
👦个人主页:Weraphael
✍🏻作者简介:目前正在学习c++和算法
✈️专栏:Linux
🐋 希望大家多多支持,咱一起进步!😁
如果文章有啥瑕疵,希望大佬指点一二
如果文章对你有帮助的话
欢迎 评论💬 点赞👍🏻 收藏 📂 加关注😍
目录
- 一、见见猪跑
- 二、命名管道的工作原理
- 三、系统调用接口mkfifo
- 四、命名管道和匿名管道的区别(特征)
- [五、 命名管道的四种情况](#五、 命名管道的四种情况)
- 六、代码
一、见见猪跑
上篇我们学习到的匿名管道主要用于血缘关系的进程之间进行通信 ,而命名管道则可以在毫不相关的进程之间进行通信。命名管道是基于文件系统的,因此在使用命名管道进行通信时,需要遵循一定的权限规则和文件路径约定(原理部分会说)。
在命令行上使用mkfifo即可创建命名管道:
bash
mkfifo <filename>mkfifo命令创建的命名管道在文件系统中显示为一种特殊的文件类型,通常以绿色文本显示,以便与普通文件区分开来。
创建命名管道后,进程可以像操作普通文件一样对其进行读取和写入操作。一个进程可以将数据写入管道,另一个进程可以从管道中读取数据。
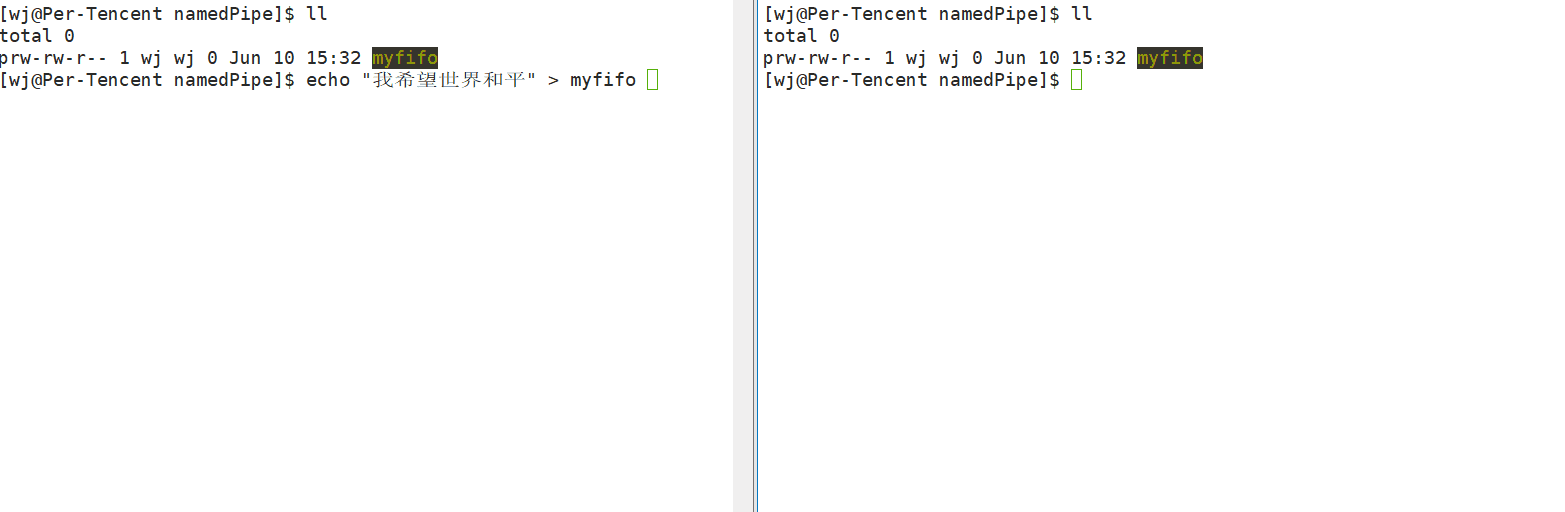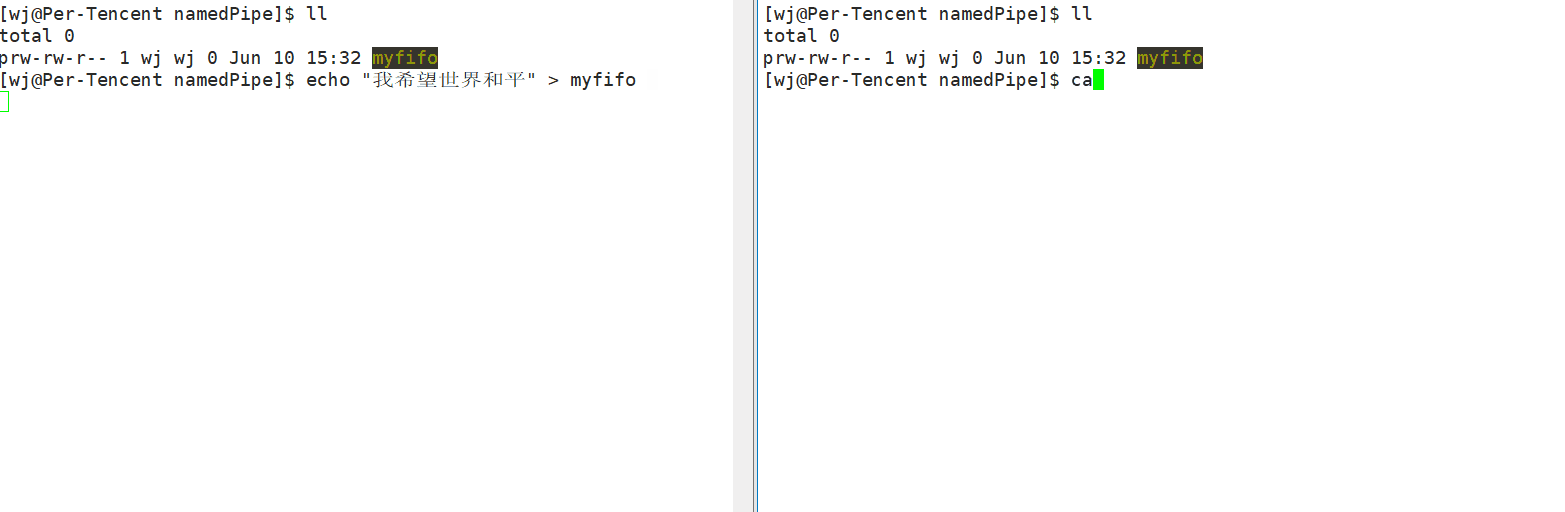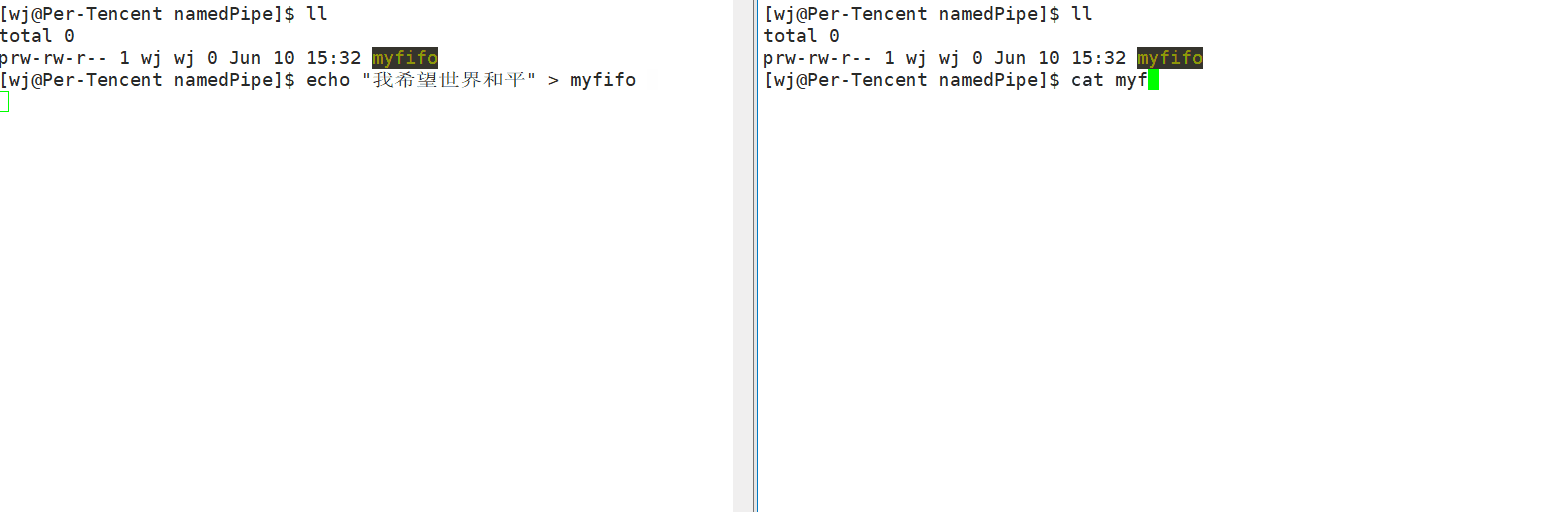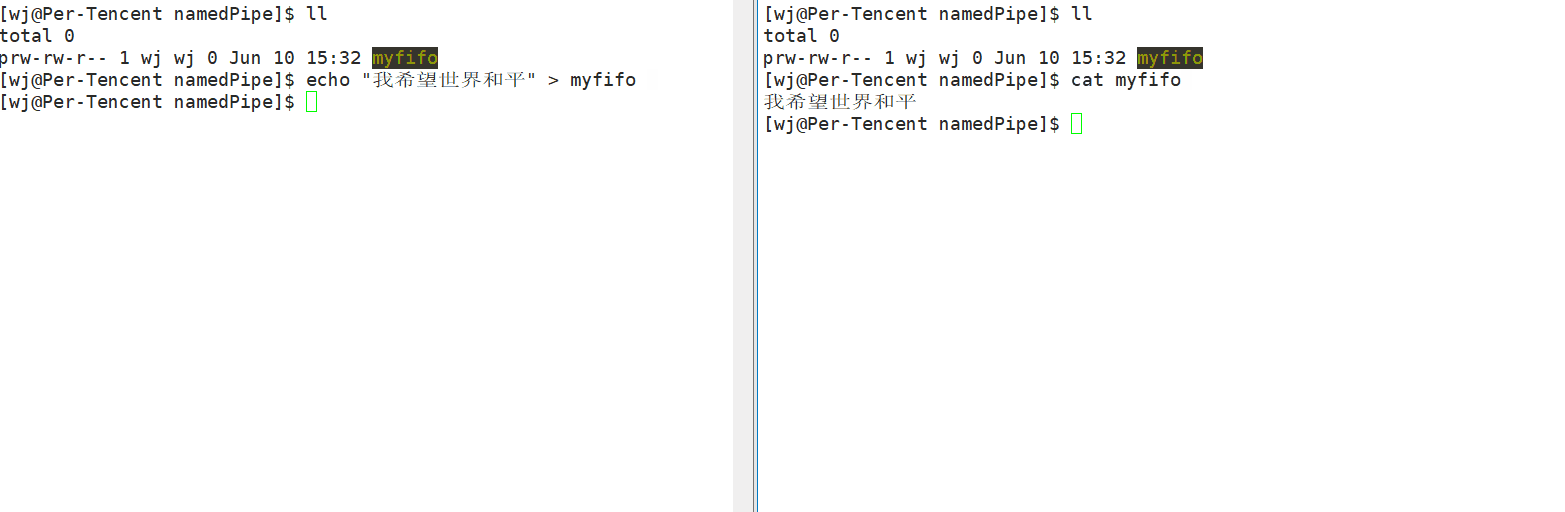
如上可以看到,左端的echo是一个进程,右端的cat也是一个进程,它们两是毫无相关的,而通过命名管道,可以让这两个毫无相关的进程通信。
但需要注意的是,如果没有任何进程打开了管道进行读取操作,那么写入操作将永远被阻塞,直到有进程打开管道进行读取操作为止。这种行为确保了在进程之间进行通信时的同步性,即写入数据的进程会等待读取数据的进程准备好后再继续执行,从而避免了数据丢失或混乱。
