首先,多数情况下免费版本的功能,已经可以满足绝大多数采集需求,想了解八爪鱼采集器版本区别的详情,请访问这篇帖子: https://blog.csdn.net/cctv1123/article/details/139581468
八爪鱼采集器免费版和个人版、团队版下载![]() https://affiliate.bazhuayu.com/retrieve
https://affiliate.bazhuayu.com/retrieve
今天我们以采集哔哩哔哩的评论作为八爪鱼采集器的案例进行讲解,提取一级评论中的发布者昵称、发布时间、评论内容、点赞数
首先采集三板斧我们回忆一下,翻页、循环、数据采集

受官方邀请做直播讲课的时候,做了一整套的ppt,如果需要可以联系我:tktk6622 免费索取
填入网址

预登陆


设定滚动翻页

使用自动识别网页内容或者执行添加滚动循环都可以

配置一些细节

设置循环列表
自动识别网页很多时候不能正确的获取到自己要点信息字段,那就手动修改吧

添加一个循环,调整到不固定元素列表,因为评论有一级评论和二级评论的区别,为了方便讲解,我们这边只提取一级评论(二级评论其实是可以采集的,也能够有关联的方式在一起采集)
一级评论的xpath代码是这个://div@class="root-reply-container"
提取循环中的数据字段

