原文链接:https://arxiv.org/abs/2312.04519
简介:自动驾驶中的雷达可以在极端天气下进行感知,但相关模型的训练受到标注困难的阻碍。本文提出自监督框架,利用大量无标注雷达数据预训练雷达表达。方法包括雷达到雷达的、以及雷达到视觉的对比损失,以从雷达热图-摄像头图像对中学习通用表达。在3D目标检测任务上的实验表明,所提出的方法可以大幅超过SotA的性能。
本文的方法基于对比学习,不了解对比学习的读者,可参考自监督学习概述。本文方法的模态内学习部分与其中【例2】的SimCLR类似。
0. 方法概述
本文提出的自监督模型称为Radical(如图所示),可以单独的雷达数据或雷达-视觉数据对为输入。自监督损失包含两项,模态内项和跨模态项。前者关注雷达数据的特定结构,后者则利用视觉先验学习场景结构,以约束和增强稀疏雷达模态的特征。
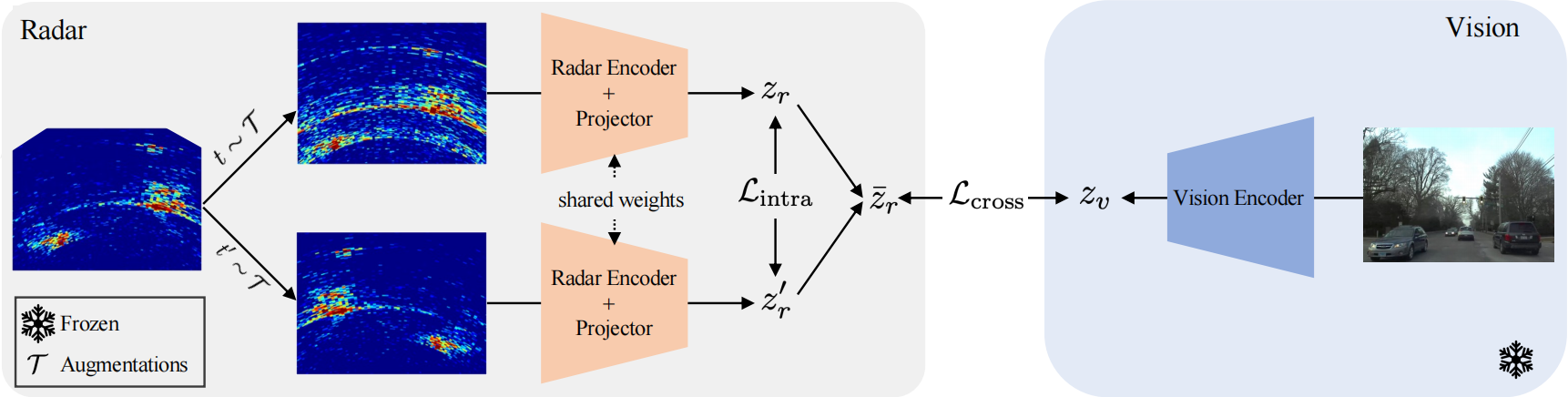
1. 蒸馏设置
令 ( r , v ) ∈ D (r,v)\in\mathcal D (r,v)∈D为数据集 D \mathcal D D的雷达-视觉数据对,其中 r ∈ R 1 × L × A r\in\mathbb R^{1\times L\times A} r∈R1×L×A为雷达热图, v ∈ R 3 × H × W v\in\mathbb R^{3\times H\times W} v∈R3×H×W为相应的RGB图像。
使用主干网络 f θ r f_{\theta^r} fθr编码雷达热图并使用MLP头 g ϕ r g_{\phi^r} gϕr投影,得到 z r = g ϕ r ( f θ r ( r ) ) ∈ R N z_r=g_{\phi^r}(f_{\theta^r}(r))\in\mathbb R^N zr=gϕr(fθr(r))∈RN。
类似地,编码图像得到 z v = f θ v ∗ ( v ) ∈ R N z_v=f^*{\theta^v}(v)\in\mathbb R^N zv=fθv∗(v)∈RN,其中 f θ v ∗ f^*{\theta^v} fθv∗为冻结的预训练图像主干。
知识会以雷达分支内部交互和雷达分支与图像分支交互的方式,从预训练图像主干 f θ v ∗ f^*{\theta^v} fθv∗中蒸馏到雷达主干 f θ r f{\theta^r} fθr。
2. 模态内雷达学习
为提高雷达嵌入的鲁棒性和区分度,本文设计数据增广(见后文) T \mathcal T T以进行雷达内实例判别学习。
具体来说,对每个雷达数据 r r r,本文先从 T \mathcal T T中随机抽取变换 t , t ′ ∼ T t,t'\sim\mathcal T t,t′∼T,以获取 r r r的两个正样本视图,并进行编码、投影和 l 2 l_2 l2归一化,得到 z r = g ϕ r ( f θ r ( t ( r ) ) ) , z r ′ = g ϕ r ( f θ r ( t ′ ( r ) ) ) z_r=g_{\phi^r}(f_{\theta^r}(t(r))),z'r=g{\phi^r}(f_{\theta^r}(t'(r))) zr=gϕr(fθr(t(r))),zr′=gϕr(fθr(t′(r)))。
