目录
[1. 结构](#1. 结构)
[2. 优化器](#2. 优化器)
[2.1 梯度下降法](#2.1 梯度下降法)
[2.2 动量优化法](#2.2 动量优化法)
[2.3 Adagrad自适应学习率优化算法](#2.3 Adagrad自适应学习率优化算法)
[2.4 Adam自适应矩估计](#2.4 Adam自适应矩估计)
[3. 激活函数](#3. 激活函数)
[3.1 Sigmoid函数](#3.1 Sigmoid函数)
[3.2 Tanh函数](#3.2 Tanh函数)
[3.3 ReLU函数](#3.3 ReLU函数)
[4. 损失函数](#4. 损失函数)
[4.1 均方误差损失函数(Mean Squared Error Loss)](#4.1 均方误差损失函数(Mean Squared Error Loss))
[4.2 交叉熵损失函数(The Cross-Entropy Loss)](#4.2 交叉熵损失函数(The Cross-Entropy Loss))
1. 结构
Convolutional Neural Network(CNN)是深度学习模型之一,适用于图像数据的处理,包含输入层、卷积层、池化层、全连接层和输出层五种类型的结构组成。
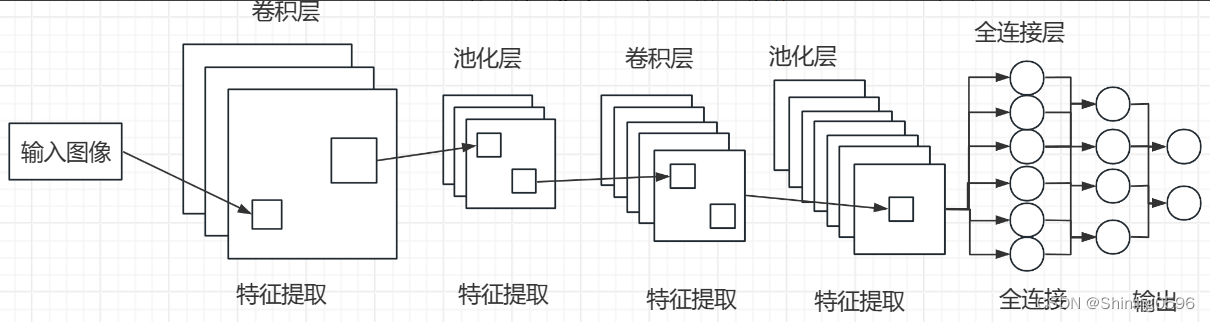
卷积神经网络的输入层负责接收由红、绿、蓝三个颜色通道构成的原始图像数据,将其转换为像素强度的二维矩阵。
卷积核又称做过滤器,利用卷积核对这些图像进行卷积运算,检测并提取局部特征,这一核心操作通过发挥卷积核的过滤作用,为后续的图像识别任务提供关键特征信息。

卷积核是一个3x3或5x5的矩阵,卷积层是通过卷积核提取图像的局部特征,形成特征图,为后续的识别任务提供关键信息。卷积核的大小决定了特征尺度,卷积核越小,所捕获的特征越细致,而较大的卷积核用于捕获广泛的特征。
池化层又叫下采样层,池化操作是通过对特征映射进行下采样,降低特征图的空间尺寸,减小数据的计算复杂性,增加特征的鲁棒性。最大池化(Max Pooling)是选取最大值像素输出。平均池化(Average Pooling)输出平均值。

全连接层也叫密集层,它是将卷积层和池化层提取得到的特征,进行一定的整合,继而输出到输出层,在此过程中,它起到了分类器的作用,通常我们使用dropout技术防止过拟合,提高模型的泛化能力,配合softmax分类器进行多分类任务,将全连接层的输出转换为概率形式,便于进行多分类任务,输出每个类别的概率值。
2. 优化器
优化器在深度学习模型的训练中负责通过迭代调整网络权重来最小化损失函数。以下是几种常用的优化器。
2.1 梯度下降法
梯度下降法是在模型参数优化的深度学习中,用来模型参数优化来指导参数更新的关键算法,通过计算损失函数关于参数的梯度,它包括三种方式,适用于不同的训练需求和数据规模,实现高效率的模型训练和参数优化,分别是批量梯度下降法、随机梯度下降法和两种方法的性能的折中的小批量梯度下降法三种方式。
2.1.1 批量梯度下降法 BGD
其公式为:


批量梯度下降法的结果是全局最优解,在每次迭代时,都需要处理全部训练集数据,若样本数据数目较多时,迭代速度较慢,但批量梯度下降法易于并行实现。
2.1.2 随机梯度下降法 SGD
其公式为:

随机梯度下降法 SGD每次使用一个样本来更新计算梯度,训练速度快,SGD缺点在于每次只能迭代处理一个样本,导致迭代次数多,而每次迭代并非都向整体最优化方向,使得梯度下降的波动较大,更容易从一个局部最优跳到另一个局部最优,不能很快的得到局部最优解,准确度下降。
2.1.3 小批量梯度下降法MBGD
其公式为:
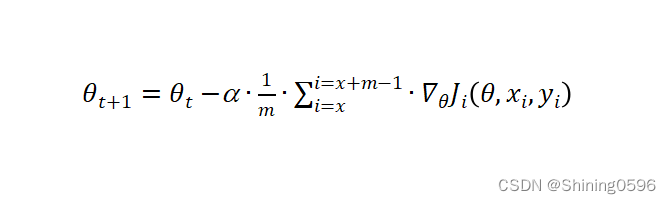
小批量随机梯度下降可以看作是 SGD 和 BGD 的中间选择,它表示这两种方法的性能的折中,小批量梯度下降法在训练时,训练过程稳定且迭代速度较快,有助于保证最终参数训练的准确率。
2.2 动量优化法
动量优化法有Momentum和Nesterov两种算法。
2.2.1 Momentum
其公式为:
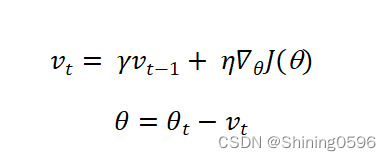
Momentum算法,我们可以理解为,推一个球上山,当开始推的时候,球会向前滚动,这时停止施力,球可能会因为惯性而继续滚动一段时间,这就是Momentum的算法思想。在训练模型时,每次更新参数都相当于是给球施加一个力,Momentum会让这个"力"具有一定的惯性,帮助球(参数)更快地到达山顶(最优解)。
当损失函数形状复杂、存在很多局部最优解时,Momentum算法能让模型避开局部最优解, 使参数更新更加稳定和高效,提高模型的训练速度和性能,最终找到最优解。
2.2.2 Nesterov accelerated gradient(NAG)
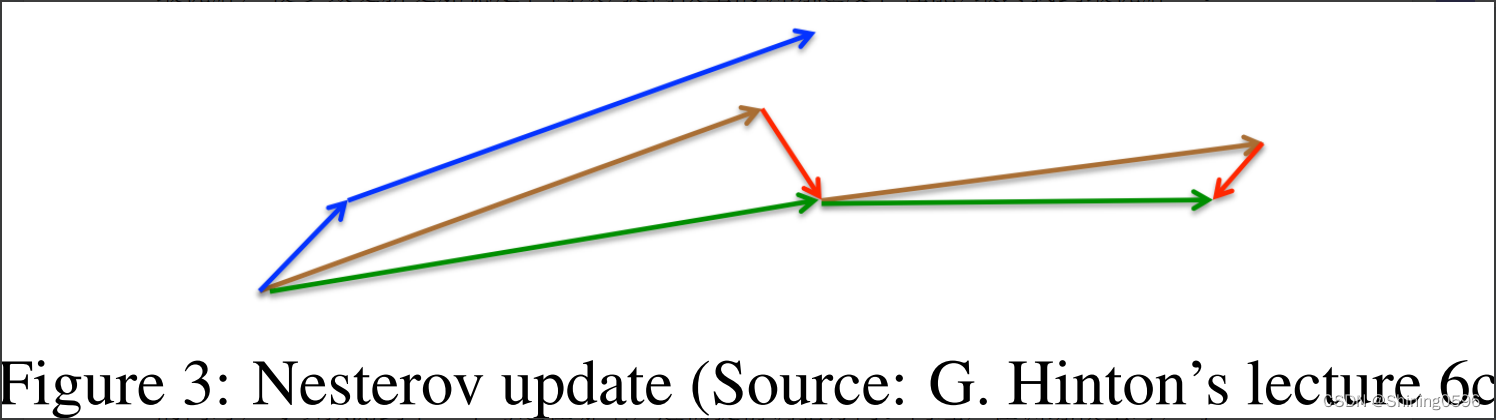
NAG算法是Momentum算法的改进,就比如骑自行车,NAG算法就是在骑自行车的同时,可以预测到下一个弯道在哪里,进而提前调整方向。同理,在训练模型时,每更新一次参数,都可以预测下一步的位置,我们可以基于这个预测的位置计算梯度,从而更加快速地找到最优解,提高模型训练效率。
2.3 Adagrad自适应学习率优化算法