二、命名管道的工作原理
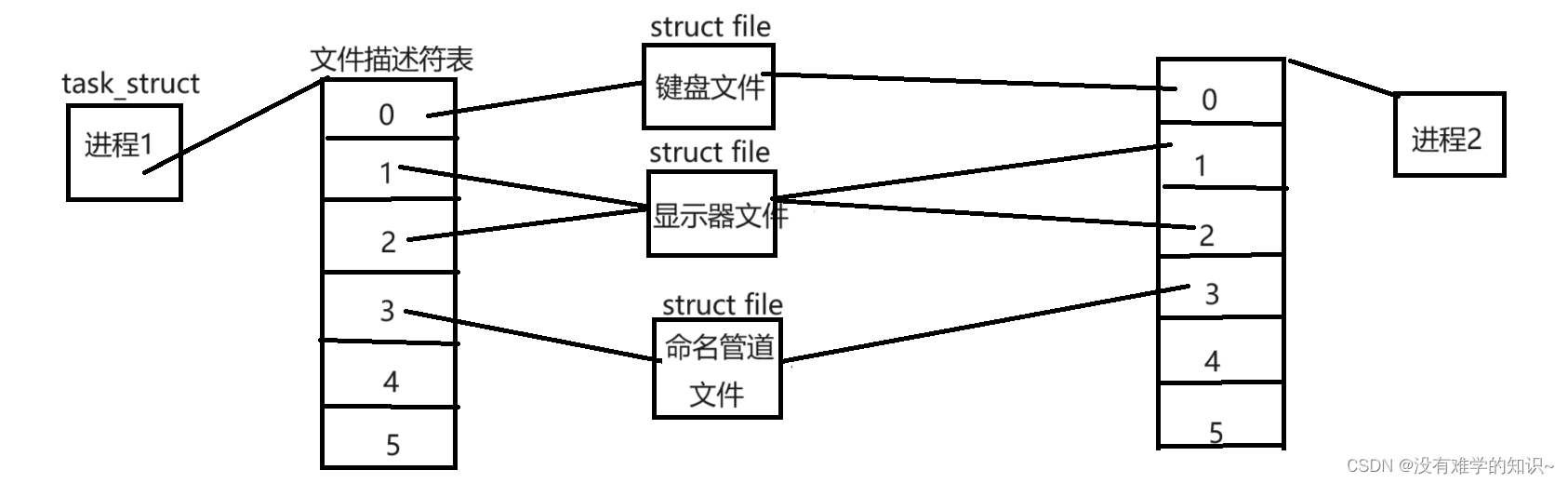
我们知道:当进程打开文件时,操作系统会在内核中创建struct file结构体对象来描述这个被打开的文件。而一个进程可以打开多个文件,那进程结构体对象task_struct就要存储哪些文件是由哪一个进程打开的。因此,每个进程的task_struct对象都要和打开的文件建立关系!所以每个task_struct对象其实有一个指针struct files_struct* files,这个指针指向结构体files_struct,而这个结构体包含一个指针数组struct file* fd_array[],这个数组我们可以称之为文件描述符表。数组中的每个元素都是指向当前进程所打开文件的指针(地址)!
