目录
一个了解无从知晓事情的超酷数学技巧
当我们审视双重差分法时,我们有来自 2 个不同城市的多个客户的数据:阿雷格里港和弗洛里亚诺波利斯。数据跨越 2 个不同的时间段:在阿雷格里港进行营销干预以增加客户存款之前和之后。为了估计干预效果,我们进行了回归,得到了差异估计量及其标准误差。
对于那种情况,我们有很多样本,因为数据是细颗粒度的。但是,如果我们所拥有的只是城市层面的汇总数据呢?例如,假设我们所拥有的只是干预前后两个城市的平均存款水平。
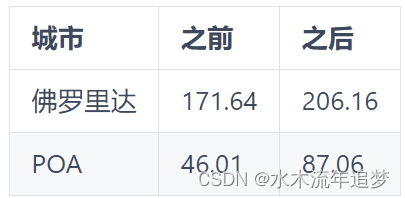
我们仍然可以计算 Diff-in-Diff 估计量
但是请注意,这里的样本量是 4,这也是我们 Diff-in-Diff 模型中的参数数量。在这种情况下,标准误差没有有效地定义,那么我们应该怎么做呢?另一个问题是弗洛里亚诺波利斯可能不像我们希望的那样与阿雷格里港相似。例如,弗洛里亚诺波利斯以其美丽的海滩和随和的人而闻名,而阿雷格里港则以其烧烤和草原而闻名。这里的问题是您永远无法确定您是否使用了适当的对照组。
为了解决这个问题,我们将使用合成控制法,该方法被称为**"过去几年政策评估文献中最重要的创新"** (https://www.aeaweb.org/articles?id=10.1257 /jep.31.2.3)。它基于一个简单但强大的想法。我们不需要在未处理中样本找到任何与处理非常相似的单个单元。相反,我们可以将自己的组合打造为多个未经处理的单元的组合,从而创建有效的合成控制。合成控制是极其有效和直观的方法,甚至有一篇文章发表在 华盛顿邮报(https://www.washingtonpost.com/news/wonk/wp/2015/10/ 30/如何在竞争性声明的世界中衡量事物/),而不是科学期刊上。
python
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
from matplotlib import style
from matplotlib import pyplot as plt
import seaborn as sns
import statsmodels.formula.api as smf
%matplotlib inline
pd.set_option("display.max_columns", 6)
style.use("fivethirtyeight")要查看它的实际应用,可以考虑估计卷烟税对其消费的影响的问题。为了提供一些背景信息,这是一个在经济学中已经争论了很长时间的问题。论点的一方面说税收将增加雪茄的成本,从而降低其需求。另一方认为,由于香烟会导致成瘾,因此价格的变化不会对他们的需求产生太大影响。在经济方面,我们会说卷烟的需求对价格没有弹性,增加税收只是以吸烟者为代价增加政府收入的一种方式。为了解决问题,我们将查看有关此事的一些美国数据。
1988 年,加利福尼亚州通过了著名的烟草税和健康保护法案,该法案被称为 Proposition 99。 "它的主要作用是对加利福尼亚州内销售的烟草卷烟征收每包 25 美分的州消费税,对雪茄和嚼烟等其他商业烟草产品的零售征收大致相当的消费税。对烟草销售的限制包括禁止在青少年可以进入的公共场所使用香烟自动售货机,以及禁止个人销售单支香烟。该法案产生的收入被指定用于各种环境和保健计划,以及反烟草烟草广告。"
为了评估其效果,我们可以收集来自多个州和多年的卷烟销售数据。在我们的例子中,我们从 39 个州获得了 1970 年到 2000 年的数据。其他州也有类似的烟草控制计划,因此被排除在分析之外。这是我们的数据的样子。
python
cigar = (pd.read_csv("data/smoking.csv")
.drop(columns=["lnincome","beer", "age15to24"]))
cigar.query("california").head()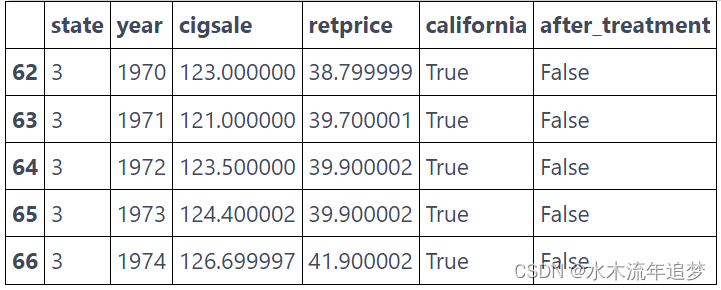