当每一个参数使用SGD更新,Adagrad则会根据参数的过去梯度,修改通用的学习率。Adagrad算法可以更高效地找到最优参数,提高模型性能和训练速度。例如,当我们在玩射箭游戏时,刚开始并不能确定力度和角度,这就需要尝试用较大的力度和角度来击中目标。这就对相应是模型训练初期,我们需要较大的学习率来快速调整参数。随着不停的射箭并观察箭地落点在哪里,由此积累了力度和角度调整地经验,由此我们得出结论"当力度调整较大时,箭会偏离目标,当角度调整过大时,箭则会飞过靶心"。
通过自适应学习调整,找到最佳的力度和角度组合,这样,我们可以正中目标。同理,Adagrad算法通过自适应地调整参数的学习率,使得模型在训练过程中更快速高效地能够找到最优的参数组合。
2.4 Adam自适应矩估计
Adam算法可以智能地调整学习率,让模型在训练时,更快的找到最佳参数,提高模型的性能和准确性。这就像训练师一样,可以根据宠物的特点和学习进度,来制定出更适合宠物的训练计划,让其能够更快地学会坐下、握手等各种动作。Adam算法的计算效率高,收敛速度快,需要调整超参数,可以自适应地调整每个参数的学习率,来提高模型的收敛速度,同时可能错过全局最优解。
3. 激活函数
激活函数在神经网络中起着重要作用,主要负责在卷积层之后引入非线性特性,使网络能够学习和模拟更为复杂的函数映射关系,常见的激活函数包括Sigmoid、Tanh、ReLU等。
3.1 Sigmoid函数
其函数公式为:
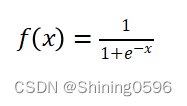
其函数图像为:
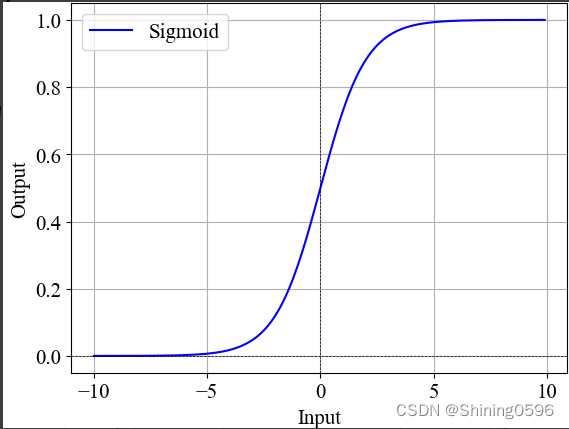
Sigmoid函数输出限定在0到1之间,表示概率分布,可用于解决二分类问题。
3.2 Tanh函数
其函数公式为:

函数图像为:
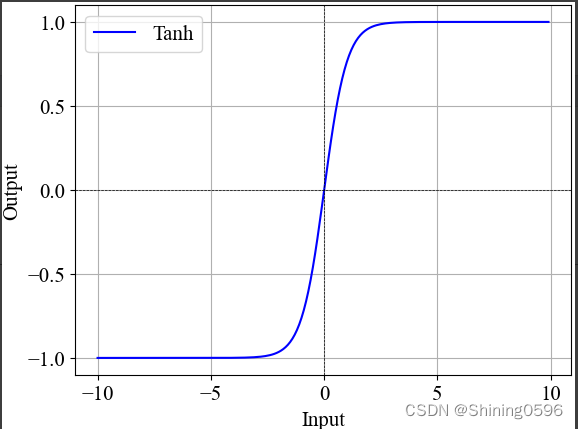
Tanh与Sigmoid类似,其输出范围在-1和1之间,没有解决出现梯度消失的问题。
3.3 ReLU函数
其函数公式为:

其函数图像为:
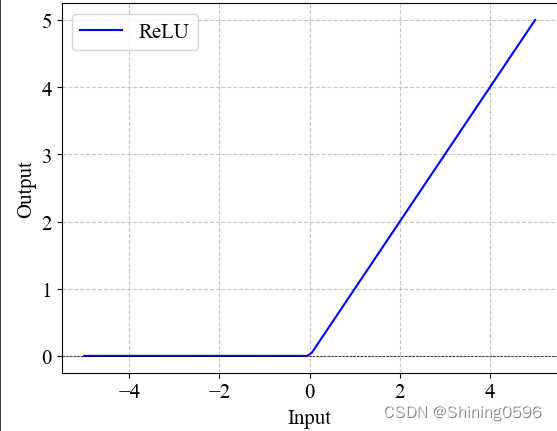
当输入值input大于或等于0,ReLU函数输出该值;当输入值input小于0,ReLU函数输出为0。
4. 损失函数
损失函数是模型预测与实际值差异的关键指标,值越小,表明模型的预测越准确,在深度学习中,常见类型有均方误差和交叉熵损失等。
4.1 均方误差损失函数(Mean Squared Error Loss)
函数定义如下:
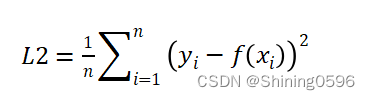
可用于回归问题,计算预测值与真实值之间的平方差的平均值。
4.2 交叉熵损失函数(The Cross-Entropy Loss)
函数定义如下:
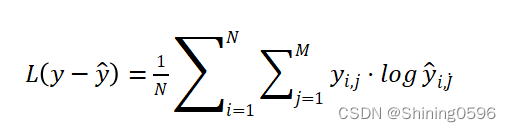
可用于分类问题,表示预测概率和真实值之间的差异。