在大数据开发中,数据分层是一个至关重要的概念。合理的数据分层可以有效地提升数据处理的效率和质量。本文将详细介绍数据分层的标准流向和相关注意事项,并结合实际应用进行说明。
数据分层的标准流向
根据行业标准,数据分层的标准流向如下:
- ODS (Operational Data Store): 操作型数据存储,主要用于数据的初步清洗和整合。
- DWD (Data Warehouse Detail): 数据仓库明细层,存储经过清洗和转换的详细数据。
- DWS (Data Warehouse Summary): 数据仓库汇总层,存储汇总和聚合后的数据。
- DM (Data Mart): 数据集市,面向具体业务场景提供定制化的数据服务。
需要注意的是,在这一标准流向中,禁止出现反向依赖,即下游数据层不应反向依赖上游数据层的数据。
维度数据流向
对于维度数据,可以从 DWD 流向 DIM 或者从 ODS 流向 DIM。在使用 ODS 直接到 DIM 的情况下,必须确保数据质量足够高,以避免数据误差的累积和放大。
数据引用和写入规则
DIM、DWS 和 DM 可以往自身分层写入数据,如不同粒度的数据写入。具体的引用和写入规则如下表所示:
| 写入 \ 引用 | ODS | DWD | DWS | DM | DIM | TMP |
|---|---|---|---|---|---|---|
| ODS | ✔ | ✔ | ||||
| DWD | ✔ | ✔ | ✔ | ✔ | ||
| DWS | ✔ | ✔ | ✔ | ✔ | ✔ | |
| DM | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| DIM | ✔ | ✔ | ✔ | ✔ | ✔ | |
| TMP | ✔ | ✔ | ✔ | ✔ | ✔ |
数据流向示意图
为了更直观地展示数据流向,以下是数据流向的示意图:
源 ODS 含缺省调整 DWD DWS DIM DM TMP 分析 接口 队列 表
更详细的流向:
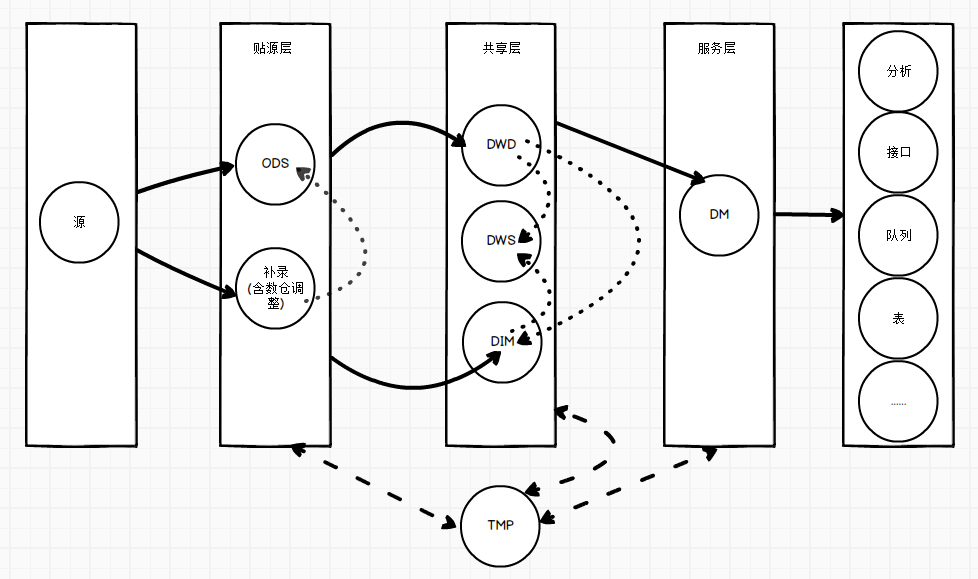
数据分层标准流向示例
为了更好地理解数据分层的标准流向,下面我们举几个实际应用中的例子来说明这些概念的具体使用场景。
示例 1:电商平台的订单数据处理
-
ODS 层:
- 电商平台每天会有大量的订单生成,这些原始订单数据首先会被存储到 ODS 层。此时的数据还未经过任何清洗和转换,直接从业务系统导出。
sqlCREATE TABLE ods_order ( order_id STRING, user_id STRING, product_id STRING, order_date STRING, order_amount DOUBLE ); -
DWD 层:
- 订单数据从 ODS 层进入 DWD 层,在这里进行数据清洗、转换,去除重复数据,格式化日期等操作,以保证数据的准确性和一致性。
sqlCREATE TABLE dwd_order ( order_id STRING, user_id STRING, product_id STRING, order_date DATE, order_amount DOUBLE ); INSERT INTO dwd_order SELECT order_id, user_id, product_id, TO_DATE(order_date, 'yyyy-MM-dd') AS order_date, order_amount FROM ods_order WHERE order_id IS NOT NULL; -
DWS 层:
- 在 DWS 层,对订单数据进行聚合和汇总,生成每日、每月的销售报表等。
sqlCREATE TABLE dws_daily_sales ( sale_date DATE, total_sales DOUBLE ); INSERT INTO dws_daily_sales SELECT order_date AS sale_date, SUM(order_amount) AS total_sales FROM dwd_order GROUP BY order_date; -
DM 层:
- 最后,在 DM 层,为业务部门提供具体分析需求的数据,如按用户、按产品类别的销售情况等。
sqlCREATE TABLE dm_user_sales ( user_id STRING, total_sales DOUBLE ); INSERT INTO dm_user_sales SELECT user_id, SUM(order_amount) AS total_sales FROM dwd_order GROUP BY user_id;
示例 2:金融机构的客户行为分析
-
ODS 层:
- 客户的原始交易记录会首先进入 ODS 层,这些数据来自不同的业务系统,包括 ATM 交易、POS 交易、网上银行交易等。
sqlCREATE TABLE ods_transaction ( transaction_id STRING, customer_id STRING, transaction_date STRING, transaction_amount DOUBLE, transaction_type STRING ); -
DWD 层:
- 在 DWD 层,对交易数据进行清洗和标准化,去除重复数据,标准化交易类型等。
sqlCREATE TABLE dwd_transaction ( transaction_id STRING, customer_id STRING, transaction_date DATE, transaction_amount DOUBLE, transaction_type STRING ); INSERT INTO dwd_transaction SELECT transaction_id, customer_id, TO_DATE(transaction_date, 'yyyy-MM-dd') AS transaction_date, transaction_amount, transaction_type FROM ods_transaction WHERE transaction_id IS NOT NULL; -
DWS 层:
- 在 DWS 层,对交易数据进行汇总和分析,生成每日、每月的交易统计报表。
sqlCREATE TABLE dws_monthly_transaction ( transaction_month STRING, total_transactions INT, total_amount DOUBLE ); INSERT INTO dws_monthly_transaction SELECT DATE_FORMAT(transaction_date, 'yyyy-MM') AS transaction_month, COUNT(transaction_id) AS total_transactions, SUM(transaction_amount) AS total_amount FROM dwd_transaction GROUP BY DATE_FORMAT(transaction_date, 'yyyy-MM'); -
DM 层:
- 在 DM 层,为风险管理部门提供客户行为分析的数据,如高频交易客户名单、异常交易行为分析等。
sqlCREATE TABLE dm_high_freq_customers ( customer_id STRING, transaction_count INT ); INSERT INTO dm_high_freq_customers SELECT customer_id, COUNT(transaction_id) AS transaction_count FROM dwd_transaction GROUP BY customer_id HAVING COUNT(transaction_id) > 100;
通过以上示例,可以清晰地看到数据从 ODS 层经过 DWD 层、DWS 层到 DM 层的流转过程。在每一层,数据都经过了一定的处理和转换,以适应不同的业务需求和分析场景。严格遵循数据分层的标准流向,可以有效地提高数据处理的效率和质量,保障数据的准确性和一致性。