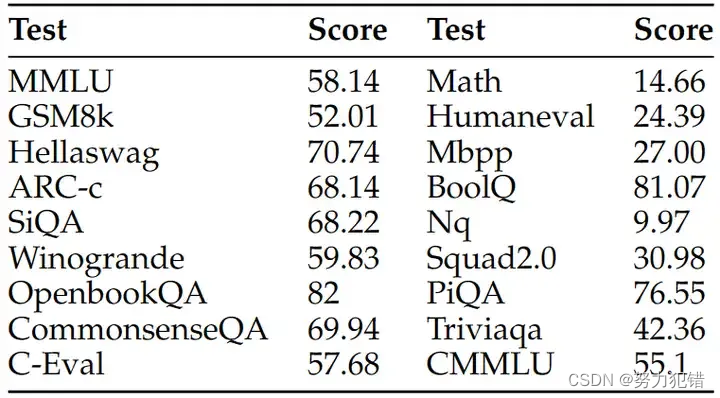
标准 基准测试 : MAP-Neo 在 BoolQ、PIQA、SIQA、HellaSwag、WinoGrande、ARC-Challenge、OpenBookQA-Fact、CommonsenseQA、MMLU、C-Eval 和 CMMLU 等标准基准测试中取得了优异成绩,展现出强大的语言理解和推理能力。
-
代码生成: MAP-Neo 在 HumanEval、HumanEval-Plus、MBPP 和 MBPP-Plus 等代码生成任务中也表现突出,展现出良好的代码生成和理解能力。
-
数学推理: MAP-Neo 在 GSM8K 和 MATH 等数学推理任务中取得了领先成绩,展现出强大的逻辑推理能力。
应用场景
MAP-Neo 作为一款全流程透明的双语大模型,具有广泛的应用场景:
-
学术研究: 为研究者提供一个可复现、可解释的平台,推动双语大模型技术的发展。
-
中文应用: 帮助解决中文LLM资源匮乏的问题,促进中文自然语言处理技术的进步。
-
商业应用: 帮助企业快速构建自己的中文和英文LLM应用,降低开发成本,提升效率。
总结
MAP-Neo 的开源和透明,不仅为双语大模型的研究和应用提供了宝贵的资源,也推动了AI技术的民主化进程。我们相信,MAP-Neo 将为LLM的发展和应用开辟新的道路,助力人工智能技术的进步和普及。
模型下载
Huggingface模型下载
https://huggingface.co/m-a-p/neo_7b
AI快站模型免费加速下载