而如果两个不同的进程打开同一个文件,操作系统只会为这个打开的文件创建一个struct file结构体对象,只不过这个文件的结构体对象有一个引用计数(计数器)字段会是2,表示当前有两个进程打开此文件。
这意味着多个进程可以共享相同的文件资源(各自进程的文件描述表指向同一个文件结构体对象),这不就是进程间通信的本质:让不同的进程能共享同一份资源。一个进程可以向文件写入数据,而另一个进程则可以从文件中读取这些数据,从而实现了通信!
- 而在上面我们看到当一个进程向管道文件写入数据时,另一个进程在查看该管道文件属性时,其文件大小却是
0,但还是可以从该管道文件中获取数据现象。这是为什么?
其原因是:不管是匿名管道还是命名管道,写入数据的时候并不是将数据直接刷新到磁盘(访问磁盘有I/O效率问题)!而是存储在内核缓冲区中 !因为操作系统管理着内核中每一个被打开的文件,那么操作系统就很清楚每一个被打开文件的类型。因此,如果操作系统识别是普通文件,那么就根据内核缓冲区的刷新策略,直接刷新到磁盘上;而如果识别到是管道文件,那么数据不会马上刷新到磁盘上,而是存储在内核缓冲区中,等待另外一个进程读取数据。因此命名管道(或匿名管道)通常被视为"内存级文件"。
- 接下来还有一个边角问题:在匿名管道中,我们可以通过子进程通过继承父进程的文件描述符表,使得不同的进程可以打开同一个管道文件;那在命名管道中,两个不相干的进程是如何看到同一份管道文件(资源)的呢?
这就设计到【文件系统】的知识了,因为磁盘中一定会存在大量没有被打开的文件,那么就需要管理磁盘中每一个文件的属性,注定了存在大量的inode结构(文件属性的集合)。因此为了区分每个文件的inode结构,操作系统会为每个inode结构取一个唯一编号,即inode编号 。所以,想要对文件操作,操作系统只认inode编号 !但用户都是通过文件名来对文件操作的呀?这又是因为文件名和inode编号的关系是由目录来建立和维护的(目录文件的数据块存储着文件名和inode编号的映射关系)。