昵称xpath://div@class="user-name"
评论://span@class="reply-content"
时间://span@class="sub-reply-time"
点赞://span@class="reply-like"
(*注意这是结合上一个循环的拼接xpath)
进行测试数据采集
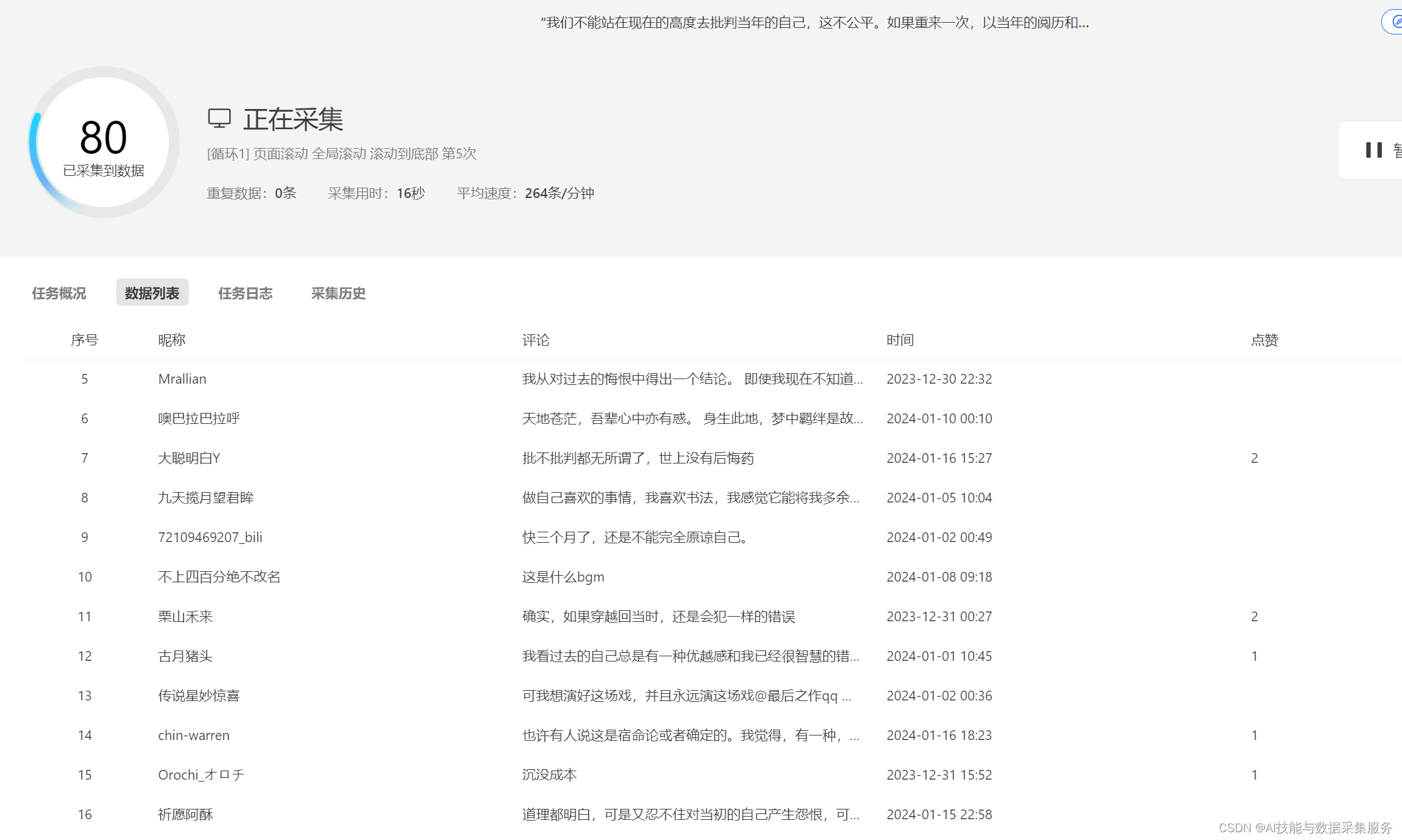
查看导出的数据情况
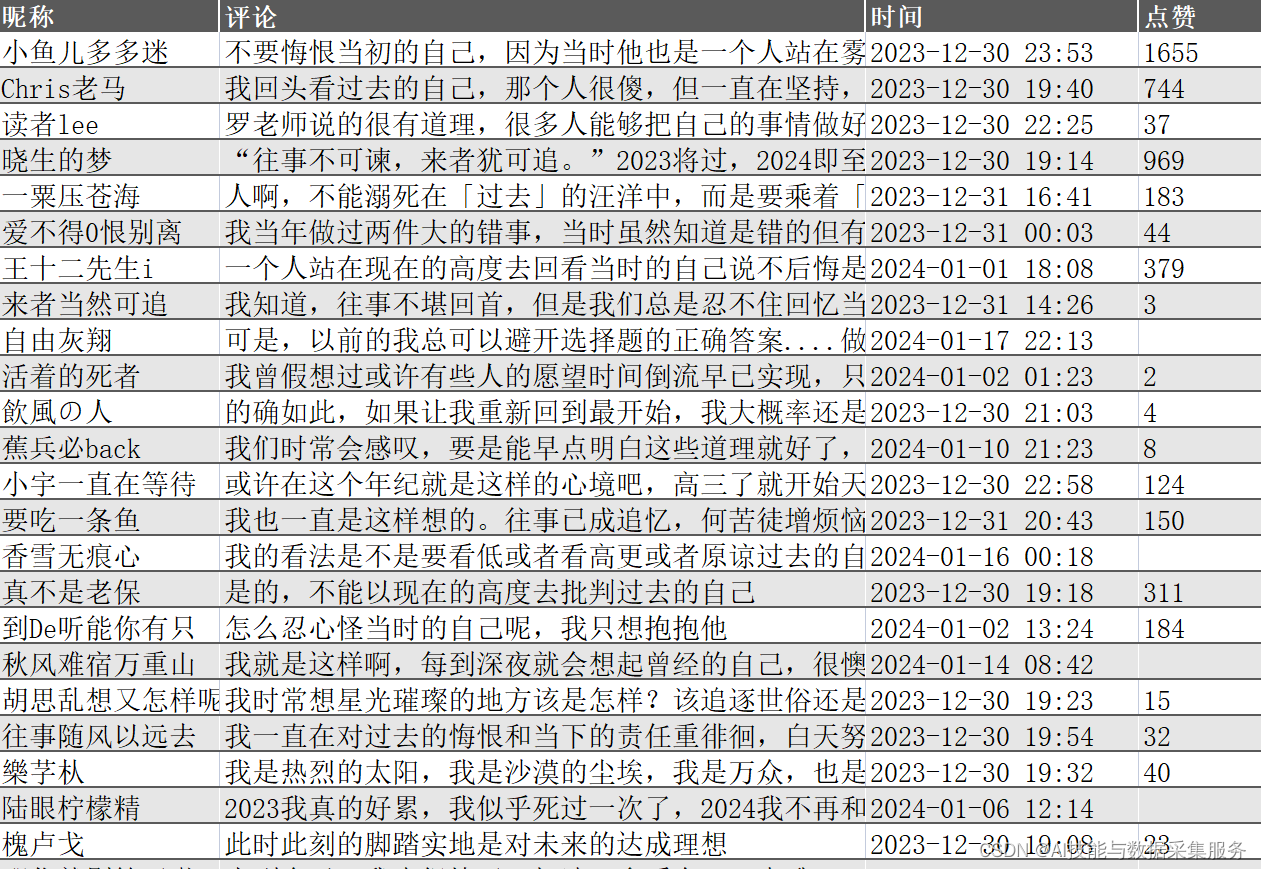
采集的数据导出到表格全都正常,没有乱码。这个采集需求圆满搞定。
需要这个采集规则,可以在我的B站资源列表中下载
做个总结,这篇教程再次通过实例讲解工作流程如何设置翻页、循环、数据提取,并给出来循环列表的xpath。下一节课我们说说:二级页面数据提取与细节页面处理------点击链接进入详情
这贴是教程专栏的目录链接: