目录
简单回顾一下,我们现在感兴趣的是发现治疗效果的异质性,即确定单位对治疗的不同反应。在这个框架中,我们想估计
或
在连续的情况下。换句话说,我们想知道这些单位对治疗的敏感程度。这在我们不能治疗所有人并且需要对治疗进行优先排序的情况下非常有用,例如,当你想提供折扣但预算有限时。
之前,我们看到了如何转换结果变量Y以便我们可以将其插入预测模型中,并获得条件平均治疗效果(CATE)估计。在那里,我们不得不付出方差增加的代价。这是我们在数据科学中经常看到的。没有一个最好的方法,因为每种方法都有其优缺点。因此,值得学习许多技术,以便根据具体情况进行权衡。本着这种精神,本章将侧重于为您提供更多可供您使用的工具。
元学习器是一种利用现成的预测机器学习方法来解决我们迄今为止一直在研究的相同问题的简单方法:估计CATE。同样,它们都不是最好的,每一个都有自己的弱点。我会试着复习一下,但请记住,这些内容高度依赖于上下文。不仅如此,元学习器还部署了预测ML模型,这些模型可以从线性回归和增强决策树到神经网络和高斯过程。元学习器的成功也将在很大程度上取决于它使用的机器学习方法。通常,你只需要尝试许多不同的东西,看看什么最有效。
python
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
from nb21 import cumulative_gain, elast在这里,我们将使用与以前相同的数据,重新考虑投资广告电子邮件。同样,这里的目标是找出谁能更好地回复电子邮件。不过也有一点小转折。这一次,我们将使用非随机数据来训练模型,并使用随机数据来验证它们。处理非随机数据是一项困难得多的任务,因为元学习者需要对数据进行去噪并估计CATE。
python
test = pd.read_csv("./data/invest_email_rnd.csv")
train = pd.read_csv("./data/invest_email_biased.csv")
train.head()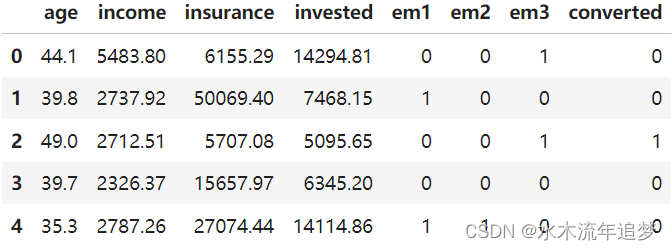 我们的结果变量是转化率,我们的治疗是通过电子邮件1。让我们创建变量,将这些变量与功能一起存储。探索治疗效果的异质性。
我们的结果变量是转化率,我们的治疗是通过电子邮件1。让我们创建变量,将这些变量与功能一起存储。探索治疗效果的异质性。
python
y = "converted"
T = "em1"
X = ["age", "income", "insurance", "invested"]S-Learner
我们将使用的第一个学习者是S-learner。这是我们能想到的最简单的学习者。我们将使用单个(因此为S)机器学习模型
估计
为此,我们将简单地将治疗作为一个特征包括在试图预测结果Y的模型中。
python
from lightgbm import LGBMRegressor
np.random.seed(123)
s_learner = LGBMRegressor(max_depth=3, min_child_samples=30)
s_learner.fit(train[X+[T]], train[y]);然后,我们可以在不同的治疗方案下进行预测。测试和对照之间的预测差异将是我们的CATE估计
如果我们把它放在一个图表中,下面是它的样子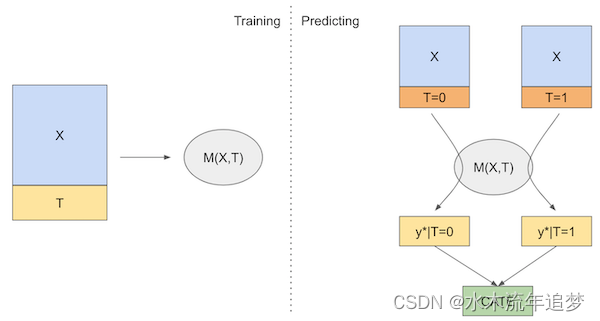
现在,让我们看看如何在代码中实现这个学习器。
python
s_learner_cate_train = (s_learner.predict(train[X].assign(**{T: 1})) -
s_learner.predict(train[X].assign(**{T: 0})))
s_learner_cate_test = test.assign(
cate=(s_learner.predict(test[X].assign(**{T: 1})) - # predict under treatment
s_learner.predict(test[X].assign(**{T: 0}))) # predict under control
)为了评估这个模型,我们将查看测试集中的累积增益曲线。我还在火车上画增益曲线。由于训练是有偏差的,如果模型是好的,这条曲线不能给出任何指示,但它可以指出我们是否过度拟合训练集。当这种情况发生时,列车组中的曲线将非常高。如果您想看看它是什么样子,请尝试将max_depth参数从3替换为20。
python
gain_curve_test = cumulative_gain(s_learner_cate_test, "cate", y="converted", t="em1")
gain_curve_train = cumulative_gain(train.assign(cate=s_learner_cate_train), "cate", y="converted", t="em1")
plt.plot(gain_curve_test, color="C0", label="Test")
plt.plot(gain_curve_train, color="C1", label="Train")
plt.plot([0, 100], [0, elast(test, "converted", "em1")], linestyle="--", color="black", label="Baseline")
plt.legend()
plt.title("S-Learner");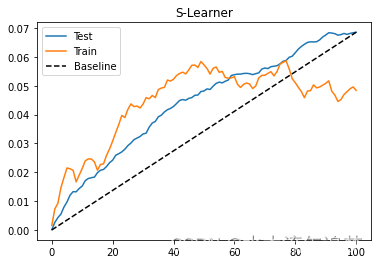
正如我们从累积增益中看到的那样,S-学习器虽然简单,但在这个数据集上可以表现良好。需要记住的一件事是,这种性能对于这个数据集来说是非常特殊的。根据你掌握的数据类型,S学习者可能会做得更好或更差。在实践中,我发现S-学习器是解决任何因果问题的好方法,主要是因为它的简单性。不仅如此,S-学习者可以处理连续和离散处理,而本章中的其他学习者只能处理离散处理。
S学习者的主要缺点是它倾向于将治疗效果偏向于零。由于S学习器使用通常是正则化的机器学习模型,该正则化可以限制估计的治疗效果。切尔诺茹科夫 等人(2016)使用模拟数据概述了这个问题:
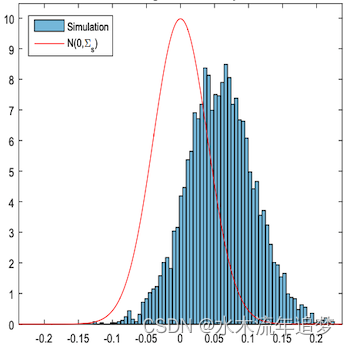
在这里,他们绘制了真实因果效应(红色轮廓)和估计因果效应之间的差异,,使用S-学习器。估计的因果效应有很大偏差。
更糟糕的是,如果治疗相对于其他协变量在解释结果时所起的作用非常弱,则S学习者可以完全放弃治疗变量。请注意,这与您所使用的所选ML模型高度相关。正则化程度越高,问题就越严重。我们将看到下一个学习者尝试解决这个问题。