论文:PET-SQL: A Prompt-enhanced Two-stage Text-to-SQL Framework with Cross-consistency
⭐⭐⭐
arXiv:2403.09732,商汤 & 北大
Code:GitHub
一、论文速读
论文一开始提出了以往 prompt-based 的 Text2SQL 方法的一些缺点:
- 缺少对 table cell value 的先验关注。比如查询 sex 时,
WHERE sex='Male'、WHERE sex='M'都是有可能的,LLM 也拿不准用哪个 - 通过 prompt 让 LLM 做 schema linking 时,让 LLM 根据 question 和 schema 列出相关 schema 的效果并不好,因为像对于 CodeLlama 这样的模型来说,基于指令生成非代码文本并不是他们的强项
- 目前方法的 post-refinements 收益也不明显:
- 如果一个由强大的 LLM 生成的 SQL 具有语义模糊而不是语法错误的话,那 LLM 是无法 self-debugging 的
- 使用 self-consistency 时,LLM 的投资和产出是不成比例,多次调用一个 LLM 产生数倍的成本,并没有从根本上让 SQL 的输出更加多样化
由此,论文提出了 Prompt-Enhanced Two-stage text2SQL framework with cross-consistency(PET-SQL)------ 通过两个 stage 来完成任务。
二、PET-SQL
2.1 Stage 1:few-shots prompt 生成 PreSQL
这个阶段构造出一个 few-shots 的 prompt 用来输入给 LLM。
2.1.1 prompt 的表示风格
有多种指导 LLM 生成 SQL 的 prompt 表示风格。以往研究发现,Code Representation(CRp )和 OpenAI Demonstration(ODp)这两种是很不错的选择,示例如下图:

论文基于 ODp 进一步丰富了 prompt 的信息,提出了 Reference-Enchanced representation(REp)的 prompt,改动如下:
- 在 instruction 最后加了一句
You must minimize SQL execution time while ensuring correctness来指示 LLM 不仅要关注执行正确性,还要注意 SQL 语句的效率,避免冗余的字符和操作符。 - prompt 中增加 table cell value 示例,也就是随机选择数据库表的 3 rows
- prompt 中增加 schema 的外键关系
提出的 REp 示例如下:

2.1.2 增加 few-shots examples
这里从 dataset 中检索出与 user question 相似的样本来作为 ICL 的 demonstrations。
注意,这里要对被检索的 NL-SQL pairs 做去语义化 :也就是把 question 中与 table schema 相关的 tokens 用 <mask> 去掉,从而得到一个只呈现问题意图的 question skeleton。然后再对这些 question skeleton 使用 embedding 做语义嵌入,从而用于检索。
检索到的 top-K 被用作 demonstrations 用于 few-shots ICL。
这样,demonstrations 和前面的 REp prompt 结构,构成了用于输入给 LLM 的 prompt:

由此,可以得到一个 LLM 生成的 preliminary SQL(PreSQL)。
2.2 Stage 2:Schema Linking 与 FinSQL 生成
这里的实现基于一个简单的原则:PreSQL 与 question 高度相关。
因此,解析 PreSQL 以识别其中提到的 db tables 和 columns,并用于数据库的 schema linking。
然后 schema linking 的结果被用来简化 prompt 中的 schema 信息,去除掉无关的 table 和 column 信息,如下所示:
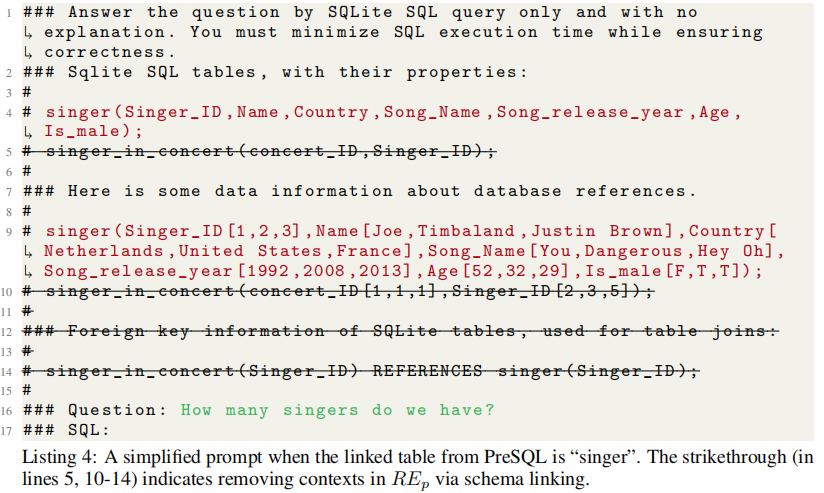
使用这个简化后的 prompt 用来生成 FinSQL。
2.3 Cross Consistency
以往做 Text2SQL 时往往会使用 self-consistency 来修正 SQL 结果,但这有一些问题:使用 self-consistency 往往是将 LLM 的问题调高使其生成多样化,然后多次生成后投票选出最终结果。但是研究也发现,高温下的 LLM 会增加幻觉、降低性能,且对于确定性任务(如生成 SQL),单个 LLM 的多样性也不足。
所以本文提出:在较低的温度下指导多个 LLMs 生成 SQL,然后在这些 SQL 的执行结果之间投票 。这也就是 Cross Consistency。
关于投票的思路,这里提出了两种:
- Naive voting:让每个 LLMs 都生成一个 SQL,执行后进行投票,将大多数结果作为最终答案
- Fine-grained voting:由于不同的 LLM 的能力不同,所能处理的问题的复杂度不同,因此,根据 PreSQL 的语法解析结果将 question 分为四个难度,然后不同的难度的问题由不同的候选 LLMs 来解决,并进行投票。这样可以最大限度发挥 LLM 的潜力,并显著减轻投票偏见。
三、实验
在 Spider 数据集上做了测试,使用 EX 作为评估,使用的 LLM 包括 CodeLlama、SQLCode、IternLM、SenseChat、GPT-4 等。
在 Spider 上的表现,在所有非基于学习的方法中实现了最高的 EX,比 DAIL-SQL 高出 1%。
具体的实现可以参考原论文。
四、总结
PET-SQL 的两阶段思路还是挺好理解上,prompt 设计上主要多了 db content 样例,整个过程中,使用 question de-semanticization 来提取问题骨架表示问题意图在实现上应该是整个流程里最复杂的。