我们将state作为州指数,其中加利福尼亚是第 3 位。我们的协变量是retprice(卷烟零售价)和cigsale(每包卷烟的人均销售额)。 我们感兴趣的结果变量是cigsale。 最后,我们有布尔辅助变量来表示加利福尼亚州和干预后时期。 如果我们绘制加州和其他州的卷烟销售量,这就是我们会得到的。
python
ax = plt.subplot(1, 1, 1)
(cigar
.assign(california = np.where(cigar["california"], "California", "Other States"))
.groupby(["year", "california"])
["cigsale"]
.mean()
.reset_index()
.pivot("year", "california", "cigsale")
.plot(ax=ax, figsize=(10,5)))
plt.vlines(x=1988, ymin=40, ymax=140, linestyle=":", lw=2, label="Proposition 99")
plt.ylabel("Cigarette Sales Trend")
plt.title("Gap in per-capita cigarette sales (in packs)")
plt.legend(); 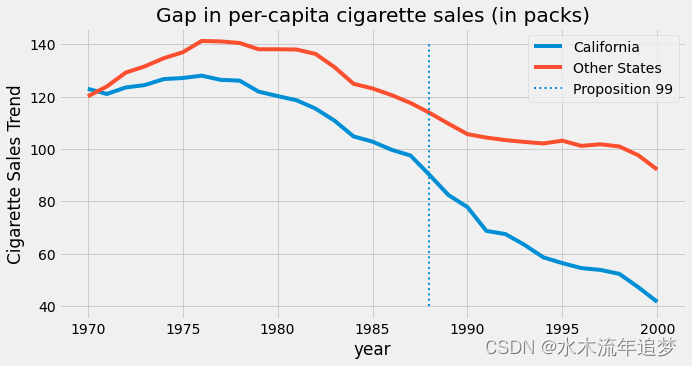
在我们有对应数据的这段时间里,加利福尼亚人的香烟购买量显然低于全国平均水平。此外,80 年代后卷烟消费似乎呈下降趋势。与其他州相比,在 99 号提案之后,加利福尼亚州的下降趋势似乎加速了,但我们不能肯定地说。这只是我们通过审阅绘出的图形得出的猜测。
为了回答 99 号提案是否对卷烟消费产生影响的问题,我们将使用干预前的时期来建立一个综合控制。我们将结合其他州来建立一个与加州趋势非常相似的假州。然后,我们将看到这种合成控制在干预后的表现。
我们有时间
为了使过程更正式一点,假设我们有 单位。不失一般性,假设单元 1 是受干预影响的单元。单位
是未经处理的单位的集合,我们将其称为"供体池"。还假设我们拥有的数据跨越 T 个时间段,在干预之前有
个时间段。对于每个单元 j 和每个时间 t,我们观察结果
。对于每个单元 j 和周期 t,将
定义为没有干预的潜在结果,将
定义为有干预的潜在结果。然后,对于处理单元 j=1 在时间 t 的影响,对于
定义为
由于单位 j=1是经过处理的单位,因此 是事实,但
不是。那么挑战就变成了我们如何估计
。请注意如何为每个时期定义治疗效果,这意味着它可以随时间变化。它不需要是瞬时的。它可以累积或消散。概括地说,估计处理效果的问题归结为估计如果不进行处理,单元 j=1 的结果会发生什么的问题 。

为了估计 ,我们记住,供体池中的单位组合可能比单独的任何未处理单位更好地近似处理单位的特征。因此,综合控制被定义为控制池中单元的加权平均值。给定权重
,
的综合控制估计为
如果所有这些数学运算让您头疼,那么您并不孤单。但别担心,我们有很多例子可以让它更直观。这一次,我喜欢将综合控制视为一种颠倒的回归方式。众所周知,线性回归也是一种将预测作为变量加权平均值的方法。现在,考虑一下那些回归,例如 diff-in-diff 示例中的回归,其中每个变量在一段时间内都是虚拟变量。在这种情况下,回归可以表示为以下矩阵乘法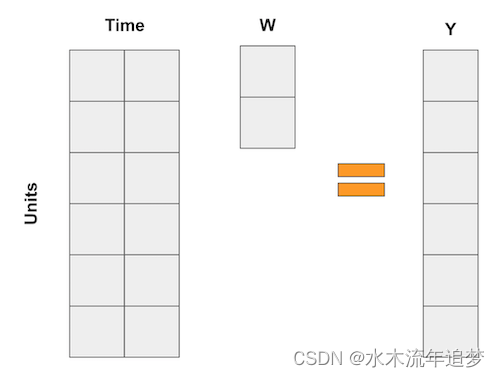
在综合控制案例中,我们没有很多样本,但我们确实有很多时间段。所以我们要做的是翻转输入矩阵。然后,样本成为"变量",我们将结果表示为样本的加权平均值,就像下面的矩阵乘法一样。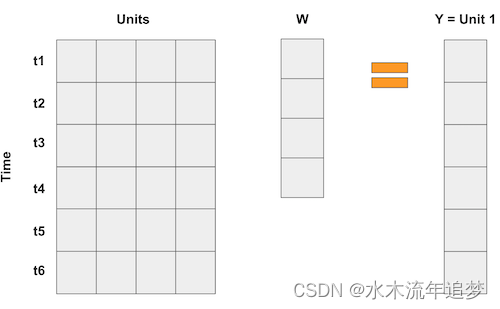
如果我们每个时间段有多个特征,我们可以像这样堆积特征。重要的是要做到这一点,以便回归试图通过使用其他单元来"预测"处理过的单元 1。这样,我们可以以某种最佳方式选择权重来实现我们想要的这种接近度。我们甚至可以对特征进行不同的缩放,以赋予它们不同的重要性。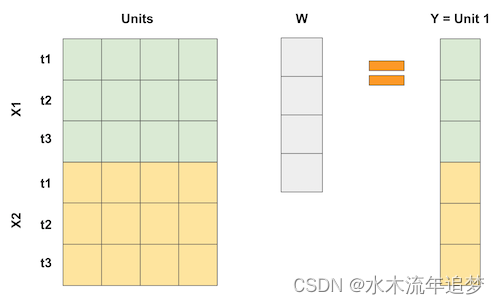
那么,如果综合控制可以看作是一个线性回归,那也意味着我们可以用 OLS 来估计它的权重,对吧?对!事实上,让我们现在就这样做。