因此,当不同进程通过需要通过同一个命名管道文件进行通信,必然要找到命名管道的 文件路径 + 文件名 ,那么操作系统会根据文件名到指定的目录下的数据块中查找文件名映射的inode编号。因为inode编号是唯一的,从而可以确保这些进程打开的是同一个管道文件。
三、系统调用接口mkfifo
除了可以用makefifo命令来创建命名管道之外,还可以使用系统调用接口mkfifo函数来创建。
cpp
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);其中
-
pathname指定了要创建的命名管道的路径(包含文件名) -
mode指定了创建出来管道文件的权限(类似于系统调用接口open函数的第三个参数)。 -
返回值:
-
成功创建命名管道时,
mkfifo函数返回0 -
失败则返回
-1
-
代码样例思路:首先为了能让两个毫不相干的进程能够通信,创建两个源文件,分别是服务端server.cc和客户端client.cc。服务端主要是创建命名管道、读取管道数据和最后回收命名管道,而客户端主要是向管道中写入数据。
补充:
.cc结尾的就是C++源文件的后缀名。常见后缀名有很多种,如.cpp、.cc或者.cxx等,这取决于个人或团队的偏好。
comm.hpp:这个头文件主要是用来存放整个项目所需要的头文件以及自定义的错误码。
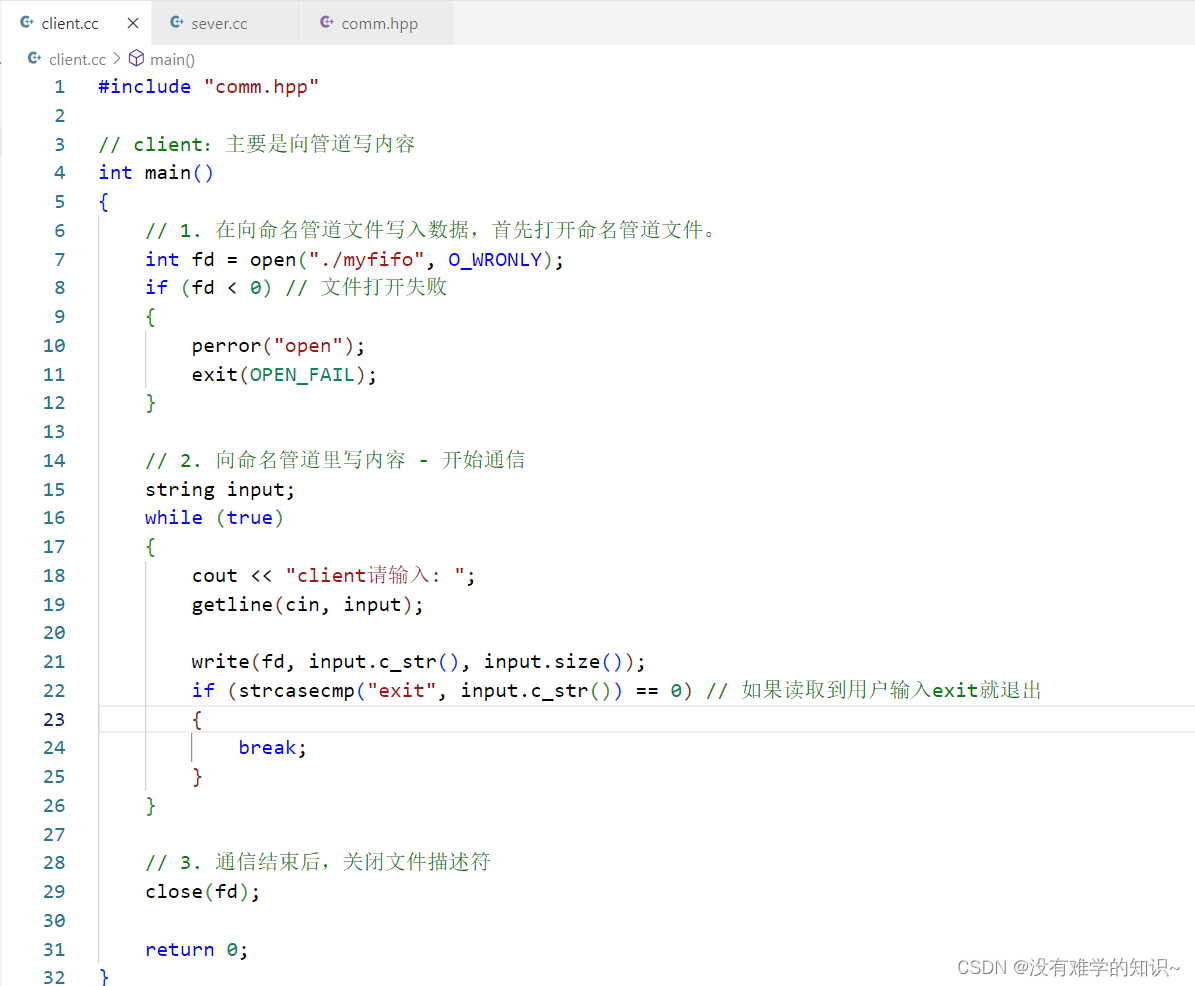
server.cc:创建命名管道、读取管道数据和最后回收命名管道。(详细内容可以看代码注释,非常详细!!!)

client.cc:向管道中写入数据。(详细内容可以看代码注释,非常详细!!!)