在大小为 B B B的小批量中计算对比损失:
l i r → r ′ = − log exp ( sim ( z r , i , z r , i ′ ) ) ∑ j = 0 B exp ( sim ( z r , i , z r , j ′ ) ) l_i^{r\rightarrow r'}=-\log\frac{\exp(\text{sim}(z_{r,i},z'{r,i}))}{\sum{j=0}^B\exp(\text{sim}(z_{r,i},z'_{r,j}))} lir→r′=−log∑j=0Bexp(sim(zr,i,zr,j′))exp(sim(zr,i,zr,i′))
其中 sim ( x , y ) : = x T y / τ \text{sim}(x,y):=x^Ty/\tau sim(x,y):=xTy/τ为相似度函数, τ \tau τ为温度超参数。
可进一步计算雷达模态内的对称损失:
L intra = 1 2 B ∑ i B ( l i r → r ′ + l i r ′ → r ) L_\text{intra}=\frac1{2B}\sum_i^B(l_i^{r\rightarrow r'}+l_i^{r'\rightarrow r}) Lintra=2B1i∑B(lir→r′+lir′→r)
3. 跨模态雷达-视觉学习
虽然图像前视图和雷达热图表达在不同的坐标系下,但可通过对比损失对齐。
本文定义原型雷达向量为 z ˉ r = ( z r + z r ′ ) / 2 \bar z_r=(z_r+z'r)/2 zˉr=(zr+zr′)/2,并编码和归一化相应的视觉样本 z v = f θ v ∗ ( v ) z_v=f^*{\theta^v}(v) zv=fθv∗(v)。
类似雷达到雷达的对比学习,本文计算 l i r ˉ → v l_i^{\bar r\rightarrow v} lirˉ→v,其中 r ˉ \bar r rˉ代表原型雷达向量的使用。则跨模态对比损失为
L cross = 1 B ∑ i B l i r ˉ → v L_\text{cross}=\frac1B\sum_i^Bl_i^{\bar r\rightarrow v} Lcross=B1i∑Blirˉ→v
4. 增广
4.1 被赋予新用途的视觉增广
由于雷达热图类似图像,但又与图像表达在不同坐标系下,因此,可以利用小部分图像数据增广方法进行雷达热图增广。
具体来说,本文使用水平翻转、旋转、中心裁剪,其中后两者作用于极坐标系下。
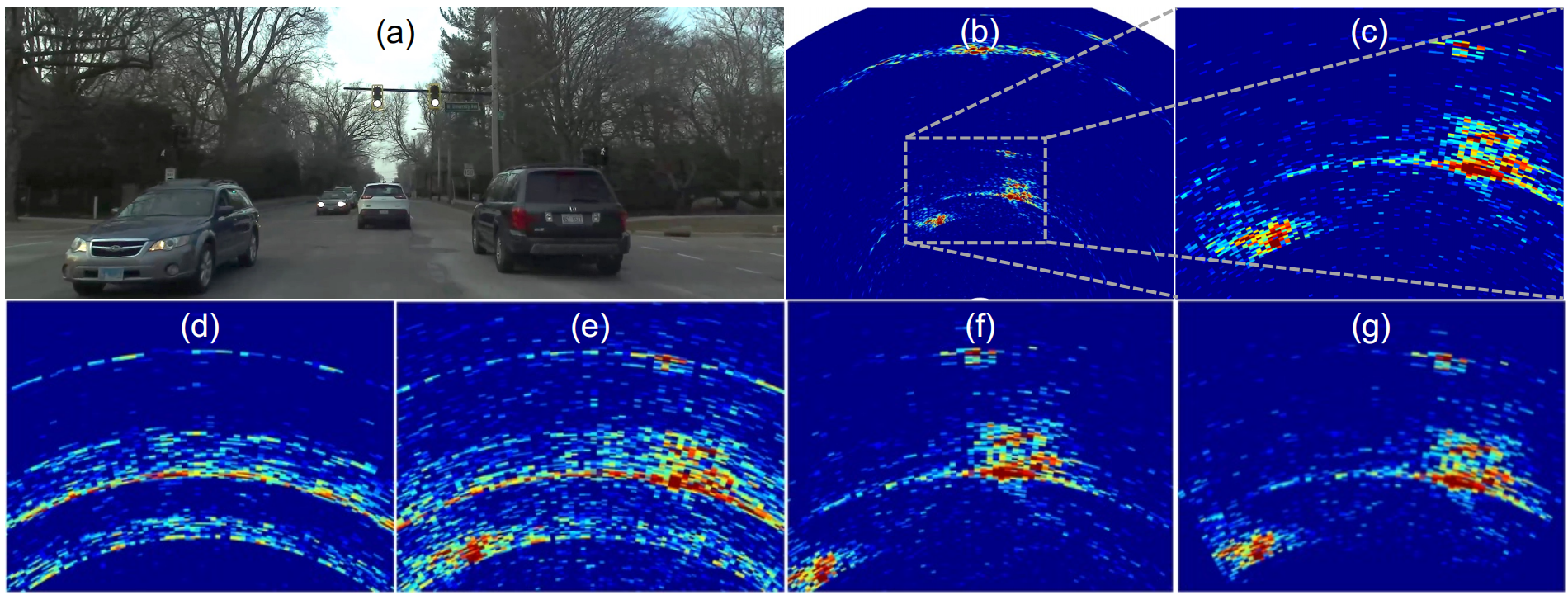
