文章目录
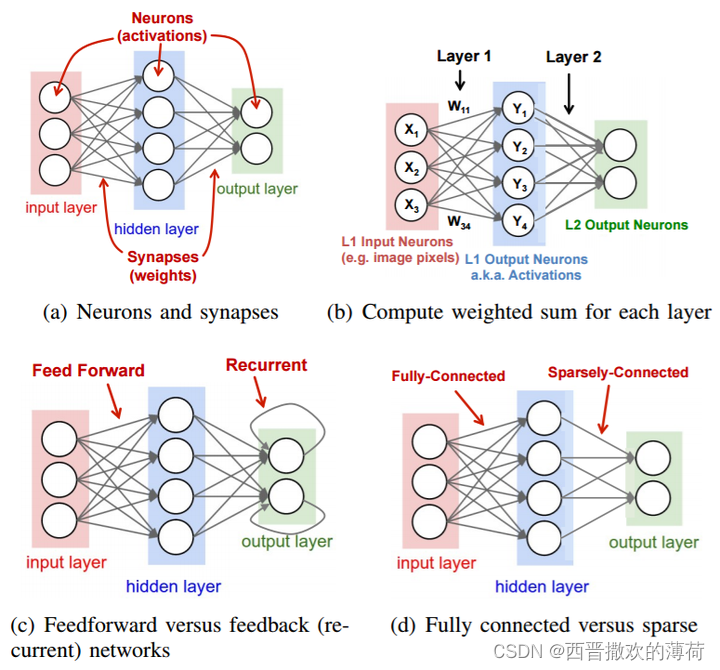
传统的神经网络模型
在深度学习中,传统的神经网络模型,如循环神经网络(RNN)和长短时记忆网络(LSTM),在处理序列数据时存在一些局限性。它们需要依次处理序列中的每个元素,导致计算效率低下,并且难以捕捉长距离依赖关系。
注意力机制的引入
为了解决这个问题,注意力机制被引入到神经网络模型中。它允许模型在处理序列数据时,能够动态地关注序列中最重要的部分,从而提高模型的表达能力和效率。
注意力机制的本质
注意力机制的本质可以理解为一种加权求和的过程。它将序列中的每个元素都与一个查询向量进行比较,并根据它们的相似度分配权重。然后将这些加权后的元素进行求和,得到一个新的表示,该表示更加突出序列中重要的信息。
Encoder-Decoder 框架
注意力机制在 Encoder-Decoder 框架中得到了广泛应用。Encoder-Decoder 框架用于处理序列到序列的任务,例如机器翻译和文本摘要。
- Encoder:将输入序列编码成一个高维特征向量表示。
- Decoder:根据编码后的特征向量生成目标序列。
注意力机制在 Encoder-Decoder 中的应用
在 Encoder-Decoder 框架中,注意力机制可以帮助 Decoder 更好地理解 Encoder 生成的特征向量。例如,在机器翻译中,Decoder 可以通过注意力机制关注 Encoder 中与当前单词最相关的单词,从而生成更准确的翻译结果。
Self-Attention 机制
Self-Attention 机制是注意力机制的一种特殊形式,它将注意力机制应用于序列本身。Self-Attention 机制可以帮助模型更好地捕捉序列中长距离依赖关系,从而提高模型的表达能力。
Transformer 模型
Transformer 模型是一种基于 Self-Attention 机制的神经网络模型,它在机器翻译等领域取得了突破性的成果。Transformer 模型由多层 Encoder 和 Decoder 组成,每一层都包含 Self-Attention 模块和前馈神经网络模块。
注意力机制的优势
- 提高模型的表达能力:注意力机制可以帮助模型更好地捕捉序列中重要的信息,从而提高模型的表达能力。
- 提高模型的效率:注意力机制可以减少模型需要处理的元素数量,从而提高模型的效率。
- 提高模型的泛化能力:注意力机制可以帮助模型更好地理解输入数据,从而提高模型的泛化能力。
总结
大语言模型作为一项颠覆性的技术,正在推动着人工智能的发展,并为我们的生活和工作带来革命性的变化。随着技术的不断进步和应用场景的不断拓展,大语言模型将在未来发挥更大的作用,为人类社会创造更多价值。
注意力机制是深度学习中的一个重要概念,它可以帮助模型更好地理解和生成文本。注意力机制在 Encoder-Decoder 框架和 Transformer 模型中得到了广泛应用,并取得了突破性的成果。