- 程序演示
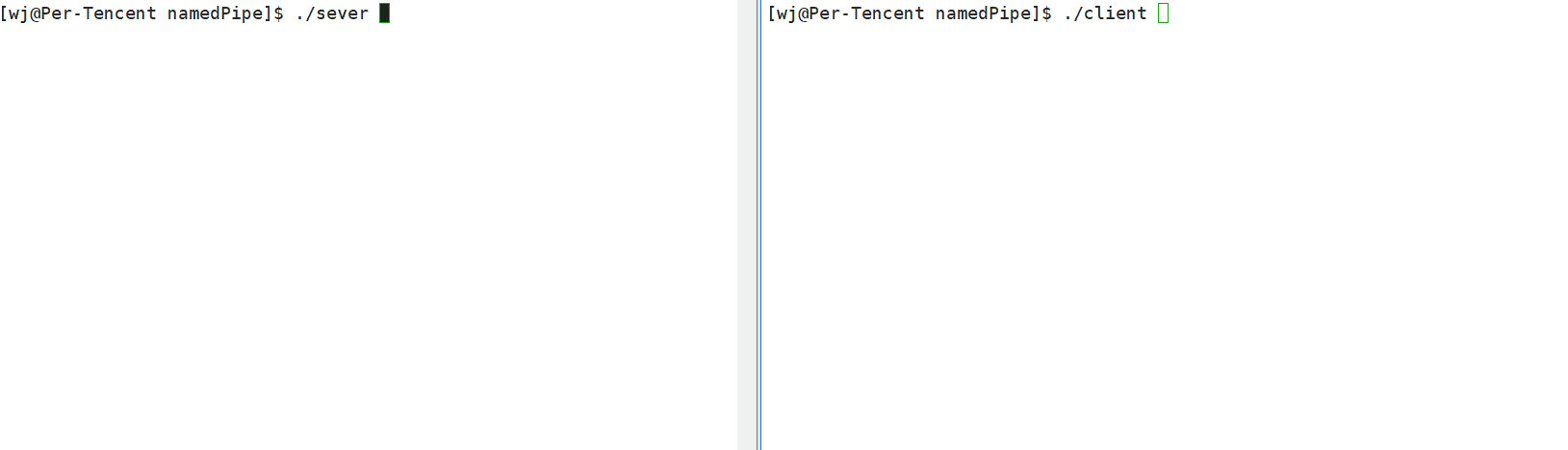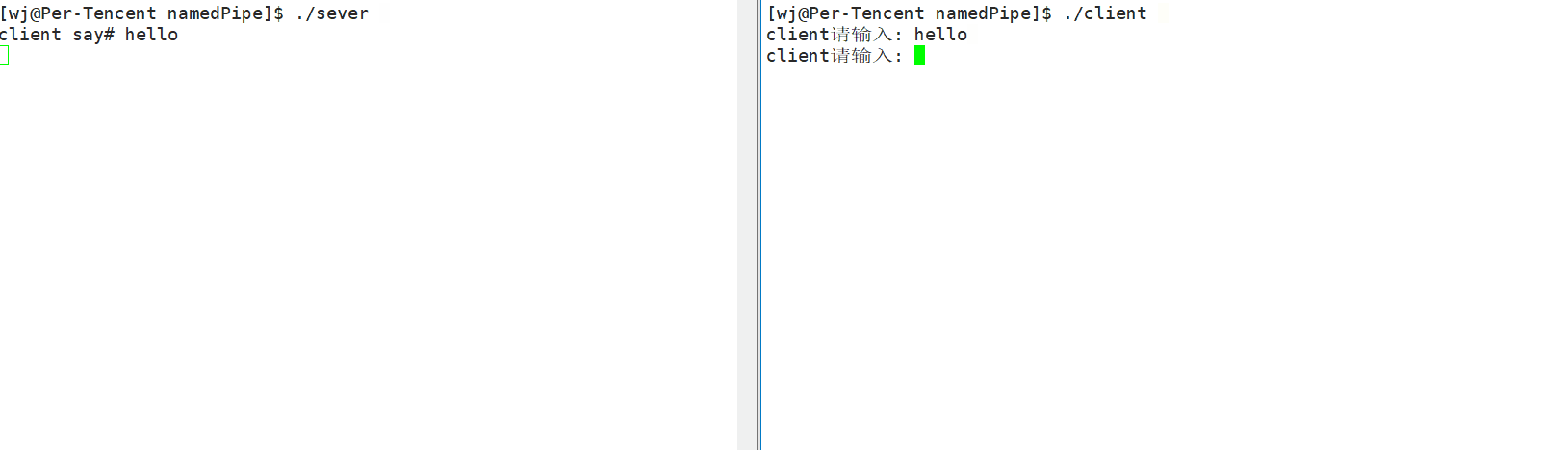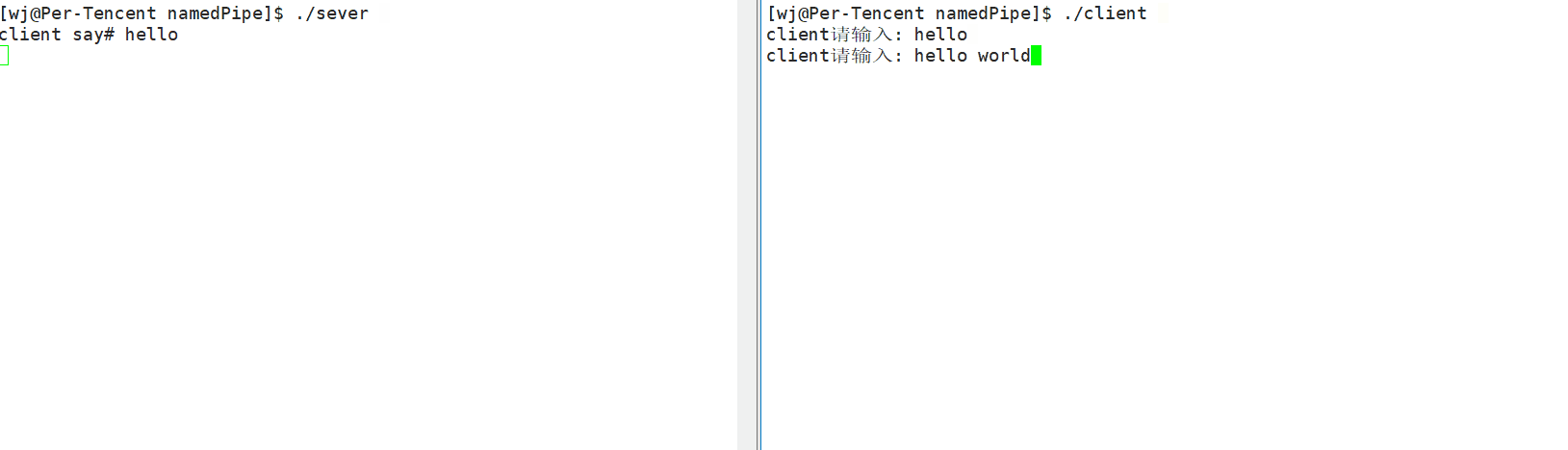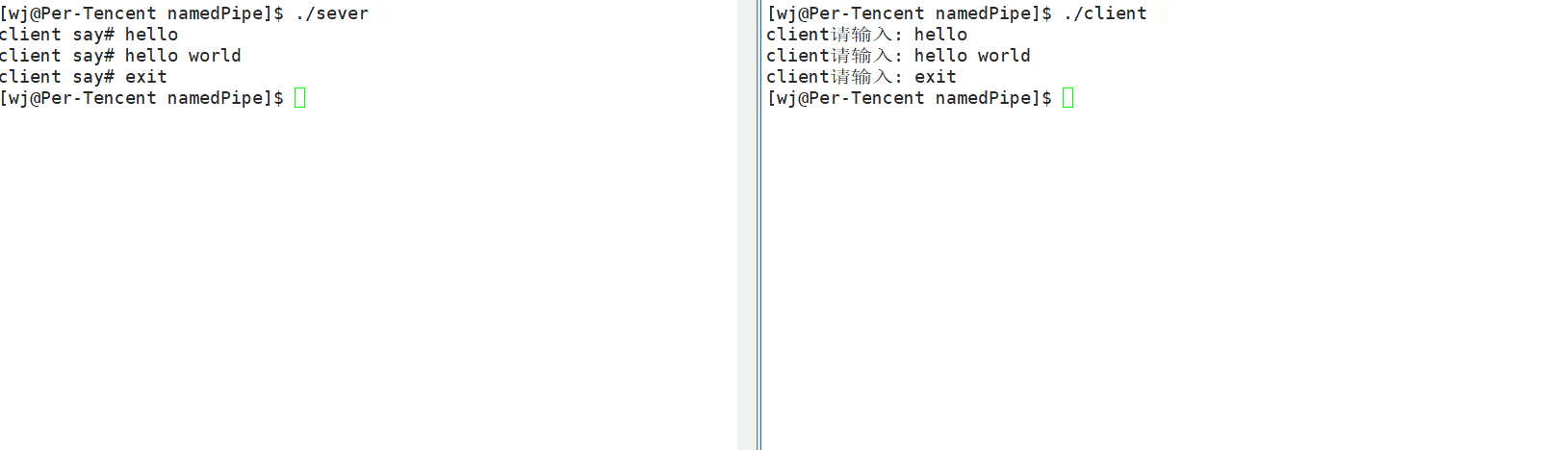
需要注意的是:
- 必须要先运行
sever端进程,因为要先将管道文件创建好后,才能开始通信。 - 服务端启动后,因为是读端,所以会阻塞等待客户端(写端)写入数据,所以你会看到运行完服务端后,会有光标一直在闪烁。
- 命名管道文件需要写端和读端都打开的时候才可以开始通信,否则只打开其中一个端会进入阻塞。我们可以理解为这是为了防止只打开读端而不打开写端,这是因为不打开写端,读端
read函数就会返回0,那么读端也会退出
四、命名管道和匿名管道的区别(特征)

命名管道的特征大致和匿名管道一样:
- 匿名管道和命名管道都是通过文件描述符进行通信的
- 无论是匿名管道还是命名管道,都是单向通信的,即数据只能从一端流向另一端。
- 面向字节流
- 进程是会协同的,同步与互斥的
不同点在于:
- 匿名管道通常用于有亲缘关系的进程之间的通信,比如父子进程;而命名管道可以用于没有亲缘关系的进程之间的通信,它是一种独立的通信方式。
- 匿名管道直接通过
pipe函数创建使用,然后创建子进程进行通信;而命名管道需要先通过mkfifo函数创建,然后再通过open打开使用。 - 在匿名管道中,如果父进程创建多个子进程,会出现写端重复继承的情况,导致子进程之间也能互相通信;而命名管道不会出现这种情况。
五、 命名管道的四种情况
命名管道的四种情况和匿名管道的四种情况差不多,主要的区别在于第四点!
- 读写端正常,管道如果为空,读端就会被阻塞,等待写端的数据。
- 读写端正常,管道为满时,写端阻塞,等待读端读取数据。
- 读端正常读,写端关闭,那么读取端会在读取完管道中的所有数据后得到一个特殊的信号,表明已经到达了管道的末尾。这样读取操作就会返回值为
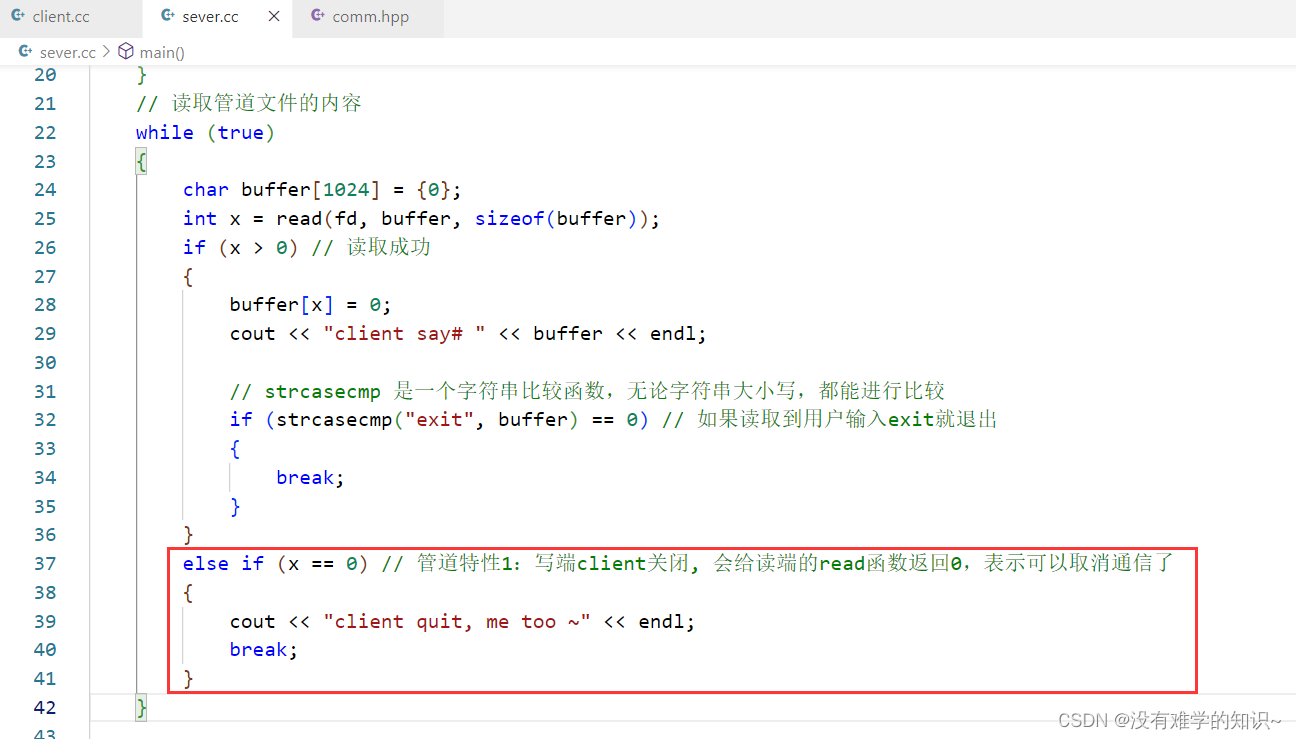
0,也就是read函数会返回0,而不会再被阻塞(不会再等待管道中会有新的数据)。因此,当写端关闭后,读端就知道不会再有新的数据写入管道,可以安全地关闭管道,结束通信。
当我ctrl + c终止了写端,对应读端也退出了
- 写端正常,读端关闭。写入操作不会因为读端关闭而阻塞,写入进程可以继续向管道写入数据,直到读取进程再次打开读端,或者管道被关闭,或者管道被写满。
这也是唯一和匿名管道的区别!对于匿名管道,写端正常,读端关闭,那么操作系统会为写端发送SIGPIPE信号终止该进程。这是因为在匿名管道中,通信的两个进程是有血缘关系的,读取端关闭后,写入端无法将数据传递给任何进程,所以操作系统只能终止;而命名管道的任意进程之间都可以通信,所以写端只管写就行。


六、代码
Gitee代码仓库:点击跳转