自学python如何成为大佬(目录):自学python如何成为大佬(目录)_利用python语言智能手机的默认语言实战一-CSDN博客
在Python中打开文件后,除了可以向其写入或追加内容,还可以读取文件中的内容。读取文件内容主要分为以下几种情况:
1 读取指定字符
文件对象提供了read()方法读取指定个数的字符,语法格式如下:
file.read(size)
参数说明:
l file:为打开的文件对象。
l size:可选参数,用于指定要读取的字符个数,如果省略,则一次性读取所有内容。
注意:在调用read()方法读取文件内容的前提是在打开文件时,指定的打开模式为r(只读)或者r+(读写),否则,将抛出如图11所示的异常。

图11 没有读取权限时抛出的异常
例如,要读取message.txt文件中的前9个字符,可以使用下面的代码:
with open('message.txt','r') as file: # 打开文件
string = file.read(9) # 读取前9个字符
print(string)
如果message.txt的文件内容为:
你使用了1张加速卡,小鸡撸起袖子开始双手吃饲料,进食速度大大加快。
那么执行上面的代码将显示以下结果:
你使用了1张加速卡
使用read(size)方法读取文件时,是从文件的开头读取的。如果想要读取部分内容,可以先使用文件对象的seek()方法将文件的指针移动到新的位置,然后再应用read(size)方法读取。seek()方法的基本语法格式如下:
file.seek(offset,whence)
参数说明:
l file:表示已经打开的文件对象。
l offset:用于指定移动的字符个数,其具体位置与whence参数有关。
l whence:用于指定从什么位置开始计算。值为0表示从文件头开始计算,值为1表示从当前位置开始计算,值为2表示从文件尾开始计算,默认为0。
注意:对于whence参数,如果在打开文件时,没有使用b模式(即rb),那么只允许从文件头开始计算相对位置,从文件尾计算时就会抛出如图12所示的异常。
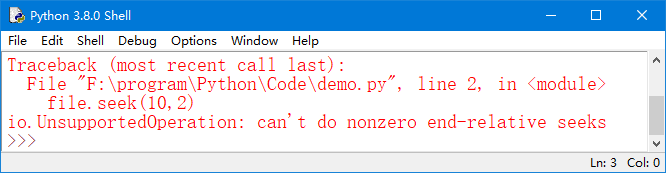
图12 抛出io.UnsupportedOperation异常
例如,想要从文件的第19个字符开始读取13个字符可以使用下面的代码:
with open('message.txt','r') as file: # 打开文件
file.seek(19) # 移动文件指针到新的位置
string = file.read(13) # 读取13个字符
print(string)
如果采用GBK编码的message.txt文件内容为:
你使用了1张加速卡,小鸡撸起袖子开始双手吃饲料,进食速度大大加快。
那么执行上面的代码将显示以下结果:
小鸡撸起袖子开始双手吃饲料
说明:在使用seek()方法时,如果采用GBK编码,那么offset的值是按一个汉字(包括中文标点符号)占两个字符计算,而采用UTF-8编码,则一个汉字占3个字符,不过无论采用何种编码英文和数字都是按一个字符计算的。这与read(size)方法不同。
场景模拟:在蚂蚁庄园的动态栏目中记录着庄园里的新鲜事。现在想显示庄园里的动态信息。

实例03 显示蚂蚁庄园的动态
在IDLE中创建一个名称为antmanor_message_r.py的文件,然后在该文件中,首先应用open()函数以只读方式打开一个文件,然后再调用read()方法读取全部动态信息,并输出,代码如下:
print("\n","="*25,"蚂蚁庄园动态","="*25,"\n")
with open('message.txt','r') as file: # 打开保存蚂蚁庄园动态信息的文件
message = file.read() # 读取全部动态信息
print(message) # 输出动态信息
print("\n","="*29,"over","="*29,"\n")
执行上面的代码,将显示如图13所示的结果。
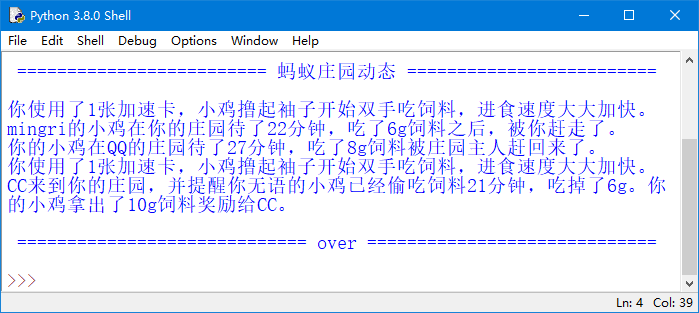
图13 显示蚂蚁庄园的全部动态
2 读取一行
在使用read()方法读取文件时,如果文件很大,一次读取全部内容到内存,容易造成内存不足,所以通常会采用逐行读取。文件对象提供了readline()方法用于每次读取一行数据。readline()方法的基本语法格式如下:
file.readline()
其中,file为打开的文件对象。同read()方法一样,打开文件时,也需要指定打开模式为r(只读)或者r+(读写)。
场景模拟:在蚂蚁庄园的动态栏目中记录着庄园里的新鲜事。现在想显示蚂蚁庄园里的动态信息。
实例04 逐行显示蚂蚁庄园的动态
在IDLE中创建一个名称为antmanor_message_rl.py的文件,然后在该文件中,首先应用open()函数以只读方式打开一个文件,然后应用while语句创建循环,在该循环中调用readline()方法读取一条动态信息并输出,另外还需要判断内容是否已经读取完毕,如果读取完毕应用break语句跳出循环,代码如下:
print("\n","="*35,"蚂蚁庄园动态","="*35,"\n")
with open('message.txt','r') as file: # 打开保存蚂蚁庄园动态信息的文件
number = 0 # 记录行号
while True:
number += 1
line = file.readline()
if line =='':
break # 跳出循环
print(number,line,end= "\n") # 输出一行内容
print("\n","="*39,"over","="*39,"\n")
执行上面的代码,将显示如图14所示的结果。
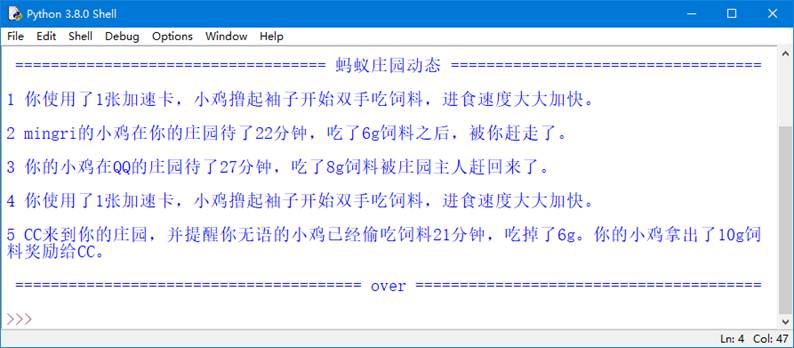
图14 逐行显示蚂蚁庄园的全部动态
3 读取全部行
读取全部行的作用同调用read()方法时不指定size类似,只不过读取全部行时,返回的是一个字符串列表,每个元素为文件的一行内容。读取全部行,使用的是文件对象的readlines()方法,其语法格式如下:
file.readlines()
其中,file为打开的文件对象。同read()方法一样,打开文件时,也需要指定打开模式为r(只读)或者r+(读写)。
例如,通过readlines()方法读取实例03中的message.txt文件,并输出读取结果,代码如下:
print("\n","="*25,"蚂蚁庄园动态","="*25,"\n")
with open('message.txt','r') as file: # 打开保存蚂蚁庄园动态信息的文件
message = file.readlines() # 读取全部动态信息
print(message) # 输出动态信息
print("\n","="*29,"over","="*29,"\n")
执行上面的代码,将显示如图15所示的运行结果。
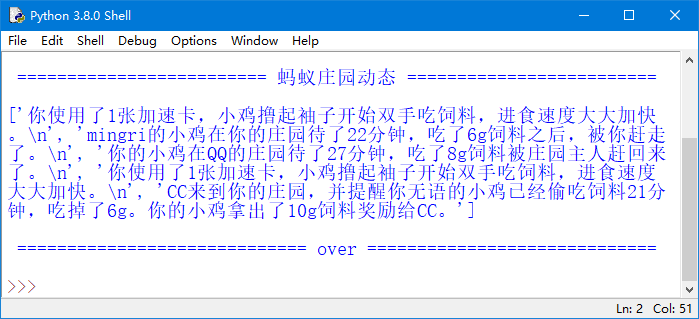
图15 readlines()方法的返回结果
从该运行结果中可以看出readlines()方法的返回值为一个字符串列表。在这个字符串列表中,每个元素记录一行内容。如果文件比较大时,采用这种方法输出读取的文件内容会很慢。这时可以将列表的内容逐行输出。例如,下面的代码可以修改为以下内容。
print("\n","="*25,"蚂蚁庄园动态","="*25,"\n")
with open('message.txt','r') as file: # 打开保存蚂蚁庄园动态信息的文件
messageall = file.readlines() # 读取全部动态信息
for message in messageall:
print(message) # 输出一条动态信息
print("\n","="*29,"over","="*29,"\n")
执行结果如图16所示。

图16 应用readlines()方法并逐行输出动态信息