图中(c)为原始雷达热图,(d)为随机相位噪声,(e)为天线丢弃,(f)为极坐标下的旋转,(g)为极坐标下的中心裁剪。
4.2 雷达增广
本文还使用雷达专用增广,称为无线电MIMO掩膜(RMM)。
RMM实施
对于含 M M M个发射天线, N N N个接收天线的MIMO雷达,其每个天线对可得到距离-水平角热图 r ( ρ , ϕ ) ∈ R L × A r(\rho,\phi)\in\mathbb R^{L\times A} r(ρ,ϕ)∈RL×A,所有天线对能组成3D复张量 S ∈ C M N × L × A S\in\mathbb C^{MN\times L\times A} S∈CMN×L×A。
RMM包括以下两个操作:
(1)天线丢弃:利用MIMO雷达虚拟阵列的可重构性。随机省略一部分虚拟天线元素,以后续的进行信号聚合。
r ′ ( ρ , ϕ ) = ∣ ∑ k = 1 M N b k S ( ρ , ϕ , k ) ∣ , b k ∼ Bernoulli ( p ) r'(\rho,\phi)=|\sum_{k=1}^{MN}b_kS(\rho,\phi,k)|,b_k\sim\text{Bernoulli}(p) r′(ρ,ϕ)=∣k=1∑MNbkS(ρ,ϕ,k)∣,bk∼Bernoulli(p)
其中 r ′ ( ρ , ϕ ) r'(\rho,\phi) r′(ρ,ϕ)为增广雷达热图, k k k为天线对的索引, b k b_k bk为离散随机掩膜,以概率 p p p将第 k k k对天线置零。
该增广模拟了传感器部分失效或部分遮挡的情况,促使模型从不完整数据中学习并提高鲁棒性。
(2)随机相位噪声:该增广在聚合前随机化接收信号的相位,即
S k ′ = S k ⋅ e i θ k , θ k ∼ U [ α π , α π ) , 1 ≤ k ≤ M N S'_k=S_k\cdot e^{i\theta_k},\theta_k\sim U[\alpha\pi,\alpha\pi),1\leq k\leq MN Sk′=Sk⋅eiθk,θk∼U[απ,απ),1≤k≤MN
其中 S k S_k Sk为第 k k k对天线的信号, S k ′ S'_k Sk′为增广信号, θ k \theta_k θk为独立同分布的相位偏移, α ∈ [ 0 , 1 ) \alpha\in[0,1) α∈[0,1)为超参数。
该随机化模拟了环境因素和雷达与环境的相对运动引起的相位变化,也称为多普勒相位噪声。因此,其可以增强训练数据的覆盖率。
RMM实例化
使用上述两种增广方法的结合。实验中设置 p = 0.9 p=0.9 p=0.9和 α = 0.1 \alpha=0.1 α=0.1。
5. 下游微调
预训练后,丢弃投影头,而仅使用雷达主干连接任务头。
6. 实施细节
本文使用Radatron(不含FPN)作为雷达主干,预训练的CLIP作为图像编码器。
总结:本文的雷达热图增广方式(即文中RMM)为本文方法的关键和主要创新点。监督学习任务中也可以考虑使用该数据增广方式。